Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 highcwu
49a971aa27
highcwu
49a971aa27
|
1 year ago | |
|---|---|---|
| annotator | 1 year ago | |
| apps | 1 year ago | |
| configs | 1 year ago | |
| docs/imgs | 1 year ago | |
| process | 1 year ago | |
| tasks | 1 year ago | |
| .gitignore | 1 year ago | |
| CITATION.cff | 1 year ago | |
| LICENSE | 1 year ago | |
| LICENSE.ControlNet | 1 year ago | |
| README.md | 1 year ago | |
| README_CN.md | 1 year ago | |
| mix_lora_and_control_lora.py | 1 year ago | |
| models.py | 1 year ago | |
| requirements.txt | 1 year ago | |
| test_dreambooth_lora.py | 1 year ago | |
| test_text_to_image_control_lora.py | 1 year ago | |
| train_dreambooth_lora.py | 1 year ago | |
| train_text_to_image_control_lora.py | 1 year ago | |
README.md
ControlLoRA: A Light Neural Network To Control Stable Diffusion Spatial Information
EN | 中文
By combining the ideas of lllyasviel/ControlNet and cloneofsimo/lora, we can easily fine-tune stable diffusion to achieve the purpose of controlling its spatial information, with ControlLoRA, a simple and small (~7M parameters, ~25M storage space) network.
ControlNet is large and it's not easy to send to your friends. With the idea of LoRA, we don't even need to transfer the entire stable diffusion model. Use the 25M ControlLoRA to save your time.
You could use gradio apps in the apps directory to try the pretrained models. More dataset types of models and their supporting gradio apps wanted. The annotator directory is borrowed from ControlNet.
You could download some pretrained models from huggingface. Note that I only used 100 MPII pictures for the training of the openpose, so the model effect is not good. So I suggest you train your own ControlLoRA.
