鹏程·mPanGu-α 2.6B MindSpore版本,在‘鹏城云脑1’ GPU(V100)和‘鹏城云脑2’ NPU(昇腾910)云际异构集群,基于AISynergy协同计算平台,进行的一带一路小语种多语言机器翻译的协同训练
背景
中国已经同140个国家和31个国际组织签署205份共建“一带一路”合作文件,“一带一路”共涉及12语系,28语族,132种语言,语言多样性是造成语言障碍的主要因素。建设以中文为核心的“一带一路”多语言机器翻译平台将是突破语言障碍的金钥匙,在促进经济、政治、外交、文化交流等方面起到越来越重要的作用。
由于语种使用人口、地理分布的不均衡以及社会信息化水平的差异,造成语种数据资源的极度不均衡和隔离,因此国内优秀的机器翻译产品在小语种翻译效果上难以发挥优势,本场景聚焦于应用场景对协同训练的需求,基于AISynergy协同计算平台,对小语种多语言机器翻译进行探索研究,旨在抛砖引玉,以联合相关科研院所、优势企业单位,推动一带一路小语种多语言机器翻译性能的不断提升,促进一带一路相关国家沟通和交流的顺畅。
数据集介绍
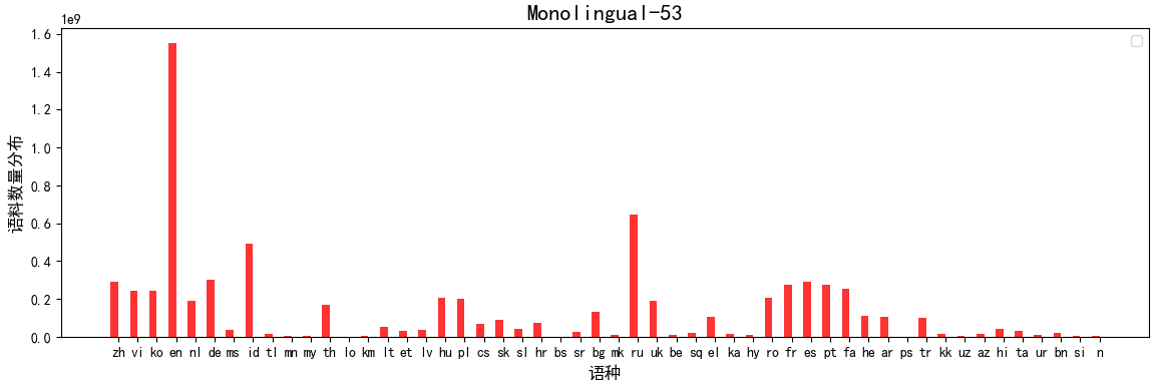
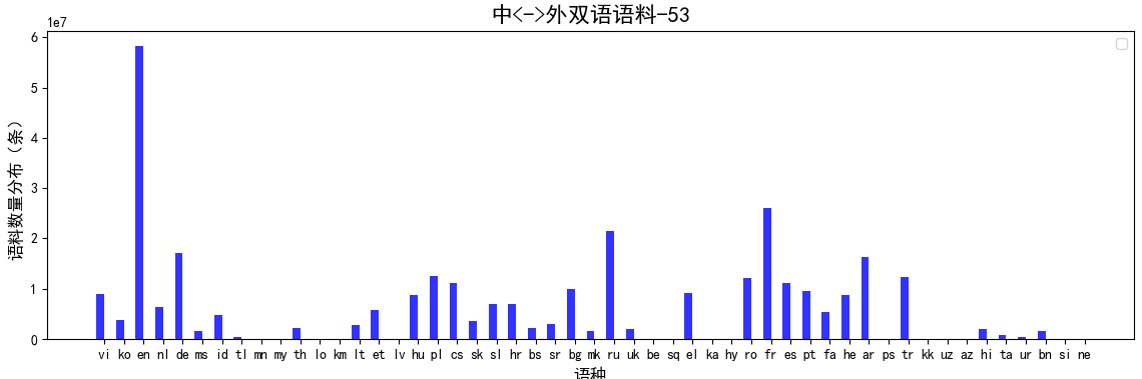
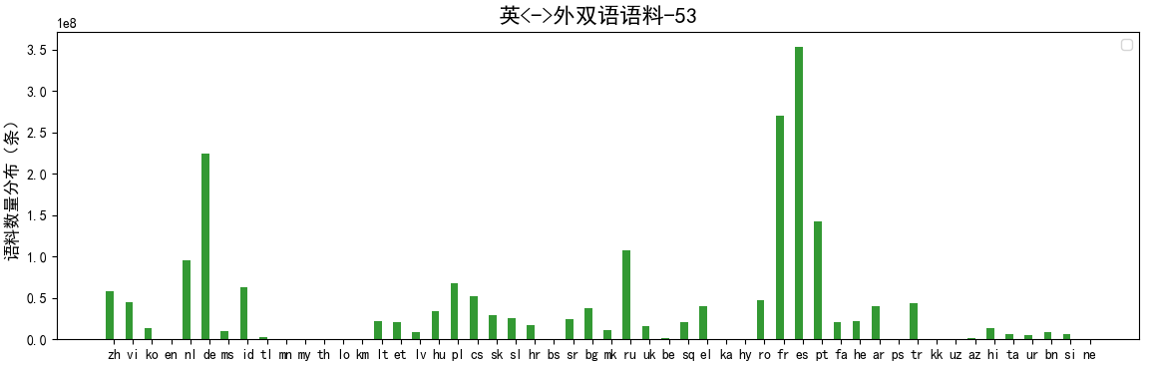
原始数据来源于PanGu-α语料、Common Crawl、CCMatrix、CC-100、OPUS等,共涵盖66个一带一路沿线国家53个语种,其中单语7.3B句对,中<->外双语0.32B句对,英<->外双语1.96B句对;
数据的清理策略有:软硬规则过滤、双语字符对齐过滤、整体精确去重、整体模糊匹配去重等,清洗后语种数据分布如下图:
