众智AI协同计算平台介绍
智算网络协同计算是指基于智算网络基础设施及服务,由多个智算网络用户按照应用场景抽象的作业角色利用数据、算力、模型、网络等资源协同完成一个智能计算作业的计算模式。鹏城众智AI协同计算平台AISynergy是一个分布式智能协同计算平台。该平台的目标是通过智算网络基础设施使能数据、算力、模型、网络和服务,完成跨多个智算中心的协同计算作业,进而实现全新计算范式和业务场景,如大模型跨域协同计算、多中心模型聚合、多中心联邦学习等。这种智能协同计算范式成为充分发挥智算网络整体效能、赋能人工智能产业规模化应用的关键。
AISynergy包括两大部分,第一大部分是协同计算作业管理部分即AISynergy-Platform,实现协同计算作业的配置、管理与可视化,另一部分是协同计算框架即AISynergy-Core,主要完成协同计算作业的核心计算逻辑,由智算网络用户进行配置和部署。众智协同计算平台包括多个组件:协同计算WEB平台、协同计算代理服务器、以及gRPC服务等。 (其中AISynergy-Core也可以单独安装和使用)
主要技术特点
众智协同计算平台的主要技术特点如下:
- 支持跨域异构协同训练:支持跨异构智算中心的协同计算,能够支持GPU、NPU、MLU等异构AI集群之间以及MindSpore、Pytorch、TensorFlow、PaddlePaddle等异构AI架构之间的模型协同训练;
- 作业管理与核心计算逻辑解耦:平台架构上将协同计算作业管理与协同计算核心计算逻辑框架解耦,协同计算作业管理既可以对接云际学习平台JoinAI,也可以对接本系统的协同计算框架AISynergy-Core。
- 接口灵活可用:针对不同的AI框架统一接口,用户只需要添加几行代码就可以将算法变为协同计算的算法,使用灵活方便。
- 并行模块:尽量减少侵入性代码,支持多种并行策略的协同训练,同时支持自动化和定制化的并行策略,并且支持了gloo端broadcast、allreduce等通信原语,以适配大模型跨域训练的场景。
- benchmark:提供benchmark,负责收集有关设备和训练模型的信息(内存、通信延迟、计算能力)等,提供每个子任务多个优化的协同计算资源分配方案。
- 多框架算法案例:提供不同框架、不同模型参数量的案例。目前已实现跨异构硬件(云脑I和云脑II)2.6B参数模型的训练。具体可参见提供的案例。
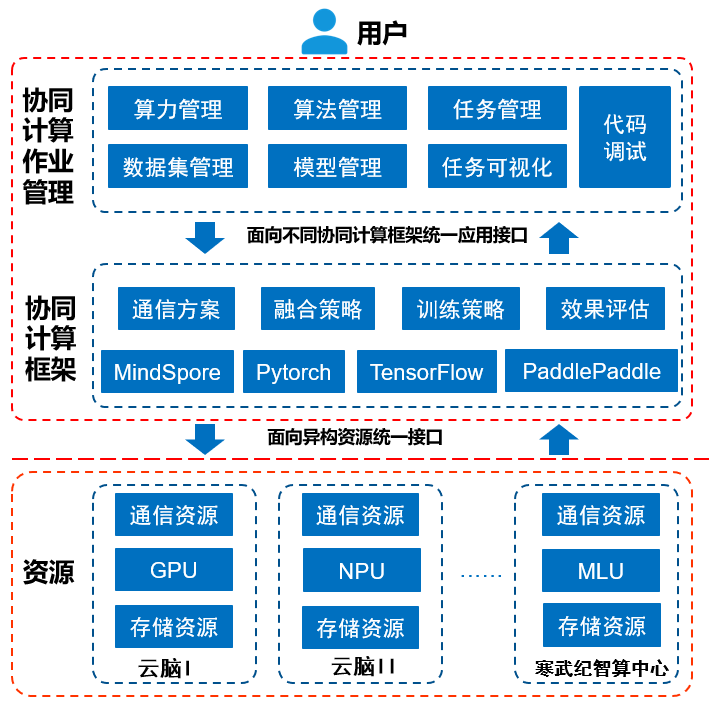
协同计算平台架构图
其中:
协同计算作业管理的功能如下:
受理外部请求,实现身份管理、权限管理、算法管理和模型管理等
负责收集存储、CPU、GPU、NPU等资源,控制参数融合事件、效果评估等分布学习过程的各类事件,以及各类请求操作
