机器学习入门与实践合集(更多详细内容请参考ipynb文件,用云脑调试)
环境安装:
!pip install matplotlib seaborn numpy
!pip install -U scikit-learn --user
部分BUG前置修改
#问题描述:annotate()缺少一个参数'text'。
#问题原因:annotate()的's'参数自Matplotlib 3.3以来已重命名为'text',对旧名称的支持将在两个次要版本之后被放弃。
#解决办法:把annotate(s=text)改为annotate(text=text)就可以了,或者把matplotlib包降到3.3以下也可以解决问题。
plt.annotate(text='New point 1',xy=(0,-1),xytext=(-2,0),color='blue',arrowprops=dict(arrowstyle='-|>',connectionstyle='arc3',color='red'))
数据集相关问题:如果无法wget的话,直接本地上传即可
# 下载需要用到的数据集
# !wget https://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/3K/horse-colic.csv
调试环境:
- fork本repo至自己名下
- 点击云脑,选择调试环境
- 推荐镜像:dockerhub.pcl.ac.cn:5000/user-images/openi:d2l-learning
- 进入调试环境,在线运行相关代码
详情参考:https://openi.pcl.ac.cn/Datawhale/d2l/src/branch/master/Tutorials.md

相关参考见文末,如有问题请在issue留言
1.机器学习算法(一): 基于逻辑回归的分类预测
1.1 逻辑回归的介绍和应用
逻辑回归(Logistic regression,简称LR)虽然其中带有"回归"两个字,但逻辑回归其实是一个分类模型,并且广泛应用于各个领域之中。虽然现在深度学习相对于这些传统方法更为火热,但实则这些传统方法由于其独特的优势依然广泛应用于各个领域中。
而对于逻辑回归而且,最为突出的两点就是其模型简单和模型的可解释性强。
逻辑回归模型的优劣势:
逻辑回归模型广泛用于各个领域,包括机器学习,大多数医学领域和社会科学。例如,最初由Boyd 等人开发的创伤和损伤严重度评分(TRISS)被广泛用于预测受伤患者的死亡率,使用逻辑回归 基于观察到的患者特征(年龄,性别,体重指数,各种血液检查的结果等)分析预测发生特定疾病(例如糖尿病,冠心病)的风险。逻辑回归模型也用于预测在给定的过程中,系统或产品的故障的可能性。还用于市场营销应用程序,例如预测客户购买产品或中止订购的倾向等。在经济学中它可以用来预测一个人选择进入劳动力市场的可能性,而商业应用则可以用来预测房主拖欠抵押贷款的可能性。条件随机字段是逻辑回归到顺序数据的扩展,用于自然语言处理。
逻辑回归模型现在同样是很多分类算法的基础组件,比如 分类任务中基于GBDT算法+LR逻辑回归实现的信用卡交易反欺诈,CTR(点击通过率)预估等,其好处在于输出值自然地落在0到1之间,并且有概率意义。模型清晰,有对应的概率学理论基础。它拟合出来的参数就代表了每一个特征(feature)对结果的影响。也是一个理解数据的好工具。但同时由于其本质上是一个线性的分类器,所以不能应对较为复杂的数据情况。很多时候我们也会拿逻辑回归模型去做一些任务尝试的基线(基础水平)。
说了这些逻辑回归的概念和应用,大家应该已经对其有所期待了吧,那么我们现在开始吧!!!
