MindTorch调试调优指南
1.简介
MindTorch是一款将PyTorch训练脚本高效迁移至MindSpore框架执行的实用工具,旨在不改变原生PyTorch用户的编程使用习惯下,使得PyTorch风格代码能在昇腾硬件上获得高效性能。用户只需要将PyTorch源代码中torch系列相关的包导入部分(如torch、torchvision等),替换为导入mindtorch.torch系列相关的包(如mindtorch.torch、mindtorch.torchvision等),加上少量训练代码适配即可实现模型在昇腾硬件上的训练。
本教材旨在为开发者提供一个简明扼要的精度问题与性能问题初步定位指导。如果您还未完成模型迁移转换,可参考MindTorch用户使用指南。
进行调试调优时,推荐调整日志级别export MSA_LOG=2协助调试分析。
2.功能调试
PyNative模式功能调试
1)当执行出现异常时,您会得到由MindSpore反馈的报错信息,MindSpore报错信息采用Python Traceback处理,包括Python堆栈信息、报错类型与报错描述等信息,对于接口级别的问题,可以根据报错堆栈信息快速定位出问题位置:

更多细节请参考MindSpore功能调试。
2)PyNative模式模式下可以通过添加Print打印信息获取问题接口当前的输入数据具体取值:
若输入数据不符合预期,则可能由于前置接口导致问题,可以在关键位置添加断点,逐步缩小范围,直至明确问题接口;
如果您在使用过程中遇到框架问题或接口无法对标请通过ISSUE 和我们反馈交流。
Graph模式功能调试
首先推荐您在PyNative模式(即默认模式)下完成功能调试后再尝试Graph模式执行。当Graph模式出现异常时,可结合报错信息和静态图语法支持文档进行手动适配。同时您将您的受限场景通过ISSUE 反馈给我们,我们会优先分析支持。
3.精度调优
您可以通过对比迁移后模型和PyTorch原始模型的执行结果,确保迁移模型的功能正确性。这里推荐两种方式进行比较:
方式一:加载PyTorch的pth文件进行精度比较,使用该方式可以对每个网络层输入输出值进行比较,如果出现精度异常时可快速定位出精度异常的网络层;
方式二:基于TroubleShooter工具进行精度比较,使用该方式不需要用户提供pth文件(依赖环境安装PyTorch库),可进行最终网络输出值的比较;
方式一:加载PyTorch的pth文件进行精度比较
该方法大致可分为以下几个步骤:
步骤 1:确保网络输入完全一致(可以使用固定的输入数据,也可调用真实数据集);
步骤 2:确保执行推理模式;
model = LeNet()
model.eval()
由于框架随机策略以及各自内置随机数生成算法的实现存在差异,所以即使用户配置相同的随机种子,两个框架生成的随机数并不一致(详情请参考MindSpore与PyTorch随机数策略的区别)。同理,带有随机性的接口,如nn.dropout,当配置概率不为0或1时,即使输入一致,由于内置随机数逻辑差异,两个框架得到的输出结果并不一致。通过配置网络为推理模式则可排除这方面随机性的影响。
步骤 3:确保网络权重的一致性;
由于MindSpore随机策略与PyTorch随机策略有所不同,即使网络层初始化策略与算法完全一致,也无法保证权重值一致。此时可以先保存PyTorch的网络权重,再加载至MindTorch迁移模型的权重中:
1):在PyTorch原始脚本中保存网络权重至本地(如果已有模型提供下载的pth文件可跳过该步骤);
import torch
torch.save(net.state_dict(), 'pytorch.pth')
2):将PyTorch权重加载至MindTorch迁移模型中(根据执行环境是否能够安装PyTorch库可细分为两种场景):
场景一:当前执行环境中安装有PyTorch库,则在MindTorch迁移网络脚本中加载 1) 中保存的pth,即可将PyTorch的权重加载到迁移模型中,从而保证网络权重的一致性;

import mindtorch.torch as torch
net.load_state_dict(torch.load('pytorch.pth'))
场景二:如果最终执行环境无法安装PyTorch库,可参考下图流程将PyTorch权重加载至MindTorch迁移模型中:

首先在任意一个安装有PyTorch和MindTorch的环境上执行以下代码:
import mindtorch.torch as torch
...
net.load_state_dict(torch.load('pytorch.pth'))
torch.save(net.state_dict(), 'msa.pth')
保存MindTorch对应的pth文件后,可在最终执行环境中加载:
import mindtorch.torch as torch
...
net.load_state_dict(torch.load('msa.pth'))
步骤 4:分别将PyTorch和MindTorch的模型推理结果打印出来进行比较,如果比较结果精度误差在1e-3范围内则表示迁移模型精度正常;
步骤 5:打印网络信息协助定位精度异常;
当出现网络输出误差过大情况,可以结合我们提供的信息调试工具(debug_layer_info),观察各网络层输入输出的信息,便于快速定位导致精度异常的网络层,提升精度调试分析效率(推荐);也可以在PyNative模式下基于关键位置添加断点,逐步缩小范围,直至明确误差是否合理。
PyTorch执行脚本:
import torch
from mindtorch.tools import debug_layer_info
...
net = Net()
net.load_state_dict(torch.load('pytorch.pth'))
net.eval()
debug_layer_info(net, frame='pytorch') # PyTorch原始脚本需配置frame='pytorch'
for X, y in train_data:
pred = net(x)
...
exit() # Just compare the first step
MindTorch执行脚本:
import mindtorch.torch as torch
from mindtorch.tools import debug_layer_info
...
net = Net()
net.load_state_dict(torch.load('pytorch.pth')) # 执行环境未安装PyTorch时加载'msa.pth'.
net.eval()
debug_layer_info(net)
for X, y in train_data:
pred = net(x)
...
exit() # Just compare the first step
用户只需要分别在MindTorch或PyTorch模型实例化对象后调用debug_layer_info接口,即可输出模型内各层的输入输出信息(更多可选配置属性可参考信息调试工具)。推荐在第一个step结束时直接exit()程序,分别捕获MindTorch和PyTorch第一个step的推理信息并进行比较就可以确定精度异常的网络层。
例:以ModelZoo中的AlexNet网络为例:

注意,用例中为保障输入数据一致性,需要取消数据的shuffle行为,并加载相同的pth文件,保证权重初始化的一致性。
打印结果如下,用户可自定调用其他工具进行比较,可以很容易观察到每个网络层的输入输出,初步确定精度异常层后再细化定位具体接口,可提升调试效率。
网络权重信息:

注:BN层中的running_mean和running_var等buffer信息在MindTorch侧会在parameters中打印,而PyTorch侧会在buffers中打印。
各网络层信息:

方式二:基于TroubleShooter工具进行精度比较
TroubleShooter工具提供API级别自动化比较功能,可实现对PyTorch 和 MindTorch 网络正、反向 API 级别输入、输出数据的自动保存以及对比
步骤 1:安装TroubleShooter工具
source安装:
git clone https://gitee.com/mindspore/toolkits.git
cd toolkits/troubleshooter
bash package.sh
pip install output/troubleshooter-*-py3-none-any.whl
pip安装:
pip install troubleshooter -i https://pypi.org/simple
注意,troubleshooter安装版本需高于或等于1.0.16版本。
步骤 2:分别在MindTorch和PyTorch的网络训练脚本中按顺序调用api dump接口并运行:
以AlexNet的训练代码为例,
MindTorch执行脚本:
import torch
import troubleshooter as ts
...
def train():
...
net = AlexNet()
ts.migrator.api_dump_init(net, './ad_res', *, retain_backward=True, compare_statedict=True) # MindTorch dump结果输出的文件位置,指定需要dump的内容
ts.migrator.api_dump_start() # 开启数据dump
for X, y in train_data:
output = net(X, y) # 开始训练
...
ts.migrator.api_dump_stop() # 停止数据dump
exit() # 只比较第一个step
PyTorch执行脚本:
import msadapter.pytorch as torch
import troubleshooter as ts
...
def train():
...
net = AlexNet()
ts.migrator.api_dump_init(net, './pt_res', *, retain_backward=True, compare_statedict=True) # 初始化PyTorch dump结果输出的文件位置,指定需要dump的内容
ts.migrator.api_dump_start() # 开启数据dump
for X, y in train_data:
output = net(X, y) # 开始训练
...
ts.migrator.api_dump_stop() # 停止数据dump
exit() # 只比较第一个step
api_dump_init中的compare_statedict参数:
compare_statedict(bool):是否比较PyTorch和MindTorch网络state_dict中的内容,默认值为 False。设置为True时,会在
output_path路径下生成相应的网络结构pth文件,最终比较结果会在执行troubleshooter.migrator.api_dump_compare时打印,不需
要在api_dump_compare的参数中再次设置。
各接口的其他参数和详细使用方法见api dump文档。
预期结果
分别运行修改后的MindTorch和PyTorch训练脚本,troubleshooter日志显示dump成功,数据储存在指定的路径下:

步骤 3:调用api_dump_compare进行数据比较
示例:比较'./pt_res/'和'./ad_res'路径下保存的dump数据
import troubleshooter as ts
if __name__ == "__main__":
ts.migrator.api_dump_compare('./pt_res/', './ad_res', equal_nan=True)
该接口的其他参数和详细使用方法见troubleshooter.migrator.api_dump_compare文档。
注意:需要在main函数中调用该接口。
预期结果
运行该脚本,获得如下执行结果:
api_dump_init中compare_statedict置为True时,结果中会包含网络中可学习参数的对比

- 正向输入输出的对比

api_dump_init中retain_backward置为True时,结果中会包含反向输入输出的对比

步骤 4:查询接口调用栈
在api_dump_init生成的dump目录中找到.json文件,用以上表格中的接口名作为关键字在文件中检索相应的调用栈信息。
示例:在MindTorch的调用栈信息中查找表格中NN_ReLU_0(torch.nn.ReLU)接口的调用栈(不区分input和output):

参考文档
更多使用细节可参考以下文档:
4.性能调优
本章节从单卡的性能调优指导入手,帮助用户快速找到单卡训练过程中的性能瓶颈点。多卡场景亦可采用类似手段进行分析。训练性能调优思路可参考下图,具体细节可参考指南中对应部分:

注:由于首步执行可能存在设备预热/初始化等耗时,下述内容均排除首步执行,推荐观察训练趋于稳定时的现象。
通常训练过程中各个迭代的耗时可拆分为数据预处理部分耗时和网络执行更新部分耗时。首先,可以分别进行耗时统计,明确性能瓶颈发生在哪个阶段,以常见的函数式训练写法为例:
import time
...
train_data = DataLoader(train_set, batch_size=128, shuffle=True, num_workers=2, drop_last=True)
...
from mindspore.common.api import _pynative_executor
# 数据迭代训练
for i in range(epochs):
train_time = time.time()
for X, y in train_data:
X, y = X.to(config_args.device), y.to(config_args.device)
_pynative_executor.sync() # 调用同步接口
date_time = time.time()
print("Data Time: ", date_time - train_time, flush=True) # 数据预处理部分耗时
res = train_step(X, y)
print("------>epoch:{}, loss:{:.6f}".format(i, res.numpy()))
_pynative_executor.sync() # 调用同步接口
train_time = time.time()
print("Train Time: ", train_time - date_time, flush=True) # 网络执行更新部分耗时
与此同时,也可以查看PyTorch的 Data Time和 Train Time。(Tips:由于算子下发时间和算子执行时间是不同的,因此在记录时间之前,调用同步接口可以保证计算操作同步执行,让计时更加准确,例如 torch是调用torch.cuda.synchronize(),而MindSpore是调用_pynative_executor.sync()接口),下面代码为PyTorch代码记录Train Time和Data Time的示例。
import time
...
train_data = DataLoader(train_set, batch_size=128, shuffle=True, num_workers=2, drop_last=True)
...
# 数据迭代训练
for i in range(epochs):
train_time = time.time()
for X, y in train_data:
X, y = X.to(config_args.device), y.to(config_args.device)
torch.cuda.synchronize() # 调用同步接口
date_time = time.time()
print("Data Time: ", date_time - train_time, flush=True) # 数据预处理部分耗时
res = model(X)
loss = loss_func(res, y)
optimizer.zero_grad()
loss.backward()
print("------>epoch:{}, loss:{:.6f}".format(i, res.numpy()))
train_time = time.time()
print("Train Time: ", train_time - date_time, flush=True) # 网络执行更新部分耗时
正常情况下,Data Time应基本可忽略不计,如果出现了Data Time和 Train Time在相同或相邻数量级的情况,可参考数据处理性能调优来降低数据加载耗时。
在Data Time忽略不计的情况下,如果Train Time有明显差距,可参考网络执行性能调优中的分析工具,进行网络执行性能优化。
数据处理性能调优
1)启用多进程数据加载
如果出现数据耗时过大的情况,请先确认是否合理配置DataLoader中的num_workers属性。num_workers表示采用多进程并行方式执行数据加载时的进程数,num_workers取值越大表示并行程度越高,但由于并行进程会开辟额外存储空间,以及进程数过多可能加剧进程间通讯耗时,不推荐配置过大,按需配置即可。推荐将num_workers配置为单次网络训练耗时与单次数据预处理耗时的差异倍数向上取整的取值,例如,网络执行单次耗时为10 s/step,数据预处理单次耗时为20 s/step,则配置num_workers=2可使得数据处理耗时基本可被完全隐藏。
2)优化数据预处理操作
如果依照上述方法预计的num_workers取值大于16,可以着重分析数据预处理耗时,性能瓶颈可能出现在预处理操作中。如自定义的collate_fn函数或自定义数据集的__getitem__函数较为耗时,针对这类场景,推荐尝试调用Numpy接口替换torch运算接口,或调用torchvision等组件自带的transforms进行预处理。
网络执行性能调优
本章节只涉及PyNative模式下分析网络API级别耗时。Graph模式为整图下沉执行,耗时主要集中于算子执行,可直接参考基于MindInsight工具分析算子性能进行分析。动态图模式下建议开启同步配置后进行性能分析,若未开启同步,由于代码的异步执行,计时工具可能不能准确反映真实执行耗时。
ms.set_context(pynative_synchronize=True)
注意:同步可能导致网络执行耗时轻微增大,性能调试结束后请关闭同步后训练网络。
开启同步配置后,可以结合打点计时分析性能瓶颈,也可以使用下列工具进行性能分析,加速分析效率:
1)基于Runtime Profiler工具快速定界性能问题
Runtime Profiler是MindSpore提供的一种性能调优工具,基于Runtime Profiler工具可分析正向执行/反向传播/优化器更新等阶段性能瓶颈,也可分析算子性能瓶颈,快速定界性能问题。
使用Runtime Profiler分三步,设置环境变量、在代码中调用接口以及查看统计结果。
步骤 1:设置环境变量
export MS_ENABLE_RUNTIME_PROFILER=1
步骤 2:在代码中调用接口
在待分析程序运行的首尾调用Profiler工具接口_framework_profiler_step_start(),以及_framework_profiler_step_end(),即可开启Profiler功能。
from mindspore._c_expression import _framework_profiler_step_start
from mindspore._c_expression import _framework_profiler_step_end
for i, data in enumerate(data_loader):
if i == 0:
_framework_profiler_step_start()
"""
training
"""
if i == 10:
_framework_profiler_step_end()
exit()
注意:收集近10次迭代的数据即可满足分析要求,迭代数越大则生成文件也越大,使用Profiler工具需保证程序正常退出,因此在示例中的待测程序的尾部调用exit()函数退出。
步骤 3:查看统计结果
当前有多种途径可以查看Runtime Profiler的统计结果,可在执行代码界面直接输出,或查看保存文件(保存的结果文件默认保存在当前执行目录,如果在代码中设置了ms.set_context(save_graphs_path='your path'),则该文件将会保存在 save_graphs_path 目录中)。文件路经下保存有反映Module-Event-Op三个层次统计信息RuntimeProfilerSummary的csv文件、Op详细性能数据RuntimeProfilerDetail的csv文件、反映TimeLine trace信息的josn文件。推荐可视化查看TimeLine trace信息;
Josn文件的命名格式为RuntimeProfilerJson+当前时间戳.json,通过浏览器使用chrome://tracing打开json文件,即可可视化观察timeline信息。

参考上图实例,可以通过可视化视图了解到网络训练流程中单步训练总耗时、正向执行耗时、反向传播耗时、优化器更新耗时、以及正反向耗时算子排序等信息,根据这些信息可以快速定界性能瓶颈:
如果整体算子执行时间较为耗时,可参考基于MindInsight工具分析算子性能进行进一步分析;
如果确定算子耗时,但无法确定性能瓶颈API接口,可参考基于cProfile工具分析主要耗时API接口进行进一步分析;
如果能够明确性能瓶颈API可参考替换接口实现等价功能进行性能优化;
如果遇到自动微分/优化器更新等框架流程有明显耗时时,请将您的遇到的问题场景通过ISSUE 反馈给我们。
2)基于cProfile工具分析主要耗时接口
cProfile 工具可用于分析Python代码执行耗时,以及正向执行中的主要耗时接口
import cProfile, pstats, io
from pstats import SortKey
pr = cProfile.Profile()
pr.enable()
...
训练代码
...
pr.disable()
s = io.StringIO()
ps = pstats.Stats(pr, stream=s).sort_stats('cumtime')
ps.print_stats()
with open('time_log.txt', 'w+') as f:
f.write(s.getvalue())
其中sort_stats配置为cumtime表示依照接口耗时(包含该接口内部调用其他接口的总耗时)排序,若配置为tottime则表示依照接口耗时(排除接口内部调用其他接口的耗时)排序。

