100 changed files with 15453 additions and 10133 deletions
-
+1 -1.drone.yml
-
+2 -2CONTRIBUTING_CN.md
-
+264 -0ConstraintList.md
-
+266 -0ConstraintList_en.md
-
+197 -0Debugging_and_Tuning.md
-
+34 -72README.md
-
+96 -0README.rst
-
+66 -0README_en.md
-
+1172 -91SupportedList.md
-
+1183 -0SupportedList_en.md
-
+450 -0USER_GUIDE.md
-
BINdoc/pic/MSA_F.png
-
BINdoc/pic/MSA_SIG.png
-
BINdoc/pic/error_log.png
-
BINdoc/pic/time_log.png
-
BINdoc/pic/troubleshooter_result1.png
-
BINdoc/pic/troubleshooter_result2.png
-
BINdoc/pic/troubleshooter_result3.png
-
+0 -5ms_adapter/__init__.py
-
+0 -52ms_adapter/pytorch/__init__.py
-
+0 -28ms_adapter/pytorch/_ref/__init__.py
-
+0 -21ms_adapter/pytorch/common/__init__.py
-
+0 -68ms_adapter/pytorch/common/dtype.py
-
+0 -22ms_adapter/pytorch/cuda/__init__.py
-
+0 -16ms_adapter/pytorch/fft/fft.py
-
+0 -2238ms_adapter/pytorch/functional.py
-
+0 -7ms_adapter/pytorch/nn/__init__.py
-
+0 -1783ms_adapter/pytorch/nn/functional.py
-
+0 -371ms_adapter/pytorch/nn/modules/container.py
-
+0 -668ms_adapter/pytorch/nn/modules/conv.py
-
+0 -288ms_adapter/pytorch/nn/modules/module.py
-
+0 -454ms_adapter/pytorch/nn/modules/pooling.py
-
+0 -104ms_adapter/pytorch/nn/modules/rnn.py
-
+0 -31ms_adapter/pytorch/nn/modules/utils.py
-
+0 -377ms_adapter/pytorch/nn/parameter.py
-
+0 -1871ms_adapter/pytorch/tensor.py
-
+0 -1ms_adapter/pytorch/utils/__init__.py
-
+0 -180ms_adapter/pytorch/utils/data/_utils/collate.py
-
+0 -17ms_adapter/pytorch/utils/data/datapipes/map/__init__.py
-
+0 -181ms_adapter/torchvision/io/video_reader.py
-
+0 -66ms_adapter/torchvision/ops/_register_onnx_ops.py
-
+0 -566ms_adapter/torchvision/utils.py
-
+0 -73ms_adapter/utils.py
-
+6 -0msadapter/__init__.py
-
+11 -0msadapter/package_info.py
-
+54 -0msadapter/pytorch/__init__.py
-
+22 -0msadapter/pytorch/_ref/__init__.py
-
+48 -0msadapter/pytorch/_register/__init__.py
-
+45 -0msadapter/pytorch/_register/getitem_impl.py
-
+162 -0msadapter/pytorch/_register/register_multitype_ops.py
-
+98 -0msadapter/pytorch/_register/register_standard_method.py
-
+254 -0msadapter/pytorch/_register/register_utils.py
-
+217 -0msadapter/pytorch/_register_numpy_primitive.py
-
+0 -0msadapter/pytorch/_six.py
-
+0 -0msadapter/pytorch/_utils.py
-
+31 -0msadapter/pytorch/amp/__init__.py
-
+0 -0msadapter/pytorch/autograd/__init__.py
-
+2 -2msadapter/pytorch/autograd/function.py
-
+2 -2msadapter/pytorch/autograd/variable.py
-
+29 -0msadapter/pytorch/common/__init__.py
-
+40 -9msadapter/pytorch/common/_inner.py
-
+0 -0msadapter/pytorch/common/device.py
-
+129 -0msadapter/pytorch/common/dtype.py
-
+7 -22msadapter/pytorch/conflict_functional.py
-
+36 -0msadapter/pytorch/cuda/__init__.py
-
+2 -1msadapter/pytorch/fft/__init__.py
-
+18 -0msadapter/pytorch/fft/fft.py
-
+2993 -0msadapter/pytorch/functional.py
-
+104 -0msadapter/pytorch/hub.py
-
+31 -0msadapter/pytorch/linalg/__init__.py
-
+230 -0msadapter/pytorch/linalg/linalg.py
-
+8 -0msadapter/pytorch/nn/__init__.py
-
+2605 -0msadapter/pytorch/nn/functional.py
-
+51 -30msadapter/pytorch/nn/init.py
-
+38 -15msadapter/pytorch/nn/modules/__init__.py
-
+226 -144msadapter/pytorch/nn/modules/activation.py
-
+198 -0msadapter/pytorch/nn/modules/adaptive.py
-
+26 -97msadapter/pytorch/nn/modules/batchnorm.py
-
+23 -0msadapter/pytorch/nn/modules/channelshuffle.py
-
+1015 -0msadapter/pytorch/nn/modules/container.py
-
+601 -0msadapter/pytorch/nn/modules/conv.py
-
+1 -1msadapter/pytorch/nn/modules/distance.py
-
+25 -74msadapter/pytorch/nn/modules/dropout.py
-
+1 -1msadapter/pytorch/nn/modules/flatten.py
-
+42 -0msadapter/pytorch/nn/modules/fold.py
-
+81 -0msadapter/pytorch/nn/modules/instancenorm.py
-
+12 -13msadapter/pytorch/nn/modules/linear.py
-
+90 -17msadapter/pytorch/nn/modules/loss.py
-
+644 -0msadapter/pytorch/nn/modules/module.py
-
+8 -8msadapter/pytorch/nn/modules/normalization.py
-
+64 -27msadapter/pytorch/nn/modules/padding.py
-
+26 -0msadapter/pytorch/nn/modules/pixelshuffle.py
-
+202 -0msadapter/pytorch/nn/modules/pooling.py
-
+504 -0msadapter/pytorch/nn/modules/rnn.py
-
+8 -12msadapter/pytorch/nn/modules/sparse.py
-
+288 -0msadapter/pytorch/nn/modules/transformer.py
-
+2 -2msadapter/pytorch/nn/modules/unpooling.py
-
+4 -2msadapter/pytorch/nn/modules/upsampling.py
-
+126 -0msadapter/pytorch/nn/modules/utils.py
-
+232 -0msadapter/pytorch/nn/parameter.py
+ 1
- 1
.drone.yml
View File
| @@ -11,7 +11,7 @@ trigger: | |||
| steps: | |||
| - name: Code Inspection | |||
| image: swr.cn-north-4.myhuaweicloud.com/hanjr/msadapter:2.0.0.dev20221113_torch1.12.1 | |||
| image: swr.cn-north-4.myhuaweicloud.com/hanjr/msadapter:mindspore2.0.0_torch1.12.1 | |||
| commands: | |||
| - sh run.sh | |||
+ 2
- 2
CONTRIBUTING_CN.md
View File
| @@ -103,8 +103,8 @@ class Linear(Module): | |||
| ``` | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from ms_adapter.pytorch.nn import Module, Linear, Identity, Bilinear | |||
| from ms_adapter.pytorch import tensor | |||
| from msadapter.pytorch.nn import Module, Linear, Identity, Bilinear | |||
| from msadapter.pytorch import tensor | |||
| from mindspore import context | |||
| import numpy as np | |||
| import mindspore as ms | |||
+ 264
- 0
ConstraintList.md
View File
| @@ -0,0 +1,264 @@ | |||
| 简体中文 | [English](ConstraintList_en.md) | |||
| - [接口约束列表](#jump1) | |||
| - [Torch](#jump2) | |||
| - [Tensor](#jump3) | |||
| - [Torch.nn](#jump4) | |||
| - [nn.functional](#jump5) | |||
| - [torch.linalg](#jump6) | |||
| ## <span id="jump1">接口约束列表</span> | |||
| ### <span id="jump2">Torch</span> | |||
| | MSAdapter接口 | 约束条件 | | |||
| | --------------- | -------------- | | |||
| | torch.frombuffer | require_grad暂不支持 | | |||
| | torch.multinomial | 暂不支持传入Generator | | |||
| | torch.randint | 暂不支持传入Generator | | |||
| | torch.randperm |暂不支持传入Generator | | |||
| | torch.imag | 暂不支持图模式 | | |||
| | torch.max | 不支持other,不支持图模式 | | |||
| | torch.sum | 暂不支持图模式 | | |||
| | torch.lu | 暂不支持图模式, `get_infos=True`场景下,暂不支持错误扫描; 暂不支持`pivot=False`入参, 仅支持二维方阵输入,不支持(*,M,N)形式输入 | | |||
| | torch.lu_solve | 暂不支持图模式, 入参`left=False`暂不支持,入参`LU`仅支持二维方阵输入,不支持三维输入 | | |||
| | torch.lstsq | 暂时不支持返回第二个参数QR,暂不支持图模式,反向梯度暂不支持 | | |||
| | torch.svd | Ascend上暂不支持图模式,Ascend上反向梯度暂不支持 | | |||
| | torch.nextafter | CPU上暂不支持float32输入 | | |||
| | torch.matrix_power | GPU上暂不支持参数`n`小于0 | | |||
| | torch.i0 | Ascend上暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.index_add | 暂不支持二维以上的`input`或`dim`>=1,暂不支持图模式 | | |||
| | torch.index_copy | 暂不支持二维以上的`input`或`dim`>=1,暂不支持图模式 | | |||
| | torch.scatter_reduce | 暂不支持`reduce`="mean" | | |||
| | torch.histogramdd | 暂不支持float64类型输入 | | |||
| | torch.asarray | 暂不支持输入`device`、 `copy`和`requires_grad`参数配置功能 | | |||
| | torch.complex | 暂不支持float16类型输入 | | |||
| | torch.fmin | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.kron | 暂不支持入参是不同复数类型 | | |||
| | torch.sort | 暂不支持`stable`入参 | | |||
| | torch.float_power | 不支持复数输入 | | |||
| | torch.add |暂不支持当两个输入都为bool类型时, 返回bool类型 | | |||
| | torch.polygamma | 当入参`n`为0时,结果可能不正确 | | |||
| | torch.matmul | GPU上暂不支持int类型输入 | | |||
| | torch.geqrf | 暂不支持大于2维的输入 | | |||
| | torch.repeat_interleave | 暂不支持`output_size`入参 | | |||
| | torch.index_reduce | 暂不支持`reduce`="mean" | | |||
| | torch.view_as_complex | 输出张量暂时以数据拷贝方式返回,无法提供视图模式 | | |||
| | torch.pad | 当`padding_mode`为'reflect'时,不支持5维的输入 | | |||
| | torch.corrcoef | 暂不支持复数类型入参 | | |||
| | torch.symeig | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.fmax | GPU和Ascend上暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.fft | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.rfft | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.norm | 1.当`p`为0/1/-1/-2时,矩阵范数不支持;2.不支持`p`为inf/-inf/0/1/-1/2/-2之外的int/float类型。| | |||
| | torch.poisson | Ascend上暂不支持反向梯度 | | |||
| | torch.xlogy | Ascend 上当前只支持float16 和float32输入 | | |||
| | torch.digamma | Ascend上仅支持float16和float32类型入参 | | |||
| | torch.lgamma | Ascend上仅支持float16和float32类型入参 | | |||
| ### <span id="jump3">Tensor</span> | |||
| | MSAdapter接口 | 约束条件 | | |||
| | --------------- | -------------- | | |||
| | Tensor.bool | 不支持memory_format参数 | | |||
| | Tensor.expand | 类型限制,只支持Tensor[Float16], Tensor[Float32], Tensor[Int32], Tensor[Int8], Tensor[UInt8] | | |||
| | Tensor.float | 不支持memory_format | | |||
| | Tensor.scatter | 不支持reduce='mutiply', Ascend不支持reduce='add', 不支持indices.shape != src.shape | | |||
| | Tensor.std | 不支持复数和float64输入 | | |||
| | Tensor.xlogy | Ascend 上当前只支持float16 和float32输入 | | |||
| | Tensor.abs_ | 暂不支持图模式 | | |||
| | Tensor.absolute_ | 暂不支持图模式 | | |||
| | Tensor.acos_ | 暂不支持图模式 | | |||
| | Tensor.arccos_ | 暂不支持图模式 | | |||
| | Tensor.addr_ | 暂不支持图模式 | | |||
| | Tensor.add_ | 暂不支持图模式 | | |||
| | Tensor.addbmm_ | 暂不支持图模式 | | |||
| | Tensor.addcdiv_ | 暂不支持图模式 | | |||
| | Tensor.addcmul_ | 暂不支持图模式 | | |||
| | Tensor.addmm_ | 暂不支持图模式 | | |||
| | Tensor.addmv_ | 暂不支持图模式 | | |||
| | Tensor.addr_ | 暂不支持图模式 | | |||
| | Tensor.asin_ | 暂不支持图模式 | | |||
| | Tensor.arcsin_ | 暂不支持图模式 | | |||
| | Tensor.atan_ | 暂不支持图模式 | | |||
| | Tensor.arctan_ | 暂不支持图模式 | | |||
| | Tensor.atan2_ | 暂不支持图模式 | | |||
| | Tensor.arctan2_ | 暂不支持图模式 | | |||
| | Tensor.baddbmm_ | 暂不支持图模式 | | |||
| | Tensor.bitwise_not_ | 暂不支持图模式 | | |||
| | Tensor.bitwise_and_ | 暂不支持图模式 | | |||
| | Tensor.bitwise_or_ | 暂不支持图模式 | | |||
| | Tensor.bitwise_xor_ | 暂不支持图模式 | | |||
| | Tensor.clamp_ | 暂不支持图模式 | | |||
| | Tensor.clip_ | 暂不支持图模式 | | |||
| | Tensor.copy_ | 暂不支持图模式 | | |||
| | Tensor.copysign_ | 暂不支持图模式 | | |||
| | Tensor.acosh_ | 暂不支持图模式 | | |||
| | Tensor.arccosh_ | 暂不支持图模式 | | |||
| | Tensor.cumprod_ | 暂不支持图模式 | | |||
| | Tensor.div_ | 暂不支持图模式 | | |||
| | Tensor.divide_ | 暂不支持图模式 | | |||
| | Tensor.eq_ | 暂不支持图模式 | | |||
| | Tensor.expm1_ | 暂不支持图模式 | | |||
| | Tensor.fix_ | 暂不支持图模式 | | |||
| | Tensor.fill_ | 暂不支持图模式 | | |||
| | Tensor.float_power_ | 暂不支持图模式 | | |||
| | Tensor.floor_ | 暂不支持图模式 | | |||
| | Tensor.fmod_ | 暂不支持图模式 | | |||
| | Tensor.ge_ | 暂不支持图模式 | | |||
| | Tensor.greater_equal_ | 暂不支持图模式 | | |||
| | Tensor.gt_ | 暂不支持图模式 | | |||
| | Tensor.greater_ | 暂不支持图模式 | | |||
| | Tensor.hypot_ | 暂不支持图模式 | | |||
| | Tensor.le_ | 暂不支持图模式 | | |||
| | Tensor.less_equal_ | 暂不支持图模式 | | |||
| | Tensor.lgamma_ | 暂不支持图模式 | | |||
| | Tensor.logical_xor_ | 暂不支持图模式 | | |||
| | Tensor.lt_ | 暂不支持图模式 | | |||
| | Tensor.less_ | 暂不支持图模式 | | |||
| | Tensor.lu | 暂不支持图模式,入参`get_infos=True`时暂不支持扫描错误信息, 暂不支持`pivot=False`,仅支持二维方阵输入,不支持(*,M,N)形式输入 | | |||
| | Tensor.lu_solve | 暂不支持图模式,入参`left=False`暂不支持,入参`LU`仅支持二维方阵输入,不支持三维输入 | | |||
| | Tensor.lstsq | 暂时不支持返回第二个参数QR, 暂不支持图模式,反向梯度暂不支持 | | |||
| | Tensor.mul_ | 暂不支持图模式 | | |||
| | Tensor.multiply_ | 暂不支持图模式 | | |||
| | Tensor.mvlgamma_ | 暂不支持图模式 | | |||
| | Tensor.ne_ | 暂不支持图模式 | | |||
| | Tensor.not_equal_ | 暂不支持图模式 | | |||
| | Tensor.neg_ | 暂不支持图模式 | | |||
| | Tensor.negative_ | 暂不支持图模式 | | |||
| | Tensor.pow_ | 暂不支持图模式 | | |||
| | Tensor.reciprocal_ | 暂不支持图模式 | | |||
| | Tensor.renorm_ | 暂不支持图模式 | | |||
| | Tensor.resize_ | 暂不支持图模式 | | |||
| | Tensor.round_ | 暂不支持图模式 | | |||
| | Tensor.sigmoid_ | 暂不支持图模式 | | |||
| | Tensor.sign_ | 暂不支持图模式 | | |||
| | Tensor.sin_ | 暂不支持图模式 | | |||
| | Tensor.sinc_ | 暂不支持图模式 | | |||
| | Tensor.sinh_ | 暂不支持图模式 | | |||
| | Tensor.asinh_ | 暂不支持图模式 | | |||
| | Tensor.square_ | 暂不支持图模式 | | |||
| | Tensor.sqrt_ | 暂不支持图模式 | | |||
| | Tensor.squeeze_ | 暂不支持图模式 | | |||
| | Tensor.sub_ | 暂不支持图模式 | | |||
| | Tensor.tan_ | 暂不支持图模式 | | |||
| | Tensor.tanh_ | 暂不支持图模式 | | |||
| | Tensor.atanh_ | 暂不支持图模式 | | |||
| | Tensor.arctanh_ | 暂不支持图模式 | | |||
| | Tensor.transpose_ | 暂不支持图模式 | | |||
| | Tensor.trunc_ | 暂不支持图模式 | | |||
| | Tensor.unsqueeze_ | 暂不支持图模式 | | |||
| | Tensor.zero_ | 暂不支持图模式 | | |||
| | Tensor.svd | Ascend上暂不支持图模式,Ascend上反向梯度暂不支持 | | |||
| | Tensor.nextafter | CPU上暂不支持float32输入 | | |||
| | Tensor.matrix_power | GPU上暂不支持参数`n`小于0 | | |||
| | Tensor.i0 | Ascend上暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.index_add | 暂不支持二维以上的`input`或`dim`为1 | | |||
| | Tensor.nextafter_ | CPU上暂不支持float32输入 | | |||
| | Tensor.fmin | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.imag | 暂不支持图模式 | | |||
| | Tensor.scatter_reduce | 暂不支持`reduce`="mean" | | |||
| | Tensor.scatter_reduce_ | 暂不支持`reduce`="mean"和图模式 | | |||
| | Tensor.neg | 暂不支持uint32, uint64输入 | | |||
| | Tensor.add | 暂不支持当两个输入都为bool类型时, 返回bool类型 | | |||
| | Tensor.polygamma | 当入参`n`为0时,结果可能不正确 | | |||
| | Tensor.matmul | GPU上暂不支持int类型输入 | | |||
| | Tensor.geqrf | 暂不支持大于2维的输入 | | |||
| | Tensor.repeat_interleave | 暂不支持`output_size`入参 | | |||
| | Tensor.index_reduce | 暂不支持`reduce`="mean" | | |||
| | Tensor.index_reduce_ | 暂不支持`reduce`="mean"和图模式 | | |||
| | Tensor.masked_scatter | 暂不支持`input`广播到`mask`和GPU后端 | | |||
| | Tensor.index_put | Ascend上暂不支持`accumulate`=False | | |||
| | Tensor.index_put_ | Ascend上暂不支持`accumulate`=False,暂不支持图模式 | | |||
| | Tensor.corrcoef | 暂不支持复数类型入参 | | |||
| | Tensor.exponential_ | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.geometric_ | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.log_normal_ | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.symeig | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.fmax | GPU和Ascend上暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.norm | 1.当`p`为0/1/-1/-2时,矩阵范数不支持;2.不支持`p`为inf/-inf/0/1/-1/2/-2之外的int/float类型。| | |||
| | Tensor.digamma | Ascend上仅支持float16和float32类型入参 | | |||
| | Tensor.lgamma | Ascend上仅支持float16和float32类型入参 | | |||
| | Tensor.arcsinh_ | 暂不支持图模式 | | |||
| ### <span id="jump4">Torch.nn</span> | |||
| | MSAdapter接口 | 约束条件 | | |||
| | --------------- | -------------- | | |||
| | nn.LPPool1d | Ascend上不支持float64 | | |||
| | nn.LPPool2d | Ascend上不支持float64 | | |||
| | nn.ELU | Alpha仅支持1.0 | | |||
| | nn.Hardshrink | 不支持float64 | | |||
| | nn.Hardtanh | 不支持float64 | | |||
| | nn.Hardswish | 不支持float64 | | |||
| | nn.LeakyReLU | 不支持float64 | | |||
| | nn.PReLU | 不支持float64 | | |||
| | nn.ReLU6 | 不支持float64 | | |||
| | nn.RReLU | inplace不支持图模式 | | |||
| | nn.SELU | inplace不支持图模式 | | |||
| | nn.CELU | inplace不支持图模式 | | |||
| | nn.Mish | inplace不支持图模式 | | |||
| | nn.Threshold | inplace不支持图模式 | | |||
| | nn.Softshrink | 不支持float64 | | |||
| | nn.LogSoftmax | 不支持float64,不支持8维及以上 | | |||
| | nn.Linear | device, dtype参数不支持 | | |||
| | nn.UpsamplingNearest2d | 不支持size为none | | |||
| | nn.Conv1d | 1.`padding_mode` 只支持'zeros';2.Ascend上,`groups`只支持1或者与`in_channels`相等 | | |||
| | nn.Conv2d | 1.`padding_mode` 只支持'zeros'; 2.Ascend上,`groups`只支持1或者与`in_channels`相等 | | |||
| | nn.Conv3d | 1.不支持复数;2.`padding_mode`只支持'zeros';3.Ascend上`groups`, `dialtion`参数只支持为1 | | |||
| | nn.ConvTranspose1d | 1.`output_padding`,`output_size`不支持; 2.Ascend上`groups`只支持1或者与`in_channels`相等 | | |||
| | nn.ConvTranspose2d | 1.`output_padding`,`output_size`不支持; 2.Ascend上`groups`只支持1或者与`in_channels`相等 | | |||
| | nn.AdaptiveLogSoftmaxWithLoss | 不支持图模式 | | |||
| | nn.LSTM | 当前`proj_size`不支持 | | |||
| | nn.ReflectionPad1d |`padding`参数不支持负数取值 | | |||
| | nn.ReflectionPad2d | `padding`参数不支持负数取值 | | |||
| | nn.ReflectionPad3d | `padding`参数不支持负数取值 | | |||
| | nn.Transformer | 不支持等号赋值关键字参数。不支持空tensor输入 | | |||
| | nn.TransformerEncoder | 不支持等号赋值关键字参数。不支持空tensor输入 | | |||
| | nn.TransformerDecoder | 不支持等号赋值关键字参数。不支持空tensor输入 | | |||
| | nn.TransformerEncoderLayer | 不支持等号赋值关键字参数。不支持空tensor输入 | | |||
| | nn.TransformerDecoderLayer | 不支持等号赋值关键字参数。不支持空tensor输入 | | |||
| | nn.AdaptiveMaxPool1d | Ascend上不支持`return_indices` | | |||
| | nn.AdaptiveMaxPool2d | Ascend上不支持`return_indices` | | |||
| | nn.Embedding | 1.`scale_grad_by_freq`, `sparse`不支持; 2.`norm_type`只能为2 | | |||
| ### <span id="jump5">nn.functional</span> | |||
| | MSAdapter接口 | 约束条件 | | |||
| | --------------- | -------------- | | |||
| | functional.lp_pool1d | Ascend上不支持float64 | | |||
| | functional.lp_pool2d | Ascend上不支持float64 | | |||
| | functional.prelu | 不支持float64 | | |||
| | functional.rrelu | 1.inplace不支持图模式; 2.`training`入参不支持 | | |||
| | functional.softshrink | 不支持float64 | | |||
| | functional.log_softmax | 不支持float64 | | |||
| | functional.dropout1d | inplace不支持图模式 | | |||
| | functional.dropout2d | inplace不支持图模式 | | |||
| | functional.dropout3d | inplace不支持图模式 | | |||
| | functional.conv3d | Ascend上`groups`, `dialtion`参数只支持1 | | |||
| | functional.upsample_bilinear | 输入张量必须是4维 | | |||
| | functional.interpolate | `recompute_scale_factor` 及 `antialias` 入参不支持。 只支持以下三种模式, 其中,'nearest'只支持4D或5D输入, 'bilinear'只支持4D输入, 'linear'只支持3D输入。| | |||
| | functional.conv1d | Ascend上,`groups`只支持1或者与`input`的通道数相等 | | |||
| | functional.conv2d | Ascend上,`groups`只支持1或者与`input`的通道数相等 | | |||
| | functional.conv_transpose1d | 1.`output_padding`暂不支持; 2.Ascend上`groups`只支持1或者与`input`的通道数相等 | | |||
| | functional.conv_transpose2d | 1.`output_padding`暂不支持; 2.Ascend上`groups`只支持1或者与`input`的通道数相等 | | |||
| | functional.adaptive_max_pool1d | Ascend上不支持`return_indices` | | |||
| | functional.adaptive_max_pool2d | Ascend上不支持`return_indices` | | |||
| | functional.instance_norm | 图模式下,训练模式时, 暂不支持`running_mean`和`running_var` | | |||
| | functional.batch_norm | 图模式下,训练模式时, 暂不支持`running_mean`及`running_var` | | |||
| | functional.embedding | 1.`scale_grad_by_freq`, `sparse`不支持; 2.`norm_type`只能为2 | | |||
| ### <span id="jump6">torch.linalg</span> | |||
| | MSAdapter接口 | 约束条件 | | |||
| | --------------- | -------------- | | |||
| | lu | 暂不支持图模式,暂不支持入参`pivot=False`, 仅支持二维方阵输入,不支持(*,M,N)形式输入 | | |||
| | lu_solve | 暂不支持图模式,入参`left=False`不支持,入参`LU`不支持三维输入 | | |||
| | lu_factor | 暂不支持图模式,仅支持二维方阵输入,不支持(*,M,N)形式输入 | | |||
| | lu_factor_ex | 暂不支持图模式,入参`get_infos=True`时暂不支持扫描错误信息, 暂不支持`pivot=False`,仅支持二维方阵输入,不支持(*,M,N)形式输入 | | |||
| | lstsq| 暂不支持图模式,反向梯度暂不支持 | | |||
| | eigvals | 暂不支持图模式,反向梯度暂不支持 | | |||
| | svd | `driver`参数只支持None, Ascend上不支持反向梯度, Ascend上暂不支持图模式 | | |||
| | svdvals | `driver`参数只支持None,Ascend上不支持反向梯度, Ascend上暂不支持图模式 | | |||
| | norm | 暂不支持复数输入, `ord`参数暂不支持浮点型输入, Ascend上暂不支持ord为nuc模式、float(`inf`)模式和整形数输入 | | |||
| | vector_norm | 暂不支持复数输入, `ord`参数暂不支持浮点型输入 | | |||
| | matrix_power | GPU上暂不支持参数`n`小于0 | | |||
| | eigvalsh | 反向梯度暂不支持 | | |||
| | eigh | 暂不支持图模式,反向梯度暂不支持 | | |||
| | solve | 反向梯度暂不支持 | | |||
+ 266
- 0
ConstraintList_en.md
View File
| @@ -0,0 +1,266 @@ | |||
| English | [简体中文](ConstraintList.md) | |||
| - [API Constraints List](#jump1) | |||
| - [Torch](#jump2) | |||
| - [Tensor](#jump3) | |||
| - [Torch.nn](#jump4) | |||
| - [nn.functional](#jump5) | |||
| - [torch.linalg](#jump6) | |||
| ## <span id="jump1">API Constraints List</span> | |||
| ### <span id="jump2">Torch</span> | |||
| | MSAdapter APIs | Constraint conditions | | |||
| | --------------- | -------------- | | |||
| | torch.frombuffer | Currently not support require_grad | | |||
| | torch.multinomial | Currently not support input Generator | | |||
| | torch.randint | Currently not support input Generator | | |||
| | torch.randperm | Currently not support input Generator | | |||
| | torch.imag | Currently not support on GRAPH mode | | |||
| | torch.max | Currently not support other, Not support on GRAPH mode | | |||
| | torch.sum | Currently not support on GRAPH mode | | |||
| | torch.lu | Currently not support GRAPH mode, input `get_infos=True` currently cannot scan the error, mindspore not support `pivot=False`,, only support 2-D square matrix as input, not support (*,M,N) shape input | | |||
| | torch.lu_solve | Currently not support GRAPH mode, input `left=False` not support, only support 2-D square matrix as input, not support 3-D input | | |||
| | torch.lstsq | Currently not support return the second result QR, not support on GRAPH mode, not support gradient computation | | |||
| | torch.svd | Currently not support GRAPH mode on Ascend, not support gradient computation on Ascend | | |||
| | torch.nextafter | Currently not support float32 on CPU | | |||
| | torch.matrix_power | Currently not support `n` < 0 on GPU | | |||
| | torch.i0 | Currently not support gradient computation on Ascend, currently not support GRAPH mode on Ascend | | |||
| | torch.index_add | Not support `input` of more than 2-D or `dim` >= 1. Not suppor GRAPH mode | | |||
| | torch.index_copy | Not support `input` of more than 2-D or `dim` >= 1. Not suppor GRAPH mode | | |||
| | torch.scatter_reduce | Currently not support `reduce`="mean" | | |||
| | torch.histogramdd | Currently not support float64 input | | |||
| | torch.asarray | Currently not support input `device`, `copy`, `requires_grad` as configuration | | |||
| | torch.complex | Currently not support float16 input | | |||
| | torch.fmin | Currently not support gradient computation, not support GRAPH mode | | |||
| | torch.kron | Currently not support different complex types for inputs | | |||
| | torch.sort | Currently not support `stable` | | |||
| | torch.float_power | Currently not support complex input | | |||
| | torch.add | Currently not support both bool type input and return bool output | | |||
| | torch.polygamma | When `n` is zero, the result may be wrong | | |||
| | torch.matmul | Currently not support int type input on GPU | | |||
| | torch.geqrf | Currently not support input ndim > 2 | | |||
| | torch.repeat_interleave | Currently not support `output_size` | | |||
| | torch.index_reduce | Currently not support `reduce`="mean" | | |||
| | torch.view_as_complex | Currently the output tensor is provided by data copying instead of a view of shared memory | | |||
| | torch.pad | when `padding_mode` is 'reflect', not support 5D input | | |||
| | torch.corrcoef | Currently not support complex inputs | | |||
| | torch.symeig | Currently not support gradient computation, not support GRAPH mode | | |||
| | torch.fmax | Currently not support gradient computation on GPU and Ascend, not support GRAPH mode on GPU and Ascend | | |||
| | torch.fft | Currently not support gradient computation, not support GRAPH mode | | |||
| | torch.rfft | Currently not support gradient computation, not support GRAPH mode | | |||
| | torch.poisson| Currently not support gradient computation on Ascend | | |||
| | torch.norm | 1.when `p` in 0/1/-1/-2,matrix-norm not support;2.not support `p` in int/float type beside inf/-inf/0/1/-1/2/-2 | | |||
| | torch.xlogy | Currently only support float16 and float32 on Ascend | | |||
| | torch.digamma | Currently only support float16 and float32 on Ascend | | |||
| | torch.lgamma | Currently only support float16 and float32 on Ascend | | |||
| ### <span id="jump3">Tensor</span> | |||
| | MSAdapter APIs | Constraint conditions | | |||
| | --------------- | -------------- | | |||
| | Tensor.bool | Not support parameter memory_format| | |||
| | Tensor.expand | Type is constrained, only support Tensor[Float16], Tensor[Float32], Tensor[Int32], Tensor[Int8], Tensor[UInt8] | | |||
| | Tensor.float | Currently not support memory_format | | |||
| | Tensor.scatter | Currently not support reduce='mutiply', AscendNot support reduce='add', Not support indices.shape != src.shape | | |||
| | Tensor.std | Currently not support complex number and float64 input | | |||
| | Tensor.xlogy | Currently only support float16 and float32 on Ascend | | |||
| | Tensor.abs_ | Currently not support on GRAPH mode | | |||
| | Tensor.absolute_ | Currently not support on GRAPH mode | | |||
| | Tensor.acos_ | Currently not support on GRAPH mode | | |||
| | Tensor.arccos_ | Currently not support on GRAPH mode | | |||
| | Tensor.addr_ | Currently not support on GRAPH mode | | |||
| | Tensor.add_ | Currently not support on GRAPH mode | | |||
| | Tensor.addbmm_ | Currently not support on GRAPH mode | | |||
| | Tensor.addcdiv_ | Currently not support on GRAPH mode | | |||
| | Tensor.addcmul_ | Currently not support on GRAPH mode | | |||
| | Tensor.addmm_ | Currently not support on GRAPH mode | | |||
| | Tensor.addmv_ | Currently not support on GRAPH mode | | |||
| | Tensor.addr_ | Currently not support on GRAPH mode | | |||
| | Tensor.asin_ | Currently not support on GRAPH mode | | |||
| | Tensor.arcsin_ | Currently not support on GRAPH mode | | |||
| | Tensor.atan_ | Currently not support on GRAPH mode | | |||
| | Tensor.arctan_ | Currently not support on GRAPH mode | | |||
| | Tensor.atan2_ | Currently not support on GRAPH mode | | |||
| | Tensor.arctan2_ | Currently not support on GRAPH mode | | |||
| | Tensor.baddbmm_ | Currently not support on GRAPH mode | | |||
| | Tensor.bitwise_not_ | Currently not support on GRAPH mode | | |||
| | Tensor.bitwise_and_ | Currently not support on GRAPH mode | | |||
| | Tensor.bitwise_or_ | Currently not support on GRAPH mode | | |||
| | Tensor.bitwise_xor_ | Currently not support on GRAPH mode | | |||
| | Tensor.clamp_ | Currently not support on GRAPH mode | | |||
| | Tensor.clip_ | Currently not support on GRAPH mode | | |||
| | Tensor.copy_ | Currently not support on GRAPH mode | | |||
| | Tensor.copysign_ | Currently not support on GRAPH mode | | |||
| | Tensor.acosh_ | Currently not support on GRAPH mode | | |||
| | Tensor.arccosh_ | Currently not support on GRAPH mode | | |||
| | Tensor.cumprod_ | Currently not support on GRAPH mode | | |||
| | Tensor.div_ | Currently not support on GRAPH mode | | |||
| | Tensor.divide_ | Currently not support on GRAPH mode | | |||
| | Tensor.eq_ | Currently not support on GRAPH mode | | |||
| | Tensor.expm1_ | Currently not support on GRAPH mode | | |||
| | Tensor.fix_ | Currently not support on GRAPH mode | | |||
| | Tensor.fill_ | Currently not support on GRAPH mode | | |||
| | Tensor.float_power_ | Currently not support on GRAPH mode | | |||
| | Tensor.floor_ | Currently not support on GRAPH mode | | |||
| | Tensor.fmod_ | Currently not support on GRAPH mode | | |||
| | Tensor.ge_ | Currently not support on GRAPH mode | | |||
| | Tensor.greater_equal_ | Currently not support on GRAPH mode | | |||
| | Tensor.gt_ | Currently not support on GRAPH mode | | |||
| | Tensor.greater_ | Currently not support on GRAPH mode | | |||
| | Tensor.hypot_ | Currently not support on GRAPH mode | | |||
| | Tensor.le_ | Currently not support on GRAPH mode | | |||
| | Tensor.less_equal_ | Currently not support on GRAPH mode | | |||
| | Tensor.lgamma_ | Currently not support on GRAPH mode | | |||
| | Tensor.logical_xor_ | Currently not support on GRAPH mode | | |||
| | Tensor.lt_ | Currently not support on GRAPH mode | | |||
| | Tensor.less_ | Currently not support on GRAPH mode | | |||
| | Tensor.lu | Currently not support GRAPH mode, input `get_infos=True` currently cannot scan the error, not support `pivot=False`, only support 2-D square matrix as input, not support (*,M,N) shape input | | |||
| | Tensor.lu_solve | Currently not support GRAPH mode, input `left=False` not support, only support 2-D square matrix as input, not support 3-D input | | |||
| | Tensor.lstsq | Not support return the second result QR, not support on GRAPH mode, not support gradient computation | | |||
| | Tensor.mul_ | Currently not support on GRAPH mode | | |||
| | Tensor.multiply_ | Currently not support on GRAPH mode | | |||
| | Tensor.mvlgamma_ | Currently not support on GRAPH mode | | |||
| | Tensor.ne_ | Currently not support on GRAPH mode | | |||
| | Tensor.not_equal_ | Currently not support on GRAPH mode | | |||
| | Tensor.neg_ | Currently not support on GRAPH mode | | |||
| | Tensor.negative_ | Currently not support on GRAPH mode | | |||
| | Tensor.pow_ | Currently not support on GRAPH mode | | |||
| | Tensor.reciprocal_ | Currently not support on GRAPH mode | | |||
| | Tensor.renorm_ | Currently not support on GRAPH mode | | |||
| | Tensor.resize_ | Currently not support on GRAPH mode | | |||
| | Tensor.round_ | Currently not support on GRAPH mode | | |||
| | Tensor.sigmoid_ | Currently not support on GRAPH mode | | |||
| | Tensor.sign_ | Currently not support on GRAPH mode | | |||
| | Tensor.sin_ | Currently not support on GRAPH mode | | |||
| | Tensor.sinc_ | Currently not support on GRAPH mode | | |||
| | Tensor.sinh_ | Currently not support on GRAPH mode | | |||
| | Tensor.asinh_ | Currently not support on GRAPH mode | | |||
| | Tensor.square_ | Currently not support on GRAPH mode | | |||
| | Tensor.sqrt_ | Currently not support on GRAPH mode | | |||
| | Tensor.squeeze_ | Currently not support on GRAPH mode | | |||
| | Tensor.sub_ | Currently not support on GRAPH mode | | |||
| | Tensor.tan_ | Currently not support on GRAPH mode | | |||
| | Tensor.tanh_ | Currently not support on GRAPH mode | | |||
| | Tensor.atanh_ | Currently not support on GRAPH mode | | |||
| | Tensor.arctanh_ | Currently not support on GRAPH mode | | |||
| | Tensor.transpose_ | Currently not support on GRAPH mode | | |||
| | Tensor.trunc_ | Currently not support on GRAPH mode | | |||
| | Tensor.unsqueeze_ | Currently not support on GRAPH mode | | |||
| | Tensor.zero_ | Currently not support on GRAPH mode | | |||
| | Tensor.svd | Currently not support GRAPH mode on Ascend, not support gradient computation on Ascend | | |||
| | Tensor.nextafter | Currently not support float32 on CPU | | |||
| | Tensor.matrix_power | Currently not support `n` < 0 on GPU | | |||
| | Tensor.i0 | Currently not support gradient computation on Ascend, currently not support GRAPH mode on Ascend | | |||
| | Tensor.index_add | Not support `input` of more than 2-D or `dim` >= 1 | | |||
| | Tensor.nextafter_ | Currently not support float32 on CPU | | |||
| | Tensor.fmin | Currently not support gradient computation, not support GRAPH mode | | |||
| | Tensor.imag | Currently not support on GRAPH mode | | |||
| | Tensor.scatter_reduce | Currently not support `reduce`="mean" | | |||
| | Tensor.scatter_reduce_ | Currently not support `reduce`="mean" and GRAPH mode | | |||
| | Tensor.neg | Currently not support uint32, uint64 | | |||
| | Tensor.add | Currently not support both bool type input and return bool output | | |||
| | Tensor.polygamma | When `n` is zero, the result may be wrong | | |||
| | Tensor.matmul | Currently not support int type input on GPU | | |||
| | Tensor.geqrf | Currently not support input ndim > 2 | | |||
| | Tensor.repeat_interleave | Currently not support `output_size` | | |||
| | Tensor.index_reduce | Currently not support `reduce`="mean" | | |||
| | Tensor.index_reduce_ | Currently not support `reduce`="mean" and GRAPH mode | | |||
| | Tensor.masked_scatter | Currently not support on GPU, or `input` to be broadcasted to the shape of `mask` | | |||
| | Tensor.index_put | Currently not support `accumulate`=False on Ascend | | |||
| | Tensor.index_put_ | Currently not support `accumulate`=False on Ascend or on GRAPH mode | | |||
| | Tensor.corrcoef | Currently not support complex inputs | | |||
| | Tensor.exponential_ | Currently not support gradient computation, not support GRAPH mode | | |||
| | Tensor.geometric_ | Currently not support gradient computation, not support GRAPH mode | | |||
| | Tensor.log_normal_ | Currently not support gradient computation, not support GRAPH mode | | |||
| | Tensor.symeig | Currently not support gradient computation, not support GRAPH mode | | |||
| | Tensor.fmax | Currently not support gradient computation on GPU and Ascend, not support GRAPH mode on GPU and Ascend | | |||
| | Tensor.norm | 1.when `p` in 0/1/-1/-2,matrix-norm not support;2.not support `p` in int/float type beside inf/-inf/0/1/-1/2/-2 | | |||
| | Tensor.digamma | Currently only support float16 and float32 on Ascend | | |||
| | Tensor.lgamma | Currently only support float16 and float32 on Ascend | | |||
| | Tensor.arcsinh_ | Currently not support on GRAPH mode | | |||
| ### <span id="jump4">Torch.nn</span> | |||
| | MSAdapter APIs | Constraint conditions | | |||
| | --------------- | -------------- | | |||
| | nn.LPPool1d | Not support float64 on Ascend | | |||
| | nn.LPPool2d | Not support float64 on Ascend | | |||
| | nn.ELU | only support Alpha = 1.0 | | |||
| | nn.Hardshrink | Not support float64 | | |||
| | nn.Hardtanh | Not support float64 | | |||
| | nn.Hardswish | Not support float64 | | |||
| | nn.LeakyReLU | Not support float64 | | |||
| | nn.PReLU | Not support float64 | | |||
| | nn.ReLU6 | Not support float64 | | |||
| | nn.RReLU | inplace not support GRAPH mode | | |||
| | nn.SELU | inplace not support GRAPH mode | | |||
| | nn.CELU | inplace not support GRAPH mode | | |||
| | nn.Mish | inplace not support GRAPH mode | | |||
| | nn.Threshold | inplace not support GRAPH mode | | |||
| | nn.Softshrink | Not support float64 | | |||
| | nn.LogSoftmax | Not support float64, Not support 8D and higher dimension | | |||
| | nn.Linear | device, dtype parameter Not support | | |||
| | nn.UpsamplingNearest2d | Not support size=None | | |||
| | nn.Conv1d | 1.`padding_mode` only support 'zeros'; 2.On Ascend, `groups` can only support 1 or equal to `in_channels` | | |||
| | nn.Conv2d | 1.`padding_mode` only support 'zeros'; 2.On Ascend, `groups` can only support 1 or equal to `in_channels` | | |||
| | nn.Conv3d | 1.Not support complex number; 2. `padding_mode` only support 'zeros'; 3.`groups`,`dialtion` only support 1 on Ascend | | |||
| | nn.ConvTranspose1d | 1.`output_padding`,`output_size` not support; 2.On Ascend, `groups` can only support 1 or equal to `in_channels` | | |||
| | nn.ConvTranspose2d | 1.`output_padding`,`output_size` not support. 2.On Ascend, `groups` can only support 1 or equal to `in_channels` | | |||
| | nn.AdaptiveLogSoftmaxWithLoss | Not support GRAPH mode | | |||
| | nn.LSTM | Currently `proj_size` not support | | |||
| | nn.ReflectionPad1d | `padding` not support negative values | | |||
| | nn.ReflectionPad2d | `padding` not support negative values | | |||
| | nn.ReflectionPad3d | `padding` not support negative values | | |||
| | nn.Transformer | Not support assigning values to keyword arguments with `=` operator. Not support input tensors of shape 0 | | |||
| | nn.TransformerEncoder | Not support assigning values to keyword arguments with `=` operator. Not support input tensors of shape 0 | | |||
| | nn.TransformerDecoder | Not support assigning values to keyword arguments with `=` operator. Not support input tensors of shape 0 | | |||
| | nn.TransformerEncoderLayer | Not support assigning values to keyword arguments with `=` operator. Not support input tensors of shape 0 | | |||
| | nn.TransformerDecoderLayer | Not support assigning values to keyword arguments with `=` operator. Not support input tensors of shape 0 | | |||
| | nn.AdaptiveMaxPool1d | `return_indices` not support on Ascend | | |||
| | nn.AdaptiveMaxPool2d | `return_indices` not support on Ascend | | |||
| | nn.Embedding | 1. `scale_grad_by_freq`, `sparse` is not supported; 2. `norm_type` can only be 2 | | |||
| ### <span id="jump5">nn.functional</span> | |||
| | MSAdapter APIs | Constraint conditions | | |||
| | --------------- | -------------- | | |||
| | functional.lp_pool1d | Not support float64 on Ascend | | |||
| | functional.lp_pool2d | Not support float64 on Ascend | | |||
| | functional.prelu | Not support float64 | | |||
| | functional.rrelu | 1.inplace not support GRAPH mode; 2.`training` not support | | |||
| | functional.softshrink | Not support float64 | | |||
| | functional.log_softmax | Not support float64 | | |||
| | functional.dropout1d | inplace not support GRAPH mode | | |||
| | functional.dropout2d | inplace not support GRAPH mode | | |||
| | functional.dropout3d | inplace not support GRAPH mode | | |||
| | functional.conv3d | `groups`,`dialtion` only support 1 on Ascend | | |||
| | functional.upsample_bilinear | Input tensor must be a 4-D tensor | | |||
| | functional.interpolate | `recompute_scale_factor` and `antialias` not support. it only supported the following 3 modes. 'nearest' only support 4D or 5D input, 'bilinear'only support 4D input, 'linear' only support 3D input | | |||
| | functional.conv1d | On Ascend, `groups` can only be 1 or equal to `input` channel | | |||
| | functional.conv2d | On Ascend, `groups` can only be 1 or equal to `input` channel | | |||
| | functional.conv_transpose1d | 1.`output_padding` not support; 2.On Ascend, `groups` can only be 1 or equal to `input` channel | | |||
| | functional.conv_transpose2d | 1.`output_padding` not support; 2.On Ascend, `groups` can only be 1 or equal to `input` channel | | |||
| | functional.adaptive_max_pool1d | `return_indices` not support on Ascend | | |||
| | functional.adaptive_max_pool2d | `return_indices` not support on Ascend | | |||
| | functional.instance_norm | In graph mode, when training mode, `running_mean` and `running_var` are not supported | | |||
| | functional.batch_norm | In graph mode, when training mode, `running_mean` and `running_var` are not supported | | |||
| | functional.embedding | 1. 'scale_grad_by_freq', 'sparse' is not supported; 2. 'norm_type' can only be 2 | | |||
| ### <span id="jump6">torch.linalg</span> | |||
| | MSAdapter APIs | Constraint conditions | | |||
| | --------------- | -------------- | | |||
| | lu | Currently not support on GRAPH mode, not support `pivot=False`, only support 2-D square matrix as input, not support (*,M,N) shape input | | |||
| | lu_solve | Currently not support on GRAPH mode, input`left=False` not support, only support 2-D square matrix as input, not support 3-D input | | |||
| | lu_factor | Currently not support on GRAPH mode, only support 2-D square matrix as input, not support (*,M,N) shape input | | |||
| | lu_factor_ex | Currently not support on GRAPH mode,Input `get_infos=True` currently cannot scan the error, not support `pivot=False`, only support 2-D square matrix as input, not support (*,M,N) shape input | | |||
| | lstsq | Currently not support on GRAPH mode, not support gradient computation | | |||
| | eigvals | Currently not support GRAPH mode, not support gradient computation | | |||
| | svd | `driver` only support None as input, not support gradient computation on Ascend, currently not support GRAPH mode on Ascend | | |||
| | svdvals | `driver` only support None as input, not support gradient computation on Ascend, currently not support on GRAPH mode on Ascend | | |||
| | norm | Currently not support complex input, `ord` not support float input, not support ord is nuclear norm, float('inf') or int on Ascend | | |||
| | vector_norm | Currently not support complex input, `ord` not support float input | | |||
| | matrix_power | Currently not support `n` < 0 on GPU | | |||
| | eigvalsh | not support gradient computation | | |||
| | eigh | Currently not support on GRAPH mode, not support gradient computation | | |||
| | solve | Currently not support gradient computation | | |||
+ 197
- 0
Debugging_and_Tuning.md
View File
| @@ -0,0 +1,197 @@ | |||
| # MSAdapter调试调优指南 | |||
| ## 1.简介 | |||
| MSAdapter是一款将PyTorch训练脚本高效迁移至MindSpore框架执行的实用工具,旨在不改变原生PyTorch用户的编程使用习惯下,使得PyTorch风格代码能在昇腾硬件上获得高效性能。用户只需要将PyTorch源代码中`import torch`替换为`import msadapter.pytorch`,加上少量训练代码适配即可实现模型在昇腾硬件上的训练。 | |||
| 本教材旨在为开发者提供一个简明扼要的精度问题与性能问题初步定位指导。如果您还未完成模型迁移转换,可参考[MSAdapter用户使用指南](USER_GUIDE.md)。 | |||
| ## 2.功能调试 | |||
| #### PyNative模式功能调试 | |||
| 1)当执行出现异常时,您会得到由MindSpore反馈的报错信息,MindSpore报错信息采用Python Traceback处理,包括Python堆栈信息、报错类型与报错描述等信息,对于接口级别的问题,可以根据报错堆栈信息快速定位出问题位置: | |||
|  | |||
| 更多细节请参考[MindSpore功能调试](https://www.mindspore.cn/tutorials/experts/zh-CN/master/debug/function_debug.html)。 | |||
| 2)PyNative模式模式下可以通过添加Print打印信息获取问题接口当前的输入数据具体取值: | |||
| 若输入数据不符合预期,则可能由于前置接口导致问题,可以在关键位置添加断点,逐步缩小范围,直至明确问题接口; | |||
| 如果您在使用过程中遇到框架问题或接口无法对标请通过[ISSUE](https://openi.pcl.ac.cn/OpenI/MSAdapter/issues) 和我们反馈交流。 | |||
| #### Graph模式功能调试 | |||
| 首先推荐您在PyNative模式(即默认模式)下完成功能调试后再尝试Graph模式执行。当Graph模式出现异常时,可结合报错信息和[静态图语法支持](https://www.mindspore.cn/docs/zh-CN/master/note/static_graph_syntax_support.html)文档进行手动适配。同时您将您的受限场景通过[ISSUE](https://openi.pcl.ac.cn/OpenI/MSAdapter/issues) 反馈给我们,我们会优先分析支持。 | |||
| ## 3.精度调优 | |||
| 您可以通过对比迁移后模型和torch原始模型的执行结果,确保迁移模型的功能正确性。 | |||
| #### 方式一:利用TroubleShooter工具进行比较 | |||
| Step1:安装TroubleShooter工具 | |||
| ``` | |||
| pip install troubleshooter -i https://pypi.org/simple | |||
| ``` | |||
| Step2:参考以下用例进行模型推理结果对比 | |||
| ```python | |||
| import sys | |||
| import numpy as np | |||
| import troubleshooter as ts | |||
| sys.path.append("./alexnet_adapter.py") # MSAdapter模型定义文件路经 | |||
| sys.path.append("./alexnet_torch.py") # PyTorch模型定义文件路经 | |||
| from alexnet_adapter import AlexNet as msa_net | |||
| from alexnet_torch import AlexNet as torch_net | |||
| pt_net = torch_net() | |||
| ms_net = msa_net() | |||
| diff_finder = ts.migrator.NetDifferenceFinder(pt_net=pt_net, ms_net=ms_net, auto_conv_ckpt=2) | |||
| # auto_conv_ckpt为2时, PyTorch网络权重会自动加载到MSAdapter网络权重中; | |||
| diff_finder.compare(auto_inputs=(((128, 3, 224, 224), np.float32), )) # 提供输入的shape和type自动构造输入数据,并进行比较输出结果,默认执行model.eval()模式; | |||
| ``` | |||
| 您将获得如下执行结果: | |||
|  | |||
| PyTorch原生模型权重与MSAdapter迁移模型权重映射情况; | |||
|  | |||
| PyTorch原生模型与MSAdapter迁移模型完成权重自动转换后权重值比较结果; | |||
|  | |||
| PyTorch原生模型与MSAdapter迁移模型推理结果比较,如图所示则表示网络推理结果完全一致。 | |||
| 更多使用细节可参考教程[应用场景5:比较MindSpore和PyTorch网络输出是否一致](https://gitee.com/mindspore/toolkits/blob/master/troubleshooter/docs/migrator.md#%E5%BA%94%E7%94%A8%E5%9C%BA%E6%99%AF5%E6%AF%94%E8%BE%83mindspore%E5%92%8Cpytorch%E7%BD%91%E7%BB%9C%E8%BE%93%E5%87%BA%E6%98%AF%E5%90%A6%E4%B8%80%E8%87%B4)。 | |||
| #### 方式二:手动加载pth进行比较 | |||
| 在比较之前,需要保证以下条件的一致性: | |||
| 1)确保网络输入完全一致(可以使用固定的输入数据,也可调用真实数据集); | |||
| 2)确保执行推理模式 | |||
| ``` | |||
| model = LeNet() | |||
| model.eval() | |||
| ``` | |||
| 由于框架随机策略(详情请参考[MindSpore与PyTorch随机数策略的区别](https://www.mindspore.cn/docs/zh-CN/r2.0/migration_guide/typical_api_comparision.html#%E4%B8%8Epytorch%E9%9A%8F%E6%9C%BA%E6%95%B0%E7%AD%96%E7%95%A5%E7%9A%84%E5%8C%BA%E5%88%AB))以及各自内置随机数生成算法的实现存在差异,所以即使用户配置相同的随机种子,两个框架生成的随机数并不一致。同理,带有随机性的接口,如`nn.dropout`,当配置概率不为0或1时,即使输入一致,由于内置随机数逻辑差异,两个框架得到的输出结果并不一致。通过配置网络为推理模式则可排除这方面随机性的影响。 | |||
| 3)确保网络权重的一致性 | |||
| 由于MindSpore随机策略与PyTorch随机策略有所不同,即使网络层初始化策略与算法完全一致,也无法保证权重值一致。此时可以先保存torch的网络权重,再加载至MSAdapter迁移模型的权重中: | |||
| Step1:在torch原始脚本中保存网络权重至本地 | |||
| ```python | |||
| torch.save(net.state_dict(), 'model.pth') | |||
| ``` | |||
| Step2:将torch权重加载至MSAdapter迁移模型中 | |||
| ```python | |||
| net.load_state_dict(torch.load('model.pth',from_torch=True), strict=True) | |||
| ``` | |||
| 在MSAdapter迁移网络脚本中加载Step1保存的pth,同时配置`from_torch=True`,即可将torch的权重加载到迁移模型中,从而保证网络权重的一致性; | |||
| 如果输出误差过大情况,可以在PyNative模式下基于关键位置添加断点,逐步缩小范围,直至明确误差是否合理。 | |||
| ## 4.性能调优 | |||
| 本章节从单卡的性能调优指导入手,帮助用户快速找到单卡训练过程中的性能瓶颈点。多卡场景亦可采用类似手段进行分析。 | |||
| 注:由于首步执行可能存在设备预热/初始化等耗时,下述内容均排除首步执行,推荐观察训练趋于稳定时的现象。 | |||
| 通常训练过程中各个迭代的耗时可拆分为数据预处理部分耗时和网络执行更新部分耗时。可以分别进行耗时统计,明确性能瓶颈发生在哪个阶段,以常见的函数式训练写法为例: | |||
| ```python | |||
| import time | |||
| ... | |||
| train_data = DataLoader(train_set, batch_size=128, shuffle=True, num_workers=2, drop_last=True) | |||
| ... | |||
| # 数据迭代训练 | |||
| for i in range(epochs): | |||
| train_time = time.time() | |||
| for X, y in train_data: | |||
| X, y = X.to(config_args.device), y.to(config_args.device) | |||
| date_time = time.time() | |||
| print("Data Time: ", date_time - train_time, flush=True) # 数据预处理部分耗时 | |||
| res = train_step(X, y) | |||
| print("------>epoch:{}, loss:{:.6f}".format(i, res.asnumpy())) | |||
| train_time = time.time() | |||
| print("Train Time: ", train_time - date_time, flush=True) # 网络执行更新部分耗时 | |||
| ``` | |||
| 一般情况下,Data Time基本可忽略不计,而Train Time基本等价于每迭代的总耗时。 | |||
| #### 数据处理性能调优 | |||
| 1.启用多进程数据加载 | |||
| 如果出现数据耗时过大的情况,请先确认是否合理配置DataLoader中的`num_workers`属性。`num_workers`表示采用多进程并行方式执行数据加载时的进程数,`num_workers`取值越大表示并行程度越高,但由于并行进程会开辟额外存储空间,以及进程数过多可能加剧进程间通讯耗时,不推荐配置过大,按需配置即可。推荐将`num_workers`配置为单次网络训练耗时与单次数据预处理耗时的差异倍数向上取整的取值,例如,网络执行单次耗时为10 s/step,数据预处理单次耗时为20 s/step,则配置`num_workers=2`可使得数据处理耗时基本可被完全隐藏。 | |||
| 2.优化数据预处理操作 | |||
| 如果依照上述方法预计的`num_workers`取值大于16,可以着重分析数据预处理耗时,性能瓶颈可能出现在预处理操作中。如自定义的collate_fn函数较为耗时等。 | |||
| #### 网络执行性能调优 | |||
| 本章节只涉及PyNative模式下分析网络API级别耗时。Graph模式为整图下沉执行,耗时主要集中于算子执行,可直接参考[算子执行性能调优](#jumpch1)进行分析。 | |||
| 1.动态图模式下可以通过开启同步结合打点计时分析性能瓶颈 | |||
| ```python | |||
| ms.set_context(pynative_synchronize=True) | |||
| ``` | |||
| 注意:若未开启同步,python侧计时可能不能准确反映真实执行耗时。同步可能导致网络执行耗时轻微增大,性能调试结束后请关闭同步后训练网络。 | |||
| 2.结合 cProfile 工具分析主要耗时接口 | |||
| ```python | |||
| import cProfile, pstats, io | |||
| from pstats import SortKey | |||
| pr = cProfile.Profile() | |||
| pr.enable() | |||
| ... | |||
| 训练代码 | |||
| ... | |||
| pr.disable() | |||
| s = io.StringIO() | |||
| ps = pstats.Stats(pr, stream=s).sort_stats('cumtime') | |||
| ps.print_stats() | |||
| with open('time_log.txt', 'w+') as f: | |||
| f.write(s.getvalue()) | |||
| ``` | |||
| 其中`sort_stats`配置为`cumtime`表示依照接口耗时(包含该接口内部调用其他接口的总耗时)排序,若配置为`tottime`则表示依照接口耗时(排除接口内部调用其他接口的耗时)排序。 | |||
|  | |||
| 执行后您将得到如图所示的统计文件,我们主要关注msadapter目录下具体接口的耗时,以alexnet为例,conv2d为耗时占比最高的接口。 | |||
| #### <span id="jumpch1">算子执行性能调优</span> | |||
| [MindSpore Insight](https://mindspore.cn/mindinsight/docs/zh-CN/r2.0/performance_tuning_guide.html)是MindSpore原生框架提供的性能分析工具,从单机和集群的角度分别提供了多项指标,用于帮助用户进行性能调优。利用该工具用户可观察到硬件侧算子的执行耗时,昇腾环境可参考[性能调试(Ascend)](https://www.mindspore.cn/mindinsight/docs/zh-CN/r2.0/performance_profiling_ascend.html),GPU环境可参考[性能调试(GPU)](https://www.mindspore.cn/mindinsight/docs/zh-CN/r2.0/performance_profiling_gpu.html)。 | |||
| 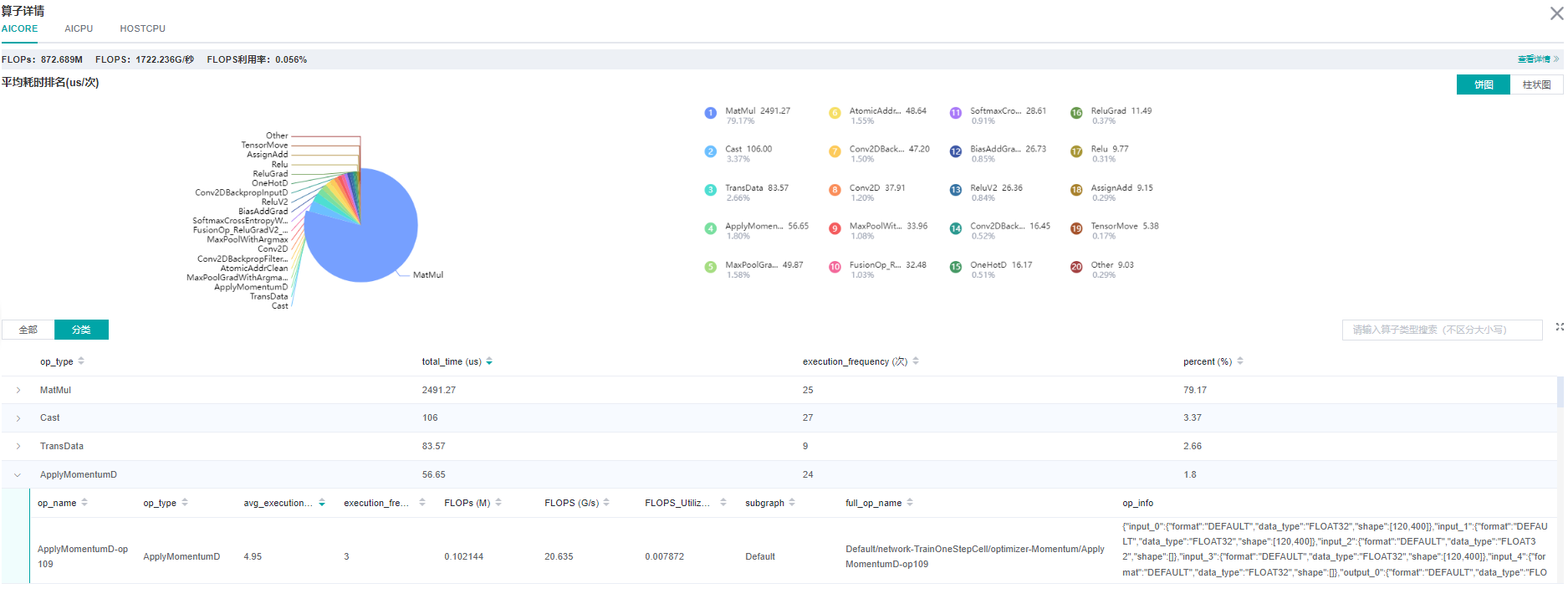 | |||
| 最终您将得到如图所示的算子性能分析看板,通过该看板可以明确算子总耗时/算子平均单次耗时/算子耗时占比等信息。 | |||
+ 34
- 72
README.md
View File
| @@ -4,24 +4,27 @@ | |||
| ## 简介 | |||
| MSAdapter是MindSpore适配PyTorch接口的工具,其目的是在不改变原有PyTorch用户的使用习惯情况下,使得PyTorch代码能在昇腾上获得高效性能. | |||
| <p align="center"><img src="https://openi.pcl.ac.cn/laich/pose_data/raw/branch/master/MSA_F.png" width="580"\></p> | |||
| MSAdapter是将PyTorch训练脚本高效迁移至MindSpore框架执行的工具,其目的是在不改变原有PyTorch用户的使用习惯情况下,使得PyTorch代码能在昇腾上获得高效性能。 | |||
| <p align="center"><img src="doc/pic/MSA_F.png" width="580"\></p> | |||
| - PyTorch接口支持: MSAdapter的目的是支持PyTorch语法的原生态表达,用户只需要将PyTorch源代码中```import torch```替换为```import ms_adapter.pytorch```即可实现模型能支持昇腾上训练。模型中所使用的高阶APIs支持状态可以从这里找到 [Supported List](SupportedList.md) | |||
| - PyTroch接口支持范围: MSAdapter目前主要适配PyTorch的数据处理和模型结构部分代码,目前完全支持MindSpore的PYNATIVE模式下训练,部分网络结构支持GRAPH模式训练。训练过程部分代码需要用户自定义编写具体使用和需要修改的地方可以参考[迁移示例](https://openi.pcl.ac.cn/OpenI/MSAdapterModelZoo/src/branch/master/official/cv/alexnet) | |||
| - **PyTorch接口支持**: MSAdapter的目的是支持PyTorch语法的原生态表达,用户只需要将PyTorch源代码中```import torch```替换为```import msadapter.pytorch```即可实现模型能支持昇腾上训练。模型中所使用的高阶APIs支持状态可以从这里找到 [Supported List](SupportedList.md)。 | |||
| - **PyTorch接口支持范围**: MSAdapter目前主要适配PyTorch的数据处理和模型结构部分代码,目前完全支持MindSpore的PYNATIVE模式下训练,部分网络结构支持GRAPH模式训练。 | |||
| - **TorchVision接口支持**: MSAdapter TorchVision是迁移自PyTorch官方实现的计算机视觉工具库,延用PyTorch官方api设计与使用习惯,内部计算调用MindSpore算子,实现与torchvision原始库同等功能。用户只需要将PyTorch源代码中```import torchvision```替换为```import msadapter.torchvision```即可。TorchVision支持状态可以从这里找到 [TorchVision Supported List](msadapter/torchvision/TorchVision_SupportedList.md)。 | |||
| ## 安装 | |||
| 首先查看[版本说明](#版本说明)选择所需的MSAdapter和MindSpore版本。 | |||
| ### 安装MindSpore | |||
| 请根据MindSpore官网[安装指南](https://www.mindspore.cn/install),安装2.0.0及以上版本的MindSpore。 | |||
| 请根据MindSpore官网[安装指南](https://www.mindspore.cn/install) 进行安装。 | |||
| ### 安装MSAdapter | |||
| #### 通过pip安装 (待版本发布后) | |||
| #### 通过pip安装 | |||
| ```bash | |||
| pip install ms_adapter | |||
| pip install msadapter | |||
| ``` | |||
| #### 通过源码安装 | |||
| ```bash | |||
| git clone https://git.openi.org.cn/OpenI/MSAdapter.git | |||
| @@ -33,78 +36,37 @@ pip install ms_adapter | |||
| python setup.py install --user || exit 1 | |||
| ``` | |||
| ## 使用 | |||
| 在数据处理和模型构建上,MSAdapter可以和PyTorch一样使用,模型训练部分代码需要自定义,示例如下: | |||
| 参考[MSAdapter用户使用指南](https://openi.pcl.ac.cn/OpenI/MSAdapter/src/branch/master/USER_GUIDE.md),您将快速入门完成PyTorch原生代码的迁移,以及上手各种进阶优化手段;如果您有对精度和性能调优的需求可参考[MSAdapter调试调优指南](https://openi.pcl.ac.cn/OpenI/MSAdapter/src/branch/master/Debugging_and_Tuning.md)。 | |||
| ### 1.数据处理(仅修改导入包) | |||
| ```python | |||
| from ms_adapter.pytorch.utils.data import DataLoader | |||
| from ms_adapter.torchvision import datasets, transforms | |||
| ## 资源 | |||
| - 模型库:MSAdapter支持丰富的深度学习应用,这里给出了从PyTorch官方代码迁移到MSAdapter模型。[已验证模型资源](https://git.openi.org.cn/OpenI/MSAdapterModelZoo) | |||
| transform = transforms.Compose([transforms.Resize((224, 224), interpolation=InterpolationMode.BICUBIC), | |||
| transforms.ToTensor(), | |||
| transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.247, 0.2435, 0.2616]) | |||
| ]) | |||
| train_images = datasets.CIFAR10('./', train=True, download=True, transform=transform) | |||
| train_data = DataLoader(train_images, batch_size=128, shuffle=True, num_workers=2, drop_last=True) | |||
| ## 版本说明 | |||
| ``` | |||
| ### 2.模型构建(仅修改导入包) | |||
| ```python | |||
| from ms_adapter.pytorch.nn import Module, Linear, Flatten | |||
| class MLP(Module): | |||
| def __init__(self): | |||
| super(MLP, self).__init__() | |||
| self.flatten = Flatten() | |||
| self.line1 = Linear(in_features=1024, out_features=64) | |||
| self.line2 = Linear(in_features=64, out_features=128, bias=False) | |||
| self.line3 = Linear(in_features=128, out_features=10) | |||
| def forward(self, inputs): | |||
| x = self.flatten(inputs) | |||
| x = self.line1(x) | |||
| x = self.line2(x) | |||
| x = self.line3(x) | |||
| return x | |||
| ``` | |||
| ### 3.模型训练(自定义训练) | |||
| ```python | |||
| import ms_adapter.pytorch as torch | |||
| import ms_adapter.pytorch.nn as nn | |||
| import mindspore as ms | |||
| net = MLP() | |||
| net.train() | |||
| epochs = 500 | |||
| criterion = nn.CrossEntropyLoss() | |||
| optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0005) | |||
| # 定义训练过程 | |||
| loss_net = ms.nn.WithLossCell(net, criterion) | |||
| train_net = ms.nn.TrainOneStepCell(loss_net, optimizer) | |||
| for i in range(epochs): | |||
| for X, y in train_data: | |||
| res = train_net(X, y) | |||
| print("epoch:{}, loss:{:.6f}".format(i, res.asnumpy())) | |||
| # 模型保存 | |||
| ms.save_checkpoint(net, "save_path.ckpt") | |||
| ``` | |||
| | **分支名** | **发布版本** | **发布时间** | **配套MindSpore版本** | 启智算力资源 | | |||
| |--------------|----------------|--------------------|-------------------------|------------------------------------------------| | |||
| | **release_0.1** | 0.1 | 2023-06-15 | [MindSpore 2.0.0](https://www.mindspore.cn/install) | [智算网络集群](https://openi.pcl.ac.cn/OpenI/MSAdapter/grampus/notebook/create?type=1) - 镜像:mindspore2.0rc_cann6.3_notebook | | |||
| | **release_0.1rc** | 0.1rc | 2023-04-23 | [MindSpore 2.0.0rc1](https://www.mindspore.cn/versions) | [智算网络集群](https://openi.pcl.ac.cn/OpenI/MSAdapter/grampus/notebook/create?type=1) - 镜像:mindspore2.0rc_cann6.3_notebook | | |||
| | **release_0.1beta** | 0.1beta | 2023-03-27 | [MindSpore Nightly(0205)](https://openi.pcl.ac.cn/attachments/63457dd2-5eb3-4a6b-a4e4-41b6dca8d0e9?type=0) | - | | |||
| | **master** | - | - | [MindSpore 2.0.0](https://www.mindspore.cn/install) | - | | |||
| - MSAdapter已发布版本获取请参阅[RELEASE](https://openi.pcl.ac.cn/OpenI/MSAdapter/releases)。 | |||
| - MindSpore版本推荐从[MindSpore官网](https://www.mindspore.cn/versions)获取,或者从启智平台[数据资源](https://openi.pcl.ac.cn/OpenI/MSAdapter/datasets)中获取。 | |||
| ## 正在进行的工作 | |||
| - 支持更多torch的接口。 | |||
| - 支持torchaudio数据处理接口。 | |||
| - 性能优化。 | |||
| ## 资源 | |||
| - 模型库:MSAdapter支持丰富的深度学习应用,这里给出了从PyTorch官方代码迁移到MSAdapter模型。[已验证模型资源](https://git.openi.org.cn/OpenI/MSAdapterModelZoo) | |||
| ## 贡献 | |||
| 欢迎开发者参与贡献。更多详情,请参阅我们的[贡献指南](https://openi.pcl.ac.cn/OpenI/MSAdapter/src/branch/master/CONTRIBUTING_CN.md). | |||
| ## 加入我们 | |||
| 如果您在使用时有任何问题或建议,欢迎加入MSAdapter SIG参与讨论。 | |||
| <p align="leaf"><img src="doc/pic/MSA_SIG.png" width="580"\></p> | |||
| ## 许可证 | |||
| [Apache License 2.0](https://openi.pcl.ac.cn/OpenI/MSAdapter/src/branch/master/LICENSE) | |||
| ## FAQ | |||
| Q:设置context.set_context(mode=context.GRAPH_MODE)后运行出现类似问题:`Tensor.add_` is an in-place operation and "x.add_()" is not encouraged to use in MindSpore static graph mode. Please use "x = x.add()" or other API instead。 | |||
| A:目前在设置GRAPH模式下不支持原地操作相关的接口,需要按照提示信息进行修改。需要注意的是,即使在PYNATIVE模式下,原地操作相关接口也是不鼓励使用的,因为目前在MSAdapter不会带来内存收益,而且会给反向梯度计算带来不确定性。 | |||
| Q:运行代码出现类似报错信息:AttributeError: module 'ms_adapter.pytorch' has no attribute 'xxx'。 | |||
| A:首先确定'xxx'是否为torch 1.12版本支持的接口,PyTorch官网明确已废弃或者即将废弃的接口和参数,MSAdapter不会兼容支持,请使用其他同等功能的接口代替。如果是PyTorch对应版本支持,而MSAdapter中暂时没有,欢迎参与[MSAdapter项目](https://openi.pcl.ac.cn/OpenI/MSAdapter)贡献你的代码,也可以通过[创建任务(New issue)](https://openi.pcl.ac.cn/OpenI/MSAdapter/issues/new)反馈需求。 | |||
+ 96
- 0
README.rst
View File
| @@ -0,0 +1,96 @@ | |||
| Introduction | |||
| ============= | |||
| MSAdapter is MindSpore tool for adapting the PyTorch interface, which is designed to make PyTorch code perform efficiently on Ascend without changing the habits of the original PyTorch users. | |||
| |MSAdapter-architecture| | |||
| Install | |||
| ======= | |||
| MSAdapter has some prerequisites that need to be installed first, including MindSpore, PIL, NumPy. | |||
| .. code:: bash | |||
| # for last stable version | |||
| pip install msadapter | |||
| # for latest release candidate | |||
| pip install --upgrade --pre msadapter | |||
| Alternatively, you can install the latest or development version by directly pulling from OpenI: | |||
| .. code:: bash | |||
| pip3 install git+https://openi.pcl.ac.cn/OpenI/MSAdapter.git | |||
| User guide | |||
| =========== | |||
