MNIST Digit Classifier
Implemented ML Model on The MNIST Database using different approaches.
Implemented a convolutional network that learns to generate encodings of passed images such as to minimize the triplet loss function given by :
ℒ(A,P,N) = max( || f(A)-f(P) ||2) - || f(A)-f(N) ||2 + 𝜶, 0)
where A is an anchor input, P is a positive input of the same class as A, N is a negative input of a different class from A, 𝜶 is a margin between positive and negative pairs, and f is an embedding.
Network Architechture
{
"name": "Model",
"arch": {
"convnet1": {
"conv1" : "Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2))",
"conv2" : "Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))",
"actv" : "ReLU()",
"pool" : "MaxPool2d(kernel_size=3, stride=2)"
},
"convnet2": {
"conv1" : "Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))",
"conv2" : "Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1))",
"actv" : "ReLU()",
"pool" : "MaxPool2d(kernel_size=2, stride=2)"
},
"convnet3": {
"conv1" : "Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2))",
"conv2" : "Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))",
"actv" : "ReLU()",
"pool" : "MaxPool2d(kernel_size=3, stride=2)"
},
"FullyConnected": {
"fc1": "Linear(in_features=4096, out_features=2048)",
"fc2": "Linear(in_features=2048, out_features=512)",
"fc3": "Linear(in_features=512, out_features=128)"
}
},
"training": {
"images": "100 images each of classes 0, 1, 2 only",
"optimizer": "Adam",
"loss" : "Triplet Loss",
"batch_size" : 10,
"epochs" : 5
},
"results": {
"Class 0": { "correct": 5804, "total": 5923,"acuracy": "97.99%" },
"Class 1": { "correct": 6648, "total": 6742,"acuracy": "98.60%" },
"Class 2": { "correct": 5830, "total": 5958,"acuracy": "97.85%" },
"Class 3": { "correct": 5877, "total": 6131,"acuracy": "95.85%" },
"Class 4": { "correct": 5830, "total": 5842,"acuracy": "99.79%" },
"Class 5": { "correct": 5274, "total": 5421,"acuracy": "97.28%" },
"Class 6": { "correct": 5908, "total": 5918,"acuracy": "99.83%" },
"Class 7": { "correct": 5589, "total": 6265,"acuracy": "89.20%" },
"Class 8": { "correct": 5777, "total": 5851,"acuracy": "98.73%" },
"Class 9": { "correct": 5849, "total": 5949,"acuracy": "98.31%" }
}
}
This Siamese Network was used to implement One Shot Learning which is a technique of learning representations from a single sample.
Images of classes 3 to 9 weren't used while training the model, i.e they were passed to the model for the first time while testing it.
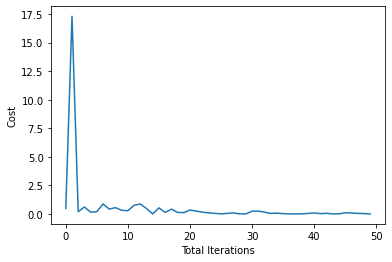
Cost
This Network comprises of two Convolutional Layers followed by three Fully Connected Layers.
Network Architecture:
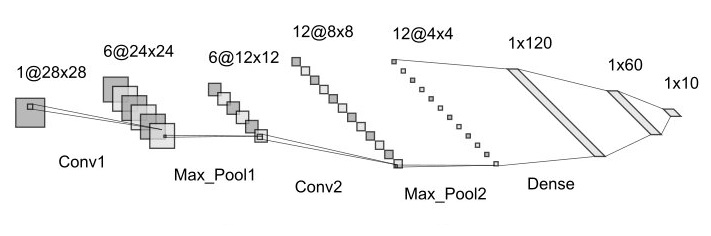
Network [
Conv1 : [in_channels=1, out_channels=6, kernel_size=5, stride=1],
MaxPool1 : [kernel_size=2, stride=2],
Conv2 : [in_channels=6, out_channels=12, kernel_size=5, stride=1],
MaxPool2 : [kernel_size=2, stride=2],
FC1 : [in_features=192, out_features=120],
FC2 : [in_features=120, out_features=60],
Output : [in_features=60, out_features=10],
]
Learning Curve:

Batch size = 100
Learning Rate = 0.002
iterations = 50
Accuracy on Train Set = 99.58 %
Accuracy on Test Set = 98.64 %
Uses 4 Linear Layers to train the model which takes 28*28 input features.
