Adversarial Autoencoders
1. 1、简介
本项目基于paddlepaddle框架复现Adversarial Autoencoders (AAE)。这是一种概率自编码器,它使用生成对抗网络(GAN),通过匹配自编码器隐变量的聚合后验与任意先验分布来执行变分推理。 它将聚合的后验与先验分布进行匹配,确保从前验空间的任何部分生成有意义的样本。 因此,AAE的Decoder学习一个深度生成模型,该模型在映射先验分布到对应的数据上。
论文:
[1] Makhzani A, Shlens J, Jaitly N, et al. Adversarial autoencoders[J]. arXiv preprint arXiv:1511.05644, 2015.
参考项目:
- https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/aae/aae.py
- https://github.com/fducau/AAE_pytorch/tree/master/
项目aistudio地址:
2. 2、复现精度
2.1. 2.1 生成图片
2.2. 2.2 loss
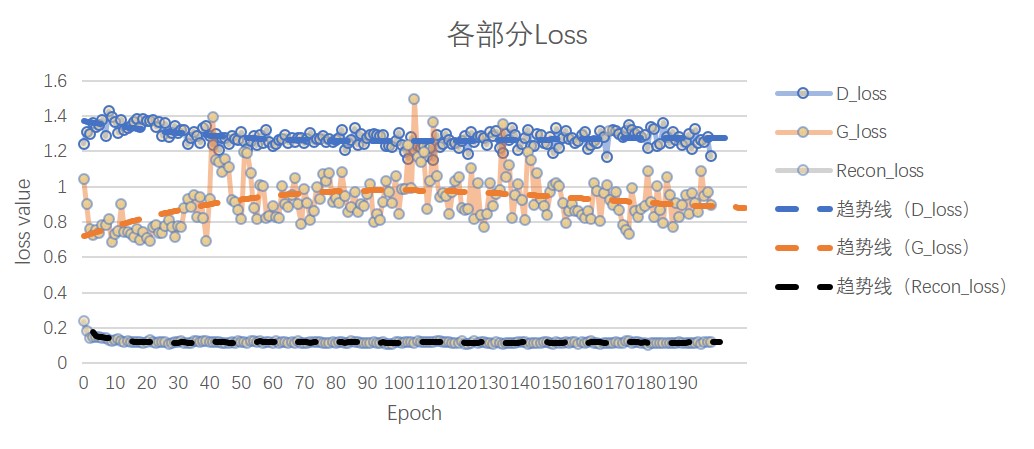
图中,D_loss 为判别器的loss,G_loss 为编码器的loss,recon_loss 为图片的loss,此处选二元交叉熵函数(BCEloss)
recon loss = BCE(X_{sample}, X_{decoder})
如图所示,D_loss 与G_loss在epoch为50轮左右达到稳定。而recon_loss则逐渐减小,在20-30轮稳定。
2.3. 2.3 Likelihood
2.3.1. 2.3.1 Parzen 窗长σ在验证集上交叉验证曲线
原文中提到对于窗长σ的选取需要通过交叉验证实现。本文使用1000个数据样本的验证集进行选择,从而得到一个符合最大似然准则下的窗长。
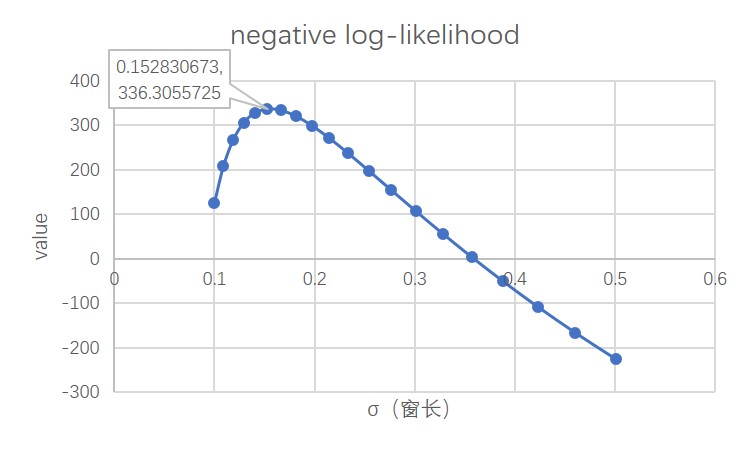
根据少量样本验证集的结果,选择使得negative log likelihood(nll)最大的σ值作为窗长
2.3.2. 2.3.2 复现结果
|
MNIST (10K) |
| 原文 |
340 ± 2 |
| 复现 |
345 ± 1.9432 |
|
 |
2.3.3. 2.3.3 对比实验
|
MNIST (10K) |
| 原文 |
340 ± 2 |
| 当前模型 |
345 ± 1.9432 |
| 参考项目[1]中模型 |
298 ± 1.7123 |
| 当前模型去除dropout层 |
232 ± 2.0113 |
实验结果分析: 结果表明,对于当前模型设置能够最接近甚至超过原文的nll指标。该指标一方面衡量了生产数据样本的多样性,另一方面又要求生成的数据样本尽可能接近数据集中的样本。去除dropout层的模型容易产生过拟合,模型倾向于保守的策略进行样本生成,数据多样性较差。参考项目[1]中模型使用了LeakyReLU激活函数,效果有所提升,但同样因没有dropout层而容易产生过拟合。
3. 3、数据集
MNIST
4. 4、环境依赖
- 硬件:GPU、CPU
- 框架:
- PaddlePaddle >= 2.0.0
- numpy >= 1.20.3
- matplotlib >= 3.4.2
- pandas >= 1.3.1
5. 5、快速开始
python data_maker.py
python train.py
python eval.py
6. 6、代码结构与详细说明
6.1. 6.1 代码结构
AAE_paddle_modified
├─ README_cn.md # 中文readme
├─ README.md # 英文readme
├─ data # 存储数据集和分割的数据
├─ images # 存储生成的图片
├─ logs # 存储实验过程log输出
├─ model # 存储训练模型
├─ utils # 存储工具类代码
├─ log.py # 输出log
├─ paddle_save_image.py # 输出图片
└─ parzen_ll.py # parzen窗估计
├─ config.py # 配置文件
├─ network.py # 网络结构
├─ data_maker.py # 数据分割
├─ train.py # 训练代码
└─ eval.py # 评估代码
6.2. 6.2 参数说明
可以在 config.py 中设置训练与评估相关参数,主要分为三类:与模型结构相关、与数据相关和与训练测试环境相关。
6.3. 6.3 实现细节说明
- 遵循原文原则,Encoder采用两层全连接层,Decoder采用两层全连接层,Discriminator采用两层全连接层。由于原文并未公布代码及相关详细参数,因此笔者在此处加入了Dropout层,以及按照原文附录中所述加入了re-parametrization trick ,即将生成的隐变量z重新参数化为高斯分布。
