全量数据分析
本文主要讲述获取到数据权限后,数据分析师如何对全量数据进行分析。
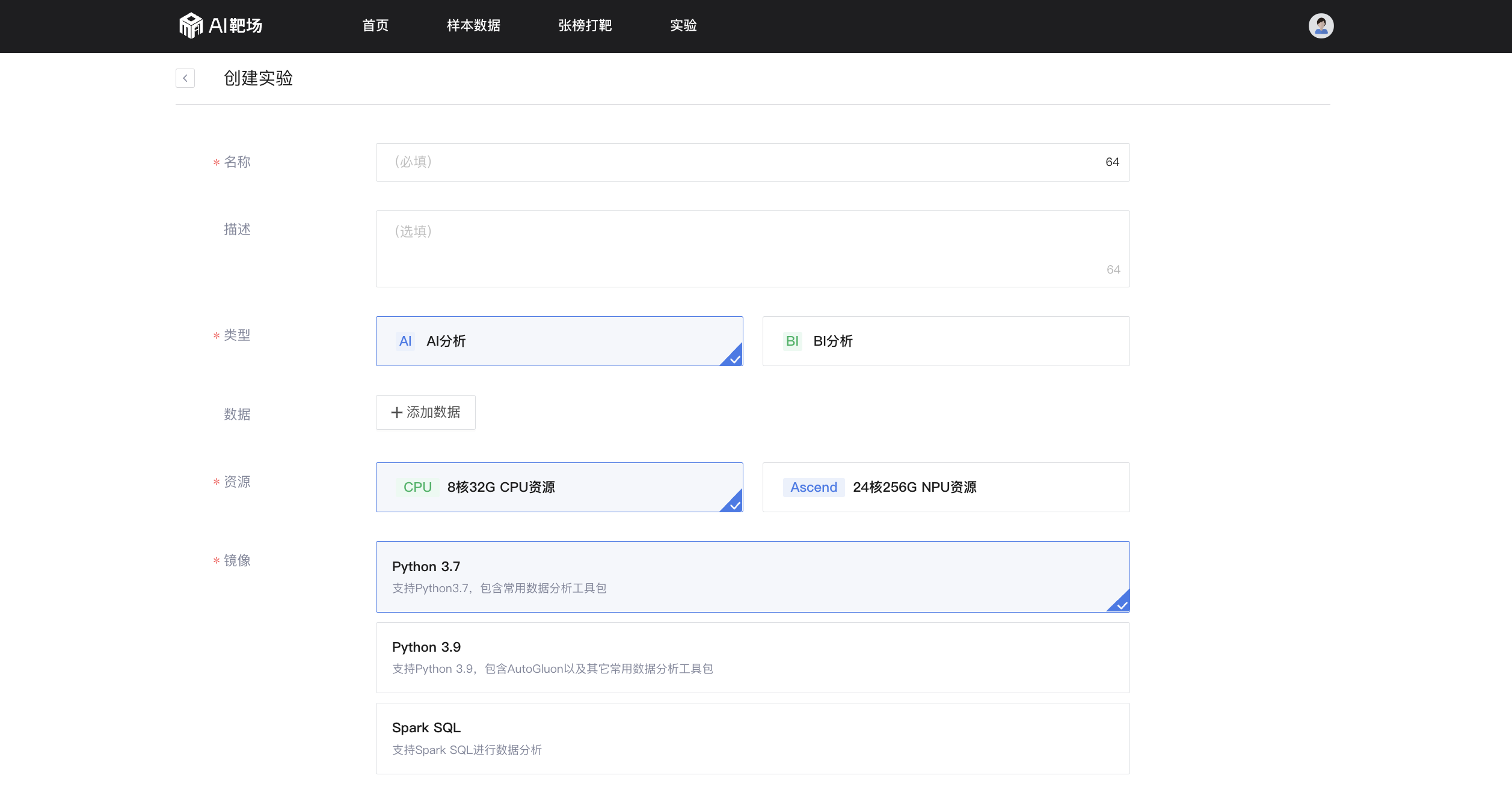
1.创建实验
获取到数据权限后,数据分析师可点击导航栏的【实验】进入实验模块。
点击【创建实验】,选择需要的计算资源及镜像,无需搭建环境即开即用。创建实验时,可点击【添加数据】选择被授权的样本数据或张榜打靶任务数据。
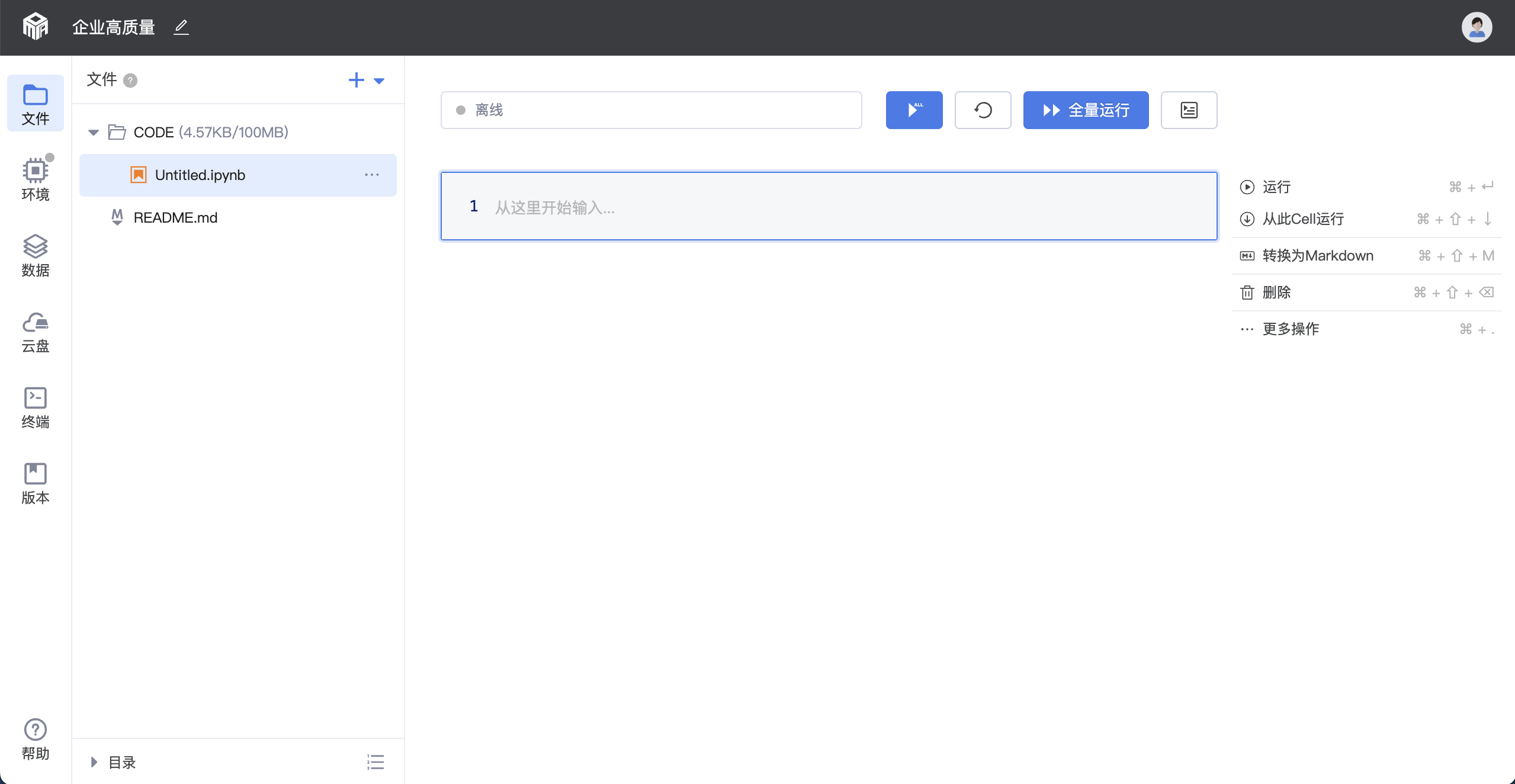
2.代码编辑与调试
