OpenI 在线推理部署示例
注意,注意,注意!!!,使用在线推理提供webui gradio服务时需要了解以下关键几点:
平台没有对外直接提供端口如:7860 对外提供服务,只能使用fastapi转发到对外暴露的指定的URL(环境变量可获取:os.getenv('OPENI_GRADIO_URL'))提供服务。
需要简单的调整原先gradio代码启动webui的方式,仅在开头和结尾稍微修改下原始代码,平台会使用fastapi方式启动webui服务。
代码需要在调试环境下先确定原先gradio代码运行没有错误,确保代码能跑起来,不然在线推理会直接呈现STOPPED或FAILED状态,因为在线推理目前没有代码运行错误的消息提示反馈。
通过api方式部署推理服务可参考示例在线推理示例api方式
可参考以下方式启动webui在线推理服务,具体代码可参考ChatGLM2在线推理webui方式:
"""以下为gradio方式平台启动需要的代码 """
from fastapi import FastAPI
import os
import gradio as gr
app = FastAPI()
#初始化导入数据集和预训练模型到容器内
from c2net.context import prepare
c2net_context = prepare()
#获取预训练模型路径
pretrain_model_path = c2net_context.pretrain_model_path
tokenizer = AutoTokenizer.from_pretrained(pretrain_model_path + "/ChatGLM2-6B", trust_remote_code=True)
model = AutoModel.from_pretrained(pretrain_model_path + "/ChatGLM2-6B", trust_remote_code=True).cuda()
#此处省略其他代码...
#设置demo
with gr.Blocks() as demo:
#省略代码
#使用demo.queue()或demo.launch()启动交互式界面
demo.queue()
#将Gradio的界面demo挂载到FastAPI应用程序app中,并使用环境变量OPENI_GRADIO_URL中指定的路径。
app = gr.mount_gradio_app(app, demo, path=os.getenv('OPENI_GRADIO_URL'))
ChatGLM2在线推理示例
示例使用的镜像地址为: 192.168.242.22:443/default-workspace/fccb038c23234b9e80105d4ccd152117/image:ChatGLM2-6B
支持多模型后选择的模型如图
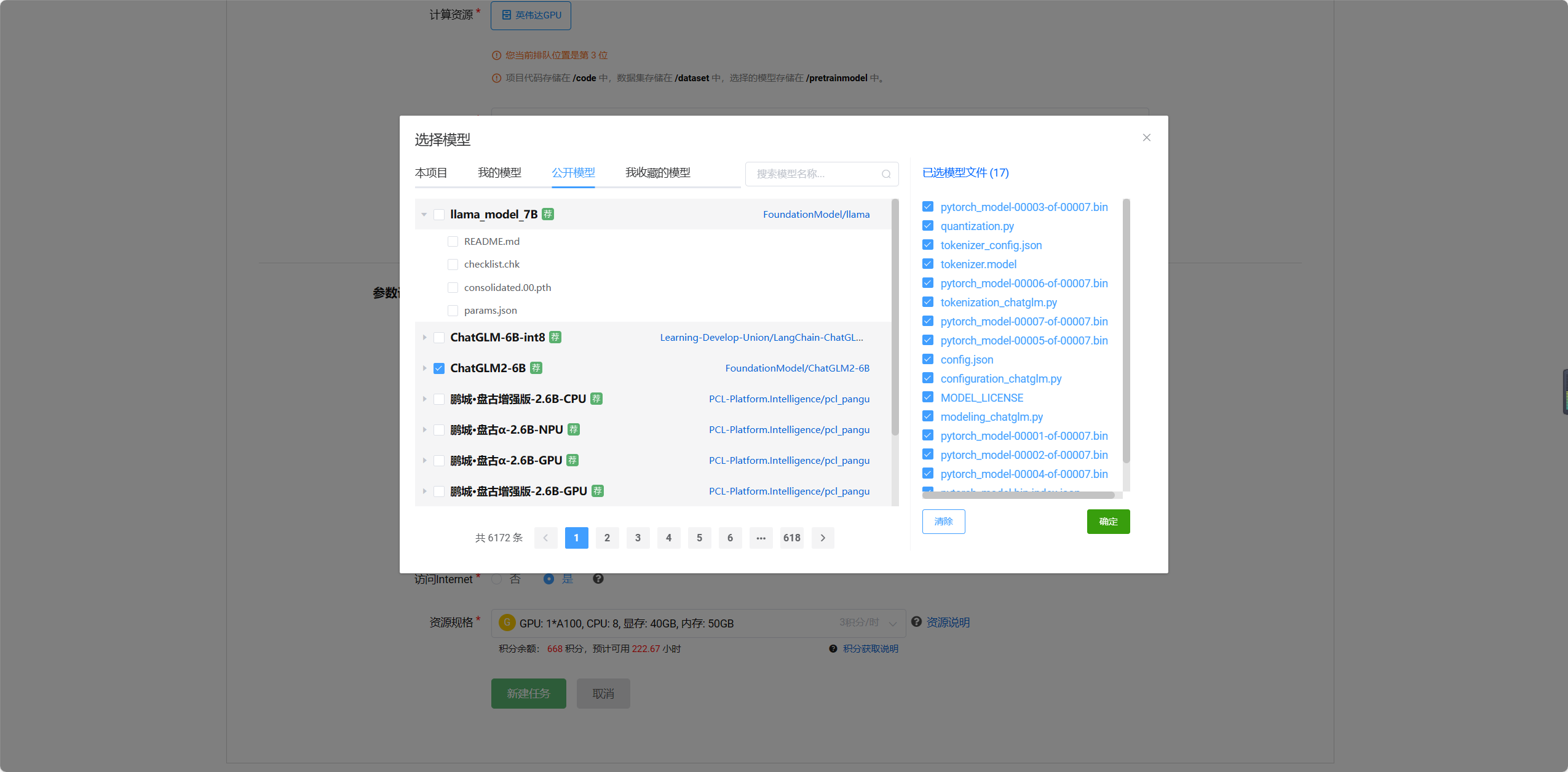
创建在线推理详细参数图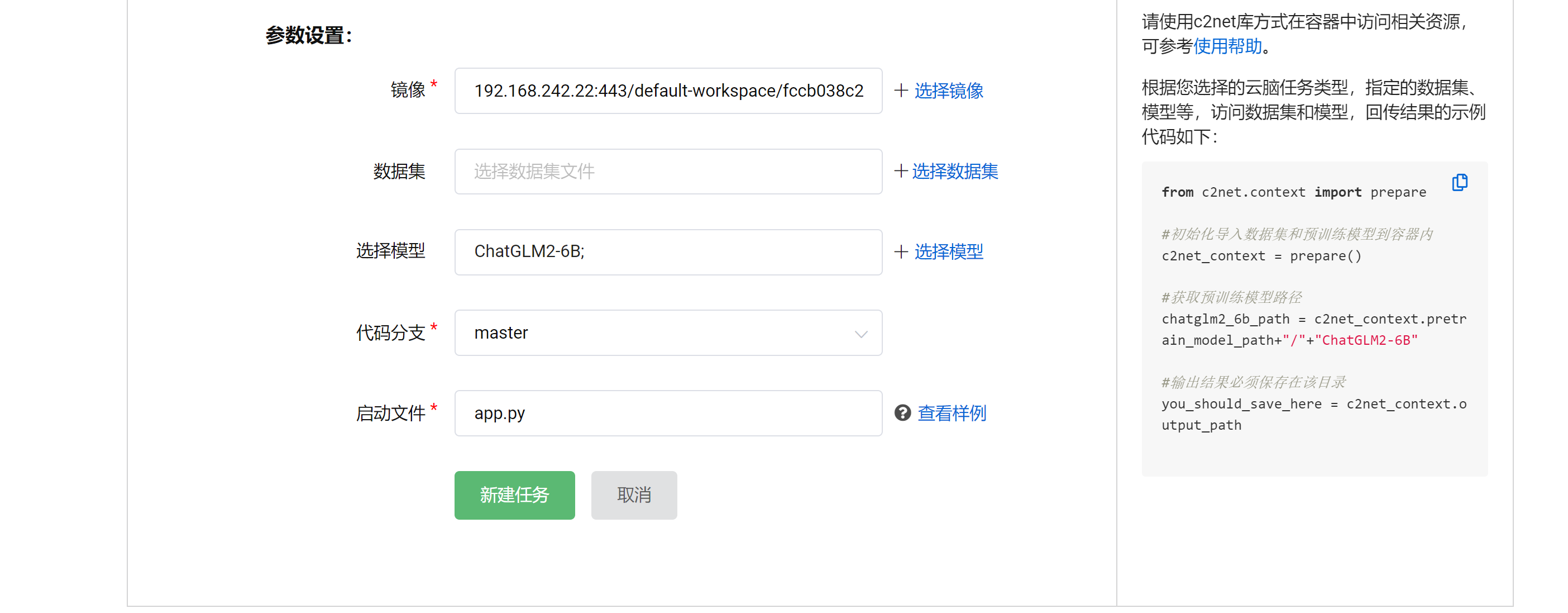
""" 以为为gradio方式平台启动固定需要的代码****** """
from fastapi import FastAPI
import os
import gradio as gr
app = FastAPI()
""" ********************************** """
from transformers import AutoModel, AutoTokenizer
import mdtex2html
from c2net.context import prepare
#初始化导入数据集和预训练模型到容器内
c2net_context = prepare()
#获取预训练模型路径
pretrain_model_path = c2net_context.pretrain_model_path
tokenizer = AutoTokenizer.from_pretrained(pretrain_model_path + "/ChatGLM2-6B", trust_remote_code=True)
model = AutoModel.from_pretrained(pretrain_model_path + "/ChatGLM2-6B", trust_remote_code=True).cuda()
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
# from utils import load_model_on_gpus
# model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2)
model = model.eval()
"""Override Chatbot.postprocess"""
def postprocess(self, y):
if y is None:
return []
for i, (message, response) in enumerate(y):
y[i] = (
None if message is None else mdtex2html.convert((message)),
None if response is None else mdtex2html.convert(response),
)
return y
gr.Chatbot.postprocess = postprocess
def parse_text(text):
"""copy from https://github.com/GaiZhenbiao/ChuanhuChatGPT/"""
lines = text.split("\n")
lines = [line for line in lines if line != ""]
count = 0
for i, line in enumerate(lines):
if "```" in line:
count += 1
items = line.split('`')
if count % 2 == 1:
lines[i] = f'<pre><code class="language-{items[-1]}">'
else:
lines[i] = f'<br></code></pre>'
else:
if i > 0:
if count % 2 == 1:
line = line.replace("`", "\`")
line = line.replace("<", "<")
line = line.replace(">", ">")
line = line.replace(" ", " ")
line = line.replace("*", "*")
line = line.replace("_", "_")
line = line.replace("-", "-")
line = line.replace(".", ".")
line = line.replace("!", "!")
line = line.replace("(", "(")
line = line.replace(")", ")")
line = line.replace("$", "$")
lines[i] = "<br>"+line
text = "".join(lines)
return text
def predict(input, chatbot, max_length, top_p, temperature, history, past_key_values):
chatbot.append((parse_text(input), ""))
for response, history, past_key_values in model.stream_chat(tokenizer, input, history, past_key_values=past_key_values,
return_past_key_values=True,
max_length=max_length, top_p=top_p,