协同计算框架的功能如下:
训练策略:对同步周期进行动态调整、对超时或失效的本地训练进行重置等
训练效果评估:对中间结果进行验证,对最终结果进行分析等
融合策略:支持多种不同的融合策略
参数融合方式:目前实现的是全同步方式,正在研发异步方式和混合方式。
协同计算资源包括:
计算资源:CPU、GPU、NPU、MLU
网络资源:带宽、网络延迟等
存储资源:分布式文件存储、状态数据库等
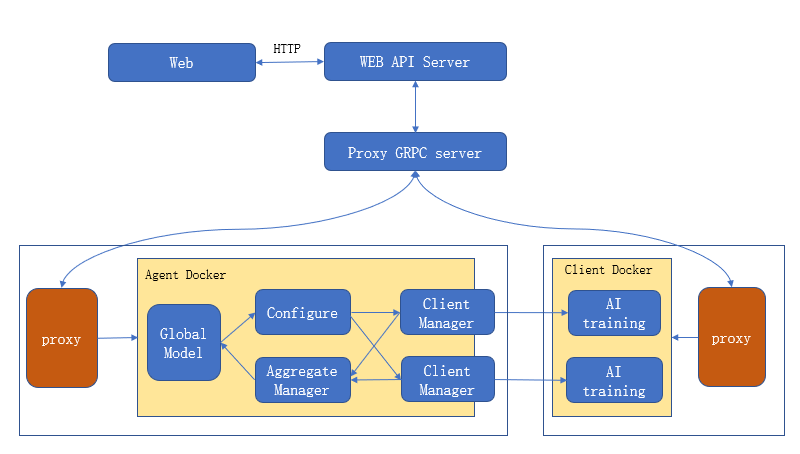
各个模块关系图
其中:
[WEB]:前端展示页面
[WEB API Server]:后台的管理、数据库的管理、命令的转发等
[Proxy gRPC server]: 实现命令的转发,采集机器信息等
[Proxy]: 实现机器信息采集、运行状态采集、任务执行。任务执行包括任务启动、任务停止等操作,主要是对容器进行启动和停止
AI agent:协同训练服务器,运行在任务组机器上面,实现协调多机构的AI Client的训练过程
AI Client: 协同训练客户端,运行在任务所在机构机器上面,实现对训练数据进行训练,并上传训练过程数据到融合节点
部署
平台部署请见
[部署]
用户使用手册
用户使用手册请见
[平台使用手册]
使用流程
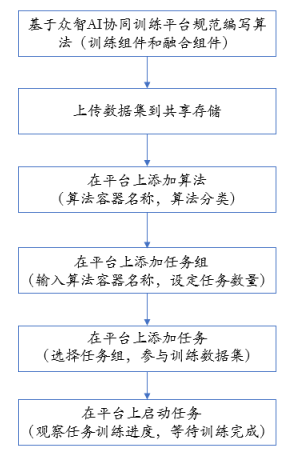
系统主要由算法、算力、数据集、任务组、任务、模型组成,首先用户需要编写特定需求的算法,并满足协同训练的融合训练的基础架构,通过Docker打包并部署到相应的Docker hub服务器完成算法的部署。算力是支撑协同训练的物理基础,可以支持物理机和鹏城云脑部署。数据集是训练的输入,需要部署在算力之上,在不同用户或相同用户均可开展协同学习。一个任务组和一个训练任务等价,任务组需要制定算法和参与用户最小数量。任务是用户加入协同训练的一个实例。
以鹏城云脑环境介绍平台使用流程如下:
协同训练启动过程
其中:
- 平台为现有智算网络用户创建账户,并通过调度器或指定的智算网络用户准备融合机器,添加到平台中
- 登入系统,添加机器信息
- 安装proxy代理软件后,平台就可以管理用户机器,代理提交机器基础细腻,并给予命令,执行启动或关闭容器功能
众智AI协同计算平台体验
地址:http://121.46.19.67:8383/login
体验账号:guest 密码:Pcl@2022 (该账号只用于查看当前任务组,并没有实际参与当前任务组的协同训练)
如果有智能协同训练场景的需求,请邮件反馈至zhangy03@pcl.ac.cn
应用案例
[跨域训练模型库]也在不断更新中!