1.2 学习目标
- 了解 逻辑回归 的理论
- 掌握 逻辑回归 的 sklearn 函数调用使用并将其运用到鸢尾花数据集预测
1.3 代码流程
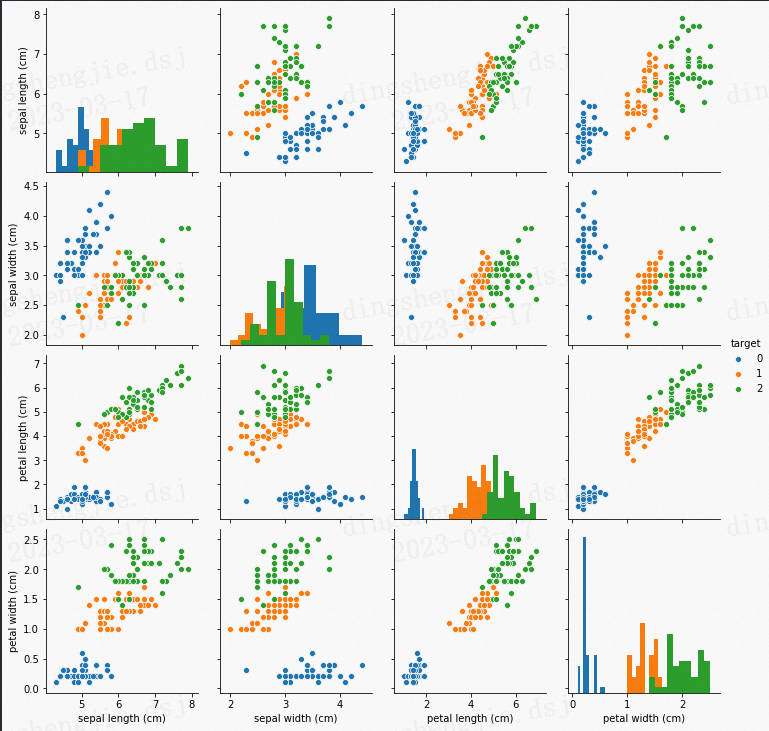
部分结果展示:
2.机器学习算法(二): 朴素贝叶斯(Naive Bayes)
2.1 朴素贝叶斯的介绍
朴素贝叶斯算法(Naive Bayes, NB) 是应用最为广泛的分类算法之一。它是基于贝叶斯定义和特征条件独立假设的分类器方法。由于朴素贝叶斯法基于贝叶斯公式计算得到,有着坚实的数学基础,以及稳定的分类效率。NB模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。当年的垃圾邮件分类都是基于朴素贝叶斯分类器识别的。
什么是条件概率,我们从一个摸球的例子来理解。我们有两个桶:灰色桶和绿色桶,一共有7个小球,4个蓝色3个紫色,分布如下图:
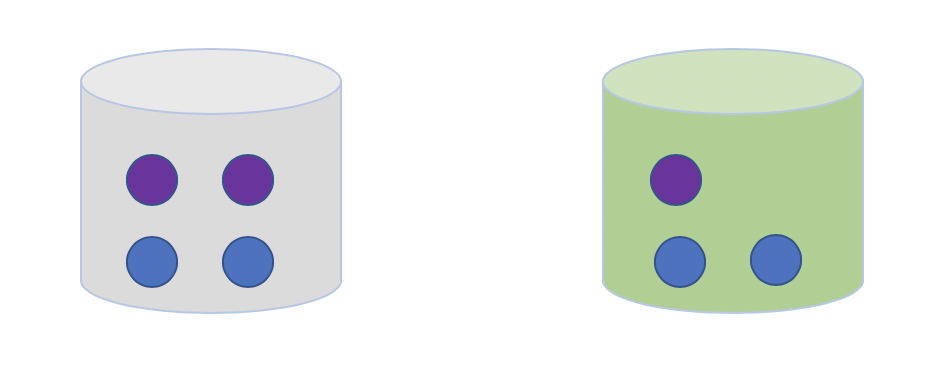
从这7个球中,随机选择1个球是紫色的概率p是多少?选择过程如下:
- 先选择桶
- 再从选择的桶中选择一个球
$p(球=紫色) \
=p(选择灰桶) \cdot p(从灰桶中选择紫色) + p(选择绿桶) \cdot p(从灰桶中选择紫色) \
=\frac{1}{2} \cdot \frac{2}{4} + \frac{1}{2} \cdot \frac{1}{2}$
上述我们选择小球的过程就是条件概率的过程,在选择桶的颜色的情况下是紫色的概率,另一种计算条件概率的方法是贝叶斯准则。
贝叶斯公式是英国数学家提出的一个数据公式:
$p(A|B)=\frac{p(A,B)}{p(B)}=\frac{p(B|A) \cdot p(A)}{\sum_{a \in ℱ_A}p(B|a) \cdot p(a)}$
p(A,B):表示事件A和事件B同时发生的概率。
p(B):表示事件B发生的概率,叫做先验概率;p(A):表示事件A发生的概率。
p(A|B):表示当事件B发生的条件下,事件A发生的概率叫做后验概率。
p(B|A):表示当事件A发生的条件下,事件B发生的概率。
我们用一句话理解贝叶斯:世间很多事都存在某种联系,假设事件A和事件B。人们常常使用已经发生的某个事件去推断我们想要知道的之间的概率。
例如,医生在确诊的时候,会根据病人的舌苔、心跳等来判断病人得了什么病。对病人来说,只会关注得了什么病,医生会通道已经发生的事件来
确诊具体的情况。这里就用到了贝叶斯思想,A是已经发生的病人症状,在A发生的条件下是B_i的概率。
2.2 朴素贝叶斯的应用
朴素贝叶斯算法假设所有特征的出现相互独立互不影响,每一特征同等重要,又因为其简单,而且具有很好的可解释性一般。相对于其他精心设计的更复杂的分类算法,朴素贝叶斯分类算法是学习效率和分类效果较好的分类器之一。朴素贝叶斯算法一般应用在文本分类,垃圾邮件的分类,信用评估,钓鱼网站检测等。
2.3 学习目标
- 掌握贝叶斯公式
- 结合两个实例了解贝朴素叶斯的参数估计
- 掌握贝叶斯估计
2.4 代码流程
-
Part 1. 莺尾花数据集--贝叶斯分类
- Step1: 库函数导入
- Step2: 数据导入&分析
- Step3: 模型训练
- Step4: 模型预测
- Step5: 原理简析
-
Part 2. 模拟离散数据集--贝叶斯分类
- Step1: 库函数导入
- Step2: 数据导入&分析
