Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 taoht
a54aa68e55
taoht
a54aa68e55
|
1 year ago | |
|---|---|---|
| .. | ||
| dataset | 1 year ago | |
| doc | 1 year ago | |
| scripts | 1 year ago | |
| src | 1 year ago | |
| AISyncore-1.1-py3-none-any.whl | 1 year ago | |
| AISyncore-2.0-py3-none-any.whl | 1 year ago | |
| AiSyn_server_start.py | 1 year ago | |
| README.md | 1 year ago | |
| __init__.py | 1 year ago | |
| predict.py | 1 year ago | |
| run_train_aisyn.ipynb | 1 year ago | |
| run_train_standalone.ipynb | 1 year ago | |
| train.py | 1 year ago | |
| train_aisyn_GPU.py | 1 year ago | |
| train_aisyn_NPU.py | 1 year ago | |
README.md
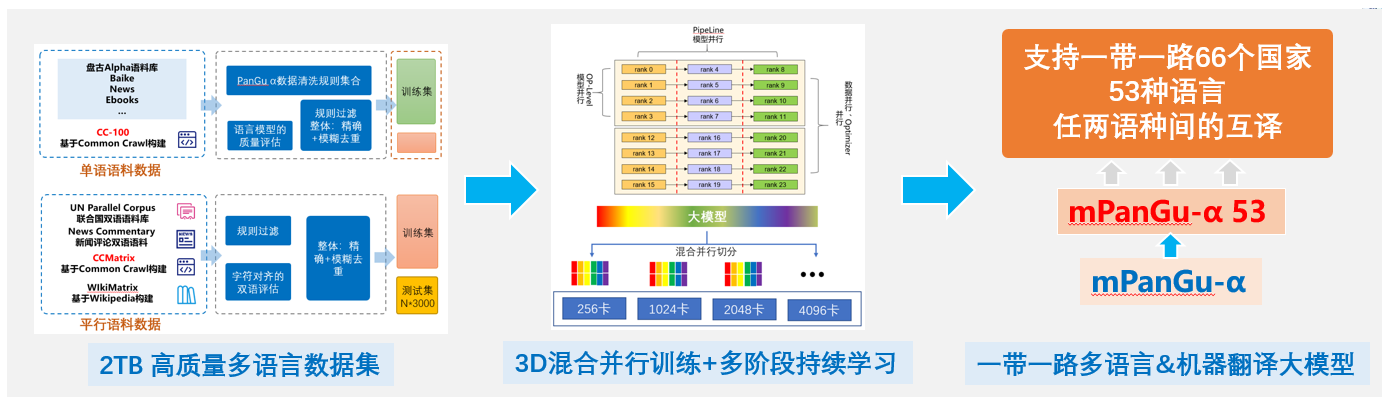
mPanGu-Alpha-53简介
mPanGu-α-53 来源于鹏程·PanGu-α,基于一带一路多语言翻译场景应用,基于“鹏城云脑2”在清洗后的高质量一带一路多语言数据集上进行单双语混合训练得到,单模型支持52种语言任意两种语言间的互译。在WMT2021多语言任务赛道,在FLORES-101 devtest数据集,对比任务榜单No.1已覆盖的50种语言“中<->外”100个翻译方向平均BLEU值提升0.354。
mPanGu-α-53 技术细节
环境说明
鹏城实验室率先开放全球最大规模自然语言语料数据集1TB高质量的一带一路多语言数据集,通过鹏程靶场+数据不动代码动的方式实现各个领域间数据要素的流通,以充分释放数据要素价值。本案例以mPanGu-350M模型为例在靶场上进行训练。
| 靶场环境(mindspore 1.7版本) | modelarts(mindspore 1.7版本) | 本地GPU环境(mindspore 1.7版本) | 案例参考 | |
|---|---|---|---|---|
| 单机单卡 | 支持 | 支持 | 支持 | 本案例 |
| 单机单卡协同训练 | 支持 | 支持 | 支持 | 本案例 |
| 单机8卡 | 支持 | 支持 | 支持 | 本案例 |
| 单机8卡协同训练 | 支持 | 支持 | 支持 | 本案例 |
| 多机多卡 | 支持 | 支持 | 支持 | 本案例 |
| 多机多卡协同训练 | 待环境支撑完成 | 支持 | 支持 | 本案例 |
环境要求
sentencepiece >= 0.1.94
AISyncore == 2.0
全流程手把手教学
1、注册成为靶场用户
打开靶场环境 https://datai.pcl.ac.cn/#/home ,进行注册登录
2、数据准备
靶场开源数据下载&本地数据上传
- a)、靶场开源数据下载
#导入数据集 一带一路多语言数据集
#测试数据集将下载到当前目录下的"./SAMPLE_DATA"文件夹下,如需改变目录名称请自行修改
import wfio
_INPUT = '{"type":25,"uri":"sample_data/2114/"}'