| For data processing and model building, MSAdapter can be used in the same way as PyTorch, while the model training part of the code needs to be customized, as shown in the following example. | |||
| 1. Data processing (only modify the import package) | |||
| .. code:: python | |||
| from msadapter.pytorch.utils.data import DataLoader | |||
| from msadapter.torchvision import datasets, transforms | |||
| transform = transforms.Compose([transforms.Resize((224, 224), interpolation=InterpolationMode.BICUBIC), | |||
| transforms.ToTensor(), | |||
| transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.247, 0.2435, 0.2616]) | |||
| ]) | |||
| train_images = datasets.CIFAR10('./', train=True, download=True, transform=transform) | |||
| train_data = DataLoader(train_images, batch_size=128, shuffle=True, num_workers=2, drop_last=True) | |||
| 2. Model construction (modify import package only) | |||
| .. code:: python | |||
| from msadapter.pytorch.nn import Module, Linear, Flatten | |||
| class MLP(Module): | |||
| def __init__(self): | |||
| super(MLP, self).__init__() | |||
| self.flatten = Flatten() | |||
| self.line1 = Linear(in_features=1024, out_features=64) | |||
| self.line2 = Linear(in_features=64, out_features=128, bias=False) | |||
| self.line3 = Linear(in_features=128, out_features=10) | |||
| def forward(self, inputs): | |||
| x = self.flatten(inputs) | |||
| x = self.line1(x) | |||
| x = self.line2(x) | |||
| x = self.line3(x) | |||
| return x | |||
| 3.Model training (custom training) | |||
| .. code:: python | |||
| import msadapter.pytorch as torch | |||
| import msadapter.pytorch.nn as nn | |||
| import mindspore as ms | |||
| net = MLP() | |||
| net.train() | |||
| epochs = 500 | |||
| criterion = nn.CrossEntropyLoss() | |||
| optimizer = ms.nn.SGD(net.trainable_params(), learning_rate=0.01, momentum=0.9, weight_decay=0.0005) | |||
| # Define the training process | |||
| loss_net = ms.nn.WithLossCell(net, criterion) | |||
| train_net = ms.nn.TrainOneStepCell(loss_net, optimizer) | |||
| for i in range(epochs): | |||
| for X, y in train_data: | |||
| res = train_net(X, y) | |||
| print("epoch:{}, loss:{:.6f}".format(i, res.asnumpy())) | |||
| # Save model | |||
| ms.save_checkpoint(net, "save_path.ckpt") | |||
| License | |||
| ======= | |||
| MSAdapter is released under the Apache 2.0 license. | |||
| .. |MSAdapter-architecture| image:: https://openi.pcl.ac.cn/laich/pose_data/raw/branch/master/MSA_F.png | |||
+ 66
- 0
README_en.md
View File
| @@ -0,0 +1,66 @@ | |||
| # MSAdapter | |||
| [简体中文](README.md) | [English] | |||
| ## Introduction | |||
| MSAdapter is MindSpore tool for adapting the PyTorch interface, which is designed to make PyTorch code perform efficiently on Ascend without changing the habits of the original PyTorch users. | |||
| <p align="center"><img src="https://openi.pcl.ac.cn/laich/pose_data/raw/branch/master/MSA_F.png" width="580"\></p> | |||
| - **PyTorch interface support**: MSAdapter aims to support the original expression of PyTorch syntax, users just need to replace ``import torch`` in PyTorch source code with ``import msadapter.pytorch`` to realize that the model can support training on ascending. The support status of the higher-order APIs used in the model can be found here [Supported List](SupportedList_en.md). | |||
| - **PyTorch interface support scope**: MSAdapter is currently mainly adapted to PyTorch data processing and model structure part of the code, currently fully supports MindSpore's PYNATIVE mode training, part of the network structure support GRAPH mode training. | |||
| - **TorchVision interface support**: MSAdapter TorchVision is a computer vision tool library migrated from PyTorch's official implementation. It continues to use PyTorch's official api design, and calls `MindSpore` operators for calculations to achieve the same functions as the original `torchvision` library. Users only need to replace ```import torchvision``` in the PyTorch source code with ```import msadapter.torchvision```. | |||
| TorchVision support status can be found from here [TorchVision Supported List](msadapter/torchvision/TorchVision_SupportedList_en.md) | |||
| ## Install | |||
| Please check the [Version Description](#Version-Description) to select the required version of MSAdapter and MindSpore. | |||
| ### Install MindSpore | |||
| Please install MindSpore according to the [Installation Guide](https://www.mindspore.cn/install/en) on MindSpore official website. | |||
| ### Install MSAdapter | |||
| #### via pip | |||
| ```bash | |||
| pip install msadapter | |||
| ``` | |||
| #### via source code | |||
| ```bash | |||
| git clone https://git.openi.org.cn/OpenI/MSAdapter.git | |||
| cd MSAdapter | |||
| python setup.py install | |||
| ``` | |||
| If there is an insufficient permissions message, install as follows | |||
| ```bash | |||
| python setup.py install --user || exit 1 | |||
| ``` | |||
| ## User guide | |||
| Refer to the [User Guide](USER_GUIDE.md), you will quickly get started and complete the transformation from PyTorch code, as well as get started with various advanced optimization skills; More over, if you have requirements for precision and performance tuning, please refer to the [Debugging and Tuning Guide](Debugging_and_Tuning.md). | |||
| ## Resources | |||
| - Model library: MSAdapter supports rich deep learning applications, migration to MSAdapter models from the official PyTorch code is given here. [Model Resources](https://git.openi.org.cn/OpenI/MSAdapterModelZoo). | |||
| ## Version Description | |||
| | **Branch** | **Version** | **Initial Release Date** | **MindSpore Version** | OpenI Computing Resources | | |||
| |--------------|----------------|------------------------|-------------------------|-----------------| | |||
| | **release_0.1** | 0.1 | 2023-06-15 | [MindSpore 2.0.0](https://www.mindspore.cn/install/en) | [China Computing NET](https://openi.pcl.ac.cn/OpenI/MSAdapter/grampus/notebook/create?type=1) - Image:mindspore2.0rc_cann6.3_notebook | | |||
| | **release_0.1rc** | 0.1rc | 2023-04-23 | [MindSpore 2.0.0rc1](https://www.mindspore.cn/versions/en) | [China Computing NET](https://openi.pcl.ac.cn/OpenI/MSAdapter/grampus/notebook/create?type=1) - Image:mindspore2.0rc_cann6.3_notebook | | |||
| | **release_0.1beta** | 0.1beta | 2023-03-27 | [MindSpore Nightly(0205)](https://openi.pcl.ac.cn/attachments/63457dd2-5eb3-4a6b-a4e4-41b6dca8d0e9?type=0) | - | | |||
| | **master** | - | - | [MindSpore 2.0.0](https://www.mindspore.cn/install)| - | | |||
| - For the released version of MSAdapter, please refer to [RELEASE](https://openi.pcl.ac.cn/OpenI/MSAdapter/releases). | |||
| - The MindSpore is recommended to be obtained from the [MindSpore official website](https://www.mindspore.cn/versions/en) or from our [data resources](https://openi.pcl.ac.cn/OpenI/MSAdapter/datasets). | |||
| ## On Going and Future Work | |||
| - More APIs of torch will be supported. | |||
| - Datasets APIs of torchaudio will be supported. | |||
| - Performance optimization. | |||
| ## Contributing | |||
| Developers are welcome to contribute. For more details, please see our [Contribution Guidelines](https://openi.pcl.ac.cn/OpenI/MSAdapter/src/branch/master/CONTRIBUTING_CN.md). | |||
| ## License | |||
| [Apache License 2.0](https://openi.pcl.ac.cn/OpenI/MSAdapter/src/branch/master/LICENSE) | |||
+ 1172
- 91
SupportedList.md
View File
| @@ -1,100 +1,1181 @@ | |||
| ## List of PyTorch APIs supported by MSAdapter | |||
| | MSAdapter APIs | Status | Notes | | |||
| | --------------- | -------------------- | -------------- | | |||
| | Conv1d | Supported| Pad支持不完善,权重不对齐,需要给出扩展为二维权重| | |||
| | Conv2d | Supported| /| | |||
| | Conv3d | Supported|Pad支持不完善 | | |||
| | ConvTranspose1d |Supported |output_padding参数不支持、pad类型支持不完备 | | |||
| | ConvTranspose2d |Supported |output_padding参数不支持、pad类型支持不完备 | | |||
| | ConvTranspose3d |Supported |output_padding参数不支持、pad类型支持不完备 | | |||
| | Linear | Supported | /| | |||
| | MaxPool1d | Supported|/| | |||
| | AvgPool1d | Supported|/| | |||
| | MaxPool2d | Supported|/| | |||
| | AvgPool2d | Supported|/| | |||
| | MaxPool3d | Supported|/| | |||
| | AvgPool3d | Supported|/| | |||
| | AdaptiveAvgPool1d | Supported| /| | |||
| | AdaptiveAvgPool2d | Supported| /| | |||
| | AdaptiveAvgPool3d | Supported| /| | |||
| | AdaptiveMaxPool1d | Supported| /| | |||
| | AdaptiveMaxPool2d | Supported|/| | |||
| | AdaptiveMaxPool3d | Supported| /| | |||
| | Embedding |Supported | scale_grad_by_freq、sparse参数不支持| | |||
| | Flatten | Supported| /| | |||
| | Unflatten| Supported| /| | |||
| | Dropout | Supported| /| | |||
| |Dropout2D|Supported|/| | |||
| |Dropout3D|Supported|/| | |||
| | BatchNorm1d | Supported| /| | |||
| | BatchNorm2d | Supported| /| | |||
| | BatchNorm3d |Supported | /| | |||
| | PRelu | Pending| /| | |||
| | ReLU |Supported| /| | |||
| | Tanh |Supported| /| | |||
| | Sigmoid |Supported| /| | |||
| | LeakyRelu Supported|| /| | |||
| | Softplus |Supported| /| | |||
| | ReLU6 | Supported| /| | |||
| | LeakyReLU6 |Supported| /| | |||
| |Hardtanh|Supported|/| | |||
| |Hardswish|Supported|/| | |||
| | Mish |Supported| /| | |||
| | Softmax |Supported| /| | |||
| | Elu |Supported | /| | |||
| | RNN | Pending| /| | |||
| | RNNCell | Pending| /| | |||
| | LSTM | Pending| /| | |||
| | LSTMCell | Pending| /| | |||
| | GRU | Pending| /| | |||
| | GRUCell | Pending| /| | |||
| | FractionalMaxPool2d| Supported| /| | |||
| | FractionalMaxPool3d| Supported| /| | |||
| | LPPool1d| Supported| /| | |||
| | LPPool2d| Supported| /| | |||
| | ReflectionPad1d| Supported| /| | |||
| | ReflectionPad2d| Supported| /| | |||
| | ReflectionPad3d| Supported| /| | |||
| | ReplicationPad2d| Supported| /| | |||
| | ReplicationPad3d| Supported| /| | |||
| | ConstantPad1d| Supported| /| | |||
| | ConstantPad2d| Supported| /| | |||
| | ConstantPad3d| Supported| /| | |||
| | Tanhshrink| Supported| /| | |||
| | Threshold| Supported| /| | |||
| | GLU| Supported| /| | |||
| | Softmin| Supported| /| | |||
| | LogSoftmax| Supported| /| | |||
| | SyncBatchNorm| Supported| /| | |||
| | GroupNorm| Supported| 只支持2D| | |||
| | LayerNorm| Supported| /| | |||
| | AlphaDropout| Supported| /| | |||
| | FeatureAlphaDropout| Supported| /| | |||
| | CosineSimilarity| Supported| /| | |||
| | PairwiseDistance| Supported| /| | |||
| | L1Loss| Supported| /| | |||
| | MSELoss| Supported| /| | |||
| | CrossEntropyLoss| Supported| /| | |||
| | NLLLoss| Supported| /| | |||
| | BCELoss| Supported| /| | |||
| | BCEWithLogitsLoss| Supported| /| | |||
| | HuberLoss| Supported| /| | |||
| | SmoothL1Loss| Supported| /| | |||
| | SoftMarginLoss| Supported| /| | |||
| | CosineEmbeddingLoss| Supported| /| | |||
| | MultiMarginLoss| Supported| /| | |||
| | TripletMarginLoss| Supported| /| | |||
| | Upsample| Supported| /| | |||
| | UpsamplingNearest2d| Supported| /| | |||
| | UpsamplingBilinear2d| Supported| /| | |||
| | | | | | |||
| | | | | | |||
| 简体中文 | [English](SupportedList_en.md) | |||
| - [MSAdapter支持API清单](#jump1) | |||
| - [Torch](#jump2) | |||
| - [Tensor](#jump3) | |||
| - [Torch.nn](#jump4) | |||
| - [nn.functional](#jump5) | |||
| - [torch.linalg](#jump6) | |||
| - [torch.optim](#jump7) | |||
| ### <span id="jump8">通用限制</span> | |||
| - 不支持`layout`, `device`, `requires_grad`, `memory_format`参数的配置功能。 | |||
| - 不支持通过`Generator`参数管理生成伪随机数的算法的状态。 | |||
| - 不支持七维及以上的计算。 | |||
| - 复数类型的支持正在完善。 | |||
| - Ascend上对float64类型的输入支持受限,部分接口无法处理float64类型入参,需转换为float32或float16类型之后输入。 | |||
| - [PyTorch中具有视图操作的接口](https://pytorch.org/docs/1.12/tensor_view.html)功能受限,当前输入和输出张量不共享底层数据,而会进行数据拷贝。 | |||
| - 在Ascend和GPU上,部分数据类型(如int16和int32)在溢出的场景下,mindspore和pytorch处理的结果存在差异,因此不建议对具有类型限制的入参进行超出上限或下限的赋值,也不建议对明显超过数据类型的数据向范围更小的数据类型进行转换,以免获得预期之外的结果。 | |||
| - 下表中存在”功能存在限制“标注的接口,请查看[接口约束列表](ConstraintList.md),获取详细信息。 | |||
| ## <span id="jump1">MSAdapter支持API清单</span> | |||
| ### <span id="jump2">Torch</span> | |||
| | MSAdapter接口 | 状态 | 约束 | | |||
| | --------------- | -------------------- | -------------- | | |||
| | torch.is_tensor | 支持 | | | |||
| | torch.is_floating_point | 支持 | | | |||
| | torch.arange | 支持 | | | |||
| | torch.cat | 支持 | | | |||
| | torch.tensor | 支持 | | | |||
| | torch.as_tensor | 支持 | | | |||
| | torch.from_numpy | 支持 | | | |||
| | torch.frombuffer | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.permute | 支持 | | | |||
| | torch.bitwise_left_shift | 支持 | | | |||
| | torch.bitwise_right_shift | 支持 | | | |||
| | torch.nan_to_num | 支持 | | | |||
| | torch.range | 支持 | | | |||
| | torch.linspace | 支持 | | | |||
| | torch.logspace | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.eye | 支持 | | | |||
| | torch.empty | 支持 | | | |||
| | torch.empty_like | 支持 | | | |||
| | torch.eig | 部分支持 | 暂不支持GPU后端 | | |||
| | torch.full | 支持 | | | |||
| | torch.full_like | 支持 | | | |||
| | torch.polar | 支持 | | | |||
| | torch.concat | 支持 | | | |||
| | torch.column_stack | 支持 | | | |||
| | torch.gather | 支持 | | | |||
| | torch.is_complex | 支持 | | | |||
| | torch.hstack | 支持 | | | |||
| | torch.index_select | 支持 | | | |||
| | torch.masked_select | 支持 | | | |||
| | torch.movedim | 支持 | | | |||
| | torch.moveaxis | 支持 | | | |||
| | torch.narrow | 支持 | | | |||
| | torch.nonzero | 支持 | | | |||
| | torch.numel | 支持 | | | |||
| | torch.reshape | 支持 | | | |||
| | torch.row_stack | 支持 | | | |||
| | torch.select | 支持 | | | |||
| | torch.zeros | 支持 | | | |||
| | torch.squeeze | 支持 | | | |||
| | torch.stack | 支持 | | | |||
| | torch.swapaxes | 支持 | | | |||
| | torch.swapdims | 支持 | | | |||
| | torch.zeros_like | 支持 | | | |||
| | torch.take | 支持 | | | |||
| | torch.ones | 支持 | | | |||
| | torch.tile | 支持 | | | |||
| | torch.transpose | 支持 | | | |||
| | torch.unbind | 支持 | | | |||
| | torch.unsqueeze | 支持 | | | |||
| | torch.ones_like | 支持 | | | |||
| | torch.vstack | 支持 | | | |||
| | torch.heaviside | 支持 | | | |||
| | torch.seed | 支持 | | | |||
| | torch.initial_seed | 支持 | | | |||
| | torch.rand | 支持 | | | |||
| | torch.randn | 支持 | | | |||
| | torch.abs | 支持 | | | |||
| | torch.absolute | 支持 | | | |||
| | torch.acos | 支持 | | | |||
| | torch.adjoint | 支持 | | | |||
| | torch.acosh | 支持 | | | |||
| | torch.arccosh | 支持 | | | |||
| | torch.add | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.addcdiv | 支持 | | | |||
| | torch.addcmul | 支持 | | | |||
| | torch.dsplit | 支持 | | | |||
| | torch.asin | 支持 | | | |||
| | torch.arcsin | 支持 | | | |||
| | torch.asinh | 支持 | | | |||
| | torch.arcsinh | 支持 | | | |||
| | torch.atan | 支持 | | | |||
| | torch.arctan | 支持 | | | |||
| | torch.atanh | 支持 | | | |||
| | torch.arctanh | 支持 | | | |||
| | torch.atan2 | 支持 | | | |||
| | torch.arctan2 | 支持 | | | |||
| | torch.bitwise_not | 支持 | | | |||
| | torch.bitwise_and | 支持 | | | |||
| | torch.bitwise_or | 支持 | | | |||
| | torch.bitwise_xor | 支持 | | | |||
| | torch.hsplit | 支持 | | | |||
| | torch.split | 支持 | | | |||
| | torch.ceil | 支持 | | | |||
| | torch.t | 支持 | | | |||
| | torch.tensor_split | 支持 | | | |||
| | torch.conj_physical | 支持 | | | |||
| | torch.copysign | 支持 | | | |||
| | torch.cos | 支持 | | | |||
| | torch.cosh | 支持 | | | |||
| | torch.deg2rad | 支持 | | | |||
| | torch.device | 支持 | | | |||
| | torch.div | 支持 | | | |||
| | torch.divide | 支持 | | | |||
| | torch.erf | 支持 | | | |||
| | torch.erfc | 支持 | | | |||
| | torch.erfinv | 支持 | | | |||
| | torch.exp | 支持 | | | |||
| | torch.exp2 | 支持 | | | |||
| | torch.expm1 | 支持 | | | |||
| | torch.fix | 支持 | | | |||
| | torch.vsplit | 支持 | | | |||
| | torch.floor | 支持 | | | |||
| | torch.floor_divide | 支持 | | | |||
| | torch.where | 支持 | | | |||
| | torch.frac | 支持 | | | |||
| | torch.frexp | 支持 | | | |||
| | torch.finfo | 支持 | | | |||
| | torch.iinfo | 支持 | | | |||
| | torch.ldexp | 支持 | | | |||
| | torch.lerp | 支持 | | | |||
| | torch.arccos | 支持 | | | |||
| | torch.log | 支持 | | | |||
| | torch.angle | 支持 | | | |||
| | torch.log1p | 支持 | | | |||
| | torch.clamp | 支持 | | | |||
| | torch.logaddexp | 支持 | | | |||
| | torch.logaddexp2 | 支持 | | | |||
| | torch.logical_not | 支持 | | | |||
| | torch.logical_or | 支持 | | | |||
| | torch.logit | 支持 | | | |||
| | torch.clip | 支持 | | | |||
| | torch.float_power | 部分支持 | [输入参数有限制](ConstraintList.md) | | |||
| | torch.igammac | 支持 | | | |||
| | torch.mul | 支持 | | | |||
| | torch.fmod | 支持 | | | |||
| | torch.lgamma | 部分支持 | [输入参数有限制](ConstraintList.md) | | |||
| | torch.neg | 支持 | | | |||
| | torch.log10 | 支持 | | | |||
| | torch.nextafter | 部分支持 | [输入参数有限制](ConstraintList.md) | | |||
| | torch.positive | 支持 | | | |||
| | torch.pow | 支持 | | | |||
| | torch.rad2deg | 支持 | | | |||
| | torch.log2 | 支持 | | | |||
| | torch.hypot | 支持 | | | |||
| | torch.remainder | 支持 | | | |||
| | torch.round | 支持 | | | |||
| | torch.sigmoid | 支持 | | | |||
| | torch.multiply | 支持 | | | |||
| | torch.negative | 支持 | | | |||
| | torch.sin | 支持 | | | |||
| | torch.reciprocal | 支持 | | | |||
| | torch.sinh | 支持 | | | |||
| | torch.sqrt | 支持 | | | |||
| | torch.roll | 支持 | | | |||
| | torch.rot90| 支持 | | | |||
| | torch.square | 支持 | | | |||
| | torch.sub | 支持 | | | |||
| | torch.rsqrt | 支持 | | | |||
| | torch.tan | 支持 | | | |||
| | torch.tanh | 支持 | | | |||
| | torch.sign | 支持 | | | |||
| | torch.trunc | 支持 | | | |||
| | torch.xlogy | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.amax | 支持 | | | |||
| | torch.amin | 支持 | | | |||
| | torch.aminmax | 支持 | | | |||
| | torch.all | 支持 | | | |||
| | torch.any | 支持 | | | |||
| | torch.min | 支持 | | | |||
| | torch.dist | 支持 | | | |||
| | torch.logsumexp | 支持 | | | |||
| | torch.nanmean | 支持 | | | |||
| | torch.nansum | 支持 | | | |||
| | torch.prod | 支持 | | | |||
| | torch.qr | 支持 | | | |||
| | torch.std | 支持 | | | |||
| | torch.sgn | 支持 | | | |||
| | torch.unique_consecutive | 支持 | | | |||
| | torch.var | 支持 | | | |||
| | torch.count_nonzero | 支持 | | | |||
| | torch.allclose | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.signbit | 支持 | | | |||
| | torch.eq | 支持 | | | |||
| | torch.equal | 支持 | | | |||
| | torch.ge | 支持 | | | |||
| | torch.greater_equal | 支持 | | | |||
| | torch.gt | 支持 | | | |||
| | torch.greater | 支持 | | | |||
| | torch.isclose | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.isfinite | 支持 | | | |||
| | torch.isin | 支持 | | | |||
| | torch.isinf | 支持 | | | |||
| | torch.isposinf | 支持 | | | |||
| | torch.isneginf | 支持 | | | |||
| | torch.isnan | 支持 | | | |||
| | torch.isreal | 支持 | | | |||
| | torch.is_nonzero | 支持 | | | |||
| | torch.le | 支持 | | | |||
| | torch.less_equal | 支持 | | | |||
| | torch.lt | 支持 | | | |||
| | torch.less | 支持 | | | |||
| | torch.lu| 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.lu_solve | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.lu_unpack | 部分支持 | 暂不支持Ascend后端 | | |||
| | torch.maximum | 支持 | | | |||
| | torch.minimum | 支持 | | | |||
| | torch.ne | 支持 | | | |||
| | torch.sinc | 支持 | | | |||
| | torch.subtract | 支持 | | | |||
| | torch.topk | 支持 | | | |||
| | torch.true_divide | 支持 | | | |||
| | torch.atleast_1d | 支持 | | | |||
| | torch.atleast_2d | 支持 | | | |||
| | torch.atleast_3d | 支持 | | | |||
| | torch.block_diag | 支持 | | | |||
| | torch.broadcast_to | 支持 | | | |||
| | torch.cdist | 支持 | | | |||
| | torch.corrcoef | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.cov | 支持 | | | |||
| | torch.cummin | 支持 | | | |||
| | torch.cumprod | 支持 | | | |||
| | torch.cumsum | 支持 | | | |||
| | torch.diag | 支持 | | | |||
| | torch.diagflat | 支持 | | | |||
| | torch.diagonal | 支持 | | | |||
| | torch.diff | 支持 | | | |||
| | torch.flatten | 支持 | | | |||
| | torch.flip | 支持 | | | |||
| | torch.flipud | 支持 | | | |||
| | torch.histc | 部分支持 | 暂不支持GPU后端 | | |||
| | torch.meshgrid | 支持 | | | |||
| | torch.ravel | 支持 | | | |||
| | torch.not_equal | 支持 | | | |||
| | torch.trace | 支持 | | | |||
| | torch.tril | 支持 | | | |||
| | torch.triu | 支持 | | | |||
| | torch.sort | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.msort | 支持 | | | |||
| | torch.addmv | 支持 | | | |||
| | torch.addr | 支持 | | | |||
| | torch.bincount | 支持 | | | |||
| | torch.bmm | 支持 | | | |||
| | torch.cholesky | 支持 | | | |||
| | torch.cholesky_inverse | 部分支持 | 暂不支持GPU后端 | | |||
| | torch.dot | 支持 | | | |||
| | torch.repeat_interleave | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.addbmm | 支持 | | | |||
| | torch.det | 支持 | | | |||
| | torch.addmm | 支持 | | | |||
| | torch.matmul | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.mv | 支持 | | | |||
| | torch.orgqr | 支持 | | | |||
| | torch.outer | 支持 | | | |||
| | torch.vdot | 支持 | | | |||
| | torch._assert | 支持 | | | |||
| | torch.inner | 支持 | | | |||
| | torch.logdet | 支持 | | | |||
| | torch.lstsq | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.mm | 支持 | | | |||
| | torch.cuda.is_available | 支持 | | | |||
| | torch.ByteTensor | 支持 | | | |||
| | torch.CharTensor | 支持 | | | |||
| | torch.IntTensor | 支持 | | | |||
| | torch.HalfTensor | 支持 | | | |||
| | torch.FloatTensor | 支持 | | | |||
| | torch.DoubleTensor | 支持 | | | |||
| | torch.ByteStorage | 支持 | | | |||
| | torch.as_strided | 支持 | | | |||
| | torch.view_as_real | 支持 | | | |||
| | torch.scatter | 不支持 | | | |||
| | torch.manual_seed | 支持 | | | |||
| | torch.matrix_exp | 不支持 | | | |||
| | torch.bernoulli | 支持 | | | |||
| | torch.multinomial | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.randint | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.randperm | 支持 |[功能存在限制](ConstraintList.md) | | |||
| | torch.digamma | 部分支持 | [输入参数有限制](ConstraintList.md) | | |||
| | torch.fft | 部分支持 | [功能存在限制](ConstraintList.md) | | | |||
| | torch.gradient | 支持 | | | |||
| | torch.imag | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.logical_and | 支持 | | | |||
| | torch.logical_xor | 支持 | | | |||
| | torch.igamma | 支持 | | | |||
| | torch.mvlgamma | 支持 | | | |||
| | torch.i0 | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.real | 支持 | | | |||
| | torch.argmax | 支持 | | | |||
| | torch.argmin | 支持 | | | |||
| | torch.max | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.mean | 支持 | | | |||
| | torch.median | 支持 | | | |||
| | torch.norm | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.normal | 支持 | | | |||
| | torch.unique | 支持 | | | |||
| | torch.bartlett_window | 支持 | | | |||
| | torch.sum | 部分支持 | 不支持图模式 | | |||
| | torch.hann_window | 支持 | | | |||
| | torch.argsort | 支持 | | | |||
| | torch.cross | 部分支持 | 暂不支持GPU后端 | | |||
| | torch.cummax | 部分支持 | 暂不支持Ascend后端 | | |||
| | torch.einsum | 部分支持 | 仅支持GPU后端 | | |||
| | torch.fliplr | 支持 | | | |||
| | torch.hamming_window | 支持 | | | |||
| | torch.svd | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.searchsorted | 支持 | | | |||
| | torch.fmax | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.fmin | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.inverse | 部分支持 | 暂不支持Ascend后端 | | |||
| | torch.poisson | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.polygamma | 部分支持 | 暂不支持Ascend后端 | | |||
| | torch.matrix_power | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.vander | 支持 | | | |||
| | torch.renorm | 支持 | | | |||
| | torch.is_conj | 部分支持 | 暂不支持图模式 | | |||
| | torch.resolve_conj | 部分支持 | 暂不支持图模式 | | |||
| | torch.index_add | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.scatter_reduce | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.scatter_add | 支持 | | | |||
| | torch.index_copy | 支持 | | | |||
| | torch.histogramdd | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.diag_embed | 支持 | | | |||
| | torch.resolve_neg | 部分支持 | 暂不支持图模式 | | |||
| | torch.pinverse | 部分支持 | 暂不支持Ascend后端 | | |||
| | torch.asarray | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.symeig | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.result_type | 支持 | | | |||
| | torch.logcumsumexp | 支持 | | | |||
| | torch.complex | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.blackman_window | 支持 | | | |||
| | torch.kaiser_window | 支持 | | | |||
| | torch.bucketize | 支持 | | | |||
| | torch.cartesian_prod | 支持 | | | |||
| | torch.clone | 支持 | | | |||
| | torch.combinations | 支持 | | | |||
| | torch.kron | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.gcd | 支持 | | | |||
| | torch.histogram | 支持 | | | |||
| | torch.lcm | 支持 | | | |||
| | torch.tensordot | 支持 | | | |||
| | torch.tril_indices | 支持 | | | |||
| | torch.triu_indices | 支持 | | | |||
| | torch.geqrf | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.trapz | 支持 | | | |||
| | torch.trapezoid | 支持 | | | |||
| | torch.kthvalue | 支持 | | | |||
| | torch.slice_scatter | 支持 | | | |||
| | torch.select_scatter | 支持 | | | |||
| | torch.take_along_dim | 支持 | | | |||
| | torch.pad | 部分支持 | 1. 暂不支持图模式 2. [功能存在限制](ConstraintList.md) | | |||
| | torch.broadcast_shapes | 支持 | | | |||
| | torch.broadcast_tensors | 支持 | | | |||
| | torch.index_reduce | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.chain_matmul | 支持 | | | |||
| | torch.view_as_complex | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.empty_strided | 支持 | | | |||
| | torch.cumulative_trapezoid | 支持 | | | |||
| | torch.can_cast | 支持 | | | |||
| | torch.diagonal_scatter | 支持 | | | |||
| | torch.rfft | 部分支持 | [功能存在限制](ConstraintList.md) | | | |||
| ### <span id="jump3">Tensor</span> | |||
| | MSAdapter接口 | 状态 | 约束 | | |||
| | --------------- | -------------------- | -------------- | | |||
| | Tensor.mm | 支持 | | | |||
| | Tensor.msort | 支持 | | | |||
| | Tensor.abs | 支持 | | | |||
| | Tensor.absolute | 支持 | | | |||
| | Tensor.acos | 支持 | | | |||
| | Tensor.acosh | 支持 | | | |||
| | Tensor.new | 支持 | | | |||
| | Tensor.new_tensor | 支持 | | | |||
| | Tensor.new_full | 支持 | | | |||
| | Tensor.new_empty | 支持 | | | |||
| | Tensor.new_ones | 支持 | | | |||
| | Tensor.new_zeros | 支持 | | | |||
| | Tensor.is_cuda | 支持 | | | |||
| | Tensor.ndim | 支持 | | | |||
| | Tensor.add | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.addbmm | 支持 | | | |||
| | Tensor.addcdiv | 支持 | | | |||
| | Tensor.addcmul | 支持 | | | |||
| | Tensor.addmm | 支持 | | | |||
| | Tensor.addmv | 支持 | | | |||
| | Tensor.addr | 支持 | | | |||
| | Tensor.all | 支持 | | | |||
| | Tensor.allclose | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.amax | 支持 | | | |||
| | Tensor.amin | 支持 | | | |||
| | Tensor.aminmax | 支持 | | | |||
| | Tensor.any | 支持 | | | |||
| | Tensor.arccos | 支持 | | | |||
| | Tensor.arccosh | 支持 | | | |||
| | Tensor.arcsin | 支持 | | | |||
| | Tensor.arcsinh | 支持 | | | |||
| | Tensor.arctan | 支持 | | | |||
| | Tensor.arctan2 | 支持 | | | |||
| | Tensor.arctanh | 支持 | | | |||
| | Tensor.asin | 支持 | | | |||
| | Tensor.asinh | 支持 | | | |||
| | Tensor.atan | 支持 | | | |||
| | Tensor.atan2 | 支持 | | | |||
| | Tensor.atanh | 支持 | | | |||
| | Tensor.baddbmm | 支持 | | | |||
| | Tensor.bincount | 支持 | | | |||
| | Tensor.bitwise_and | 支持 | | | |||
| | Tensor.bitwise_left_shift | 支持 | | | |||
| | Tensor.bitwise_not | 支持 | | | |||
| | Tensor.bitwise_or | 支持 | | | |||
| | Tensor.bitwise_right_shift | 支持 | | | |||
| | Tensor.bitwise_xor | 支持 | | | |||
| | Tensor.bmm | 支持 | | | |||
| | Tensor.bool | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.broadcast_to | 支持 | | | |||
| | Tensor.byte | 支持 | | | |||
| | Tensor.ceil | 支持 | | | |||
| | Tensor.char | 支持 | | | |||
| | Tensor.cholesky | 支持 | | | |||
| | Tensor.cholesky_inverse | 部分支持 | 暂不支持GPU后端 | | |||
| | Tensor.clamp | 支持 | | | |||
| | Tensor.clip | 支持 | | | |||
| | Tensor.clone | 支持 | | | |||
| | Tensor.conj | 支持 | | | |||
| | Tensor.copysign | 支持 | | | |||
| | Tensor.cos | 支持 | | | |||
| | Tensor.cosh | 支持 | | | |||
| | Tensor.count_nonzero | 支持 | | | |||
| | Tensor.cpu | 支持 | | | |||
| | Tensor.cummax | 部分支持 | 暂不支持Ascend后端 | | |||
| | Tensor.cummin | 支持 | | | |||
| | Tensor.cumprod | 支持 | | | |||
| | Tensor.cumsum | 支持 | | | |||
| | Tensor.data | 支持 | | | |||
| | Tensor.deg2rad | 支持 | | | |||
| | Tensor.detach | 支持 | | | |||
| | Tensor.diag | 支持 | | | |||
| | Tensor.diagflat | 支持 | | | |||
| | Tensor.diagonal | 支持 | | | |||
| | Tensor.diff | 支持 | | | |||
| | Tensor.dim | 支持 | | | |||
| | Tensor.dist | 支持 | | | |||
| | Tensor.divide | 支持 | | | |||
| | Tensor.dot | 支持 | | | |||
| | Tensor.double | 支持 | | | |||
| | Tensor.dsplit | 支持 | | | |||
| | Tensor.eig | 部分支持 | 暂不支持GPU后端 | | |||
| | Tensor.eq | 支持 | | | |||
| | Tensor.equal | 支持 | | | |||
| | Tensor.erf | 支持 | | | |||
| | Tensor.erfc | 支持 | | | |||
| | Tensor.erfinv | 支持 | | | |||
| | Tensor.exp | 支持 | | | |||
| | Tensor.expand_as | 支持 | | | |||
| | Tensor.expm1 | 支持 | | | |||
| | Tensor.fix | 支持 | | | |||
| | Tensor.flatten | 支持 | | | |||
| | Tensor.flip | 支持 | | | |||
| | Tensor.flipud | 支持 | | | |||
| | Tensor.float_power | 支持 | | | |||
| | Tensor.floor | 支持 | | | |||
| | Tensor.fmod | 支持 | | | |||
| | Tensor.gather | 支持 | | | |||
| | Tensor.ge | 支持 | | | |||
| | Tensor.ger | 支持 | | | |||
| | Tensor.greater | 支持 | | | |||
| | Tensor.greater_equal | 支持 | | | |||
| | Tensor.gt | 支持 | | | |||
| | Tensor.half | 支持 | | | |||
| | Tensor.hardshrink | 支持 | | | |||
| | Tensor.heaviside | 支持 | | | |||
| | Tensor.hsplit | 支持 | | | |||
| | Tensor.hypot | 支持 | | | |||
| | Tensor.index_select | 支持 | | | |||
| | Tensor.int | 支持 | | | |||
| | Tensor.is_complex | 支持 | | | |||
| | Tensor.isclose | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.isfinite | 支持 | | | |||
| | Tensor.isinf | 支持 | | | |||
| | Tensor.isnan | 支持 | | | |||
| | Tensor.isneginf | 支持 | | | |||
| | Tensor.isposinf | 支持 | | | |||
| | Tensor.isreal | 支持 | | | |||
| | Tensor.is_tensor | 支持 | | | |||
| | Tensor.item | 支持 | | | |||
| | Tensor.le | 支持 | | | |||
| | Tensor.less | 支持 | | | |||
| | Tensor.less_equal | 支持 | | | |||
| | Tensor.log | 支持 | | | |||
| | Tensor.log10 | 支持 | | | |||
| | Tensor.log1p | 支持 | | | |||
| | Tensor.log2 | 支持 | | | |||
| | Tensor.logaddexp | 支持 | | | |||
| | Tensor.logdet | 支持 | | | |||
| | Tensor.logical_not | 支持 | | | |||
| | Tensor.logical_or | 支持 | | | |||
| | Tensor.logical_xor | 支持 | | | |||
| | Tensor.logsumexp | 支持 | | | |||
| | Tensor.long | 支持 | | | |||
| | Tensor.lt | 支持 | | | |||
| | Tensor.lu | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.lu_solve | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.lstsq | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.masked_fill | 支持 | | | |||
| | Tensor.matmul | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.max | 支持 | | | |||
| | Tensor.maximum | 支持 | | | |||
| | Tensor.mean | 支持 | | | |||
| | Tensor.min | 支持 | | | |||
| | Tensor.fmax | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.fmin | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.histc | 部分支持 | 暂不支持GPU后端 | | |||
| | Tensor.minimum | 支持 | | | |||
| | Tensor.moveaxis | 支持 | | | |||
| | Tensor.movedim | 支持 | | | |||
| | Tensor.mul | 支持 | | | |||
| | Tensor.multiply | 支持 | | | |||
| | Tensor.mvlgamma | 支持 | | | |||
| | Tensor.nanmean | 支持 | | | |||
| | Tensor.nansum | 支持 | | | |||
| | Tensor.narrow | 支持 | | | |||
| | Tensor.ndimension | 支持 | | | |||
| | Tensor.ne | 支持 | | | |||
| | Tensor.neg | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.negative | 支持 | | | |||
| | Tensor.nonzero | 支持 | | | |||
| | Tensor.not_equal | 支持 | | | |||
| | Tensor.numel | 支持 | | | |||
| | Tensor.numpy | 支持 | | | |||
| | Tensor.orgqr | 支持 | | | |||
| | Tensor.permute | 支持 | | | |||
| | Tensor.pow | 支持 | | | |||
| | Tensor.prod | 支持 | | | |||
| | Tensor.qr | 支持 | | | |||
| | Tensor.rad2deg | 支持 | | | |||
| | Tensor.ravel | 支持 | | | |||
| | Tensor.random_ | 支持 | | | |||
| | Tensor.reciprocal | 支持 | | | |||
| | Tensor.remainder | 支持 | | | |||
| | Tensor.renorm | 支持 | | | |||
| | Tensor.repeat | 支持 | | | |||
| | Tensor.repeat_interleave | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.reshape | 支持 | | | |||
| | Tensor.reshape_as | 支持 | | | |||
| | Tensor.resize_as_ | 支持 | | | |||
| | Tensor.round | 支持 | | | |||
| | Tensor.roll | 支持 | | | |||
| | Tensor.rot90| 支持 | | | |||
| | Tensor.rsqrt_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.rsqrt | 支持 | | | |||
| | Tensor.select | 支持 | | | |||
| | Tensor.short | 支持 | | | |||
| | Tensor.sigmoid | 支持 | | | |||
| | Tensor.sign | 支持 | | | |||
| | Tensor.signbit | 支持 | | | |||
| | Tensor.sin | 支持 | | | |||
| | Tensor.sinc | 支持 | | | |||
| | Tensor.sinh | 支持 | | | |||
| | Tensor.size | 支持 | | | |||
| | Tensor.sort | 支持 | | | |||
| | Tensor.split | 支持 | | | |||
| | Tensor.sqrt | 支持 | | | |||
| | Tensor.square | 支持 | | | |||
| | Tensor.squeeze | 支持 | | | |||
| | Tensor.stride | 支持 | | | |||
| | Tensor.sub | 支持 | | | |||
| | Tensor.subtract | 支持 | | | |||
| | Tensor.sum | 支持 | | | |||
| | Tensor.swapaxes | 支持 | | | |||
| | Tensor.swapdims | 支持 | | | |||
| | Tensor.T | 支持 | | | |||
| | Tensor.t | 支持 | | | |||
| | Tensor.H | 支持 | | | |||
| | Tensor.take | 支持 | | | |||
| | Tensor.tan | 支持 | | | |||
| | Tensor.tanh | 支持 | | | |||
| | Tensor.tensor_split | 支持 | | | |||
| | Tensor.tile | 支持 | | | |||
| | Tensor.tolist | 支持 | | | |||
| | Tensor.topk | 支持 | | | |||
| | Tensor.trace | 支持 | | | |||
| | Tensor.transpose | 支持 | | | |||
| | Tensor.tril | 支持 | | | |||
| | Tensor.tril_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.triu | 支持 | | | |||
| | Tensor.triu_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.true_divide | 支持 | | | |||
| | Tensor.true_divide_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.trunc | 支持 | | | |||
| | Tensor.type | 支持 | | | |||
| | Tensor.type_as | 支持 | | | |||
| | Tensor.unbind | 支持 | | | |||
| | Tensor.uniform_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.unique_consecutive | 支持 | | | |||
| | Tensor.unsqueeze | 支持 | | | |||
| | Tensor.var | 支持 | | | |||
| | Tensor.vdot | 支持 | | | |||
| | Tensor.view_as | 支持 | | | |||
| | Tensor.vsplit | 支持 | | | |||
| | Tensor.xlogy_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.argmin | 支持 | | | |||
| | Tensor.argsort | 支持 | | | |||
| | Tensor.as_strided | 支持 | | | |||
| | Tensor.bernoulli | 支持 | | | |||
| | Tensor.bernoulli_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.cauchy_ | 部分支持 | 暂不支持图模式,暂不支持GPU后端 | | |||
| | Tensor.chunk | 支持 | | | |||
| | Tensor.contiguous | 支持 | | | |||
| | Tensor.cross | 部分支持 | 暂不支持GPU后端 | | |||
| | Tensor.cuda | 支持 | | | |||
| | Tensor.det | 支持 | | | |||
| | Tensor.digamma | 部分支持 | [输入参数有限制](ConstraintList.md) | | |||
| | Tensor.div | 支持 | | | |||
| | Tensor.expand | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.fliplr | 部分支持 | 暂不支持Ascend后端 | | |||
| | Tensor.float | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.index_fill | 支持 | | | |||
| | Tensor.inverse | 部分支持 | 暂不支持Ascend后端 | | |||
| | Tensor.is_floating_point | 支持 | | | |||
| | Tensor.norm | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.real | 支持 | | | |||
| | Tensor.scatter_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.scatter | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.std | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.svd | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.to | 支持 | | | |||
| | Tensor.unique | 支持 | | | |||
| | Tensor.view | 支持 | | | |||
| | Tensor.where | 支持 | | | |||
| | Tensor.xlogy | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.abs_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.absolute_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.acos_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.arccos_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.add_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.addbmm_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.addcdiv_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.addcmul_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.addmm_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.addmv_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.addr_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.asin_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.arcsin_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.atan_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.arctan_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.atan2_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.arctan2_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.baddbmm_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.bitwise_not_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.bitwise_and_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.bitwise_or_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.bitwise_xor_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.clamp_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.clip_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.copy_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.copysign_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.acosh_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.arccosh_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.cumprod_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.div_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.divide_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.eq_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.expm1_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.fix_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.fill_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.float_power_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.floor_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.fmod_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.ge_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.greater_equal_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.gt_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.greater_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.hypot_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.le_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.less_equal_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.lgamma_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.logical_xor_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.lt_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.less_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.mul_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.multiply_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.mvlgamma_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.ne_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.not_equal_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.neg_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.negative_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.pow_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.reciprocal_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.renorm_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.resize_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.round_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.sigmoid_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.sign_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.sin_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.sinc_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.sinh_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.asinh_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.square_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.sqrt_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.squeeze_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.sub_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.tan_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.tanh_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.atanh_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.arctanh_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.transpose_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.trunc_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.unsqueeze_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.zero_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.is_conj | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.resolve_conj | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.i0 | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.nextafter | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.logit | 支持 | | | |||
| | Tensor.matrix_power | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.index_fill_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.index_add | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.index_add_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.scatter_add | 支持 | | | |||
| | Tensor.scatter_add_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.index_copy | 支持 | | | |||
| | Tensor.index_copy_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.diag_embed | 支持 | | | |||
| | Tensor.resolve_neg | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.i0_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.logit_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.pinverse | 部分支持 | 暂不支持Ascend后端 | | |||
| | Tensor.symeig | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.put_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.index_put | 支持 | | | |||
| | Tensor.index_put_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.nan_to_num | 支持 | | | |||
| | Tensor.nan_to_num_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.unfold | 支持 | | | |||
| | Tensor.logcumsumexp | 支持 | | | |||
| | Tensor.nextafter_ | 部分支持 | [输入参数有限制](ConstraintList.md) | | |||
| | Tensor.lgamma | 部分支持 | [输入参数有限制](ConstraintList.md) | | |||
| | Tensor.log2_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.logaddexp2 | 支持 | | | |||
| | Tensor.logical_and | 支持 | | | |||
| | Tensor.logical_and_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.logical_not_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.logical_or_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.igamma | 支持 | | | |||
| | Tensor.igamma_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.igammac | 支持 | | | |||
| | Tensor.igammac_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.positive | 支持 | | | |||
| | Tensor.remainder_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.sgn | 支持 | | | |||
| | Tensor.sgn_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.subtract_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.argmax | 支持 | | | |||
| | Tensor.gcd | 支持 | | | |||
| | Tensor.histogram | 支持 | | | |||
| | Tensor.lcm | 支持 | | | |||
| | Tensor.geqrf | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.inner | 支持 | | | |||
| | Tensor.kthvalue | 支持 | | | |||
| | Tensor.adjoint | 支持 | | | |||
| | Tensor.angle | 支持 | | | |||
| | Tensor.argwhere | 支持 | | | |||
| | Tensor.cov | 支持 | | | |||
| | Tensor.element_size | 支持 | | | |||
| | Tensor.is_signed | 支持 | | | |||
| | Tensor.masked_select | 支持 | | | |||
| | Tensor.median | 支持 | | | |||
| | Tensor.mv | 支持 | | | |||
| | Tensor.multinomial | 支持 | | | |||
| | Tensor.nelement | 支持 | | | |||
| | Tensor.outer | 支持 | | | |||
| | Tensor.slice_scatter | 支持 | | | |||
| | Tensor.select_scatter | 支持 | | | |||
| | Tensor.slogdet | 支持 | | | |||
| | Tensor.sum_to_size | 支持 | | | |||
| | Tensor.take_along_dim | 支持 | | | |||
| | Tensor.unflatten | 支持 | | | |||
| | Tensor.conj_physical | 支持 | | | |||
| | Tensor.conj_physical_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.arcsinh_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.bitwise_right_shift_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.ceil_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.cos_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.cosh_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.cumsum_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.digamma_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.erf_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.erfc_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.erfinv_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.exp_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.fill_diagonal_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.floor_divide | 支持 | | | |||
| | Tensor.floor_divide_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.frac | 支持 | | | |||
| | Tensor.frac_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.gcd_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.lcm_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.imag | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.ldexp | 支持 | | | |||
| | Tensor.ldexp_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.log_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.log10_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.log1p_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.masked_fill_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.normal_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.scatter_reduce | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.scatter_reduce_ | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.exponential_ | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.index_reduce | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.index_reduce_ | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.masked_scatter | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.masked_scatter_ | 部分支持 | 暂不支持图模式和GPU后端 | | |||
| | Tensor.index_put | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.index_put_ | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.corrcoef | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.geometric_ | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.log_normal_ | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.map_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.diagonal_scatter | 支持 | | | |||
| | Tensor.apply_ | 部分支持 | 暂不支持图模式 | | |||
| ### <span id="jump4">Torch.nn</span> | |||
| | MSAdapter接口 | 状态 | 约束 | | |||
| | --------------- | -------------------- | -------------- | | |||
| | nn.ModuleDict | 部分支持 | 暂不支持图模式 | | |||
| | nn.ParameterList | 部分支持 | 暂不支持图模式 | | |||
| | nn.ParameterDict | 部分支持 | 暂不支持图模式 | | |||
| | nn.Unfold | 支持 | | | |||
| | nn.Fold | 支持 | | | |||
| | nn.MaxPool1d | 支持 | | | |||
| | nn.MaxPool2d | 支持 | | | |||
| | nn.MaxPool3d | 支持 | | | |||
| | nn.AvgPool1d | 支持 | | | |||
| | nn.AvgPool2d | 支持 | | | |||
| | nn.AvgPool3d | 支持 | | | |||
| | nn.FractionalMaxPool2d | 支持 | | | |||
| | nn.FractionalMaxPool3d | 支持 | | | |||
| | nn.LPPool1d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.LPPool2d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.AdaptiveMaxPool1d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.AdaptiveMaxPool2d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.AdaptiveMaxPool3d | 支持 | | | |||
| | nn.AdaptiveAvgPool1d | 支持 | | | |||
| | nn.AdaptiveAvgPool2d | 支持 | | | |||
| | nn.AdaptiveAvgPool3d | 支持 | | | |||
| | nn.ReflectionPad1d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.ReflectionPad2d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.ReflectionPad3d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.ReplicationPad1d | 支持 | | | |||
| | nn.ReplicationPad2d | 支持 | | | |||
| | nn.ReplicationPad3d | 支持 | | | |||
| | nn.ZeroPad2d | 支持 | | | |||
| | nn.ConstantPad1d | 支持 | | | |||
| | nn.ConstantPad2d | 支持 | | | |||
| | nn.ConstantPad3d | 支持 | | | |||
| | nn.ELU | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.Hardshrink | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.Hardsigmoid | 支持 | | | |||
| | nn.Hardtanh | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.Hardswish | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.LeakyReLU | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.LogSigmoid | 支持 | | | |||
| | nn.PReLU | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.ReLU | 支持 | | | |||
| | nn.ReLU6 | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.RReLU | 部分支持 | inplace不支持图模式 | | |||
| | nn.SELU | 部分支持 | inplace不支持图模式 | | |||
| | nn.CELU | 部分支持 | inplace不支持图模式 | | |||
| | nn.GELU | 支持 | | | |||
| | nn.Sigmoid | 支持 | | | |||
| | nn.SiLU | 支持 | | | |||
| | nn.Mish | 部分支持 | inplace不支持图模式 | | |||
| | nn.Softplus | 支持 | | | |||
| | nn.Softshrink | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.Softsign | 支持 | | | |||
| | nn.Tanh | 支持 | | | |||
| | nn.Tanhshrink | 支持 | | | |||
| | nn.Threshold | 部分支持 | inplace不支持图模式 | | |||
| | nn.GLU | 支持 | | | |||
| | nn.Softmin | 支持 | | | |||
| | nn.Softmax | 支持 | | | |||
| | nn.Softmax2d | 支持 | | | |||
| | nn.LogSoftmax | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.BatchNorm1d | 支持 | | | |||
| | nn.BatchNorm2d | 支持 | | | |||
| | nn.BatchNorm3d | 支持 | | | |||
| | nn.LazyBatchNorm1d | 不支持 | | | |||
| | nn.LazyBatchNorm2d | 不支持 | | | |||
| | nn.LazyBatchNorm3d | 不支持 | | | |||
| | nn.GroupNorm | 支持 | | | |||
| | nn.LayerNorm | 支持 | | | |||
| | nn.LocalResponseNorm | 支持 | | | |||
| | nn.RNNBase | 支持 | | | |||
| | nn.RNN | 支持 | | | |||
| | nn.RNNCell | 支持 | | | |||
| | nn.LSTMCell | 支持 | | | |||
| | nn.GRUCell | 支持 | | | |||
| | nn.Identity | 支持 | | | |||
| | nn.Linear | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.Bilinear | 支持 | | | |||
| | nn.LazyLinear | 支持 | | | |||
| | nn.Dropout | 部分支持 | `inplace`不支持图模式 | | |||
| | nn.Dropout1d | 部分支持 | `inplace`不支持图模式 | | |||
| | nn.Dropout2d | 部分支持 | `inplace`不支持图模式 | | |||
| | nn.Dropout3d | 部分支持 | `inplace`不支持图模式 | | |||
| | nn.AlphaDropout | 部分支持 | `inplace`不支持图模式 | | |||
| | nn.FeatureAlphaDropout | 部分支持 | `inplace`不支持图模式 | | |||
| | nn.CosineSimilarity | 支持 | | | |||
| | nn.PairwiseDistance | 支持 | | | |||
| | nn.L1Loss | 支持 | | | |||
| | nn.MSELoss | 支持 | | | |||
| | nn.CrossEntropyLoss | 支持 | | | |||
| | nn.CTCLoss | 支持 | | | |||
| | nn.NLLLoss | 支持 | | | |||
| | nn.PoissonNLLLoss | 支持 | | | |||
| | nn.GaussianNLLLoss | 支持 | | | |||
| | nn.BCELoss | 支持 | | | |||
| | nn.BCEWithLogitsLoss | 支持 | | | |||
| | nn.MarginRankingLoss | 支持 | | | |||
| | nn.HingeEmbeddingLoss | 支持 | | | |||
| | nn.HuberLoss | 支持 | | | |||
| | nn.SmoothL1Loss | 支持 | | | |||
| | nn.SoftMarginLoss | 部分支持 | 暂不支持CPU后端 | | |||
| | nn.MultiLabelSoftMarginLoss | 支持 | | | |||
| | nn.CosineEmbeddingLoss | 支持 | | | |||
| | nn.TripletMarginWithDistanceLoss | 支持 | | | |||
| | nn.PixelShuffle | 支持 | | | |||
| | nn.PixelUnshuffle | 支持 | | | |||
| | nn.Upsample | 支持 | | | |||
| | nn.UpsamplingNearest2d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.UpsamplingBilinear2d | 支持 | | | |||
| | nn.ChannelShuffle | 支持 | | | |||
| | nn.Flatten | 支持 | | | |||
| | nn.Unflatten | 支持 | | | |||
| | nn.Module | 支持 | | | |||
| | nn.Sequential | 支持 | | | |||
| | nn.ModuleList | 支持 | | | |||
| | nn.Conv1d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.Conv2d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.Conv3d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.ConvTranspose1d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.ConvTranspose2d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.ConvTranspose3d | 支持 | | | |||
| | nn.LazyConv1d | 不支持 | | | |||
| | nn.LazyConv2d | 不支持 | | | |||
| | nn.LazyConv3d | 不支持 | | | |||
| | nn.LazyConvTranspose1d | 不支持 | | | |||
| | nn.LazyConvTranspose2d | 不支持 | | | |||
| | nn.LazyConvTranspose3d | 不支持 | | | |||
| | nn.MaxUnpool1d | 支持 | | | |||
| | nn.MaxUnpool2d | 支持 | | | |||
| | nn.MaxUnpool3d | 支持 | | | |||
| | nn.MultiheadAttention | 支持 | | | |||
| | nn.AdaptiveLogSoftmaxWithLoss | 部分支持 | 暂不支持图模式 | | |||
| | nn.SyncBatchNorm | 部分支持 | 仅支持Ascend后端 | | |||
| | nn.InstanceNorm1d | 部分支持 | 仅支持GPU后端 | | |||
| | nn.InstanceNorm2d | 部分支持 | 仅支持GPU后端 | | |||
| | nn.InstanceNorm3d | 部分支持 | 仅支持GPU后端 | | |||
| | nn.LazyInstanceNorm1d | 不支持 | | | |||
| | nn.LazyInstanceNorm2d | 不支持 | | | |||
| | nn.LazyInstanceNorm3d | 不支持 | | | |||
| | nn.LSTM | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.GRU | 支持 | | | |||
| | nn.Embedding | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.KLDivLoss | 支持 | | | |||
| | nn.MultiLabelMarginLoss | 部分支持 | 暂不支持CPU后端 | | |||
| | nn.MultiMarginLoss | 支持 | | | |||
| | nn.Module.named_module | 支持 | | | |||
| | nn.TripletMarginLoss | 支持 | | | |||
| | nn.Transformer | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.TransformerEncoder | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.TransformerDecoder | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.TransformerEncoderLayer | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.TransformerDecoderLayer | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.utils.rnn.pad_sequence | 支持 | | | |||
| | nn.utils.rnn.pack_padded_sequence | 支持 | | | |||
| | nn.utils.rnn.PackedSequence | 支持 | | | |||
| | nn.utils.rnn.pad_packed_sequence | 支持 | | | |||
| | nn.utils.rnn.pack_sequence | 支持 | | | |||
| | nn.init.eye_ | 部分支持 | 暂不支持图模式 | | |||
| | nn.init.dirac_ | 部分支持 | 暂不支持图模式 | | |||
| | nn.init.orthogonal_ | 部分支持 | 暂不支持图模式 | | |||
| ### <span id="jump5">nn.functional</span> | |||
| | MSAdapter接口 | 状态 | 约束 | | |||
| | --------------- | -------------------- | -------------- | | |||
| | functional.max_pool2d | 支持 | | | |||
| | functional.max_pool3d | 支持 | | | |||
| | functional.conv_transpose2d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.conv_transpose3d | 支持 | | | |||
| | functional.avg_pool2d | 支持 | | | |||
| | functional.avg_pool3d | 支持 | | | |||
| | functional.max_pool1d | 支持 | | | |||
| | functional.max_unpool1d | 支持 | | | |||
| | functional.max_unpool2d | 支持 | | | |||
| | functional.max_unpool3d | 支持 | | | |||