实验创建成功,进入即开即用的个人Notebook工作台。
2.1 新建/上传ipynb文件
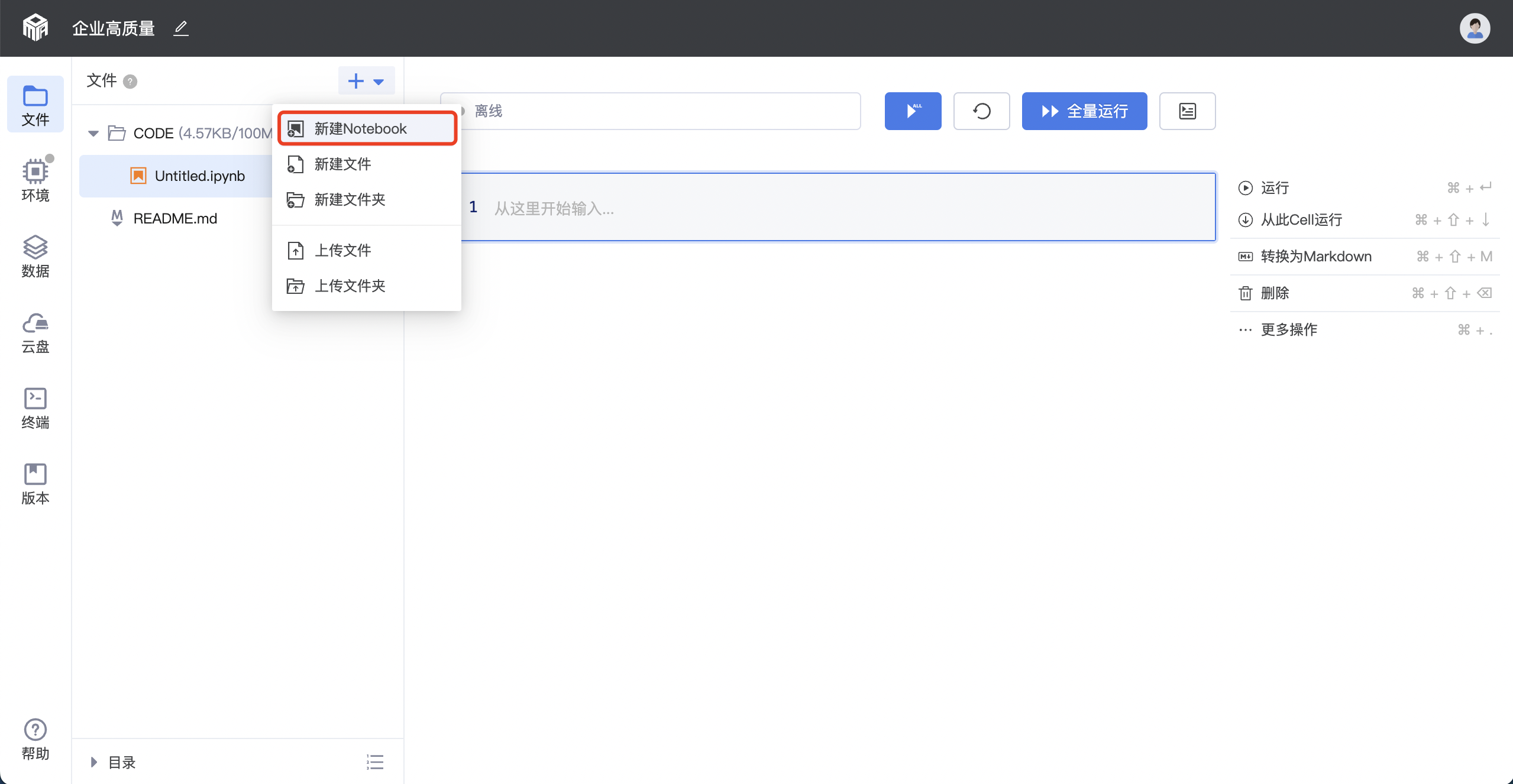
2.1.1 新建
在实验界面,点击文件模块右上角的【+】,新建Notebook编写自己的数据分析代码.
2.1.2 上传
Notebook实验也可以通过点击【文件】-【上传文件】,上传已经写好的代码文件进行模型训练。
新建/上传好Python文件后,在文件列表双击打开一个.ipynb文件,打开的文件会在右边同步显示,分析师可在右侧代码编辑区进行在线代码调试。