wfio.load_files(_INPUT, dir_name='./SAMPLE_DATA')
- b)、本地数据上传使用
若您的数据集大小小于20G,则可以利用靶场云盘的功能上传到数据集
## 下载数据集
import wfio
wfio.download_from_cloud_disk('path://44047257fdf04ea8b2b59f42875b3126', './USER_DATA/webtext2019zh-train.zip')
#进行解压到指定目录,如需改变目录名称请自行修改
!unzip -d ./USER_DATA ./USER_DATA/webtext2019zh-train.zip
数据抽样
这里以“一带一路多语言数据集”为例(单双语数据格式及容量,详见一带一路多语言数据集):
# 设定抽样文件本地路径和抽样保存路径
data_dir = '/cache/data/'
save_path = '/cache/data_sample/'
# 设定抽样策略, 配置中、英单语文件抽取容量, MB
mono_sample_strategy = {'zh': 1024, 'en': 1024}
# 设定抽样策略, 配置中、英双语文件抽取容量, MB
corpus_sample_strategy = {'zh-en': 1024}
# 单语抽取
!python ./dataset/dataset_sample.py \
--data_path $data_dir \ # 原始数据路径
--output_path $save_path \ # 抽取数据保存路径
--sample_strategy "{mono_sample_strategy}" \ # 数据抽取的策略
--mode 'mono' # 单语抽取模式
# 双语抽取
!python ./dataset/dataset_sample.py \
--data_path $data_dir \ # 原始数据路径
--output_path $save_path \ # 抽取数据保存路径
--sample_strategy "{corpus_sample_strategy}" \ # 数据抽取的策略
--mode 'corpus' # 双语抽取模式
数据转化
这里以转化为mindRecord数据文件为例:
data_dir = '/cache/data_sample/*.txt'
save_path = '/cache/MindRecord/mPanGu_zh-en_mindrecord'
# 多进程,一个进程绑定一个mindrecord文件写
num_mindrecord = 50 #不要设置的太小,不然进程少,转换较慢
!python ./dataset/pre_process_bc.py \
--data_path "{data_dir}" \
--output_file $save_path \
--num_process $num_mindrecord \
--tokenizer 'spm_13w'
# 文件内打乱
!python ./dataset/mindrecord_shuffle.py \
--input-dir "/cache/MindRecord/" \
--output-dir "/cache/MindRecord_shuffle/"
3、启动训练
靶场本地调试
- 单机单卡、8卡训练(多机多卡同8卡)
【注意】这里为靶场环境的任务启动形式,在cmd列表中配置启动命令参数如下:
import os
from davincirunsdk import start_and_wait_distributed_train
# 单机单卡, cmd
cmd = ['python', 'train.py', '--distribute=false',
'--device_num=1',
