第18课-CIFAR-10图像识别项目实战(PaddlePaddle版本)
hi,大家好,经历了前面多轮课程,相比大家已经对平台的各部分功能差不多都熟悉了,恭喜大家已经不再是当初那个小白啦~
今天我们通过平台演示一个猫狗图像识别的小项目,将前面所学到的知识串联起来加以巩固,开始向启智社区达人迈进!
话不多说,接下来进入CIFAR10图像数据集识别的项目实操。(对于此教程有问题的童鞋,可以点此参考大家的经验~)
快速开始: PaddlePaddle手写识别GPU训练任务实例
如果你是初学者或者不熟悉平台云脑任务的使用,通过以下5个简单步骤,你将快速学会如何创建项目,并开启一个GPU训练任务,实现10个类别图像的识别。
cifar10数据集由60000张大小为32 * 32的彩色图片组成,其中有50000张图片组成了训练集,另外10000张图片组成了测试集。
这些图片分为10个类别,本课程将训练一个模型能够把图片进行正确的分类。
本节课主要演示如何在云脑1完成训练任务以及模型管理,大致内容如下:
创建项目
代码提交
关联数据集
创建训练任务
训练完成
1 创建项目
-
首先你需要注册一个启智社区的账号。
-
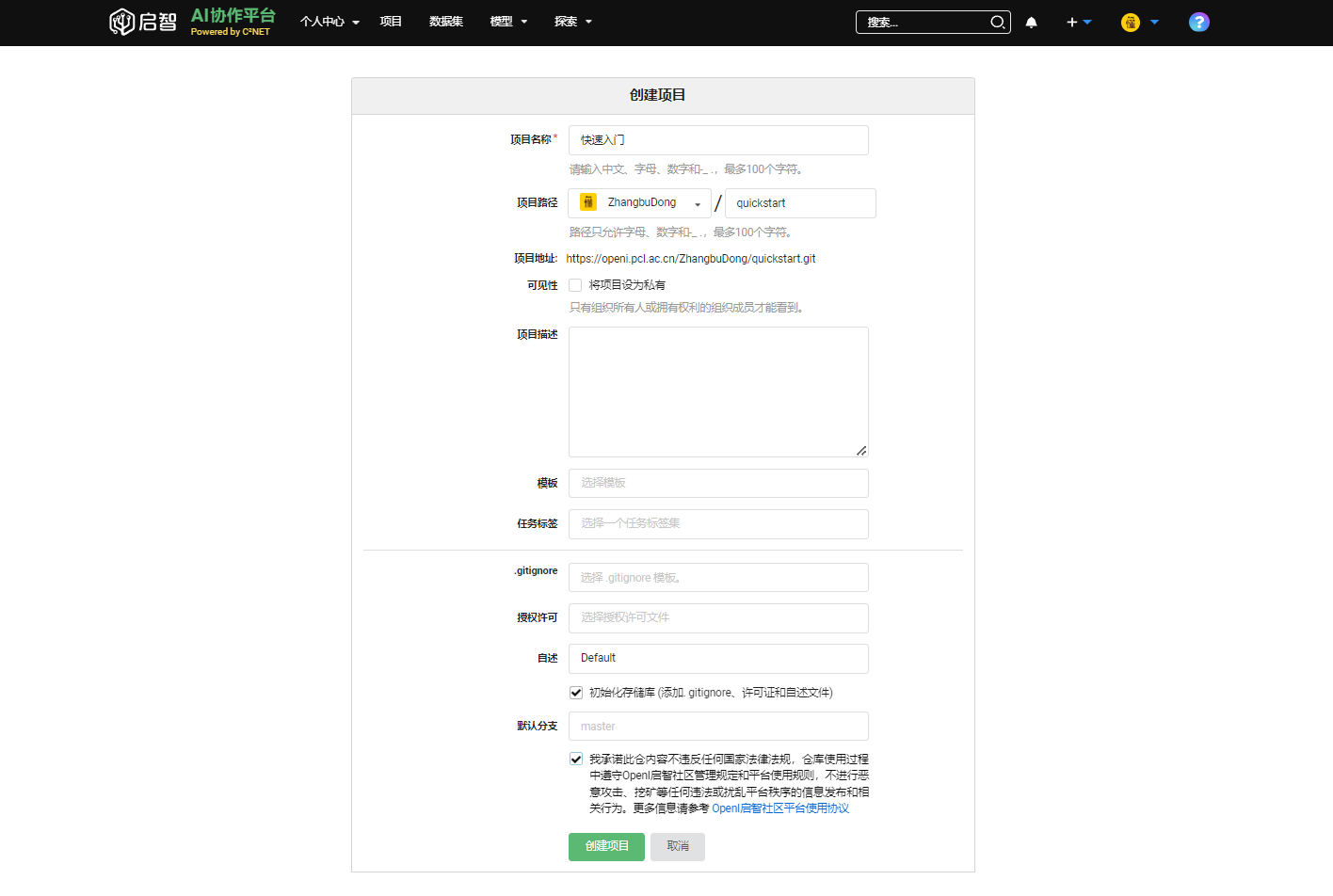
注册成功之后,请 点击这里 创建新项目。
-
进入创建项目详情界面
- 填写
项目名称
- 勾选
初始化存储库
- 勾选
承诺遵守平台使用协议
- 点击
创建项目
2 代码提交
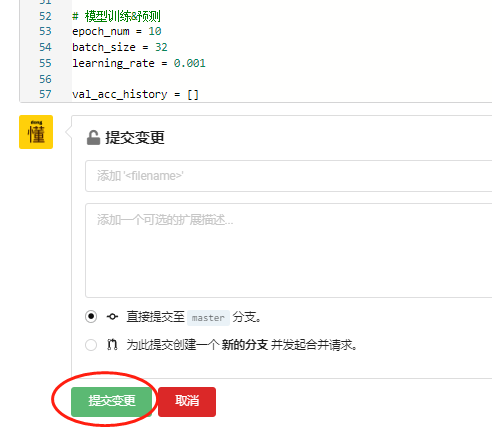
- 创建成功之后,来到项目主页。可以看到代码仓里已经默认生成了
README.md 描述文件,包含项目名称以及项目描述。
- 点击蓝色的
新建文件 按钮,将下面的示例代码复制到代码框,并命名为 train.py 。