Features & News
2023/02/22 - Add ControlLora v2, which decomposites the prompt features and the spatial information with smaller size (~5M parameters, ~20M storage space). You could do something like: training on sd v1.5 then inference on anything v3.0 .
How To Train
Refer to the script in the tasks directory. I highly refer to the training code from diffusers.
You could add or modify config file in the configs directory to custom the ControlLoRA model architecture. To enhance the effect of the model, you could change some blocks to other residual block types of diffusers and you could increase the number of layers of blocks by modify the config files.
Work In Progress
ControlLoRA with Canny Edge
sd-diffusiondb-canny-model-control-lora, on 100 openpose pictures, 30k training steps
Stable Diffusion 1.5 + ControlLoRA (using simple Canny edge detection)
python apps/gradio_canny2image.py
Highly refered to the ControlNet codes.
The Gradio app also allows you to change the Canny edge thresholds. Just try it for more details.
Prompt: "bird"
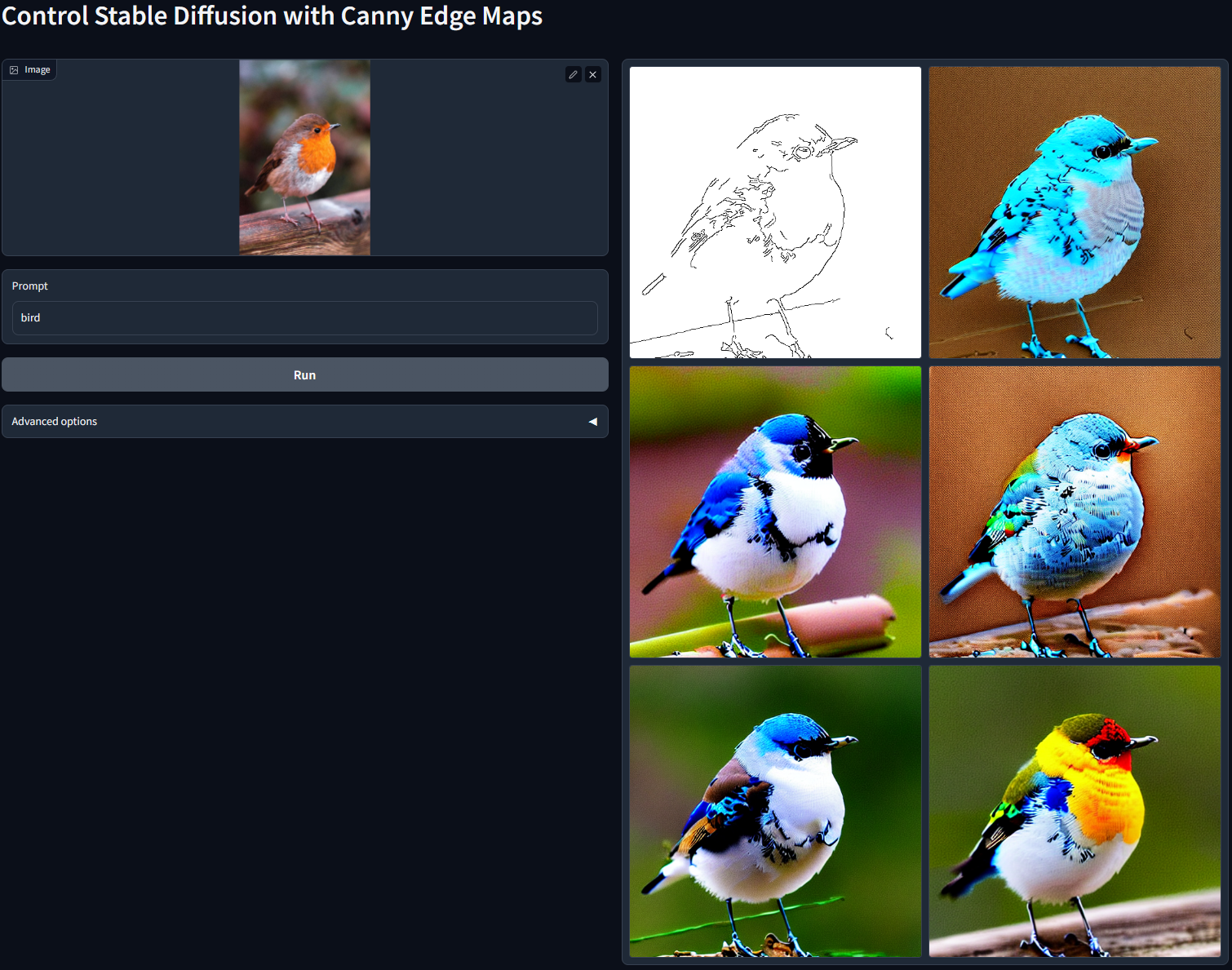
Prompt: "cute dog"

ControlLoRA with Human Pose
sd-mpii-pose-model-control-lora, on 100 openpose pictures, 30k training steps
Stable Diffusion 1.5 + ControlLoRA (using human pose)
python apps/gradio_pose2image.py
Highly refered to the ControlNet codes.
Apparently, this model deserves a better UI to directly manipulate pose skeleton. However, again, Gradio is somewhat difficult to customize. Right now you need to input an image and then the Openpose will detect the pose for you.
Note that I only used 100 MPII pictures for the training of the openpose, so the model effect is not good. So I suggest you train your own ControlLoRA.