'--data_url=/cache/MindRecord/',
'--run_type=train',
'--mode=350M',
'--per_batch_size=4',
'--save_checkpoint_path=/cache/ckpt/',
'--save_checkpoint=True']
# 单机8卡, cmd
cmd = ['python', 'train.py', '--distribute=true',
'--device_num=8',
'--data_url=/cache/MindRecord/',
'--run_type=train',
'--mode=350M',
'--per_batch_size=4'
'--save_checkpoint_path=/cache/ckpt/',
'--save_checkpoint=True']
start_and_wait_distributed_train(cmd, output_notebook=True)
- 单机单卡、8卡协同训练(暂不支持在靶场环境的多机协同)
【注意】这里为靶场环境的任务启动形式,在cmd列表中配置启动命令参数如下:
# 任意节点,启动Server, 通过调用API获取协同计算任务的端口
! python AiSyn_server_start.py --uid 666000
# 可得到待使用port端口打印, 对应client使用的ng_port配置, 如下19309即为分配使用端口号
Example: start_server:20 - start : 19309
import os
from davincirunsdk import start_and_wait_distributed_train
# 单卡节点
cmd = ['python', 'train_aisyn_NPU.py', '--distribute=false',
'--device_num=1',
'--data_url=/cache/MindRecord/',
'--run_type=train',
'--mode=350M',
'--per_batch_size=4'
'--ng_port=30021']
# 8卡节点
cmd = ['python', 'train_aisyn_NPU.py', '--distribute=true',
'--device_num=8',
'--data_url=/cache/MindRecord/',
'--run_type=train',
'--mode=350M',
'--per_batch_size=4'
'--ng_port=30021']
start_and_wait_distributed_train(cmd, output_notebook=True)
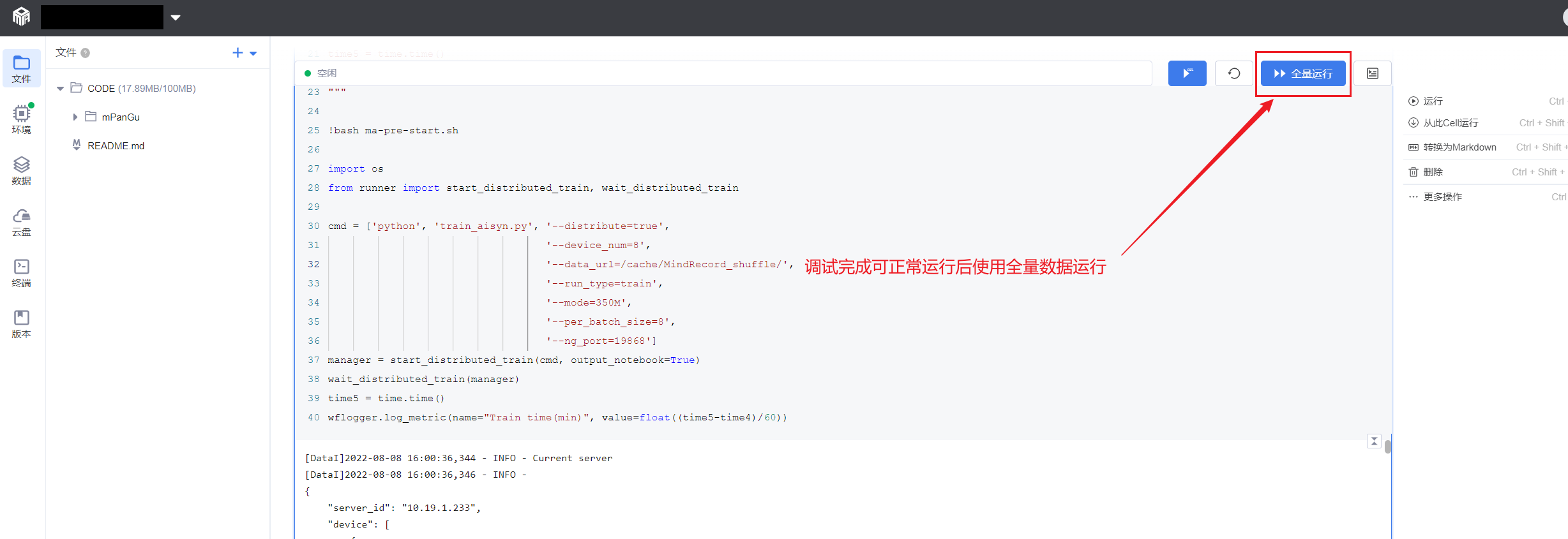
靶场全量训练
本地调试环境完全跑通后,jupyter右上角按钮提交全量训练作业,则任务自动下发到全量训练环境,数据对应全量数据。
全量运行环境用户不可查看运行日志,需通过靶场特有API实现训练过程的监控,添加代码如下:
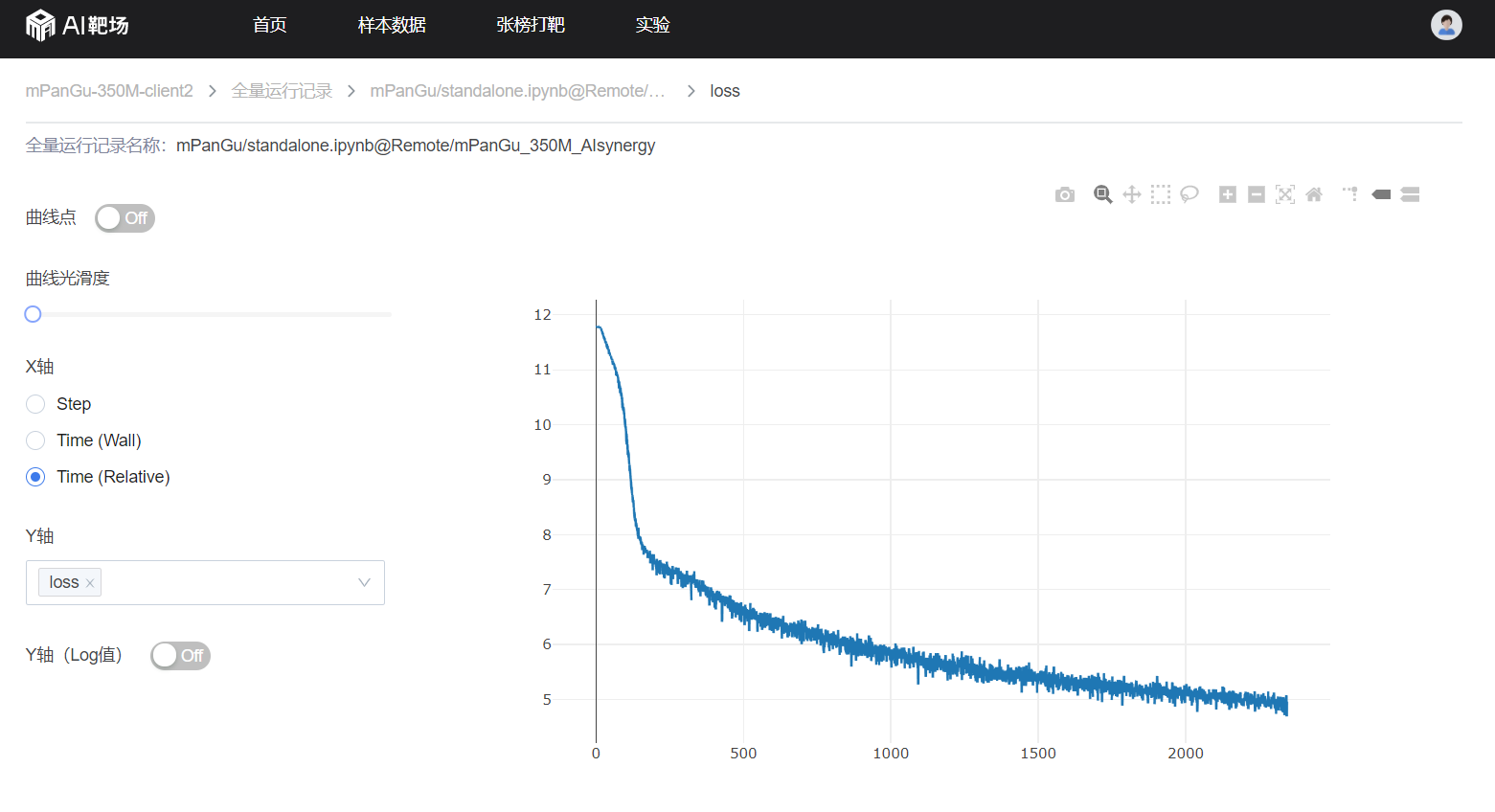
a)、添加训练过程记录
在./src/callback.py line:66, 为了在靶场全量运行封闭环境打印训练过程相关信息
from wf_analyse.analyse import wflogger
steps = cb_params.cur_step_num + int(self.has_trained_step)
if steps%50 == 0:
wflogger.log_metrics(metrics={"loss": float(loss_value),
"scale": int(cb_params.net_outputs[2].asnumpy())