2.2 添加/编辑数据
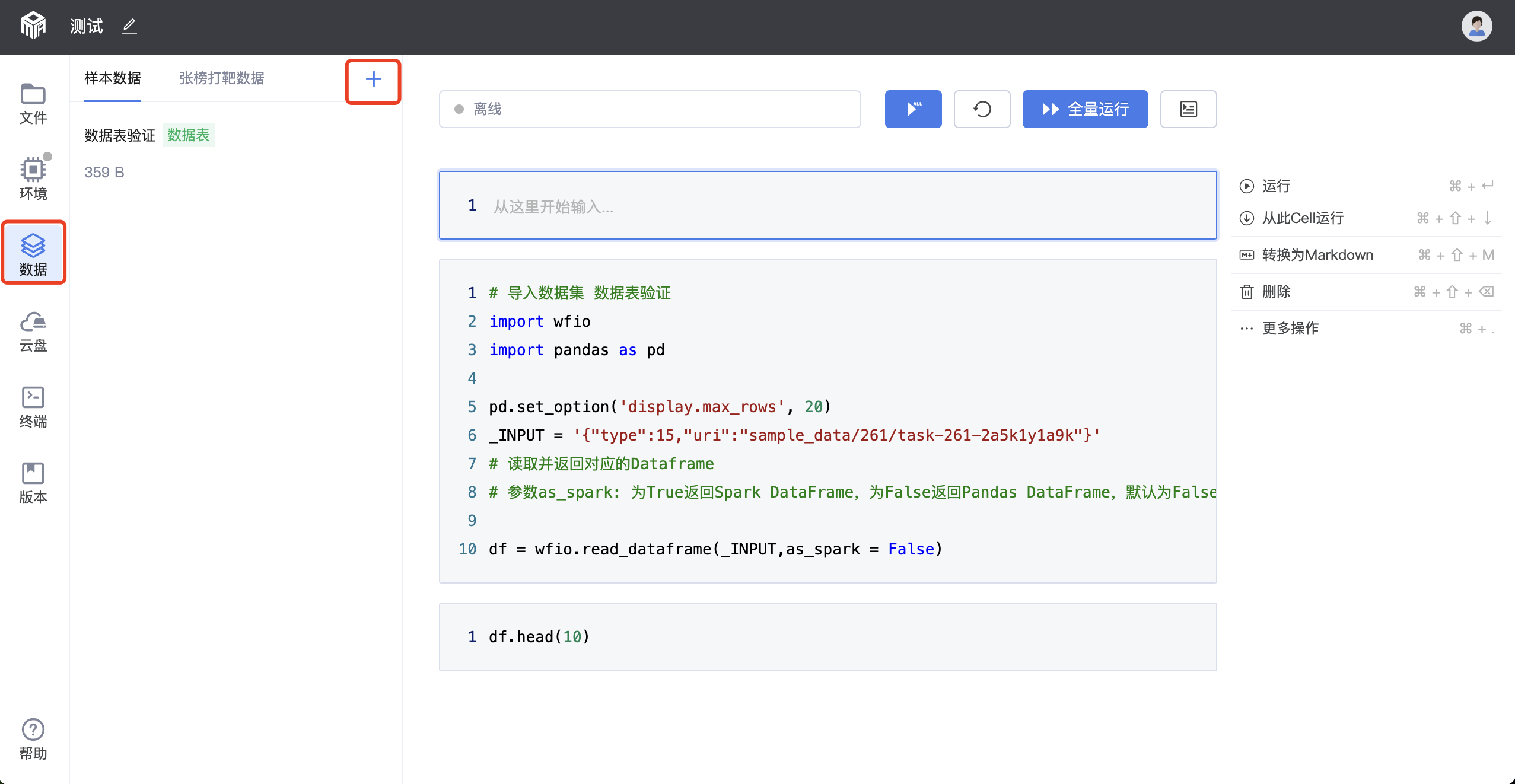
在实验界面中,数据分析师可在[数据]模块添加/编辑数据。
step 1:添加/编辑样本数据
AI靶场支持两类数据添加,一类是样本数据,此为管理员授权所得,需向管理员进行申请;另一类是张榜打靶数据,用户揭榜张榜打靶任务即可获得数据权限。
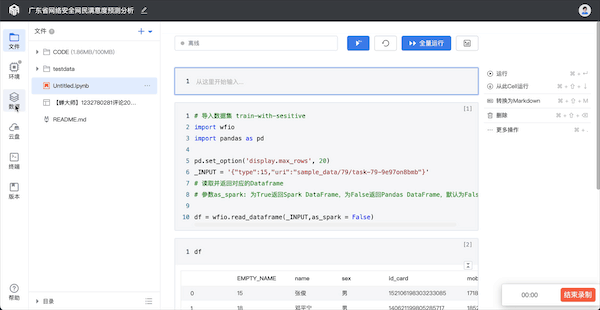