Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 wangql15
102ba7b93b
wangql15
102ba7b93b
|
2 years ago | |
|---|---|---|
| .. | ||
| chinese_L-12_H-768_A-12 | 2 years ago | |
| datasets | 2 years ago | |
| images | 2 years ago | |
| layers | 2 years ago | |
| models | 2 years ago | |
| result | 2 years ago | |
| save_result_test | 2 years ago | |
| QAstance_cl_2x3_tokenizer.dat | 2 years ago | |
| README.md | 2 years ago | |
| data_utils_bert.py | 2 years ago | |
| eval_utils.py | 2 years ago | |
| label_con_stance_consis.txt | 2 years ago | |
| losses.py | 2 years ago | |
| run_test.sh | 2 years ago | |
| run_train.sh | 2 years ago | |
| train_model_run.py | 2 years ago | |
README.md
Title: Question answering stance detection based on multi-task contrastive learning

Abstract
At present, the task of Q & A stance detection is limited by fewer annotated data resources and a single model classification strategy, resulting in the current Q & A stance detection models prefer to build complex model architectures to obtain more subtle semantic information among Q & A texts.
Therefore, if the tasks or labels related to the Q&A stance can be introduced into the model as frontal information, the generalization capability of the model can be further enhanced based on the sharing mechanism among multiple related tasks.
This paper investigates a model architecture for question and answer stance detection based on multi-task comparison learning. The model architecture automates the construction of new question-answer consistency labels (question-answer dependent and question-answer independent) through data augmentation strategies to provide additional information to support the dependency relationships between question-answer texts. At the same time, the stance representation between similar tags is pulled in and alienated by a targeted contrast learning mechanism, enabling the model to focus on information about the data between each category of tags. Finally, a multi-task learning strategy that combines the contrast learning task and the Q & A stance classification task to maintain a shared underlying representation of the model allows the model to capture the shared features between tasks while reducing the impact of inter-task noise on the data classification results.
Model
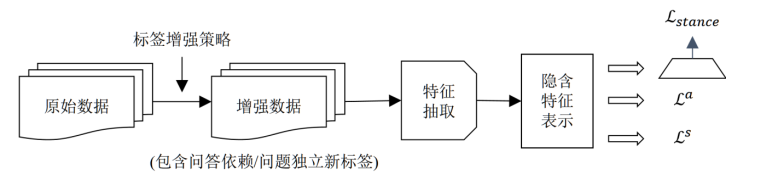
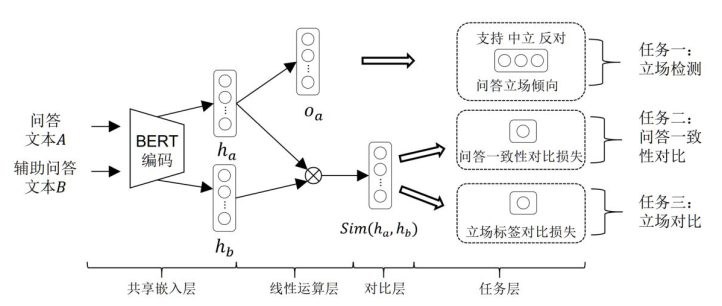
The architecture of this paper consists of four modules:
- Data augmentation module is mainly based on whether the answer representation in the Q&A text depends on the stance output of the question classification, to automate the data to obtain new Q&A consistency labels (Q&A-dependent/ Q&A-independent).
- Feature extraction module for feature representation of Q&A text, extracting features related to semantics of Q&A text or Q&A dependent representation and integrating them.
- The implicit feature representation module is the implicit feature representation obtained by putting the Q&A text feature representation into the model for stance calculation.
- The multi-task-based comparison learning module mainly combines the question-answer consistency comparison loss, question-answer stance comparison loss and question-answer stance classification cross-entropy loss for multi-task optimization.
Experiments





Usage
-
Dataset The data set used in the paper is an open source Chinese social question and answer data set, which was proposed by Yuan et al. at. This data set is mainly derived from popular Internet Q&A community platforms such as Baidu Zhizhi and Sogou Q&A, and involves Q&A texts in areas such as daily life, food, and medical diseases.
-
Install the following packages:
jieba 0.42.1 numpy 1.21.4 pandas 1.3.4 pytorch-pretrained-bert 0.6.2 PyYAML 6.0 scipy 1.7.3 six 1.16.0 sklearn 0.0 torch 1.5.0 tqdm 4.62.3 wheel 0.36.2``
-
Download the Chinese BERT model and put it in the chinese_L-12_H-768_A-12 directory
-
./run_train.sh
Cite
骆旺达.面向社交媒体文本的问答立场检测方法研究[D].导师:徐睿峰教授.哈尔滨工业大学(深圳),2021 年 12 月.
@inproceedings{
title={Exploring answer stance detection with recurrent conditional attention},
author={Yuan, Jianhua and Zhao, Yanyan and Xu, Jingfang and Qin, Bing},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={33},
number={01},
pages={7426--7433},
year={2019}
}
Stance detection is the extraction of a subject's reaction to a claim made by a primary actor.
Text CSV Pickle HCL other
Contributors (1)
