English | 简体中文
autox_competition是什么
AutoX开发的,针对于表格类型的数据挖掘竞赛的自动化机器学习工具
框架
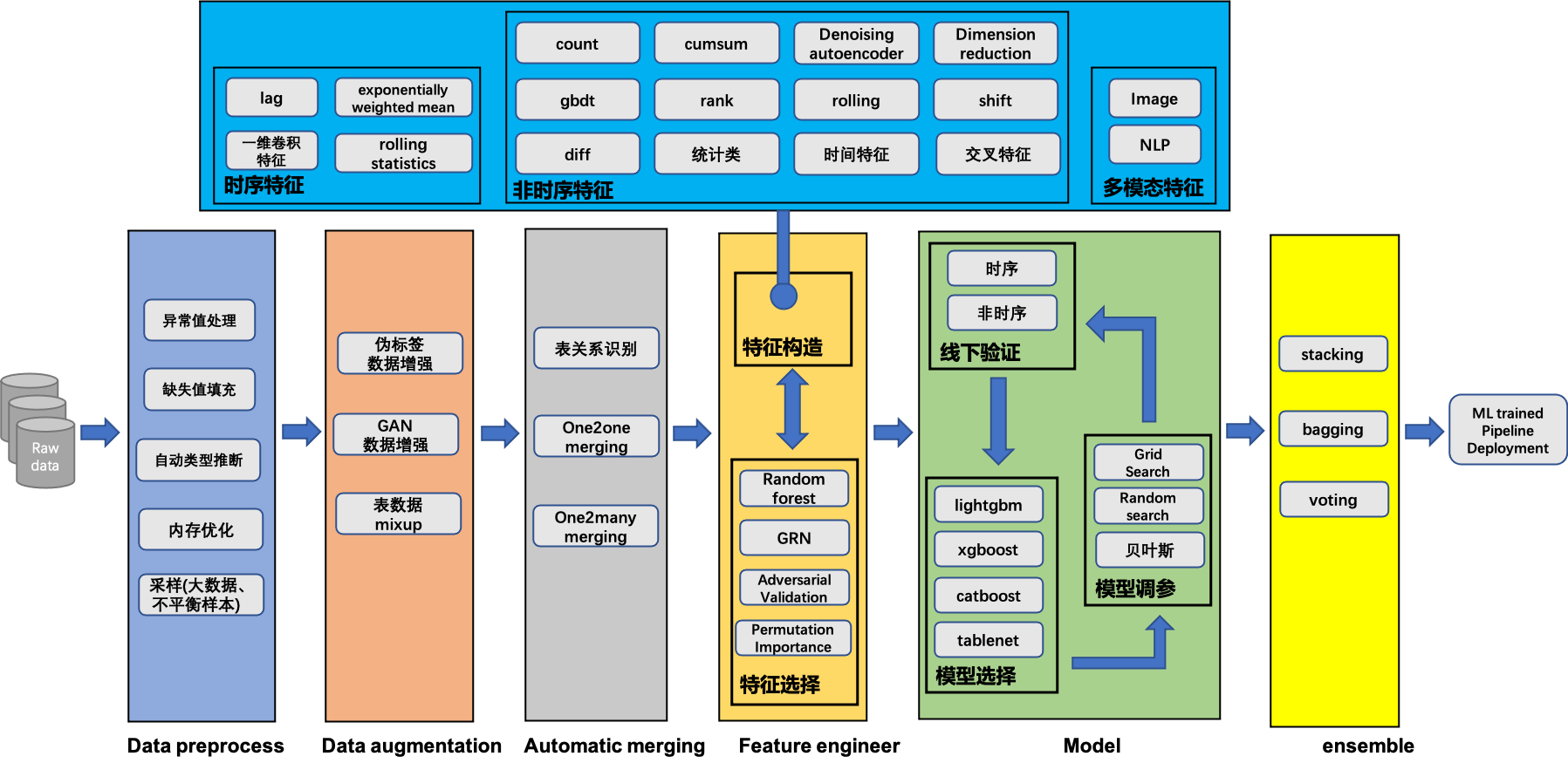
快速上手
使用以下函数一键获取预测结果:
autox.get_submit # 回归或分类问题
autox.get_submit_ts # 时间序列数据集
Demo(按数据类型划分)
二分类问题
Kaggle_Santander-AutoX解决方案:
2021神州信息极客大赛-贷款反欺诈-AutoX解决方案:
回归问题
DC租金预测-AutoX解决方案:
时序预测问题(多表)
2021阿里云供应链大赛-AutoX解决方案:
表格数据集中包含图片数据
kaggle petfinder-AutoX解决方案:
Demo(按使用场景划分)
营销场景
预测银行客户是否会认购定期存款
风控场景
贷款违约预测
推荐场景
预测移动端的广告是否会被点击
使用以下函数一键获取topk重要特征:
autox.get_top_features # 回归或分类问题
autox.get_top_features_ts # 时间序列数据集
获取topk重要特征Demo
kaggle-Allstate获取topk重要的特征:
目录
效果对比
数据类型
- cat: Categorical,类别型无序变量
- ord: Ordinal,类别型有序变量
- num: Numeric,连续型变量
- datetime: Datetime型时间变量
- timestamp: imestamp型时间变量
表关系
"relations": [ # 表关系(可以包含为1-1, 1-M, M-1, M-M四种)
{
"related_to_main_table": "true", # 是否为和主表的关系
"left_entity": "overdue", # 左表名字
"left_on": ["new_user_id"], # 左表拼表键
"right_entity": "userinfo", # 右表名字
"right_on": ["new_user_id"], # 右表拼表键
"type": "1-1" # 左表与右表的连接关系
},
{
"related_to_main_table": "true",
"left_entity": "overdue",
"left_on": ["new_user_id"],
"left_time_col": "flag1",
"right_entity": "bank",
"right_on": ["new_user_id"],
"right_time_col": "flag1",
"type": "1-M"
},
{
"related_to_main_table": "true",
"left_entity": "overdue",
"left_on": ["new_user_id"],
"left_time_col": "flag1",
"right_entity": "browse",
"right_on": ["new_user_id"],
"right_time_col": "flag1",
"type": "1-M"
},
{
"related_to_main_table": "true",
"left_entity": "overdue",
"left_on": ["new_user_id"],
"left_time_col": "flag1",
"right_entity": "bill",
"right_on": ["new_user_id"],
"right_time_col": "flag1",
"type": "1-M"
}
]
pipeline的逻辑
1.1 读数据
1.2 合并train和test
1.3 识别数据表中列的类型
1.4 数据预处理
特征工程包含单表特征和多表特征。
每一个特征工程类都包含以下功能:
一、自动筛选要执行当前操作的特征;
二、查看筛选出来的特征
三、修改要执行当前操作的特征
四、执行特征数据的计算,返回和主表样本条数以及顺序一致的特征
将构造出来的特征进行合并,行数不变,列数增加,返回大的宽表
将宽表划分成训练集和测试集
通过train和test的特征列数据分布情况,对构造出来的特征进行过滤,避免过拟合
利用过滤后的宽表特征对模型进行训练
模型类提供功能包括:
一、查看模型默认参数;
二、模型训练;
三、模型调参;
