pcl_pangu: 鹏程·盘古系列模型SDK
简介
欢迎您使用鹏程·盘古SDK 发布版——pcl_pangu v1.1!,如果您使用过程中有任何问题请加入鹏程·盘古技术交流群进行交流[加入],或者在<任务>中提issue。
pcl_pangu项目的目标是将 鹏程·盘古[项目主页]开源模型、以及基于该模型的一系列任务拓展与持续学习得到的模型从语料数据预处理到模型训练推理部署整个流水线封装成开发工具包SDK。其目标与特点在于:
- 向开发者提供简单易用的 鹏程·盘古应用拓展API,包括数据预处理、模型预训练、推理、微调、模型转换、模型压缩等功能。您可以快速体验鹏程·盘古大模型,并且可以轻松的开发自己的模型;
- 向开发者提供基于鹏程·盘古大模型的应用拓展案例,如:鹏程.盘古增强版(Evolution);鹏程·盘古多语言模型(mPanGu);
- 支持 mindspore 和 pytorch 框架,支持 NPU 和 GPU 设备;提供 mindspore 和 pytorch 模型转换工具,可实现鹏程·盘古模型异构框架的快速切换及兼容生态发展。
SDK API
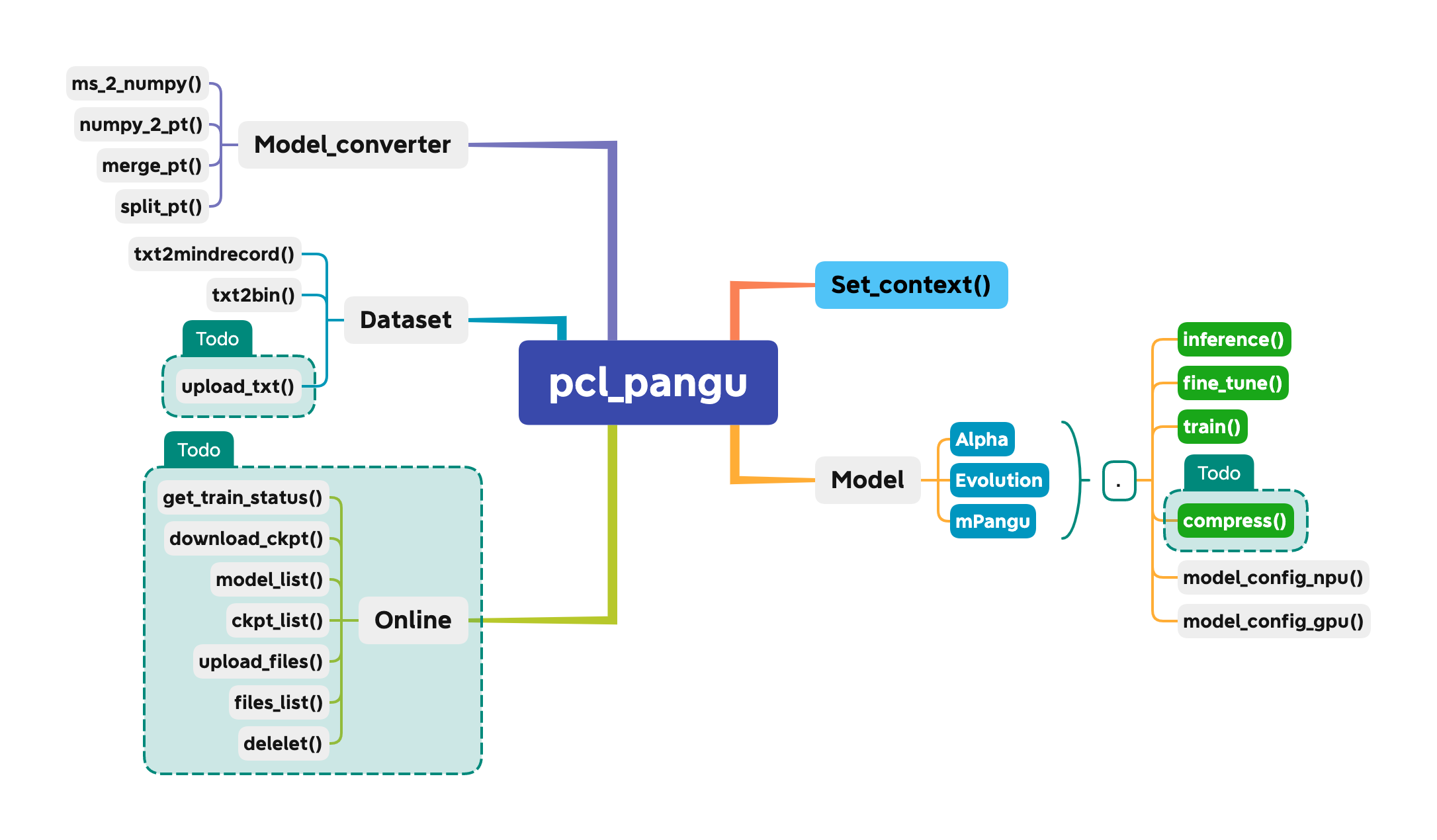
案例教程
红利!!! 免费算力申请
如果您需要华为昇腾NPU或英伟达GPU算力对pcl_pangu进行试用和测试,请登录[启智开源社区],注册后进入本项目即可直接申请免费算力。
快速上手
提供了简单的推理流程,用户只需要输入需要生成的文本就可以在进行推理。首先需要在模型下载页面下载对应的模型,并且解压。下面展示如何快速使用 alpha 模型推理:
from pcl_pangu.context import set_context
from pcl_pangu.model import alpha, evolution, mPangu
set_context(backend='mindspore')
config = alpha.model_config_npu(model='350M',load='350M/mode/path')
alpha.inference(config,input='四川的省会是?')
在 pytorch 框架上使用只需要把set_context(backend='mindspore') 改为 backend='pytorch',并配置model_config_gpu
大模型的训练具有较高的入门门槛,不易上手,因此我们提供了一个简单的训练工具,可以快速的训练一个模型。用户只需要准备好训练数据,然后运行下面的代码:
- 建议训练【350M模型】使用至少1卡;
- 建议训练【2B6模型】使用8卡,至少2卡;默认模型并行数为2,可手工配置model_config.model_parallel_size <= 卡数
- 建议训练【13B模型】使用8卡;默认模型并行数为4,可手工配置model_config.model_parallel_size <= 卡数
from pcl_pangu.context import set_context
from pcl_pangu.dataset import txt2mindrecord