Network Architecture:
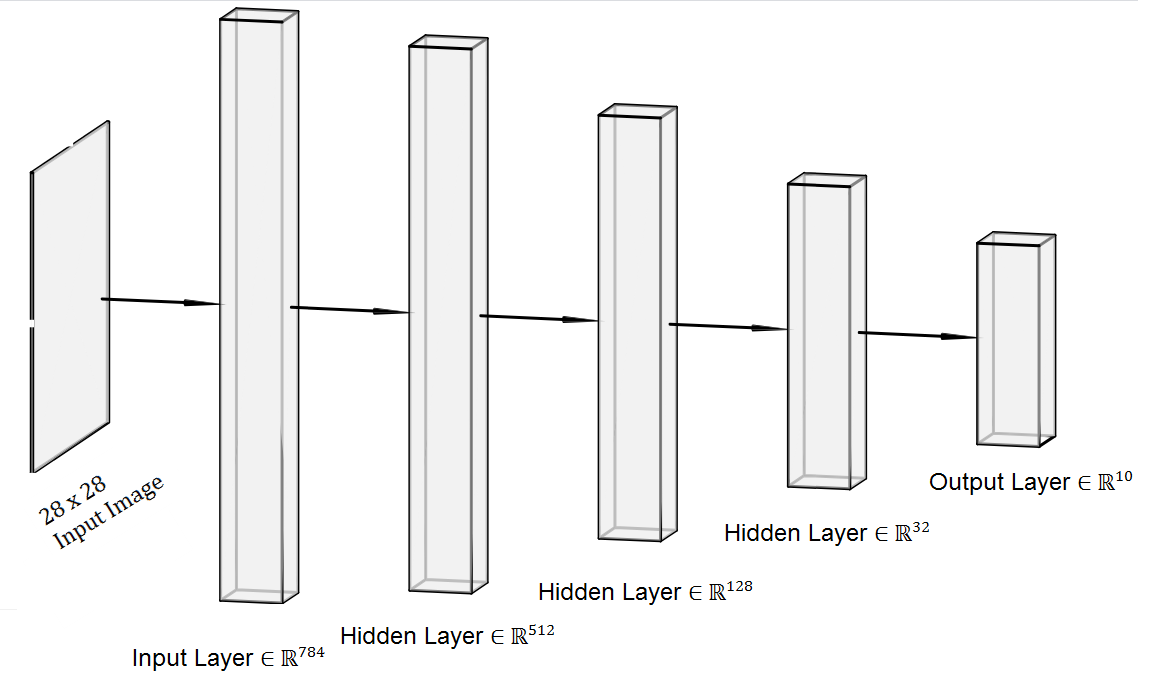
Learning Curve:

Learning Rate = 0.11
Accuracy on Train Set = 98.272 %
Accuracy on Test Set = 98.259 %
Take input with input features = 28*28. Uses a Single Layer(also the output layer) to implement the model.
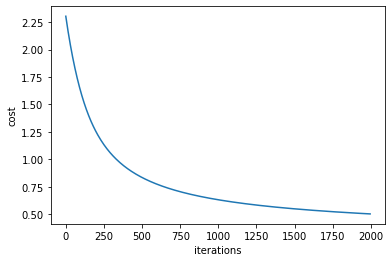
Learning Rate = 0.009
Accuracy on Test Set = 94.181 %
Others Branches