一、resnet50分类模型
[resnet50协同训练代码]
数据集&模型:cifar10 resnet50
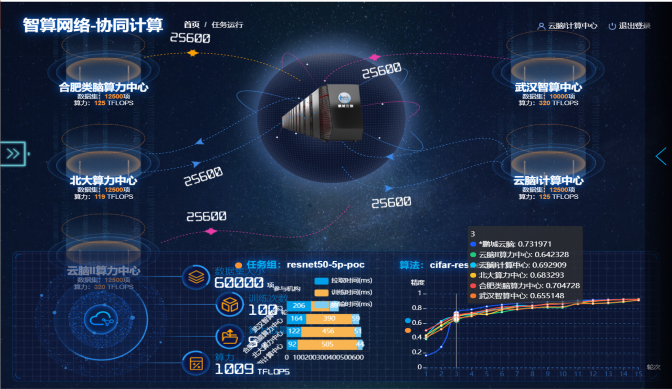
算力:5方智算网络用户中心参与的图像分类协同训练,数据平均划分为5份
训练超参:训练epoch=15,采用平均融合策略
如图所示,显示的协同训练场景,是联合5个智算中心,分别是位于深圳的鹏城云脑I、鹏城云脑II、位于北京的北大智算中心、位于合肥的类脑智算中心、位于武汉的武汉智算中心,每个分中心都有部分私有数据,要求数据不出本地, 其中鹏城云脑II、武汉智算中心都是通过对接modelarts进行资源的管理与调度。
- 从展示的曲线可以看到:协同训练模型的精度较各方中心仅用本地数据训练得到的精度,有提升4个百分点,而对比用全量数据训练的精度,只下降了1个百分点,而且从耗时上分析来看,通信时间在整个训练耗时中占的比例较少,不到20%。
- 充分验证了通过跨域的异构算力资源,利用多方数据协同训练多的模型相比各中心仅用本地数据训练的模型,性能有较大的提升。
查看训练过程:登录众智AI协同计算平台,点击任务resnet50-cifar10查看按钮
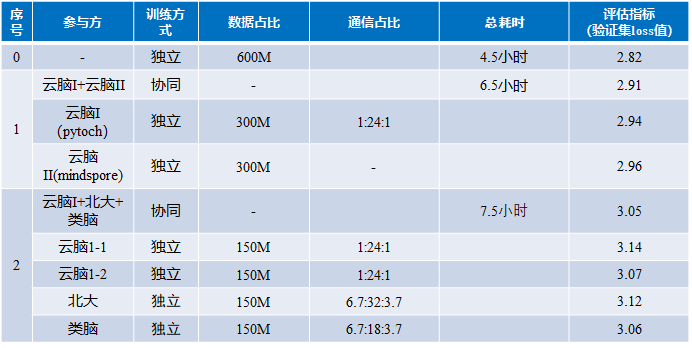
二、盘古-350M异构框架协同训练模型
[盘古350M-Pytorch代码]
[盘古350M-Mindspore代码]
数据集:600M(baike)
算力:4方智算网络用户中心参与的盘古模型协同训练,数据平均划分为4份,各方数据占150M
训练超参:训练epoch=9,采用平均融合策略
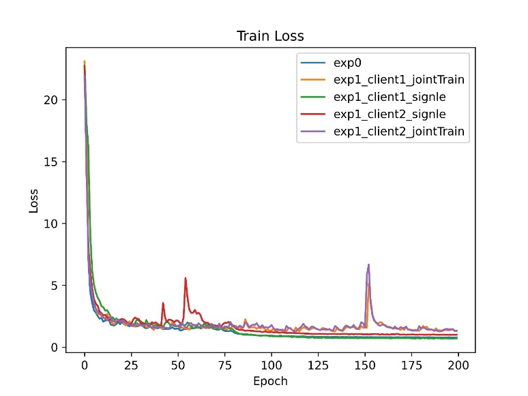
实验结果数据如下图:
结论:
- 验证了协同计算在nlp自然语言处理上的有效性,协同训练模型检测准确率高于参与方单独训练时模型准确率
- 通信时间在整个耗时中占比较小,最慢的参与方通讯时间占整个耗时的百分之20左右
- 目前用600M数据,数据量偏小,继续往后训练,训练loss不断降低,但是验证集的Loss不下降,会出现过拟合