}, step=steps)
b)、添加模型文件上传
添加如下代码对保存的模型压缩上传,训练任务完成后可支持模型文件的下载
import os
from pathlib import Path
from zipfile import ZipFile
import wfio
def zip_compression(source_dir, target_file):
"""zip压缩文件夹
:param source_dir: 需要压缩的文件夹
:param target_file:目标zip文件
:return:"""
with ZipFile(target_file, mode='w') as zf:
# 扫描目录下所有文件
for path, dir_names, filenames in os.walk(source_dir):
path = Path(path)
# 生成在文件夹在压缩包中的相对路径
arc_dir = path.relative_to(source_dir)
for filename in filenames:
zf.write(path.joinpath(filename), arc_dir.joinpath(filename))
zip_compression('../../ckpt/rank_0', '/local/path/to/ckpt.zip')
# 对应:上传文件, 本地压缩文件路径
wfio.upload_to_oss('ckpt.zip', '/local/path/to/ckpt.zip')
c)、启动全量训练
GPU本地训练
- GPU本地单机单卡、8卡训练
# 单机单卡, cmd
python train.py --distribute=false \
--device_target="GPU" \
--data_url="/tmp/data" \
--mode="350M" \
--run_type="train" \
--per_batch_size=1
# 单机8卡, cmd
export NCCL_DEBUG=INFO
export NCCL_SOCKET_IFNAME=ib
export NCCL_IB_HCA=^mlx5_16,mlx5_17
bash scripts/run_train.sh RANK_SIZE HOSTFILE DATASET PER_BATCH MOD
Example: bash run_train.sh 2 hostfile /cache/MindRecord_shuffle/ 4 350M
- GPU本地单机单卡、8卡协同训练
# 单机单卡, cmd
python train_aisyn_GPU.py --distribute=false \
--device_target="GPU" \
--data_url="/tmp/data" \
--mode="350M" \
--run_type="train" \
--per_batch_size=1 \
--ng_port=*****
# 单机8卡, cmd
export NCCL_DEBUG=INFO
export NCCL_SOCKET_IFNAME=ib
export NCCL_IB_HCA=^mlx5_16,mlx5_17
bash scripts/run_train_aisyn_GPU.sh RANK_SIZE HOSTFILE DATASET PER_BATCH MOD PORT
Example: bash run_train_aisyn_GPU.sh 2 hostfile /cache/MindRecord_shuffle/ 4 350M 30021
多卡协同案例
| 多卡协同场景类型 | 靶场环境(mindspore 1.7版本) | modelarts(mindspore 1.7版本) | 本地GPU环境(mindspore 1.7版本) | 是否支持 |
|---|---|---|---|---|
| 同构 | client 1 | client 2 | - | 支持 |
| 异构 | client 1 | - | client 2 | 支持 |
| 异构 | - | client 1 | client 2 | 支持 |
| 异构 | client 1 | client 2 | client 3 | 支持 |
1.数据处理
client 1, client 2, client 3数据处理流程一致,同上述流程
2.server启动
# 任意节点,启动Server, 通过调用API获取协同计算任务的端口
! python AiSyn_server_start.py --uid 666000
# 可得到待使用port端口打印, 对应client使用的ng_port配置, 如下19309即为分配使用端口号
Example: start_server:20 - start : 19309
3.client启动(靶场)
import os
from davincirunsdk import start_and_wait_distributed_train
cmd = ['python', 'train_aisyn_NPU.py', '--distribute=true',
'--device_num=8',
'--data_url=/cache/MindRecord/',
'--run_type=train',
'--mode=350M',
'--per_batch_size=4',
'--ng_port=30021']
start_and_wait_distributed_train(cmd, output_notebook=True)
4.client启动(ModelArts)
提交训练作业,配置代码路径和数据路径
python train_aisyn_NPU.py --distribute=true,
--device_num=8,
--data_url=/cache/MindRecord/,
--run_type=train,
--mode=350M,
--per_batch_size=4,
--ng_port=30021
5.client启动(本地GPU)
镜像:docker pull zhangy03/mindspore_gpu_zy:1.7.0
export NCCL_DEBUG=INFO
export NCCL_SOCKET_IFNAME=ib
export NCCL_IB_HCA=^mlx5_16,mlx5_17
bash scripts/run_train_aisyn_GPU.sh RANK_SIZE HOSTFILE DATASET PER_BATCH MOD PORT
Example: bash run_train_aisyn_GPU.sh 2 hostfile /cache/MindRecord_shuffle/ 4 350M 30021
交流通道
- 提问:https://git.openi.org.cn/PCL-Platform.Intelligence/mPanGu-Alpha-53/issues
- 邮箱:taoht@pcl.ac.cn
项目信息
鹏城实验室-智能部-高效能云计算所-分布式计算研究室
许可证
[Apache License 2.0]
鹏城众智AI协同计算平台AISynergy是一个分布式智能协同计算平台。该平台的目标是通过智算网络基础设施使能数据、算力、模型、网络和服务,完成跨多个智算中心的协同计算作业,进而实现全新计算范式和业务场景,如大模型跨域协同计算、多中心模型聚合、多中心联邦学习等。
Java Vue Python JavaScript Go other