Prompt: "Chief in the kitchen"
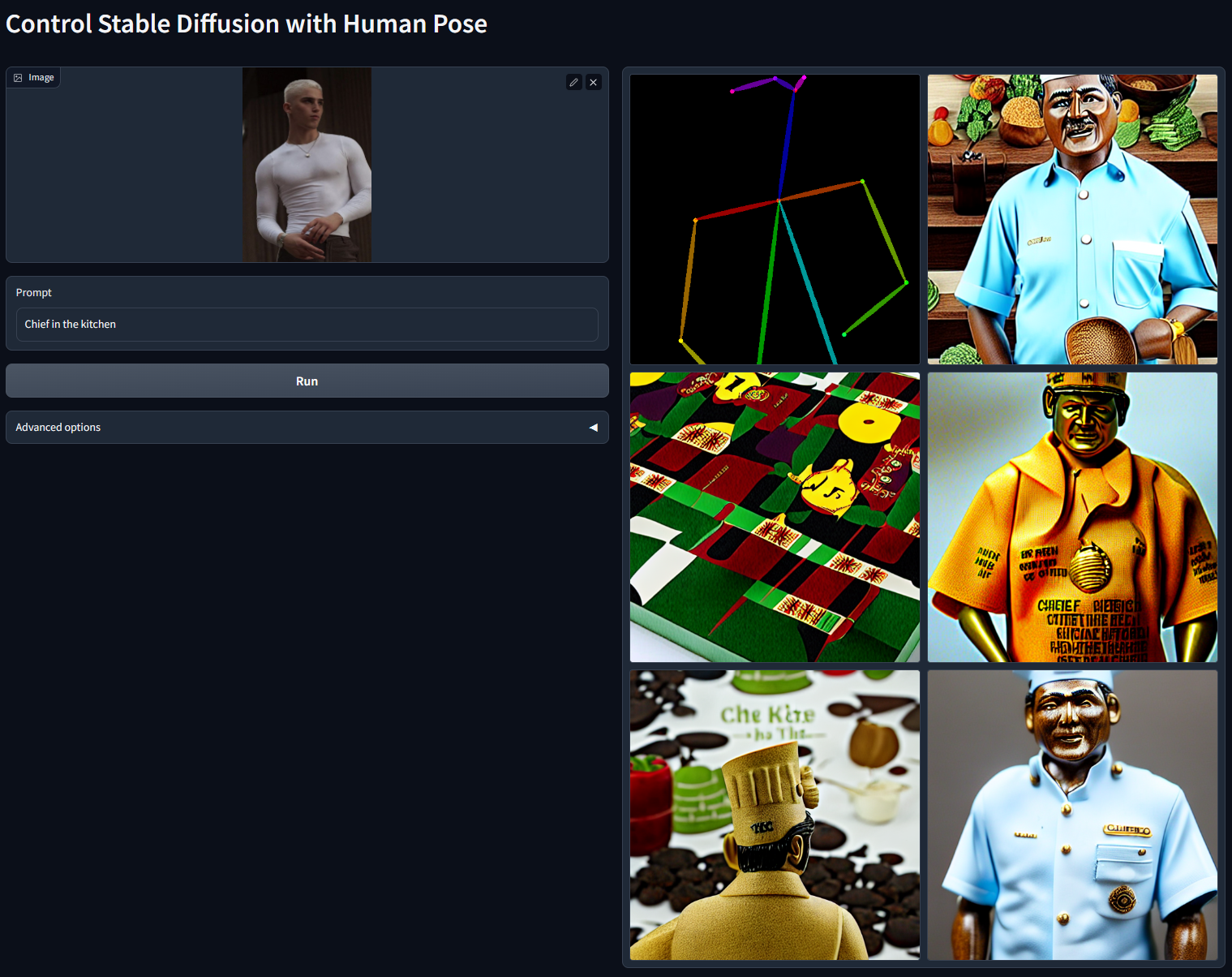
Prompt: "An astronaut on the moon"
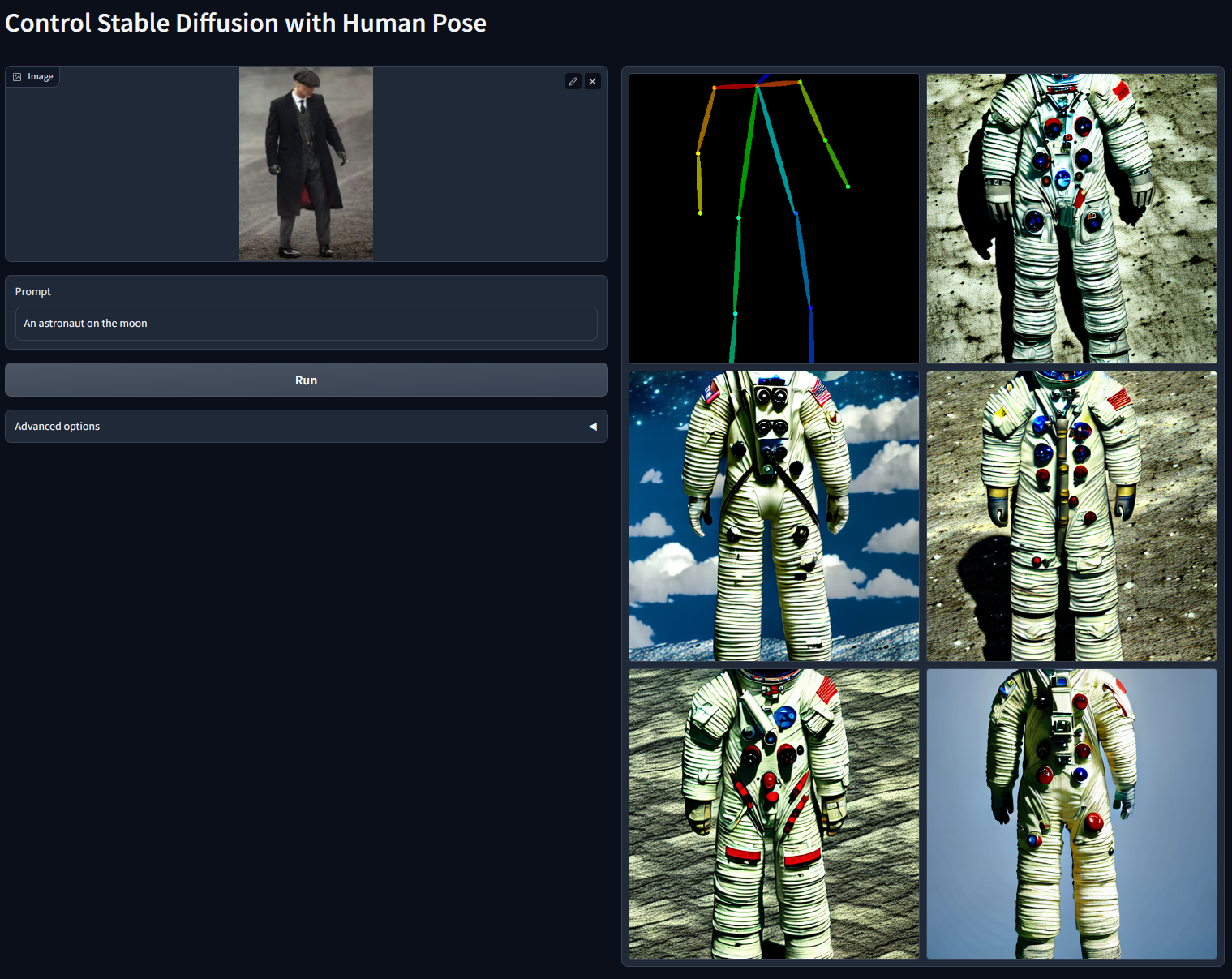
PS: I don't know why my gallery didn't show the full images and I should click an output to show the full result of one of the outputs, like this: 
Discuss together
QQ Group: 艾梦的小群
QQ Channel: 艾梦的AI造梦堂
Discord: AI Players - AI Dream Bakery
Citation
@software{wu2023controllora,
author = {Wu Hecong},
month = {2},
title = {{ControlLoRA: A Light Neural Network To Control Stable Diffusion Spatial Information}},
url = {https://github.com/HighCWu/ControlLoRA},
version = {1.0.0},
year = {2023}
}