执行后您将得到如图所示的统计文件,我们主要关注mindtorch目录下具体接口的耗时,以alexnet为例,conv2d为耗时占比最高的接口。
3)基于MindInsight工具分析算子性能
MindSpore Insight是MindSpore原生框架提供的性能分析工具,从单机和集群的角度分别提供了多项指标,用于帮助用户进行性能调优。利用该工具用户可观察到硬件侧算子的执行耗时,昇腾环境可参考性能调试(Ascend),GPU环境可参考性能调试(GPU)。
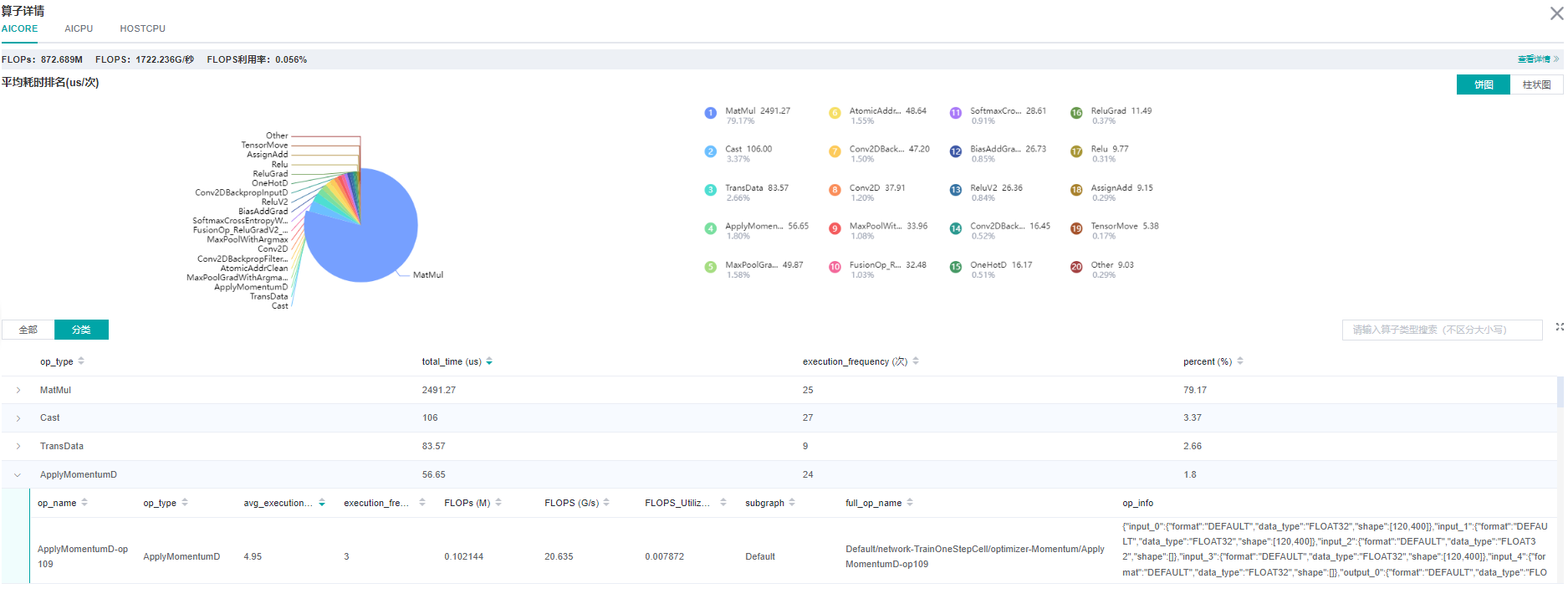
最终您将得到如图所示的算子性能分析看板,通过该看板可以明确算子总耗时/算子平均单次耗时/算子耗时占比等信息。 如果是进行性能对比,和PyTorch的 Profiler结果进行比较可进一步确定性能瓶颈是否源于算子执行,并明确各算子性能差距。 在昇腾硬件上可参考使用混合精度加速训练教程利用混合精度特性加速算子执行性能。
4)替换接口实现等价功能/反馈问题
如果经上述手段分析,能够确定某个API的执行性能为整体训练的性能瓶颈,则可以尝试通过替换或组合其他API进行等价替换,例如,mindtorch.torch.pow(x, 2)可尝试替换为mindtorch.torch.square(x);或通过自定义算子实现加速。
如果您遇到等价替换无法进一步优化性能或者优化器更新等框架流程有明显耗时的场景,请将您的遇到的问题通过ISSUE 反馈给我们。