temperature=temperature):
chatbot[-1] = (parse_text(input), parse_text(response))
yield chatbot, history, past_key_values
def reset_user_input():
return gr.update(value='')
def reset_state():
return [], [], None
with gr.Blocks() as demo:
gr.HTML("""<h1 align="center">ChatGLM2-6B</h1>""")
chatbot = gr.Chatbot()
with gr.Row():
with gr.Column(scale=4):
with gr.Column(scale=12):
user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10).style(
container=False)
with gr.Column(min_width=32, scale=1):
submitBtn = gr.Button("Submit", variant="primary")
with gr.Column(scale=1):
emptyBtn = gr.Button("Clear History")
max_length = gr.Slider(0, 32768, value=8192, step=1.0, label="Maximum length", interactive=True)
top_p = gr.Slider(0, 1, value=0.8, step=0.01, label="Top P", interactive=True)
temperature = gr.Slider(0, 1, value=0.95, step=0.01, label="Temperature", interactive=True)
history = gr.State([])
past_key_values = gr.State(None)
submitBtn.click(predict, [user_input, chatbot, max_length, top_p, temperature, history, past_key_values],
[chatbot, history, past_key_values], show_progress=True)
submitBtn.click(reset_user_input, [], [user_input])
emptyBtn.click(reset_state, outputs=[chatbot, history, past_key_values], show_progress=True)
demo.queue()
#demo.launch()
"""以下为平台固定需要的代码""""
app = gr.mount_gradio_app(app, demo, path=os.getenv('OPENI_GRADIO_URL'))
示例一
示例使用的镜像地址为: 192.168.242.22:443/default-workspace/fccb038c23234b9e80105d4ccd152117/image:fastapi-gradio-SD1

上图展示示例一的相应的参数设置;
示例二
示例使用的镜像地址为: 192.168.242.22:443/default-workspace/fccb038c23234b9e80105d4ccd152117/image:fastapi-gradio-SD1
当模型需要加载多个的模型文件或配置文件时可以将相应文件打包到数据集进行相应的部署,此示例的文件结构详情为https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main

上图展示示例二的相应的参数设置;