- 高斯先验分布为8维,方差为5,神经元数为1200. 网络结构与原文一致
6.4. 6.4 训练流程
运行
python train.py
在终端会产生输出,并会保存到./logs/train.log中
[2021-09-22 21:04:17,682][train.py][line:62][INFO] Namespace(n_epochs=200, batch_size=100, gen_lr=0.0002, reg_lr=0.0001, load=False, N=1200, img_size=28, channels=1, latent_dim=8, std=5, N_train=59000, N_valid=1000, N_test=10000, N_gen=10000, batchsize=100, load_epoch=199, sigma=None)
W0922 21:04:18.062372 50879 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 10.1, Runtime API Version: 10.1
W0922 21:04:18.067184 50879 device_context.cc:422] device: 0, cuDNN Version: 7.6.
[2021-09-22 21:04:48,115][train.py][line:174][INFO] [Epoch 0/200] [Batch 589/590] [D loss: 1.399173] [G loss: 0.836521] [recon loss: 0.201558]
[2021-09-22 21:04:48,154][train.py][line:181][INFO] images0 saved in ./images/images0.png
[2021-09-22 21:05:15,312][train.py][line:174][INFO] [Epoch 1/200] [Batch 589/590] [D loss: 1.831465] [G loss: 0.627008] [recon loss: 0.163741]
6.5. 6.5 测试流程
运行
python eval.py
在终端会产生输出,并会保存到./logs/eval.log中
[2021-09-22 22:36:11,013][eval.py][line:29][INFO] Namespace(n_epochs=200, batch_size=100, gen_lr=0.0002, reg_lr=0.0001, load=False, N=1200, img_size=28, channels=1, latent_dim=8, std=5, N_train=59000, N_valid=1000, N_test=10000, N_gen=10000, batchsize=100, load_epoch=199, sigma=None)
W0922 22:36:12.574378 66119 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 10.1, Runtime API Version: 10.1
W0922 22:36:12.579428 66119 device_context.cc:422] device: 0, cuDNN Version: 7.6.
[2021-09-22 22:36:14,076][eval.py][line:40][INFO] model/model199.pkl loaded!
[2021-09-22 22:37:04,696][parzen_ll.py][line:32][INFO] sigma = 0.10000, nll = 134.13950
[2021-09-22 22:37:53,652][parzen_ll.py][line:32][INFO] sigma = 0.10885, nll = 214.54500
6.6. 6.6 使用预训练模型评估
预训练模型保存在aistudio项目中的./model/model199.pkl,为第199轮输出结果。可以快速对模型进行评估。如./data/文件夹下无分割后的数据集,请先运行datamaker.py产生分割后的数据集。
7. 7、模型信息
关于模型的其他信息,可以参考下表:
| 信息 |
说明 |
| 发布者 |
钟晨曦 |
| 时间 |
2021.08 |
| 框架版本 |
Paddle 2.1.2 |
| 应用场景 |
数据降维 |
| 支持硬件 |
GPU、CPU |
| 下载链接 |
预训练模型 |
| 在线运行 |
notebook |