# 环境配置
import paddle
import paddle.nn.functional as F
from paddle.vision.transforms import ToTensor
import numpy as np
# 数据加载
transform = ToTensor()
cifar10_train = paddle.vision.datasets.Cifar10(mode='train',
transform=transform)
cifar10_test = paddle.vision.datasets.Cifar10(mode='test',
transform=transform)
# 构建网络
class MyNet(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(MyNet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=3, out_channels=32, kernel_size=(3, 3))
self.pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=32, out_channels=64, kernel_size=(3,3))
self.pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv3 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3))
self.flatten = paddle.nn.Flatten()
self.linear1 = paddle.nn.Linear(in_features=1024, out_features=64)
self.linear2 = paddle.nn.Linear(in_features=64, out_features=num_classes)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.pool2(x)
x = self.conv3(x)
x = F.relu(x)
x = self.flatten(x)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
return x
# 模型训练&预测
epoch_num = 10
batch_size = 32
learning_rate = 0.001
val_acc_history = []
val_loss_history = []
def train(model):
print('start training ... ')
# turn into training mode
model.train()
opt = paddle.optimizer.Adam(learning_rate=learning_rate,
parameters=model.parameters())
train_loader = paddle.io.DataLoader(cifar10_train,
shuffle=True,
batch_size=batch_size)
valid_loader = paddle.io.DataLoader(cifar10_test, batch_size=batch_size)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = paddle.to_tensor(data[1])