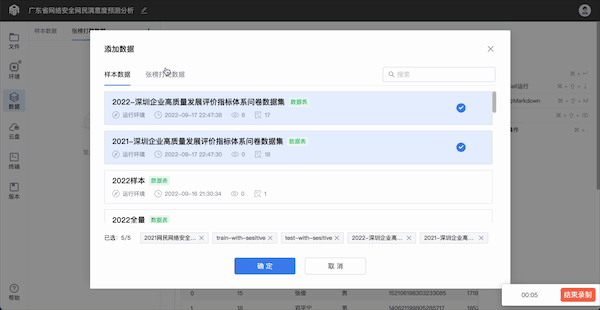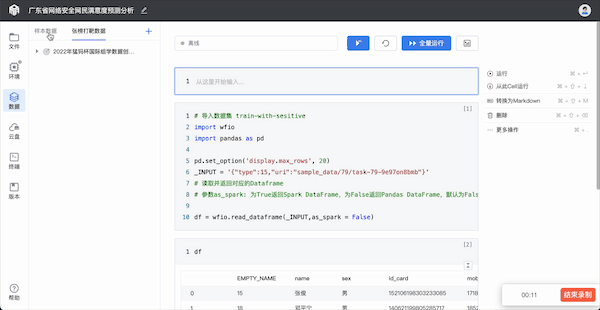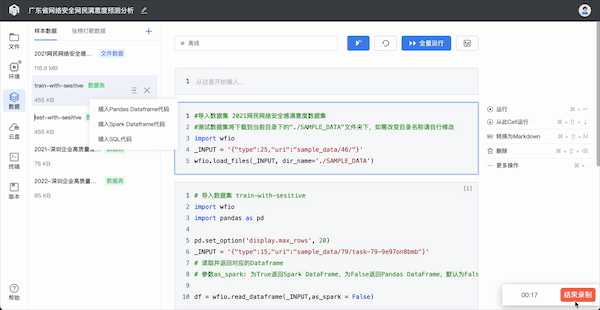
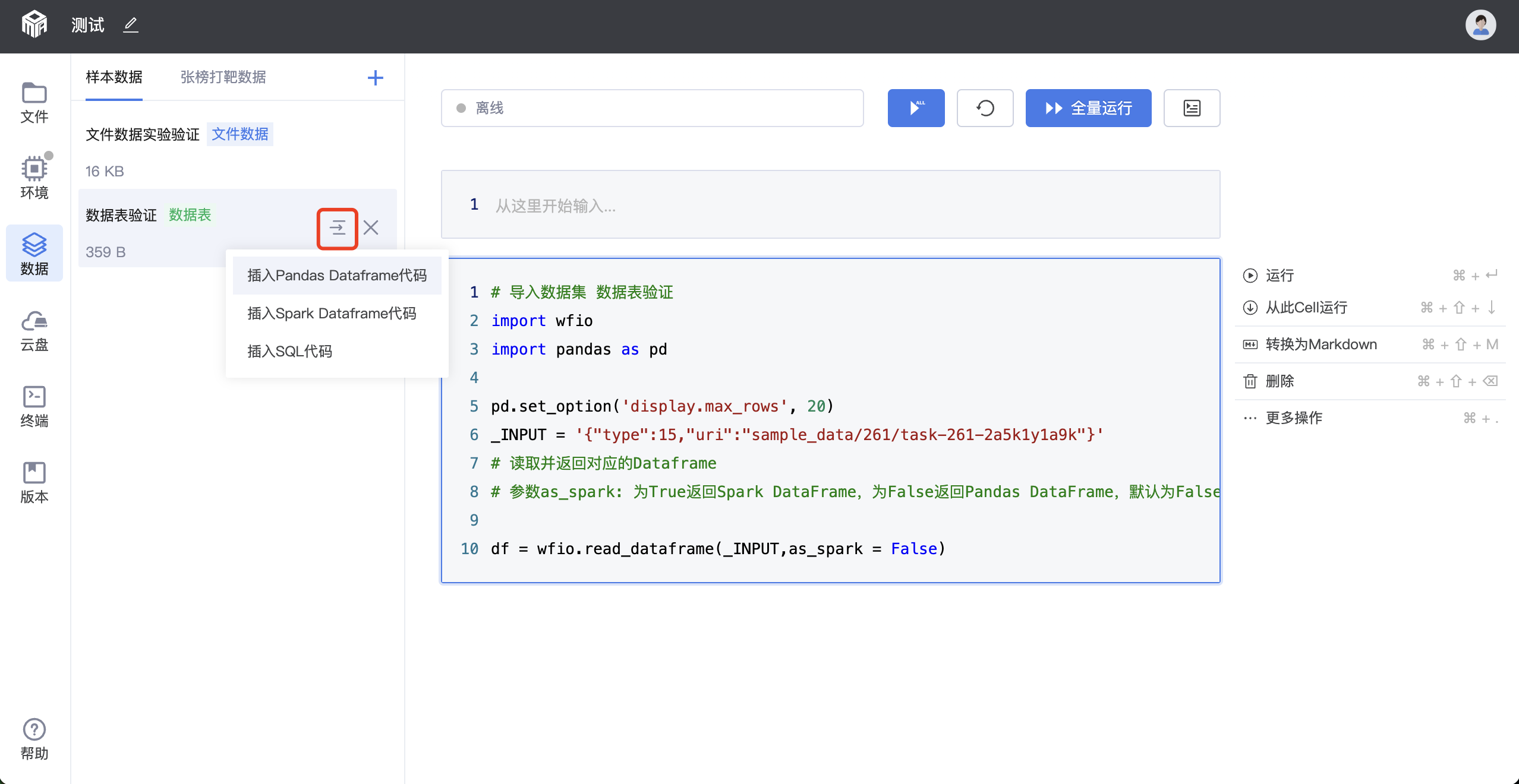
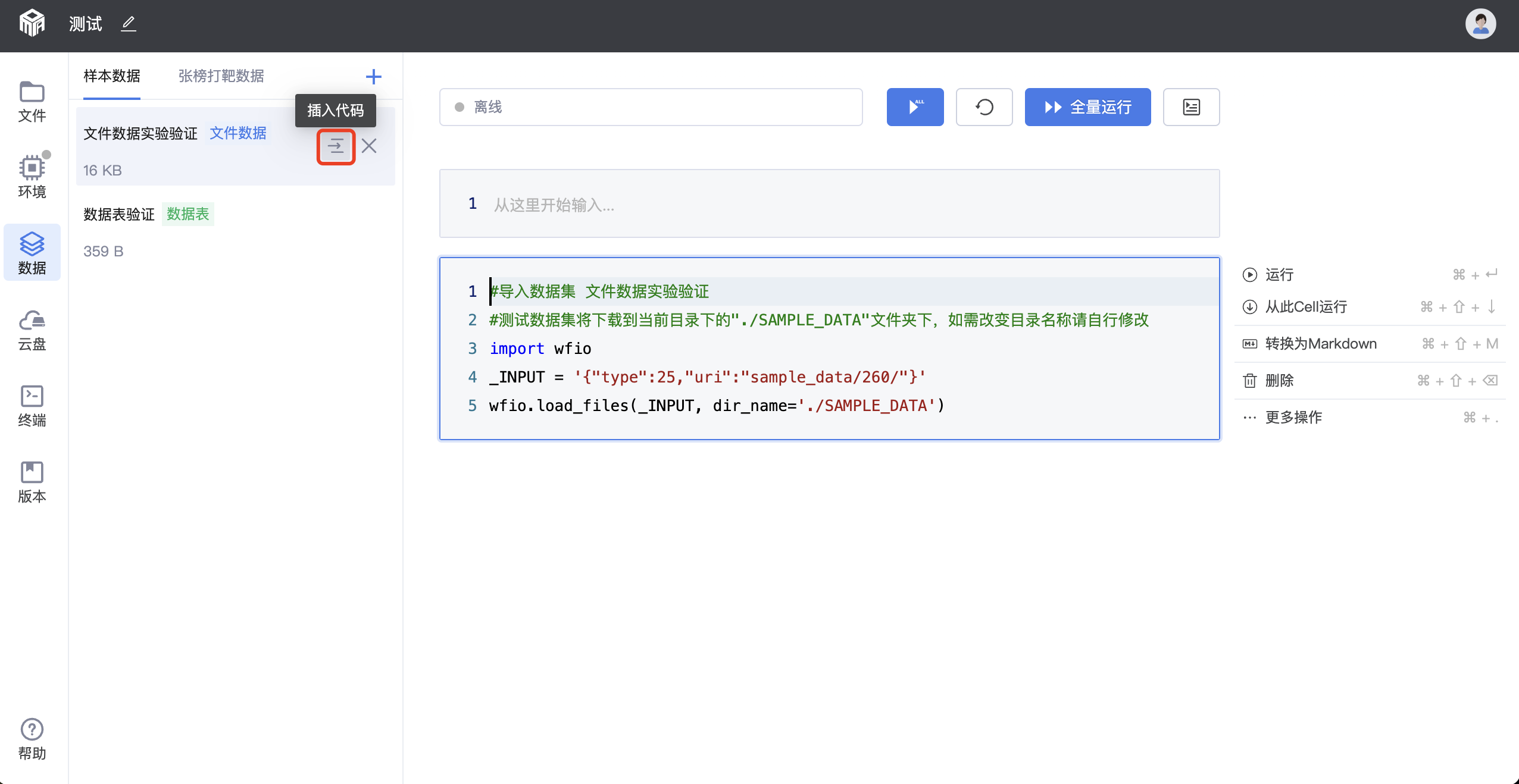
step 2:插入代码获取数据路径
编辑数据成功后,选中的数据集会出现在左侧数据列表下。