from pcl_pangu.model import alpha, evolution, mPangu
set_context(backend='mindspore')
data_path = 'path/of/training/dataset'
txt2mindrecord(input_glob='your/txt/path/*.txt', output_prefix=data_path)
config = alpha.model_config_npu(model='350M',
load='path/to/save/ckpt',
data_path=data_path)
alpha.train(config)
模型的 fine-tuning 流程基本和训练的流程一致,只需要更改为调用 model.fine_tune() :
- 建议微调【350M模型】使用至少1卡;
- 建议微调【2B6模型】使用8卡,至少2卡;默认模型并行数为2,可手工配置model_config.model_parallel_size <= 卡数
- 建议微调【13B模型】使用8卡;默认模型并行数为4,可手工配置model_config.model_parallel_size <= 卡数
from pcl_pangu.context import set_context
from pcl_pangu.dataset import txt2mindrecord
from pcl_pangu.model import alpha, evolution, mPangu
set_context(backend='mindspore')
data_path = 'path/of/training/dataset'
txt2mindrecord(input_glob='your/txt/path/*.txt', output_prefix=data_path)
config = alpha.model_config_npu(model='350M',
load='path/of/your/existing/ckpt',
data_path=data_path)
alpha.fine_tune(config)
环境搭建
-
mindspore
1、推荐使用 openi 启智社区提供的 npu 环境,使用教程:
2、裸机使用:需要安装 mindspore 环境,并且安装:
pip install pcl_pangu
-
pytorch
如果你想在 pytorch 框架下使用,强烈建议使用我们预构建好的 docker 环境:
docker pull yands/pangu-alpha-megatron-lm-nvidia-pytorch:20.03.2
or
docker pull registry.cn-hangzhou.aliyuncs.com/pcl_hub/pangu_pytorch:pytorch.20.03.2
容器安装包pip install pcl_pangu,并使用 /opt/conda/bin/python。
模型下载
所有模型文件下载地址:请参考文件
微信交流群
添加微信:鹏程.盘古α交流群: