Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 laoyu
20e8d6b03e
laoyu
20e8d6b03e
|
2 years ago | |
|---|---|---|
| README.md | 2 years ago | |
README.md
Spiking Audio Dataset
本项目提供基于语音的两个分类数据集,包含输入脉冲序列和输出标签类别。其中,700通道的输入脉冲序列由人工耳蜗模型生成。
Spiking Heidelberg Digits (SHD) dataset
SHD数据集由约10000段对齐的高品质语音生成,语音是用德语或英语读出的数字(0~9)。数据集一共包含12位不同的发言者,其中2位的数据仅存在于测试集。数据以HDF5的格式存储,压缩后大小合计约338 MB。更多相关内容可点击标题链接获取。
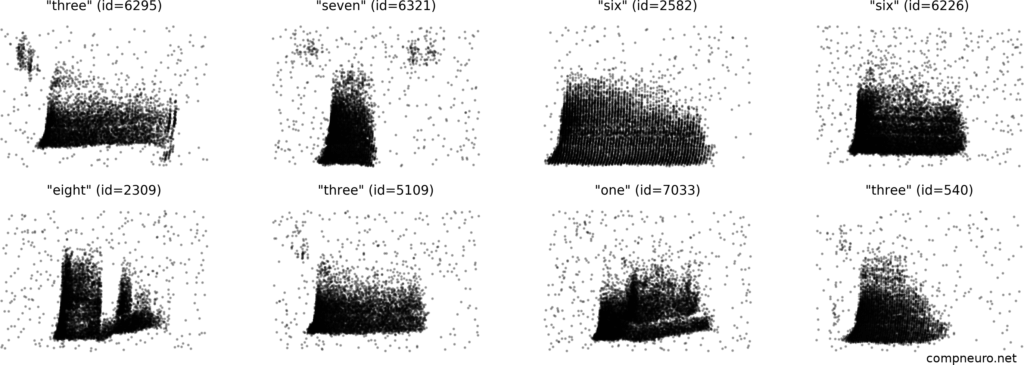
Spiking Speech Command (SSC) dataset
SSC数据集由Google发布的Speech Commands数据集生成,涵盖很多发言者在非可控场景下读出的词语,共包含35类词语。数据以HDF5的格式存储,压缩后大小合计约3.3 GB。更多相关内容可点击标题链接获取。
Reference
Cramer, B., Stradmann, Y., Schemmel, J., and Zenke, F. (2020). The Heidelberg Spiking Data Sets for the Systematic Evaluation of Spiking Neural Networks. IEEE Transactions on Neural Networks and Learning Systems 1–14. https://ieeexplore.ieee.org/document/9311226
