Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 sk-w
b7c5c16dd2
sk-w
b7c5c16dd2
|
1 year ago | |
|---|---|---|
| mdImage | 1 year ago | |
| README.md | 1 year ago | |
| dataset.py | 1 year ago | |
| net.py | 1 year ago | |
| test.py | 1 year ago | |
| train.py | 1 year ago | |
README.md
AlexNet
Model Innovation
1.Relu is used as the activation function instead of the traditional sigmoid and tanh.

Relu is an unsaturated function. In this paper, it is verified that its effect exceeds sigmoid in a deeper network, and
the gradient dispersion problem of sigmoid in a deeper network is successfully solved.
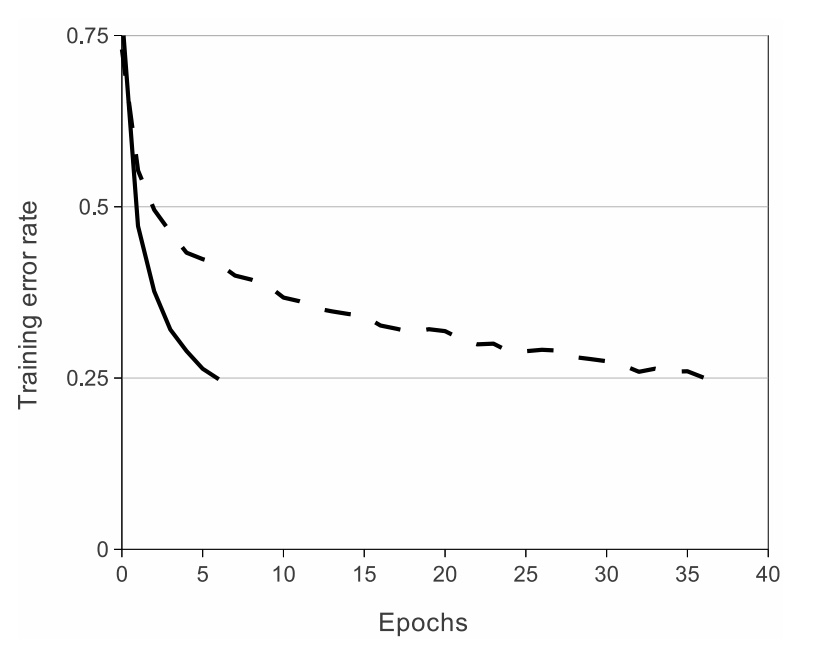
2.Model training on multiple GPUs
Improve the training speed of the model and the use scale of data
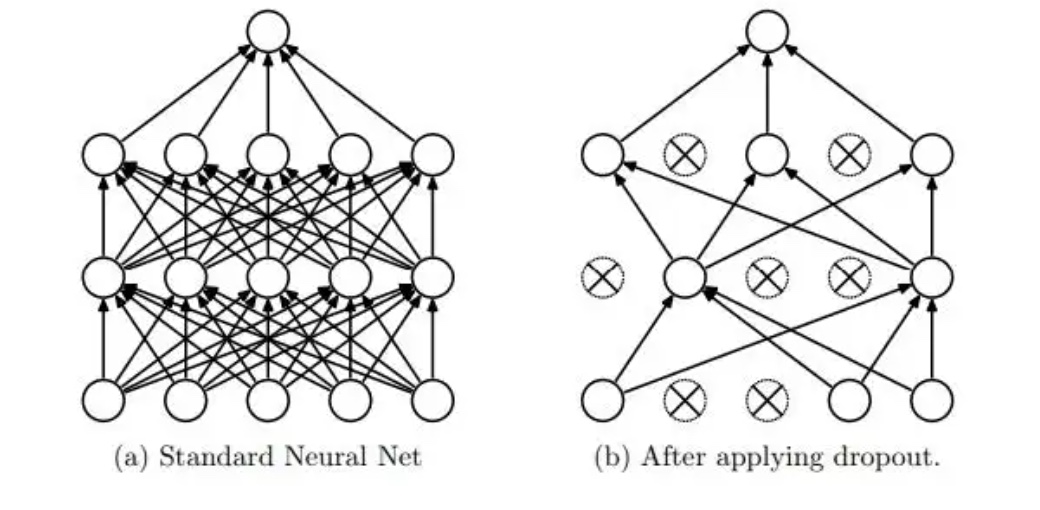
3.Using random drop technique (dropout)
Selectively ignore individual neurons in training,avoid overfitting of the model.
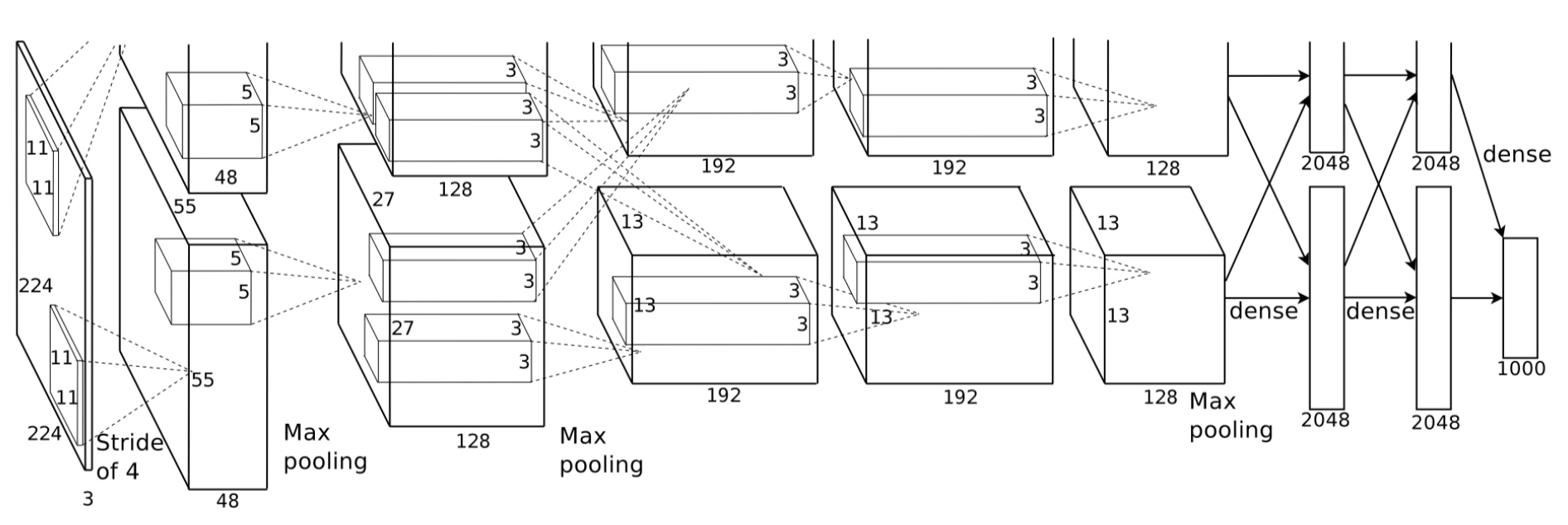
Model Architecture
The architecture of AlexNet is 5(convolution layer,relu and pool)+3(full connect layer).

No Description
Python