X-modaler
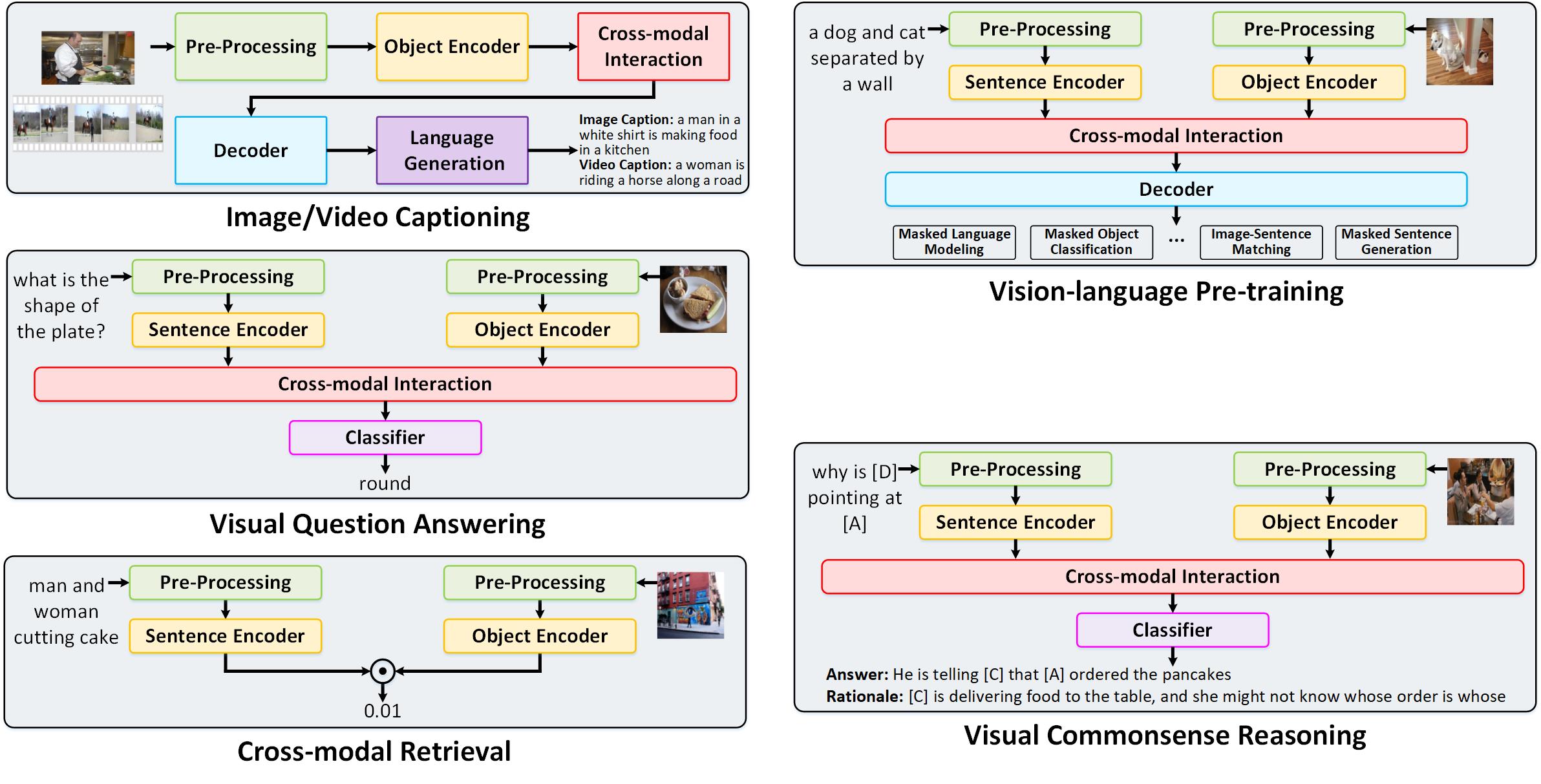
X-modaler is a versatile and high-performance codebase for cross-modal analytics (e.g., image captioning, video captioning, vision-language pre-training, visual question answering, visual commonsense reasoning, and cross-modal retrieval). This codebase unifies comprehensive high-quality modules in state-of-the-art vision-language techniques, which are organized in a standardized and user-friendly fashion.
