Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 superqing
1da8d35a6c
superqing
1da8d35a6c
|
1 year ago | |
|---|---|---|
| .. | ||
| datadefine | 1 year ago | |
| inference | 1 year ago | |
| resource | 1 year ago | |
| scripts | 1 year ago | |
| train | 1 year ago | |
| README.md | 1 year ago | |
| __init__.py | 1 year ago | |
README.md
鹏程.盘古-Dialog
中文|English
1 简介
鹏程.盘古对话生成大模型(PanGu-Dialog)。PanGu-Dialog是以大数据和大模型为显著特征的大规模开放域对话生成模型,充分利用了大规模预训练语言模型的知识和语言能力,基于预训练+持续微调的学习策略融合大规模普通文本和对话数据训练而成。在各项指标上达到了中文纯模型生成式对话SOTA水平,在知识性和信息量方面优势明显。
要说明的是,目前生成式对话仍处于较低水平,大模型+大数据的范式对话整体质量、知识正确性有明显优势,但安全性、可靠、可信、可控、智慧等方面的提升并不明显,与人类对话能力存在明显的差距,这仍是对话生成一道难题。后续我们将在现有基础上针对不同的维度不断优化迭代,不断进步。
2 方法
2.1 基本信息
基础模型:鹏程.盘古2.6B,1024最大序列长度。
模型结构:decoder only,简单高效、生成能力更强、预训练更简单。
数据格式:采用特殊token将同一对话session中每一个对话轮次的语句分割,用另一特殊token分割不同的对话session。为了提升数据利用率,context和response都会参与loss计算。为了提升训练效率,不同的对话session将被拼接起来作为最大序列长度的自回归式语言模型的输入,并通过attention mask隔离session间的干扰。
训练数据:收集开源数据集,并进行初步的清洗过滤。第一阶段最终整理出3000w多轮对话、7000w句子、16亿文字的对话数据,覆盖社交媒体、闲聊、知识对话、知识问答10个数据集。详细信息如下表。
2.2 训练
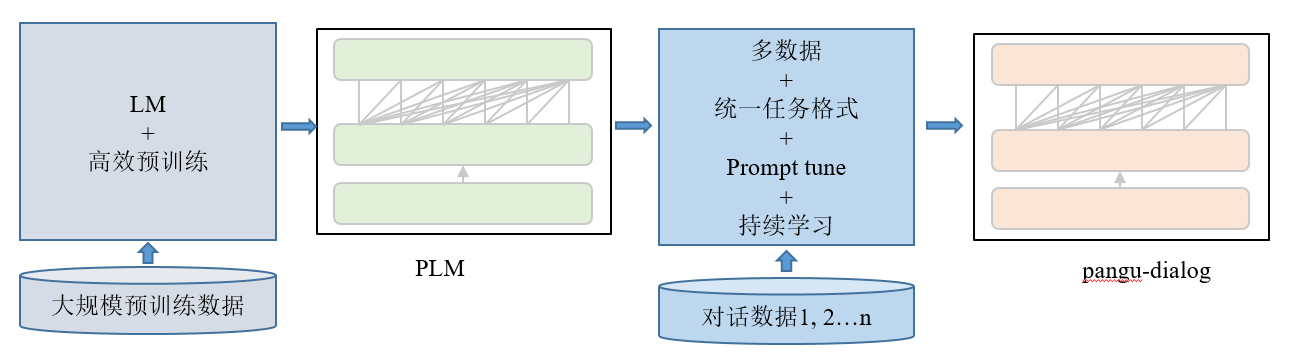
基于鹏程.盘古预训练语言的大规模中文对话模型,采用多阶段持续训练的方式在对话数据进行学习,充分利用训练语言模型语言能力和知识。整个训练框架如下图所示,PLM实际为鹏程.盘古模型,多数据是指收集的多源的对话数据,统一任务格式和Prompt tune和持续学习采用与鹏程.盘古增强版一致的方法。
模型文件
| 模型文件 | Md5 | 大小 | 参数配置 |
|---|---|---|---|
| pangu_dialog_fp16_2b6.zip | *** | 4.6G | num-layers : 31 hidden-size : 2560 num-attention-heads : 32 |
pangu_dialog_fp16_2b6 # 模型目录
-- iter_0001000 # 迭代次数目录
--mp_rank_00 # 模型并行时各个 GPU 的目录
--model_optim_rng.pt # 模型文件
--latest_checkpointed_iteration.txt # 记录 ckpt 的迭代次数文件
注:num-layers 等于 Pangu 项目中的 num-layers - 1
3 使用
推理代码
bash scripts/pangu_dialog_infer.sh
训练或微调
# 指定数据路径,数据为一个session一行,对话间tab间隔
# 如果要做多卡模型并行微调,需要先做模型切分,训练完成后再做合并
bash scripts/pangu_dialog_tune.sh
4 环境
pytorch版
支持 python >= 3.6, pytorch >= 1.5, cuda >= 10, nccl >= 2.6, and nltk。
推荐使用英伟达的官方 docker 镜像docker pull nvcr.io/nvidia/pytorch:20.03-py3。