| | functional.lp_pool1d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.lp_pool2d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.adaptive_max_pool1d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.adaptive_max_pool2d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.adaptive_avg_pool1d | 支持 | | | |||
| | functional.fractional_max_pool2d | 支持 | | | |||
| | functional.fractional_max_pool3d | 支持 | | | |||
| | functional.threshold | 支持 | | | |||
| | functional.threshold_ | 部分支持 | 暂不支持图模式 | | |||
| | functional.relu | 支持 | | | |||
| | functional.relu_ | 部分支持 | 暂不支持图模式 | | |||
| | functional.hardtanh | 支持 | | | |||
| | functional.hardtanh_ | 部分支持 | 暂不支持图模式 | | |||
| | functional.hardswish | 支持 | | | |||
| | functional.relu6 | 支持 | | | |||
| | functional.elu | 支持 | | | |||
| | functional.elu_ | 部分支持 | 暂不支持图模式 | | |||
| | functional.selu | 支持 | | | |||
| | functional.celu | 支持 | | | |||
| | functional.leaky_relu | 支持 | | | |||
| | functional.leaky_relu_ | 部分支持 | 暂不支持图模式 | | |||
| | functional.prelu | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.rrelu | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.rrelu_ | 部分支持 | 暂不支持图模式 | | |||
| | functional.glu | 支持 | | | |||
| | functional.gelu | 支持 | | | |||
| | functional.logsigmoid | 支持 | | | |||
| | functional.hardshrink | 支持 | | | |||
| | functional.tanhshrink | 支持 | | | |||
| | functional.softsign | 支持 | | | |||
| | functional.softplus | 支持 | | | |||
| | functional.softmin | 支持 | | | |||
| | functional.softmax | 支持 | | | |||
| | functional.softshrink | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.gumbel_softmax | 支持 | | | |||
| | functional.log_softmax | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.tanh | 支持 | | | |||
| | functional.sigmoid | 支持 | | | |||
| | functional.hardsigmoid | 支持 | | | |||
| | functional.silu | 支持 | | | |||
| | functional.mish | 支持 | | | |||
| | functional.batch_norm | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.group_norm | 支持 | | | |||
| | functional.instance_norm | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.layer_norm | 支持 | | | |||
| | functional.local_response_norm | 支持 | | | |||
| | functional.normalize | 支持 | | | |||
| | functional.linear | 支持 | | | |||
| | functional.bilinear | 支持 | | | |||
| | functional.dropout | 支持 | | | |||
| | functional.alpha_dropout | 部分支持 | `inplace`不支持图模式 | | |||
| | functional.feature_alpha_dropout | 部分支持 | `inplace`不支持图模式 | | |||
| | functional.dropout1d | 部分支持 | `inplace`不支持图模式 | | |||
| | functional.dropout2d | 部分支持 | `inplace`不支持图模式 | | |||
| | functional.dropout3d | 部分支持 | `inplace`不支持图模式 | | |||
| | functional.one_hot | 支持 | | | |||
| | functional.pairwise_distance | 支持 | | | |||
| | functional.cosine_similarity | 支持 | | | |||
| | functional.pdist | 支持 | | | |||
| | functional.binary_cross_entropy | 支持 | | | |||
| | functional.binary_cross_entropy_with_logits | 支持 | | | |||
| | functional.poisson_nll_loss | 支持 | | | |||
| | functional.cosine_embedding_loss | 支持 | | | |||
| | functional.cross_entropy | 支持 | | | |||
| | functional.gaussian_nll_loss | 支持 | | | |||
| | functional.hinge_embedding_loss | 支持 | | | |||
| | functional.l1_loss | 支持 | | | |||
| | functional.mse_loss | 支持 | | | |||
| | functional.margin_ranking_loss | 支持 | | | |||
| | functional.multilabel_soft_margin_loss | 支持 | | | |||
| | functional.nll_loss | 支持 | | | |||
| | functional.smooth_l1_loss | 支持 | | | |||
| | functional.soft_margin_loss | 部分支持 | 暂不支持CPU后端 | | |||
| | functional.triplet_margin_loss | 支持 | | | |||
| | functional.triplet_margin_with_distance_loss | 支持 | | | |||
| | functional.pixel_shuffle | 支持 | | | |||
| | functional.pixel_unshuffle | 支持 | | | |||
| | functional.grid_sample | 支持 | | | |||
| | functional.huber_loss | 支持 | | | |||
| | functional.conv1d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.conv2d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.conv3d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.conv_transpose1d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.unfold | 支持 | | | |||
| | functional.fold | 支持 | | | |||
| | functional.adaptive_max_pool3d | 支持 | | | |||
| | functional.adaptive_avg_pool2d | 支持 | | | |||
| | functional.adaptive_avg_pool3d | 支持 | | | |||
| | functional.embedding | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.ctc_loss | 支持 | | | |||
| | functional.kl_div | 支持 | | | |||
| | functional.multilabel_margin_loss | 部分支持 | 暂不支持CPU后端 | | |||
| | functional.multi_margin_loss | 支持 | | | |||
| | functional.interpolate | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.upsample | 支持 | | | |||
| | functional.upsample_nearest | 支持 | | | |||
| | functional.upsample_bilinear | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.affine_grid | 支持 | | | |||
| | functional.avg_pool1d | 支持 | | | |||
| ### <span id="jump6">torch.linalg</span> | |||
| | MSAdapter接口 | 状态 | 约束 | | |||
| | --------------- | -------------------- | -------------- | | |||
| | norm | 部分支持 | [功能存在限制](ConstraintList.md)| | |||
| | vector_norm | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | matrix_norm | 不支持 | | | |||
| | diagonal | 支持 | | | |||
| | det | 支持 | | | |||
| | slogdet | 支持 | | | |||
| | cond | 不支持 | | | |||
| | matrix_rank | 不支持 | | | |||
| | cholesky | 不支持 | | | |||
| | qr | 不支持 | | | |||
| | lu | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | lu_factor | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | lu_factor_ex | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | lu_solve | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | eig | 部分支持 | 暂不支持GPU后端 | | |||
| | eigvals | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | eigh | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | eigvalsh | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | svd | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | svdvals | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | solve | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | solve_triangular | 不支持 | | | |||
| | lstsq | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | inv | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | pinv | 部分支持 | 暂不支持Ascend后端 | | |||
| | qr | 支持| | | |||
| | matrix_exp | 不支持 | | | |||
| | matrix_power | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | cross | 不支持 | | | |||
| | matmul | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | vecdot | 不支持 | | | |||
| | multi_dot | 支持 | | | |||
| | householder_product | 支持 | | | |||
| | tensorinv | 不支持 | | | |||
| | tensorsolve | 不支持 | | | |||
| | vander | 支持 | | | |||
| | cholesky_ex | 不支持 | | | |||
| | inv_ex | 不支持 | | | |||
| | solve_ex | 不支持 | | | |||
| | lu_factor_ex | 不支持 | | | |||
| | ldl_factor | 不支持 | | | |||
| | ldl_factor_ex | 不支持 | | | |||
| | ldl_solve | 不支持 | | | |||
| | eigh | 支持 | | | |||
| | solve | 支持 | | | |||
| ### <span id="jump7">torch.optim</span> | |||
| | MSAdapter接口 | 状态 | 约束 | | |||
| | --------------- | -------------------- | -------------- | | |||
| | Optimizer | 不支持 | 请使用[mindspore.nn.Optimizer](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.Optimizer.html?highlight=optimizer#mindspore.nn.Optimizer)代替| | |||
| | Adadelta | 不支持 | 请使用[mindspore.nn.Adadelta](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.Adadelta.html?highlight=adadelta#mindspore.nn.Adadelta)代替| | |||
| | Adagrad | 不支持 | 请使用[mindspore.nn.Adagrad](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.Adagrad.html?highlight=adagrad#mindspore.nn.Adagrad)代替| | |||
| | Adam | 不支持 | 请使用[mindspore.nn.Adam](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.Adam.html?highlight=adam#mindspore.nn.Adam)代替| | |||
| | AdamW | 不支持 | 请使用[mindspore.nn.AdamWeightDecay](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.AdamWeightDecay.html?highlight=adamw#mindspore.nn.AdamWeightDecay)代替| | |||
| | SparseAdam | 不支持 | | | |||
| | Adamax | 不支持 | 请使用[mindspore.nn.AdaMax](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.AdaMax.html?highlight=adamax#mindspore.nn.AdaMax)代替| | |||
| | ASGD | 不支持 | 请使用[mindspore.nn.ASGD](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.ASGD.html?highlight=asgd#mindspore.nn.ASGD)代替| | |||
| | LBFGS | 不支持 | | | |||
| | NAdam | 不支持 | | | |||
| | RAdam | 不支持 | | | |||
| | RMSprop | 不支持 | 请使用[mindspore.nn.RMSprop](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.RMSProp.html?highlight=rmsprop#mindspore.nn.RMSProp)代替| | |||
| | Rprop | 不支持 | 请使用[mindspore.nn.Rprop](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.Rprop.html?highlight=rprop#mindspore.nn.Rprop)代替 | | |||
| | SGD | 不支持 | 请使用[mindspore.nn.SGD](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.SGD.html?highlight=sgd#mindspore.nn.SGD)代替| | |||
+ 1183
- 0
SupportedList_en.md
View File
| @@ -0,0 +1,1183 @@ | |||
| English | [简体中文](SupportedList.md) | |||
| - [List of PyTorch APIs supported by MSAdapter](#jump1) | |||
| - [Torch](#jump2) | |||
| - [Tensor](#jump3) | |||
| - [Torch.nn](#jump4) | |||
| - [nn.functional](#jump5) | |||
| - [torch.linalg](#jump6) | |||
| - [torch.optim](#jump7) | |||
| ### <span id="jump8">General Constraint</span> | |||
| - Not support the function of configuration `layout`, `device`, `requires_grad`, `memory_format`. | |||
| - Not support `Generator` that manages the state of the algorithm which produces pseudo random numbers. | |||
| - Not support 7D and higher dimensions calculations. | |||
| - The Complex type function is being improved. | |||
| - Ascend not fully support float64 type value as input, if the function is not applicable for float64, please try float32 and float16 instead. | |||
| - The function of [PyTorch APIs that support tensor to be a view](https://pytorch.org/docs/1.12/tensor_view.html) is constrained. Currently MSAdapter does not support sharing memory between the input and output tensor, but copying the data. | |||
| - On Ascend and GPU, there are differences between mindspore and pytorch in the processing overflow results, such as the upper limits of int16 and int32. Therefore, it is not recommended to assign input parameters exceed the upper or lower limits, or to convert data that significantly exceeds the data type to a smaller range of data types to avoid unexpected results. | |||
| - For the function with note "Function is constrained", please check the [APIs Constraints List](ConstraintList_en.md) for more details. | |||
| ## <span id="jump1">List of PyTorch APIs supported by MSAdapter</span> | |||
| ### <span id="jump2">Torch</span> | |||
| | MSAdapter APIs | Status | Restrictions | | |||
| | --------------- | -------------------- | -------------- | | |||
| | torch.is_tensor | Supported | | | |||
| | torch.is_floating_point | Supported | | | |||
| | torch.arange | Supported | | | |||
| | torch.cat | Supported | | | |||
| | torch.tensor | Supported | | | |||
| | torch.as_tensor | Supported | | | |||
| | torch.from_numpy | Supported | | | |||
| | torch.frombuffer | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.permute | Supported | | | |||
| | torch.bitwise_left_shift | Supported | | | |||
| | torch.bitwise_right_shift | Supported | | | |||
| | torch.nan_to_num | Supported | | | |||
| | torch.range | Supported | | | |||
| | torch.linspace | Supported | | | |||
| | torch.logspace | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.eye | Supported | | | |||
| | torch.empty | Supported | | | |||
| | torch.empty_like | Supported | | | |||
| | torch.eig | Partly supported | Currently not support on GPU | | |||
| | torch.full | Supported | | | |||
| | torch.full_like | Supported | | | |||
| | torch.polar | Supported | | | |||
| | torch.concat | Supported | | | |||
| | torch.column_stack | Supported | | | |||
| | torch.gather | Supported | | | |||
| | torch.is_complex | Supported | | | |||
| | torch.hstack | Supported | | | |||
| | torch.index_select | Supported | | | |||
| | torch.masked_select | Supported | | | |||
| | torch.movedim | Supported | | | |||
| | torch.moveaxis | Supported | | | |||
| | torch.narrow | Supported | | | |||
| | torch.nonzero | Supported | | | |||
| | torch.numel | Supported | | | |||
| | torch.reshape | Supported | | | |||
| | torch.row_stack | Supported | | | |||
| | torch.select | Supported | | | |||
| | torch.zeros | Supported | | | |||
| | torch.squeeze | Supported | | | |||
| | torch.stack | Supported | | | |||
| | torch.swapaxes | Supported | | | |||
| | torch.swapdims | Supported | | | |||
| | torch.zeros_like | Supported | | | |||
| | torch.take | Supported | | | |||
| | torch.ones | Supported | | | |||
| | torch.tile | Supported | | | |||
| | torch.transpose | Supported | | | |||
| | torch.unbind | Supported | | | |||
| | torch.unsqueeze | Supported | | | |||
| | torch.ones_like | Supported | | | |||
| | torch.vstack | Supported | | | |||
| | torch.heaviside | Supported | | | |||
| | torch.seed | Supported | | | |||
| | torch.initial_seed | Supported | | | |||
| | torch.rand | Supported | | | |||
| | torch.randn | Supported | | | |||
| | torch.abs | Supported | | | |||
| | torch.absolute | Supported | | | |||
| | torch.acos | Supported | | | |||
| | torch.adjoint | Supported | | | |||
| | torch.acosh | Supported | | | |||
| | torch.arccosh | Supported | | | |||
| | torch.add | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.addcdiv | Supported | | | |||
| | torch.addcmul | Supported | | | |||
| | torch.dsplit | Supported | | | |||
| | torch.asin | Supported | | | |||
| | torch.arcsin | Supported | | | |||
| | torch.asinh | Supported | | | |||
| | torch.arcsinh | Supported | | | |||
| | torch.atan | Supported | | | |||
| | torch.arctan | Supported | | | |||
| | torch.atanh | Supported | | | |||
| | torch.arctanh | Supported | | | |||
| | torch.atan2 | Supported | | | |||
| | torch.arctan2 | Supported | | | |||
| | torch.bitwise_not | Supported | | | |||
| | torch.bitwise_and | Supported | | | |||
| | torch.bitwise_or | Supported | | | |||
| | torch.bitwise_xor | Supported | | | |||
| | torch.hsplit | Supported | | | |||
| | torch.split | Supported | | | |||
| | torch.ceil | Supported | | | |||
| | torch.t | Supported | | | |||
| | torch.tensor_split | Supported | | | |||
| | torch.conj_physical | Supported | | | |||
| | torch.copysign | Supported | | | |||
| | torch.cos | Supported | | | |||
| | torch.cosh | Supported | | | |||
| | torch.deg2rad | Supported | | | |||
| | torch.device | Supported | | | |||
| | torch.div | Supported | | | |||
| | torch.divide | Supported | | | |||
| | torch.erf | Supported | | | |||
| | torch.erfc | Supported | | | |||
| | torch.erfinv | Supported | | | |||
| | torch.exp | Supported | | | |||
| | torch.exp2 | Supported | | | |||
| | torch.expm1 | Supported | | | |||
| | torch.fix | Supported | | | |||
| | torch.vsplit | Supported | | | |||
| | torch.floor | Supported | | | |||
| | torch.floor_divide | Supported | | | |||
| | torch.where | Supported | | | |||
| | torch.frac | Supported | | | |||
| | torch.frexp | Supported | | | |||
| | torch.finfo | Supported | | | |||
| | torch.iinfo | Supported | | | |||
| | torch.ldexp | Supported | | | |||
| | torch.lerp | Supported | | | |||
| | torch.arccos | Supported | | | |||
| | torch.log | Supported | | | |||
| | torch.angle | Supported | | | |||
| | torch.log1p | Supported | | | |||
| | torch.clamp | Supported | | | |||
| | torch.logaddexp | Supported | | | |||
| | torch.logaddexp2 | Supported | | | |||
| | torch.logical_not | Supported | | | |||
| | torch.logical_or | Supported | | | |||
| | torch.logit | Supported | | | |||
| | torch.clip | Supported | | | |||
| | torch.float_power | Partly Supported | [Input type is constrained](ConstraintList_en.md) | | |||
| | torch.igammac | Supported | | | |||
| | torch.mul | Supported | | | |||
| | torch.fmod | Supported | | | |||
| | torch.lgamma | Partly supported | [Input type is constrained](ConstraintList_en.md) | | |||
| | torch.neg | Supported | | | |||
| | torch.log10 | Supported | | | |||
| | torch.nextafter | Partly supported | [Input type is constrained](ConstraintList_en.md) | | |||
| | torch.positive | Supported | | | |||
| | torch.pow | Supported | | | |||
| | torch.rad2deg | Supported | | | |||
| | torch.log2 | Supported | | | |||
| | torch.hypot | Supported | | | |||
| | torch.remainder | Supported | | | |||
| | torch.round | Supported | | | |||
| | torch.sigmoid | Supported | | | |||
| | torch.multiply | Supported | | | |||
| | torch.negative | Supported | | | |||
| | torch.sin | Supported | | | |||
| | torch.reciprocal | Supported | | | |||
| | torch.sinh | Supported | | | |||
| | torch.sqrt | Supported | | | |||
| | torch.roll | Supported | | | |||
| | torch.rot90 | Supported | | | |||
| | torch.square | Supported | | | |||
| | torch.sub | Supported | | | |||
| | torch.rsqrt | Supported | | | |||
| | torch.tan | Supported | | | |||
| | torch.tanh | Supported | | | |||
| | torch.sign | Supported | | | |||
| | torch.trunc | Supported | | | |||
| | torch.xlogy | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.amax | Supported | | | |||
| | torch.amin | Supported | | | |||
| | torch.aminmax | Supported | | | |||
| | torch.all | Supported | | | |||
| | torch.any | Supported | | | |||
| | torch.min | Supported | | | |||
| | torch.dist | Supported | | | |||
| | torch.logsumexp | Supported | | | |||
| | torch.nanmean | Supported | | | |||
| | torch.nansum | Supported | | | |||
| | torch.prod | Supported | | | |||
| | torch.qr | Supported | | | |||
| | torch.std | Supported | | | |||
| | torch.sgn | Supported | | | |||
| | torch.unique_consecutive | Supported | | | |||
| | torch.var | Supported | | | |||
| | torch.count_nonzero | Supported | | | |||
| | torch.allclose | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.signbit | Supported | | | |||
| | torch.eq | Supported | | | |||
| | torch.equal | Supported | | | |||
| | torch.ge | Supported | | | |||
| | torch.greater_equal | Supported | | | |||
| | torch.gt | Supported | | | |||
| | torch.greater | Supported | | | |||
| | torch.isclose | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.isfinite | Supported | | | |||
| | torch.isin | Supported | | | |||
| | torch.isinf | Supported | | | |||
| | torch.isposinf | Supported | | | |||
| | torch.isneginf | Supported | | | |||
| | torch.isnan | Supported | | | |||
| | torch.isreal | Supported | | | |||
| | torch.is_nonzero | Supported | | | |||
| | torch.le | Supported | | | |||
| | torch.less_equal | Supported | | | |||
| | torch.lt | Supported | | | |||
| | torch.less | Supported | | | |||
| | torch.lu | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.lu_solve | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.lu_unpack | Partly supported | Currently not support on Ascend | | |||
| | torch.maximum | Supported | | | |||
| | torch.minimum | Supported | | | |||
| | torch.ne | Supported | | | |||
| | torch.sinc | Supported | | | |||
| | torch.subtract | Supported | | | |||
| | torch.topk | Supported | | | |||
| | torch.true_divide | Supported | | | |||
| | torch.atleast_1d | Supported | | | |||
| | torch.atleast_2d | Supported | | | |||
| | torch.atleast_3d | Supported | | | |||
| | torch.block_diag | Supported | | | |||
| | torch.broadcast_to | Supported | | | |||
| | torch.cdist | Supported | | | |||
| | torch.corrcoef | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.cov | Supported | | | |||
| | torch.cummin | Supported | | | |||
| | torch.cumprod | Supported | | | |||
| | torch.cumsum | Supported | | | |||
| | torch.diag | Supported | | | |||
| | torch.diagflat | Supported | | | |||
| | torch.diagonal | Supported | | | |||
| | torch.diff | Supported | | | |||
| | torch.flatten | Supported | | | |||
| | torch.flip | Supported | | | |||
| | torch.flipud | Supported | | | |||
| | torch.histc | Partly supported | Currently not support on GPU | | |||
| | torch.meshgrid | Supported | | | |||
| | torch.ravel | Supported | | | |||
| | torch.not_equal | Supported | | | |||
| | torch.trace | Supported | | | |||
| | torch.tril | Supported | | | |||
| | torch.triu | Supported | | | |||
| | torch.sort | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.msort | Supported | | | |||
| | torch.addmv | Supported | | | |||
| | torch.addr | Supported | | | |||
| | torch.bincount | Supported | | | |||
| | torch.bmm | Supported | | | |||
| | torch.cholesky | Supported | | | |||
| | torch.cholesky_inverse | Partly supported | Currently not support on GPU | | |||
| | torch.dot | Supported | | | |||
| | torch.repeat_interleave | Partly Supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.addbmm | Supported | | | |||
| | torch.det | Supported | | | |||
| | torch.addmm | Supported | | | |||
| | torch.matmul | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.mv | Supported | | | |||
| | torch.orgqr | Supported | | | |||
| | torch.outer | Supported | | | |||
| | torch.vdot | Supported | | | |||
| | torch._assert | Supported | | | |||
| | torch.inner | Supported | | | |||
| | torch.logdet | Supported | | | |||
| | torch.lstsq | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.mm | Supported | | | |||
| | torch.cuda.is_available | Supported | | | |||
| | torch.ByteTensor | Supported | | | |||
| | torch.CharTensor | Supported | | | |||
| | torch.IntTensor | Supported | | | |||
| | torch.HalfTensor | Supported | | | |||
| | torch.FloatTensor | Supported | | | |||
| | torch.DoubleTensor | Supported | | | |||
| | torch.ByteStorage | Supported | | | |||
| | torch.as_strided | Supported | | | |||
| | torch.view_as_real | Supported | | | |||
| | torch.scatter | Unsupported | | | |||
| | torch.manual_seed | Supported | | | |||
| | torch.matrix_exp | Unspported | | | |||
| | torch.bernoulli | Supported | | | |||
| | torch.multinomial | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.randint | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.randperm | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.digamma | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.fft | Partly supported | [Function is constrained](ConstraintList_en.md) | | | |||
| | torch.gradient | Supported | | | |||
| | torch.imag | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.logical_and | supported | | | |||
| | torch.logical_xor | Supported | | | |||
| | torch.igamma | Supported | | | |||
| | torch.mvlgamma | Supported | | | |||
| | torch.i0 | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.real | Supported | | | |||
| | torch.argmax | Supported | | | |||
| | torch.argmin | Supported | | | |||
| | torch.max | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.mean | Supported | | | |||
| | torch.median | Supported | | | |||
| | torch.norm | Partly Supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.normal | Supported | | | |||
| | torch.unique | Supported | | | |||
| | torch.bartlett_window | Supported | | | |||
| | torch.sum | Partly supported | Currently not support on GRAPH mode | | |||
| | torch.hann_window | Supported | | | |||
| | torch.argsort | Supported | | | |||
| | torch.cross | Partly supported | Currently not support on GPU | | |||
| | torch.cummax | Partly supported | Currently not support on Ascend | | |||
| | torch.einsum | Partly supported | Only support on GPU | | |||
| | torch.fliplr | Supported | | | |||
| | torch.hamming_window | Supported | | | |||
| | torch.svd | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.searchsorted | Supported | | | |||
| | torch.fmax | Partly supported | Only support on CPU | | |||
| | torch.fmin | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.inverse | Partly supported | Currently not support on Ascend | | |||
| | torch.poisson | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.polygamma | Partly supported | Currently not support on Ascend | | |||
| | torch.matrix_power | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.vander | Supported | | | |||
| | torch.renorm | Supported | | | |||
| | torch.conj | Partly supported | Currently not support on GRAPH mode | | |||
| | torch.is_conj | Partly supported | Currently not support on GRAPH mode | | |||
| | torch.resolve_conj | Partly supported | Currently not support on GRAPH mode | | |||
| | torch.index_add | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.scatter_reduce | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.scatter_add | Supported | | | |||
| | torch.index_copy | Supported | | | |||
| | torch.histogramdd | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.diag_embed | Supported | | | |||
| | torch.resolve_neg | Partly supported | Currently not support on GRAPH mode | | |||
| | torch.pinverse | Partly supported | Currently not support on Ascend | | |||
| | torch.asarray | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.symeig | Partly supported | Currently not support on Ascend | | |||
| | torch.result_type | Supported | | | |||
| | torch.logcumsumexp | Supported | | | |||
| | torch.complex | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.blackman_window | Supported | | | |||
| | torch.kaiser_window | Supported | | | |||
| | torch.bucketize | Supported | | | |||
| | torch.cartesian_prod | Supported | | | |||
| | torch.clone | Supported | | | |||
| | torch.clone | combinations | | | |||
| | torch.kron | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.gcd | Supported | | | |||
| | torch.histogram | Supported | | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.lcm | Supported | | | |||
| | torch.tensordot | Supported | | | |||
| | torch.tril_indices | Supported | | | |||
| | torch.triu_indices | Supported | | | |||
| | torch.geqrf | Partly Supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.trapz | Supported | | | |||
| | torch.trapezoid | Supported | | | |||
| | torch.kthvalue | Supported | | | |||
| | torch.slice_scatter | Supported | | | |||
| | torch.select_scatter | Supported | | | |||
| | torch.take_along_dim | Supported | | | |||
| | torch.pad | Partly supported | 1.Currently not support on GRAPH mode. 2.[Function is constrained](ConstraintList_en.md) | | |||
| | torch.broadcast_shapes | Supported | | | |||
| | torch.broadcast_tensors | Supported | | | |||
| | torch.index_reduce | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.chain_matmul | Supported | | | |||
| | torch.view_as_complex | Partly Supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.empty_strided | Supported | | | |||
| | torch.cumulative_trapezoid | Supported | | | |||
| | torch.can_cast | Supported | | | |||
| | torch.diagonal_scatter | Supported | | | |||
| | torch.rfft | Partly supported | [Function is constrained](ConstraintList_en.md) | | | |||
| ### <span id="jump3">Tensor</span> | |||
| | MSAdapter APIs | Status | Restrictions | | |||
| | --------------- | -------------------- | -------------- | | |||
| | Tensor.mm | Supported | | | |||
| | Tensor.msort | Supported | | | |||
| | Tensor.abs | Supported | | | |||
| | Tensor.absolute | Supported | | | |||
| | Tensor.acos | Supported | | | |||
| | Tensor.acosh | Supported | | | |||
| | Tensor.new | Supported | | | |||
| | Tensor.new_tensor | Supported | | | |||
| | Tensor.new_full | Supported | | | |||
| | Tensor.new_empty | Supported | | | |||
| | Tensor.new_ones | Supported | | | |||
| | Tensor.new_zeros | Supported | | | |||
| | Tensor.is_cuda | Supported | | | |||
| | Tensor.ndim | Supported | | | |||
| | Tensor.add | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.addbmm | Supported | | | |||
| | Tensor.addcdiv | Supported | | | |||
| | Tensor.addcmul | Supported | | | |||
| | Tensor.addmm | Supported | | | |||
| | Tensor.addmv | Supported | | | |||
| | Tensor.addr | Supported | | | |||
| | Tensor.all | Supported | | | |||
| | Tensor.allclose | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.amax | Supported | | | |||
| | Tensor.amin | Supported | | | |||
| | Tensor.aminmax | Supported | | | |||
| | Tensor.any | Supported | | | |||
| | Tensor.arccos | Supported | | | |||
| | Tensor.arccosh | Supported | | | |||
| | Tensor.arcsin | Supported | | | |||
| | Tensor.arcsinh | Supported | | | |||
| | Tensor.arctan | Supported | | | |||
| | Tensor.arctan2 | Supported | | | |||
| | Tensor.arctanh | Supported | | | |||
| | Tensor.asin | Supported | | | |||
| | Tensor.asinh | Supported | | | |||
| | Tensor.atan | Supported | | | |||
| | Tensor.atan2 | Supported | | | |||
| | Tensor.atanh | Supported | | | |||
| | Tensor.baddbmm | Supported | | | |||
| | Tensor.bincount | Supported | | | |||
| | Tensor.bitwise_and | Supported | | | |||
| | Tensor.bitwise_left_shift | Supported | | | |||
| | Tensor.bitwise_not | Supported | | | |||
| | Tensor.bitwise_or | Supported | | | |||
| | Tensor.bitwise_right_shift | Supported | | | |||
| | Tensor.bitwise_xor | Supported | | | |||
| | Tensor.bmm | Supported | | | |||
| | Tensor.bool | Partly supported | [Function is constrained](ConstraintList_en.md)| | |||
| | Tensor.broadcast_to | Supported | | | |||
| | Tensor.byte | Supported | | | |||
| | Tensor.ceil | Supported | | | |||
| | Tensor.char | Supported | | | |||
| | Tensor.cholesky | Supported | | | |||
| | Tensor.cholesky_inverse | Partly supported | Currently not support on GPU | | |||
| | Tensor.clamp | Supported | | | |||
| | Tensor.clip | Supported | | | |||
| | Tensor.clone | Supported | | | |||
| | Tensor.conj | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.copysign | Supported | | | |||
| | Tensor.cos | Supported | | | |||
| | Tensor.cosh | Supported | | | |||
| | Tensor.count_nonzero | Supported | | | |||
| | Tensor.cpu | Supported | | | |||
| | Tensor.cummax | Partly supported | Currently not support on Ascend | | |||
| | Tensor.cummin | Supported | | | |||
| | Tensor.cumprod | Supported | | | |||
| | Tensor.cumsum | Supported | | | |||
| | Tensor.data | Supported | | | |||
| | Tensor.deg2rad | Supported | | | |||
| | Tensor.detach | Supported | | | |||
| | Tensor.diag | Supported | | | |||
| | Tensor.diagflat | Supported | | | |||
| | Tensor.diagonal | Supported | | | |||
| | Tensor.diff | Supported | | | |||
| | Tensor.dim | Supported | | | |||
| | Tensor.dist | Supported | | | |||
| | Tensor.divide | Supported | | | |||
| | Tensor.dot | Supported | | | |||
| | Tensor.double | Supported | | | |||
| | Tensor.dsplit | Supported | | | |||
| | Tensor.eig | Partly supported | Currently not support on GPU | | |||
| | Tensor.eq | Supported | | | |||
| | Tensor.equal | Supported | | | |||
| | Tensor.erf | Supported | | | |||
| | Tensor.erfc | Supported | | | |||
| | Tensor.erfinv | Supported | | | |||
| | Tensor.exp | Supported | | | |||
| | Tensor.expand_as | Supported | | | |||
| | Tensor.expm1 | Supported | | | |||
| | Tensor.fix | Supported | | | |||
| | Tensor.flatten | Supported | | | |||
| | Tensor.flip | Supported | | | |||
| | Tensor.flipud | Supported | | | |||
| | Tensor.float_power | Supported | | | |||
| | Tensor.floor | Supported | | | |||
| | Tensor.fmod | Supported | | | |||
| | Tensor.gather | Supported | | | |||
| | Tensor.ge | Supported | | | |||
| | Tensor.ger | Supported | | | |||
| | Tensor.greater | Supported | | | |||
| | Tensor.greater_equal | Supported | | | |||
| | Tensor.gt | Supported | | | |||
| | Tensor.half | Supported | | | |||
| | Tensor.hardshrink | Supported | | | |||
| | Tensor.heaviside | Supported | | | |||
| | Tensor.hsplit | Supported | | | |||
| | Tensor.hypot | Supported | | | |||
| | Tensor.index_select | Supported | | | |||
| | Tensor.int | Supported | | | |||
| | Tensor.is_complex | Supported | | | |||
| | Tensor.isclose | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.isfinite | Supported | | | |||
| | Tensor.isinf | Supported | | | |||
| | Tensor.isnan | Supported | | | |||
| | Tensor.isneginf | Supported | | | |||
| | Tensor.isposinf | Supported | | | |||
| | Tensor.isreal | Supported | | | |||
| | Tensor.is_tensor | Supported | | | |||
| | Tensor.item | Supported | | | |||
| | Tensor.le | Supported | | | |||
| | Tensor.less | Supported | | | |||
| | Tensor.less_equal | Supported | | | |||
| | Tensor.log | Supported | | | |||
| | Tensor.log10 | Supported | | | |||
| | Tensor.log1p | Supported | | | |||
| | Tensor.log2 | Supported | | | |||
| | Tensor.logaddexp | Supported | | | |||
| | Tensor.logdet | Supported | | | |||
| | Tensor.logical_not | Supported | | | |||
| | Tensor.logical_or | Supported | | | |||
| | Tensor.logical_xor | Supported | | | |||
| | Tensor.logsumexp | Supported | | | |||
| | Tensor.long | Supported | | | |||
| | Tensor.lt | Supported | | | |||
| | Tensor.lu | Partly supported | Currently not support on Ascend | | |||
| | Tensor.lu_solve | Partly supported | Currently not support on Ascend | | |||
| | Tensor.lstsq | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.masked_fill | Supported | | | |||
| | Tensor.matmul | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.max | Supported | | | |||
| | Tensor.maximum | Supported | | | |||
| | Tensor.mean | Supported | | | |||
| | Tensor.min | Supported | | | |||
| | Tensor.fmax | Partly supported | Only support on CPU | | |||
| | Tensor.fmin | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.histc | Partly supported | Currently not support on GPU | | |||
| | Tensor.minimum | Supported | | | |||
| | Tensor.moveaxis | Supported | | | |||
| | Tensor.movedim | Supported | | | |||
| | Tensor.mul | Supported | | | |||
| | Tensor.multiply | Supported | | | |||
| | Tensor.mvlgamma | Supported | | | |||
| | Tensor.nanmean | Supported | | | |||
| | Tensor.nansum | Supported | | | |||
| | Tensor.narrow | Supported | | | |||
| | Tensor.ndimension | Supported | | | |||
| | Tensor.ne | Supported | | | |||
| | Tensor.neg | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.negative | Supported | | | |||
| | Tensor.nonzero | Supported | | | |||
| | Tensor.not_equal | Supported | | | |||
| | Tensor.numel | Supported | | | |||
| | Tensor.numpy | Supported | | | |||
| | Tensor.orgqr | Supported | | | |||
| | Tensor.permute | Supported | | | |||
| | Tensor.pow | Supported | | | |||
| | Tensor.prod | Supported | | | |||
| | Tensor.qr | Supported | | | |||
| | Tensor.rad2deg | Supported | | | |||
| | Tensor.ravel | Supported | | | |||
| | Tensor.random_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.reciprocal | Supported | | | |||
| | Tensor.remainder | Supported | | | |||
| | Tensor.renorm | Supported | | | |||
| | Tensor.repeat | Supported | | | |||
| | Tensor.repeat_interleave | Partly Supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.reshape | Supported | | | |||
| | Tensor.reshape_as | Supported | | | |||
| | Tensor.resize_as_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.round | Supported | | | |||
| | Tensor.roll | Supported | | | |||
| | Tensor.rot90 | Supported | | | |||
| | Tensor.rsqrt_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.rsqrt | Supported | | | |||
| | Tensor.select | Supported | | | |||
| | Tensor.short | Supported | | | |||
| | Tensor.sigmoid | Supported | | | |||
| | Tensor.sign | Supported | | | |||
| | Tensor.signbit | Supported | | | |||
| | Tensor.sin | Supported | | | |||
| | Tensor.sinc | Supported | | | |||
| | Tensor.sinh | Supported | | | |||
| | Tensor.size | Supported | | | |||
| | Tensor.sort | Supported | | | |||
| | Tensor.split | Supported | | | |||
| | Tensor.sqrt | Supported | | | |||
| | Tensor.square | Supported | | | |||
| | Tensor.squeeze | Supported | | | |||
| | Tensor.stride | Supported | | | |||
| | Tensor.sub | Supported | | | |||
| | Tensor.subtract | Supported | | | |||
| | Tensor.sum | Supported | | | |||
| | Tensor.swapaxes | Supported | | | |||
| | Tensor.swapdims | Supported | | | |||
| | Tensor.T | Supported | | | |||
| | Tensor.t | Supported | | | |||
| | Tensor.H | Supported | | | |||
| | Tensor.take | Supported | | | |||
| | Tensor.tan | Supported | | | |||
| | Tensor.tanh | Supported | | | |||
| | Tensor.tensor_split | Supported | | | |||
| | Tensor.tile | Supported | | | |||
| | Tensor.tolist | Supported | | | |||
| | Tensor.topk | Supported | | | |||
| | Tensor.trace | Supported | | | |||
| | Tensor.transpose | Supported | | | |||
| | Tensor.tril | Supported | | | |||
| | Tensor.tril_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.triu | Supported | | | |||
| | Tensor.triu_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.true_divide | Supported | | | |||
| | Tensor.true_divide_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.trunc | Supported | | | |||
| | Tensor.type | Supported | | | |||
| | Tensor.type_as | Supported | | | |||
| | Tensor.unbind | Supported | | | |||
| | Tensor.uniform_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.unique_consecutive | Supported | | | |||
| | Tensor.unsqueeze | Supported | | | |||
| | Tensor.var | Supported | | | |||
| | Tensor.vdot | Supported | | | |||
| | Tensor.view_as | Supported | | | |||
| | Tensor.vsplit | Supported | | | |||
| | Tensor.xlogy_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.argmin | Supported | | | |||
| | Tensor.argsort | Supported | | | |||
| | Tensor.as_strided | Supported | | | |||
| | Tensor.bernoulli | Supported | | | |||
| | Tensor.bernoulli_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.cauchy_ | Partly supported | Currently not support on GPU and GRAPH mode | | |||
| | Tensor.chunk | Supported | | | |||
| | Tensor.contiguous | Supported | | | |||
| | Tensor.cross | Partly supported | Currently not support on GPU | | |||
| | Tensor.cuda | Supported | | | |||
| | Tensor.det | Supported | | | |||
| | Tensor.digamma | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.div | Supported | | | |||
| | Tensor.expand | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.fliplr | Partly supported | Currently not support on Ascend | | |||
| | Tensor.float | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.index_fill | Supported | | | |||
| | Tensor.inverse | Partly supported | Currently not support on Ascend | | |||
| | Tensor.is_floating_point | Supported | | | |||
| | Tensor.norm | Partyly Supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.real | Supported | | | |||
| | Tensor.scatter_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.scatter | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.std | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.svd | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.to | Supported | | | |||
| | Tensor.unique | Supported | | | |||
| | Tensor.view | Supported | | | |||
| | Tensor.where | Supported | | | |||
| | Tensor.xlogy | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.abs_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.absolute_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.acos_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.arccos_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.add_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.addbmm_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.addcdiv_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.addcmul_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.addmm_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.addmv_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.addr_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.asin_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.arcsin_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.atan_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.arctan_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.atan2_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.arctan2_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.baddbmm_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.bitwise_not_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.bitwise_and_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.bitwise_or_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.bitwise_xor_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.clamp_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.clip_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.copy_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.copysign_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.acosh_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.arccosh_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.cumprod_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.div_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.divide_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.eq_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.expm1_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.fix_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.fill_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.float_power_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.floor_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.fmod_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.ge_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.greater_equal_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.gt_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.greater_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.hypot_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.le_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.less_equal_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.lgamma_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.logical_xor_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.lt_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.less_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.mul_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.multiply_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.mvlgamma_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.ne_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.not_equal_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.neg_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.negative_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.pow_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.reciprocal_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.renorm_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.resize_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.round_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.sigmoid_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.sign_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.sin_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.sinc_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.sinh_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.asinh_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.square_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.sqrt_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.squeeze_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.sub_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.tan_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.tanh_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.atanh_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.arctanh_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.transpose_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.trunc_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.unsqueeze_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.zero_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.is_conj | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.resolve_conj | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.i0 | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.nextafter | Partly supported | [Input type is constrained](ConstraintList_en.md) | | |||
| | Tensor.logit | Supported | | | |||
| | Tensor.matrix_power | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.index_fill_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.index_add | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.index_add_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.scatter_add | Supported | | | |||
| | Tensor.scatter_add_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.index_copy | Supported | | | |||
| | Tensor.index_copy_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.diag_embed | Supported | | | |||
| | Tensor.resolve_neg | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.i0_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.logit_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.pinverse | Partly supported | Currently not support on Ascend | | |||
| | Tensor.symeig | Partly supported | Currently not support on Ascend | | |||
| | Tensor.put_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.index_put | Supported | | | |||
| | Tensor.index_put_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.nan_to_num | Supported | | | |||
| | Tensor.nan_to_num_ | Partly supported | Currently not support on Ascend | | |||
| | Tensor.logcumsumexp | Supported | | | |||
| | Tensor.nextafter_ | Partly supported | [Input type is constrained](ConstraintList_en.md) | | |||
| | Tensor.lgamma | Partly supported | [Input type is constrained](ConstraintList_en.md) | | |||
| | Tensor.log2_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.logaddexp2 | Supported | | | |||
| | Tensor.logical_and | Supported | | | |||
| | Tensor.logical_and_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.logical_not_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.logical_or_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.igamma | Supported | | | |||
| | Tensor.igamma_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.igammac | Supported | | | |||
| | Tensor.igammac_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.positive | Supported | | | |||
| | Tensor.remainder_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.sgn | Supported | | | |||
| | Tensor.sgn_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.subtract_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.argmax | Supported | | | |||
| | Tensor.gcd | Supported | | | |||
| | Tensor.histogram | Supported | | | |||
| | Tensor.lcm | Supported | | | |||
| | Tensor.geqrf | Partly Supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.inner | Supported | | | |||
| | Tensor.kthvalue | Supported | | | |||
| | Tensor.adjoint | Supported | | | |||
| | Tensor.angle | Supported | | | |||
| | Tensor.argwhere | Supported | | | |||
| | Tensor.cov | Supported | | | |||
| | Tensor.element_size | Supported | | | |||
| | Tensor.is_signed | Supported | | | |||
| | Tensor.masked_select | Supported | | | |||
| | Tensor.median | Supported | | | |||
| | Tensor.mv | Supported | | | |||
| | Tensor.multinomial | Supported | | | |||
| | Tensor.nelement | Supported | | | |||
| | Tensor.outer | Supported | | | |||
| | Tensor.slice_scatter | Supported | | | |||
| | Tensor.select_scatter | Supported | | | |||
| | Tensor.slogdet | Supported | | | |||
| | Tensor.sum_to_size | Supported | | | |||
| | Tensor.take_along_dim | Supported | | | |||
| | Tensor.unflatten | Supported | | | |||
| | Tensor.unfold | Supported | | | |||
| | Tensor.conj_physical | Supported | | | |||
| | Tensor.conj_physical_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.arcsinh_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.bitwise_right_shift_ | Partly supported | Currently not support on GRAPH mode | |||
| | Tensor.ceil_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.cos_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.cosh_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.cumsum_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.digamma_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.erf_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.erfc_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.erfinv_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.exp_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.fill_diagonal_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.floor_divide | Supported | | | |||
| | Tensor.floor_divide_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.frac | Supported | | | |||
| | Tensor.frac_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.gcd_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.lcm_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.imag | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.ldexp | Supported | | | |||
| | Tensor.ldexp_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.log_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.log10_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.log1p_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.masked_fill_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.normal_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.scatter_reduce | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.scatter_reduce_ | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.exponential_ | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.index_reduce | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.index_reduce_ | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.masked_scatter | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.masked_scatter_ | Partly supported | Currently not support on GRAPH mode or on GPU | | |||
| | Tensor.index_put | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.index_put_ | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.corrcoef | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.geometric_ | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.log_normal_ | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.map_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.diagonal_scatter | Supported | | | |||
| | Tensor.apply_ | Partly Supported | Currently not support on GRAPH mode | | |||
| ### <span id="jump4">Torch.nn</span> | |||
| | MSAdapter APIs | Status | Restrictions | | |||
| | --------------- | -------------------- | -------------- | | |||
| | nn.ModuleDict | Partly supported | Currently not support on GRAPH mode | | |||
| | nn.ParameterList | Partly supported | Currently not support on GRAPH mode | | |||
| | nn.ParameterDict | Partly supported | Currently not support on GRAPH mode | | |||
| | nn.Unfold | Supported | | | |||
| | nn.Fold | Supported | | | |||
| | nn.MaxPool1d | Supported | | | |||
| | nn.MaxPool2d | Supported | | | |||
| | nn.MaxPool3d | Supported | | | |||
| | nn.AvgPool1d | Supported | | | |||
| | nn.AvgPool2d | Supported | | | |||
| | nn.AvgPool3d | Supported | | | |||
| | nn.FractionalMaxPool2d | Supported | | | |||
| | nn.FractionalMaxPool3d | Supported | | | |||
| | nn.LPPool1d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.LPPool2d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.AdaptiveMaxPool1d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.AdaptiveMaxPool2d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.AdaptiveMaxPool3d | Supported | | | |||
| | nn.AdaptiveAvgPool1d | Supported | | | |||
| | nn.AdaptiveAvgPool2d | Supported | | | |||
| | nn.AdaptiveAvgPool3d | Supported | | | |||
| | nn.ReflectionPad1d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.ReflectionPad2d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.ReflectionPad3d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.ReplicationPad1d | Supported | | | |||
| | nn.ReplicationPad2d | Supported | | | |||
| | nn.ReplicationPad3d | Supported | | | |||
| | nn.ZeroPad2d | Supported | | | |||
| | nn.ConstantPad1d | Supported | | | |||
| | nn.ConstantPad2d | Supported | | | |||
| | nn.ConstantPad3d | Supported | | | |||
| | nn.ELU | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.Hardshrink | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.Hardsigmoid | Supported | | | |||
| | nn.Hardtanh | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.Hardswish | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.LeakyReLU | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.LogSigmoid | Supported | | | |||
| | nn.PReLU | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.ReLU | Supported | | | |||
| | nn.ReLU6 | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.RReLU | Partly supported | inplace not support on GRAPH mode | | |||
| | nn.SELU | Partly supported | inplace not support on GRAPH mode | | |||
| | nn.CELU | Partly supported | inplace not support on GRAPH mode | | |||
| | nn.GELU | Supported | | | |||
| | nn.Sigmoid | Supported | | | |||
| | nn.SiLU | Supported | | | |||
| | nn.Mish | Partly supported | inplace not support on GRAPH mode | | |||
| | nn.Softplus | Supported | | | |||
| | nn.Softshrink | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.Softsign | Supported | | | |||
| | nn.Tanh | Supported | | | |||
| | nn.Tanhshrink | Supported | | | |||
| | nn.Threshold | Partly supported | inplace not support on GRAPH mode | | |||
| | nn.GLU | Supported | | | |||
| | nn.Softmin | Supported | | | |||
| | nn.Softmax | Supported | | | |||
| | nn.Softmax2d | Supported | | | |||
| | nn.LogSoftmax | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.BatchNorm1d | Supported | | | |||
| | nn.BatchNorm2d | Supported | | | |||
| | nn.BatchNorm3d | Supported | | | |||
| | nn.LazyBatchNorm1d | Unsupported | | | |||
| | nn.LazyBatchNorm2d | Unsupported | | | |||
| | nn.LazyBatchNorm3d | Unsupported | | | |||
| | nn.GroupNorm | Supported | | | |||
| | nn.LayerNorm | Supported | | | |||
| | nn.LocalResponseNorm | Supported | | | |||
| | nn.RNNBase | Supported | | | |||
| | nn.RNN | Supported | | | |||
| | nn.RNNCell | Supported | | | |||
| | nn.LSTMCell | Supported | | | |||
| | nn.GRUCell | Supported | | | |||
| | nn.Identity | Supported | | | |||
| | nn.Linear | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.Bilinear | Supported | | | |||
| | nn.LazyLinear | Supported | | | |||
| | nn.Dropout | Partly supported | `inplace` not support on GRAPH mode | | |||
| | nn.Dropout1d | Partly supported | `inplace` not support on GRAPH mode | | |||
| | nn.Dropout2d | Partly supported | `inplace` not support on GRAPH mode | | |||
| | nn.Dropout3d | Partly supported | `inplace` not support on GRAPH mode | | |||
| | nn.AlphaDropout | Partly supported | `inplace` not support on GRAPH mode | | |||
| | nn.FeatureAlphaDropout | Partly supported | `inplace` not support on GRAPH mode | | |||
| | nn.CosineSimilarity | Supported | | | |||
| | nn.PairwiseDistance | Supported | | | |||
| | nn.L1Loss | Supported | | | |||
| | nn.MSELoss | Supported | | | |||
| | nn.CrossEntropyLoss | Supported | | | |||
| | nn.CTCLoss | Supported | | | |||
| | nn.NLLLoss | Supported | | | |||
| | nn.PoissonNLLLoss | Supported | | | |||
| | nn.GaussianNLLLoss | Supported | | | |||
| | nn.BCELoss | Supported | | | |||
| | nn.BCEWithLogitsLoss | Supported | | | |||
| | nn.MarginRankingLoss | Supported | | | |||
| | nn.HingeEmbeddingLoss | Supported | | | |||
| | nn.HuberLoss | Supported | | | |||
| | nn.SmoothL1Loss | Supported | | | |||
| | nn.SoftMarginLoss | Partly supported | Currently not support on CPU | | |||
| | nn.MultiLabelSoftMarginLoss | Supported | | | |||
| | nn.CosineEmbeddingLoss | Supported | | | |||
| | nn.TripletMarginWithDistanceLoss | Supported | | | |||
| | nn.PixelShuffle | Supported | | | |||
| | nn.PixelUnshuffle | Supported | | | |||
| | nn.Upsample | Supported | | | |||
| | nn.UpsamplingNearest2d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.UpsamplingBilinear2d | Supported | | | |||
| | nn.ChannelShuffle | Supported | | | |||
| | nn.Flatten | Supported | | | |||
| | nn.Unflatten | Supported | | | |||
| | nn.Module | Supported | | | |||
| | nn.Sequential | Supported | | | |||
| | nn.ModuleList | Supported | | | |||
| | nn.Conv1d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.Conv2d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.Conv3d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.ConvTranspose1d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.ConvTranspose2d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.ConvTranspose3d | Supported | | | |||
| | nn.LazyConv1d | Unsupported | | | |||
| | nn.LazyConv2d | Unsupported | | | |||
| | nn.LazyConv3d | Unsupported | | | |||
| | nn.LazyConvTranspose1d | Unsupported | | | |||
| | nn.LazyConvTranspose2d | Unsupported | | | |||
| | nn.LazyConvTranspose3d | Unsupported | | | |||
| | nn.MaxUnpool1d | Supported | | | |||
| | nn.MaxUnpool2d | Supported | | | |||
| | nn.MaxUnpool3d | Supported | | | |||
| | nn.MultiheadAttention | Supported | | | |||
| | nn.AdaptiveLogSoftmaxWithLoss | Partly supported | Currently not support on GRAPH mode | | |||
| | nn.SyncBatchNorm | Partly supported | Only support on Ascend | | |||
| | nn.InstanceNorm1d | Partly supported | Only support on GPU | | |||
| | nn.InstanceNorm2d | Partly supported | Only support on GPU | | |||
| | nn.InstanceNorm3d | Partly supported | Only support on GPU | | |||
| | nn.LazyInstanceNorm1d | Unsupported | | | |||
| | nn.LazyInstanceNorm2d | Unsupported | | | |||
| | nn.LazyInstanceNorm3d | Unsupported | | | |||
| | nn.LSTM | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.GRU | Supported | | | |||
| | nn.Embedding | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.KLDivLoss | Supported | | | |||
| | nn.MultiLabelMarginLoss | Partly supported | Currently not support on CPU | | |||
| | nn.MultiMarginLoss | Supported | | | |||
| | nn.Module.named_module | Supported | | | |||
| | nn.TripletMarginLoss | Supported | | | |||
| | nn.Transformer | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.TransformerEncoder | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.TransformerDecoder | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.TransformerEncoderLayer | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.TransformerDecoderLayer | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.utils.rnn.pad_sequence | Supported | | | |||
| | nn.utils.rnn.pack_padded_sequence | Supported | | | |||
| | nn.utils.rnn.PackedSequence | Supported | | | |||
| | nn.utils.rnn.pad_packed_sequence | Supported | | | |||
| | nn.utils.rnn.pack_sequence | Supported | | | |||
| | nn.init.eye_ | Partly supported | Currently not support on GRAPH mode | | |||
| | nn.init.dirac_ | Partly supported | Currently not support on GRAPH mode | | |||
| | nn.init.orthogonal_ | Partly supported | Currently not support on GRAPH mode | | |||
| ### <span id="jump5">nn.functional</span> | |||
| | MSAdapter APIs | Status | Restrictions | | |||
| | --------------- | -------------------- | -------------- | | |||
| | functional.max_pool2d | Supported | | | |||
| | functional.max_pool3d | Supported | | | |||
| | functional.conv_transpose2d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.conv_transpose3d | Supported | | | |||
| | functional.avg_pool2d | Supported | | | |||
| | functional.avg_pool3d | Supported | | | |||
| | functional.max_pool1d | Supported | | | |||
| | functional.max_unpool1d | Supported | | | |||
| | functional.max_unpool2d | Supported | | | |||
| | functional.max_unpool3d | Supported | | | |||
| | functional.lp_pool1d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.lp_pool2d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.adaptive_max_pool1d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.adaptive_max_pool2d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.adaptive_avg_pool1d | Supported | | | |||
| | functional.fractional_max_pool2d | Supported | | | |||
| | functional.fractional_max_pool3d | Supported | | | |||
| | functional.threshold | Supported | | | |||
| | functional.threshold_ | Partly supported | Currently not support on GRAPH mode | | |||
| | functional.relu | Supported | | | |||
| | functional.relu_ | Partly supported | Currently not support on GRAPH mode | | |||
| | functional.hardtanh | Supported | | | |||
| | functional.hardtanh_ | Partly supported | Currently not support on GRAPH mode | | |||
| | functional.hardswish | Supported | | | |||
| | functional.relu6 | Supported | | | |||
| | functional.elu | Supported | | | |||
| | functional.elu_ | Partly supported | Currently not support on GRAPH mode | | |||
| | functional.selu | Supported | | | |||
| | functional.celu | Supported | | | |||
| | functional.leaky_relu | Supported | | | |||
| | functional.leaky_relu_ | Partly supported | Currently not support on GRAPH mode | | |||
| | functional.prelu | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.rrelu | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.rrelu_ | Partly supported | Currently not support on GRAPH mode | | |||
| | functional.glu | Supported | | | |||
| | functional.gelu | Supported | | | |||
| | functional.logsigmoid | Supported | | | |||
| | functional.hardshrink | Supported | | | |||
| | functional.tanhshrink | Supported | | | |||
| | functional.softsign | Supported | | | |||
| | functional.softplus | Supported | | | |||
| | functional.softmin | Supported | | | |||
| | functional.softmax | Supported | | | |||
| | functional.softshrink | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.gumbel_softmax | Supported | | | |||
| | functional.log_softmax | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.tanh | Supported | | | |||
| | functional.sigmoid | Supported | | | |||
| | functional.hardsigmoid | Supported | | | |||
| | functional.silu | Supported | | | |||
| | functional.mish | Supported | | | |||
| | functional.batch_norm | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.group_norm | Supported | | | |||
| | functional.instance_norm | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.layer_norm | Supported | | | |||
| | functional.local_response_norm | Supported | | | |||
| | functional.normalize | Supported | | | |||
| | functional.linear | Supported | | | |||
| | functional.bilinear | Supported | | | |||
| | functional.dropout | Partly supported | `inplace` not support on GRAPH mode | | |||
| | functional.alpha_dropout | Partly supported | `inplace` not support on GRAPH mode | | |||
| | functional.feature_alpha_dropout | Partly supported | `inplace` not support on GRAPH mode | | |||
| | functional.dropout1d | Partly supported | `inplace` not support on GRAPH mode | | |||
| | functional.dropout2d | Partly supported | `inplace` not support on GRAPH mode | | |||
| | functional.dropout3d | Partly supported | `inplace` not support on GRAPH mode | | |||
| | functional.one_hot | Supported | | | |||
| | functional.pairwise_distance | Supported | | | |||
| | functional.cosine_similarity | Supported | | | |||
| | functional.pdist | Supported | | | |||
| | functional.binary_cross_entropy | Supported | | | |||
| | functional.binary_cross_entropy_with_logits | Supported | | | |||
| | functional.poisson_nll_loss | Supported | | | |||
| | functional.cosine_embedding_loss | Supported | | | |||
| | functional.cross_entropy | Supported | | | |||
| | functional.gaussian_nll_loss | Supported | | | |||
| | functional.hinge_embedding_loss | Supported | | | |||
| | functional.l1_loss | Supported | | | |||
| | functional.mse_loss | Supported | | | |||
| | functional.margin_ranking_loss | Supported | | | |||
| | functional.multilabel_soft_margin_loss | Supported | | | |||
| | functional.nll_loss | Supported | | | |||
| | functional.smooth_l1_loss | Supported | | | |||
| | functional.soft_margin_loss | Partly supported | Currently not support on CPU | | |||
| | functional.triplet_margin_loss | Supported | | | |||
| | functional.triplet_margin_with_distance_loss | Supported | | | |||
| | functional.pixel_shuffle | Supported | | | |||
| | functional.pixel_unshuffle | Supported | | | |||
| | functional.grid_sample | Supported | | | |||
| | functional.huber_loss | Supported | | | |||
| | functional.conv1d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.conv2d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.conv3d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.conv_transpose1d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.unfold | Supported | | | |||
| | functional.fold | Supported | | | |||
| | functional.adaptive_max_pool3d | Supported | | | |||
| | functional.adaptive_avg_pool2d | Supported | | | |||
| | functional.adaptive_avg_pool3d | Supported | | | |||
| | functional.embedding | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.ctc_loss | Supported | | | |||
| | functional.kl_div | Supported | | | |||
| | functional.multilabel_margin_loss | Partly supported | Currently not support on CPU | | |||
| | functional.multi_margin_loss | Supported | | | |||
| | functional.interpolate | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.upsample | Supported | | | |||
| | functional.upsample_nearest | Supported | | | |||
| | functional.upsample_bilinear | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.affine_grid | Supported | | | |||
| | functional.avg_pool1d | Supported | | | |||
| ### <span id="jump6">torch.linalg</span> | |||
| | MSAdapter APIs | Status | Restrictions | | |||
| | --------------- | -------------------- | -------------- | | |||
| | norm | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | vector_norm | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | matrix_norm | Unsupported | | | |||
| | diagonal | Supported | | | |||
| | det | Supported | | | |||
| | slogdet | Supported | | | |||
| | cond | Unsupported | | | |||
| | matrix_rank | Unsupported | | | |||
| | cholesky | Unsupported | | | |||
| | qr | Unsupported | | | |||
| | lu | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | lu_factor | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | lu_factor_ex | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | lu_solve | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | eig | Partly supported | Currently not support on GPU | | |||
| | eigvals | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | eigh | SPartly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | eigvalsh | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | svd | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | svdvals | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | solve | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | solve_triangular | Unsupported | | | |||
| | lu_solve | Unsupported | | | |||
| | lstsq | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | inv | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | pinv | Unsupported | Currently not support on Ascend | | |||
| | qr | Supported| | | |||
| | matrix_exp | Unsupported | | | |||
| | matrix_power | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | cross | Unsupported | | | |||
| | matmul | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | vecdot | Unsupported | | | |||
| | multi_dot | Supported | | | |||
| | householder_product | Supported | | | |||
| | tensorinv | Unsupported | | | |||
| | tensorsolve | Unsupported | | | |||
| | vander | Supported | | | |||
| | cholesky_ex | Unsupported | | | |||
| | inv_ex | Unsupported | | | |||
| | solve_ex | Unsupported | | | |||
| | lu_factor_ex | Unsupported | | | |||
| | ldl_factor | Unsupported | | | |||
| | ldl_factor_ex | Unsupported | | | |||
| | ldl_solve | Unsupported | | | |||
| | eigh | Supported | | | |||
| | solve | Supported | | | |||
| ### <span id="jump7">torch.optim</span> | |||
| | MSAdapter APIs | Status | Restrictions | | |||
| | --------------- | -------------------- | -------------- | | |||
| | Optimizer | Unsupported | Please use [mindspore.nn.Optimizer](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.Optimizer.html#mindspore.nn.Optimizer) instead| | |||
| | Adadelta | Unsupported | Please use [mindspore.nn.Adadelta](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.Adadelta.html#mindspore.nn.Adadelta) instead| | |||
| | Adagrad | Unsupported | Please use [mindspore.nn.Adagrad](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.Adagrad.html#mindspore.nn.Adagrad) instead| | |||
| | Adam | Unsupported | Please use [mindspore.nn.Adam](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.Adam.html#mindspore.nn.Adam) instead| | |||
| | AdamW | Unsupported | Please use [mindspore.nn.AdamWeightDecay](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.AdamWeightDecay.html#mindspore.nn.AdamWeightDecay) instead| | |||
| | SparseAdam | Unsupported | | | |||
| | Adamax | Unsupported | Please use [mindspore.nn.AdaMax](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.AdaMax.html#mindspore.nn.AdaMax) instead| | |||
| | ASGD | Unsupported | Please use [mindspore.nn.ASGD](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.ASGD.html#mindspore.nn.ASGD) instead| | |||
| | LBFGS | Unsupported | | | |||
| | NAdam | Unsupported | | | |||
| | RAdam | Unsupported | | | |||
| | RMSprop | Unsupported | Please use [mindspore.nn.RMSprop](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.RMSProp.html#mindspore.nn.RMSProp) instead| | |||
| | Rprop | Unsupported | Please use [mindspore.nn.Rprop](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.Rprop.html#mindspore.nn.Rprop) instead | | |||
| | SGD | Unsupported | Please use [mindspore.nn.SGD](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.SGD.html#mindspore.nn.SGD) instead| | |||
+ 450
- 0
USER_GUIDE.md
View File
| @@ -0,0 +1,450 @@ | |||
| # MSAdapter用户手册 | |||
| ## 1.简介 | |||
| MSAdapter是一款将PyTorch训练脚本高效迁移至MindSpore框架执行的实用工具,旨在不改变原生PyTorch用户的编程使用习惯下,使得PyTorch风格代码能在昇腾硬件上获得高效性能。用户只需要将PyTorch源代码中`import torch`替换为`import msadapter.pytorch`,加上少量训练代码适配即可实现模型在昇腾硬件上的训练。 | |||
| 本教程旨在协助用户快速完成PyTorch脚本迁移工作,精度调优和性能调优可参考[MSAdapter调试调优指南](Debugging_and_Tuning.md)。 | |||
| ## 2.模型迁移入门指南 | |||
| 将现有PyTorch原生代码利用MSAdapter移植至MindSpore时,当前通常需要以下三个步骤: | |||
| **Step1: 替换导入模块** | |||
| ```python | |||
| # import torch | |||
| # import torch.nn as nn | |||
| # import torch.nn.functional as F | |||
| # from torchvision import datasets, transforms | |||
| import msadapter.pytorch as torch | |||
| import msadapter.pytorch.nn as nn | |||
| import msadapter.pytorch.nn.functional as F | |||
| from msadapter.torchvision import datasets, transforms | |||
| class LeNet(nn.Module): | |||
| def __init__(self): | |||
| super(LeNet, self).__init__() | |||
| self.conv1 = nn.Conv2d(3, 16, 5) | |||
| self.pool1 = nn.MaxPool2d(2, 2) | |||
| self.conv2 = nn.Conv2d(16, 32, 5) | |||
| self.pool2 = nn.MaxPool2d(2, 2) | |||
| self.fc1 = nn.Linear(32*5*5, 120) | |||
| self.fc2 = nn.Linear(120, 84) | |||
| self.fc3 = nn.Linear(84, 10) | |||
| def forward(self, x): | |||
| x = F.relu(self.conv1(x)) | |||
| x = self.pool1(x) | |||
| x = F.relu(self.conv2(x)) | |||
| x = self.pool2(x) | |||
| x = x.view(-1, 32*5*5) | |||
| x = F.relu(self.fc1(x)) | |||
| x = F.relu(self.fc2(x)) | |||
| x = self.fc3(x) | |||
| return x | |||
| criterion = nn.CrossEntropyLoss() | |||
| transform = transforms.Compose( | |||
| [transforms.ToTensor(), | |||
| transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) | |||
| train_set = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) | |||
| train_data = DataLoader(train_set, batch_size=128, shuffle=True, num_workers=2, drop_last=True) | |||
| ``` | |||
| MSAdapter已经支持大部分PyTorch和torchvision的原生态表达,用户只需要替换导入包即可完成模型定义和数据初始化。模型中所使用的高阶API支持状态可以从这里找到 [Supported List](https://openi.pcl.ac.cn/OpenI/MSAdapter/src/branch/master/SupportedList.md)。如果有一些必要的接口和功能缺失可以通过[ISSUE](https://openi.pcl.ac.cn/OpenI/MSAdapter/issues) 向我们反馈,我们会优先支持。 | |||
| **Step2: 替换网络训练脚本** | |||
| 请根据以下示例进行适配修改: | |||
| 迁移前网络表达: | |||
| ```python | |||
| net = LeNet().to(config_args.device) | |||
| optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0005) | |||
| net.train() | |||
| # 数据迭代训练 | |||
| for i in range(epochs): | |||
| for X, y in train_data: | |||
| X, y = X.to(config_args.device), y.to(config_args.device) | |||
| out = net(X) | |||
| loss = criterion(out, y) | |||
| optimizer.zero_grad() | |||
| loss.backward() | |||
| optimizer.step() | |||
| print("------>epoch:{}, loss:{:.6f}".format(i, loss)) | |||
| ``` | |||
| 替换为Mindspore函数式迭代训练表达: | |||
| ```python | |||
| import mindspore as ms | |||
| net = LeNet().to(config_args.device) | |||
| optimizer = ms.nn.SGD(net.trainable_params(), learning_rate=0.01, momentum=0.9, weight_decay=0.0005) | |||
| # 定义前向过程 | |||
| def forward_fn(data, label): | |||
| logits = net(data) | |||
| loss = criterion(logits, label) | |||
| return loss, logits | |||
| # 反向梯度定义 | |||
| grad_fn = ms.ops.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True) | |||
| # 单步训练定义 | |||
| def train_step(data, label): | |||
| (loss, _), grads = grad_fn(data, label) | |||
| loss = ms.ops.depend(loss, optimizer(grads)) | |||
| return loss | |||
| net.train() | |||
| # 数据迭代训练 | |||
| for i in range(epochs): | |||
| for X, y in train_data: | |||
| X, y = X.to(config_args.device), y.to(config_args.device) | |||
| res = train_step(X, y) | |||
| print("------>epoch:{}, loss:{:.6f}".format(i, res.asnumpy())) | |||
| ``` | |||
| 当前网络训练流程仍无法完全自动适配(自动适配特性开发中,敬请期待!),需要调用MindSpore的优化器接口和训练流程,如果您想了解更多当前流程与PyTorch原生流程的区别可参考[与PyTorch执行流程区别](https://www.mindspore.cn/docs/zh-CN/r2.0/migration_guide/typical_api_comparision.html#%E4%B8%8Epytorch%E6%89%A7%E8%A1%8C%E6%B5%81%E7%A8%8B%E5%8C%BA%E5%88%AB) 和[与PyTorch优化器的区别](https://www.mindspore.cn/docs/zh-CN/r2.0/migration_guide/typical_api_comparision.html#%E4%B8%8Epytorch%E4%BC%98%E5%8C%96%E5%99%A8%E7%9A%84%E5%8C%BA%E5%88%AB) 。 | |||
| 如果您想要运用分布式训练、图模式加速、数据下沉和混合精度等更高阶的训练方式加速训练可以参考[3.进阶训练指南](#jumpch3)。如果在使用过程中遇到问题或无法对标的内容欢迎通过[ISSUE](https://openi.pcl.ac.cn/OpenI/MSAdapter/issues) 和我们反馈交流。当前存在部分接口暂时无法完全对标PyTorch(参考[Supported List](https://openi.pcl.ac.cn/OpenI/MSAdapter/src/branch/master/SupportedList.md)),针对这类接口我们正在积极优化中,您可以暂时参考[4.手动适配指南](#jumpch4)进行适配处理(不影响网络的正常执行训练)。 | |||
| 更多迁移用例请参考[MSAdapterModelZoo](https://openi.pcl.ac.cn/OpenI/MSAdapterModelZoo)。 | |||
| ## 3.<span id="jumpch3">进阶训练指南</span> | |||
| ### 3.1 使用Graph模式加速训练 | |||
| 目前MSAdapte默认支持MindSpore的PyNative模式训练,如果想调用静态图模式进行训练加速(推荐您先在PyNative模式下完成功能调试后再尝试Graph模式执行),可参考[静态图](https://www.mindspore.cn/tutorials/zh-CN/master/advanced/compute_graph.html)使用教程调用Graph训练模式: | |||
| 方式一:全局设置Graph模式,更适合module表达 | |||
| ```python | |||
| ms.set_context(mode=ms.GRAPH_MODE) | |||
| ``` | |||
| 方式二:采用即时编译装饰器`jit`,使能部分函数粒度表达模块以静态图模式执行 | |||
| ```python | |||
| @ms.jit | |||
| def mul(x, y): | |||
| return x * y | |||
| ``` | |||
| 注意,部分网络中Graph模式训练无法一键切换,可能需要对代码进行相应调整,当前主要体现在inplace类型操作和MindSpore原生框架用法限制,具体细节可参考[静态图语法支持](https://www.mindspore.cn/docs/zh-CN/master/note/static_graph_syntax_support.html)。 | |||
| ### 3.2 使用混合精度加速训练 | |||
| ```python | |||
| from mindspore.amp import auto_mixed_precision | |||
| ... | |||
| net = LeNet().to(config_args.device) | |||
| optimizer = ms.nn.SGD(net.trainable_params(), learning_rate=0.01, momentum=0.9, weight_decay=0.0005) | |||
| net.train() | |||
| net = auto_mixed_precision(net, 'O3') # Ascend环境推荐配置'O3',GPU环境推荐配置'O2'; | |||
| # 定义前向过程 | |||
| def forward_fn(data, label): | |||
| logits = net(data) | |||
| logits = torch.cast_to_adapter_tensor(logits) # 可选 | |||
| loss = criterion(logits, label) | |||
| return loss, logits | |||
| ... | |||
| ``` | |||
| Step1:调用`auto_mixed_precision`自动生成混合精度模型,如果需要调用原始模型的方法请在混合精度模型生成前执行,如`net.train()`; | |||
| Step2(可选):如果后续仍有对网络输出Tensor的操作,需调用`torch.cast_to_adapter_tensor`手动将输出 Tensor转换为MSAdater Tensor; | |||
| 更多细节请参考[自动混合精度使用教程](https://www.mindspore.cn/tutorials/zh-CN/master/advanced/mixed_precision.html)。 | |||
| ### 3.3 使用分布式训练加速训练 | |||
| 请参考[快速入门分布式并行训练](https://www.mindspore.cn/tutorials/experts/zh-CN/master/parallel/parallel_training_quickstart.html)选择合适的分布式训练方式。推荐使用OpenMPI训练方式,其效果类似PyTorch的分布式数据并行[DistributedDataParallel](https://pytorch.org/docs/1.12/generated/torch.nn.parallel.DistributedDataParallel.html?highlight=distributeddataparallel#torch.nn.parallel.DistributedDataParallel)训练方式: | |||
| ```python | |||
| # 分布式数据处理 | |||
| from msadapter.pytorch.utils.data import DataLoader, DistributedSampler | |||
| # 初始化通信环境 | |||
| from mindspore.communication import init | |||
| ... | |||
| train_images = datasets.CIFAR10('./', train=True, download=True, transform=transform) | |||
| sampler = DistributedSampler(train_images) | |||
| train_data = DataLoader(train_images, batch_size=32, num_workers=2, drop_last=True, sampler=sampler) | |||
| ... | |||
| ``` | |||
| 执行脚本命令为: | |||
| ``` | |||
| mpirun -n DEVICE_NUM python train.py | |||
| ``` | |||
| ### 3.4 分组学习率/动态学习率配置 | |||
| 请参考以下代码使用MindSpore的分组学习率配置策略: | |||
| ```python | |||
| net = Net() | |||
| # 卷积参数 | |||
| conv_params = list(filter(lambda x: 'conv' in x.name, net.trainable_params())) | |||
| # 非卷积参数 | |||
| no_conv_params = list(filter(lambda x: 'conv' not in x.name, net.trainable_params())) | |||
| # 卷积参数使用固定学习率0.001,权重衰减为0.01 | |||
| # 非卷积参数使用固定学习率0.003,权重衰减为0.0 | |||
| group_params = [{'params': conv_params, 'weight_decay': 0.01, 'lr': 0.001}, | |||
| {'params': no_conv_params, 'lr': 0.003}] | |||
| optim = nn.Momentum(group_params, learning_rate=0.1, momentum=0.9, weight_decay=0.0) | |||
| ``` | |||
| 请参考以下代码使用MindSpore的动态学习率更新策略: | |||
| ```python | |||
| def lr_cosine_policy(base_lr, warmup_length, epochs, iter_per_epoch): | |||
| def _lr_fn(epoch): | |||
| if epoch < warmup_length: | |||
| lr = base_lr * (epoch + 1) / warmup_length | |||
| else: | |||
| e = epoch - warmup_length | |||
| es = epochs - warmup_length | |||
| lr = 0.5 * (1 + np.cos(np.pi * e / es)) * base_lr | |||
| return lr | |||
| output = [] | |||
| for epoch in range(0, epochs): | |||
| lr = _lr_fn(epoch) | |||
| for iter in range(iter_per_epoch) | |||
| output.append(lr) | |||
| return output | |||
| lr_scheduler = lr_cosine_policy(args.lr, args.warmup, args.epochs, iter_per_epoch) | |||
| optimizer = ms.nn.SGD(net.trainable_params(), learning_rate=lr_scheduler, momentum=0.9, weight_decay=1e-4) | |||
| ``` | |||
| PyTorch提供了`torch.optim.lr_scheduler`包用于动态修改lr,使用的时候需要显式地调用`optimizer.step()`和`scheduler.step()`来更新lr(详情请参考[如何调整学习率](https://pytorch.org/docs/1.12/optim.html#how-to-adjust-learning-rate))。而MindSpore的学习率是在优化器中自动更新的,每调用一次优化器,学习率更新的step会自动更新一次(详情请参考[动态学习率使用教程](https://www.mindspore.cn/tutorials/zh-CN/master/advanced/modules/optimizer.html?highlight=%E5%8A%A8%E6%80%81%E5%AD%A6%E4%B9%A0%E7%8E%87#%E5%8A%A8%E6%80%81%E5%AD%A6%E4%B9%A0%E7%8E%87))。 | |||
| ### 3.5 其他训练表达 | |||
| 除前文推荐的函数式迭代训练表达外,还有两种训练表达形式可供选择: | |||
| 方式二:使用MindSpore的Model.train训练 | |||
| ```python | |||
| import mindspore as ms | |||
| from mindspore.dataset import GeneratorDataset | |||
| from mindspore.train.callback import LossMonitor, TimeMonitor | |||
| model = LeNet() | |||
| criterion = nn.CrossEntropyLoss() | |||
| optimizer = ms.nn.SGD(model.trainable_params(), learning_rate=0.1, momentum=0.9, weight_decay=1e-4) | |||
| model = ms.Model(model, criterion, optimizer, metrics={'accuracy'}) | |||
| dataset = GeneratorDataset(source=train_data, column_names=["data", "label"]) | |||
| model.train(epochs, dataset, callbacks=[TimeMonitor(), LossMonitor()]) | |||
| ``` | |||
| 方式三:使用WithLossCell和TrainOneStepCell迭代训练 | |||
| ```python | |||
| import mindspore as ms | |||
| from msadapter.pytorch import nn | |||
| import msadapter.pytorch as torch | |||
| model = LeNet() | |||
| criterion = nn.CrossEntropyLoss() | |||
| optimizer = ms.nn.SGD(model.trainable_params(), learning_rate=0.1, momentum=0.9, weight_decay=1e-4) | |||
| loss_net = ms.nn.WithLossCell(model, criterion) | |||
| train_net = ms.nn.TrainOneStepCell(loss_net, optimizer) | |||
| for i in range(epochs): | |||
| for X, y in train_data: | |||
| loss = train_net(X, y) | |||
| ``` | |||
| ## 4.<span id="jumpch4">手动适配指南</span> | |||
| ### 4.1 数据处理部分 | |||
| 通常情况下仅需将数据处理相关导入包修改为从msadapter导入,即可实现PyTorch数据部分的迁移,示例如下: | |||
| ```python | |||
| from msadapter.pytorch.utils.data import DataLoader | |||
| from msadapter.torchvision import datasets, transforms | |||
| transform = transforms.Compose([transforms.Resize((224, 224), interpolation=InterpolationMode.BICUBIC), | |||
| transforms.ToTensor(), | |||
| transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.247, 0.2435, 0.2616]) | |||
| ]) | |||
| train_images = datasets.CIFAR10('./', train=True, download=True, transform=transform) | |||
| train_data = DataLoader(train_images, batch_size=128, shuffle=True, num_workers=2, pin_memory=True) | |||
| ``` | |||
| **TorchVision接口支持**: MSAdapter torchvision是迁移自PyTorch官方实现的计算机视觉工具库,延用PyTorch官方API设计与使用习惯,内部计算调用MindSpore算子,实现与torchvision原始库同等功能。用户只需要将PyTorch源代码中`import torchvision`替换为`import msadapter.torchvision`即可。torchvision支持状态可以从这里找到 [TorchVision Supported List](https://openi.pcl.ac.cn/OpenI/MSAdapter/src/branch/master/msadapter/torchvision/TorchVision_SupportedList.md)。 | |||
| 另外,如果遇到数据处理接口未完全适配的场景,可以暂时使用PyTorch原生的数据处理流程,将生成的数据PyTorch张量转为MSAdapter支持的张量对象,请参考[convert_tensor 工具使用教程](https://openi.pcl.ac.cn/OpenI/MSAdapter/src/branch/master/msadapter/tools#user-content-convert-tensor)实现。 | |||
| ### 4.2 模型构建部分 | |||
| #### 4.2.1 自定义module | |||
| ```python | |||
| from msadapter.pytorch.nn import Module, Linear, Flatten | |||
| class MLP(Module): | |||
| def __init__(self): | |||
| super(MLP, self).__init__() | |||
| self.flatten = Flatten() | |||
| self.line1 = Linear(in_features=1024, out_features=64) | |||
| self.line2 = Linear(in_features=64, out_features=128, bias=False) | |||
| self.line3 = Linear(in_features=128, out_features=10) | |||
| def forward(self, inputs): | |||
| x = self.flatten(inputs) | |||
| x = self.line1(x) | |||
| x = self.line2(x) | |||
| x = self.line3(x) | |||
| return x | |||
| ``` | |||
| 自定义module写法和PyTorch原生写法一致,但需要注意下述问题: | |||
| 1. 自定义module时可能出现变量名已被使用场景,如`self.phase`,需要用户自行变更变量名; | |||
| 2. 自定义反向传播函数差异,反向函数需要满足MindSpore自定义反向函数格式要求,请参考[自定义Cell反向](https://www.mindspore.cn/tutorials/zh-CN/master/advanced/modules/layer.html#%E8%87%AA%E5%AE%9A%E4%B9%89cell%E5%8F%8D%E5%90%91),以下是适配案例: | |||
| ```python | |||
| # PyTorch 写法 | |||
| class GdnFunction(Function): | |||
| @staticmethod | |||
| def forward(ctx, x, gamma, beta): | |||
| # save variables for backprop | |||
| ctx.save_for_backward(x, gamma, beta) | |||
| ... | |||
| return y | |||
| @staticmethod | |||
| def backward(ctx, grad_output): | |||
| x, gamma, beta = ctx.saved_variables | |||
| ... | |||
| return grad_input, grad_gamma, grad_beta | |||
| # MSadapter 写法 | |||
| class GdnFunction(nn.Module): | |||
| def __init__(self): | |||
| super(GdnFunction, self).__init__() | |||
| def forward(self, x, gamma, beta): | |||
| ... | |||
| return y | |||
| def bprop(self, x, gamma, beta, out, grad_output): | |||
| x = torch.Tensor(x) | |||
| gamma = torch.Tensor(gamma) | |||
| beta = torch.Tensor(beta) | |||
| grad_output = torch.Tensor(grad_output) | |||
| ... | |||
| return grad_input, grad_gamma, grad_beta | |||
| ``` | |||
| #### 4.2.2 多态接口适配 | |||
| PyTorch存在一些多态接口,使用灵活。MSAdapter作为Python层适配中间件,暂时只能支持主流场景,部分场景可能需要用户补齐默认参数或替换接口实现,已经识别到的此类接口有: | |||
| 1. `torch.max(tensor1, tensor2)`需要替换为`torch.maximum(tensor1, tensor2)`等价实现; | |||
| 2. `torch.min(tensor1, tensor2)`需要替换为`torch.minimum(tensor1, tensor2)`等价实现; | |||
| 3. `torch.randint(10, (2, 2))`需要补齐默认参数`torch.randint(0, 10, (2, 2))`等价实现,类似的接口还有`torch.arange`/`torch.normal`/`torch.randint_like`; | |||
| #### 4.2.3 view类接口和inplace类接口适配 | |||
| 1. 当前`torch.view`操作实际等价于创建指定shape的新tensor,并**不真实共享内存**,需要用户自己保证tensor的赋值更新。(共享内存的view接口正在研发中,敬请期待!); | |||
| 2. 暂时无法对标inplace相关操作,当前此类并**不真实共享内存**,所以`torch.xxx(*, out=output)`接口推荐写成`output = torch.xxx(*)`形式,`tensor_a.xxx_(*)`推荐写成`tensor_b = tensor_a.xxx(*)`形式,则该接口在图模式下也可正常执行; | |||
| 3. 切片后的inplace算子不生效,需修改为如下写法: | |||
| ```python | |||
| # PyTorch 原生写法 | |||
| boxes[i,:,0::4].clamp_(0, im_shape[i, 1]-1) | |||
| # MSAdapter 推荐写法 | |||
| a = boxes[i,:,0::4].clamp_(0, im_shape[i, 1]-1) | |||
| boxes[i, :, 0::4] = a | |||
| ``` | |||
| ### 4.3 训练流程部分 | |||
| #### 4.3.1 指定执行硬件 | |||
| PyTorch原生接口通过`to`等接口将数据拷贝到指定硬件中执行,但是MSAdapter暂不支持指定硬件执行,实际执行的硬件后端由conetxt指定。如果您的程序运行在云脑2,则默认执行昇腾硬件,如果想执行在其他硬件后端可以参考如下代码; | |||
| ```python | |||
| ms.context.set_context(device_target="CPU") | |||
| ``` | |||
| #### 4.3.2 冗余代码删除 | |||
| 部分接口功能暂时无法对标,请将相关代码删除或进行相应适配,如: | |||
| 1. torch.cuda模块的相关操作在昇腾硬件上无实质作用,请删除; | |||
| 2. 请删除torch.no_grad接口。除非主动调用微分相关接口,MSAdapter默认不计算变量梯度; | |||
| 3. 请删除分布式并行训练的相关接口,并参考[3.3 使用分布式训练](#3.3-使用分布式训练)进行分布式训练; | |||
| #### 4.3.3 网络训练流程 | |||
| 1. 当调用`ms.ops.value_and_grad`接口时,如果`has_aux`为True,不允许存在多层嵌套的输出(**优化中**),且求导位置必须为第一个输出; | |||
| 2. `torch.nn.utils.clip_grad_norm_` 可替换为 `ms.ops.clip_by_global_norm`等价实现梯度裁剪功能; | |||
| ### 4.4 其他 | |||
| 1. 网络中如果调用了MindSpore原生接口,则需要调用`msadapter.pytorch.cast_to_adapter_tensor`接口将输出tensor转换为MSAdapter tensor后方可继续调用PyTorch风格接口。除网络训练部分,不推荐混用MSAdapter接口和MindSpore接口; | |||
| 2. MSAdapter tensor暂不支持格式化输出,如`label = f"{class_names[labels[i]]}: {probs[i]:.2f}"`,可先转换为numpy后输出; | |||
| 3. 代码中调用`torch.autograd.Variable`接口,替换为`torch.tensor`即可; | |||
| 4. 输出tensor如果要输入到opencv等其他组件进行处理时需要先转为numpy后再执行; | |||
| 5. 模型保存与加载: | |||
| ```python | |||
| # 模型保存 | |||
| torch.save(net.state_dict(), 'epoch1.pth') | |||
| # 加载来自torch原生脚本保存的pth | |||
| net.load_state_dict(torch.load('troch_origin.pth',from_torch=True), strict=True) | |||
| # 加载来自MSAdapter迁移模型保存的pth | |||
| net.load_state_dict(torch.load('troch_origin.pth'), strict=True) | |||
| ``` | |||
| 我们支持PyTorch原生的模型保存语法,允许用户保存网络权重或以字典形式保存其他数据;对于模型加载阶段,当前暂不支持加载网络模型结构。 | |||
| 用户可以通过配置`from_torch=True`标志位加载来自PyTorch原生的pth文件,仅支持加载网络权重,不支持加载网络结构。基于MSAdapter保存的pth文件不支持PyTorch原生脚本使用。 | |||
| ## FAQ | |||
| **Q**:设置context.set_context(mode=context.GRAPH_MODE)后运行出现类似问题: | |||
| > "Tensor.add\_" is an in-place operation and "x.add\_()" is not encouraged to use in MindSpore static graph mode. Please use "x = x.add()" or other API instead。 | |||
| **A**:目前在设置GRAPH模式下不支持原地操作相关的接口,需要按照提示信息进行修改。需要注意的是,即使在PYNATIVE模式下,原地操作相关接口也是不鼓励使用的,因为目前在MSAdapter不会带来内存收益,而且会给反向梯度计算带来不确定性。 | |||
| **Q**:运行代码出现类似报错信息: | |||
| > AttributeError: module 'msadapter.pytorch' has no attribute 'xxx'。 | |||
| **A**:首先确定'xxx'是否为torch 1.12版本支持的接口,PyTorch官网明确已废弃或者即将废弃的接口和参数,MSAdapter不会兼容支持,请使用其他同等功能的接口代替。如果是PyTorch对应版本支持,而MSAdapter中暂时没有,欢迎参与[MSAdapter项目](https://openi.pcl.ac.cn/OpenI/MSAdapter)贡献你的代码,也可以通过[创建任务(New issue)](https://openi.pcl.ac.cn/OpenI/MSAdapter/issues/new)反馈需求。 | |||
BIN
doc/pic/MSA_F.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1006 | Height: 866 | Size: 35 KiB |
BIN
doc/pic/MSA_SIG.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 633 | Height: 639 | Size: 185 KiB |
BIN
doc/pic/error_log.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1493 | Height: 185 | Size: 34 KiB |
BIN
doc/pic/time_log.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1587 | Height: 643 | Size: 167 KiB |
BIN
doc/pic/troubleshooter_result1.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1279 | Height: 415 | Size: 72 KiB |
BIN
doc/pic/troubleshooter_result2.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1284 | Height: 395 | Size: 61 KiB |
BIN
doc/pic/troubleshooter_result3.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1285 | Height: 198 | Size: 28 KiB |
+ 0
- 5
ms_adapter/__init__.py
View File
| @@ -1,5 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from ms_adapter import pytorch | |||
| from ms_adapter.utils import unsupported_attr, pynative_mode_condition | |||
+ 0
- 52
ms_adapter/pytorch/__init__.py
View File
| @@ -1,52 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from ms_adapter.pytorch.common import * | |||
| from ms_adapter.pytorch.tensor import * | |||
| from ms_adapter.pytorch import nn | |||
| from ms_adapter.pytorch import optim | |||
| from ms_adapter.pytorch.functional import * | |||
| from ms_adapter.pytorch.utils import data | |||
| from ms_adapter.pytorch._ref import * | |||
| from ms_adapter.pytorch import cuda | |||
| from ms_adapter.pytorch.conflict_functional import * | |||
| import ms_adapter.pytorch.fft as fft | |||
| from ms_adapter.pytorch import autograd | |||
| # Variables with simple values, from math.py | |||
| e = 2.718281828459045 | |||
| pi = 3.141592653589793 | |||
| tau = 6.283185307179586 | |||
| def _assert(condition, message): | |||
| assert condition, message | |||
| def is_tensor(obj): | |||
| r"""Returns True if `obj` is a ms_adapter.pytorch tensor. | |||
| Note that this function is simply doing ``isinstance(obj, Tensor)``. | |||
| Using that ``isinstance`` check is better for typechecking with mypy, | |||
| and more explicit - so it's recommended to use that instead of | |||
| ``is_tensor``. | |||
| """ | |||
| return isinstance(obj, Tensor) | |||
| def is_floating_point(obj): | |||
| # TODO: return mindspore.ops.is_floating_point(obj) | |||
| if not is_tensor(obj): | |||
| raise TypeError("is_floating_point(): argument 'input' (position 1) must be Tensor, not {}.".format(type(obj))) | |||
| return obj._dtype in (mstype.float16, mstype.float32, mstype.float64) | |||
| class Size(tuple): | |||
| def __new__(cls, shape): | |||
| if isinstance(shape, Tensor): | |||
| _shape = shape.tolist() | |||
| else: | |||
| _shape = shape | |||
| if not isinstance(_shape, (tuple, list)): | |||
| raise TypeError("{} object is not supportted.".format(type(shape))) | |||
| return tuple.__new__(Size, _shape) | |||
+ 0
- 28
ms_adapter/pytorch/_ref/__init__.py
View File
| @@ -1,28 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import mindspore as ms | |||
| from ms_adapter.utils import unsupported_attr | |||
| from ms_adapter.pytorch.tensor import cast_to_adapter_tensor | |||
| def randn(*size, out=None, dtype=None, layout=None, | |||
| device=None, requires_grad=False): | |||
| unsupported_attr(layout) | |||
| unsupported_attr(device) | |||
| unsupported_attr(requires_grad) | |||
| if isinstance(size[0], (tuple, list)): | |||
| _size = size[0] | |||
| elif isinstance(size[0], int): | |||
| _size = size | |||
| else: | |||
| raise TypeError("`size` type in `randn` only support int, tuple and list") | |||
| if dtype is None: | |||
| dtype = ms.float32 | |||
| out_value = ms.numpy.randn(_size, dtype=dtype) | |||
| if out is not None: | |||
| ms.ops.assign(out, out_value) | |||
| return out | |||
| return cast_to_adapter_tensor(out_value) | |||
+ 0
- 21
ms_adapter/pytorch/common/__init__.py
View File
| @@ -1,21 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from ms_adapter.pytorch.common.dtype import * | |||
| from ms_adapter.pytorch.common.device import * | |||
| __all__ = ["float", "double", | |||
| "float16", "float32", | |||
| "float64", "int8", | |||
| "int16", "int32", | |||
| "int64", "uint8", | |||
| "uint16", "uint32", | |||
| "uint64", "bool_", | |||
| "complex64", "complex128", | |||
| "long", "bfloat16", | |||
| "cfloat", "cdouble", | |||
| "half", "short", | |||
| "int", "bool", | |||
| "iinfo", "finfo", | |||
| "Device" | |||
| ] | |||
+ 0
- 68
ms_adapter/pytorch/common/dtype.py
View File
| @@ -1,68 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import numpy as np | |||
| from mindspore import dtype as mstype | |||
| float = mstype.float32 | |||
| double = mstype.float64 | |||
| float16 = mstype.float16 | |||
| # TODO: mindspore to support mstype.bfloat16 | |||
| bfloat16 = mstype.float32 | |||
| float32 = mstype.float32 | |||
| float64 = mstype.float64 | |||
| int8 = mstype.int8 | |||
| int16 = mstype.int16 | |||
| int32 = mstype.int32 | |||
| int64 = mstype.int64 | |||
| uint8 = mstype.uint8 | |||
| uint16 = mstype.uint16 | |||
| uint32 = mstype.uint32 | |||
| uint64 = mstype.uint64 | |||
| bool_ = mstype.bool_ | |||
| complex64 = mstype.complex64 | |||
| complex128 = mstype.complex128 | |||
| long = mstype.int64 | |||
| cfloat = mstype.complex64 | |||
| cdouble = mstype.complex128 | |||
| half = mstype.half | |||
| short = mstype.short | |||
| int = mstype.int32 | |||
| bool = mstype.bool_ | |||
| _TypeDict = {mstype.float16: np.float16, | |||
| mstype.float32: np.float32, | |||
| mstype.float64: np.float64, | |||
| mstype.int8: np.int8, | |||
| mstype.int16: np.int16, | |||
| mstype.int32: np.int32, | |||
| mstype.int64: np.int64, | |||
| mstype.uint8: np.uint8} | |||
| class iinfo: | |||
| def __init__(self, dtype): | |||
| if dtype in (mstype.uint8, mstype.int8, mstype.int16, mstype.int32, mstype.int64): | |||
| np_iinfo = np.iinfo(_TypeDict[dtype]) | |||
| self.bits = np_iinfo.bits | |||
| self.max = np_iinfo.max | |||
| self.min = np_iinfo.min | |||
| else: | |||
| raise ValueError("iinfo currently only supports torch.uint8/torch.int8/torch.int16/torch.int32/" | |||
| "torch.int64 as the input, but get a", dtype) | |||
| class finfo: | |||
| def __init__(self, dtype): | |||
| if dtype in (mstype.float16, mstype.float32, mstype.float64): | |||
| np_finfo = np.finfo(_TypeDict[dtype]) | |||
| self.bits = np_finfo.bits | |||
| self.eps = np_finfo.eps | |||
| self.max = np_finfo.max | |||
| self.min = np_finfo.min | |||
| self.tiny = np_finfo.tiny | |||
| # TODO: numpy vision >= 1.23 | |||
| # self.smallest_normal = np_finfo.smallest_normal | |||
| self.resolution = np_finfo.resolution | |||
| else: | |||
| raise ValueError("finfo currently only supports torch.float16/torch.float32/" | |||
| "torch.float64 as the input, but get a", dtype) | |||
+ 0
- 22
ms_adapter/pytorch/cuda/__init__.py
View File
| @@ -1,22 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import mindspore as ms | |||
| from mindspore.communication.management import init, get_group_size | |||
| from ms_adapter.utils import get_backend | |||
| from ms_adapter.pytorch.tensor import FloatTensor, LongTensor | |||
| def is_available(): | |||
| backend = get_backend() | |||
| if backend == 'GPU': | |||
| return True | |||
| return False | |||
| def current_device(): | |||
| return 0 | |||
| def device_count(): | |||
| # TODO Use this method when supported | |||
| # init() | |||
| # return get_group_size() | |||
| return 1 | |||
+ 0
- 16
ms_adapter/pytorch/fft/fft.py
View File
| @@ -1,16 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import numpy as np | |||
| import mindspore as ms | |||
| from ms_adapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| def fft(input, n=None, dim=-1, norm=None, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| input = input.asnumpy() | |||
| output = np.fft.fft(input, n, axis=dim, norm=norm) | |||
| output = cast_to_adapter_tensor(ms.Tensor(output)) | |||
| if out is not None: | |||
| out.assign_value(output) | |||
| return output | |||
+ 0
- 2238
ms_adapter/pytorch/functional.py
File diff suppressed because it is too large
View File
+ 0
- 7
ms_adapter/pytorch/nn/__init__.py
View File
| @@ -1,7 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from ms_adapter.pytorch.nn.modules import * | |||
| from ms_adapter.pytorch.nn import init | |||
| from ms_adapter.pytorch.nn.parameter import Parameter, ParameterTuple | |||
| from ms_adapter.pytorch.nn.functional import * | |||
+ 0
- 1783
ms_adapter/pytorch/nn/functional.py
View File
| @@ -1,1783 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| """Functional interface""" | |||
| import math | |||
| import warnings | |||
| import numpy as np | |||
| import mindspore as ms | |||
| import mindspore.nn as nn | |||
| from mindspore.ops import constexpr | |||
| from mindspore.ops.operations.nn_ops import TripletMarginLoss as TripletMarginLossOp | |||
| from mindspore.ops._primitive_cache import _get_cache_prim | |||
| from ms_adapter.utils import unsupported_attr, get_backend | |||
| from ms_adapter.pytorch.tensor import Tensor, cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from ms_adapter.pytorch.common._inner import _inplace_assign_pynative | |||
| all = [ | |||
| 'smooth_l1_loss', | |||
| 'log_softmax', | |||
| 'logsigmoid', | |||
| 'elu', | |||
| 'elu_', | |||
| 'relu', | |||
| 'relu_', | |||
| 'upsample', | |||
| 'rrelu', | |||
| 'rrelu_', | |||
| 'selu', | |||
| 'celu', | |||
| 'gelu', | |||
| 'mish', | |||
| 'softshrink', | |||
| 'hardtanh', | |||
| 'hardtanh_', | |||
| 'hardswish', | |||
| 'relu6', | |||
| 'leaky_relu', | |||
| 'softmax', | |||
| 'softmin', | |||
| 'softsign', | |||
| 'tanh', | |||
| 'tanhshrink', | |||
| 'glu', | |||
| 'softplus', | |||
| 'sigmoid', | |||
| 'hardsigmoid', | |||
| 'silu', | |||
| 'gumbel_softmax', | |||
| 'threshold', | |||
| 'threshold_', | |||
| 'hardshrink', | |||
| 'normalize', | |||
| 'local_response_norm', | |||
| 'l1_loss', | |||
| 'cross_entropy', | |||
| 'nll_loss', | |||
| 'kl_div', | |||
| 'binary_cross_entropy', | |||
| 'binary_cross_entropy_with_logits', | |||
| 'upsample_nearest', | |||
| 'pairwise_distance', | |||
| 'cosine_similarity', | |||
| 'pdist', | |||
| 'dropout1d', | |||
| 'dropout2d', | |||
| 'dropout3d', | |||
| 'dropout', | |||
| 'alpha_dropout', | |||
| 'feature_alpha_dropout' | |||
| 'huber_loss', | |||
| 'soft_margin_loss', | |||
| 'cosine_embedding_loss', | |||
| 'pixel_shuffle', | |||
| 'pixel_unshuffle', | |||
| 'one_hot', | |||
| 'embedding', | |||
| 'max_pool2d', | |||
| ] | |||
| @constexpr | |||
| def _get_adaptive_pool_args(input_shape, output_size): | |||
| _, _, h, w = input_shape | |||
| if isinstance(output_size, int): | |||
| output_size = [output_size, ] * 2 | |||
| condition = [0, ] * 2 | |||
| out_h = output_size[0] + condition[0] * h | |||
| out_w = output_size[1] + condition[1] * w | |||
| stride_h = math.floor(h / out_h) | |||
| kernel_h = h - (out_h - 1) * stride_h | |||
| stride_w = math.floor(w / out_w) | |||
| kernel_w = w - (out_w - 1) * stride_w | |||
| return kernel_h, kernel_w, stride_h, stride_w | |||
| def adaptive_avg_pool2d(input, output_size): | |||
| kernel_h, kernel_w, stride_h, stride_w = _get_adaptive_pool_args(input.shape, output_size) | |||
| avg_pool = _get_cache_prim(ms.ops.AvgPool)(kernel_size=(kernel_h, kernel_w), | |||
| strides=(stride_h, stride_w), | |||
| pad_mode="valid", | |||
| data_format="NCHW") | |||
| input = cast_to_ms_tensor(input) | |||
| out = avg_pool(input) | |||
| return cast_to_adapter_tensor(out) | |||
| def adaptive_avg_pool1d(input, output_size): | |||
| input = cast_to_ms_tensor(input) | |||
| output = ms.ops.adaptive_avg_pool1d(input, output_size) | |||
| return cast_to_adapter_tensor(output) | |||
| # def adaptive_avg_pool2d(input, output_size): | |||
| # TODO: This ops only supports the GPU | |||
| # input = cast_to_ms_tensor(input) | |||
| # output = ms.ops.adaptive_avg_pool2d(input, output_size) | |||
| # return cast_to_adapter_tensor(output) | |||
| def adaptive_avg_pool3d(input, output_size): | |||
| input = cast_to_ms_tensor(input) | |||
| output = ms.ops.adaptive_avg_pool3d(input, output_size) | |||
| return cast_to_adapter_tensor(output) | |||
| def adaptive_max_pool1d(input, output_size, return_indices=False): | |||
| input = cast_to_ms_tensor(input) | |||
| if return_indices: | |||
| raise ValueError('keyword argument return_indices is ont supported.') | |||
| output = ms.ops.adaptive_max_pool1d(input, output_size) | |||
| return cast_to_adapter_tensor(output) | |||
| def adaptive_max_pool2d(input, output_size, return_indices=False): | |||
| input = cast_to_ms_tensor(input) | |||
| output = ms.ops.adaptive_max_pool2d(input, output_size, return_indices) | |||
| return cast_to_adapter_tensor(output) | |||
| def adaptive_max_pool3d(input, output_size, return_indices=False): | |||
| input = cast_to_ms_tensor(input) | |||
| output = ms.ops.adaptive_max_pool3d(input, output_size, return_indices) | |||
| return cast_to_adapter_tensor(output) | |||
| def pad(input, pad, mode="constant", value=0): | |||
| if mode == "replicate": | |||
| mode = "edge" | |||
| value = ms.Tensor(value, dtype=input.dtype) | |||
| dims = len(input.shape) | |||
| list_pad = [pad[i:i+2] for i in range(0, len(pad), 2)] | |||
| list_pad.reverse() | |||
| new_pad = [[0,0],] * int((dims - len(pad) /2)) | |||
| new_pad.extend(list_pad) | |||
| input = cast_to_ms_tensor(input) | |||
| # TODO: -> ms.ops.PadV3 | |||
| output = ms.ops.operations.nn_ops.PadV3(mode=mode)(input, pad, value) | |||
| return cast_to_adapter_tensor(output) | |||
| def log_softmax(input, dim=None, _stacklevel=3, dtype=None): | |||
| unsupported_attr(_stacklevel) | |||
| # MS dim default is -1 | |||
| if dim is None: | |||
| warnings.warn("Implicit dimension choice for log_softmax has been deprecated. " | |||
| "Change the call to include dim=X as an argument") | |||
| dim = -1 | |||
| input = cast_to_ms_tensor(input) | |||
| if dtype is not None: | |||
| input = ms.ops.cast(input, dtype) | |||
| out = ms.ops.log_softmax(input, dim) | |||
| return cast_to_adapter_tensor(out) | |||
| def logsigmoid(input): | |||
| input = cast_to_ms_tensor(input) | |||
| sigmoid_op = _get_cache_prim(ms.ops.Sigmoid)() | |||
| sigmoid_out= sigmoid_op(input) | |||
| ret = ms.ops.log(sigmoid_out) | |||
| return cast_to_adapter_tensor(ret) | |||
| def elu(input, alpha=1.0, inplace=False): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| out = ms.ops.elu(input_ms, alpha) | |||
| return _inplace_assign_pynative(input, inplace, out, "elu") | |||
| def rrelu(input, lower=1.0/8, upper=1.0/3, training=False, inplace=False): | |||
| if training: | |||
| raise ValueError("training '{}' is not currently supported.".format(training)) | |||
| input_ms = cast_to_ms_tensor(input) | |||
| #TODO: nn.RReLU should be replaced | |||
| out = nn.RReLU(lower=lower, upper=upper)(input_ms) | |||
| return _inplace_assign_pynative(input, inplace, out, "rrelu") | |||
| def selu(input, inplace=False): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| out = ms.ops.selu(input_ms) | |||
| return _inplace_assign_pynative(input, inplace, out, "selu") | |||
| def celu(input, alpha=1.0, inplace=False): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| out = ms.ops.celu(input_ms, alpha) | |||
| return _inplace_assign_pynative(input, inplace, out, "celu") | |||
| def gelu(input, approximate='none'): | |||
| input_x = cast_to_ms_tensor(input) | |||
| out = ms.ops.gelu(input_x, approximate) | |||
| return cast_to_adapter_tensor(out) | |||
| def mish(input, inplace=False): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| out = ms.ops.mish(input_ms) | |||
| return _inplace_assign_pynative(input, inplace, out, "mish") | |||
| def softshrink(input, lambd=0.5): | |||
| input = cast_to_ms_tensor(input) | |||
| out = ms.ops.soft_shrink(input, lambd) | |||
| return cast_to_adapter_tensor(out) | |||
| def relu(input, inplace=False): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| out = ms.ops.relu(input_ms) | |||
| return _inplace_assign_pynative(input, inplace, out, "relu") | |||
| def hardtanh(input, min_val=-1.0, max_val=1.0, inplace=False): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| out = nn.Hardtanh(min_val, max_val)(input_ms) | |||
| return _inplace_assign_pynative(input, inplace, out, "hardtanh") | |||
| def hardswish(input, inplace=False): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| out = ms.ops.hardswish(input_ms) | |||
| return _inplace_assign_pynative(input, inplace, out, "hardswish") | |||
| def relu6(input, inplace=False): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| out = ms.ops.relu6(input_ms) | |||
| return _inplace_assign_pynative(input, inplace, out, "relu6") | |||
| def leaky_relu(input, negative_slope=0.01, inplace=False): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| #TODO:nn.LeakyReLU should be replaced. | |||
| out = nn.LeakyReLU(alpha=negative_slope)(input_ms) | |||
| return _inplace_assign_pynative(input, inplace, out, "leaky_relu") | |||
| def upsample(input, size=None, scale_factor=None, mode='nearest', | |||
| align_corners=False): | |||
| if size is None and scale_factor is None: | |||
| raise ValueError("either size or scale_factor should be defined") | |||
| if size is not None and scale_factor is not None: | |||
| raise ValueError("only one of size or scale_factor should be defined") | |||
| def linear_func(input): | |||
| if align_corners is True: | |||
| trans_mode = 'align_corners' | |||
| else: | |||
| trans_mode = 'half_pixel' | |||
| _size =_upsample_common_process_size(size=size, scale_factor=scale_factor, shape=input.shape) | |||
| input = cast_to_ms_tensor(input) | |||
| out = ms.ops.interpolate(input, scales=None, sizes=_size, | |||
| coordinate_transformation_mode=trans_mode, mode=mode) | |||
| return cast_to_adapter_tensor(out) | |||
| def bllinear_func(input): | |||
| return upsample_bilinear(input, size=size, scale_factor=scale_factor, align_corners=align_corners) | |||
| def resize_nearest_neighbor_func(input): | |||
| return upsample_nearest(input, size=size, scale_factor=scale_factor, align_corners=align_corners) | |||
| mode_func = {'linear': linear_func, | |||
| 'bilinear': bllinear_func, | |||
| 'nearest': resize_nearest_neighbor_func} | |||
| if mode not in mode_func: | |||
| raise ValueError("Until now, `mode` beside 'linear', 'bilinear', 'nearest' are not supported") | |||
| func = mode_func[mode] | |||
| out = func(input) | |||
| return out | |||
| @constexpr | |||
| def _get_softmax_dim(ndim): | |||
| if ndim in (0, 1, 3): | |||
| ret = 0 | |||
| else: | |||
| ret = 1 | |||
| return ret | |||
| def softmax(input, dim=None, dtype=None): | |||
| # MS dim default is -1 | |||
| if dim is None: | |||
| dim = -1 | |||
| input = cast_to_ms_tensor(input) | |||
| if dtype is not None: | |||
| input = ms.ops.cast(input, dtype) | |||
| out = ms.ops.softmax(input, axis=dim) | |||
| return cast_to_adapter_tensor(out) | |||
| def softmin(input, dim=None, dtype=None): | |||
| # MS dim default is -1 | |||
| # TODO | |||
| # ms.ops.softmax should be replaced by ms.ops.softmin | |||
| if dim is None: | |||
| dim = _get_softmax_dim(input.dim()) | |||
| input = cast_to_ms_tensor(input) | |||
| if dtype is not None: | |||
| input = ms.ops.cast(input, dtype) | |||
| x = -input | |||
| out = ms.ops.softmax(x, axis=dim) | |||
| return cast_to_adapter_tensor(out) | |||
| def softsign(input): | |||
| input = cast_to_ms_tensor(input) | |||
| output = ms.ops.functional.softsign(input) | |||
| return cast_to_adapter_tensor(output) | |||
| def tanh(input): | |||
| input = cast_to_ms_tensor(input) | |||
| output = ms.ops.functional.tanh(input) | |||
| return cast_to_adapter_tensor(output) | |||
| def tanhshrink(input): | |||
| input = cast_to_ms_tensor(input) | |||
| ouput = input - ms.ops.functional.tanh(input) | |||
| return cast_to_adapter_tensor(ouput) | |||
| def glu(input, dim=-1): | |||
| if input.dim() == 0: | |||
| raise RuntimeError("glu does not support scalars because halving size must be even") | |||
| if input.shape[dim] % 2 == 1: | |||
| raise RuntimeError("Halving dimension must be even, but dimension {} is size {}".format(dim,input.shape[dim])) | |||
| halflen = input.shape[dim]//2 | |||
| data_a = input.narrow(axis=dim, start=0, length=halflen) | |||
| data_b = input.narrow(axis=dim, start=halflen, length=halflen) | |||
| data_a = cast_to_ms_tensor(data_a) | |||
| data_b = cast_to_ms_tensor(data_b) | |||
| sigmoid_data_b = ms.ops.sigmoid(data_b) | |||
| out = ms.ops.mul(data_a, sigmoid_data_b) | |||
| return cast_to_adapter_tensor(out) | |||
| def normalize(input, p=2.0, dim=1, eps=1e-12, out=None): | |||
| #the type of 'p' in ms.ops.functional.norm should be 'int' | |||
| input = cast_to_ms_tensor(input) | |||
| input_p = ms.ops.pow(abs(input), p) | |||
| input_p_sum = input_p.sum(axis = dim, keepdims=True) | |||
| norm = ms.ops.pow(input_p_sum, 1.0/p) | |||
| min_value = ms.Tensor(eps, ms.float32) | |||
| denom = ms.ops.clip_by_value(norm, min_value) | |||
| denom = denom.expand_as(input) | |||
| output = ms.ops.functional.div(input, denom) | |||
| if out is not None: | |||
| ms.ops.assign(out, output) | |||
| return out | |||
| return cast_to_adapter_tensor(output) | |||
| def softplus(input, beta=1, threshold=20): | |||
| input = cast_to_ms_tensor(input) | |||
| input_x = beta * input | |||
| dtype_op = _get_cache_prim(ms.ops.DType)() | |||
| cast_op = _get_cache_prim(ms.ops.Cast)() | |||
| alpha_array = cast_op(ms.ops.functional.scalar_to_tensor(threshold), dtype_op(input)) | |||
| mask = ms.ops.less(alpha_array, input_x) | |||
| input_mask = ms.ops.masked_fill(input_x, mask, 0) | |||
| out_mask = ms.ops.exp(input_mask) | |||
| out_mask_log = ms.ops.log1p(out_mask) | |||
| ret_mask = out_mask_log/beta | |||
| ret = ms.ops.select(mask, input, ret_mask) | |||
| return cast_to_adapter_tensor(ret) | |||
| def sigmoid(input): | |||
| input = cast_to_ms_tensor(input) | |||
| sigmoid_op = _get_cache_prim(ms.ops.Sigmoid)() | |||
| out = sigmoid_op(input) | |||
| return cast_to_adapter_tensor(out) | |||
| def hardsigmoid(input, inplace=False): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| hardsigmoid_op = _get_cache_prim(ms.ops.HSigmoid)() | |||
| out = hardsigmoid_op(input_ms) | |||
| return _inplace_assign_pynative(input, inplace, out, "hardsigmoid") | |||
| def silu(input, inplace=False): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| sigmoid_op = _get_cache_prim(ms.ops.Sigmoid)() | |||
| out = sigmoid_op(input_ms) * input_ms | |||
| return _inplace_assign_pynative(input, inplace, out, "silu") | |||
| def gumbel_softmax(logits, tau=1.0, hard=False, eps=1e-10, dim=-1): | |||
| if eps != 1e-10: | |||
| warnings.warn("`eps` parameter is deprecated and has no effect.") | |||
| logits = cast_to_ms_tensor(logits) | |||
| out = ms.ops.gumbel_softmax(logits, tau, hard, dim) | |||
| return cast_to_adapter_tensor(out) | |||
| def threshold(input, threshold, value, inplace=False): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| cond = ms.ops.gt(input_ms, threshold) | |||
| value = ms.ops.fill(input_ms.dtype, input_ms.shape, value) | |||
| out = ms.ops.select(cond, input_ms, value) | |||
| return _inplace_assign_pynative(input, inplace, out, "threshold") | |||
| rrelu_ = rrelu | |||
| relu_ = relu | |||
| elu_ = elu | |||
| hardtanh_ = hardtanh | |||
| leaky_relu_ = leaky_relu | |||
| threshold_ = threshold | |||
| @constexpr | |||
| def _get_reduce_string(size_average, reduce): | |||
| if size_average is None: | |||
| size_average = True | |||
| if reduce is None: | |||
| reduce = True | |||
| if size_average and reduce: | |||
| ret = 'mean' | |||
| elif reduce: | |||
| ret = 'sum' | |||
| else: | |||
| ret = 'none' | |||
| warning = "size_average and reduce args will be deprecated, please use reduction='{}' instead." | |||
| warnings.warn(warning.format(ret)) | |||
| return ret | |||
| def smooth_l1_loss(input, target, size_average=None, reduce=None, reduction='mean', beta=1.0): | |||
| if reduce is not None or size_average is not None: | |||
| reduction = _get_reduce_string(size_average, reduce) | |||
| input = cast_to_ms_tensor(input) | |||
| target = cast_to_ms_tensor(target) | |||
| output = ms.ops.smooth_l1_loss(input, target, beta, reduction) | |||
| if reduction != 'none': | |||
| return Tensor(output[0]) | |||
| return cast_to_adapter_tensor(output) | |||
| def _get_loss(x, reduction): | |||
| """ | |||
| Computes the loss. | |||
| """ | |||
| if reduction is None or reduction == 'none': | |||
| return x | |||
| def _get_axis(x): | |||
| shape = ms.ops.shape(x) | |||
| length = ms.ops.tuple_len(shape) | |||
| perm = ms.ops.make_range(0, length) | |||
| return perm | |||
| input_dtype = x.dtype | |||
| x = ms.ops.cast(x, ms.float32) | |||
| if reduction == 'mean': | |||
| reduce_mean_op = _get_cache_prim(ms.ops.ReduceMean)() | |||
| x = reduce_mean_op(x, _get_axis(x)) | |||
| if reduction == 'sum': | |||
| x = ms.ops.reduce_sum(x, _get_axis(x)) | |||
| x = ms.ops.cast(x, input_dtype) | |||
| return x | |||
| def l1_loss(input, target, size_average=None, reduce=None, reduction="mean"): | |||
| """ | |||
| Function that takes the mean element-wise absolute value difference. | |||
| """ | |||
| if reduce is not None or size_average is not None: | |||
| reduction = _get_reduce_string(size_average, reduce) | |||
| def _l1_loss_function(input, target, reduction): | |||
| x = ms.ops.abs(input - target) | |||
| return _get_loss(x, reduction) | |||
| input = cast_to_ms_tensor(input) | |||
| target = cast_to_ms_tensor(target) | |||
| # TODO: Replace with ms.ops.l1_loss | |||
| result = _l1_loss_function(input, target, reduction) | |||
| return cast_to_adapter_tensor(result) | |||
| def mse_loss(input, target, size_average=None, reduce=None, reduction="mean"): | |||
| """ | |||
| Measures the element-wise mean squared error. | |||
| """ | |||
| if reduce is not None or size_average is not None: | |||
| reduction = _get_reduce_string(size_average, reduce) | |||
| input = cast_to_ms_tensor(input) | |||
| target = cast_to_ms_tensor(target) | |||
| x = ms.ops.square(input - target) | |||
| result = _get_loss(x, reduction) | |||
| return cast_to_adapter_tensor(result) | |||
| def cross_entropy(input, target, weight=None, size_average=None, ignore_index=-100, | |||
| reduce=None, reduction="mean", label_smoothing=0.0): | |||
| """ | |||
| This criterion computes the cross entropy loss between input logits and target. | |||
| """ | |||
| if reduce is not None or size_average is not None: | |||
| reduction = _get_reduce_string(size_average, reduce) | |||
| input = cast_to_ms_tensor(input) | |||
| target = cast_to_ms_tensor(target) | |||
| weight = cast_to_ms_tensor(weight) | |||
| result = ms.ops.cross_entropy(input, target, weight, ignore_index, reduction, label_smoothing) | |||
| return cast_to_adapter_tensor(result) | |||
| def nll_loss(input, target, weight=None, size_average=None, ignore_index=-100, | |||
| reduce=None, reduction="mean"): | |||
| """ | |||
| The negative log likelihood loss. | |||
| """ | |||
| if reduce is not None or size_average is not None: | |||
| reduction = _get_reduce_string(size_average, reduce) | |||
| input = cast_to_ms_tensor(input) | |||
| target = cast_to_ms_tensor(target) | |||
| weight = cast_to_ms_tensor(weight) | |||
| result = ms.ops.nll_loss(input, target, weight, ignore_index, reduction, label_smoothing=0.0) | |||
| return cast_to_adapter_tensor(result) | |||
| def kl_div(input, target, size_average=None, reduce=None, reduction="mean", log_target=False): | |||
| """ | |||
| The `Kullback-Leibler divergence Loss. | |||
| <https://en.wikipedia.org/wiki/Kullback-Leibler_divergence>` | |||
| """ | |||
| if size_average is not None or reduce is not None: | |||
| reduction = _get_reduce_string(size_average, reduce) | |||
| # TODO | |||
| if log_target is True: | |||
| raise ValueError('`log_target` in `{}` can not support True'.format(kl_div.__name__)) | |||
| input = cast_to_ms_tensor(input) | |||
| target = cast_to_ms_tensor(target) | |||
| result = ms.ops.kl_div(input, target, reduction) | |||
| return cast_to_adapter_tensor(result) | |||
| def binary_cross_entropy(input, target, weight=None, size_average=None, reduce=None, reduction="mean"): | |||
| """ | |||
| Function that measures the Binary Cross Entropy between the target and input probabilities. | |||
| """ | |||
| if size_average is not None or reduce is not None: | |||
| reduction = _get_reduce_string(size_average, reduce) | |||
| input = cast_to_ms_tensor(input) | |||
| target = cast_to_ms_tensor(target) | |||
| weight = cast_to_ms_tensor(weight) | |||
| result = ms.ops.binary_cross_entropy(input, target, weight, reduction) | |||
| return cast_to_adapter_tensor(result) | |||
| def binary_cross_entropy_with_logits(input, target, weight=None, size_average=None, | |||
| reduce=None, reduction="mean", pos_weight=None): | |||
| """ | |||
| Function that measures Binary Cross Entropy between target and input logits. | |||
| """ | |||
| if size_average is not None or reduce is not None: | |||
| reduction = _get_reduce_string(size_average, reduce) | |||
| input = cast_to_ms_tensor(input) | |||
| target = cast_to_ms_tensor(target) | |||
| weight = cast_to_ms_tensor(weight) | |||
| pos_weight = cast_to_ms_tensor(pos_weight) | |||
| if weight is None or pos_weight is None: | |||
| ones_input = ms.ops.ones_like(input) | |||
| if weight is None: | |||
| weight = ones_input | |||
| if pos_weight is None: | |||
| pos_weight = ones_input | |||
| result = ms.ops.binary_cross_entropy_with_logits(input, target, weight, pos_weight, reduction) | |||
| return cast_to_adapter_tensor(result) | |||
| def _upsample_common_check(size, scale_factor): | |||
| if size is None and scale_factor is None: | |||
| raise ValueError("either size or scale_factor should be defined.") | |||
| if size is not None and scale_factor is not None: | |||
| raise ValueError("only one of size or scale_factor should be defined.") | |||
| def _upsample_common_process_size(size, scale_factor, shape): | |||
| input_shape = list(shape) | |||
| input_rank = len(shape) | |||
| if scale_factor is not None: | |||
| size_ = input_shape[2:] | |||
| for i, _ in enumerate(size_): | |||
| size_[i] *= scale_factor | |||
| else: | |||
| if not isinstance(size, (int, list, tuple)): | |||
| raise TypeError("`size` should be in types of int, list and tuple.") | |||
| if isinstance(size, int): | |||
| size_ = [size for i in range(2, input_rank)] | |||
| else: | |||
| if len(size) != input_rank - 2: | |||
| raise ValueError( | |||
| "Input and output must have the same number of spatial dimensions, but got " | |||
| f"input with spatial dimensions of {list(input_shape[2:])} and output size of {size}. " | |||
| "Please provide input tensor in (N, C, d1, d2, ...,dK) format and " | |||
| "output size in (o1, o2, ...,oK) format.") | |||
| size_ = size | |||
| return tuple(size_) | |||
| def upsample_nearest(input, size=None, scale_factor=None, *, align_corners=False): | |||
| input_shape = input.shape | |||
| if len(input_shape) != 4: | |||
| raise ValueError("Until now, upsample_nearest only support 4-D input.") | |||
| _upsample_common_check(size, scale_factor) | |||
| size_ = _upsample_common_process_size(size, scale_factor, input_shape) | |||
| input = cast_to_ms_tensor(input) | |||
| result = ms.ops.ResizeNearestNeighbor(size_, align_corners=align_corners)(input) | |||
| return cast_to_adapter_tensor(result) | |||
| def upsample_bilinear(input, size=None, scale_factor=None, *, align_corners=True): | |||
| input_shape = input.shape | |||
| if len(input_shape) != 4: | |||
| raise ValueError("Until now, upsample_bilinear only support 4-D input.") | |||
| _upsample_common_check(size, scale_factor) | |||
| size_ = _upsample_common_process_size(size, scale_factor, input_shape) | |||
| input = cast_to_ms_tensor(input) | |||
| if align_corners is True: | |||
| _cor_mode = "align_corners" | |||
| else: | |||
| # TODO: To support "half_pixel" on CPU | |||
| if get_backend() == 'CPU': | |||
| raise NotImplementedError("For upsample_bilinear, 'align_corners=False' is not supported on CPU.") | |||
| _cor_mode = "half_pixel" | |||
| result = ms.ops.interpolate(input, sizes=size_, coordinate_transformation_mode=_cor_mode, mode="bilinear") | |||
| return cast_to_adapter_tensor(result) | |||
| def pairwise_distance(x1, x2, p=2.0, eps=1e-06, keepdim=False): | |||
| x1 = cast_to_ms_tensor(x1) | |||
| x2 = cast_to_ms_tensor(x2) | |||
| input = x1-x2+eps | |||
| input_p = ms.ops.pow(ms.ops.abs(input), p) | |||
| input_p_sum = input_p.sum(axis=-1, keepdims=keepdim) | |||
| out = ms.ops.pow(input_p_sum, 1.0 / p) | |||
| return cast_to_adapter_tensor(out) | |||
| def cosine_similarity(x1, x2, dim=1, eps=1e-08): | |||
| x1 = cast_to_ms_tensor(x1) | |||
| x2 = cast_to_ms_tensor(x2) | |||
| while x1.ndim < x2.ndim: | |||
| x1 = x1.expand_dims(0) | |||
| while x2.ndim < x1.ndim: | |||
| x2 = x2.expand_dims(0) | |||
| if x1.size < x2.size: | |||
| x1 = ms.ops.broadcast_to(x1, x2.shape) | |||
| if x2.size < x1.size: | |||
| x2 = ms.ops.broadcast_to(x2, x1.shape) | |||
| min_value = ms.Tensor(eps, ms.float32) | |||
| x1_norm = ms.ops.pow(x1, 2) | |||
| x1_norm = x1_norm.sum(axis=dim) | |||
| x1_norm = ms.ops.pow(x1_norm, 1.0/2) | |||
| x1_norm = ms.ops.clip_by_value(x1_norm, min_value) | |||
| x2_norm = ms.ops.pow(x2, 2) | |||
| x2_norm = x2_norm.sum(axis=dim) | |||
| x2_norm = ms.ops.pow(x2_norm, 1.0/2) | |||
| x2_norm = ms.ops.clip_by_value(x2_norm, min_value) | |||
| denom = ms.ops.mul(x1_norm, x2_norm) | |||
| out = ms.ops.mul(x1, x2).sum(axis=dim)/denom | |||
| return cast_to_adapter_tensor(out) | |||
| def pdist(input, p=2): | |||
| inp_dim = input.dim() | |||
| if inp_dim != 2: | |||
| raise RuntimeError(f"pdist only supports 2D tensors, got: {inp_dim}D") | |||
| if p < 0: | |||
| raise RuntimeError("pdist only supports non-negative p values") | |||
| input = cast_to_ms_tensor(input) | |||
| n, m = input.shape | |||
| x = input.broadcast_to((n, n, m)).astype(ms.float32) | |||
| y = x.transpose(1, 0, 2) | |||
| norm = ms.ops.pow(ms.ops.abs(x-y), p) | |||
| norm = norm.sum(axis=-1) | |||
| if p > 0: | |||
| norm = ms.ops.pow(norm, 1.0/p) | |||
| select = np.ones([n, n]) | |||
| select = np.triu(select, 1).astype(np.bool8) | |||
| select_t = ms.Tensor(select) | |||
| out = ms.ops.masked_select(norm, select_t) | |||
| return cast_to_adapter_tensor(out) | |||
| def dropout1d(input, p = 0.5, training = True, inplace = False): | |||
| if p < 0.0 or p > 1.0: | |||
| raise ValueError("dropout probability has to be between 0 and 1, " "but got {}".format(p)) | |||
| inp_dim = input.dim() | |||
| if inp_dim not in (2, 3): | |||
| raise RuntimeError(f"dropout1d: Expected 2D or 3D input, but received a {inp_dim}D input. " | |||
| "Note that dropout1d exists to provide channel-wise dropout on inputs with 1 " | |||
| "spatial dimension, a channel dimension, and an optional batch dimension " | |||
| "(i.e. 2D or 3D inputs).") | |||
| # is_batched = inp_dim == 3 | |||
| if not training: | |||
| return input | |||
| input_ms = cast_to_ms_tensor(input) | |||
| out = ms.ops.dropout1d(input_ms, p) | |||
| return _inplace_assign_pynative(input, inplace, out, "dropout1d") | |||
| def dropout2d(input, p=0.5, training=True, inplace=False): | |||
| if p < 0.0 or p > 1.0: | |||
| raise ValueError("dropout probability has to be between 0 and 1, " "but got {}".format(p)) | |||
| inp_dim = input.dim() | |||
| if inp_dim not in (3, 4): | |||
| warn_msg = (f"dropout2d: Received a {inp_dim}-D input to dropout2d, which is deprecated " | |||
| "and will result in an error in a future release. To retain the behavior " | |||
| "and silence this warning, please use dropout instead. Note that dropout2d " | |||
| "exists to provide channel-wise dropout on inputs with 2 spatial dimensions, " | |||
| "a channel dimension, and an optional batch dimension (i.e. 3D or 4D inputs).") | |||
| warnings.warn(warn_msg) | |||
| if not training: | |||
| return input | |||
| if inp_dim == 3: | |||
| warnings.warn("dropout2d: Received a 3D input to dropout2d and assuming that channel-wise " | |||
| "1D dropout behavior is desired - input is interpreted as shape (N, C, L), where C " | |||
| "is the channel dim. This behavior will change in a future release to interpret the " | |||
| "input as one without a batch dimension, i.e. shape (C, H, W). To maintain the 1D " | |||
| "channel-wise dropout behavior, please switch to using dropout1d instead.") | |||
| return dropout1d(input, p, training, inplace) | |||
| input_ms = cast_to_ms_tensor(input) | |||
| out, _ = ms.ops.dropout2d(input_ms, p) | |||
| return _inplace_assign_pynative(input, inplace, out, "dropout2d") | |||
| def dropout3d(input, p=0.5, training=True, inplace=False): | |||
| if p < 0.0 or p > 1.0: | |||
| raise ValueError("dropout probability has to be between 0 and 1, " "but got {}".format(p)) | |||
| inp_dim = input.dim() | |||
| if inp_dim not in (4, 5): | |||
| warn_msg = (f"dropout3d: Received a {inp_dim}-D input to dropout3d, which is deprecated " | |||
| "and will result in an error in a future release. To retain the behavior " | |||
| "and silence this warning, please use dropout instead. Note that dropout3d " | |||
| "exists to provide channel-wise dropout on inputs with 3 spatial dimensions, " | |||
| "a channel dimension, and an optional batch dimension (i.e. 4D or 5D inputs).") | |||
| warnings.warn(warn_msg) | |||
| if not training: | |||
| return input | |||
| is_batched = inp_dim == 5 | |||
| input_ms = cast_to_ms_tensor(input) | |||
| if not is_batched: | |||
| input_ms = ms.ops.expand_dims(input_ms, 0) | |||
| out, _ = ms.ops.dropout3d(input_ms, p) | |||
| if not is_batched: | |||
| out = ms.ops.squeeze(out, 0) | |||
| return _inplace_assign_pynative(input, inplace, out, "dropout3d") | |||
| def dropout(input, p=0.5, training=True, inplace=False): | |||
| if p < 0.0 or p > 1.0: | |||
| raise ValueError("dropout probability has to be between 0 and 1, " "but got {}".format(p)) | |||
| if not training: | |||
| return input | |||
| input_ms = cast_to_ms_tensor(input) | |||
| shape = input_ms.shape | |||
| random_array_np = np.random.rand(input_ms.size).reshape(shape) | |||
| random_array = ms.Tensor(random_array_np, ms.float32) | |||
| mask = (random_array > ms.Tensor(p, ms.float32)) | |||
| out = mask * 1.0 / (1.0-p) * input_ms | |||
| return _inplace_assign_pynative(input, inplace, out, "dropout") | |||
| def alpha_dropout(input, p=0.5, training=False, inplace=False): | |||
| if p < 0.0 or p > 1.0: | |||
| raise ValueError("dropout probability has to be between 0 and 1, " "but got {}".format(p)) | |||
| if not training: | |||
| return input | |||
| input_x = cast_to_ms_tensor(input) | |||
| # mean = input.mean() | |||
| # var = input.var() | |||
| mean = 0.0 | |||
| var = 1.0 | |||
| scale = 1.0507009873554804934193349852946 | |||
| alpha = 1.6732632423543772848170429916717 | |||
| alpha_ = -scale * alpha | |||
| q = 1.0 - p | |||
| a = math.sqrt(var/(q*var + q*(1.0-q)*(alpha_-mean)*(alpha_-mean))) | |||
| b = mean - a*(q*mean + (1.0-q)*alpha_) | |||
| shape = input_x.shape | |||
| random_array_np = np.random.rand(input_x.size).reshape(shape) | |||
| random_array = ms.Tensor(random_array_np, ms.float32) | |||
| mask = (random_array > ms.Tensor(p, ms.float32)) | |||
| value = ms.ops.fill(input_x.dtype, shape, alpha_) | |||
| out = input_x * mask | |||
| out = ms.ops.select(mask, out, value) | |||
| out = out * a + b | |||
| return _inplace_assign_pynative(input, inplace, out, "alpha_dropout") | |||
| def feature_alpha_dropout(input, p=0.5, training=False, inplace=False): | |||
| if p < 0.0 or p > 1.0: | |||
| raise ValueError("dropout probability has to be between 0 and 1, " "but got {}".format(p)) | |||
| if not training: | |||
| return input | |||
| input_x = cast_to_ms_tensor(input) | |||
| # mean = input.mean() | |||
| # var = input.var() | |||
| mean = 0.0 | |||
| var = 1.0 | |||
| scale = 1.0507009873554804934193349852946 | |||
| alpha = 1.6732632423543772848170429916717 | |||
| alpha_ = -scale * alpha | |||
| q = 1.0 - p | |||
| a = math.sqrt(var/(q*var + q*(1.0-q)*(alpha_-mean)*(alpha_-mean))) | |||
| b = mean - a*(q*mean + (1.0-q)*alpha_) | |||
| shape = input_x.shape | |||
| random_array_np = np.random.rand(shape[0], shape[1]) | |||
| random_array = ms.Tensor(random_array_np, ms.float32) | |||
| if input_x.dim() > 2: | |||
| random_array = random_array.expand_dims(2) | |||
| random_array = random_array.expand_as(input_x.reshape(shape[0], shape[1], -1)).reshape(shape) | |||
| mask = (random_array > ms.Tensor(p, ms.float32)) | |||
| value = ms.ops.fill(input_x.dtype, input_x.shape, alpha_) | |||
| out = input_x * mask | |||
| out = ms.ops.select(mask, out, value) | |||
| out = out * a + b | |||
| return _inplace_assign_pynative(input, inplace, out, "feature_alpha_dropout") | |||
| def hardshrink(input, lambd=0.5): | |||
| input = cast_to_ms_tensor(input) | |||
| out = ms.ops.hardshrink(input, lambd) | |||
| return cast_to_adapter_tensor(out) | |||
| def huber_loss(input, target, reduction='mean', delta=1.0): | |||
| input = cast_to_ms_tensor(input) | |||
| target = cast_to_ms_tensor(target) | |||
| delta_half = 0.5 * delta | |||
| z = ms.ops.abs(ms.ops.sub(input, target)) | |||
| condition = ms.ops.less(z, delta) | |||
| l1 = ms.ops.mul(0.5, ms.ops.square(z)) | |||
| l2 = ms.ops.mul(delta, ms.ops.sub(z, delta_half)) | |||
| loss = ms.ops.select(condition, l1, l2) | |||
| loss = _get_loss(loss, reduction) | |||
| return cast_to_adapter_tensor(loss) | |||
| def soft_margin_loss(input, target, size_average=None, reduce=None, reduction='mean'): | |||
| if size_average is not None or reduce is not None: | |||
| reduction = _get_reduce_string(size_average, reduce) | |||
| input = cast_to_ms_tensor(input) | |||
| target = cast_to_ms_tensor(target) | |||
| ops = ms.ops.SoftMarginLoss(reduction) | |||
| loss = ops(input, target) | |||
| return cast_to_adapter_tensor(loss) | |||
| def cosine_embedding_loss( | |||
| input1, | |||
| input2, | |||
| target, | |||
| margin=0, | |||
| size_average=None, | |||
| reduce=None, | |||
| reduction="mean", | |||
| ): | |||
| if margin < -1.0 or margin > 1.0: | |||
| raise ValueError(f"'cosine_embedding_loss': `margin` should be from -1 to 1, but got {margin}") | |||
| if size_average is not None or reduce is not None: | |||
| reduction = _get_reduce_string(size_average, reduce) | |||
| input1 = cast_to_ms_tensor(input1) | |||
| input2 = cast_to_ms_tensor(input2) | |||
| target = cast_to_ms_tensor(target) | |||
| reduce_sum = _get_cache_prim(ms.ops.ReduceSum)() | |||
| maximum = _get_cache_prim(ms.ops.Maximum)() | |||
| prod_sum = reduce_sum(input1 * input2, (1,)) | |||
| square1 = reduce_sum(ms.ops.square(input1), (1,)) | |||
| square2 = reduce_sum(ms.ops.square(input2), (1,)) | |||
| denom = ms.ops.sqrt(square1) * ms.ops.sqrt(square2) | |||
| cosine = prod_sum / denom | |||
| pos_value = 1.0 - cosine | |||
| neg_value = maximum(cosine - margin, 0.0) | |||
| zeros = ms.ops.zeros_like(cosine) | |||
| pos_part = ms.ops.select(target == 1, pos_value, zeros) | |||
| neg_part = ms.ops.select(target == -1, neg_value, zeros) | |||
| output_unreduced = pos_part + neg_part | |||
| loss = _get_loss(output_unreduced, reduction) | |||
| return cast_to_adapter_tensor(loss) | |||
| def triplet_margin_loss( | |||
| anchor, | |||
| positive, | |||
| negative, | |||
| margin=1.0, | |||
| p=2, | |||
| eps=1e-6, | |||
| swap=False, | |||
| size_average=None, | |||
| reduce=None, | |||
| reduction="mean", | |||
| ): | |||
| if size_average is not None or reduce is not None: | |||
| reduction = _get_reduce_string(size_average, reduce) | |||
| anchor, positive, negative = cast_to_ms_tensor((anchor, positive, negative)) | |||
| margin = ms.ops.scalar_to_tensor(margin) | |||
| # TODO: 'TripletMarginLossOp' is a inner interface, should be change to public api in the future | |||
| triplet_margin_loss = _get_cache_prim(TripletMarginLossOp)(p=p, swap=swap, eps=eps, reduction=reduction) | |||
| loss = triplet_margin_loss(anchor, positive, negative, margin) | |||
| return cast_to_adapter_tensor(loss) | |||
| def multi_margin_loss( | |||
| input, | |||
| target, | |||
| p=1, | |||
| margin=1.0, | |||
| weight=None, | |||
| size_average=None, | |||
| reduce=None, | |||
| reduction="mean", | |||
| ): | |||
| if size_average is not None or reduce is not None: | |||
| reduction = _get_reduce_string(size_average, reduce) | |||
| if p not in (1, 2): | |||
| raise ValueError("only p == 1 and p == 2 supported") | |||
| input, target = cast_to_ms_tensor((input, target)) | |||
| if weight is not None: | |||
| if weight.dim() != 1: | |||
| raise ValueError("weight must be one-dimensional") | |||
| weight = cast_to_ms_tensor(weight) | |||
| loss = ms.ops.multi_margin_loss(input, target, p=p, margin=margin, weight=weight, reduction=reduction) | |||
| return cast_to_adapter_tensor(loss) | |||
| loss = ms.ops.multi_margin_loss(input, target, p=p, margin=margin, weight=weight, reduction=reduction) | |||
| return cast_to_adapter_tensor(loss) | |||
| def avg_pool2d(input, kernel_size, stride=None, padding=0, ceil_mode=False, | |||
| count_include_pad=True, divisor_override=None): | |||
| unsupported_attr(ceil_mode) | |||
| unsupported_attr(count_include_pad) | |||
| unsupported_attr(divisor_override) | |||
| if stride is None: | |||
| stride = kernel_size | |||
| padding = padding if isinstance(padding, tuple) else (padding, padding) | |||
| pad_ops = ms.ops.Pad(((0, 0), (0, 0), (padding[0], padding[0]), (padding[1], padding[1]))) | |||
| avg_pool_ops = ms.ops.AvgPool(kernel_size=kernel_size, strides=stride, pad_mode='valid') | |||
| input = cast_to_ms_tensor(input) | |||
| input = pad_ops(input) | |||
| out = avg_pool_ops(input) | |||
| return cast_to_adapter_tensor(out) | |||
| def local_response_norm(input, size, alpha=0.0001, beta=0.75, k=1.0): | |||
| dim = input.dim() | |||
| if dim < 3: | |||
| raise ValueError( | |||
| "Expected 3D or higher dimensionality \ | |||
| input (got {} dimensions)".format( | |||
| dim | |||
| ) | |||
| ) | |||
| if input.size() == 0: | |||
| return input | |||
| input = cast_to_ms_tensor(input) | |||
| div = ms.ops.mul(input, input).expand_dims(axis=1) | |||
| if dim == 3: | |||
| div = ms.ops.pad(div, ((0, 0), (0, 0), (size//2, (size-1)//2), (0, 0))) | |||
| div = ms.ops.avg_pool2d(div, (size, 1), stride=1).squeeze(1) | |||
| else: | |||
| shape = input.shape | |||
| div = div.view(shape[0], 1, shape[1], shape[2], -1) | |||
| div = ms.ops.pad(div, ((0, 0), (0, 0), (size//2, (size-1)//2), (0, 0), (0, 0))) | |||
| div = _get_cache_prim(ms.ops.AvgPool3D)((size, 1, 1), strides=1)(div).squeeze(1) | |||
| div = div.view(shape) | |||
| div = div * alpha + k | |||
| div = ms.ops.pow(div, beta) | |||
| output = input / div | |||
| return cast_to_adapter_tensor(output) | |||
| def one_hot(input, num_classes=-1): | |||
| if num_classes == -1: | |||
| depth = int(input.asnumpy().max()) + 1 | |||
| else: | |||
| depth = num_classes | |||
| input = cast_to_ms_tensor(input) | |||
| on_value = ms.Tensor(1.0, ms.float32) | |||
| off_value = ms.Tensor(0.0, ms.float32) | |||
| out = ms.ops.one_hot(input, depth, on_value, off_value).astype(ms.int64) | |||
| return cast_to_adapter_tensor(out) | |||
| def pixel_shuffle(input, upscale_factor): | |||
| dim = input.dim() | |||
| if dim < 3: | |||
| raise RuntimeError("pixel_shuffle expects input to have at least 3 dimensions, " | |||
| "but got input with {} dimension(s)".format(dim)) | |||
| input = cast_to_ms_tensor(input) | |||
| if dim == 3: | |||
| input = input.expand_dims(0) | |||
| shape_in = list(input.shape) | |||
| tmp = input.reshape(-1, shape_in[-3], shape_in[-2], shape_in[-1]) | |||
| c = int(tmp.shape[-3] / upscale_factor / upscale_factor) | |||
| if c * upscale_factor * upscale_factor != tmp.shape[-3]: | |||
| raise RuntimeError( | |||
| "pixel_shuffle expects its input's 'channel' dimension to be divisible by the square of upscale_factor," | |||
| "but input.size(-3)={} is not divisible by {}".format(tmp.shape[-3], upscale_factor*upscale_factor)) | |||
| h = tmp.shape[-2] | |||
| w = tmp.shape[-1] | |||
| tmp = tmp.reshape(-1, c, upscale_factor, upscale_factor, h, w).transpose(0, 1, 4, 2, 5, 3) | |||
| out = tmp.reshape(-1, c, h * upscale_factor, w * upscale_factor) | |||
| shape_in[-3] = c | |||
| shape_in[-2] = h * upscale_factor | |||
| shape_in[-1] = w * upscale_factor | |||
| out = out.reshape(shape_in) | |||
| if dim == 3: | |||
| out = out.squeeze(0) | |||
| return cast_to_adapter_tensor(out) | |||
| def pixel_unshuffle(input, downscale_factor): | |||
| dim = input.dim() | |||
| if dim < 3: | |||
| raise RuntimeError("pixel_shuffle expects input to have at least 3 dimensions, " | |||
| "but got input with {} dimension(s)".format(dim)) | |||
| input = cast_to_ms_tensor(input) | |||
| if dim == 3: | |||
| input = input.expand_dims(0) | |||
| shape_in = list(input.shape) | |||
| tmp = input.reshape(-1, shape_in[-3], shape_in[-2], shape_in[-1]) | |||
| c = tmp.shape[-3] | |||
| h = int(tmp.shape[-2] / downscale_factor) | |||
| w = int(tmp.shape[-1] / downscale_factor) | |||
| if h * downscale_factor != tmp.shape[-2]: | |||
| raise RuntimeError( | |||
| "pixel_unshuffle expects height to be divisible by downscale_factor, " | |||
| "but input.size(-2)={} is not divisible by {}".format(tmp.shape[-2], downscale_factor)) | |||
| if w * downscale_factor != tmp.shape[-1]: | |||
| raise RuntimeError( | |||
| "pixel_unshuffle expects width to be divisible by downscale_factor, " | |||
| "but input.size(-1)={} is not divisible by {}".format(tmp.shape[-1], downscale_factor)) | |||
| tmp = tmp.reshape(-1, c, h, downscale_factor, w, downscale_factor).transpose(0, 1, 3, 5, 2, 4) | |||
| out = tmp.reshape(-1, c * downscale_factor * downscale_factor, h, w) | |||
| shape_in[-3] = c * downscale_factor * downscale_factor | |||
| shape_in[-2] = h | |||
| shape_in[-1] = w | |||
| out = out.reshape(shape_in) | |||
| if dim == 3: | |||
| out = out.squeeze(0) | |||
| return cast_to_adapter_tensor(out) | |||
| def interpolate(input, | |||
| size=None, | |||
| scale_factor=None, | |||
| mode='nearest', | |||
| align_corners=None, | |||
| recompute_scale_factor=None, | |||
| antialias=False): | |||
| unsupported_attr(recompute_scale_factor) | |||
| unsupported_attr(antialias) | |||
| if mode in ("nearest", "area", "nearest-exact"): | |||
| if align_corners is not None: | |||
| raise ValueError( | |||
| "align_corners option can only be set with the " | |||
| "interpolating modes: linear | bilinear | bicubic | trilinear" | |||
| ) | |||
| align_corners = False | |||
| else: | |||
| if align_corners is None: | |||
| align_corners = False | |||
| if recompute_scale_factor is not None and recompute_scale_factor: | |||
| # TODO: not support these two arguments until now | |||
| pass | |||
| if antialias: | |||
| raise NotImplementedError("antialias in interpolate is not supported to True.") | |||
| # TODO: not support `antialias` until now. | |||
| if antialias and not (mode in ("bilinear", "bicubic") and input.ndim == 4): | |||
| raise ValueError("Anti-alias option is only supported for bilinear and bicubic modes") | |||
| # TODO: 'nearest' only support 4D input. 3D, 5D are not support until now. | |||
| if mode == 'nearest': | |||
| if input.dim() != 4: | |||
| raise NotImplementedError(f"For now, 'nearest' only 4D input is supported, but got {input.dim()}D") | |||
| return upsample_nearest(input, size, scale_factor, align_corners=align_corners) | |||
| # TODO: 'bilinear' only support 4D input. 3D, 5D are not support until now. | |||
| if mode == 'bilinear': | |||
| if input.dim() != 4: | |||
| raise NotImplementedError(f"For now, 'bilinear' only 4D input is supported, but got {input.dim()}D") | |||
| # TODO: To support "align_corners=False" on CPU | |||
| if align_corners is False and get_backend() == 'CPU': | |||
| raise NotImplementedError("For interpolate, if 'mode='bilinear'', " | |||
| "'align_corners=False' is not supported on CPU.") | |||
| return upsample_bilinear(input, size, scale_factor, align_corners=align_corners) | |||
| if mode == 'linear': | |||
| if input.dim() != 3: | |||
| raise ValueError(f"'linear' mode only support 3D input, but got {input.dim()}D") | |||
| if align_corners is True: | |||
| trans_mode = 'align_corners' | |||
| else: | |||
| trans_mode = 'half_pixel' | |||
| _size =_upsample_common_process_size(size=size, scale_factor=scale_factor, shape=input.shape) | |||
| input = cast_to_ms_tensor(input) | |||
| out = ms.ops.interpolate(input, scales=None, sizes=_size, | |||
| coordinate_transformation_mode=trans_mode, mode=mode) | |||
| return cast_to_adapter_tensor(out) | |||
| if mode in ['bicubic', 'trilinear', 'area', 'nearest-exact']: | |||
| raise NotImplementedError(f"For interpolate: currently not support mode '{mode}'") | |||
| raise NotImplementedError( | |||
| "Input Error: Only 3D, 4D and 5D input Tensors supported" | |||
| " (got {}D) for the modes: nearest | linear | bilinear | bicubic | trilinear | area | nearest-exact" | |||
| " (got {})".format(input.dim(), mode) | |||
| ) | |||
| def embedding( | |||
| input, | |||
| weight, | |||
| padding_idx=None, | |||
| max_norm=None, | |||
| norm_type=2.0, | |||
| scale_grad_by_freq=False, | |||
| sparse=False | |||
| ): | |||
| unsupported_attr(scale_grad_by_freq) | |||
| unsupported_attr(sparse) | |||
| if padding_idx: | |||
| raise NotImplementedError("nn.Embedding: `padding_idx` is not supported until now.") | |||
| input = cast_to_ms_tensor(input) | |||
| if padding_idx is not None: | |||
| if padding_idx > 0: | |||
| if padding_idx >= weight.shape[0]: | |||
| raise ValueError("Padding_idx must be within num_embeddings") | |||
| elif padding_idx < 0: | |||
| if padding_idx < -weight.shape[0]: | |||
| raise ValueError("Padding_idx must be within num_embeddings") | |||
| padding_idx = weight.shape[0] + padding_idx | |||
| # TODO: norm_type only support '2', others are not supported yet | |||
| if norm_type != 2: | |||
| raise NotImplementedError("`norm_type` beside 2 is not supported until now.") | |||
| # TODO: Try to let 'weight[padding_idx]' not updating by gradient, but pynative didn't work. | |||
| # Actually, when use "weight[padding_idx] = ...", it will create ops 'TensorScatterUpdate' | |||
| # And 'TensorScatterUpdate''s backprop can meet that it would not pass gradient to weight[padding_idx]. | |||
| # However, when directly use 'TensorScatterUpdate', ops will be eliminated in graph optimization. | |||
| # So, that is the problem to solve, which means the 'padding_idx' will be supported in the future. | |||
| if max_norm: | |||
| weight = _get_cache_prim(ms.nn.ClipByNorm)(axis=1)(weight, clip_norm=ms.ops.scalar_to_tensor(max_norm)) | |||
| out = ms.ops.gather(weight, input, axis=0) | |||
| return cast_to_adapter_tensor(out) | |||
| def grid_sample(input, grid, mode='bilinear', padding_mode='zeros', align_corners=None): | |||
| input = cast_to_ms_tensor(input) | |||
| grid = cast_to_ms_tensor(grid) | |||
| if align_corners is None: | |||
| align_corners = False | |||
| output = ms.ops.grid_sample(input, grid, interpolation_mode=mode, | |||
| padding_mode=padding_mode, align_corners=align_corners) | |||
| output = cast_to_adapter_tensor(output) | |||
| return output | |||
| def conv1d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1): | |||
| # TODO: not support float64, change to float32 now | |||
| input_ms = cast_to_ms_tensor(input) | |||
| weight_ms = cast_to_ms_tensor(weight) | |||
| is_float64 = False | |||
| if input_ms.dtype in (ms.float64, ms.double): | |||
| input_ms = input_ms.astype(ms.float32) | |||
| weight_ms = weight_ms.astype(ms.float32) | |||
| is_float64 = True | |||
| if isinstance(stride, tuple): | |||
| stride = stride[0] | |||
| pad_mode = "pad" | |||
| if isinstance(padding, int): | |||
| padding = (0, 0, padding, padding) | |||
| elif isinstance(padding, tuple): | |||
| padding = (0, 0, padding[0], padding[0]) | |||
| else: | |||
| pad_mode = padding | |||
| padding = 0 | |||
| if isinstance(dilation, tuple): | |||
| dilation = dilation[0] | |||
| input_shape = input_ms.shape | |||
| if len(input_shape) != 3: | |||
| raise ValueError(f"For 'conv1d', the dimension of input must be 3d, but got {len(input_shape)}.") | |||
| input_ms = ms.ops.expand_dims(input_ms, 2) | |||
| weight_ms = ms.ops.expand_dims(weight_ms, 2) | |||
| output = ms.ops.conv2d(input_ms, weight_ms, pad_mode, padding, stride, dilation, groups) | |||
| if bias is not None: | |||
| # TODO: ms.ops.biasadd also not support float64 | |||
| if bias.dtype != output.dtype: | |||
| bias = bias.astype(output.dtype) | |||
| output = ms.ops.bias_add(output, bias) | |||
| output = ms.ops.squeeze(output, 2) | |||
| if is_float64: | |||
| output = output.astype(ms.float64) | |||
| return cast_to_adapter_tensor(output) | |||
| def conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1): | |||
| # Todo: not support float64, change to float32 now | |||
| input_ms = cast_to_ms_tensor(input) | |||
| weight_ms = cast_to_ms_tensor(weight) | |||
| is_float64 = False | |||
| if input_ms.dtype in (ms.float64, ms.double): | |||
| input_ms = input_ms.astype(ms.float32) | |||
| weight_ms = weight_ms.astype(ms.float32) | |||
| is_float64 = True | |||
| if isinstance(stride, int): | |||
| stride = (stride, stride) | |||
| elif len(stride)==1: | |||
| stride = (stride[0], stride[0]) | |||
| pad_mode = "pad" | |||
| if isinstance(padding, int): | |||
| padding = (padding, padding, padding, padding) | |||
| elif isinstance(padding, tuple): | |||
| if len(padding)==1: | |||
| padding = (padding[0], padding[0], padding[0], padding[0]) | |||
| else: | |||
| padding = (padding[0], padding[0], padding[1], padding[1]) | |||
| else: | |||
| pad_mode = padding | |||
| padding = 0 | |||
| if isinstance(dilation, int): | |||
| dilation = (dilation, dilation) | |||
| elif len(dilation) == 1: | |||
| dilation = (dilation[0], dilation[0]) | |||
| output = ms.ops.conv2d(input_ms, weight_ms, pad_mode, padding, stride, dilation, groups) | |||
| if bias is not None: | |||
| # TODO: ms.ops.biasadd also not support float64 | |||
| if bias.dtype != output.dtype: | |||
| bias = bias.astype(output.dtype) | |||
| output = ms.ops.bias_add(output, bias) | |||
| if is_float64: | |||
| output = output.astype(ms.float64) | |||
| return cast_to_adapter_tensor(output) | |||
| def max_pool2d(input, kernel_size, stride=None, padding=0, dilation=1, | |||
| ceil_mode=False, return_indices=False): | |||
| unsupported_attr(ceil_mode) | |||
| unsupported_attr(return_indices) | |||
| unsupported_attr(dilation) | |||
| if return_indices is True or dilation != 1: | |||
| raise NotImplementedError("These parameters cannot be set now.") | |||
| _kernel_size = kernel_size if isinstance(kernel_size, tuple) else (kernel_size, kernel_size) | |||
| if stride is None: | |||
| _stride = _kernel_size | |||
| else: | |||
| _stride = stride if isinstance(stride, tuple) else (stride, stride) | |||
| _padding = padding if isinstance(padding, tuple) else (padding, padding) | |||
| _dilation = dilation if isinstance(dilation, tuple) else (dilation, dilation) | |||
| _extra_pad_h = 0 | |||
| _extra_pad_w = 0 | |||
| if ceil_mode: | |||
| _input_shape = ms.ops.shape(input) | |||
| _valid_in_h = (_input_shape[2] + _padding[0] * 2 - _dilation[0] * (_kernel_size[0] - 1) - 1) | |||
| _valid_out_h = _valid_in_h // _stride[0] | |||
| tmp = _valid_out_h * _stride[0] | |||
| if tmp < _valid_in_h: | |||
| _extra_pad_h = tmp + _stride[0] - _valid_in_h | |||
| _valid_in_w = (_input_shape[3] + _padding[1] * 2 - _dilation[1] * (_kernel_size[1] - 1) - 1) | |||
| _valid_out_w = _valid_in_w // _stride[1] | |||
| tmp = _valid_out_w * _stride[1] | |||
| if tmp < _valid_in_w: | |||
| _extra_pad_w = tmp + _stride[1] - _valid_in_w | |||
| # TODO: _pad = (_padding[1], _padding[1] + _extra_pad_w, _padding[0], _padding[0] + _extra_pad_h) | |||
| _pad = (((0, 0), (0, 0), (_padding[0], _padding[0] + _extra_pad_h), (_padding[1], _padding[1] + _extra_pad_w))) | |||
| _max_pool = ms.ops.MaxPool(kernel_size=_kernel_size, strides=_stride, pad_mode='valid') | |||
| _pad_op = _get_cache_prim(ms.ops.Pad)(_pad) | |||
| input = cast_to_ms_tensor(input) | |||
| # TODO: to support `value=float("inf")` in ms.ops.pad in future version | |||
| # TODO: ms.ops.pad not support on ascend | |||
| # input = ms.ops.pad(input, _pad) | |||
| input = _pad_op(input) | |||
| out = _max_pool(input) | |||
| return cast_to_adapter_tensor(out) | |||
| def max_unpool1d(input, indices, kernel_size, stride, padding, output_size = None): | |||
| input = cast_to_ms_tensor(input) | |||
| indices = cast_to_ms_tensor(indices) | |||
| out = ms.ops.max_unpool1d(input, indices, kernel_size, stride, padding, output_size) | |||
| return out | |||
| def max_unpool2d(input, indices, kernel_size, stride, padding, output_size = None): | |||
| input = cast_to_ms_tensor(input) | |||
| indices = cast_to_ms_tensor(indices) | |||
| out = ms.ops.max_unpool2d(input, indices, kernel_size, stride, padding, output_size) | |||
| return out | |||
| def max_unpool3d(input, indices, kernel_size, stride, padding, output_size = None): | |||
| input = cast_to_ms_tensor(input) | |||
| indices = cast_to_ms_tensor(indices) | |||
| out = ms.ops.max_unpool3d(input, indices, kernel_size, stride, padding, output_size) | |||
| return cast_to_adapter_tensor(out) | |||
| def linear(input, weight, bias=None): | |||
| @constexpr | |||
| def get_transpose_perm(shape): | |||
| _rank = len(shape) | |||
| perm = list(i for i in range(_rank)) | |||
| _tmp = perm[-1] | |||
| perm[-1] = perm[-2] | |||
| perm[-2] = _tmp | |||
| return tuple(perm) | |||
| weight_shape = weight.shape | |||
| weight_rank = len(weight_shape) | |||
| if weight_rank not in (1, 2): | |||
| raise ValueError("For nn.functional.linear, weight only support 2D or 1D input" | |||
| f"but got {weight_rank}D input") | |||
| if weight_rank == 2: | |||
| weight = ms.ops.transpose(weight, get_transpose_perm(weight_shape)) | |||
| input = cast_to_ms_tensor(input) | |||
| output = ms.ops.matmul(input, weight) | |||
| if bias is not None: | |||
| output = ms.ops.add(output, bias) | |||
| output = cast_to_adapter_tensor(output) | |||
| return output | |||
| def lp_pool1d(input, norm_type, kernel_size, stride = None, ceil_mode = False): | |||
| input = cast_to_ms_tensor(input) | |||
| output = ms.ops.lp_pool1d(input, norm_type, kernel_size, stride, ceil_mode) | |||
| return cast_to_adapter_tensor(output) | |||
| def lp_pool2d(input, norm_type, kernel_size, stride = None, ceil_mode = False): | |||
| input = cast_to_ms_tensor(input) | |||
| output = ms.ops.lp_pool2d(input, norm_type, kernel_size, stride, ceil_mode) | |||
| return cast_to_adapter_tensor(output) | |||
| def fractional_max_pool2d(input_x, kernel_size, output_size=None, output_ratio=None, return_indices=False, | |||
| _random_samples=None): | |||
| input_ms = cast_to_ms_tensor(input_x) | |||
| _kernel_size = kernel_size | |||
| _output_size = output_size | |||
| _output_ratio = output_ratio | |||
| _return_indices = return_indices | |||
| __random_samples = _random_samples | |||
| out = ms.ops.fractional_max_pool2d(input_ms, _kernel_size, _output_size, _output_ratio, _return_indices, | |||
| __random_samples) | |||
| return cast_to_adapter_tensor(out) | |||
| def fractional_max_pool3d(input_x, kernel_size, output_size=None, output_ratio=None, return_indices=False, | |||
| _random_samples=None): | |||
| input_ms = cast_to_ms_tensor(input_x) | |||
| _kernel_size = kernel_size | |||
| _output_size = output_size | |||
| _output_ratio = output_ratio | |||
| _return_indices = return_indices | |||
| __random_samples = _random_samples | |||
| out = ms.ops.fractional_max_pool3d(input_ms, _kernel_size, _output_size, _output_ratio, _return_indices, | |||
| __random_samples) | |||
| return cast_to_adapter_tensor(out) | |||
| def avg_pool1d(input_x, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True): | |||
| input_ms = cast_to_ms_tensor(input_x) | |||
| if input_ms.ndim == 2: | |||
| _input_ms = input_ms[None, ...] | |||
| else: | |||
| _input_ms = input_ms | |||
| if stride is None: | |||
| _stride = kernel_size | |||
| else: | |||
| _stride = stride | |||
| out = ms.ops.avg_pool1d(_input_ms, kernel_size, _stride, padding, ceil_mode, count_include_pad) | |||
| if input_ms.ndim == 2: | |||
| out = out.squeeze(0) | |||
| return cast_to_adapter_tensor(out) | |||
| def avg_pool3d(input, kernel_size, stride=None, padding=0, | |||
| ceil_mode=False, count_include_pad=True, divisor_override=None): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| if input_ms.ndim == 4: | |||
| _input_ms = input_ms[None,...] | |||
| else: | |||
| _input_ms = input_ms | |||
| if stride is None: | |||
| _stride = kernel_size | |||
| else: | |||
| _stride = stride | |||
| if divisor_override is None: | |||
| _divisor_override = 0 | |||
| else: | |||
| _divisor_override = divisor_override | |||
| if isinstance(padding, tuple) and len(padding) == 3: | |||
| _padding = (padding[0], padding[0], padding[1], padding[1], padding[2], padding[2]) | |||
| else: | |||
| _padding = padding | |||
| out = ms.ops.avg_pool3d(_input_ms, kernel_size, _stride, _padding, ceil_mode, count_include_pad, _divisor_override) | |||
| if input_ms.ndim == 4: | |||
| out = out.squeeze(0) | |||
| return cast_to_adapter_tensor(out) | |||
| def max_pool1d(input, kernel_size, stride=None, padding=0, dilation=1, ceil_mode=False, return_indices=False): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| if input_ms.ndim == 2: | |||
| _input_ms = input_ms[None,...,None,None] | |||
| elif input_ms.ndim == 3: | |||
| _input_ms = input_ms[..., None, None] | |||
| else: | |||
| _input_ms = input_ms | |||
| if isinstance(kernel_size, int): | |||
| _kernel_size = (kernel_size, 1, 1) | |||
| elif isinstance(kernel_size, tuple): | |||
| _kernel_size = kernel_size + (1, 1) | |||
| else: | |||
| _kernel_size = kernel_size | |||
| if stride is None: | |||
| _stride = (kernel_size, 1, 1) | |||
| elif isinstance(stride, int): | |||
| _stride = (stride, 1, 1) | |||
| elif isinstance(stride, tuple): | |||
| _stride = stride + (1, 1) | |||
| else: | |||
| _stride = stride | |||
| _padding = (padding, 0, 0) | |||
| _dilation = (dilation, 1, 1) | |||
| out = ms.ops.max_pool3d(_input_ms, _kernel_size, _stride, _padding, _dilation, ceil_mode, return_indices) | |||
| if isinstance(out, tuple): | |||
| out = list(out) | |||
| for id, value in enumerate(out): | |||
| out[id] = value.squeeze(-1).squeeze(-1) | |||
| if input_ms.ndim == 2: | |||
| out[id] = out[id].squeeze(0) | |||
| out = tuple(out) | |||
| else: | |||
| out = out.squeeze(-1).squeeze(-1) | |||
| if input_ms.ndim == 2: | |||
| out = out.squeeze(0) | |||
| return cast_to_adapter_tensor(out) | |||
| def max_pool3d(input, kernel_size, stride=None, padding=0, dilation=1, ceil_mode=False, return_indices=False): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| if input_ms.ndim == 4: | |||
| _input_ms = input_ms[None, ...] | |||
| else: | |||
| _input_ms = input_ms | |||
| out = ms.ops.max_pool3d(_input_ms, kernel_size, stride, padding, dilation, ceil_mode, return_indices) | |||
| if input_ms.ndim == 4: | |||
| if isinstance(out, tuple): | |||
| out = list(out) | |||
| for id, value in enumerate(out): | |||
| out[id] = value.squeeze(0) | |||
| out = tuple(out) | |||
| else: | |||
| out = out.squeeze(0) | |||
| return cast_to_adapter_tensor(out) | |||
| def conv_transpose1d(inputs, weight, bias=None, stride=1, padding=0, output_padding=0, groups=1, dilation=1): | |||
| inputs = cast_to_ms_tensor(inputs) | |||
| weight = cast_to_ms_tensor(weight) | |||
| has_bias = bias is not None | |||
| bias = cast_to_ms_tensor(bias) if bias is not None else 'zeros' | |||
| if len(inputs.shape) != 3: | |||
| raise ValueError("the rank of inputs tensor should be 3.") | |||
| if len(weight.shape) != 3: | |||
| raise ValueError("the rank of weight tensor should be 3") | |||
| in_channel = inputs.shape[1] | |||
| out_channel = weight.shape[1] * groups | |||
| kernel_size = weight.shape[2] | |||
| if stride != 1 and padding == (kernel_size - 1) // 2 and output_padding == stride - 1: | |||
| pad_mode = 'same' | |||
| padding = 0 | |||
| raise Warning("pad_mode = same is some thing wrong, please switch to others") | |||
| elif stride != 1 and padding == 0 and output_padding == 0: | |||
| pad_mode = 'valid' | |||
| padding = 0 | |||
| else: | |||
| pad_mode = 'pad' | |||
| _conv_1d_transpose = nn.Conv1dTranspose( | |||
| in_channels=in_channel, out_channels=out_channel, kernel_size=kernel_size, stride=stride, | |||
| pad_mode=pad_mode, padding=padding, dilation=dilation, group=groups, has_bias=has_bias, | |||
| weight_init=weight, bias_init=bias) | |||
| out = _conv_1d_transpose(inputs) | |||
| return cast_to_adapter_tensor(out) | |||
| def conv_transpose2d(inputs, weight, bias=None, stride=1, padding=0, output_padding=0, groups=1, dilation=1): | |||
| inputs = cast_to_ms_tensor(inputs) | |||
| weight = cast_to_ms_tensor(weight) | |||
| has_bias = bias is not None | |||
| bias = cast_to_ms_tensor(bias) if bias is not None else 'zeros' | |||
| if len(inputs.shape) != 4: | |||
| raise ValueError("the rank of inputs tensor should be 4.") | |||
| if len(weight.shape) != 4: | |||
| raise ValueError("the rank of weight tensor should be 4") | |||
| in_channel = inputs.shape[1] | |||
| out_channel = weight.shape[1] * groups | |||
| kernel_size = weight.shape[2:] | |||
| if isinstance(padding, tuple): | |||
| padding = list(np.repeat(padding, 2)) | |||
| # convert default data type 'int64' to 'int' | |||
| padding = tuple(map(int, padding)) | |||
| if stride != 1 and padding == 0 and output_padding == 0: | |||
| pad_mode = 'valid' | |||
| padding = 0 | |||
| else: | |||
| pad_mode = 'pad' | |||
| _conv_2d_transpose = nn.Conv2dTranspose( | |||
| in_channels=in_channel, out_channels=out_channel, kernel_size=kernel_size, stride=stride, | |||
| pad_mode=pad_mode, padding=padding, dilation=dilation, group=groups, has_bias=has_bias, | |||
| weight_init=weight, bias_init=bias) | |||
| out = _conv_2d_transpose(inputs) | |||
| return cast_to_adapter_tensor(out) | |||
| def conv_transpose3d(inputs, weight, bias=None, stride=1, padding=0, output_padding=0, groups=1, dilation=1): | |||
| inputs = cast_to_ms_tensor(inputs) | |||
| weight = cast_to_ms_tensor(weight) | |||
| has_bias = bias is not None | |||
| bias = cast_to_ms_tensor(bias) if bias is not None else 'zeros' | |||
| if len(inputs.shape) != 5: | |||
| raise ValueError("the rank of inputs tensor should be 5.") | |||
| if len(weight.shape) != 5: | |||
| raise ValueError("the rank of weight tensor should be 5") | |||
| in_channel = inputs.shape[1] | |||
| out_channel = weight.shape[1] * groups | |||
| kernel_size = weight.shape[2:] | |||
| if isinstance(padding, tuple): | |||
| padding = list(np.repeat(padding, 2)) | |||
| # convert default data type 'int64' to 'int' | |||
| padding = tuple(map(int, padding)) | |||
| if stride != 1 and padding == 0 and output_padding == 0: | |||
| pad_mode = 'valid' | |||
| padding = 0 | |||
| else: | |||
| pad_mode = 'pad' | |||
| _conv_3d_transpose = nn.Conv3dTranspose( | |||
| in_channels=in_channel, out_channels=out_channel, kernel_size=kernel_size, stride=stride, | |||
| pad_mode=pad_mode, padding=padding, dilation=dilation, group=groups, has_bias=has_bias, | |||
| weight_init=weight, bias_init=bias) | |||
| out = _conv_3d_transpose(inputs) | |||
| return cast_to_adapter_tensor(out) | |||
| def affine_grid(theta, size, align_corners=None): | |||
| theta = cast_to_ms_tensor(theta) | |||
| if align_corners is None: | |||
| align_corners = False | |||
| # TODO:the input argument[theta] must be a type of {Tensor[Float16], Tensor[Float32]} | |||
| if theta.dtype == ms.float64: | |||
| theta = theta.astype(ms.float32) | |||
| output = ms.ops.affine_grid(theta, size, align_corners) | |||
| return cast_to_adapter_tensor(output) | |||
| def batch_norm(inputs, running_mean, running_var, weight=None, bias=None, training=False, momentum=0.1, | |||
| eps=1e-05): | |||
| inputs = cast_to_ms_tensor(inputs) | |||
| running_mean = cast_to_ms_tensor(running_mean) | |||
| running_var = cast_to_ms_tensor(running_var) | |||
| weight = cast_to_ms_tensor(weight) if weight is not None else weight | |||
| bias = cast_to_ms_tensor(bias) if bias is not None else bias | |||
| reduced_dim = tuple(i for i in range(inputs.dim()) if i != 1) | |||
| normalized_shape = [1] * len(inputs.shape) | |||
| normalized_shape[1] = inputs.shape[1] | |||
| if training: | |||
| mean = inputs.mean(axis=reduced_dim, keep_dims=True) | |||
| var = inputs.var(reduced_dim, keepdims=True, ddof=False) | |||
| mean_update = mean.squeeze() | |||
| var_update = inputs.var(axis=reduced_dim, ddof=True) | |||
| out = (inputs - mean) / ms.ops.sqrt(var + eps) | |||
| # parameters updating reserved for future use | |||
| running_mean = (1 - momentum) * running_mean + momentum * mean_update | |||
| running_var = (1 - momentum) * running_var + momentum * var_update | |||
| else: | |||
| out = (inputs - running_mean.view(*normalized_shape)) / ms.ops.sqrt(running_var.view(*normalized_shape) + eps) | |||
| if weight is not None: | |||
| out = out * weight.view(*normalized_shape) | |||
| if bias is not None: | |||
| out = out + bias.view(*normalized_shape) | |||
| return cast_to_adapter_tensor(out) | |||
| def group_norm(inputs, num_groups, weight=None, bias=None, eps=1e-05): | |||
| inputs = cast_to_ms_tensor(inputs) | |||
| weight = cast_to_ms_tensor(weight) if weight is not None else weight | |||
| bias = cast_to_ms_tensor(bias) if bias is not None else bias | |||
| inputs_shape = list(inputs.shape) | |||
| shape = [inputs_shape[0]] + [num_groups, inputs_shape[1] // num_groups] + inputs_shape[2:] | |||
| normalized_shape = [1] * len(inputs.shape) | |||
| normalized_shape[1] = inputs_shape[1] | |||
| reduced_dim = tuple(i for i in range(len(shape) - 1, 1, -1)) | |||
| inputs = inputs.reshape(*shape) | |||
| mean = inputs.mean(axis=reduced_dim, keep_dims=True) | |||
| var = inputs.var(axis=reduced_dim, keepdims=True, ddof=False) | |||
| out = (inputs - mean) / ms.ops.sqrt(var + eps) | |||
| out = out.reshape(*inputs_shape) | |||
| if weight is not None: | |||
| out = out * weight.view(*normalized_shape) | |||
| if bias is not None: | |||
| out = out + bias.view(*normalized_shape) | |||
| return cast_to_adapter_tensor(out) | |||
| def instance_norm(inputs, running_mean=None, running_var=None, weight=None, bias=None, use_input_stats=True, | |||
| momentum=0.1, eps=1e-05): | |||
| inputs = cast_to_ms_tensor(inputs) | |||
| running_mean = cast_to_ms_tensor(running_mean) | |||
| running_var = cast_to_ms_tensor(running_var) | |||
| weight = cast_to_ms_tensor(weight) if weight is not None else weight | |||
| bias = cast_to_ms_tensor(bias) if bias is not None else bias | |||
| reduced_dim = tuple(i for i in range(inputs.dim()) if i not in [0, 1]) | |||
| normalized_shape = [1] * len(inputs.shape) | |||
| normalized_shape[1] = inputs.shape[1] | |||
| shape = [1] * len(inputs.shape) | |||
| shape[:2] = inputs.shape[:2] | |||
| if use_input_stats: | |||
| mean = inputs.mean(axis=reduced_dim) | |||
| var = inputs.var(axis=reduced_dim, ddof=False) | |||
| mean_update = mean.mean(0) | |||
| var_update = inputs.var(axis=reduced_dim, ddof=True).mean(0) | |||
| out = (inputs - mean.view(*shape)) / ms.ops.sqrt(var.view(*shape) + eps) | |||
| running_mean = (1 - momentum) * running_mean + momentum * mean_update | |||
| running_var = (1 - momentum) * running_var + momentum * var_update | |||
| else: | |||
| out = (inputs - running_mean.view(*normalized_shape)) \ | |||
| / ms.ops.sqrt(running_var.view(*normalized_shape) + eps) | |||
| if weight is not None: | |||
| out = out * weight.view(*normalized_shape) | |||
| if bias is not None: | |||
| out = out + bias.view(*normalized_shape) | |||
| return cast_to_adapter_tensor(out) | |||
| def layer_norm(inputs, normalized_shape, weight=None, bias=None, eps=1e-05): | |||
| inputs = cast_to_ms_tensor(inputs) | |||
| if weight is not None: | |||
| weight = cast_to_ms_tensor(weight) | |||
| else: | |||
| weight = ms.Tensor(np.ones(normalized_shape), inputs.dtype) | |||
| if bias is not None: | |||
| bias = cast_to_ms_tensor(bias) | |||
| else: | |||
| bias = ms.Tensor(np.zeros(normalized_shape), inputs.dtype) | |||
| assert inputs.shape[-len(normalized_shape):] == normalized_shape | |||
| _layer_norm = ms.ops.LayerNorm(epsilon=eps) | |||
| out = _layer_norm(inputs, weight, bias) | |||
| return cast_to_adapter_tensor(out[0]) | |||
+ 0
- 371
ms_adapter/pytorch/nn/modules/container.py
View File
| @@ -1,371 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from abc import abstractmethod | |||
| from collections import OrderedDict, abc as container_abcs | |||
| from mindspore.nn.layer.container import _get_prefix_and_index, _valid_index, _valid_cell | |||
| from ms_adapter.pytorch.tensor import cast_to_adapter_tensor | |||
| from .module import Module | |||
| class Sequential(Module): | |||
| """ | |||
| Sequential Module container. For more details about Module, please refer to | |||
| A list of Cells will be added to it in the order they are passed in the constructor. | |||
| Alternatively, an ordered dict of cells can also be passed in. | |||
| Note: | |||
| Sequential and torch.nn.ModuleList are different, ModuleList is a list for storing modules. However, | |||
| the layers in a Sequential are connected in a cascading way. | |||
| Args: | |||
| args (list, OrderedDict): List or OrderedDict of subclass of Module. | |||
| Inputs: | |||
| - **x** (Tensor) - Tensor with shape according to the first Module in the sequence. | |||
| Outputs: | |||
| Tensor, the output Tensor with shape depending on the input `x` and defined sequence of Cells. | |||
| Raises: | |||
| TypeError: If the type of the `args` is not list or OrderedDict. | |||
| Supported Platforms: | |||
| ``Ascend`` ``GPU`` ``CPU`` | |||
| Examples: | |||
| >>> conv = nn.Conv2d(3, 2, 3, pad_mode='valid', weight_init="ones") | |||
| >>> relu = nn.ReLU() | |||
| >>> seq = nn.Sequential([conv, relu]) | |||
| >>> x = Tensor(np.ones([1, 3, 4, 4]), dtype=mindspore.float32) | |||
| >>> output = seq(x) | |||
| >>> print(output) | |||
| [[[[27. 27.] | |||
| [27. 27.]] | |||
| [[27. 27.] | |||
| [27. 27.]]]] | |||
| >>> from collections import OrderedDict | |||
| >>> d = OrderedDict() | |||
| >>> d["conv"] = conv | |||
| >>> d["relu"] = relu | |||
| >>> seq = nn.Sequential(d) | |||
| >>> x = Tensor(np.ones([1, 3, 4, 4]), dtype=mindspore.float32) | |||
| >>> output = seq(x) | |||
| >>> print(output) | |||
| [[[[27. 27.] | |||
| [27. 27.]] | |||
| [[27. 27.] | |||
| [27. 27.]]]] | |||
| """ | |||
| def __init__(self, *args): | |||
| """Initialize Sequential.""" | |||
| super(Sequential, self).__init__() | |||
| self._is_dynamic_name = [] | |||
| if len(args) == 1: | |||
| cells = args[0] | |||
| if isinstance(cells, list): | |||
| for index, cell in enumerate(cells): | |||
| self.insert_child_to_cell(str(index), cell) | |||
| cell.update_parameters_name(str(index) + ".") | |||
| self._is_dynamic_name.append(True) | |||
| elif isinstance(cells, OrderedDict): | |||
| for name, cell in cells.items(): | |||
| self.insert_child_to_cell(name, cell) | |||
| cell.update_parameters_name(name + ".") | |||
| self._is_dynamic_name.append(False) | |||
| elif isinstance(cells, Module): | |||
| for index, cell in enumerate(args): | |||
| self.insert_child_to_cell(str(index), cell) | |||
| cell.update_parameters_name(str(index) + ".") | |||
| self._is_dynamic_name.append(True) | |||
| else: | |||
| raise TypeError(f"For '{self.__class__.__name__}', the 'args[0]' must be list or orderedDict, " | |||
| f"but got {type(cells).__name__}") | |||
| else: | |||
| for index, cell in enumerate(args): | |||
| self.insert_child_to_cell(str(index), cell) | |||
| cell.update_parameters_name(str(index) + ".") | |||
| self._is_dynamic_name.append(True) | |||
| self.cell_list = list(self._cells.values()) | |||
| def __getitem__(self, index): | |||
| if isinstance(index, slice): | |||
| return self.__class__( | |||
| OrderedDict(list(self._cells.items())[index])) | |||
| index = _valid_index(len(self), index, self.__class__.__name__) | |||
| return list(self._cells.values())[index] | |||
| def __setitem__(self, index, module): | |||
| cls_name = self.__class__.__name__ | |||
| if _valid_cell(module, cls_name): | |||
| prefix, _ = _get_prefix_and_index(self._cells) | |||
| index = _valid_index(len(self), index, cls_name) | |||
| key = list(self._cells.keys())[index] | |||
| self._cells[key] = module | |||
| module.update_parameters_name(prefix + key + ".") | |||
| self.cell_list = list(self._cells.values()) | |||
| def __delitem__(self, index): | |||
| cls_name = self.__class__.__name__ | |||
| if isinstance(index, int): | |||
| index = _valid_index(len(self), index, cls_name) | |||
| key = list(self._cells.keys())[index] | |||
| del self._cells[key] | |||
| del self._is_dynamic_name[index] | |||
| elif isinstance(index, slice): | |||
| keys = list(self._cells.keys())[index] | |||
| for key in keys: | |||
| del self._cells[key] | |||
| del self._is_dynamic_name[index] | |||
| else: | |||
| raise TypeError(f"For '{cls_name}', the type of index must be int type or slice type, " | |||
| f"but got {type(index).__name__}") | |||
| prefix, key_index = _get_prefix_and_index(self._cells) | |||
| temp_dict = OrderedDict() | |||
| for idx, key in enumerate(self._cells.keys()): | |||
| cell = self._cells[key] | |||
| if self._is_dynamic_name[idx]: | |||
| for _, param in cell.parameters_and_names(): | |||
| param.name = prefix + str(idx) + "." + ".".join(param.name.split(".")[key_index+1:]) | |||
| temp_dict[str(idx)] = cell | |||
| else: | |||
| temp_dict[key] = cell | |||
| self._cells = temp_dict | |||
| self.cell_list = list(self._cells.values()) | |||
| def __len__(self): | |||
| return len(self._cells) | |||
| def set_grad(self, flag=True): | |||
| self.requires_grad = flag | |||
| for cell in self._cells.values(): | |||
| cell.set_grad(flag) | |||
| def append(self, module): | |||
| """ | |||
| Appends a given Module to the end of the list. | |||
| Args: | |||
| module(Module): The Module to be appended. | |||
| Examples: | |||
| >>> conv = nn.Conv2d(3, 2, 3, pad_mode='valid', weight_init="ones") | |||
| >>> bn = nn.BatchNorm2d(2) | |||
| >>> relu = nn.ReLU() | |||
| >>> seq = nn.Sequential([conv, bn]) | |||
| >>> seq.append(relu) | |||
| >>> x = Tensor(np.ones([1, 3, 4, 4]), dtype=mindspore.float32) | |||
| >>> output = seq(x) | |||
| >>> print(output) | |||
| [[[[26.999863 26.999863] | |||
| [26.999863 26.999863]] | |||
| [[26.999863 26.999863] | |||
| [26.999863 26.999863]]]] | |||
| """ | |||
| if _valid_cell(module, self.__class__.__name__): | |||
| prefix, _ = _get_prefix_and_index(self._cells) | |||
| module.update_parameters_name(prefix + str(len(self)) + ".") | |||
| self._is_dynamic_name.append(True) | |||
| self._cells[str(len(self))] = module | |||
| self.cell_list = list(self._cells.values()) | |||
| def add_module(self, name, module): | |||
| if not isinstance(module, Module) and module is not None: | |||
| raise TypeError("{} is not a Module subclass".format( | |||
| module.__name__)) | |||
| elif hasattr(self, name) and name not in self._cells: | |||
| raise KeyError("attribute '{}' already exists".format(name)) | |||
| elif '.' in name: | |||
| raise KeyError("module name can't contain \".\", got: {}".format(name)) | |||
| elif name == '': | |||
| raise KeyError("module name can't be empty string \"\"") | |||
| if _valid_cell(module, self.__class__.__name__): | |||
| module.update_parameters_name(name + ".") | |||
| self._is_dynamic_name.append(False) | |||
| self._cells[name] = module | |||
| self.cell_list = list(self._cells.values()) | |||
| def forward(self, input): | |||
| for cell in self.cell_list: | |||
| input = cell(input) | |||
| return cast_to_adapter_tensor(input) | |||
| class _ModuleListBase: | |||
| """ | |||
| An interface for base the Module as list. | |||
| The sequential Module may be iterated using the construct method using for-in statement. | |||
| But there are some scenarios that the construct method built-in does not fit. | |||
| For convenience, we provide an interface that indicates the sequential | |||
| Module may be interpreted as list of Cells, so it can be accessed using | |||
| iterator or subscript when a sequential Module instantiate is accessed | |||
| by iterator or subscript, it will be interpreted as a list of Cells. | |||
| """ | |||
| def __init__(self): | |||
| """Initialize _ModuleListBase.""" | |||
| self.__cell_as_list__ = True | |||
| @abstractmethod | |||
| def __len__(self): | |||
| pass | |||
| @abstractmethod | |||
| def __getitem__(self, index): | |||
| pass | |||
| def construct(self): | |||
| raise NotImplementedError | |||
| class ModuleList(_ModuleListBase, Module): | |||
| """ | |||
| Holds Cells in a list. For more details about Module, please refer to | |||
| ModuleList can be used like a regular Python list, the Cells it contains have been initialized. | |||
| Args: | |||
| args (list, optional): List of subclass of Module. | |||
| Supported Platforms: | |||
| ``Ascend`` ``GPU`` ``CPU`` | |||
| Examples: | |||
| >>> import mindspore.nn as nn | |||
| >>> | |||
| >>> conv = nn.Conv2d(100, 20, 3) | |||
| >>> bn = nn.BatchNorm2d(20) | |||
| >>> relu = nn.ReLU() | |||
| >>> cell_ls = nn.ModuleList([bn]) | |||
| >>> cell_ls.insert(0, conv) | |||
| >>> cell_ls.append(relu) | |||
| >>> cell_ls.extend([relu, relu]) | |||
| """ | |||
| def __init__(self, *args, **kwargs): | |||
| """Initialize ModuleList.""" | |||
| auto_prefix = kwargs["auto_prefix"] if "auto_prefix" in kwargs.keys() else True | |||
| _ModuleListBase.__init__(self) | |||
| Module.__init__(self, auto_prefix) | |||
| if len(args) == 1: | |||
| self.extend(args[0]) | |||
| def __getitem__(self, index): | |||
| cls_name = self.__class__.__name__ | |||
| if isinstance(index, slice): | |||
| return self.__class__(list(self._cells.values())[index]) | |||
| if isinstance(index, int): | |||
| index = _valid_index(len(self), index, cls_name) | |||
| return self._cells[str(index)] | |||
| raise TypeError(f"For '{cls_name}', the type of 'index' must be int or slice, " | |||
| f"but got {type(index).__name__}.") | |||
| def __setitem__(self, index, module): | |||
| cls_name = self.__class__.__name__ | |||
| if not isinstance(index, int) and _valid_cell(module, cls_name): | |||
| raise TypeError(f"For '{cls_name}', the type of 'index' must be int, " | |||
| f"but got {type(index).__name__}.") | |||
| index = _valid_index(len(self), index, cls_name) | |||
| if self._auto_prefix: | |||
| prefix, _ = _get_prefix_and_index(self._cells) | |||
| module.update_parameters_name(prefix + str(index) + ".") | |||
| self._cells[str(index)] = module | |||
| def __delitem__(self, index): | |||
| cls_name = self.__class__.__name__ | |||
| if isinstance(index, int): | |||
| index = _valid_index(len(self), index, cls_name) | |||
| del self._cells[str(index)] | |||
| elif isinstance(index, slice): | |||
| keys = list(self._cells.keys())[index] | |||
| for key in keys: | |||
| del self._cells[key] | |||
| else: | |||
| raise TypeError(f"For '{cls_name}', the type of 'index' must be int or slice, " | |||
| f"but got {type(index).__name__}.") | |||
| # adjust orderedDict | |||
| prefix, key_index = _get_prefix_and_index(self._cells) | |||
| temp_dict = OrderedDict() | |||
| for idx, cell in enumerate(self._cells.values()): | |||
| if self._auto_prefix: | |||
| for _, param in cell.parameters_and_names(): | |||
| param.name = prefix + str(idx) + "." + ".".join(param.name.split(".")[key_index+1:]) | |||
| temp_dict[str(idx)] = cell | |||
| self._cells = temp_dict | |||
| def __len__(self): | |||
| return len(self._cells) | |||
| def __iter__(self): | |||
| return iter(self._cells.values()) | |||
| def __iadd__(self, modules): | |||
| self.extend(modules) | |||
| return self | |||
| def insert(self, index, module): | |||
| """ | |||
| Inserts a given Module before a given index in the list. | |||
| Args: | |||
| index(int): The Insert index in the ModuleList. | |||
| module(Module): The Module to be inserted. | |||
| """ | |||
| cls_name = self.__class__.__name__ | |||
| idx = _valid_index(len(self), index, cls_name) | |||
| _valid_cell(module, cls_name) | |||
| length = len(self) | |||
| prefix, key_index = _get_prefix_and_index(self._cells) | |||
| while length > idx: | |||
| if self._auto_prefix: | |||
| tmp_cell = self._cells[str(length-1)] | |||
| for _, param in tmp_cell.parameters_and_names(): | |||
| param.name = prefix + str(length) + "." + ".".join(param.name.split(".")[key_index+1:]) | |||
| self._cells[str(length)] = self._cells[str(length - 1)] | |||
| length -= 1 | |||
| self._cells[str(idx)] = module | |||
| if self._auto_prefix: | |||
| module.update_parameters_name(prefix + str(idx) + ".") | |||
| def extend(self, modules): | |||
| """ | |||
| Appends Cells from a Python iterable to the end of the list. | |||
| Args: | |||
| cells(list): The Cells to be extended. | |||
| Raises: | |||
| TypeError: If the argument cells are not a list of Cells. | |||
| """ | |||
| cls_name = self.__class__.__name__ | |||
| if not isinstance(modules, container_abcs.Iterable): | |||
| raise TypeError("ModuleList.extend should be called with an " | |||
| "iterable, but got " + type(modules).__name__) | |||
| prefix, _ = _get_prefix_and_index(self._cells) | |||
| for module in modules: | |||
| if _valid_cell(module, cls_name): | |||
| if self._auto_prefix: | |||
| module.update_parameters_name(prefix + str(len(self)) + ".") | |||
| self._cells[str(len(self))] = module | |||
| return self | |||
| def append(self, module): | |||
| """ | |||
| Appends a given Module to the end of the list. | |||
| Args: | |||
| module(Module): The subcell to be appended. | |||
| """ | |||
| if _valid_cell(module, self.__class__.__name__): | |||
| if self._auto_prefix: | |||
| prefix, _ = _get_prefix_and_index(self._cells) | |||
| module.update_parameters_name(prefix + str(len(self)) + ".") | |||
| self._cells[str(len(self))] = module | |||
| def set_grad(self, flag=True): | |||
| self.requires_grad = flag | |||
| for cell in self._cells.values(): | |||
| cell.set_grad(flag) | |||
| def construct(self, *inputs): | |||
| raise NotImplementedError | |||
+ 0
- 668
ms_adapter/pytorch/nn/modules/conv.py
View File
| @@ -1,668 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import math | |||
| from mindspore.ops import operations as P | |||
| from ms_adapter.pytorch.nn.parameter import Parameter | |||
| from ms_adapter.pytorch.nn import init | |||
| from ms_adapter.pytorch.functional import empty | |||
| from ms_adapter.utils import unsupported_attr | |||
| from ms_adapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from .utils import _triple, _pair, _single, _reverse_repeat_tuple | |||
| from .module import Module | |||
| __all__ = ['Conv1d', 'Conv2d', 'Conv3d', | |||
| 'ConvTranspose1d', 'ConvTranspose2d', 'ConvTranspose3d', | |||
| 'LazyConv1d', 'LazyConv2d', 'LazyConv3d', | |||
| 'LazyConvTranspose1d', 'LazyConvTranspose2d', 'LazyConvTranspose3d'] | |||
| class _ConvNd(Module): | |||
| def __init__(self, | |||
| in_channels, | |||
| out_channels, | |||
| kernel_size, | |||
| stride, | |||
| padding, | |||
| dilation, | |||
| output_padding, | |||
| groups, | |||
| bias, | |||
| padding_mode, | |||
| device=None, | |||
| dtype=None, | |||
| transposed=False | |||
| ): | |||
| """Initialize _Conv.""" | |||
| unsupported_attr(device) | |||
| unsupported_attr(dtype) | |||
| super(_ConvNd, self).__init__() | |||
| self.in_channels = in_channels | |||
| self.out_channels = out_channels | |||
| self.kernel_size = kernel_size | |||
| self.stride = stride | |||
| self.padding = padding | |||
| self.dilation = dilation | |||
| self.transposed = transposed | |||
| self.output_padding = output_padding | |||
| self.groups = groups | |||
| self.padding_mode = padding_mode | |||
| # MS add | |||
| self.pad_mode = 'same' | |||
| self.data_format = 'NCHW' | |||
| if in_channels % groups != 0: | |||
| raise ValueError('in_channels must be divisible by groups') | |||
| if out_channels % groups != 0: | |||
| raise ValueError('out_channels must be divisible by groups') | |||
| valid_padding_strings = {'same', 'valid'} | |||
| if isinstance(padding, str): | |||
| if padding not in valid_padding_strings: | |||
| raise ValueError( | |||
| "Invalid padding string {!r}, should be one of {}".format( | |||
| padding, valid_padding_strings)) | |||
| if padding == 'same' and any(s != 1 for s in stride): | |||
| raise ValueError("padding='same' is not supported for strided convolutions") | |||
| if isinstance(self.padding, str): | |||
| self._reversed_padding_repeated_twice = [0, 0] * len(kernel_size) | |||
| if padding == 'same': | |||
| for d, k, i in zip(dilation, kernel_size, | |||
| range(len(kernel_size) - 1, -1, -1)): | |||
| total_padding = d * (k - 1) | |||
| left_pad = total_padding // 2 | |||
| self._reversed_padding_repeated_twice[2 * i] = left_pad | |||
| self._reversed_padding_repeated_twice[2 * i + 1] = ( | |||
| total_padding - left_pad) | |||
| else: | |||
| self._reversed_padding_repeated_twice = _reverse_repeat_tuple(self.padding, 2) | |||
| if transposed: | |||
| self.weight = Parameter(empty((in_channels, out_channels // groups, *kernel_size))) | |||
| else: | |||
| self.weight = Parameter(empty((out_channels, in_channels // groups, *kernel_size))) | |||
| if bias: | |||
| self.bias = Parameter(empty(out_channels)) | |||
| else: | |||
| self.bias = None | |||
| self.reset_parameters() | |||
| def reset_parameters(self): | |||
| init.kaiming_uniform_(self.weight, a=math.sqrt(5)) | |||
| if self.bias is not None: | |||
| fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight) | |||
| if fan_in != 0: | |||
| bound = 1 / math.sqrt(fan_in) | |||
| init.uniform_(self.bias, -bound, bound) | |||
| def extra_repr(self): | |||
| s = ('{in_channels}, {out_channels}, kernel_size={kernel_size}' | |||
| ', stride={stride}') | |||
| if self.padding != (0,) * len(self.padding): | |||
| s += ', padding={padding}' | |||
| if self.dilation != (1,) * len(self.dilation): | |||
| s += ', dilation={dilation}' | |||
| if self.output_padding != (0,) * len(self.output_padding): | |||
| s += ', output_padding={output_padding}' | |||
| if self.groups != 1: | |||
| s += ', groups={groups}' | |||
| if self.bias is None: | |||
| s += ', bias=False' | |||
| if self.padding_mode != 'zeros': | |||
| s += ', padding_mode={padding_mode}' | |||
| return s.format(**self.__dict__) | |||
| class Conv1d(_ConvNd): | |||
| r""" | |||
| 1D convolution layer. | |||
| Calculates the 1D convolution on the input tensor which is typically of shape :math:`(N, C_{in}, L_{in})`, | |||
| where :math:`N` is batch size, :math:`C_{in}` is a number of channels and :math:`L_{in}` is a length of | |||
| sequence. For the tensor of each batch, its shape is :math:`(C_{in}, L_{in})`, the formula is defined as: | |||
| Supported Platforms: | |||
| ``Ascend`` ``GPU`` ``CPU`` | |||
| Examples: | |||
| >>> net = nn.Conv1d(120, 240, 4, has_bias=False, weight_init='normal') | |||
| >>> x = Tensor(np.ones([1, 120, 640]), mindspore.float32) | |||
| >>> output = net(x).shape | |||
| >>> print(output) | |||
| (1, 240, 640) | |||
| """ | |||
| def __init__( | |||
| self, | |||
| in_channels, | |||
| out_channels, | |||
| kernel_size, | |||
| stride=1, | |||
| padding=0, | |||
| dilation=1, | |||
| groups=1, | |||
| bias=True, | |||
| padding_mode='zeros', | |||
| device=None, | |||
| dtype=None | |||
| ): | |||
| factory_kwargs = {'device': device, 'dtype': dtype, 'transposed': False} | |||
| self.has_bias = False | |||
| if bias: | |||
| self.has_bias=True | |||
| kernel_size_ = (1, kernel_size) | |||
| stride_ = (1, stride if isinstance(stride, int) else stride[0]) | |||
| dilation_ = (1, dilation) | |||
| padding_ = padding if isinstance(padding, str) else _single(padding) | |||
| super(Conv1d, self).__init__(in_channels, out_channels, kernel_size_, stride_, padding_, dilation_, | |||
| _pair(0), groups, bias, padding_mode, **factory_kwargs) | |||
| #TODO pad_mode in ['zeros', 'reflect', 'replicate', 'circular'] | |||
| if padding_mode in {'reflect', 'replicate', 'circular'}: | |||
| raise ValueError("Pad mode '{}' is not currently supported.".format(padding_mode)) | |||
| if padding == 0: | |||
| self.pad_mode = 'valid' | |||
| self.padding =(0, 0, 0, 0) | |||
| elif isinstance(self.padding, str): | |||
| self.pad_mode = self.padding | |||
| self.padding = 0 | |||
| elif padding_mode == 'zeros': | |||
| self.pad_mode = "pad" | |||
| self.padding =(0, 0, padding, padding) | |||
| self.conv2d = P.Conv2D(out_channel=self.out_channels, | |||
| kernel_size=self.kernel_size, | |||
| mode=1, | |||
| pad_mode=self.pad_mode, | |||
| pad=self.padding, | |||
| stride=self.stride, | |||
| dilation=self.dilation, | |||
| group=groups) | |||
| self.bias_add = P.BiasAdd() | |||
| self.expand_dims = P.ExpandDims() | |||
| self.squeeze = P.Squeeze(2) | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| x = self.expand_dims(input, 2) | |||
| output = self.conv2d(x, self.weight) | |||
| if self.has_bias: | |||
| output = self.bias_add(output, self.bias) | |||
| output = self.squeeze(output) | |||
| return cast_to_adapter_tensor(output) | |||
| class Conv2d(_ConvNd): | |||
| def __init__(self, | |||
| in_channels, | |||
| out_channels, | |||
| kernel_size, | |||
| stride=1, | |||
| padding=0, | |||
| dilation=1, | |||
| groups=1, | |||
| bias=True, | |||
| padding_mode='zeros', | |||
| device=None, | |||
| dtype=None): | |||
| """Initialize Conv2d.""" | |||
| factory_kwargs = {'device': device, 'dtype': dtype, 'transposed': False} | |||
| kernel_size_ = _pair(kernel_size) | |||
| stride_ = _pair(stride) | |||
| padding_ = padding if isinstance(padding, str) else _pair(padding) | |||
| dilation_ = _pair(dilation) | |||
| super(Conv2d, self).__init__(in_channels, out_channels, kernel_size_, stride_, padding_, dilation_, | |||
| _pair(0), groups, bias, padding_mode, **factory_kwargs) | |||
| #TODO pad_mode in ['zeros', 'reflect', 'replicate', 'circular'] | |||
| if padding_mode in {'reflect', 'replicate', 'circular'}: | |||
| raise ValueError("Pad mode '{}' is not currently supported.".format(padding_mode)) | |||
| if padding == 0: | |||
| self.pad_mode = 'valid' | |||
| self.padding =(self.padding[0], self.padding[0], self.padding[1], self.padding[1]) | |||
| elif isinstance(self.padding, str): | |||
| self.pad_mode = self.padding | |||
| self.padding = 0 | |||
| elif padding_mode == 'zeros': | |||
| self.pad_mode = "pad" | |||
| self.padding =(self.padding[0], self.padding[0], self.padding[1], self.padding[1]) | |||
| self.conv2d = P.Conv2D(out_channel=self.out_channels, | |||
| kernel_size=self.kernel_size, | |||
| mode=1, | |||
| pad_mode=self.pad_mode, | |||
| pad=self.padding, | |||
| stride=self.stride, | |||
| dilation=self.dilation, | |||
| group=self.groups, | |||
| data_format=self.data_format) | |||
| self.bias_add = P.BiasAdd(data_format=self.data_format) | |||
| def forward(self, x): | |||
| x = cast_to_ms_tensor(x) | |||
| output = self.conv2d(x, self.weight) | |||
| if self.bias is not None: | |||
| output = self.bias_add(output, self.bias) | |||
| return cast_to_adapter_tensor(output) | |||
| class Conv3d(_ConvNd): | |||
| r""" | |||
| 3D convolution layer. | |||
| Calculates the 3D convolution on the input tensor which is typically of shape | |||
| Supported Platforms: | |||
| ``Ascend`` ``GPU`` ``CPU`` | |||
| Examples: | |||
| >>> x = Tensor(np.ones([16, 3, 10, 32, 32]), mindspore.float32) | |||
| >>> conv3d = nn.Conv3d(in_channels=3, out_channels=32, kernel_size=(4, 3, 3)) | |||
| >>> output = conv3d(x) | |||
| >>> print(output.shape) | |||
| (16, 32, 10, 32, 32) | |||
| """ | |||
| def __init__( | |||
| self, | |||
| in_channels, | |||
| out_channels, | |||
| kernel_size, | |||
| stride=1, | |||
| padding=0, | |||
| dilation=1, | |||
| groups=1, | |||
| bias=True, | |||
| padding_mode='zeros', | |||
| device=None, | |||
| dtype=None | |||
| ): | |||
| factory_kwargs = {'device': device, 'dtype': dtype, 'transposed': True} | |||
| self.has_bias = False | |||
| if bias: | |||
| self.has_bias=True | |||
| kernel_size_ = _triple(kernel_size) | |||
| stride_ = _triple(stride) | |||
| padding_ = padding if isinstance(padding, str) else _triple(padding) | |||
| dilation_ = _triple(dilation) | |||
| super(Conv3d, self).__init__(in_channels, out_channels, kernel_size_, stride_, padding_, dilation_, | |||
| _pair(0), groups, bias, padding_mode, **factory_kwargs) | |||
| #TODO pad_mode in ['zeros', 'reflect', 'replicate', 'circular'] | |||
| if padding_mode in {'reflect', 'replicate', 'circular'}: | |||
| raise ValueError("Pad mode '{}' is not currently supported.".format(padding_mode)) | |||
| if padding == 0: | |||
| self.pad_mode = 'valid' | |||
| self.padding =(self.padding[0], self.padding[0], self.padding[1], | |||
| self.padding[1], self.padding[2], self.padding[2]) | |||
| elif isinstance(self.padding, str): | |||
| self.pad_mode = self.padding | |||
| self.padding = 0 | |||
| elif padding_mode == 'zeros': | |||
| self.pad_mode = "pad" | |||
| self.padding =(self.padding[0], self.padding[0], self.padding[1], | |||
| self.padding[1], self.padding[2], self.padding[2]) | |||
| self.conv3d = P.Conv3D(out_channel=self.out_channels, | |||
| kernel_size=self.kernel_size, | |||
| mode=1, | |||
| pad_mode=self.pad_mode, | |||
| pad=self.padding, | |||
| stride=self.stride, | |||
| dilation=self.dilation, | |||
| group=groups, | |||
| data_format='NCDHW') | |||
| self.bias_add = P.BiasAdd(data_format='NCDHW') | |||
| self.shape = P.Shape() | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| output = self.conv3d(input, self.weight) | |||
| if self.has_bias: | |||
| output = self.bias_add(output, self.bias) | |||
| return cast_to_adapter_tensor(output) | |||
| class ConvTranspose1d(_ConvNd): | |||
| r""" | |||
| 1D transposed convolution layer. | |||
| Calculates a 1D transposed convolution, which can be regarded as Conv1d for the gradient of the input. | |||
| It also called deconvolution (although it is not an actual deconvolution). | |||
| Supported Platforms: | |||
| ``Ascend`` ``GPU`` ``CPU`` | |||
| Examples: | |||
| >>> net = nn.ConvTranspose1d(3, 64, 4, has_bias=False) | |||
| >>> x = Tensor(np.ones([1, 3, 50]), mindspore.float32) | |||
| >>> output = net(x).shape | |||
| >>> print(output) | |||
| (1, 64, 53) | |||
| """ | |||
| def __init__( | |||
| self, | |||
| in_channels, | |||
| out_channels, | |||
| kernel_size, | |||
| stride=1, | |||
| padding=0, | |||
| output_padding=0, | |||
| groups=1, | |||
| bias=True, | |||
| dilation=1, | |||
| padding_mode='zeros', | |||
| device=None, | |||
| dtype=None, | |||
| ): | |||
| factory_kwargs = {'device': device, 'dtype': dtype, 'transposed': True} | |||
| self.has_bias = False | |||
| if bias: | |||
| self.has_bias=True | |||
| _padding = _single(padding) | |||
| _kernel_size = (1, kernel_size) | |||
| _stride = (1, stride) | |||
| _dilation = (1, dilation) | |||
| super(ConvTranspose1d, self).__init__(in_channels, out_channels, _kernel_size, _stride, | |||
| _padding, _dilation, output_padding, groups, bias, | |||
| padding_mode, **factory_kwargs) | |||
| self.shape = P.Shape() | |||
| if padding_mode in {'reflect', 'replicate', 'circular'}: | |||
| raise ValueError("Pad mode '{}' is not currently supported.".format(padding_mode)) | |||
| if output_padding > 0: | |||
| raise ValueError("output_padding '{}' is not currently supported.".format(output_padding)) | |||
| if padding == 0: | |||
| self.pad_mode = 'valid' | |||
| self.padding = (0, 0, padding, padding) | |||
| elif padding_mode == 'zeros': | |||
| self.pad_mode = "pad" | |||
| self.padding = (0, 0, padding, padding) | |||
| self.is_valid = self.pad_mode == 'valid' | |||
| self.is_same = self.pad_mode == 'same' | |||
| self.is_pad = self.pad_mode == 'pad' | |||
| # cause Conv2DBackpropInput's out_channel refers to Conv2D's out_channel. | |||
| self.conv2d_transpose = P.Conv2DBackpropInput(out_channel=self.in_channels, | |||
| kernel_size=self.kernel_size, | |||
| mode=1, | |||
| pad_mode=self.pad_mode, | |||
| pad=self.padding, | |||
| stride=self.stride, | |||
| dilation=self.dilation, | |||
| group=groups) | |||
| self.bias_add = P.BiasAdd() | |||
| self.expand_dims = P.ExpandDims() | |||
| self.squeeze = P.Squeeze(2) | |||
| def construct(self, input, output_size=None): | |||
| if output_size is not None: | |||
| raise ValueError("output_size '{}' is not currently supported.".format(output_size)) | |||
| x = cast_to_ms_tensor(input) | |||
| x = self.expand_dims(x, 2) | |||
| n, _, h, w = self.shape(x) | |||
| h_out = _deconv_output_length(self.is_valid, self.is_same, self.is_pad, h, self.kernel_size[0], | |||
| self.stride[0], self.dilation[0], self.padding[0] + self.padding[1]) | |||
| w_out = _deconv_output_length(self.is_valid, self.is_same, self.is_pad, w, self.kernel_size[1], | |||
| self.stride[1], self.dilation[1], self.padding[2] + self.padding[3]) | |||
| output = self.conv2d_transpose(x, self.weight, (n, self.out_channels, h_out, w_out)) | |||
| if self.has_bias: | |||
| output = self.bias_add(output, self.bias) | |||
| output = self.squeeze(output) | |||
| return cast_to_adapter_tensor(output) | |||
| def extend_repr(self): | |||
| s = 'input_channels={}, output_channels={}, kernel_size={}, ' \ | |||
| 'stride={}, pad_mode={}, padding={}, dilation={}, ' \ | |||
| 'group={}, has_bias={}, ' \ | |||
| 'weight_init={}'.format(self.in_channels, | |||
| self.out_channels, | |||
| self.kernel_size, | |||
| self.stride, | |||
| self.pad_mode, | |||
| self.padding, | |||
| self.dilation, | |||
| self.group, | |||
| self.bias, | |||
| self.weight_init, | |||
| ) | |||
| return s | |||
| class ConvTranspose2d(_ConvNd): | |||
| r""" | |||
| 2D transposed convolution layer. | |||
| Calculates a 2D transposed convolution, which can be regarded as Conv2d for the gradient of the input. | |||
| It also called deconvolution (although it is not an actual deconvolution). | |||
| Supported Platforms: | |||
| ``Ascend`` ``GPU`` ``CPU`` | |||
| Examples: | |||
| >>> net = nn.ConvTranspose2d(3, 64, 4, has_bias=False) | |||
| >>> x = Tensor(np.ones([1, 3, 16, 50]), mindspore.float32) | |||
| >>> output = net(x).shape | |||
| >>> print(output) | |||
| (1, 64, 19, 53) | |||
| """ | |||
| def __init__( | |||
| self, | |||
| in_channels, | |||
| out_channels, | |||
| kernel_size, | |||
| stride=1, | |||
| padding=0, | |||
| output_padding=0, | |||
| groups=1, | |||
| bias=True, | |||
| dilation=1, | |||
| padding_mode='zeros', | |||
| device=None, | |||
| dtype=None | |||
| ): | |||
| factory_kwargs = {'device': device, 'dtype': dtype, 'transposed': True} | |||
| self.has_bias = False | |||
| if bias: | |||
| self.has_bias=True | |||
| _kernel_size = _pair(kernel_size) | |||
| _stride = _pair(stride) | |||
| _padding = _pair(padding) | |||
| _dilation = _pair(dilation) | |||
| output_padding = _pair(output_padding) | |||
| super(ConvTranspose2d, self).__init__(in_channels, out_channels, _kernel_size, _stride, _padding, _dilation, | |||
| output_padding, groups, bias, padding_mode, **factory_kwargs) | |||
| self.shape = P.Shape() | |||
| if padding == 0: | |||
| self.pad_mode = 'valid' | |||
| self.padding =(self.padding[0], self.padding[0], self.padding[1], self.padding[1]) | |||
| elif isinstance(self.padding, str): | |||
| self.pad_mode = self.padding | |||
| self.padding = 0 | |||
| elif padding_mode == 'zeros': | |||
| self.pad_mode = "pad" | |||
| self.padding =(self.padding[0], self.padding[0], self.padding[1], self.padding[1]) | |||
| if self.padding_mode != 'zeros': | |||
| raise ValueError('Only `zeros` padding mode is supported for ConvTranspose2d') | |||
| self.is_valid = self.pad_mode == 'valid' | |||
| self.is_same = self.pad_mode == 'same' | |||
| self.is_pad = self.pad_mode == 'pad' | |||
| # cause Conv2DTranspose's out_channel refers to Conv2D's out_channel. | |||
| self.conv2d_transpose = P.Conv2DTranspose(out_channel=self.in_channels, | |||
| kernel_size=self.kernel_size, | |||
| mode=1, | |||
| pad_mode=self.pad_mode, | |||
| pad=self.padding, | |||
| stride=self.stride, | |||
| dilation=self.dilation, | |||
| group=groups) | |||
| self.bias_add = P.BiasAdd() | |||
| if isinstance(self.padding, int): | |||
| self.padding_top, self.padding_bottom, self.padding_left, self.padding_right = (self.padding,) * 4 | |||
| else: | |||
| self.padding_top, self.padding_bottom, self.padding_left, self.padding_right = self.padding | |||
| def forward(self, input, output_size = None): | |||
| if output_size is not None: | |||
| raise ValueError("output_size '{}' is not currently supported.".format(output_size)) | |||
| x = cast_to_ms_tensor(input) | |||
| n, _, h, w = self.shape(x) | |||
| h_out = _deconv_output_length(self.is_valid, self.is_same, self.is_pad, h, self.kernel_size[0], | |||
| self.stride[0], self.dilation[0], self.padding_top + self.padding_bottom) | |||
| w_out = _deconv_output_length(self.is_valid, self.is_same, self.is_pad, w, self.kernel_size[1], | |||
| self.stride[1], self.dilation[1], self.padding_left + self.padding_right) | |||
| if self.has_bias: | |||
| return self.bias_add(self.conv2d_transpose(x, self.weight, (n, self.out_channels, h_out, w_out)), | |||
| self.bias) | |||
| output = self.conv2d_transpose(x, self.weight, (n, self.out_channels, h_out, w_out)) | |||
| return cast_to_adapter_tensor(output) | |||
| def extend_repr(self): | |||
| s = 'input_channels={}, output_channels={}, kernel_size={}, ' \ | |||
| 'stride={}, pad_mode={}, padding={}, dilation={}, ' \ | |||
| 'group={}, has_bias={}'.format(self.in_channels, | |||
| self.out_channels, | |||
| self.kernel_size, | |||
| self.stride, | |||
| self.pad_mode, | |||
| self.padding, | |||
| self.dilation, | |||
| self.group, | |||
| self.has_bias) | |||
| return s | |||
| class ConvTranspose3d(_ConvNd): | |||
| r""" | |||
| 3D transposed convolution layer. | |||
| Calculates a 3D transposed convolution, which can be regarded as Conv3d for the gradient of the input. | |||
| It also called deconvolution (although it is not an actual deconvolution). | |||
| Examples: | |||
| >>> x = Tensor(np.ones([32, 16, 10, 32, 32]), mindspore.float32) | |||
| >>> conv3d_transpose = nn.ConvTranspose3d(in_channels=16, out_channels=3, kernel_size=(4, 6, 2), | |||
| ... pad_mode='pad') | |||
| >>> output = conv3d_transpose(x) | |||
| >>> print(output.shape) | |||
| (32, 3, 13, 37, 33) | |||
| """ | |||
| def __init__( | |||
| self, | |||
| in_channels, | |||
| out_channels, | |||
| kernel_size, | |||
| stride = 1, | |||
| padding = 0, | |||
| output_padding = 0, | |||
| groups = 1, | |||
| bias = True, | |||
| dilation = 1, | |||
| padding_mode = 'zeros', | |||
| device=None, | |||
| dtype=None | |||
| ): | |||
| factory_kwargs = {'device': device, 'dtype': dtype, 'transposed': True} | |||
| _kernel_size = _triple(kernel_size) | |||
| _stride = _triple(stride) | |||
| _padding = _triple(padding) | |||
| _dilation = _triple(dilation) | |||
| output_padding = _triple(output_padding) | |||
| super(ConvTranspose3d, self).__init__(in_channels, out_channels, _kernel_size, _stride, _padding, _dilation, | |||
| output_padding, groups, bias, padding_mode, **factory_kwargs) | |||
| if padding == 0: | |||
| self.pad_mode = 'valid' | |||
| self.padding =(self.padding[0], self.padding[0], self.padding[1], | |||
| self.padding[1],self.padding[2], self.padding[2]) | |||
| elif isinstance(self.padding, str): | |||
| self.pad_mode = self.padding | |||
| self.padding = 0 | |||
| elif padding_mode == 'zeros': | |||
| self.pad_mode = "pad" | |||
| self.padding =(self.padding[0], self.padding[0], self.padding[1], | |||
| self.padding[1], self.padding[2], self.padding[2]) | |||
| if self.padding_mode != 'zeros': | |||
| raise ValueError('Only `zeros` padding mode is supported for ConvTranspose3d') | |||
| self.conv3d_transpose = P.Conv3DTranspose(in_channel=self.in_channels, | |||
| out_channel=self.out_channels, | |||
| kernel_size=self.kernel_size, | |||
| mode=1, | |||
| pad_mode=self.pad_mode, | |||
| pad=self.padding, | |||
| stride=self.stride, | |||
| dilation=self.dilation, | |||
| group=groups, | |||
| output_padding=self.output_padding, | |||
| data_format='NCDHW') | |||
| self.bias_add = P.BiasAdd(data_format='NCDHW') | |||
| def forward(self, input, output_size = None): | |||
| x = cast_to_ms_tensor(input) | |||
| if output_size is not None: | |||
| raise ValueError("output_size '{}' is not currently supported.".format(output_size)) | |||
| output = self.conv3d_transpose(x, self.weight) | |||
| if self.has_bias: | |||
| output = self.bias_add(output, self.bias) | |||
| return cast_to_adapter_tensor(output) | |||
| def _deconv_output_length(is_valid, is_same, is_pad, input_length, filter_size, stride_size, dilation_size, padding): | |||
| """Calculate the width and height of output.""" | |||
| length = 0 | |||
| filter_size = filter_size + (filter_size - 1) * (dilation_size - 1) | |||
| if is_valid: | |||
| if filter_size - stride_size > 0: | |||
| length = input_length * stride_size + filter_size - stride_size | |||
| else: | |||
| length = input_length * stride_size | |||
| elif is_same: | |||
| length = input_length * stride_size | |||
| elif is_pad: | |||
| length = input_length * stride_size - padding + filter_size - stride_size | |||
| return length | |||
| LazyConv1d = Conv1d | |||
| LazyConv2d = Conv2d | |||
| LazyConv3d = Conv3d | |||
| LazyConvTranspose1d = ConvTranspose1d | |||
| LazyConvTranspose2d = ConvTranspose2d | |||
| LazyConvTranspose3d = ConvTranspose3d | |||
+ 0
- 288
ms_adapter/pytorch/nn/modules/module.py
View File
| @@ -1,288 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from collections import OrderedDict | |||
| from mindspore.nn import Cell | |||
| from mindspore import Tensor as ms_Tensor | |||
| from ms_adapter.pytorch.tensor import tensor | |||
| from ms_adapter.pytorch.nn.parameter import Parameter | |||
| from ms_adapter.utils import unsupported_attr | |||
| from ms_adapter.pytorch.common.device import Device | |||
| __all__ = ['Module'] | |||
| class Module(Cell): | |||
| def __init__(self, auto_prefix=True, flags=None): | |||
| super(Module, self).__init__(auto_prefix, flags) | |||
| self.training = True | |||
| def __del__(self): | |||
| pass | |||
| def __repr__(self): | |||
| extra_str = self.extra_repr() | |||
| info_str = self.__class__.__name__ + '<' | |||
| if self._cells: | |||
| sub_str = '\n' | |||
| if extra_str: | |||
| sub_str += '{}\n'.format(self.extra_repr()) | |||
| for key, value in self._cells.items(): | |||
| sub_str += '({}): {}\n'.format(key, repr(value)) | |||
| sub_str = sub_str.replace('\n', '\n ') + '>' | |||
| info_str += sub_str | |||
| else: | |||
| info_str += extra_str + '>' | |||
| return info_str | |||
| def extra_repr(self): | |||
| r"""Set the extra representation of the module""" | |||
| return '' | |||
| def construct(self, *inputs, **kwargs): | |||
| return self.forward(*inputs, **kwargs) | |||
| def _run_construct(self, cast_inputs, kwargs): | |||
| """Run the construct function""" | |||
| if self._enable_forward_pre_hook: | |||
| cast_inputs = self._run_forward_pre_hook(cast_inputs) | |||
| if self._enable_backward_hook: | |||
| output = self._backward_hook_construct(*cast_inputs) | |||
| elif hasattr(self, "_shard_fn"): | |||
| output = self._shard_fn(*cast_inputs, **kwargs) | |||
| else: | |||
| output = self.construct(*cast_inputs, **kwargs) | |||
| if self._enable_forward_hook: | |||
| output = self._run_forward_hook(cast_inputs, output) | |||
| return output | |||
| def forward(self, *inputs, **kwargs): | |||
| raise NotImplementedError("The forward method must be implemented by inherited class") | |||
| def train(self, mode=True): | |||
| self.set_train(mode) | |||
| def eval(self): | |||
| self.set_train(False) | |||
| def modules(self): | |||
| result = [] | |||
| cells_names = self.cells_and_names() | |||
| for m in cells_names: | |||
| result.append(m[1]) | |||
| return iter(result) | |||
| def _parameters_and_names(self, name_prefix='', expand=True): | |||
| cells = [] | |||
| if expand: | |||
| cells = self.cells_and_names(name_prefix=name_prefix) | |||
| else: | |||
| cells.append((name_prefix, self)) | |||
| params_set = set() | |||
| for cell_name, cell in cells: | |||
| params = cell._params.items() | |||
| for par_name, par in params: | |||
| if par.inited_param is not None: | |||
| par = par.inited_param | |||
| if par is not None and id(par) not in params_set: | |||
| params_set.add(id(par)) | |||
| par_new_name = par_name | |||
| if cell_name: | |||
| par_new_name = cell_name + '.' + par_new_name | |||
| # TODO Update parameter names to avoid duplicates | |||
| par.name = par_new_name | |||
| yield par_new_name, par | |||
| def add_module(self, name, module): | |||
| if not isinstance(module, Module) and module is not None: | |||
| raise TypeError("{} is not a Module subclass".format( | |||
| module.__name__)) | |||
| elif hasattr(self, name) and name not in self._cells: | |||
| raise KeyError("attribute '{}' already exists".format(name)) | |||
| elif '.' in name: | |||
| raise KeyError("module name can't contain \".\", got: {}".format(name)) | |||
| elif name == '': | |||
| raise KeyError("module name can't be empty string \"\"") | |||
| self._cells[name] = module | |||
| def register_module(self, name, module): | |||
| """Alias for :func:`add_module`.""" | |||
| self.add_module(name, module) | |||
| def named_parameters(self, prefix='', recurse=True): | |||
| return self._parameters_and_names(prefix, recurse) | |||
| def parameters_and_names(self, name_prefix='', expand=True): | |||
| return self._parameters_and_names(name_prefix=name_prefix, expand=expand) | |||
| def named_children(self): | |||
| r"""Returns an iterator over immediate children modules, yielding both | |||
| the name of the module as well as the module itself. | |||
| Yields: | |||
| (string, Module): Tuple containing a name and child module | |||
| Example:: | |||
| >>> for name, module in model.named_children(): | |||
| >>> if name in ['conv4', 'conv5']: | |||
| >>> print(module) | |||
| """ | |||
| memo = set() | |||
| for name, module in self._cells.items(): | |||
| if module is not None and module not in memo: | |||
| memo.add(module) | |||
| yield name, module | |||
| def children(self): | |||
| r"""Returns an iterator over immediate children modules. | |||
| Yields: | |||
| Module: a child module | |||
| """ | |||
| for _, module in self.named_children(): | |||
| yield module | |||
| def apply(self, fn=None): | |||
| r"""Applies ``fn`` recursively to every submodule (as returned by ``.children()``) | |||
| as well as self. Typical use includes initializing the parameters of a model | |||
| (see also :ref:`nn-init-doc`). | |||
| Args: | |||
| fn (:class:`Module` -> None): function to be applied to each submodule | |||
| Returns: | |||
| Module: self | |||
| Example:: | |||
| >>> def init_weights(m): | |||
| >>> print(m) | |||
| >>> if type(m) == nn.Linear: | |||
| >>> m.weight.fill_(1.0) | |||
| >>> print(m.weight) | |||
| >>> net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2)) | |||
| >>> net.apply(init_weights) | |||
| """ | |||
| for module in self.children(): | |||
| module.apply(fn) | |||
| fn(self) | |||
| return self | |||
| def parameters(self, recurse = True): | |||
| for _, param in self.named_parameters(recurse=recurse): | |||
| yield param | |||
| def state_dict(self, destination=None, prefix='', keep_vars=False): | |||
| unsupported_attr(keep_vars) | |||
| unsupported_attr(prefix) | |||
| if destination is None: | |||
| destination = OrderedDict() | |||
| for n, v in self.named_parameters(): | |||
| destination[n] = tensor(v) | |||
| return destination | |||
| def register_buffer(self, name, tensor, persistent=True): | |||
| r"""Adds a buffer to the module. | |||
| This is typically used to register a buffer that should not to be | |||
| considered a model parameter. For example, BatchNorm's ``running_mean`` | |||
| is not a parameter, but is part of the module's state. Buffers, by | |||
| default, are persistent and will be saved alongside parameters. This | |||
| behavior can be changed by setting :attr:`persistent` to ``False``. The | |||
| only difference between a persistent buffer and a non-persistent buffer | |||
| is that the latter will not be a part of this module's | |||
| :attr:`state_dict`. | |||
| Buffers can be accessed as attributes using given names. | |||
| Args: | |||
| name (string): name of the buffer. The buffer can be accessed | |||
| from this module using the given name | |||
| tensor (Tensor or None): buffer to be registered. If ``None``, then operations | |||
| that run on buffers, such as :attr:`cuda`, are ignored. If ``None``, | |||
| the buffer is **not** included in the module's :attr:`state_dict`. | |||
| persistent (bool): whether the buffer is part of this module's | |||
| :attr:`state_dict`. | |||
| """ | |||
| unsupported_attr(persistent) | |||
| if '_params' not in self.__dict__: | |||
| raise AttributeError("cannot assign buffer before Module.__init__() call.") | |||
| elif not isinstance(name, str): | |||
| raise TypeError("buffer name should be a string. " | |||
| "Got {}".format(type(name))) | |||
| elif '.' in name: | |||
| raise KeyError("buffer name can't contain \".\"") | |||
| elif name == '': | |||
| raise KeyError("buffer name can't be empty string \"\"") | |||
| elif hasattr(self, name) and name not in self._params: | |||
| raise KeyError("attribute '{}' already exists".format(name)) | |||
| elif tensor is not None and not isinstance(tensor, ms_Tensor): | |||
| raise TypeError("cannot assign '{}' object to buffer '{}' " | |||
| "(Tensor or None required)" | |||
| .format(type(tensor), name)) | |||
| else: | |||
| self._params[name] = Parameter(tensor, name=name, requires_grad=False) | |||
| def to(self, *args, **kwargs): | |||
| # TODO: | |||
| # Note that this API requires the user to ensure the correctness of the input currently, | |||
| # and only the function of modifying device is available. | |||
| args_len = len(args) | |||
| kwargs_len = len(kwargs) | |||
| if args_len == 0 and kwargs_len == 0: | |||
| raise ValueError("Module.to is missing inputs, please check.") | |||
| elif (args_len + kwargs_len > 1) or (kwargs_len > 0 and "device" not in kwargs): | |||
| raise ValueError("Currently only the function of modifying device is available.") | |||
| elif (args_len > 0 and not isinstance(args[0], (str, Device))) or \ | |||
| (kwargs_len > 0 and not isinstance(kwargs.get("device"), (str, Device))): | |||
| raise ValueError("Currently only the function of modifying device is available, " | |||
| "which via a string or torch.device.") | |||
| def register_parameter(self, name, param): | |||
| """Adds a parameter to the module. | |||
| The parameter can be accessed as an attribute using given name. | |||
| Args: | |||
| name (string): name of the parameter. The parameter can be accessed | |||
| from this module using the given name | |||
| param (Parameter or None): parameter to be added to the module. If | |||
| ``None``, then operations that run on parameters, such as :attr:`cuda`, | |||
| are ignored. If ``None``, the parameter is **not** included in the | |||
| module's :attr:`state_dict`. | |||
| """ | |||
| if '_params' not in self.__dict__: | |||
| raise AttributeError("cannot assign parameter before Module.__init__() call") | |||
| elif not isinstance(name, str): | |||
| raise TypeError("parameter name should be a string. Got {}".format(type(name))) | |||
| elif '.' in name: | |||
| raise KeyError("parameter name can't contain \".\"") | |||
| elif name == '': | |||
| raise KeyError("parameter name can't be empty string \"\"") | |||
| elif hasattr(self, name) and name not in self._params: | |||
| raise KeyError("attribute '{}' already exists".format(name)) | |||
| if param is None: | |||
| self._params[name] = None | |||
| elif not isinstance(param, Parameter): | |||
| raise TypeError("cannot assign '{}' object to parameter '{}' " | |||
| "(nn.Parameter or None required)" | |||
| .format(type(param), name)) | |||
| else: | |||
| self._params[name] = param | |||
| def cuda(self, device): | |||
| unsupported_attr(device) | |||
| return self | |||
+ 0
- 454
ms_adapter/pytorch/nn/modules/pooling.py
View File
| @@ -1,454 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from typing import Iterable | |||
| import mindspore as ms | |||
| from mindspore.ops import operations as P | |||
| from mindspore.ops import functional as F | |||
| from mindspore.ops._primitive_cache import _get_cache_prim | |||
| import ms_adapter.pytorch.nn.functional as Adapter_F | |||
| from ms_adapter.utils import unsupported_attr, is_under_ascend_context | |||
| from ms_adapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from .module import Module | |||
| __all__ = ['MaxPool1d', 'MaxPool2d', 'MaxPool3d', | |||
| 'AvgPool1d', 'AvgPool2d', 'AvgPool3d', | |||
| 'AdaptiveAvgPool1d', 'AdaptiveAvgPool2d', 'AdaptiveAvgPool3d', | |||
| 'AdaptiveMaxPool1d', 'AdaptiveMaxPool2d', 'AdaptiveMaxPool3d', | |||
| 'LPPool1d', 'LPPool2d', 'FractionalMaxPool2d', 'FractionalMaxPool3d'] | |||
| class _MaxPoolNd(Module): | |||
| def __init__(self, kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False): | |||
| super(_MaxPoolNd, self).__init__() | |||
| self.kernel_size = kernel_size | |||
| self.stride = stride if (stride is not None) else kernel_size | |||
| self.padding = padding | |||
| self.dilation = dilation | |||
| self.return_indices = return_indices | |||
| self.ceil_mode = ceil_mode | |||
| unsupported_attr(return_indices) | |||
| unsupported_attr(dilation) | |||
| if return_indices is True or dilation != 1: | |||
| raise NotImplementedError("These parameters cannot be set now.") | |||
| def extra_repr(self): | |||
| return 'kernel_size={kernel_size}, stride={stride}, padding={padding}' \ | |||
| ', dilation={dilation}, ceil_mode={ceil_mode}'.format(**self.__dict__) | |||
| class MaxPool1d(_MaxPoolNd): | |||
| def __init__(self, kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False): | |||
| super(MaxPool1d, self).__init__(kernel_size, stride, padding, dilation, return_indices, ceil_mode) | |||
| self.kernel_size = (1, kernel_size) | |||
| self.stride = (1, self.stride) | |||
| self.pad = P.Pad(((0, 0), (0, 0), (0, 0), (padding, padding))) | |||
| self.max_pool = P.MaxPool(kernel_size=self.kernel_size, | |||
| strides=self.stride, | |||
| pad_mode='valid') | |||
| self.expand = P.ExpandDims() | |||
| self.squeeze = P.Squeeze(2) | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| input = self.expand(input, 2) | |||
| input = self.pad(input) | |||
| output = self.max_pool(input) | |||
| output = self.squeeze(output) | |||
| return cast_to_adapter_tensor(output) | |||
| class MaxPool2d(_MaxPoolNd): | |||
| def __init__(self, kernel_size=1, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False): | |||
| super(MaxPool2d, self).__init__(kernel_size, stride, padding, dilation, return_indices, ceil_mode) | |||
| def forward(self, input): | |||
| return Adapter_F.max_pool2d(input, self.kernel_size, self.stride, self.padding, self.dilation, | |||
| self.ceil_mode, self.return_indices) | |||
| class MaxPool3d(_MaxPoolNd): | |||
| def __init__(self, kernel_size=1, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False): | |||
| super(MaxPool3d, self).__init__(kernel_size, stride, padding, dilation, return_indices, ceil_mode) | |||
| # TODO Processing 4D inputs | |||
| # reference https://mindspore.cn/docs/zh-CN/master/note/api_mapping/pytorch_diff/MaxPool3D.html? | |||
| self.padding = padding if isinstance(padding, tuple) else (padding, padding, padding) | |||
| self.pad = P.Pad(((0, 0), (0, 0), (self.padding[0], self.padding[0]), (self.padding[1], self.padding[1]), | |||
| (self.padding[2], self.padding[2]))) | |||
| self.max_pool = P.MaxPool3D(kernel_size=self.kernel_size, | |||
| strides=self.stride, | |||
| pad_mode='valid') | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| input = self.pad(input) | |||
| output = self.max_pool(input) | |||
| return cast_to_adapter_tensor(output) | |||
| class _AvgPoolNd(Module): | |||
| def __init__(self, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, | |||
| divisor_override = None): | |||
| super(_AvgPoolNd, self).__init__() | |||
| self.kernel_size = kernel_size | |||
| self.stride = stride if (stride is not None) else kernel_size | |||
| self.padding = padding | |||
| self.ceil_mode = ceil_mode | |||
| self.count_include_pad = count_include_pad | |||
| self.divisor_override = divisor_override | |||
| unsupported_attr(ceil_mode) | |||
| unsupported_attr(count_include_pad) | |||
| unsupported_attr(divisor_override) | |||
| if ceil_mode is True or count_include_pad is False or divisor_override is not None: | |||
| raise NotImplementedError("These parameters cannot be set now.") | |||
| def extra_repr(self): | |||
| return 'kernel_size={}, stride={}, padding={}'.format( | |||
| self.kernel_size, self.stride, self.padding | |||
| ) | |||
| class AvgPool1d(_AvgPoolNd): | |||
| def __init__(self, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, | |||
| divisor_override = None): | |||
| super(AvgPool1d, self).__init__(kernel_size, stride, padding, ceil_mode, count_include_pad, divisor_override) | |||
| self.kernel_size = (1, kernel_size) | |||
| self.stride = (1, self.stride) | |||
| self.padding = padding if isinstance(padding, tuple) else (padding, padding) | |||
| self.pad = P.Pad(((0, 0), (0, 0), (0, 0), (padding, padding))) | |||
| self.avg_pool = P.AvgPool(kernel_size=self.kernel_size, | |||
| strides=self.stride, | |||
| pad_mode='valid') | |||
| self.shape = F.shape | |||
| self.reduce_mean = P.ReduceMean(keep_dims=True) | |||
| self.slice = P.Slice() | |||
| self.expand = P.ExpandDims() | |||
| self.squeeze = P.Squeeze(2) | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| batch, channel, width = self.shape(input) | |||
| if width == self.kernel_size[1]: | |||
| output = self.reduce_mean(input, 2) | |||
| elif width - self.kernel_size[1] < self.stride[1]: | |||
| input = self.slice(input, (0, 0, 0), (batch, channel, self.kernel_size[1])) | |||
| output = self.reduce_mean(input, 2) | |||
| else: | |||
| input = self.expand(input, 2) | |||
| input = self.pad(input) | |||
| output = self.avg_pool(input) | |||
| output = self.squeeze(output) | |||
| return cast_to_adapter_tensor(output) | |||
| class AvgPool2d(_AvgPoolNd): | |||
| def __init__(self, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, | |||
| divisor_override=None): | |||
| super(AvgPool2d, self).__init__(kernel_size, stride, padding, ceil_mode, count_include_pad, divisor_override) | |||
| self.padding = padding | |||
| self.kernel_size = kernel_size | |||
| def forward(self, input): | |||
| return Adapter_F.avg_pool2d(input, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding) | |||
| class AvgPool3d(_AvgPoolNd): | |||
| def __init__(self, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, | |||
| divisor_override = None): | |||
| super(AvgPool3d, self).__init__(kernel_size, stride, padding, ceil_mode, count_include_pad, divisor_override) | |||
| self.padding = padding if isinstance(padding, tuple) else (padding, padding, padding) | |||
| self.pad = P.Pad(((0, 0), (0, 0), (self.padding[0], self.padding[0]), (self.padding[1], self.padding[1]), | |||
| (self.padding[2], self.padding[2]))) | |||
| self.avg_pool = P.AvgPool3D(kernel_size=self.kernel_size, | |||
| strides=self.stride, | |||
| pad_mode='valid') | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| input = self.pad(input) | |||
| output = self.avg_pool(input) | |||
| return cast_to_adapter_tensor(output) | |||
| class _AdaptiveAvgPoolNd(Module): | |||
| def __init__(self, output_size): | |||
| super(_AdaptiveAvgPoolNd, self).__init__() | |||
| self.output_size = output_size | |||
| def extra_repr(self): | |||
| return 'output_size={}'.format(self.output_size) | |||
| class AdaptiveAvgPool1d(_AdaptiveAvgPoolNd): | |||
| def __init__(self, output_size): | |||
| """Initialize AdaptiveMaxPool1d.""" | |||
| super(AdaptiveAvgPool1d, self).__init__(output_size) | |||
| self.expand = P.ExpandDims() | |||
| self.squeeze = P.Squeeze(2) | |||
| self.output_size = output_size | |||
| self.shape = F.shape | |||
| def construct(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| _, _, width = self.shape(input) | |||
| stride = width // self.output_size | |||
| kernel_size = width - (self.output_size - 1) * stride | |||
| stride = (1, width // self.output_size) | |||
| kernel_size = (1, kernel_size) | |||
| max_pool = _get_cache_prim(P.AvgPool)(kernel_size=kernel_size, strides=stride, | |||
| pad_mode="valid", data_format="NCHW") | |||
| input = self.expand(input, 2) | |||
| x = max_pool(input) | |||
| x = self.squeeze(x) | |||
| return cast_to_adapter_tensor(x) | |||
| class AdaptiveAvgPool2d(_AdaptiveAvgPoolNd): | |||
| def __init__(self, output_size): | |||
| super(AdaptiveAvgPool2d, self).__init__(output_size) | |||
| self.output_size = output_size | |||
| self.shape = P.Shape() | |||
| if not isinstance(self.output_size, Iterable): | |||
| self.output_size = [self.output_size, ] * 2 | |||
| self.condition = [0,] * 2 | |||
| if None in self.output_size: | |||
| self.output_size = list(self.output_size) | |||
| if self.output_size[0] is None: | |||
| self.condition [0] = 1 | |||
| self.output_size[0] = 0 | |||
| if self.output_size[1] is None: | |||
| self.condition [1] = 1 | |||
| self.output_size[1] = 0 | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| _, _, h, w = self.shape(input) | |||
| out_h = self.output_size[0] + self.condition[0] * h | |||
| out_w = self.output_size[1] + self.condition[1] * w | |||
| stride_h = h // out_h | |||
| kernel_h = h - (out_h - 1) * stride_h | |||
| stride_w = w // out_w | |||
| kernel_w = w - (out_w - 1) * stride_w | |||
| avg_pool = _get_cache_prim(P.AvgPool)( | |||
| kernel_size=(kernel_h, kernel_w), strides=(stride_h, stride_w), pad_mode="valid", data_format="NCHW" | |||
| ) | |||
| outputs = avg_pool(input) | |||
| return cast_to_adapter_tensor(outputs) | |||
| class AdaptiveAvgPool3d(_AdaptiveAvgPoolNd): | |||
| def __init__(self, output_size): | |||
| super(AdaptiveAvgPool3d, self).__init__(output_size) | |||
| self.output_size = output_size | |||
| self.shape = P.Shape() | |||
| if not isinstance(self.output_size, Iterable): | |||
| self.output_size = [self.output_size, ] * 3 | |||
| self.condition = [0,] * 3 | |||
| if None in self.output_size: | |||
| self.output_size = list(self.output_size) | |||
| if self.output_size[0] is None: | |||
| self.condition [0] = 1 | |||
| self.output_size[0] = 0 | |||
| if self.output_size[1] is None: | |||
| self.condition [1] = 1 | |||
| self.output_size[1] = 0 | |||
| if self.output_size[2] is None: | |||
| self.condition[2] = 1 | |||
| self.output_size[2] = 0 | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| _, _, d, h, w = self.shape(input) | |||
| out_d = self.output_size[0] + self.condition[0] * d | |||
| out_h = self.output_size[1] + self.condition[1] * h | |||
| out_w = self.output_size[2] + self.condition[2] * w | |||
| stride_d = d // out_d | |||
| kernel_d = d - (out_d - 1) * stride_d | |||
| stride_h = h // out_h | |||
| kernel_h = h - (out_h - 1) * stride_h | |||
| stride_w = w // out_w | |||
| kernel_w = w - (out_w - 1) * stride_w | |||
| avg_pool = _get_cache_prim(P.AvgPool3D)(kernel_size=(kernel_d, kernel_h, kernel_w), | |||
| strides=(stride_d, stride_h, stride_w), | |||
| pad_mode="valid", data_format="NCDHW") | |||
| outputs = avg_pool(input) | |||
| return cast_to_adapter_tensor(outputs) | |||
| class _AdaptiveMaxPoolNd(Module): | |||
| def __init__(self, output_size, return_indices = False): | |||
| super(_AdaptiveMaxPoolNd, self).__init__() | |||
| self.output_size = output_size | |||
| self.return_indices = return_indices | |||
| def extra_repr(self) -> str: | |||
| return 'output_size={}'.format(self.output_size) | |||
| class AdaptiveMaxPool1d(_AdaptiveMaxPoolNd): | |||
| def __init__(self, output_size, return_indices = False): | |||
| """Initialize AdaptiveMaxPool1d.""" | |||
| super(AdaptiveMaxPool1d, self).__init__(output_size, return_indices) | |||
| self.expand = P.ExpandDims() | |||
| self.squeeze = P.Squeeze(2) | |||
| self.output_size = output_size | |||
| self.shape = F.shape | |||
| self.return_indices = return_indices | |||
| def construct(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| _, _, width = self.shape(input) | |||
| stride = width // self.output_size | |||
| kernel_size = width - (self.output_size - 1) * stride | |||
| stride = (1, width // self.output_size) | |||
| kernel_size = (1, kernel_size) | |||
| if self.return_indices: | |||
| max_pool = P.MaxPoolWithArgmax(kernel_size=kernel_size, strides=stride, | |||
| pad_mode='valid', data_format="NCHW") | |||
| x = self.expand(input, 2) | |||
| x, idx = max_pool(x) | |||
| x = self.squeeze(x) | |||
| # TODO: to avoid ascend not return ms.int32 but ms.uint16 | |||
| idx = idx.astype(ms.int32) | |||
| idx = self.squeeze(idx) | |||
| return cast_to_adapter_tensor((x, idx)) | |||
| else: | |||
| max_pool = P.MaxPool(kernel_size=kernel_size, strides=stride, pad_mode="valid", data_format="NCHW") | |||
| x = self.expand(input, 2) | |||
| x = max_pool(x) | |||
| x = self.squeeze(x) | |||
| return cast_to_adapter_tensor(x) | |||
| class AdaptiveMaxPool2d(_AdaptiveMaxPoolNd): | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| if is_under_ascend_context() and len(input.shape) == 3: | |||
| input = ms.ops.expand_dims(input, 0) | |||
| output = ms.ops.adaptive_max_pool2d(input, self.output_size, self.return_indices) | |||
| if self.return_indices: | |||
| output[0] = ms.ops.squeeze(output[0], 0) | |||
| output[1] = ms.ops.squeeze(output[1], 1) | |||
| else: | |||
| output = ms.ops.squeeze(output, 0) | |||
| else: | |||
| output = ms.ops.adaptive_max_pool2d(input, self.output_size, self.return_indices) | |||
| return cast_to_adapter_tensor(output) | |||
| class AdaptiveMaxPool3d(_AdaptiveMaxPoolNd): | |||
| def __init__(self, output_size, return_indices = False): | |||
| super(AdaptiveMaxPool3d, self).__init__(output_size, return_indices) | |||
| self.output_size = output_size | |||
| self.shape = P.Shape() | |||
| if not isinstance(self.output_size, Iterable): | |||
| self.output_size = [self.output_size, ] * 3 | |||
| self.condition = [0,] * 3 | |||
| if None in self.output_size: | |||
| self.output_size = list(self.output_size) | |||
| if self.output_size[0] is None: | |||
| self.condition [0] = 1 | |||
| self.output_size[0] = 0 | |||
| if self.output_size[1] is None: | |||
| self.condition [1] = 1 | |||
| self.output_size[1] = 0 | |||
| if self.output_size[2] is None: | |||
| self.condition[2] = 1 | |||
| self.output_size[2] = 0 | |||
| if return_indices: | |||
| raise NotImplementedError('AdaptiveMaxPool3d doesn\'t support return_indices now.') | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| _, _, d, h, w = self.shape(input) | |||
| out_d = self.output_size[0] + self.condition[0] * d | |||
| out_h = self.output_size[1] + self.condition[1] * h | |||
| out_w = self.output_size[2] + self.condition[2] * w | |||
| stride_d = d // out_d | |||
| kernel_d = d - (out_d - 1) * stride_d | |||
| stride_h = h // out_h | |||
| kernel_h = h - (out_h - 1) * stride_h | |||
| stride_w = w // out_w | |||
| kernel_w = w - (out_w - 1) * stride_w | |||
| avg_pool = P.MaxPool3D(kernel_size=(kernel_d, kernel_h, kernel_w), | |||
| strides=(stride_d, stride_h, stride_w), | |||
| pad_mode="valid", data_format="NCDHW") | |||
| outputs = avg_pool(input) | |||
| return cast_to_adapter_tensor(outputs) | |||
| class _LPPoolNd(Module): | |||
| def __init__(self, norm_type, kernel_size, stride = None, | |||
| ceil_mode = False): | |||
| super(_LPPoolNd, self).__init__() | |||
| self.norm_type = norm_type | |||
| self.kernel_size = kernel_size | |||
| self.stride = stride | |||
| self.ceil_mode = ceil_mode | |||
| def extra_repr(self): | |||
| return 'norm_type={norm_type}, kernel_size={kernel_size}, stride={stride}, ' \ | |||
| 'ceil_mode={ceil_mode}'.format(**self.__dict__) | |||
| class LPPool1d(_LPPoolNd): | |||
| def forward(self, input): | |||
| return Adapter_F.lp_pool1d(input, float(self.norm_type), self.kernel_size, | |||
| self.stride, self.ceil_mode) | |||
| class LPPool2d(_LPPoolNd): | |||
| def forward(self, input): | |||
| return Adapter_F.lp_pool2d(input, float(self.norm_type), self.kernel_size, | |||
| self.stride, self.ceil_mode) | |||
| class FractionalMaxPool2d(Module): | |||
| def __init__(self, kernel_size, output_size=None, output_ratio=None, return_indices=False, | |||
| _random_samples=None): | |||
| super(FractionalMaxPool2d, self).__init__() | |||
| self.kernel_size = kernel_size | |||
| self.return_indices = return_indices | |||
| self.output_size = output_size | |||
| self.output_ratio = output_ratio | |||
| self._random_samples = _random_samples | |||
| if output_size is None and output_ratio is None: | |||
| raise ValueError("FractionalMaxPool2d requires specifying either " | |||
| "an output size, or a pooling ratio") | |||
| if output_size is not None and output_ratio is not None: | |||
| raise ValueError("only one of output_size and output_ratio may be specified") | |||
| if self.output_ratio is not None: | |||
| if not (0 < self.output_ratio[0] < 1 and 0 < self.output_ratio[1] < 1): | |||
| raise ValueError("output_ratio must be between 0 and 1 (got {})" | |||
| .format(output_ratio)) | |||
| def forward(self, input): | |||
| return Adapter_F.fractional_max_pool2d(input, self.kernel_size, self.output_size, self.output_ratio, | |||
| self.return_indices, self._random_samples) | |||
| class FractionalMaxPool3d(Module): | |||
| def __init__(self, kernel_size, output_size=None, output_ratio=None, return_indices=False, | |||
| _random_samples=None): | |||
| super(FractionalMaxPool3d, self).__init__() | |||
| self.kernel_size = kernel_size | |||
| self.return_indices = return_indices | |||
| self.output_size = output_size | |||
| self.output_ratio = output_ratio | |||
| self._random_samples = _random_samples | |||
| if output_size is None and output_ratio is None: | |||
| raise ValueError("FractionalMaxPool3d requires specifying either " | |||
| "an output size, or a pooling ratio") | |||
| if output_size is not None and output_ratio is not None: | |||
| raise ValueError("only one of output_size and output_ratio may be specified") | |||
| if self.output_ratio is not None: | |||
| if not (0 < self.output_ratio[0] < 1 and 0 < self.output_ratio[1] < 1): | |||
| raise ValueError("output_ratio must be between 0 and 1 (got {})" | |||
| .format(output_ratio)) | |||
| def forward(self, input): | |||
| return Adapter_F.fractional_max_pool3d(input, self.kernel_size, self.output_size, self.output_ratio, | |||
| self.return_indices, self._random_samples) | |||
+ 0
- 104
ms_adapter/pytorch/nn/modules/rnn.py
View File
| @@ -1,104 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from mindspore import nn | |||
| from ms_adapter.pytorch.nn.modules.module import Module | |||
| from ms_adapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| class RNNBase(Module): | |||
| def __init__(self, mode, *args, **kwargs): | |||
| super(RNNBase, self).__init__() | |||
| # args transformation | |||
| self.rnn = None | |||
| if 'bias' in kwargs: | |||
| kwargs['has_bias'] = kwargs.pop('bias') | |||
| if 'dropout' in kwargs: | |||
| # TODO | |||
| # if not in kwargs but in args? | |||
| value = kwargs['dropout'] | |||
| kwargs['dropout'] = float(value) | |||
| # TODO | |||
| # For LSTM, torch has `proj_size`, while mindspore did not. | |||
| if mode == 'RNN': | |||
| self.rnn = nn.RNN(*args, **kwargs) | |||
| elif mode == 'GRU': | |||
| self.rnn = nn.GRU(*args, **kwargs) | |||
| elif mode == 'LSTM': | |||
| self.rnn = nn.LSTM(*args, **kwargs) | |||
| def forward(self, input, h_0): | |||
| input = cast_to_ms_tensor(input) | |||
| h_0 = cast_to_ms_tensor(h_0) | |||
| output = self.rnn(input, h_0) | |||
| return cast_to_adapter_tensor(output) | |||
| # TODO | |||
| # more function interface should be add in the future | |||
| class RNN(RNNBase): | |||
| def __init__(self, *args, **kwargs): | |||
| super(RNN, self).__init__(mode='RNN', *args, **kwargs) | |||
| class GRU(RNNBase): | |||
| def __init__(self, *args, **kwargs): | |||
| super(GRU, self).__init__(mode='GRU', *args, **kwargs) | |||
| class LSTM(RNNBase): | |||
| def __init__(self, *args, **kwargs): | |||
| super(LSTM, self).__init__(mode='LSTM', *args, **kwargs) | |||
| def forward(self, input, hc_0): | |||
| input = cast_to_ms_tensor(input) | |||
| hc_0 = cast_to_ms_tensor(hc_0) | |||
| output, hc_n = self.rnn(input, hc_0) | |||
| return cast_to_adapter_tensor(output), cast_to_adapter_tensor(hc_n) | |||
| class RNNCellBase(Module): | |||
| def __init__(self, mode, *args, **kwargs): | |||
| super(RNNCellBase, self).__init__() | |||
| self.rnn_cell = None | |||
| if 'bias' in kwargs: | |||
| kwargs['has_bias'] = kwargs.pop('bias') | |||
| if mode == 'RNNCell': | |||
| self.rnn_cell = nn.RNNCell(*args, **kwargs) | |||
| elif mode == 'GRUCell': | |||
| self.rnn_cell = nn.GRUCell(*args, **kwargs) | |||
| elif mode == 'LSTMCell': | |||
| self.rnn_cell = nn.LSTMCell(*args, **kwargs) | |||
| def forward(self, input, h_x=None): | |||
| input = cast_to_ms_tensor(input) | |||
| h_x = cast_to_ms_tensor(h_x) | |||
| output = self.rnn_cell(input, h_x) | |||
| return cast_to_adapter_tensor(output) | |||
| # TODO | |||
| # more function interfaces should add in the future | |||
| class RNNCell(RNNCellBase): | |||
| def __init__(self, *args, **kwargs): | |||
| super(RNNCell, self).__init__('RNNCell', *args, **kwargs) | |||
| class LSTMCell(RNNCellBase): | |||
| def __init__(self, *args, **kwargs): | |||
| super(LSTMCell, self).__init__('LSTMCell', *args, **kwargs) | |||
| def forward(self, input, hc_0): | |||
| input = cast_to_ms_tensor(input) | |||
| hc_0 = cast_to_ms_tensor(hc_0) | |||
| output, hc_n = self.rnn(input, hc_0) | |||
| return cast_to_adapter_tensor(output), cast_to_adapter_tensor(hc_n) | |||
| class GRUCell(RNNCellBase): | |||
| def __init__(self, *args, **kwargs): | |||
| super(GRUCell, self).__init__('GRUCell', *args, **kwargs) | |||
+ 0
- 31
ms_adapter/pytorch/nn/modules/utils.py
View File
| @@ -1,31 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import collections | |||
| from itertools import repeat | |||
| def _ntuple(n, name="parse"): | |||
| def parse(x): | |||
| if isinstance(x, list) and len(x) == 1: | |||
| x = x[0] | |||
| if isinstance(x, collections.abc.Iterable): | |||
| return tuple(x) | |||
| return tuple(repeat(x, n)) | |||
| parse.__name__ = name | |||
| return parse | |||
| _single = _ntuple(1, "_single") | |||
| _pair = _ntuple(2, "_pair") | |||
| _triple = _ntuple(3, "_triple") | |||
| _quadruple = _ntuple(4, "_quadruple") | |||
| def _reverse_repeat_tuple(t, n): | |||
| r"""Reverse the order of `t` and repeat each element for `n` times. | |||
| This can be used to translate padding arg used by Conv and Pooling modules | |||
| to the ones used by `F.pad`. | |||
| """ | |||
| return tuple(x for x in reversed(t) for _ in range(n)) | |||
+ 0
- 377
ms_adapter/pytorch/nn/parameter.py
View File
| @@ -1,377 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| """Parameter interface""" | |||
| import sys | |||
| import numbers | |||
| from copy import copy | |||
| import mindspore as ms | |||
| import mindspore.common.dtype as mstype | |||
| from mindspore.common.initializer import initializer | |||
| from mindspore._checkparam import Validator | |||
| from mindspore._c_expression import Tensor as Tensor_ | |||
| from mindspore.parallel._tensor import _get_slice_index | |||
| from mindspore.parallel._auto_parallel_context import auto_parallel_context | |||
| from mindspore.parallel._ps_context import _is_role_worker, _is_role_sched, _clone_hash_table | |||
| from mindspore.parallel._ps_context import _insert_weight_init_info, _insert_accumu_init_info | |||
| from mindspore.common.seed import _get_global_and_op_seed | |||
| from mindspore.ops import functional as F | |||
| from ms_adapter.pytorch.tensor import Tensor, cast_to_adapter_tensor | |||
| __all__ = ['Parameter', 'ParameterTuple'] | |||
| PARAMETER_NAME_DEFAULT = "Parameter" | |||
| PARAMETER_NAME_PREFIX_MAX_LEN = 1024 | |||
| # Global variable for parameter unique key. | |||
| _GLOBAL_PARAMETER_KEY = -1 | |||
| def _is_in_parallel_mode(): | |||
| """Get parallel mode.""" | |||
| return auto_parallel_context().get_parallel_mode() in ["semi_auto_parallel", "auto_parallel"] | |||
| def init_to_value(init): | |||
| """ | |||
| Get value of initializer. | |||
| Returns: | |||
| Value of the initializer. | |||
| Raises: | |||
| ValueError: The value of the argument 'init' is not correct. | |||
| """ | |||
| if isinstance(init, str): | |||
| if init == 'zeros': | |||
| return 0.0 | |||
| if init == 'ones': | |||
| return 1.0 | |||
| raise ValueError("The argument 'init' should be one of values in ['zeros', 'ones'].") | |||
| if isinstance(init, numbers.Number): | |||
| return float(init) | |||
| raise ValueError("The argument 'init' should be number or string, but got {}.".format(type(init))) | |||
| def _get_unique_parameter_key(): | |||
| """ | |||
| Get parameter unique key. | |||
| Used to identify the same Parameter for Worker and Server in the embedding cache scenario. | |||
| Returns: | |||
| Integer. The unique parameter key. | |||
| """ | |||
| global _GLOBAL_PARAMETER_KEY | |||
| _GLOBAL_PARAMETER_KEY += 1 | |||
| return _GLOBAL_PARAMETER_KEY | |||
| class Parameter(ms.Parameter): | |||
| # Parameter is an subclass of ms.Parameter and adapter.Tensor, only 'Parameter' in methods need be overload. | |||
| def __new__(cls, data, *args, **kwargs): | |||
| init_data_flag = bool(isinstance(data, ms.Tensor) and data.has_init) | |||
| rc = sys.getrefcount(data) | |||
| _, *class_init_args = Parameter._get_parameter_new_args(data, rc) | |||
| new_type = Parameter._get_base_class(Tensor) | |||
| obj = Tensor.__new__(new_type) | |||
| Tensor.__init__(obj, *class_init_args, inner=True) | |||
| # it's better to make the Initializer a kind of tensor. | |||
| obj.init_mode = None | |||
| obj.is_default_input_init = init_data_flag | |||
| if obj.has_init: | |||
| obj.init_mode = data | |||
| return obj | |||
| def __reduce_ex__(self, _): | |||
| data = self | |||
| if self.init_mode is not None: | |||
| data = self.init_mode | |||
| else: | |||
| # cast to break deep infinite loop while deepcopy | |||
| data = Tensor(self) | |||
| return ( | |||
| Parameter, (data, self.name, self.requires_grad, self.layerwise_parallel)) | |||
| def __init__(self, data, name=None, requires_grad=True, layerwise_parallel=False, parallel_optimizer=True): | |||
| super().__init__(default_input=data, name=name, requires_grad=requires_grad, | |||
| layerwise_parallel=layerwise_parallel, parallel_optimizer=parallel_optimizer) | |||
| def __deepcopy__(self, memodict): | |||
| new_obj = Parameter(self) | |||
| new_obj.name = self.name | |||
| new_obj._inited_param = self._inited_param | |||
| return new_obj | |||
| def __str__(self): | |||
| return f'Parameter containing: {Tensor_.__repr__(self.data)}, requires_grad={self.requires_grad})' | |||
| def __parameter__(self): | |||
| """For parse check.""" | |||
| @staticmethod | |||
| def _get_base_class(input_class): | |||
| input_class_name = Parameter.__name__ | |||
| if input_class_name in Parameter._base_type: | |||
| new_type = Parameter._base_type.get(input_class_name) | |||
| else: | |||
| new_type = type(input_class_name, (Parameter, input_class), {}) | |||
| Parameter._base_type[input_class_name] = new_type | |||
| return new_type | |||
| def copy(self): | |||
| """ | |||
| Copy the parameter. | |||
| Returns: | |||
| Parameter, a new parameter. | |||
| """ | |||
| return self.clone(init='same') | |||
| def clone(self, init='same'): | |||
| """ | |||
| Clone the parameter. | |||
| Args: | |||
| init (Union[Tensor, str, numbers.Number]): Initialize the shape and dtype of the parameter. | |||
| If `init` is a `Tensor` or `numbers.Number`, clone a new parameter with the same shape | |||
| and dtype, and the data of the new parameter will be set according to `init`. If `init` | |||
| is a `str`, the `init` should be the alias of the class inheriting from `Initializer`. | |||
| For example, if `init` is 'same', clone a new parameter with the same data, shape, and | |||
| dtype. Default: 'same'. | |||
| Returns: | |||
| Parameter, a new parameter. | |||
| """ | |||
| x = copy(self) | |||
| param_info_clone = self.param_info.clone() | |||
| info = self.param_info | |||
| if hasattr(info, "cloned_obj"): | |||
| info.cloned_obj.append(x) | |||
| else: | |||
| info.cloned_obj = [x] | |||
| self.param_info = info | |||
| param_info_clone.obj = x | |||
| x.param_info = param_info_clone | |||
| x.is_init = False | |||
| x.init = self.init | |||
| x.is_param_ps = self.is_param_ps | |||
| x.init_in_server = self.init_in_server | |||
| x.cache_enable = self.cache_enable | |||
| if x.cache_enable: | |||
| x.key = _get_unique_parameter_key() | |||
| x.requires_aggr = self.requires_aggr | |||
| if self.cache_shape: | |||
| x.cache_shape = self.cache_shape | |||
| if init != 'same': | |||
| shape = self.shape | |||
| dtype = self.dtype | |||
| init_data = initializer(init, shape=shape, dtype=dtype) | |||
| x.set_data(cast_to_adapter_tensor(init_data)) | |||
| return x | |||
| @property | |||
| def data(self): | |||
| """Return the parameter object.""" | |||
| return self | |||
| def _update_tensor_data(self, data): | |||
| """Update the parameter by a Tensor.""" | |||
| if isinstance(self, Tensor): | |||
| self.init_flag = False | |||
| self.init = None | |||
| return self.assign_value(data) | |||
| new_param = Parameter(data, self.name, self.requires_grad) | |||
| new_param.param_info = self.param_info | |||
| return new_param | |||
| @staticmethod | |||
| def _from_tensor(tensor, *args, **kwargs): | |||
| """Create a `Parameter` that data is shared from a `Tensor`.""" | |||
| if not isinstance(tensor, Tensor_): | |||
| raise TypeError(f"The type of input must be Tensor, but got {type(tensor)}.") | |||
| param = Tensor_.__new__(Parameter) | |||
| Tensor_.__init__(param, tensor) | |||
| param.init = None | |||
| param.init_mode = None | |||
| param.is_default_input_init = False | |||
| Parameter.__init__(param, tensor, *args, **kwargs) | |||
| return param | |||
| def set_data(self, data, slice_shape=False): | |||
| """ | |||
| Set Parameter's data. | |||
| Args: | |||
| data (Union[Tensor, int, float]): New data. | |||
| slice_shape (bool): If slice the parameter is set to true, the shape is not checked for consistency. | |||
| Default: False. | |||
| Returns: | |||
| Parameter, the parameter after set data. | |||
| """ | |||
| if not isinstance(data, (Tensor, int, float)): | |||
| raise TypeError(f"Parameter data must be [`Tensor`, `int`, `float`] or a kind of `Tensor` " | |||
| f"(like `Tensor`). But with type {type(data)}.") | |||
| if isinstance(data, (int, float)): | |||
| if self.dtype in mstype.int_type and isinstance(data, float): | |||
| self._raise_type_error(mstype.float_) | |||
| data = Tensor(data, self.dtype) | |||
| # both not init. | |||
| incoming_tensor_is_init = isinstance(data, Tensor) and not data.has_init | |||
| current_tensor_is_init = isinstance(self, Tensor) and not self.has_init | |||
| Parameter._set_data_check_input_valid(self.shape, data.shape, current_tensor_is_init, incoming_tensor_is_init, | |||
| slice_shape) | |||
| if self.dtype != data.dtype: | |||
| if mstype.implicit_conversion_seq[self.dtype] < mstype.implicit_conversion_seq[data.dtype]: | |||
| self._raise_type_error(data.dtype) | |||
| else: | |||
| if isinstance(data, Tensor) and data.init is not None: | |||
| data.init_data() | |||
| data = F.cast(data, self.dtype) | |||
| if isinstance(data, Tensor) and data.has_init: | |||
| # The parameter has been initialized, directly update by the data | |||
| if current_tensor_is_init: | |||
| self._update_tensor_data(data.init_data()) | |||
| else: | |||
| # also update the related inited parameter data | |||
| if self.inited_param is not None: | |||
| self.inited_param.set_data(data) | |||
| self.init_mode = data | |||
| elif incoming_tensor_is_init or current_tensor_is_init: | |||
| self._update_tensor_data(data) | |||
| self.sliced = slice_shape | |||
| return self | |||
| @staticmethod | |||
| def _get_init_data_args(layout=None): | |||
| """Get the data layout args.""" | |||
| init_data_args = () | |||
| if layout: | |||
| if not isinstance(layout, tuple): | |||
| raise TypeError("The argument 'layout' should be tuple, but got {}.".format(type(layout))) | |||
| if len(layout) < 6: | |||
| raise ValueError("The length of 'layout' must be larger than 5, but got {}.".format(len(layout))) | |||
| slice_index = int(_get_slice_index(layout[0], layout[1])) | |||
| init_data_args += (slice_index, layout[2], layout[5]) | |||
| return init_data_args | |||
| def init_data(self, layout=None, set_sliced=False): | |||
| """ | |||
| Initialize the parameter's data. | |||
| Args: | |||
| layout (Union[None, tuple]): The parameter's layout info. | |||
| layout [dev_mat, tensor_map, slice_shape, filed_size, uniform_split, opt_shard_group]. Default: None. | |||
| It's not None only in 'SEMI_AUTO_PARALLEL' or 'AUTO_PARALLEL' mode. | |||
| - dev_mat (list(int)): The parameter's device matrix. | |||
| - tensor_map (list(int)): The parameter's tensor map. | |||
| - slice_shape (list(int)): The parameter's slice shape. | |||
| - filed_size (int): The parameter's filed size. | |||
| - uniform_split (bool): Whether the parameter is split evenly. | |||
| - opt_shard_group (str): The group of the parameter while running optimizer parallel. | |||
| set_sliced (bool): True if the parameter is set sliced after initializing the data. | |||
| Default: False. | |||
| Raises: | |||
| RuntimeError: If it is from Initializer, and parallel mode has changed after the Initializer created. | |||
| ValueError: If the length of the layout is less than 6. | |||
| TypeError: If `layout` is not tuple. | |||
| Returns: | |||
| Parameter, the `Parameter` after initializing data. If current `Parameter` was already initialized before, | |||
| returns the same initialized `Parameter`. | |||
| """ | |||
| if self.is_default_input_init and self.is_in_parallel != _is_in_parallel_mode(): | |||
| raise RuntimeError("Must set or change parallel mode before any Tensor created.") | |||
| if self.init_mode is None: | |||
| return self | |||
| if self.inited_param is not None: | |||
| return self.inited_param | |||
| if _is_role_worker() and self.cache_enable: | |||
| global_seed, op_seed = _get_global_and_op_seed() | |||
| _insert_weight_init_info(self.name, global_seed, op_seed) | |||
| init_data_args = self._get_init_data_args(layout) | |||
| if self.init_in_server and self.is_param_ps and isinstance(self.init_mode, Tensor) and \ | |||
| self.init_mode.init is not None and (_is_role_worker() or _is_role_sched()): | |||
| if self.cache_enable: | |||
| data = self.init_mode.init_data(*init_data_args) | |||
| else: | |||
| data = self.init_mode.init_data(0, [1]) | |||
| else: | |||
| data = self.init_mode.init_data(*init_data_args) | |||
| obj = self._update_tensor_data(data) | |||
| if id(obj) != id(self): | |||
| self._inited_param = obj | |||
| obj.init_mode = None | |||
| obj.sliced = set_sliced | |||
| return obj | |||
| def requires_grad_(self, requires_grad=True): | |||
| self.requires_grad = requires_grad | |||
| class ParameterTuple(tuple): | |||
| """ | |||
| Inherited from tuple, ParameterTuple is used to save multiple parameter. | |||
| Note: | |||
| It is used to store the parameters of the network into the parameter tuple collection. | |||
| """ | |||
| def __new__(cls, iterable): | |||
| """Create instance object of ParameterTuple.""" | |||
| data = tuple(iterable) | |||
| ids = set() | |||
| names = set() | |||
| for x in data: | |||
| if not isinstance(x, Parameter): | |||
| raise TypeError(f"For ParameterTuple initialization, " | |||
| f"ParameterTuple input should be 'Parameter' collection, " | |||
| f"but got a {type(iterable)}. ") | |||
| if id(x) not in ids: | |||
| if x.name in names: | |||
| raise ValueError("The value {} , its name '{}' already exists. " | |||
| "Please set a unique name for the parameter.".format(x, x.name)) | |||
| names.add(x.name) | |||
| ids.add(id(x)) | |||
| return tuple.__new__(ParameterTuple, tuple(data)) | |||
| def clone(self, prefix, init='same'): | |||
| """ | |||
| Clone the parameters in ParameterTuple element-wisely to generate a new ParameterTuple. | |||
| Args: | |||
| prefix (str): Namespace of parameter, the prefix string will be added to the names of parameters | |||
| in parametertuple. | |||
| init (Union[Tensor, str, numbers.Number]): Clone the shape and dtype of Parameters in ParameterTuple and | |||
| set data according to `init`. Default: 'same'. | |||
| If `init` is a `Tensor` , set the new Parameter data to the input Tensor. | |||
| If `init` is `numbers.Number` , set the new Parameter data to the input number. | |||
| If `init` is a `str`, data will be seted according to the initialization method of the same name in | |||
| the `Initializer`. | |||
| If `init` is 'same', the new Parameter has the same value with the original Parameter. | |||
| Returns: | |||
| Tuple, the new Parameter tuple. | |||
| """ | |||
| Validator.check_str_by_regular(prefix) | |||
| new = [] | |||
| for x in self: | |||
| x1 = x.clone(init) | |||
| x1.name = prefix + "." + x1.name | |||
| new.append(x1) | |||
| if not x1.cache_enable: | |||
| continue | |||
| if _is_role_worker(): | |||
| _clone_hash_table(x.name, x.key, x1.name, x1.key) | |||
| _insert_accumu_init_info(x1.name, init_to_value(init)) | |||
| return ParameterTuple(new) | |||
| def __parameter_tuple__(self): | |||
| """For parse check.""" | |||
+ 0
- 1871
ms_adapter/pytorch/tensor.py
View File
| @@ -1,1871 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import warnings | |||
| import copy | |||
| import numpy as np | |||
| import mindspore as ms | |||
| from mindspore.common import dtype as mstype | |||
| from mindspore.common._register_for_tensor import tensor_operator_registry | |||
| from mindspore.ops._primitive_cache import _get_cache_prim | |||
| import mindspore.ops as P | |||
| from mindspore.ops import constexpr | |||
| from mindspore.common.initializer import _init_random_normal, _init_random_uniform | |||
| from mindspore.common.initializer import Zero | |||
| from mindspore._c_expression import Tensor as Tensor_ | |||
| from ms_adapter.utils import unsupported_attr, pynative_mode_condition, is_under_gpu_context, get_backend, \ | |||
| is_under_ascend_context | |||
| import ms_adapter.pytorch.common.dtype as msdapter_dtype | |||
| _dtypeDict = { | |||
| 'float16': mstype.float16, | |||
| 'float32': mstype.float32, | |||
| 'float64': mstype.float64, | |||
| 'int8': mstype.int8, | |||
| 'int16': mstype.int16, | |||
| 'int32': mstype.int32, | |||
| 'int64': mstype.int64, | |||
| 'uint8': mstype.uint8, | |||
| 'uint16': mstype.uint16, | |||
| 'uint32': mstype.uint32, | |||
| 'uint64': mstype.uint64, | |||
| 'bool': mstype.bool_, | |||
| 'complex64': mstype.complex64, | |||
| 'complex128': mstype.complex128, | |||
| 'long': mstype.int64, | |||
| 'half': mstype.float16, | |||
| 'int': mstype.int32, | |||
| 'double': mstype.float64, | |||
| 'float': mstype.float32, | |||
| 'char': mstype.int8, | |||
| 'byte': mstype.uint8, | |||
| 'short': mstype.int16 | |||
| } | |||
| kMaxInt8 = 2 ** 7 - 1 | |||
| kMaxInt16 = 2 ** 15 - 1 | |||
| kMaxInt32 = 2 ** 31 - 1 | |||
| kMaxInt64 = 2 ** 63 - 1 | |||
| kMaxUint8 = 2 ** 8 - 1 | |||
| kMaxUint16 = 2 ** 16 - 1 | |||
| kMaxUint32 = 2 ** 32 - 1 | |||
| kMaxUint64 = 2 ** 64 - 1 | |||
| kMantissaFloat16 = 2 ** 11 | |||
| kMantissaFloat32 = 2 ** 24 | |||
| kMantissaFloat64 = 2 ** 53 | |||
| _dtype2typeDict = { | |||
| 'float32': 'FloatTensor', | |||
| 'float': 'FloatTensor', | |||
| 'float64': 'DoubleTensor', | |||
| 'double': 'DoubleTensor', | |||
| 'complex64': 'ComplexFloatTensor', | |||
| 'cfloat': 'ComplexFloatTensor', | |||
| 'complex128': 'ComplexDoubleTensor', | |||
| 'cdouble': 'ComplexDoubleTensor', | |||
| 'float16': 'HalfTensor', | |||
| 'half': 'HalfTensor', | |||
| 'bfloat16': 'BFloat16Tensor', | |||
| 'uint8': 'ByteTensor', | |||
| 'int8': 'CharTensor', | |||
| 'int16': 'ShortTensor', | |||
| 'short': 'ShortTensor', | |||
| 'int32': 'IntTensor', | |||
| 'int': 'IntTensor', | |||
| 'int64': 'LongTensor', | |||
| 'long': 'LongTensor', | |||
| 'bool': 'BoolTensor' | |||
| } | |||
| _type2dtypeDict = { | |||
| 'FloatTensor': msdapter_dtype.float32, | |||
| 'DoubleTensor': msdapter_dtype.float64, | |||
| 'ComplexFloatTensor': msdapter_dtype.complex64, | |||
| 'ComplexDoubleTensor': msdapter_dtype.complex128, | |||
| 'HalfTensor': msdapter_dtype.float16, | |||
| 'BFloat16Tensor': msdapter_dtype.bfloat16, | |||
| 'ByteTensor': msdapter_dtype.uint8, | |||
| 'CharTensor' : msdapter_dtype.int8, | |||
| 'ShortTensor': msdapter_dtype.int16, | |||
| 'IntTensor': msdapter_dtype.int32, | |||
| 'LongTensor': msdapter_dtype.int64, | |||
| 'BoolTensor': msdapter_dtype.bool | |||
| } | |||
| class Tensor(ms.Tensor): | |||
| def __init__(self, *data, dtype=None, inner=False): | |||
| def _process_data(data): | |||
| _shape = None | |||
| _input_data = None | |||
| if len(data) == 1: | |||
| if isinstance(data[0], int): | |||
| _shape = data | |||
| elif isinstance(data[0], (np.ndarray, ms.Tensor, list)): | |||
| _input_data = data[0] | |||
| elif isinstance(data[0], tuple): | |||
| if len(data[0]) == 1: | |||
| _shape = data[0] | |||
| else: | |||
| _input_data = data[0] | |||
| else: | |||
| raise TypeError(f"For Tensor, data must be a sequence, got {type(data[0])}") | |||
| elif len(data) > 1: | |||
| if not isinstance(data[0], int): | |||
| raise TypeError("For Tensor, elements of shape must be int.") | |||
| _shape = data | |||
| else: | |||
| _input_data = () | |||
| return _input_data, _shape | |||
| if dtype is not None: | |||
| dtype = _dtypeDict[str(dtype).split('.')[-1].lower()] | |||
| if inner is True: | |||
| super(Tensor, self).__init__(*data, dtype=dtype) | |||
| else: | |||
| _input_data, _shape = _process_data(data) | |||
| if _shape: | |||
| if dtype is None: | |||
| dtype = mstype.float32 | |||
| super(Tensor, self).__init__(shape=_shape, dtype=dtype, init=Zero()) | |||
| self.init_data() | |||
| else: | |||
| if dtype is None: | |||
| if not isinstance(_input_data, ms.Tensor): | |||
| dtype=mstype.float32 | |||
| super(Tensor, self).__init__(input_data=_input_data, dtype=dtype) | |||
| def __neg__(self): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| out = tensor_ms.__neg__() | |||
| return cast_to_adapter_tensor(out) | |||
| def __invert__(self): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| if tensor_ms.dtype != ms.bool_: | |||
| out = - 1 - tensor_ms | |||
| else: | |||
| out = tensor_ms.__invert__() | |||
| return cast_to_adapter_tensor(out) | |||
| def __round__(self): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| out = tensor_ms.__round__() | |||
| return cast_to_adapter_tensor(out) | |||
| def __pos__(self): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| out = tensor_ms.__pos__() | |||
| return cast_to_adapter_tensor(out) | |||
| def __abs__(self): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| out = tensor_ms.__abs__() | |||
| return cast_to_adapter_tensor(out) | |||
| def __add__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__add__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __and__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__and__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __xor__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__xor__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __or__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__or__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __radd__(self, other): | |||
| return self.__add__(other) | |||
| def __iadd__(self, other): | |||
| return self.__add__(other) | |||
| def __sub__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__sub__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __rsub__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__rsub__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __isub__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__isub__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __mul__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__mul__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __rmul__(self, other): | |||
| return self.__mul__(other) | |||
| def __imul__(self, other): | |||
| return self.__mul__(other) | |||
| def __truediv__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__truediv__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __rtruediv__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__rtruediv__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __mod__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__mod__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __rmod__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__rmod__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __imod__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__imod__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __pow__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__pow__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __rpow__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__rpow__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __floordiv__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__floordiv__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __rfloordiv__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__rfloordiv__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __ifloordiv__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__ifloordiv__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __lt__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__lt__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __le__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__le__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __gt__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__gt__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __ge__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__ge__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __eq__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__eq__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __hash__(self): | |||
| return hash(id(self)) | |||
| def __ne__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__ne__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| # __setitem__ no need to overload | |||
| def _getitem_handler(self, index): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| if isinstance(index, bool): | |||
| if index: | |||
| return tensor_ms.expand_dims(0) | |||
| else: | |||
| index = ms.Tensor(False) | |||
| out = ms.ops.masked_select(tensor_ms, index) | |||
| return out | |||
| if isinstance(index, tuple) and isinstance(index[0], bool): | |||
| if False in index: | |||
| index = ms.Tensor(False) | |||
| out = ms.ops.masked_select(tensor_ms, index) | |||
| return out | |||
| else: | |||
| return tensor_ms.expand_dims(0) | |||
| if isinstance(index, ms.Tensor) and index.dtype == ms.bool_: | |||
| ms_shape_len = len(tensor_ms.shape) | |||
| index_shape_len = len(index.shape) | |||
| out_shape = [-1] | |||
| while index_shape_len < ms_shape_len: | |||
| out_shape.append(tensor_ms.shape[index_shape_len]) | |||
| index = index.expand_dims(-1) | |||
| index_shape_len += 1 | |||
| out = ms.ops.masked_select(tensor_ms, index) | |||
| if len(out_shape) > 1: | |||
| out = out.reshape(out_shape) | |||
| else: | |||
| out = tensor_ms.__getitem__(index) | |||
| return out | |||
| def __getitem__(self, index): | |||
| out = cast_to_adapter_tensor(self._getitem_handler(index)) | |||
| if out is not self: | |||
| out.parent_tensor_ = self | |||
| out.index_of_parent_ = index | |||
| return out | |||
| def __getstate__(self): | |||
| pickled = {"input_data": self.asnumpy(), "dtype": self.dtype, "const_arg": self.const_arg} | |||
| return pickled | |||
| def __setstate__(self, state): | |||
| self.__init__(state["input_data"], dtype=state["dtype"]) | |||
| def fill_adapter(self, val): | |||
| if not isinstance(val, (int, float, bool)): | |||
| raise TypeError("For 'Tensor.fill', the type of the argument 'value' must be int, float or bool, " | |||
| "but got {}.".format(type(val))) | |||
| output = tensor_operator_registry.get("fill")(self.dtype, self.shape, val) | |||
| return cast_to_adapter_tensor(output) | |||
| def fill_(self, val): | |||
| output = self.fill_adapter(val) | |||
| return _tensor_inplace_assign(self, output, "fill_", "fill_adapter") | |||
| def normal_adapter(self, mean=0, std=1, *, generator=None): | |||
| if generator is not None: | |||
| raise ValueError("`generator` can not be supportted.") | |||
| output = ms.Tensor(_init_random_normal(mean, std, self.shape), ms.float32) | |||
| return cast_to_adapter_tensor(output) | |||
| def normal_(self, mean=0, std=1, *, generator=None): | |||
| output = self.normal_adapter(mean, std, generator=generator) | |||
| return _tensor_inplace_assign(self, output, "normal_", "normal_adapter") | |||
| def size(self, dim=None): | |||
| """ | |||
| tensor.size() has the same function as tensor.size() in PyTorch, | |||
| but different from the tensor.size in MindSpore. | |||
| """ | |||
| if dim is None: | |||
| return self.shape | |||
| return self.shape[dim] | |||
| def uniform_adpater(self, from_alias=0, to=1): #TODO: from_alias->from | |||
| self_dtype = self.dtype | |||
| output = ms.Tensor(_init_random_uniform(from_alias, to, self.shape), self_dtype) | |||
| return cast_to_adapter_tensor(output) | |||
| def uniform_(self, from_alias=0, to=1): | |||
| output = self.uniform_adpater(from_alias, to) | |||
| return _tensor_inplace_assign(self, output, "uniform_", "uniform_adpater") | |||
| def random_adapter(self, from_alias=0, to=None, *, generator=None): #TODO: from_alias->from | |||
| unsupported_attr(generator) | |||
| if generator: | |||
| raise NotImplementedError("generator is not supported.") | |||
| self_dtype = self.dtype | |||
| if not to: | |||
| if self_dtype == ms.float64: | |||
| return self.uniform_adpater(from_alias, kMantissaFloat64) | |||
| elif self_dtype == ms.float32: | |||
| return self.uniform_adpater(from_alias, kMantissaFloat32) | |||
| elif self_dtype == ms.float16: | |||
| return self.uniform_adpater(from_alias, kMantissaFloat16) | |||
| elif self_dtype == ms.uint64: | |||
| return self.uniform_adpater(from_alias, kMaxUint64) | |||
| elif self_dtype == ms.uint32: | |||
| return self.uniform_adpater(from_alias, kMaxUint32) | |||
| elif self_dtype == ms.uint16: | |||
| return self.uniform_adpater(from_alias, kMaxUint16) | |||
| elif self_dtype == ms.uint8: | |||
| return self.uniform_adpater(from_alias, kMaxUint8) | |||
| elif self_dtype == ms.int64: | |||
| return self.uniform_adpater(from_alias, kMaxInt64) | |||
| elif self_dtype == ms.int32: | |||
| return self.uniform_adpater(from_alias, kMaxInt32) | |||
| elif self_dtype == ms.int16: | |||
| return self.uniform_adpater(from_alias, kMaxInt16) | |||
| elif self_dtype == ms.int8: | |||
| return self.uniform_adpater(from_alias, kMaxInt8) | |||
| return self.uniform_adpater(from_alias, to) | |||
| def random_(self, from_alias=0, to=None, *, generator=None): | |||
| output = self.random_adapter(from_alias, to, generator=generator) | |||
| return _tensor_inplace_assign(self, output, "random_", "random_adapter") | |||
| def zero_adapter(self): | |||
| output = tensor_operator_registry.get("fill")(self.dtype, self.shape, 0.0) | |||
| return cast_to_adapter_tensor(output) | |||
| def zero_(self): | |||
| output = self.zero_adapter() | |||
| return _tensor_inplace_assign(self, output, "zero_", "zero_adapter") | |||
| def new_zeros(self, size, *, dtype=None, device=None, requires_grad=False, layout=None, pin_memory=False): | |||
| unsupported_attr(device) | |||
| unsupported_attr(requires_grad) | |||
| unsupported_attr(layout) | |||
| if layout: | |||
| raise NotImplementedError("layout is not supported.") | |||
| unsupported_attr(pin_memory) | |||
| if pin_memory is True: | |||
| raise NotImplementedError("pin_memory is not supported to True.") | |||
| output = tensor_operator_registry.get("fill")(dtype, size, 0.0) | |||
| return cast_to_adapter_tensor(output) | |||
| def add(self, other, *, alpha=1): | |||
| input = cast_to_ms_tensor(self) | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.add(input, other*alpha) | |||
| return cast_to_adapter_tensor(output) | |||
| def add_(self, other, *, alpha=1): | |||
| output = self.add(other, alpha=alpha) | |||
| return _tensor_inplace_assign(self, output, "add_", "add") | |||
| def erfinv(self): | |||
| input = cast_to_ms_tensor(self) | |||
| output = ms.ops.erfinv(input) | |||
| return cast_to_adapter_tensor(output) | |||
| def erfinv_(self): | |||
| output = self.erfinv() | |||
| return _tensor_inplace_assign(self, output, "erfinv_", "erfinv") | |||
| def permute(self, *dims): | |||
| ms_input = cast_to_ms_tensor(self) | |||
| output = ms_input.transpose(*dims) | |||
| return cast_to_adapter_tensor(output) | |||
| def contiguous(self, memory_format=None): | |||
| #TODO | |||
| unsupported_attr(memory_format) | |||
| return self | |||
| def new_tensor(self, data, *, dtype=None, device=None, requires_grad=False, layout=None, pin_memory=False): | |||
| unsupported_attr(device) | |||
| unsupported_attr(requires_grad) | |||
| unsupported_attr(layout) | |||
| unsupported_attr(pin_memory) | |||
| if isinstance(data, Tensor): | |||
| raise ValueError("To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() " | |||
| "or sourceTensor.clone().detach().requires_grad_(True), " | |||
| "rather than tensor.new_tensor(sourceTensor).") | |||
| return tensor(data, dtype) | |||
| def copy_(self, src, non_blocking=False): | |||
| unsupported_attr(non_blocking) | |||