四、查看模型对应的特征重要性;
五、模型预测
AutoX类
AutoX类自动为用户管理数据集和数据集信息。
初始化AutoX类之后会执行以下操作:
一、读数据;
二、合并train和test;
三、识别数据表中列的类型;
四、数据预处理。
属性
info_: info_属性用于保存数据集的信息。
- info_['id']: List,用于标识样本的唯一Key
- info_['target']: String,用于标识数据表的标签列
- info_['shape_of_train']: Int,train数据集的数据样本条数
- info_['shape_of_test']: Int,test数据集的数据样本条数
- info_['feature_type']: Dict of Dict,标识数据表中特征列的数据类型
- info_['train_name']: String,用于训练集主表表名
- info_['test_name']: String,用于测试集主表表名
dfs_: dfs_属性用于保存所有的DataFrame,包含原始表数据和构造的表数据。
- dfs_['train_test']: train数据和test数据合并后的数据
- dfs_['FE_feature_name']:特征工程所构造出的数据,例如FE_count,FE_groupby
- dfs_['FE_all']:原始特征和所有特征工程合并后的数据集
方法
- concat_train_test: 将训练集和测试集拼接起来,一般在读取数据之后执行
- split_train_test: 将训练集和测试集分开,一般在完成特征工程之后执行
- get_submit: 获得预测结果(中间过程执行了完成的机器学习pipeline,包括数据预处理,特征工程,模型训练,模型调参,模型融合,模型预测等)
AutoX的pipeline中的操作对应的具体细节:
读数据
读取给定路径下的所有文件。默认情况下,会将训练集主表和测试集主表进行拼接,
再进行后续的数据预处理以及特征工程等操作,并在模型预测开始前,将训练集和测试进行拆分。
数据预处理
- 对时间列解析年, 月, 日, 时、星期几等信息
- 在每次训练前,会对输入到模型的数据删除无效(nunique为1)的特征
- 去除异常样本,去除label为nan的样本
特征工程
- time diff特征
- 聚合统计类特征
对要操作的特征列,将全体数据集中,和当前样本特征属性一致的样本计数作为特征
使用两层for训练提取统计类特征。
第一层for循环遍历所有筛选出来的分组特征(group_col),
第二层for循环遍历所有筛选出来的聚合特征(agg_col),
在第二层for循环中,
若遇到类别型特征,计算的统计特征为nunique,
若遇到数值型特征,计算的统计特征包括[median, std, sum, max, min, mean].
模型训练
AutoX目前支持以下模型:
1. Lightgbm
2. Xgboost
3. TabNet
模型融合
AutoX支持的模型融合方式包括一下两种,默认情况下,使用Bagging的方式进行融合。
1. Stacking;
2. Bagging。
比赛上分点总结:
| 比赛 |
magics |
| kaggle criteo |
对于nunique很大的特征列,进行分桶操作。例如,对于nunique大于10000的特征,做hash后截断保留4位,再进行label_encode。 |
| zhidemai |
article_id隐含了时间信息,增加article_id的排序特征。例如,groupby(['date'])['article_id'].rank()。 |
| kaggle StumbleUpon |
以文本列特征作为输入,使用Bert模型进行训练。 |
| kaggle ventilator |
对breath_id聚合的shift、diff、cumsum特征 |
| kaggle Santander |
识别出fake test,剔除之后再和train合并,构造全局的count特征。识别的方法:真实的样本至少有一个特征对应的值是全局唯一的,而fake的样本没有全局唯一的特征值。参考: List of Fake Samples and Public/Private LB split |
| kaggle Allstate Claims Severity |
label取log1p后训练模型,获得结果后取expm1,mae能降低35+ |