y_data = paddle.unsqueeze(y_data, 1)
logits = model(x_data)
loss = F.cross_entropy(logits, y_data)
if batch_id % 1000 == 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, loss.numpy()))
loss.backward()
opt.step()
opt.clear_grad()
# evaluate model after one epoch
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
x_data = data[0]
y_data = paddle.to_tensor(data[1])
y_data = paddle.unsqueeze(y_data, 1)
logits = model(x_data)
loss = F.cross_entropy(logits, y_data)
acc = paddle.metric.accuracy(logits, y_data)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)
print("[validation] accuracy/loss: {}/{}".format(avg_acc, avg_loss))
val_acc_history.append(avg_acc)
val_loss_history.append(avg_loss)
model.train()
model = MyNet(num_classes=10)
train(model)
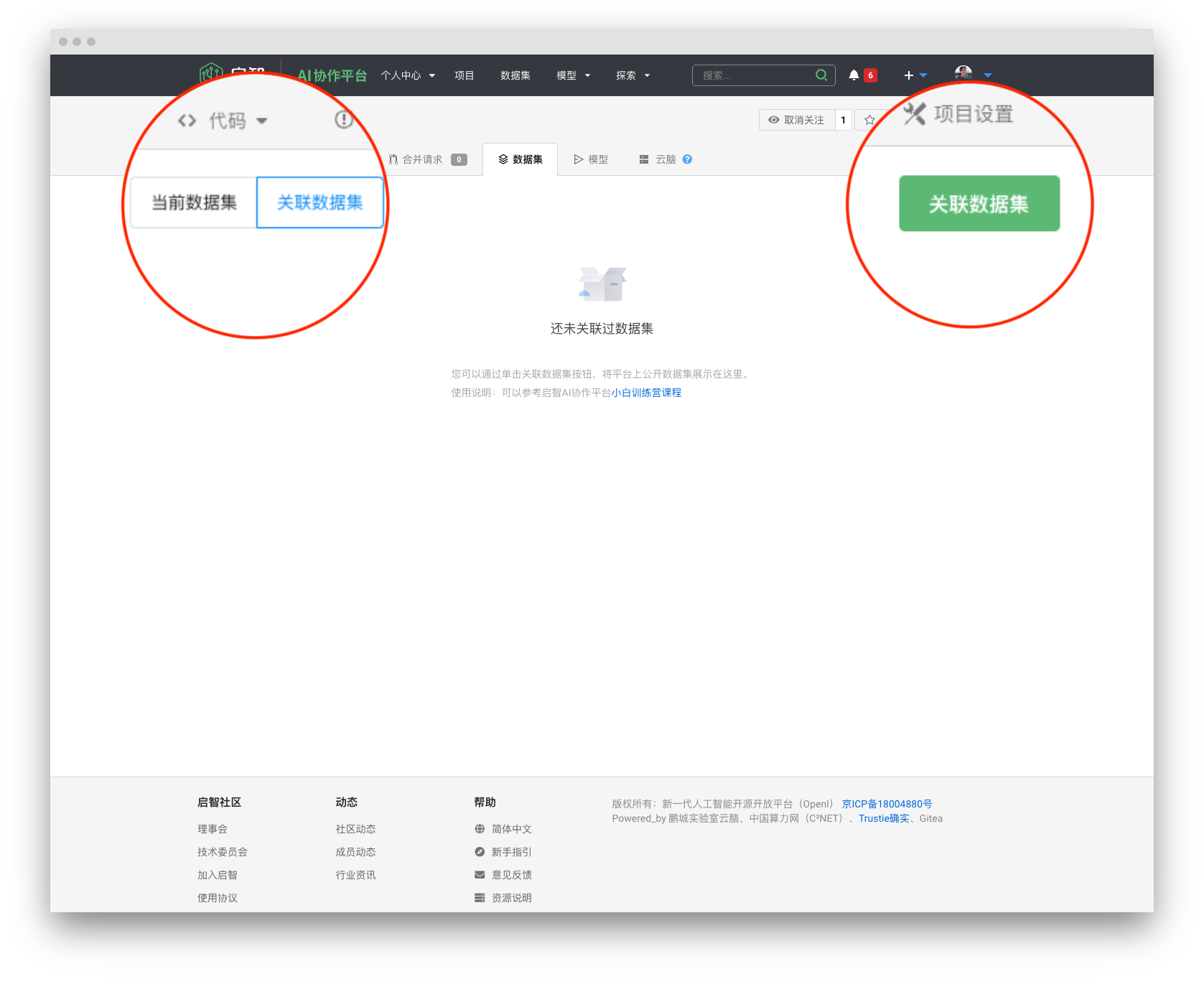
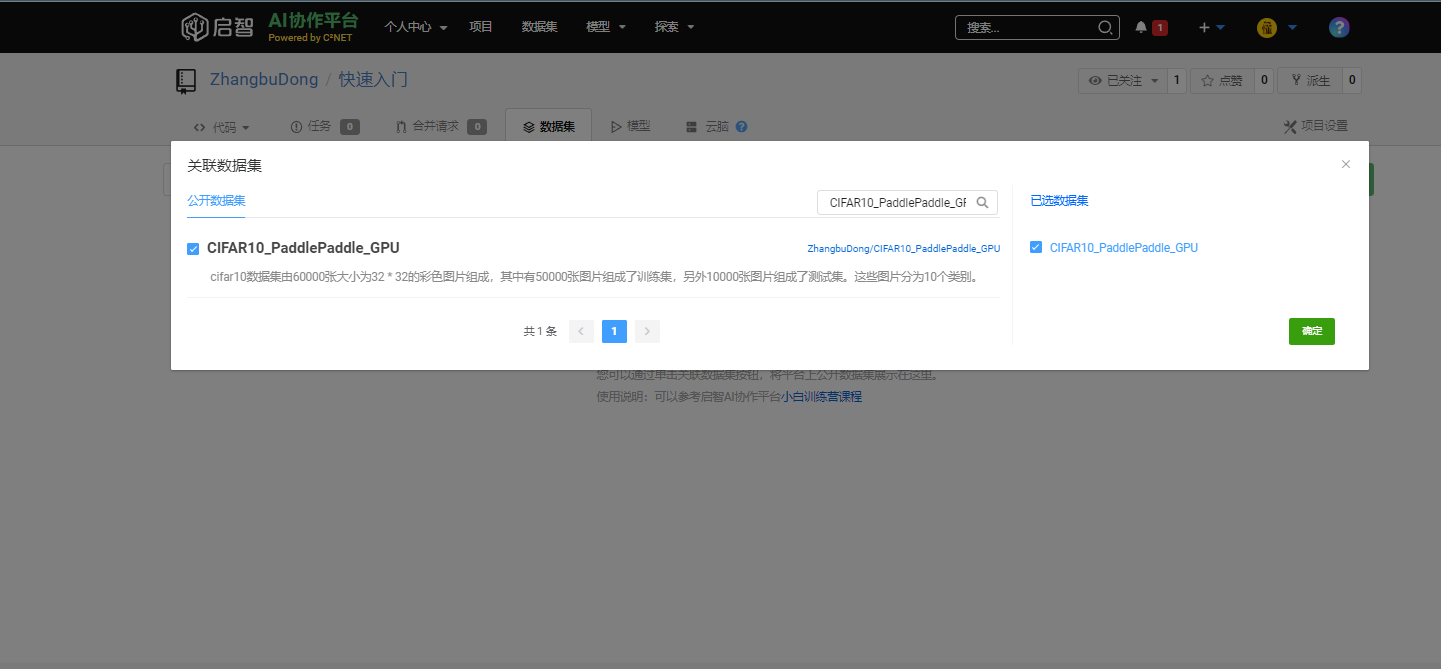
3 关联数据集
在项目页面中,依次点击 数据集→关联数据集→关联数据集, 搜索CIFAR10_PaddlePaddle_GPU,选择并关联。
4 创建训练任务
- 接下来创建云脑训练任务,在项目里找到 云脑 → 训练任务 → 新建训练任务。
-
填写以下参数
- 算力集群 启智集群
- 计算资源
CPU/GPU
- 任务名称
cifar10_gpu
- 镜像 复制并粘贴地址
dockerhub.pcl.ac.cn:5000/user-images/openi:ColugoMum-product
- 启动文件
train.py
- 数据集 本项目关联
CIFAR10_PaddlePaddle_GPU/cifar10.zip
- 资源规格 GPU: 1*A100, CPU: 4, 内存: 32GB, 共享内存: 16GB
- 其他配置保持默认值即可
5 训练完成
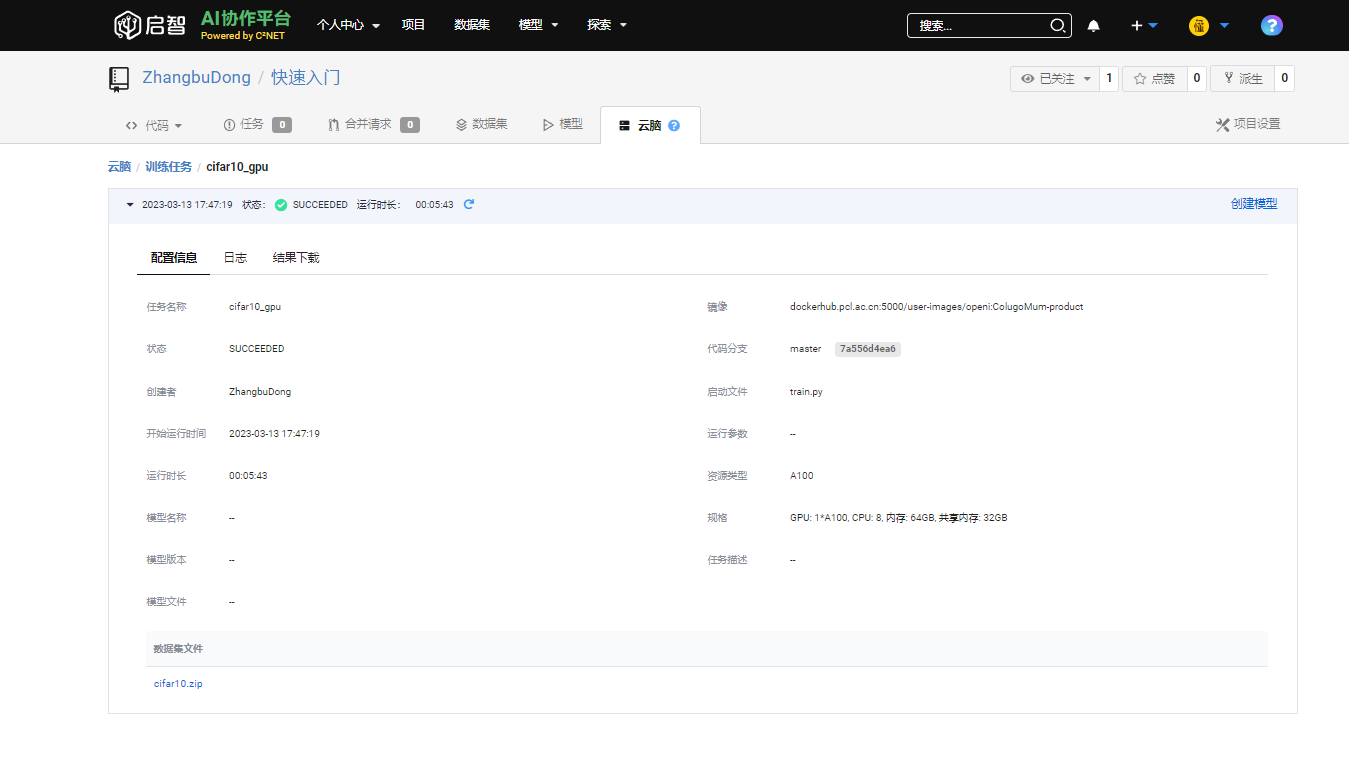
- 当训练任务的状态由 WAITING 变为 SUCCEEDED,任务训练成功。点击 任务名称 查看详情。
5.1 在配置信息界面可以查看任务配置
- 包括任务具体配置,包括镜像,数据集,资源规格,运行时间以及脚本文件。
5.2 在日志界面可以查看运行日志
- 这里是脚本文件中的所有输出打印,也叫做你的
任务日志。你可以自行在脚本文件中编辑你输出的信息。示例脚本 中打印了训练中每一个 batch 的损失,以及模型最终的准确率。
5.3 训练结束后可以下载模型文件
- 在这里你可以下载在脚本中输出的所有文件以及日志文本。
示例脚本 里输出了最终的PyTorch模型文件。