The original paper can be found here.
Installation
See installation instructions.
Requiremenets
- Linux or macOS with Python ≥ 3.6
- PyTorch ≥ 1.8 and torchvision that matches the PyTorch installation. Install them together at pytorch.org to make sure of this
- fvcore
- pytorch_transformers
- jsonlines
- pycocotools
Getting Started
See Getting Started with X-modaler
Training & Evaluation in Command Line
We provide a script in "train_net.py", that is made to train all the configs provided in X-modaler. You may want to use it as a reference to write your own training script.
To train a model(e.g., UpDown) with "train_net.py", first setup the corresponding datasets following datasets, then run:
# Teacher Force
python train_net.py --num-gpus 4 \
--config-file configs/image_caption/updown.yaml
# Reinforcement Learning
python train_net.py --num-gpus 4 \
--config-file configs/image_caption/updown_rl.yaml
Model Zoo and Baselines
A large set of baseline results and trained models are available here.
| Image Captioning |
| Attention |
Show, attend and tell: Neural image caption generation with visual attention |
ICML |
2015 |
| LSTM-A3 |
Boosting image captioning with attributes |
ICCV |
2017 |
| Up-Down |
Bottom-up and top-down attention for image captioning and visual question answering |
CVPR |
2018 |
| GCN-LSTM |
Exploring visual relationship for image captioning |
ECCV |
2018 |
| Transformer |
Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning |
ACL |
2018 |
| Meshed-Memory |
Meshed-Memory Transformer for Image Captioning |
CVPR |
2020 |
| X-LAN |
X-Linear Attention Networks for Image Captioning |
CVPR |
2020 |
| Video Captioning |
| MP-LSTM |
Translating Videos to Natural Language Using Deep Recurrent Neural Networks |
NAACL HLT |
2015 |
| TA |
Describing Videos by Exploiting Temporal Structure |
ICCV |
2015 |
| Transformer |
Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning |
ACL |
2018 |
| TDConvED |
Temporal Deformable Convolutional Encoder-Decoder Networks for Video Captioning |
AAAI |
2019 |
| Vision-Language Pretraining |
| Uniter |
UNITER: UNiversal Image-TExt Representation Learning |
ECCV |
2020 |
| TDEN |
Scheduled Sampling in Vision-Language Pretraining
with Decoupled Encoder-Decoder Network |
AAAI |
2021 |
Image Captioning on MSCOCO (Cross-Entropy Loss)
| Name |
Model |
BLEU@1 |
BLEU@2 |
BLEU@3 |
BLEU@4 |
METEOR |
ROUGE-L |
CIDEr-D |
SPICE |
| LSTM-A3 |
GoogleDrive |
75.3 |
59.0 |
45.4 |
35.0 |
26.7 |
55.6 |
107.7 |
19.7 |
| Attention |
GoogleDrive |
76.4 |
60.6 |
46.9 |
36.1 |
27.6 |
56.6 |
113.0 |
20.4 |
| Up-Down |
GoogleDrive |
76.3 |
60.3 |
46.6 |
36.0 |
27.6 |
56.6 |
113.1 |
20.7 |
| GCN-LSTM |
GoogleDrive |
76.8 |
61.1 |
47.6 |
36.9 |
28.2 |
57.2 |
116.3 |
21.2 |