鼠标悬浮在数据集条目上时,出现【插入代码】按钮,点击按钮会直接将数据访问代码插入右边选中的cell里。此时运行该cell,样本数据会下载到左侧的文件列表下。
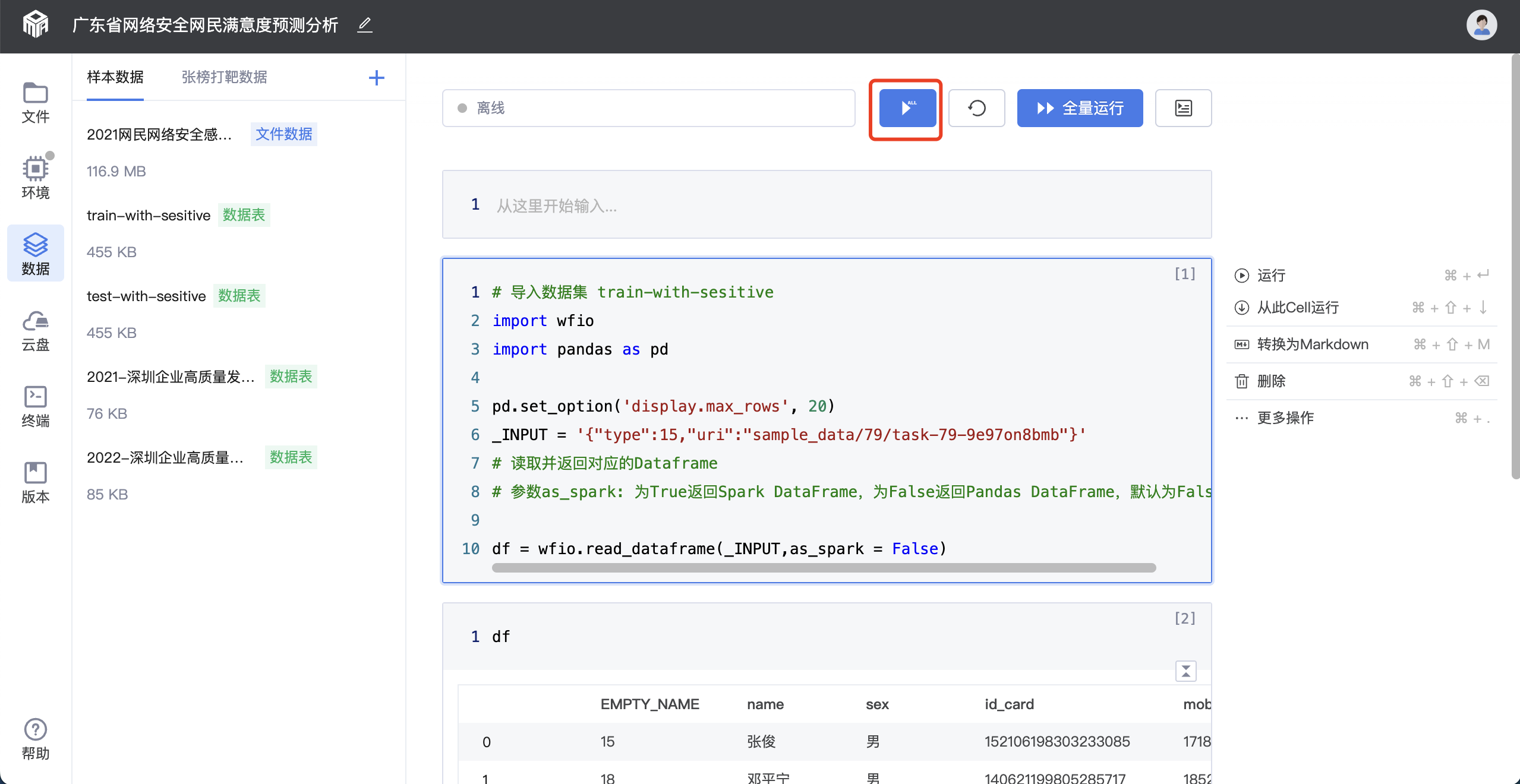
2.3 基于样本数据调通代码
基于样本数据完成模型程序编写后,点击上方的【运行全部单元格】,可运行基于样本数据的调试程序。运行完成后,在右边每个cell下可以直接看到对应的运行结果,通过运行结果可对程序进行调试。
3.全量运行
