
{kind=link}
Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 kongdebug
24df59ce3c
kongdebug
24df59ce3c
|
1 year ago | |
|---|---|---|
| data/lite_data/10_03 | 1 year ago | |
| datasets | 1 year ago | |
| losses | 1 year ago | |
| networks | 1 year ago | |
| splits | 1 year ago | |
| test_tipc | 1 year ago | |
| utils | 1 year ago | |
| README.md | 1 year ago | |
| export.py | 1 year ago | |
| inference.py | 1 year ago | |
| output_17_0.png | 1 year ago | |
| predict.py | 1 year ago | |
| test.py | 1 year ago | |
| train.py | 1 year ago | |
| trainer.py | 1 year ago | |
README.md
基于Paddle复现MLDA-Net实现单目深度估计
1. 项目背景
- 在计算机视觉领域里,深度指的是图像中所表示像素的3D点,在三维空间中到相机镜头的距离。 而深度估计是场景感知中重要的一环,测量与物体间的距离是所有生物赖以生存的技能。在计算机视觉领域中,深度估计同样是许多高层任务的基石,其结果广泛用于视觉导航、障碍物检测、三维立体重建等方向
| 视觉导航 | 障碍物规避 | 三维立体重建 |
|---|---|---|
 |
 |
 |
-
传统的方法是使用激光雷达或结构光在物体表面的反射来获取深度信息,但是由于获得稠密而准确的深度图的成本过高,无法得到广泛的应用。相比之下,基于图像的深度估计方法直接根据输入的(R, G, B)信息估计出场景的深度信息,不需要成本高昂的设备,应用场景更广
-
根据输入图像的数量可以将基于图像的深度估计方法分为多目深度估计和单目深度估计
- 多目深度估计是通过观测得到的多张像片估计深度,比较经典的算法有从运动中恢复(SfM)、多视图重建(MVS)等。这些的方法大多需要成对图像或图像序列作为输入、要已知相机参数,对输入有较强限制且结果受到特征点提取与特征匹配影响大
- 单目深度估计只需要单张像片就能估计深度,相对于多目深度估计更加灵活,但是由于缺乏深度线索,所以它是一个不适定的问题
| 双目深度估计 | 单目深度估计 |
|---|---|
 |
 |
-
虽然从单张图难以得到准确的深度信息,单目深度估计算法给的粗略预测结果可以作为先验知识,为算法的收敛性和鲁棒性提供保障;在工业生产中有不少硬件能直接获取深度,不过都各自有相应的缺陷:Lidar设备昂贵;基于结构光的深度摄像头如Kinect其不能在室外使用,得到的深度图也存在大量噪声;双目摄像头需要用到立体匹配算法,计算量大,在低纹理区域效果不好。单目摄像头对比来看,成本最低、设备普及广,因此单目深度估计应用潜力比其他方案更大
-
基于深度学习的单目深度估计可以分为两大类:有监督单目深度估计和自监督单目深度估计。有监督的单目深度估计方法需要地面真实深度作为监督,通常依赖高精度深度传感器来捕获地面真实深度信息,这大大限制了这些方法的使用。最近发展的自监督单目深度估计部分缓解了这些缺点,其目的是使用连续帧之间的约束来预测深度信息,相比之下,自监督单目深度估计方法不依赖于地面真实深度信息,这使得它们更便于在许多应用中应用。
-
本项目展示的是以IEEE TRANSACTIONS ON IMAGE PROCESSING 2021的论文《MLDA-Net: Multi-Level Dual Attention-Based Network for Self-Supervised Monocular Depth Estimation》为参考, 复现的基于多级双重注意力的自监督深度估计网络MLDA-Net,针对自监督方法预测的深度图往往比较模糊导致许多深度细节丢失的问题,提出新的自监督深度估计框架MLDA-Net,能提供边界准确、细节丰富的像素级深度信息。 在KITTI基准数据集上达到SOTA,在其他基准数据集同样能体现该模型的优越性
2. 技术难点
- 有监督的深度估计真值获取耗费大量的物力和财力,代价高昂
- 当前自监督深度估计特征提取不足,限制了自监督深度估计方法的性能
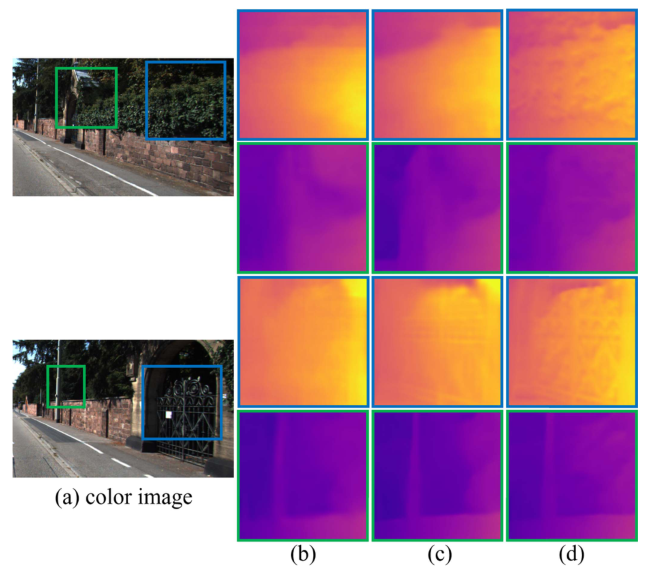
- 目前方法获取的深度估计图存在深度模糊的现象,例如图中的(b)和(c)部分所示,一些图像中的小目标:如闸门的图案和植物叶子区域等深度估计信息,可以看到细节容易丢失
3.解决方案
- 采用自监督的深度估计框架MLDA-Net,提供了深度信息估计能力,以低分辨率的彩色图像作为输入,可以以自监督的方式估计对应的深度信息,有效减少对于深度采集设备的依赖
- 使用多级特征融合(multi-level feature extraction, MLFE)的策略,从不同尺度层中提取丰富的层次表示,用于高质量深度预测
- 采用了一种双重注意策略来获得有效的特征,该策略通过结合全局和局部注意力模块来增强全局和局部的结构信息
- 利用重新加权(re-weighted)的策略计算损失函数,对不同层级的输出的深度信息进行重新加权,从而对最终输出的深度信息有效监督
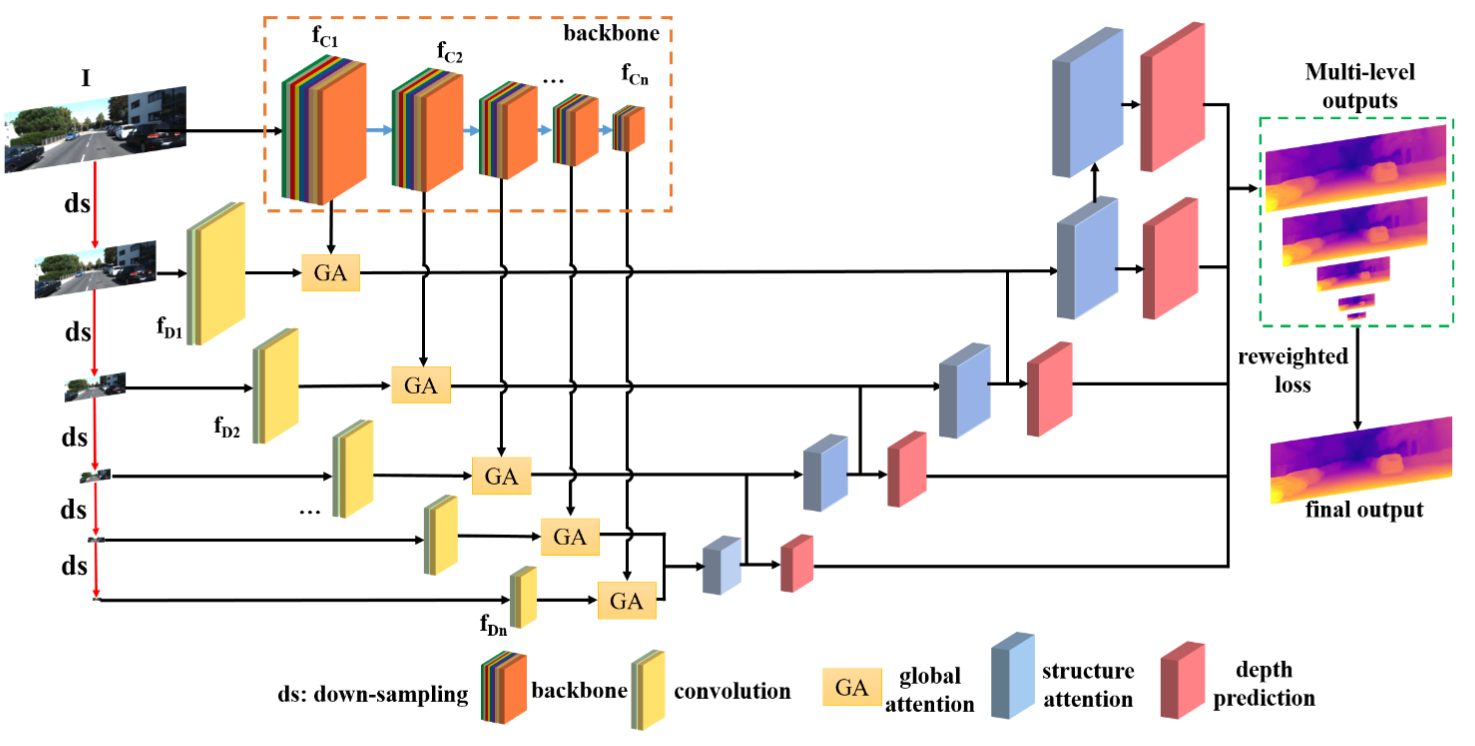
- 该模型的总体结构如上图所示。
- 最左边一列为多个不同尺度的输入数据,该尺度为可选参数scales。输入数据过两路卷积网络来提取特征,接着用注意网络GA进行整合并进一步提取特征。这部分就是该模型的第一个网络结构,在代码中名为models["encoder"]
- 在提取特征后,该模型就进入第二个网络结构models["depth"],即为上图右侧一半结构。该网络主要基于两种注意力块进行特征提取和上采样,最终输出不同尺度输入图所对应的不同尺度的深度图
4. 数据准备
数据集介绍
- 本项目使用的数据集为KITTI数据集,KITTI数据集由德国卡尔斯鲁厄理工学院和丰田工业大学芝加哥分校联合赞助的用于自动驾驶领域研究的数据集
- 数据集作者收集了长达6个小时的真实交通环境,数据集有经过校正和同步的图像、雷达扫描、高精度的GPS信息和IMU加速信息等多种模态的信息组成。作者还在数据集官网提供了光流、物体检测、深度估计等多种任务的Benchmark
- 更多信息可参考KITTI,图源【深度估计】KITTI数据集介绍与使用说明
训练数据集
-
使用的训练数据集为KITTI,该数据集由经过和激光雷达测量配准后的校准视频组成,深度信息的评估为使用激光雷达点云,数据集大小为176G
-
将KITTI数据集进行划分,训练集为39810个3张单目影像集,测试集和验证集的数量分别为4424与697。自监督学习的单目深度估计有3种训练模式:
- 单目视觉
- 双目立体视觉
- 单目+双目立体视觉
-
文章中三种模式分别试验了,本项目采用第3种单目+双目立体视觉的训练模式,具体做法可参考论文原文。同时,数据集需要生成depth_hints,实验结果表明使用depth_hints能提升深度估计的结果,具体如何生成可参考:https://github.com/nianticlabs/depth-hints
-
本项目也提供了较小规模的kitti数据集,该数据集是kitti数据集中的10_03部分,并提供了生成的depth_hint进行简化训练。
- 可通过以下链接和验证码获取该数据集,链接:https://pan.baidu.com/s/1Rj5biYkAR2pURuzR881GQw , 提取码:n5wa
- 也可以通过使用上传到AI Studio上的数据集:https://aistudio.baidu.com/aistudio/datasetdetail/148774
# 解压文件到dataset文件夹下,尽管是一部份,由于数据集比较大,解压时间依然超过10分钟
# 如果不打算训练可跳过这步
unzip -oq 10_03.zip -d ./dataset/
数据格式
- 解压到
dataset文件夹中的数据格式如下
tree -L 3 ./dataset
./dataset
├── 2011_10_03
│ ├── 2011_10_03_drive_0027_sync
│ │ ├── image_00
│ │ ├── image_01
│ │ ├── image_02
│ │ ├── image_03
│ │ ├── oxts
│ │ └── velodyne_points
│ ├── 2011_10_03_drive_0034_sync
│ │ ├── image_00
│ │ ├── image_01
│ │ ├── image_02
│ │ ├── image_03
│ │ ├── oxts
│ │ └── velodyne_points
│ ├── 2011_10_03_drive_0042_sync
│ │ ├── image_00
│ │ ├── image_01
│ │ ├── image_02
│ │ ├── image_03
│ │ ├── oxts
│ │ └── velodyne_points
│ ├── 2011_10_03_drive_0047_sync
│ │ ├── image_00
│ │ ├── image_01
│ │ ├── image_02
│ │ ├── image_03
│ │ ├── oxts
│ │ └── velodyne_points
│ ├── calib_cam_to_cam.txt
│ ├── calib_imu_to_velo.txt
│ └── calib_velo_to_cam.txt
└── depth_hints
└── 2011_10_03
├── 2011_10_03_drive_0034_sync
└── 2011_10_03_drive_0042_sync
33 directories, 3 files
5. 环境准备
- 运行本项目需要安装PaddlePaddle2.2.2,并安装依赖项、准备本项目提供的预训练模型
- 预训练模型文件夹有4个文件,2个是预测深度信息的权重,另外两个是预测位姿的权重。因为单目视觉的训练需要模型同时估计深度信息和相机位姿,这样才能计算损失函数,具体细节见论文
#安装必要的库
pip install munch
pip install scikit-image
pip install natsort
- 权重已上传到AI Studio数据集MLDA-NET-weight+program上,将其下载并放置于
weights文件夹下
# 将权重转移到新建的文件夹
mkdir -p ./weights
cp -r data/data149788/*.pdparams ./weights
6. 模型训练
- 运行如下代码开始训练模型:默认使用一个gpu训练
- 训练过程中会在
MLDA-Net-repo/log_train/文件夹下生成train.log文件夹,用于保存训练日志。 模型训练需使用paddle2.2版本,paddle2.3版本由于paddle.cumsum函数存在问题,会输出错误结果
%cd MLDA-Net-repo
python train.py --data_path ../dataset --depth_hint_path ../dataset/depth_hints
7. 模型评估
- MLDA-Net使用单张GPU通过如下命令一键式启动评估
- 注:如果要在自己提供的模型上进行测试,请将修改参数 --load_weights_folder your_weight_folder
python test.py --data_path ../dataset/ --depth_hint_path ../dataset/depth_hints --load_weights_folder ../weights/
W0708 13:21:27.491781 21099 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0708 13:21:27.497159 21099 device_context.cc:465] device: 0, cuDNN Version: 7.6.
loading model from folder ../weights/
Loading encoder weights...
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/framework/io.py:415: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
if isinstance(obj, collections.Iterable) and not isinstance(obj, (
Loading depth weights...
Loading pose_encoder weights...
Loading pose weights...
Epoch 0: StepDecay set learning rate to 0.0001.
Models and images files are saved to:
./log_test
There are 11220 training items and 438 validation items
[2022-07-08 13:23:42,986][INFO] val_dateset: rmse_avg=4.196064473287156,rmse_min=1.2780027389526367 ,rmse_max=9.574527740478516
eval: ...........................................................................................................................................................................................................................
复现精度(192 x 640 分辨率):
| Backbone | Train dataset | Test dataset | RMSE | checkpoints_dir |
|---|---|---|---|---|
| MLDA | kitti/10_03/train | kitti/10_03/val | 4.690 | |
| MLDA | kitti/10_03/train | kitti/10_03/val | 4.216(复现) | pretrain_weights |
8. 模型预测
使用测试集中的单张图像预测
- 对模型进行单图像的简单测试时,运行以下命令
- 输出深度信息结果保存在
MLDA-Net-repo/predict_figs文件夹下,名字为depth_predict.jpg
python predict.py --load_weights_folder ../weights/
W0708 13:27:25.425439 21837 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0708 13:27:25.430135 21837 device_context.cc:465] device: 0, cuDNN Version: 7.6.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/framework/io.py:415: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
if isinstance(obj, collections.Iterable) and not isinstance(obj, (
predict_img saved to ./predict_figs/depth_predict.jpg
eval
abs_rel | sq_rel | rmse | rmse_log | a1 | a2 | a3 |
& 0.120 & 0.765 & 4.355 & 0.170 & 0.848 & 0.973 & 0.992 \\
-> Done!
# 展示结果,图像上方为RGB图,下方为对应的预测深度图
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline
img_depth = Image.open(r"./predict_figs/depth_predict.jpg")
plt.figure(figsize=(10,8))
plt.imshow(img_depth)
plt.axis("off")
plt.show()

使用自己的数据进行预测
- 如果要在自己提供的图片上进行测试,执行以下命令
color_path参数为要预测的图像路径
python predict.py --load_weights_folder ../weights/ --color_path ../work/color/1.jpg --no_rmse True
9. 模型导出
-
以下命令将训练好的模型导出成预测所需的模型结构文件
model.pdmodel和模型权重文件model.pdiparams以及model.pdiparams.info文件,均存放在MLDA-Net-repo\inference\目录下。 -
注:由于该模型的主体实际上是两组模型,所以会生成两组文件model_encoder和model_depth.
python export.py --load_weights_folder ../weights/ --save_dir ./inference
10. 模型部署
- 利用导出的模型文件和paddle inference进行python端的部署
python inference.py
- 使用自己的数据,则执行以下命令
python inference.py --color_path ../work/color/1.jpg --no_rmse True
11. 项目参考
本项目基于Paddle版本的MLDA-Net实现单目深度估计,提供从“数据处理→模型训练与验证→模型部署” 的全流程指导,读者可参考在自定义的单目深度估计数据集中训练单目深度估计网络
Text Python other
Contributors (1)
