LARK策略
一、策略背景
现有的需求预测应用时序模型框架时,步骤如下:
事先确定模型池(包含多个单时序模型,如holt winters等)
确定历史数据长度(his_length),预测数据长度(forc_length),基于模型池中的所有单模型,对单个sku做历史回测
根据单模型的回测表现,从模型池中选出N个表现优异的模型,进行实际预测
对表现优异的模型预测结果,进行集成(均值集成、按照回测准确率分配权重、fforma等)
基于上述框架,在wm项目调优过程中发现,存在预测总是偏低或偏高的状况,经分析原因主要为:
受销售趋势影响,选出的N个回测表现优异模型,预测结果均偏低或偏高
某个模型的预测结果偏低/高较多,进行预测集成后,仍对最终结果产生影响
难以确定表现优异的N个模型的N的取值
于此,考虑改进单模型的集成策略,应用LASSO回归方法进行集成。
二、策略思路
-
lasso介绍
lasso是一种统计回归模型,在广义回归的基础上加入了L1正则项,进行变量筛选和复杂度调整。(详细理论不展开描述)
其中,由于L1正则项的数理结构(权值向量w中各个元素的绝对值之和,通常表示为∣∣w∣∣1),在进行参数优化时(如下图),L1正则化有助于生成一个稀疏权值矩阵(大部分矩阵元素是0),进而可以用于特征选择。当自变量特征较多时,通常只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(回归系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时可以只关注系数是非零值的特征。
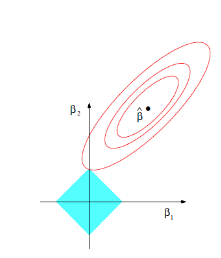
- 图注:同心椭圆(回归项)最先与蓝色正方形接触的点,就是符合约束同时最小化误差平方和的点。这个点就是同一个问题 LASSO 回归得到的自变量系数。 因为约束是一个正方形,所以除非相切,正方形与同心椭圆的接触点往往在正方形顶点上。而顶点又落在坐标轴上,这就意味着符合约束的自变量系数有一个值是 0。
-
lark策略思路
lark策略将单时序模型的回测结果作为lasso模型的自变量,真实销量为lasso模型的因变量y,训练集成模型。最终得到的lasso模型为:
yhat = w1 * model1 +w2 * model2 +... + wn * modeln(*)
基于(*),对单模型的预测结果进行集成,经项目调优实践,此策略可从一定程度上解决预测总是偏大、偏小的问题,并且不需要进行N的参数设置,表现较差的模型的回归系数会被设为0或极小。
- 策略可视化如下:

-
lark策略细节
3.1. 样本量少
以往仅通过距离预测时间节点最近的(his_length +forc_length)长度历史销量数据回测。然而,在训练lasso回归模型时,通常需要较多训练样本,当数据量较少时,可以通对历史销量数据进行切片并抽样的方式,扩大样本数据。
3.2. 模型训练
以往通常对单个sku进行回测和预测集成,有时会受到异常点的影响,集成预测不够稳健。经调研,lark策略可以有两种应用方式:
- 方式1:应用单sku序列,进行lasso集成预测,每个sku训练一个lasso模型。
- 方式2:应用所有(多个)序列,进行lasso集成预测,多个sku训练一个lasso模型,有文献说明,此种方法效果更好。
目前在wm调优中,考虑到现有预测工程框架的改造工程量,只应用了方式1。
三、后续研究
- 这种集成策略可以进一步拓展,除了lasso外,可以尝试其他模型,如ridge回归、mlp等,也许会有不同效果。
- 可以尝试应用策略方式2(多个sku序列一起训练lasso)
- 专利撰写完成。
四、参考文献
- 《LASSO regression》
- 《Meta-learning how to forecast time series》