全量运行是将当前调试环境的代码程序发送至运行环境,在运行环境可信计算沙箱中,基于样本数据对应的全量数据运行该代码程序,运行成功后返回调用wflogger记录的全量运行参数、训练记录或评估指标,便于进行后续调试。
3.1 全量运行
基于样本数据不断调试程序得到较好的结果后,可点击代码编辑区的【全量运行】按钮,弹出:《全量运行弹窗》,填写版本名称和备注,点击【确定】,开始全量运行。
为方便调试,AI靶场提供了一些接口来监测训练过程中的指标变化:全量运行代码调用。
3.2 查看全量运行记录
全量运行成功后在,《全量运行记录》页面可查看全量运行状态、全量运行结果、指标数据、训练记录等信息,还可对多个全量运行记录进行指标对比。数据分析师可根据反馈的指标结果对代码不断调试,获得自己满意的结果。
为保证平台稳定运行,每个参赛用户最多有3个全量运行记录同时为“运行中”状态,若超出则全量运行可能失败。
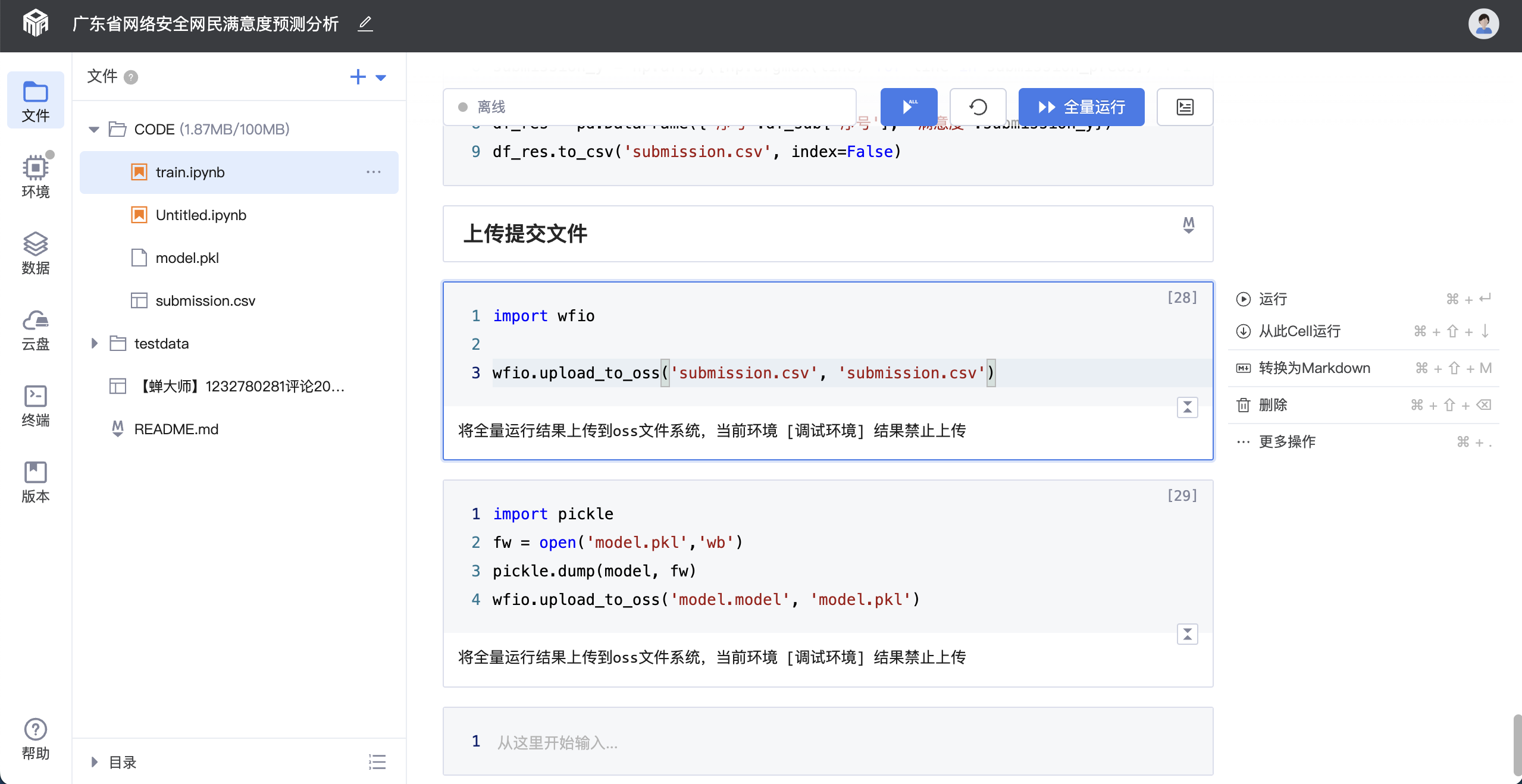
4.保存全量运行结果文件
若得到了理想的全量数据分析结果,数据分析师可在代码中调用wfio.upload_to_oss() 保存全量运行结果文件。
完成全量数据分析后,若数据分析师想带走分析结果,可申请结果导出,详见STEP4-申请结果导出。
实际上就是要在jupyter写一个比较完善的pipeline,一次性做完数据读取、数据分析、结果上传等代码,才能得到最终结果。其中:
(1)数据读取需要使用平台的插入代码的代码段,这样才能获取到对应的全量数据。
(2)若需要查看基于全量数据的分析结果,需在代码中调用wfio.upload_to_oss()保存全量运行结果文件。若要带走全量运行结果,可申请结果导出,详见[STEP4-申请结果导出]。