AISynergy 的使用
AISynergy提供了两种使用方式:网页前端启动任务和服务器手动启动任务,两种方式选其一
1、基于网页前端启动任务,可以参考文档平台使用手册。
2、基于AISynergy-core启动任务,可以参考下面步骤。
MindSpore框架下的同构和异构协同训练
鹏程·mPanGu-α2.6B采用混合并行方案,详细技术细节,请参考PanGu-α,
环境要求
AISynergy
MindSpore >= 1.6
2.6B同构协同训练
启动server
# 起8个端口,对用8路模型并行,使用端口的修改在.sh文件中
bash multi_server_start.sh 8
启动client
bash scripts/run_distribute_train_gpu.sh device_number /hostfile /path_to_dataset batchsize 2.6B
ModelArts 提交任务,启动文件:train_client_npu.py
2.6B云际异构协同训练
启动server
# 起8个端口,对应8路模型并行,使用端口的修改在.sh文件中
bash multi_server_start.sh 8
启动client
bash scripts/run_distribute_train_gpu.sh device_number /hostfile /path_to_dataset batchsize 2.6B
ModelArts 提交任务,启动文件:train_client_npu.py
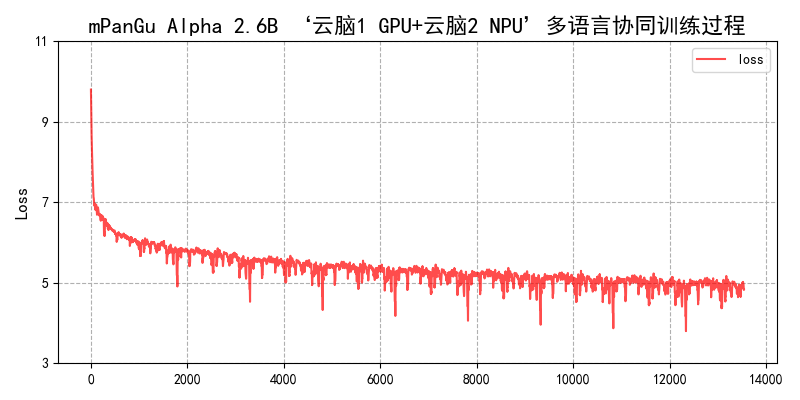
训练loss
目前训练还在进行,最新结果会及时进行更新
许可证
Apache License 2.0