查看训练过程:登录众智AI协同计算平台,点击任务pangu-pt-ms查看按钮
三、基于协同计算的产前先天性心脏病医学影像分析与应用
EllipseNet检测模型协同训练验证具体可参考AISyn-EllipseNet
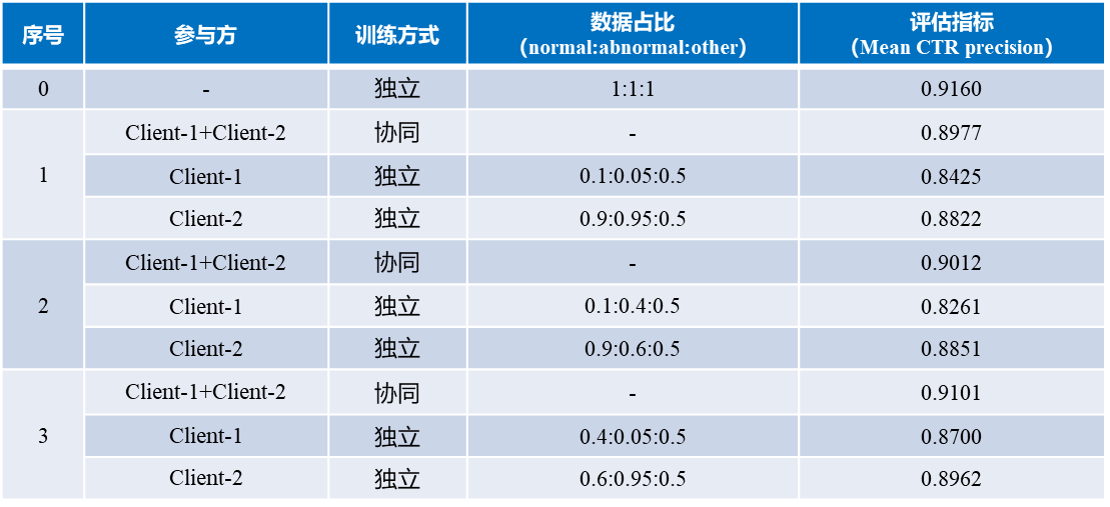
数据集:训练集总共病例图像:1669,normal:468,abnormal:230,other:971
基础模型:EllipseNet
实验场景描述:2方参与的EllipseNet模型协同训练,数据划分成2份,各方数据集中normal、abnormal和other类型的数据量根据比例划分,具体比例见实验结果表。训练epoch=200,协同训练时每个epoch同步一次模型参数,采用平均融合策略
实验结果:
结论:
- 验证了协同计算在儿童心脏检测应用场景的有效性,协同训练模型检测准确率高于参与方单独训练时模型准确率
- 参与方数据分布的不均匀性影响协同计算训练检测模型准确率上限,数据分布越均匀,协同训练效率越接近数据聚合时准确率
- 协同训练时模型会因为数据分布和模型融合更新周的变化出现一些loss收敛波动
四、一带一路多语言模型云际协同训练
针对一带一路国家多语言语料稀缺且资源分布不均衡等挑战,多语言模型云际协同训练案例旨在模拟低资源语料分布在多个智算中心且数据不出本地的情形下联合训练一个多语言模型的场景,探索以中文为核心的“一带一路”多语言模型的持续学习技术。
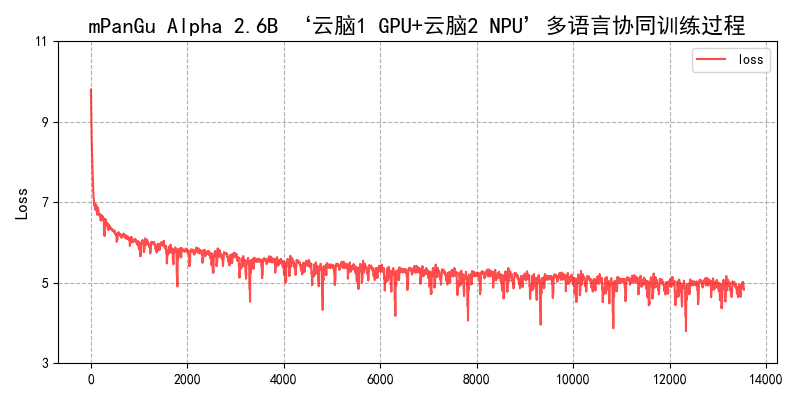
- 鹏程·mPanGu-α 2.6B 云际异构协同训练,具体可参考:
mPanGu-α2.6B
训练基于‘鹏城云脑1’ GPU(V100)和‘鹏城云脑2’ NPU(昇腾910),数据集清洗后涵盖66个一带一路沿线国家的53个语种,其中单语7.3B句对,中<->外双语0.32B句对,英<->外双语1.96B句对;
训练loss
目前训练还在进行,最新结果会及时进行更新
交流群
添加微信入鹏城众智协同计算平台交流群
许可证
Apache License 2.0