| Transformer |
GoogleDrive |
76.4 |
60.3 |
46.5 |
35.8 |
28.2 |
56.7 |
116.6 |
21.3 |
| Meshed-Memory |
GoogleDrive |
76.3 |
60.2 |
46.4 |
35.6 |
28.1 |
56.5 |
116.0 |
21.2 |
| X-LAN |
GoogleDrive |
77.5 |
61.9 |
48.3 |
37.5 |
28.6 |
57.6 |
120.7 |
21.9 |
| TDEN |
GoogleDrive |
75.5 |
59.4 |
45.7 |
34.9 |
28.7 |
56.7 |
116.3 |
22.0 |
Image Captioning on MSCOCO (CIDEr Score Optimization)
| Name |
Model |
BLEU@1 |
BLEU@2 |
BLEU@3 |
BLEU@4 |
METEOR |
ROUGE-L |
CIDEr-D |
SPICE |
| LSTM-A3 |
GoogleDrive |
77.9 |
61.5 |
46.7 |
35.0 |
27.1 |
56.3 |
117.0 |
20.5 |
| Attention |
GoogleDrive |
79.4 |
63.5 |
48.9 |
37.1 |
27.9 |
57.6 |
123.1 |
21.3 |
| Up-Down |
GoogleDrive |
80.1 |
64.3 |
49.7 |
37.7 |
28.0 |
58.0 |
124.7 |
21.5 |
| GCN-LSTM |
GoogleDrive |
80.2 |
64.7 |
50.3 |
38.5 |
28.5 |
58.4 |
127.2 |
22.1 |
| Transformer |
GoogleDrive |
80.5 |
65.4 |
51.1 |
39.2 |
29.1 |
58.7 |
130.0 |
23.0 |
| Meshed-Memory |
GoogleDrive |
80.7 |
65.5 |
51.4 |
39.6 |
29.2 |
58.9 |
131.1 |
22.9 |
| X-LAN |
GoogleDrive |
80.4 |
65.2 |
51.0 |
39.2 |
29.4 |
59.0 |
131.0 |
23.2 |
| TDEN |
GoogleDrive |
81.3 |
66.3 |
52.0 |
40.1 |
29.6 |
59.8 |
132.6 |
23.4 |
Video Captioning on MSVD
| Name |
Model |
BLEU@1 |
BLEU@2 |
BLEU@3 |
BLEU@4 |
METEOR |
ROUGE-L |
CIDEr-D |
SPICE |
| MP-LSTM |
GoogleDrive |
77.0 |
65.6 |
56.9 |
48.1 |
32.4 |
68.1 |
73.1 |
4.8 |
| TA |
GoogleDrive |
80.4 |
68.9 |
60.1 |
51.0 |
33.5 |
70.0 |
77.2 |
4.9 |
| Transformer |
GoogleDrive |
79.0 |
67.6 |
58.5 |
49.4 |
33.3 |
68.7 |
80.3 |
4.9 |
| TDConvED |
GoogleDrive |
81.6 |
70.4 |
61.3 |
51.7 |
34.1 |
70.4 |
77.8 |
5.0 |
Video Captioning on MSR-VTT
| Name |
Model |
BLEU@1 |
BLEU@2 |
BLEU@3 |
BLEU@4 |
METEOR |
ROUGE-L |
CIDEr-D |
SPICE |
| MP-LSTM |
GoogleDrive |
73.6 |
60.8 |
49.0 |
38.6 |
26.0 |
58.3 |
41.1 |
5.6 |
| TA |
GoogleDrive |
74.3 |
61.8 |
50.3 |
39.9 |
26.4 |
59.4 |
42.9 |
5.8 |
| Transformer |
GoogleDrive |
75.4 |
62.3 |
50.0 |
39.2 |
26.5 |
58.7 |
44.0 |
5.9 |
| TDConvED |
GoogleDrive |
76.4 |
62.3 |
49.9 |
38.9 |
26.3 |
59.0 |
40.7 |
5.7 |
Visual Question Answering
| Name |
Model |
Overall |
Yes/No |
Number |
Other |
| Uniter |
GoogleDrive |
70.1 |
86.8 |
53.7 |
59.6 |
| TDEN |
GoogleDrive |
71.9 |
88.3 |
54.3 |
62.0 |
Caption-based image retrieval on Flickr30k
Visual commonsense reasoning
License
X-modaler is released under the Apache License, Version 2.0.
Citing X-modaler
If you use X-modaler in your research, please use the following BibTeX entry.
@inproceedings{Xmodaler2021,
author = {Yehao Li, Yingwei Pan, Jingwen Chen, Ting Yao, and Tao Mei},
title = {X-modaler: A Versatile and High-performance Codebase for Cross-modal Analytics},
booktitle = {Proceedings of the 29th ACM international conference on Multimedia},
year = {2021}
}