- Step3: 模型训练&可视化
- Step4: 原理简析
3.机器学习算法(三):K近邻(k-nearest neighbors)
3.1 KNN的介绍和应用
kNN(k-nearest neighbors),中文翻译K近邻。我们常常听到一个故事:如果要了解一个人的经济水平,只需要知道他最好的5个朋友的经济能力,
对他的这五个人的经济水平求平均就是这个人的经济水平。这句话里面就包含着kNN的算法思想。
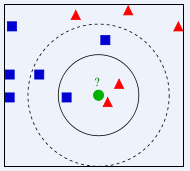
示例 :如上图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
1) KNN建立过程
1 给定测试样本,计算它与训练集中的每一个样本的距离。
2 找出距离近期的K个训练样本。作为测试样本的近邻。
3 依据这K个近邻归属的类别来确定样本的类别。
2) 类别的判定
①投票决定,少数服从多数。取类别最多的为测试样本类别。
②加权投票法,依据计算得出距离的远近,对近邻的投票进行加权,距离越近则权重越大,设定权重为距离平方的倒数。
- KNN的应用
KNN虽然很简单,但是人们常说"大道至简",一句"物以类聚,人以群分"就能揭开其面纱,看似简单的KNN即能做分类又能做回归,
还能用来做数据预处理的缺失值填充。由于KNN模型具有很好的解释性,一般情况下对于简单的机器学习问题,我们可以使用KNN作为
Baseline,对于每一个预测结果,我们可以很好的进行解释。推荐系统的中,也有着KNN的影子。例如文章推荐系统中,
对于一个用户A,我们可以把和A最相近的k个用户,浏览过的文章推送给A。
机器学习领域中,数据往往很重要,有句话叫做:"数据决定任务的上限, 模型的目标是无限接近这个上限"。
可以看到好的数据非常重要,但是由于各种原因,我们得到的数据是有缺失的,如果我们能够很好的填充这些缺失值,
就能够得到更好的数据,以至于训练出来更鲁棒的模型。接下来我们就来看看KNN如果做分类,怎么做回归以及怎么填充空值。
3.2 学习目标
- 了解KNN怎么做分类问题
- 了解KNN如何做回归
- 了解KNN怎么做空值填充, 如何使用knn构建带有空值的pipeline
3.3 代码流程
-
二维数据集--knn分类
- Step1: 库函数导入
- Step2: 数据导入
- Step3: 模型训练&可视化
- Step4: 原理简析
-
莺尾花数据集--kNN分类
- Step1: 库函数导入
- Step2: 数据导入&分析
- Step3: 模型训练
- Step4: 模型预测&可视化
-
模拟数据集--kNN回归
- Step1: 库函数导入
- Step2: 数据导入&分析
- Step3: 模型训练&可视化
-
马绞痛数据--kNN数据预处理+kNN分类pipeline
- Step1: 库函数导入
- Step2: 数据导入&分析
- Step3: KNNImputer空值填充--使用和原理介绍
- Step4: KNNImputer空值填充--欧式距离的计算
- Step5: 基于pipeline模型预测&可视化


项目参考以及说明:项目参考阿里天池并在启智社区进行云脑适配,修改了部分bug,使程序可以正常运行,该系列教程比较不错推荐大家学习
参考链接:https://tianchi.aliyun.com/course/310?spm=5176.21206777.J_3641663050.5.2e4517c9k8FTF7