| input_ms = cast_to_ms_tensor(src) | |||
| output = ms.ops.broadcast_to(input_ms, self.shape) | |||
| output = output.astype(self.dtype) | |||
| return _tensor_inplace_assign(self, output, "copy_", "new_tensor") | |||
| def expand(self, *size): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| if isinstance(size[0], (list, tuple)): | |||
| size = size[0] | |||
| out = ms.ops.broadcast_to(input_ms, size) | |||
| return cast_to_adapter_tensor(out) | |||
| def sigmoid(self): | |||
| input = cast_to_ms_tensor(self) | |||
| output = P.Sigmoid()(input) | |||
| return cast_to_adapter_tensor(output) | |||
| def sigmoid_(self): | |||
| output = self.sigmoid() | |||
| return _tensor_inplace_assign(self, output, "sigmoid_", "sigmoid") | |||
| def float(self, memory_format=None): | |||
| unsupported_attr(memory_format) | |||
| if memory_format: | |||
| raise NotImplementedError("memory_format is not supported.") | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.float()) | |||
| def flip(self, dims): # TODO ms.numpy.flip -> Tensor.flip | |||
| input_ms = cast_to_ms_tensor(self) | |||
| output = ms.numpy.flip(input_ms, dims) | |||
| return cast_to_adapter_tensor(output) | |||
| def sign(self): | |||
| input = cast_to_ms_tensor(self) | |||
| output = _get_cache_prim(P.Sign)()(input) | |||
| return cast_to_adapter_tensor(output) | |||
| def mul(self, value): | |||
| input = cast_to_ms_tensor(self) | |||
| ms_value = cast_to_ms_tensor(value) | |||
| output = ms.ops.mul(input, ms_value) | |||
| return cast_to_adapter_tensor(output) | |||
| def mul_(self, value): | |||
| output = self.mul(value) | |||
| return _tensor_inplace_assign(self, output, "mul_", "mul") | |||
| def device(self): | |||
| #TODO | |||
| pass | |||
| def div(self, value, *, rounding_mode=None) : | |||
| output = _div_calcu(self, value, rounding_mode) | |||
| return cast_to_adapter_tensor(output) | |||
| def div_(self, value, *, rounding_mode=None): | |||
| output = _div_calcu(self, value, rounding_mode) | |||
| return _tensor_inplace_assign(self, output, "div_", "div") | |||
| def cpu(self): | |||
| #TODO | |||
| return self | |||
| def min(self, dim=None, keepdim=False): | |||
| input = cast_to_ms_tensor(self) | |||
| if dim is None: | |||
| return cast_to_adapter_tensor(input.min()) | |||
| #TODO | |||
| # Until now, P.min do not support when `input` is type of `int32`, `int64``. | |||
| if self.dtype == mstype.int64 or self.dtype == mstype.int32: | |||
| if self.dtype == mstype.int64: | |||
| dtype_name = 'torch.int64' | |||
| else: | |||
| dtype_name = 'torch.int32' | |||
| raise TypeError("For 'Tensor.min', the type of `input` do not support `torch.int64` and " | |||
| "`torch.int32`, got {}.".format(dtype_name)) | |||
| indices, result = P.min(input, axis=dim, keep_dims=keepdim) | |||
| return cast_to_adapter_tensor(result), cast_to_adapter_tensor(indices) | |||
| def max(self, dim=None, keepdim=False): | |||
| input = cast_to_ms_tensor(self) | |||
| if dim is None: | |||
| return cast_to_adapter_tensor(input.max()) | |||
| # TODO: Until now, P.max do not support when `input` is type of `int32`, `int64``. | |||
| if self.dtype == mstype.int64 or self.dtype == mstype.int32: | |||
| if self.dtype == mstype.int64: | |||
| dtype_name = 'torch.int64' | |||
| else: | |||
| dtype_name = 'torch.int32' | |||
| raise TypeError("For 'Tensor.max', the type of `input` do not support `torch.int64` and " | |||
| "`torch.int32`, got {}.".format(dtype_name)) | |||
| indices, result = P.max(input, axis=dim, keep_dims=keepdim) | |||
| return cast_to_adapter_tensor(result), cast_to_adapter_tensor(indices) | |||
| def numel(self): | |||
| input = cast_to_ms_tensor(self) | |||
| return P.size(input) | |||
| def detach(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| output = ms.ops.stop_gradient(input_ms) | |||
| return cast_to_adapter_tensor(output) | |||
| def sum(self, dim=None, keepdim=False, dtype=None): | |||
| input = cast_to_ms_tensor(self) | |||
| if not dtype and self.dtype in (mstype.uint8, mstype.uint16, mstype.uint32, | |||
| mstype.int8, mstype.int16, mstype.int32): | |||
| dtype = mstype.int64 | |||
| input = input.astype(dtype) | |||
| return cast_to_adapter_tensor(input.sum(axis=dim, dtype=dtype, keepdims=keepdim)) | |||
| def mean(self, dim=None, keepdim=False, dtype=None): | |||
| if dim is None: | |||
| axis = () | |||
| else: | |||
| axis = dim | |||
| input = cast_to_adapter_tensor(self) | |||
| if dtype: | |||
| input = self.astype(dtype) | |||
| output = ms.ops.mean(input, axis, keepdim) | |||
| return cast_to_adapter_tensor(output) | |||
| def prod(self, dim=None, keepdim=False, dtype=None): | |||
| if dim is None: | |||
| axis = () | |||
| else: | |||
| axis = dim | |||
| input = cast_to_adapter_tensor(self) | |||
| if dtype: | |||
| input = self.astype(dtype) | |||
| output = ms.ops.prod(input, axis, keepdim) | |||
| return cast_to_adapter_tensor(output) | |||
| def split(self, split_size, dim=0): | |||
| tensor = cast_to_ms_tensor(self) | |||
| tensor_shape = list(tensor.shape) | |||
| length_along_dim = tensor_shape[dim] | |||
| dims = tensor.ndim | |||
| if isinstance(split_size, int): | |||
| if split_size > length_along_dim: | |||
| return cast_to_adapter_tensor(tensor) | |||
| if length_along_dim % split_size == 0: | |||
| output_num = int(length_along_dim / split_size) | |||
| output = ms.ops.split(tensor, axis=dim, output_num=output_num) | |||
| else: | |||
| num_short_tensor = int(length_along_dim % split_size) | |||
| length1 = split_size * (length_along_dim // split_size) | |||
| length2 = num_short_tensor | |||
| start1 = [0, ] * dims | |||
| size1 = copy.deepcopy(tensor_shape) | |||
| size1[dim] = length1 | |||
| start2 = [0, ] * dims | |||
| start2[dim] = length1 | |||
| size2 = copy.deepcopy(tensor_shape) | |||
| size2[dim] = length2 | |||
| tensor1 = ms.ops.slice(tensor, begin=start1, size=size1) | |||
| tensor2 = ms.ops.slice(tensor, begin=start2, size=size2) | |||
| output_num = int(length_along_dim / split_size) | |||
| output = list(ms.ops.split(tensor1, axis=dim, output_num=output_num)) | |||
| output.append(tensor2) | |||
| elif isinstance(split_size, (list, tuple)): | |||
| sum = 0 | |||
| for i in split_size: | |||
| sum += i | |||
| if sum != tensor_shape[dim]: | |||
| raise ValueError("split_with_sizes expects split_sizes to sum exactly to {} " | |||
| "(input tensor's size at dimension {}), " | |||
| "but got split_sizes={}".format(tensor_shape[dim], dim, split_size)) | |||
| output = [] | |||
| cur = 0 | |||
| for i in split_size: | |||
| start = [0, ] * dims | |||
| start[dim] = cur | |||
| size = tensor_shape | |||
| size[dim] = i | |||
| res = ms.ops.slice(tensor, begin=start, size=size) | |||
| cur += i | |||
| output.append(res) | |||
| else: | |||
| raise ValueError("Argument `split_size_or_sections` should be be integer, " | |||
| "tuple(int) or list(int), but got {}.".format(split_size)) | |||
| res = [] | |||
| for i in output: | |||
| res.append(cast_to_adapter_tensor(i)) | |||
| return res | |||
| def numpy(self): | |||
| return self.asnumpy() | |||
| def view(self, *shape): | |||
| self._init_check() | |||
| if not shape: | |||
| raise ValueError("The shape variable should not be empty") | |||
| if isinstance(shape[0], (tuple, list)): | |||
| if len(shape) != 1: | |||
| raise ValueError(f"Only one tuple is needed, but got {shape}") | |||
| shape = shape[0] | |||
| if isinstance(shape, list): | |||
| shape = tuple(shape) | |||
| input = cast_to_ms_tensor(self) | |||
| output = tensor_operator_registry.get('reshape')()(input, shape) | |||
| return cast_to_adapter_tensor(output) | |||
| def ndimension(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return input_ms.ndimension() | |||
| def pow(self, exponent): | |||
| power = cast_to_ms_tensor(exponent) | |||
| input_ms = cast_to_ms_tensor(self) | |||
| output = input_ms.pow(power) | |||
| return cast_to_adapter_tensor(output) | |||
| def repeat(self, *sizes): | |||
| input_x = cast_to_ms_tensor(self) | |||
| if isinstance(sizes[0], (tuple, list)): | |||
| output = ms.ops.tile(input_x, *sizes) | |||
| else: | |||
| output = ms.ops.tile(input_x, sizes) | |||
| return cast_to_adapter_tensor(output) | |||
| def repeat_interleave(self, repeats, dim=None, *, output_size=None): | |||
| unsupported_attr(output_size) | |||
| if isinstance(repeats, Tensor): | |||
| new_repeats = [] | |||
| for index in repeats: | |||
| new_repeats.append(int(index)) | |||
| repeats = new_repeats | |||
| input_ms = cast_to_ms_tensor(self) | |||
| output = input_ms.repeat(repeats, dim) | |||
| return cast_to_adapter_tensor(output) | |||
| def reshape(self, *shape): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.reshape(*shape)) | |||
| def reshape_as(self, other): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| other = cast_to_ms_tensor(other) | |||
| return cast_to_adapter_tensor(input_ms.reshape_as(other)) | |||
| def arcsinh(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.arcsinh()) | |||
| def arctanh(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.arctanh()) | |||
| def det(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.det()) | |||
| def negative(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.negative()) | |||
| def negative_(self): | |||
| output = self.negative() | |||
| return _tensor_inplace_assign(self, output, "negative_", "negative") | |||
| def abs(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.abs()) | |||
| def abs_(self): | |||
| output = self.abs() | |||
| return _tensor_inplace_assign(self, output, "abs_", "abs") | |||
| @property | |||
| def ndim(self): | |||
| return len(self.shape) | |||
| def amax(self, dim=None, keepdim=False): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| if dim is not None: | |||
| return cast_to_adapter_tensor(input_ms.amax(axis=dim, keep_dims=keepdim)) | |||
| return cast_to_adapter_tensor(input_ms.amax(keep_dims=keepdim)) | |||
| def amin(self, dim=None, keepdim=False): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| if dim is not None: | |||
| return cast_to_adapter_tensor(input_ms.amin(axis=dim, keep_dims=keepdim)) | |||
| return cast_to_adapter_tensor(input_ms.amin(keep_dims=keepdim)) | |||
| def as_strided(self, size, stride, storage_offset=None): | |||
| warnings.warn("not support output as a view.") | |||
| input_ms = cast_to_ms_tensor(self) | |||
| if len(size) != len(stride): | |||
| raise RuntimeError("mismatch in length of strides and shape.") | |||
| index = np.arange(0, size[0]*stride[0], stride[0]) | |||
| for i in range(1, len(size)): | |||
| tmp = np.arange(0, size[i]*stride[i], stride[i]) | |||
| index = np.expand_dims(index, -1) | |||
| index = index + tmp | |||
| if storage_offset is not None: | |||
| index = index + storage_offset | |||
| input_indices = ms.Tensor(index) | |||
| out = ms.ops.gather(input_ms.reshape(-1), input_indices, 0) | |||
| return cast_to_adapter_tensor(out) | |||
| def bmm(self, batch2): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.bmm(batch2)) | |||
| def clamp(self, min=None, max=None): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| type = input_ms.dtype | |||
| if min is not None and max is not None and min > max: | |||
| output = ms.ops.ones_like(input_ms).astype(type)*max | |||
| else: | |||
| if min is not None: | |||
| min = ms.Tensor(min, type) | |||
| if max is not None: | |||
| max = ms.Tensor(max, type) | |||
| output = ms.ops.clip_by_value(input_ms, min, max) | |||
| return cast_to_adapter_tensor(output) | |||
| def clamp_(self, min=None, max=None): | |||
| output = self.clamp(min, max) | |||
| return _tensor_inplace_assign(self, output, "clamp_", "clamp") | |||
| def dim(self): | |||
| return len(self.shape) | |||
| def expand_as(self, other): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| output = input_ms.expand_as(other) | |||
| return cast_to_adapter_tensor(output) | |||
| def item(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| if input_ms.size > 1: | |||
| raise ValueError("only one element tensors can be converted to Python scalars") | |||
| output = input_ms.reshape(-1).asnumpy().tolist() | |||
| return output[0] | |||
| def log(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| output = input_ms.log() | |||
| return cast_to_adapter_tensor(output) | |||
| def log2(self): | |||
| input = cast_to_ms_tensor(self) | |||
| output = ms.ops.log2(input) | |||
| return cast_to_adapter_tensor(output) | |||
| def matmul(self, tensor2): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| tensor2_ms = cast_to_ms_tensor(tensor2) | |||
| output = ms.ops.matmul(input_ms, tensor2_ms) | |||
| return cast_to_adapter_tensor(output) | |||
| def squeeze(self, dim=None): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| if dim is not None: | |||
| if input_ms.shape[dim] != 1: | |||
| output = input_ms | |||
| else: | |||
| output = ms.ops.squeeze(input_ms, dim) | |||
| else: | |||
| output = ms.ops.squeeze(input_ms) | |||
| return cast_to_adapter_tensor(output) | |||
| def squeeze_(self, dim=None): | |||
| output = self.squeeze(dim) | |||
| return _tensor_inplace_assign(self, output, "squeeze_", "squeeze") | |||
| def stride(self, dim=None): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| bytelen = input_ms.nbytes//input_ms.size | |||
| output = list(input_ms.strides) | |||
| for i in range(len(output)): | |||
| output[i] = output[i]//bytelen | |||
| output = tuple(output) | |||
| if dim is not None: | |||
| output = output[dim] | |||
| return output | |||
| def sub(self, other, *, alpha=1): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| input_other = cast_to_ms_tensor(other) * alpha | |||
| output = ms.ops.sub(input_ms, input_other) | |||
| return cast_to_adapter_tensor(output) | |||
| def sub_(self, other, *, alpha=1): | |||
| output = self.sub(other, alpha=alpha) | |||
| return _tensor_inplace_assign(self, output, "sub_", "sub") | |||
| # TODO: delete it, apply ms.Tensor.is_floating_point | |||
| def is_floating_point(self): | |||
| return self._dtype in (mstype.float16, mstype.float32, mstype.float64) | |||
| def unbind(self, dim=0): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.unbind(dim)) | |||
| def unsqueeze(self, dim): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.unsqueeze(dim)) | |||
| def unsqueeze_(self, dim): | |||
| output = self.unsqueeze(dim) | |||
| return _tensor_inplace_assign(self, output, "unsqueeze_", "unsqueeze") | |||
| def is_signed(self): | |||
| # input_ms = cast_to_ms_tensor(self) | |||
| # return input_ms.is_signed() #TODO mindspore 11/17 2.0nightly supported | |||
| pass | |||
| def transpose(self, dim0, dim1): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| dims = list(range(input_ms.ndim)) | |||
| dims[dim0], dims[dim1] = dim1, dim0 | |||
| output = input_ms.transpose(dims) | |||
| return cast_to_adapter_tensor(output) | |||
| def transpose_(self, dim0, dim1): | |||
| output = self.transpose(dim0, dim1) | |||
| return _tensor_inplace_assign(self, output, "transpose_", "transpose") | |||
| def floor(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| output = input_ms.floor() | |||
| return cast_to_adapter_tensor(output) | |||
| def floor_(self): | |||
| output = self.floor() | |||
| return _tensor_inplace_assign(self, output, "floor_", "floor") | |||
| def isfinite(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| output = ms.ops.isfinite(input_ms) | |||
| return cast_to_adapter_tensor(output) | |||
| def isnan(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.isnan()) | |||
| def clone(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.copy()) | |||
| def to(self, *args, **kwargs): | |||
| # TODO: | |||
| # Note that this API requires the user to ensure the correctness of the input currently, | |||
| # and only the function of modifying dtype is available. | |||
| if len(args) == 0 and len(kwargs) == 0: | |||
| raise ValueError("Tensor.to is missing inputs, please check.") | |||
| input_ms = cast_to_ms_tensor(self) | |||
| if "dtype" in kwargs: | |||
| set_dtype = kwargs.get("dtype") | |||
| return cast_to_adapter_tensor(input_ms.astype(set_dtype)) | |||
| elif "other" in kwargs: | |||
| set_dtype = kwargs.get("other")._dtype | |||
| return cast_to_adapter_tensor(input_ms.astype(set_dtype)) | |||
| elif "device" in kwargs: | |||
| return self | |||
| if len(args) == 0: | |||
| raise ValueError("The inputs of Tensor.to is abnormal, please check.") | |||
| if args[0] in _dtypeDict.values(): | |||
| return cast_to_adapter_tensor(input_ms.astype(args[0])) | |||
| elif isinstance(args[0], Tensor): | |||
| set_dtype = args[0]._dtype | |||
| return cast_to_adapter_tensor(input_ms.astype(set_dtype)) | |||
| elif not isinstance(args[0], str): | |||
| raise ValueError("The inputs of Tensor.to is abnormal, please check.") | |||
| if len(args) > 1 and args[1] in _dtypeDict.values(): | |||
| return cast_to_adapter_tensor(input_ms.astype(args[1])) | |||
| return self | |||
| def sort(self, dim=-1, descending=False): | |||
| # TODO: ops.sort() should be replaced. | |||
| input_ms = cast_to_ms_tensor(self) | |||
| input_type = input_ms.dtype | |||
| if 'Int' in str(input_type): | |||
| input_ms = input_ms.astype(ms.float32) | |||
| sort_tensor, sort_index = ms.ops.Sort(dim, descending)(input_ms) | |||
| sort_tensor = sort_tensor.astype(input_type) | |||
| sort_index = sort_index.astype(ms.int64) | |||
| return cast_to_adapter_tensor((sort_tensor, sort_index)) | |||
| else: | |||
| output = _get_cache_prim(ms.ops.Sort)(dim, descending)(input_ms) | |||
| return cast_to_adapter_tensor(output) | |||
| def msort(self): | |||
| # TODO: ops.sort() should be replaced. | |||
| input_ms = cast_to_ms_tensor(self) | |||
| sort_op = _get_cache_prim(ms.ops.Sort)(axis=0) | |||
| input_type = input_ms.dtype | |||
| if 'Int' in str(input_type): | |||
| input_ms = input_ms.astype(ms.float32) | |||
| output, _ = sort_op(input_ms) | |||
| output = output.astype(input_type) | |||
| else: | |||
| output, _ = sort_op(input_ms) | |||
| return cast_to_adapter_tensor(output) | |||
| def argsort(self, dim=-1, descending=False): | |||
| # TODO: ops.sort() should be replaced. | |||
| input_ms = cast_to_ms_tensor(self) | |||
| sort_op = _get_cache_prim(ms.ops.Sort)(dim, descending) | |||
| input_type = input_ms.dtype | |||
| if 'Int' in str(input_type): | |||
| input_ms = input_ms.astype(ms.float32) | |||
| _, output = sort_op(input_ms) | |||
| output = output.astype(ms.int64) | |||
| else: | |||
| _, output = sort_op(input_ms) | |||
| return cast_to_adapter_tensor(output) | |||
| def sqrt(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(ms.ops.sqrt(input_ms)) | |||
| def sqrt_(self): | |||
| output = self.sqrt() | |||
| return _tensor_inplace_assign(self, output, "sqrt_", "sqrt") | |||
| def rsqrt(self): | |||
| input = cast_to_ms_tensor(self) | |||
| if 'Bool' in str(input.dtype) or 'Int' in str(input.dtype): | |||
| input = input.astype(ms.float32) | |||
| output = _get_cache_prim(ms.ops.Rsqrt)()(input) | |||
| return cast_to_adapter_tensor(output) | |||
| def rsqrt_(self): | |||
| output = self.rsqrt() | |||
| return _tensor_inplace_assign(self, output, "rsqrt_", "rsqrt") | |||
| def resize(self, *size, memory_format=None): | |||
| unsupported_attr(memory_format) | |||
| input = cast_to_ms_tensor(self) | |||
| input_size = input.shape | |||
| if len(input_size) == 1 and input_size[0] == 0: | |||
| out = ms.ops.zeros(size, self.dtype) | |||
| else: | |||
| out = input.resize(size) | |||
| return cast_to_adapter_tensor(out) | |||
| def resize_(self, *size, memory_format=None): | |||
| output = self.resize(*size, memory_format=memory_format) | |||
| return _tensor_inplace_assign(self, output, "resize_", "resize") | |||
| def resize_as(self, tensor, memory_format=None): | |||
| unsupported_attr(memory_format) | |||
| if not isinstance(tensor, Tensor): | |||
| raise TypeError("resize_as(): argument 'tensor' must be Tensor.") | |||
| input = cast_to_ms_tensor(self) | |||
| size = tensor.shape | |||
| input_size = input.shape | |||
| if len(input_size) == 1 and input_size[0] == 0: | |||
| out = ms.ops.zeros(size, self.dtype) | |||
| else: | |||
| out = input.resize(size) | |||
| return cast_to_adapter_tensor(out) | |||
| def resize_as_(self, tensor, memory_format=None): | |||
| output = self.resize_as(tensor, memory_format) | |||
| return _tensor_inplace_assign(self, output, "resize_as_", "resize_as") | |||
| def index_fill(self, dim, index, value): | |||
| input = cast_to_ms_tensor(self) | |||
| index = cast_to_ms_tensor(index) | |||
| index = ms.ops.cast(index, mstype.int32) | |||
| if is_under_ascend_context(): | |||
| raise NotImplementedError("for adapter, index_fill not supported on ascend.") | |||
| out = input.index_fill(dim, index, value) | |||
| return cast_to_adapter_tensor(out) | |||
| def index_fill_(self, dim, index, value): | |||
| output = self.index_fill(dim, index, value) | |||
| return _tensor_inplace_assign(self, output, "index_fill_", "index_fill") | |||
| def index_select(self, dim, index): | |||
| _input_params = cast_to_ms_tensor(self) | |||
| _input_indices = cast_to_ms_tensor(index) | |||
| output = ms.ops.gather(_input_params, _input_indices, dim) | |||
| return cast_to_adapter_tensor(output) | |||
| @property | |||
| def data(self): | |||
| return self.detach() | |||
| def new(self, *size): | |||
| return Tensor(*size, dtype=self.dtype) | |||
| def cuda(self, device=None, non_blocking=False, memory_format=None): | |||
| unsupported_attr(device) | |||
| unsupported_attr(non_blocking) | |||
| unsupported_attr(memory_format) | |||
| if not is_under_gpu_context(): | |||
| backend = get_backend() | |||
| warning = f"MsAdater.pytorch.Tensor.cuda() didn't work because it is under {backend} context." | |||
| warnings.warn(warning) | |||
| return self | |||
| def is_cuda(self): | |||
| return is_under_gpu_context() | |||
| def le(self, other): | |||
| input = cast_to_ms_tensor(self) | |||
| if isinstance(other, Tensor): | |||
| other = cast_to_ms_tensor(other) | |||
| out = ms.ops.le(input, other) | |||
| return cast_to_adapter_tensor(out) | |||
| def le_(self, other): | |||
| output = self.le(other) | |||
| return _tensor_inplace_assign(self, output, "le_", "le") | |||
| def t(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| if input_ms.ndim > 2: | |||
| raise ValueError("t() expects a tensor with <= 2 dimensions, but self is {}D".format(input_ms.ndim)) | |||
| dims = list(range(input_ms.ndim)).reverse() | |||
| output = input_ms.transpose(dims) | |||
| return cast_to_adapter_tensor(output) | |||
| @property | |||
| def T(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| if input_ms.ndim <= 2: | |||
| warning = ("The use of Tensor.T() on tensors of dimension other than 2 to reverse " | |||
| "their shape is deprecated and it will throw an error in a future release. ") | |||
| warnings.warn(warning) | |||
| dims = list(range(input_ms.ndim)).reverse() | |||
| output = input_ms.transpose(dims) | |||
| return cast_to_adapter_tensor(output) | |||
| @property | |||
| def requires_grad(self): | |||
| return True | |||
| def requires_grad_(self, requires_grad=True): | |||
| if requires_grad is False: | |||
| warnings.warn("requires_grad is always True in Tensor.") | |||
| def nonzero(self, *, out=None, as_tuple=False): | |||
| if out is not None: | |||
| warnings.warn("Do not support parameter 'out'.") | |||
| input = cast_to_ms_tensor(self) | |||
| output = None | |||
| if as_tuple: | |||
| if input.ndim == 1: | |||
| res = ms.ops.nonzero(input) | |||
| output = (cast_to_adapter_tensor(res.flatten()),) | |||
| elif input.ndim > 1: | |||
| output = [] | |||
| res = ms.ops.nonzero(input) | |||
| res = res.transpose(1, 0) | |||
| res = ms.ops.split(res, axis=0, output_num=input.ndim) | |||
| for cur in res: | |||
| output.append(cast_to_adapter_tensor(cur)) | |||
| output = tuple(output) | |||
| elif input.ndim == 0: | |||
| raise ValueError("Do not support input ndim == 0.") | |||
| return output | |||
| return cast_to_adapter_tensor(ms.ops.nonzero(input)) | |||
| def bool(self, memory_format=None): | |||
| unsupported_attr(memory_format) | |||
| input = cast_to_ms_tensor(self) | |||
| output = input.bool() | |||
| return cast_to_adapter_tensor(output) | |||
| def eq(self, other): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| output = input_ms.equal(other_ms) | |||
| return cast_to_adapter_tensor(output) | |||
| def eq_(self, other): | |||
| output = self.eq(other) | |||
| return _tensor_inplace_assign(self, output, "eq_", "eq") | |||
| def std(self, dim=None, unbiased=True, keepdim=False): | |||
| #TODO: not support float64 or complex input | |||
| input_ms = cast_to_ms_tensor(self) | |||
| type_float64 = False | |||
| if input_ms.dtype == ms.float64: | |||
| input_ms = input_ms.astype(ms.float32) | |||
| type_float64 = True | |||
| # TODO: mindspore.ops.std() not supported GPU, use tensor.std() instead, which means ms.ops.var(). | |||
| if is_under_gpu_context(): | |||
| _dim = dim if dim is not None else () | |||
| _ddof = 1 if unbiased else 0 | |||
| output = input_ms.std(_dim, _ddof, keepdim) | |||
| else: | |||
| if dim is not None: | |||
| output, _ = ms.ops.std(input_ms, dim, unbiased, keepdim) | |||
| else: | |||
| output, _ = ms.ops.std(input_ms, unbiased=unbiased, keep_dims=keepdim) | |||
| if type_float64: | |||
| output = output.astype(ms.float64) | |||
| return cast_to_adapter_tensor(output) | |||
| def exp(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| output = input_ms.exp() | |||
| return cast_to_adapter_tensor(output) | |||
| def masked_fill(self, mask, value): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| output = input_ms.masked_fill(mask, value) | |||
| return cast_to_adapter_tensor(output) | |||
| def masked_fill_(self, mask, value): | |||
| output = self.masked_fill(mask, value) | |||
| return _tensor_inplace_assign(self, output, "masked_fill_", "masked_fill") | |||
| def tolist(self): | |||
| return self.numpy().tolist() | |||
| def bernoulli(self, *, generator=None): | |||
| unsupported_attr(generator) | |||
| if generator: | |||
| raise NotImplementedError("generator is not supported.") | |||
| input_ms = cast_to_ms_tensor(self) | |||
| bernoulli_seed = ms.get_seed() | |||
| if not bernoulli_seed: | |||
| bernoulli_seed = -1 | |||
| return cast_to_adapter_tensor(input_ms.bernoulli(input_ms, bernoulli_seed)) | |||
| def bernoulli_(self, p=0.5, *, generator=None): | |||
| output = self.bernoulli_adapter(p, generator=generator) | |||
| return _tensor_inplace_assign(self, output, "bernoulli_", "bernoulli_adapter") | |||
| def bernoulli_adapter(self, p=0.5, *, generator=None): | |||
| unsupported_attr(generator) | |||
| if generator: | |||
| raise NotImplementedError("generator is not supported.") | |||
| input_ms = cast_to_ms_tensor(self) | |||
| bernoulli_seed = ms.get_seed() | |||
| if not bernoulli_seed: | |||
| bernoulli_seed = -1 | |||
| return cast_to_adapter_tensor(input_ms.bernoulli(p, bernoulli_seed)) | |||
| def round(self, decimals=0): | |||
| input = cast_to_ms_tensor(self) | |||
| if decimals == 0: | |||
| output = ms.ops.round(input) | |||
| else: | |||
| p = 10 ** decimals | |||
| input = input * p | |||
| output = ms.ops.round(input) / p | |||
| return cast_to_adapter_tensor(output) | |||
| def long(self, memory_format=None): | |||
| unsupported_attr(memory_format) | |||
| if memory_format: | |||
| raise NotImplementedError("memory_format is not supported.") | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.astype(_dtypeDict["long"])) | |||
| def half(self, memory_format=None): | |||
| unsupported_attr(memory_format) | |||
| if memory_format: | |||
| raise NotImplementedError("memory_format is not supported.") | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.astype(_dtypeDict["half"])) | |||
| def int(self, memory_format=None): | |||
| unsupported_attr(memory_format) | |||
| if memory_format: | |||
| raise NotImplementedError("memory_format is not supported.") | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.int()) | |||
| def double(self, memory_format=None): | |||
| unsupported_attr(memory_format) | |||
| if memory_format: | |||
| raise NotImplementedError("memory_format is not supported.") | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.astype(_dtypeDict["double"])) | |||
| def char(self, memory_format=None): | |||
| unsupported_attr(memory_format) | |||
| if memory_format: | |||
| raise NotImplementedError("memory_format is not supported.") | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.astype(_dtypeDict["char"])) | |||
| def byte(self, memory_format=None): | |||
| unsupported_attr(memory_format) | |||
| if memory_format: | |||
| raise NotImplementedError("memory_format is not supported.") | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.astype(_dtypeDict["byte"])) | |||
| def short(self, memory_format=None): | |||
| unsupported_attr(memory_format) | |||
| if memory_format: | |||
| raise NotImplementedError("memory_format is not supported.") | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.astype(_dtypeDict["short"])) | |||
| def chunk(self, chunks, dim=0): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| len = input_ms.shape[dim] | |||
| if len<=chunks: | |||
| return cast_to_adapter_tensor(input_ms) | |||
| elif len % chunks == 0: | |||
| output = ms.ops.split(input_ms, dim, chunks) | |||
| return cast_to_adapter_tensor(output) | |||
| else: | |||
| num = len // chunks + 1 | |||
| split_num = len // num | |||
| output1 = ms.ops.narrow(input_ms, dim, 0, num*split_num) | |||
| output1 = ms.ops.split(output1, dim, split_num) | |||
| output2 = ms.ops.narrow(input_ms, dim, num*split_num, len-num*split_num) | |||
| output = list(output1) | |||
| output.append(output2) | |||
| output = tuple(output) | |||
| return cast_to_adapter_tensor(output) | |||
| def flatten(self, start_dim=0, end_dim=-1): | |||
| @constexpr | |||
| def get_dst_shape(): | |||
| self_shape = self.shape | |||
| rank = len(self_shape) | |||
| start = start_dim | |||
| end = end_dim | |||
| if start < 0: | |||
| start += rank | |||
| if end < 0: | |||
| end += rank | |||
| dst_shape = [] | |||
| i = 0 | |||
| while i != start: | |||
| dst_shape.append(self_shape[i]) | |||
| i = i + 1 | |||
| flatten_shape = 1 | |||
| while i <= end: | |||
| flatten_shape = flatten_shape * self_shape[i] | |||
| i = i + 1 | |||
| dst_shape.append(flatten_shape) | |||
| while i < rank: | |||
| dst_shape.append(self_shape[i]) | |||
| i = i + 1 | |||
| return tuple(dst_shape) | |||
| shape = get_dst_shape() | |||
| input_ms = cast_to_ms_tensor(self) | |||
| input_ms.reshape(shape) | |||
| return cast_to_adapter_tensor(input_ms.reshape(shape)) | |||
| def sin(self): | |||
| input = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(ms.ops.sin(input)) | |||
| def sin_(self): | |||
| output = self.sin() | |||
| return _tensor_inplace_assign(self, output, "sin_", "sin") | |||
| def ge(self, other): | |||
| input = cast_to_ms_tensor(self) | |||
| other = cast_to_ms_tensor(other) | |||
| output = input.ge(other) | |||
| return cast_to_adapter_tensor(output) | |||
| def ge_(self, other): | |||
| output = self.ge(other) | |||
| return _tensor_inplace_assign(self, output, "ge_", "ge") | |||
| def cumsum(self, dim, dtype=None): | |||
| input = cast_to_ms_tensor(self) | |||
| output = input.cumsum(axis=dim, dtype=dtype) | |||
| return cast_to_adapter_tensor(output) | |||
| def absolute(self): | |||
| return self.abs() | |||
| def absolute_(self): | |||
| output = self.abs() | |||
| return _tensor_inplace_assign(self, output, "absolute_", "absolute") | |||
| def acos(self): | |||
| input = cast_to_ms_tensor(self) | |||
| output = ms.ops.acos(input) | |||
| return cast_to_adapter_tensor(output) | |||
| def acos_(self): | |||
| output = self.acos() | |||
| return _tensor_inplace_assign(self, output, "acos_", "acos") | |||
| def arccos(self): | |||
| return self.acos() | |||
| def arccos_(self): | |||
| output = self.acos() | |||
| return _tensor_inplace_assign(self, output, "arccos_", "arccos") | |||
| def asinh(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| output = ms.ops.asinh(input_ms) | |||
| return cast_to_adapter_tensor(output) | |||
| def asinh_(self): | |||
| output = self.asinh() | |||
| return _tensor_inplace_assign(self, output, "asinh_", "asinh") | |||
| def atanh(self): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| output = ms.ops.atanh(input_ms) | |||
| return cast_to_adapter_tensor(output) | |||
| def atanh_(self): | |||
| output = self.atanh() | |||
| return _tensor_inplace_assign(self, output, "atanh_", "atanh") | |||
| def addcdiv(self, tensor1, tensor2, *, value=1): | |||
| input = cast_to_ms_tensor(self) | |||
| tensor1 = cast_to_ms_tensor(tensor1) | |||
| tensor2 = cast_to_ms_tensor(tensor2) | |||
| value = ms.Tensor(value) | |||
| output = ms.ops.addcdiv(input, tensor1, tensor2, value) | |||
| return cast_to_adapter_tensor(output) | |||
| def addcdiv_(self, tensor1, tensor2, *, value=1): | |||
| output = self.addcdiv(tensor1, tensor2, value=value) | |||
| return _tensor_inplace_assign(self, output, "addcdiv_", "addcdiv") | |||
| def gather(self, dim, index): | |||
| input = cast_to_ms_tensor(self) | |||
| index = cast_to_ms_tensor(index) | |||
| output = ms.ops.gather_elements(input, dim, index) | |||
| return cast_to_adapter_tensor(output) | |||
| def fmod(self, divisor): | |||
| x = cast_to_ms_tensor(self) | |||
| other = cast_to_ms_tensor(divisor) | |||
| #TODO: repalce with ms.ops.fmod | |||
| if not (isinstance(x, (Tensor, Tensor_)) or isinstance(other, (Tensor, Tensor_))): | |||
| raise TypeError("At least one of the types of inputs must be tensor, " + \ | |||
| f"but the type of 'x' got is {type(x)}, " + \ | |||
| f"and the type of 'other' is {type(other)}.") | |||
| return x - ms.ops.div(x, other, rounding_mode="trunc") * other | |||
| def fmod_(self, divisor): | |||
| output = self.fmod(divisor) | |||
| return _tensor_inplace_assign(self, output, "fmod_", "fmod") | |||
| def lt(self, other): | |||
| input = cast_to_ms_tensor(self) | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.less(input, other) | |||
| return cast_to_adapter_tensor(output) | |||
| def lt_(self, other): | |||
| output = self.lt(other) | |||
| return _tensor_inplace_assign(self, output, "lt_", "lt") | |||
| def less(self, other): | |||
| return self.lt(other) | |||
| def less_(self, other): | |||
| output = self.lt(other) | |||
| return _tensor_inplace_assign(self, output, "less_", "less") | |||
| def less_equal(self, other): | |||
| input = cast_to_ms_tensor(self) | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.less_equal(input, other) | |||
| return cast_to_adapter_tensor(output) | |||
| def less_equal_(self, other): | |||
| output = self.less_equal(other) | |||
| return _tensor_inplace_assign(self, output, "less_equal_", "less_equal") | |||
| def ne(self, other): | |||
| input = cast_to_ms_tensor(self) | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.ne(input, other) | |||
| return cast_to_adapter_tensor(output) | |||
| def ne_(self, other): | |||
| output = self.ne(other) | |||
| return _tensor_inplace_assign(self, output, "ne_", "ne") | |||
| def not_equal(self, other): | |||
| return self.ne(other) | |||
| def not_equal_(self, other): | |||
| output = self.ne(other) | |||
| return _tensor_inplace_assign(self, output, "not_equal_", "not_equal") | |||
| def equal(self, other): | |||
| if not isinstance(other, Tensor): | |||
| raise ValueError("`other` must be Tensor") | |||
| x = cast_to_ms_tensor(self) | |||
| y = cast_to_ms_tensor(other) | |||
| if x.dtype != y.dtype: | |||
| return False | |||
| if x.shape == y.shape: | |||
| size = x.size | |||
| output = ms.ops.equal(x, y) | |||
| output = output.sum() | |||
| if output == size: | |||
| return True | |||
| return False | |||
| def greater(self, other): | |||
| input = cast_to_ms_tensor(self) | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.greater(input, other) | |||
| return cast_to_adapter_tensor(output) | |||
| def greater_(self, other): | |||
| output = self.greater(other) | |||
| return _tensor_inplace_assign(self, output, "greater_", "greater") | |||
| def gt(self, other): | |||
| input = cast_to_ms_tensor(self) | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.gt(input, other) | |||
| return cast_to_adapter_tensor(output) | |||
| def gt_(self, other): | |||
| output = self.greater(other) | |||
| return _tensor_inplace_assign(self, output, "gt_", "gt") | |||
| def greater_equal(self, other): | |||
| x = cast_to_ms_tensor(self) | |||
| y = cast_to_ms_tensor(other) | |||
| output = ms.ops.greater_equal(x, y) | |||
| return cast_to_adapter_tensor(output) | |||
| def greater_equal_(self, other): | |||
| output = self.greater_equal(other) | |||
| return _tensor_inplace_assign(self, output, "greater_equal_", "greater_equal") | |||
| def argmin(self, dim=None, keepdim=False): | |||
| input = cast_to_ms_tensor(self) | |||
| # TODO: output = ms.ops.argmin(input, axis=dim, keepdims=keepdim) | |||
| if keepdim: | |||
| raise NotImplementedError("keepdim is not supported.") | |||
| # TODO: ascend not support argmin | |||
| if is_under_ascend_context(): | |||
| input = input * -1 | |||
| output = ms.ops.argmax(input, axis=dim) | |||
| else: | |||
| output = ms.ops.argmin(input, axis=dim) | |||
| return cast_to_adapter_tensor(output) | |||
| def argmax(self, dim=None, keepdim=False): | |||
| input = cast_to_ms_tensor(self) | |||
| # TODO: output = ms.ops.argmax(input, axis=dim, keepdims=keepdim) | |||
| if keepdim: | |||
| raise NotImplementedError("keepdim is not supported.") | |||
| output = ms.ops.argmax(input, axis=dim) | |||
| return cast_to_adapter_tensor(output) | |||
| def type(self, dtype=None, non_blocking=False, **kwargs): | |||
| def _get_type_from_dtype(dtype): | |||
| str_dtype = str(dtype).split('.')[-1].lower() | |||
| _type = _dtype2typeDict.get(str_dtype) | |||
| return _type | |||
| def _get_dtype_from_type(type): | |||
| _dtype = _type2dtypeDict.get(type, 'None') | |||
| if _dtype == 'None': | |||
| _dtype = type | |||
| return _dtype | |||
| unsupported_attr(non_blocking) | |||
| unsupported_attr(kwargs) | |||
| if dtype is None: | |||
| return _get_type_from_dtype(self.dtype) | |||
| _dtype = _get_dtype_from_type(dtype) | |||
| if _dtype == self.dtype: | |||
| return self | |||
| x = cast_to_ms_tensor(self) | |||
| output = x.astype(_dtype) | |||
| return cast_to_adapter_tensor(output) | |||
| def type_as(self, tensor): | |||
| if self.dtype == tensor.dtype: | |||
| return self | |||
| x = cast_to_ms_tensor(self) | |||
| output = x.astype(tensor.dtype) | |||
| return cast_to_adapter_tensor(output) | |||
| def get_device(self): | |||
| return -1 | |||
| def baddbmm(self, batch1, batch2, *, beta=1, alpha=1): | |||
| x = cast_to_ms_tensor(self) | |||
| batch1 = cast_to_ms_tensor(batch1) | |||
| batch2 = cast_to_ms_tensor(batch2) | |||
| output = ms.ops.baddbmm(x, batch1, batch2, beta, alpha) | |||
| return cast_to_adapter_tensor(output) | |||
| def baddbmm_(self, batch1, batch2, *, beta=1, alpha=1): | |||
| output = self.baddbmm(batch1, batch2, beta=beta, alpha=alpha) | |||
| return _tensor_inplace_assign(self, output, "baddbmm_", "baddbmm") | |||
| def topk(self, k, dim=None, largest=True, sorted=True): | |||
| unsupported_attr(dim) | |||
| unsupported_attr(largest) | |||
| input = cast_to_ms_tensor(self) | |||
| output = input.top_k(k, sorted=sorted) | |||
| return cast_to_adapter_tensor(output) | |||
| def maximum(self, other): | |||
| x = cast_to_ms_tensor(self) | |||
| y = cast_to_ms_tensor(other) | |||
| #TODO: NAN is different | |||
| output = ms.ops.maximum(x, y) | |||
| return cast_to_adapter_tensor(output) | |||
| def minimum(self, other): | |||
| x = cast_to_ms_tensor(self) | |||
| y = cast_to_ms_tensor(other) | |||
| #TODO: NAN is different | |||
| output = ms.ops.minimum(x, y) | |||
| return cast_to_adapter_tensor(output) | |||
| def multiply(self, value): | |||
| x = cast_to_ms_tensor(self) | |||
| y = cast_to_ms_tensor(value) | |||
| output = ms.ops.mul(x, y) | |||
| return cast_to_adapter_tensor(output) | |||
| def multiply_(self, value): | |||
| output = self.multiply(value) | |||
| return _tensor_inplace_assign(self, output, "multiply_", "multiply") | |||
| def neg(self): | |||
| x = cast_to_ms_tensor(self) | |||
| output = ms.ops.neg(x) | |||
| return cast_to_adapter_tensor(output) | |||
| def neg_(self): | |||
| output = self.neg() | |||
| return _tensor_inplace_assign(self, output, "neg_", "neg") | |||
| def ravel(self): | |||
| x = cast_to_ms_tensor(self) | |||
| output = x.ravel() | |||
| return cast_to_adapter_tensor(output) | |||
| def select(self, dim, index): | |||
| input = cast_to_ms_tensor(self) | |||
| _input_indices = ms.Tensor(index) | |||
| output = ms.ops.gather(input, _input_indices, dim) | |||
| @constexpr | |||
| def _get_out_shape(input_shape, dim): | |||
| shape = [input_shape[i] for i in range(len(input_shape)) if i != dim] | |||
| return tuple(shape) | |||
| output_shape = _get_out_shape(input.shape, dim) | |||
| output = output.reshape(output_shape) | |||
| return cast_to_adapter_tensor(output) | |||
| def square(self): | |||
| x = cast_to_ms_tensor(self) | |||
| output = ms.ops.square(x) | |||
| return cast_to_adapter_tensor(output) | |||
| def broadcast_to(self, shape): | |||
| input = cast_to_ms_tensor(self) | |||
| output = ms.ops.broadcast_to(input, shape) | |||
| return cast_to_adapter_tensor(output) | |||
| def divide(self, value, *, rounding_mode=None) : | |||
| output = _div_calcu(self, value, rounding_mode) | |||
| return cast_to_adapter_tensor(output) | |||
| def divide_(self, value, *, rounding_mode=None) : | |||
| output = _div_calcu(self, value, rounding_mode) | |||
| return _tensor_inplace_assign(self, output, "divide_", "divide") | |||
| def unique(self, sorted=True, return_inverse=False, return_counts=False, dim=None): | |||
| unsupported_attr(dim) | |||
| unsupported_attr(return_counts) | |||
| input = cast_to_ms_tensor(self) | |||
| data_type = input.dtype | |||
| if sorted and return_inverse: | |||
| raise ValueError("Don't support sorted=True and return_inverse=True.") | |||
| res, idx = ms.ops.unique(input) | |||
| if sorted: | |||
| res = ms.ops.cast(res, ms.float32) | |||
| res, _ = ms.ops.sort(res) | |||
| res = ms.ops.cast(res, data_type) | |||
| if return_inverse: | |||
| res = cast_to_adapter_tensor(res) | |||
| idx = cast_to_adapter_tensor(idx) | |||
| return (res, idx) | |||
| else: | |||
| res = cast_to_adapter_tensor(res) | |||
| return res | |||
| class _TypeTensor(Tensor): | |||
| def __init__(self, *input_data, dtype_name): | |||
| super(_TypeTensor, self).__init__(*input_data, dtype=dtype_name, inner=False) | |||
| class ByteTensor(_TypeTensor): | |||
| def __init__(self, *input_data): | |||
| super(ByteTensor, self).__init__(*input_data, dtype_name='uint8') | |||
| class CharTensor(_TypeTensor): | |||
| def __init__(self, *input_data): | |||
| super(CharTensor, self).__init__(*input_data, dtype_name='int8') | |||
| class ShortTensor(_TypeTensor): | |||
| def __init__(self, *input_data): | |||
| super(ShortTensor, self).__init__(*input_data, dtype_name='int16') | |||
| class IntTensor(_TypeTensor): | |||
| def __init__(self, *input_data): | |||
| super(IntTensor, self).__init__(*input_data, dtype_name='int32') | |||
| class HalfTensor(_TypeTensor): | |||
| def __init__(self, *input_data): | |||
| super(HalfTensor, self).__init__(*input_data, dtype_name='float16') | |||
| class FloatTensor(_TypeTensor): | |||
| def __init__(self, *input_data): | |||
| super(FloatTensor, self).__init__(*input_data, dtype_name='float32') | |||
| class DoubleTensor(_TypeTensor): | |||
| def __init__(self, *input_data): | |||
| super(DoubleTensor, self).__init__(*input_data, dtype_name='float64') | |||
| class LongTensor(_TypeTensor): | |||
| def __init__(self, *input_data): | |||
| super(LongTensor, self).__init__(*input_data, dtype_name='int64') | |||
| def tensor(data, dtype=None, device=None, requires_grad=True): | |||
| unsupported_attr(device) | |||
| if requires_grad is False: | |||
| msg = ("In Adapter, Tensor's `requires_grad` is always 'True', can not be set to 'False'. ") | |||
| warnings.warn(msg) | |||
| return Tensor(data, dtype=dtype, inner=True) | |||
| def cast_to_ms_tensor(inputs): | |||
| """ | |||
| Cast MSAdapter.Tensor to MindSpore.Tensor before call mindspore API. | |||
| """ | |||
| def _cast(inputs): | |||
| if isinstance(inputs, Tensor): | |||
| inputs = ms.Tensor(inputs) | |||
| elif isinstance(inputs, (tuple, list)): | |||
| inputs = list(inputs) | |||
| for id, value in enumerate(inputs): | |||
| inputs[id] = _cast(value) | |||
| inputs = tuple(inputs) | |||
| return inputs | |||
| # TODO: 'GRAPH_MODE' depends on MindSpore and is under development. | |||
| if pynative_mode_condition(): | |||
| inputs = _cast(inputs) | |||
| return inputs | |||
| def cast_to_adapter_tensor(outputs): | |||
| """ | |||
| Cast MindSpore.Tensor to MSAdapter.Tensor after call mindspore API. | |||
| """ | |||
| def _cast(outputs): | |||
| if isinstance(outputs, (ms.Tensor, Tensor_)): | |||
| outputs = Tensor(outputs, inner=True) | |||
| elif isinstance(outputs, (tuple, list)): | |||
| outputs = list(outputs) | |||
| for id, value in enumerate(outputs): | |||
| outputs[id] = _cast(value) | |||
| outputs = tuple(outputs) | |||
| return outputs | |||
| # TODO: 'GRAPH_MODE' depends on MindSpore and is under development. | |||
| if pynative_mode_condition(): | |||
| outputs = _cast(outputs) | |||
| return outputs | |||
| # def cast_tensor(func): | |||
| # """ | |||
| # inputs: cast MSAdapter.Tensor to MindSpore.Tensor before call func. | |||
| # result: cast MindSpore.Tensor to MSAdapter.Tensor after call func. | |||
| # """ | |||
| # @wraps(func) | |||
| # def cast_function(*args): | |||
| # inputs = cast_to_ms_tensor(args) | |||
| # result = func(*inputs) | |||
| # result = cast_to_adapter_tensor(result) | |||
| # return result | |||
| # return cast_function | |||
| def _tensor_inplace_assign(input, output, op_name, replace_op): | |||
| if pynative_mode_condition(): # TODO: ms_function | |||
| input.assign_value(output) | |||
| return input | |||
| raise RuntimeError('`Tensor.{a}` is an in-place operation and "x.{a}()" is not encouraged to use ' | |||
| 'in MindSpore static graph mode. Please use "x = x.{b}()" or other API ' | |||
| 'instead.'.format(a=op_name, b=replace_op)) | |||
| def _div_calcu(input, other, rounding_mode): | |||
| input = cast_to_ms_tensor(input) | |||
| other = cast_to_ms_tensor(other) | |||
| if rounding_mode is None: | |||
| if input.dtype == mstype.int64 or input.dtype == mstype.int32: | |||
| input = ms.ops.cast(input, mstype.float32) | |||
| output = ms.ops.div(input, other) | |||
| if rounding_mode == "trunc": | |||
| output = ms.ops.div(input, other) | |||
| if input.dtype == ms.int64: | |||
| dtype_ = output.dtype | |||
| output = ms.numpy.trunc(output, dtype=dtype_) | |||
| else: | |||
| output = ms.ops.trunc(output) | |||
| if rounding_mode == "floor": | |||
| input_dtype = input.dtype | |||
| output = ms.ops.floor_div(input, other) | |||
| output = ms.ops.cast(output, input_dtype) | |||
| return output | |||
+ 0
- 1
ms_adapter/pytorch/utils/__init__.py
View File
| @@ -1 +0,0 @@ | |||
| from ms_adapter.pytorch.utils import data | |||
+ 0
- 180
ms_adapter/pytorch/utils/data/_utils/collate.py
View File
| @@ -1,180 +0,0 @@ | |||
| r""""Contains definitions of the methods used by the _BaseDataLoaderIter workers to | |||
| collate samples fetched from dataset into Tensor(s). | |||
| These **needs** to be in global scope since Py2 doesn't support serializing | |||
| static methods. | |||
| `default_collate` and `default_convert` are exposed to users via 'dataloader.py'. | |||
| """ | |||
| import mindspore as ms | |||
| from ms_adapter.pytorch.tensor import Tensor | |||
| from ms_adapter.pytorch.functional import stack | |||
| import re | |||
| import collections | |||
| from ms_adapter.pytorch._six import string_classes | |||
| from mindspore.common.api import _pynative_executor | |||
| np_str_obj_array_pattern = re.compile(r'[SaUO]') | |||
| def default_convert(data): | |||
| r""" | |||
| Function that converts each NumPy array element into a :class:`torch.Tensor`. If the input is a `Sequence`, | |||
| `Collection`, or `Mapping`, it tries to convert each element inside to a :class:`torch.Tensor`. | |||
| If the input is not an NumPy array, it is left unchanged. | |||
| This is used as the default function for collation when both `batch_sampler` and | |||
| `batch_size` are NOT defined in :class:`~torch.utils.data.DataLoader`. | |||
| The general input type to output type mapping is similar to that | |||
| of :func:`~torch.utils.data.default_collate`. See the description there for more details. | |||
| Args: | |||
| data: a single data point to be converted | |||
| Examples: | |||
| >>> # Example with `int` | |||
| >>> default_convert(0) | |||
| 0 | |||
| >>> # Example with NumPy array | |||
| >>> default_convert(np.array([0, 1])) | |||
| tensor([0, 1]) | |||
| >>> # Example with NamedTuple | |||
| >>> Point = namedtuple('Point', ['x', 'y']) | |||
| >>> default_convert(Point(0, 0)) | |||
| Point(x=0, y=0) | |||
| >>> default_convert(Point(np.array(0), np.array(0))) | |||
| Point(x=tensor(0), y=tensor(0)) | |||
| >>> # Example with List | |||
| >>> default_convert([np.array([0, 1]), np.array([2, 3])]) | |||
| [tensor([0, 1]), tensor([2, 3])] | |||
| """ | |||
| elem_type = type(data) | |||
| if isinstance(data, ms.Tensor): | |||
| return Tensor(data) | |||
| elif elem_type.__module__ == 'numpy' and elem_type.__name__ != 'str_' \ | |||
| and elem_type.__name__ != 'string_': | |||
| # array of string classes and object | |||
| if elem_type.__name__ == 'ndarray' \ | |||
| and np_str_obj_array_pattern.search(data.dtype.str) is not None: | |||
| return data | |||
| return Tensor(data) | |||
| elif isinstance(data, collections.abc.Mapping): | |||
| try: | |||
| return elem_type({key: default_convert(data[key]) for key in data}) | |||
| except TypeError: | |||
| # The mapping type may not support `__init__(iterable)`. | |||
| return {key: default_convert(data[key]) for key in data} | |||
| elif isinstance(data, tuple) and hasattr(data, '_fields'): # namedtuple | |||
| return elem_type(*(default_convert(d) for d in data)) | |||
| elif isinstance(data, tuple): | |||
| return [default_convert(d) for d in data] # Backwards compatibility. | |||
| elif isinstance(data, collections.abc.Sequence) and not isinstance(data, string_classes): | |||
| try: | |||
| return elem_type([default_convert(d) for d in data]) | |||
| except TypeError: | |||
| # The sequence type may not support `__init__(iterable)` (e.g., `range`). | |||
| return [default_convert(d) for d in data] | |||
| else: | |||
| return data | |||
| default_collate_err_msg_format = ( | |||
| "default_collate: batch must contain tensors, numpy arrays, numbers, " | |||
| "dicts or lists; found {}") | |||
| def default_collate(batch): | |||
| r""" | |||
| Function that takes in a batch of data and puts the elements within the batch | |||
| into a tensor with an additional outer dimension - batch size. The exact output type can be | |||
| a :class:`torch.Tensor`, a `Sequence` of :class:`torch.Tensor`, a | |||
| Collection of :class:`torch.Tensor`, or left unchanged, depending on the input type. | |||
| This is used as the default function for collation when | |||
| `batch_size` or `batch_sampler` is defined in :class:`~torch.utils.data.DataLoader`. | |||
| Here is the general input type (based on the type of the element within the batch) to output type mapping: | |||
| * :class:`torch.Tensor` -> :class:`torch.Tensor` (with an added outer dimension batch size) | |||
| * NumPy Arrays -> :class:`torch.Tensor` | |||
| * `float` -> :class:`torch.Tensor` | |||
| * `int` -> :class:`torch.Tensor` | |||
| * `str` -> `str` (unchanged) | |||
| * `bytes` -> `bytes` (unchanged) | |||
| * `Mapping[K, V_i]` -> `Mapping[K, default_collate([V_1, V_2, ...])]` | |||
| * `NamedTuple[V1_i, V2_i, ...]` -> `NamedTuple[default_collate([V1_1, V1_2, ...]), | |||
| default_collate([V2_1, V2_2, ...]), ...]` | |||
| * `Sequence[V1_i, V2_i, ...]` -> `Sequence[default_collate([V1_1, V1_2, ...]), | |||
| default_collate([V2_1, V2_2, ...]), ...]` | |||
| Args: | |||
| batch: a single batch to be collated | |||
| Examples: | |||
| >>> # Example with a batch of `int`s: | |||
| >>> default_collate([0, 1, 2, 3]) | |||
| tensor([0, 1, 2, 3]) | |||
| >>> # Example with a batch of `str`s: | |||
| >>> default_collate(['a', 'b', 'c']) | |||
| ['a', 'b', 'c'] | |||
| >>> # Example with `Map` inside the batch: | |||
| >>> default_collate([{'A': 0, 'B': 1}, {'A': 100, 'B': 100}]) | |||
| {'A': tensor([ 0, 100]), 'B': tensor([ 1, 100])} | |||
| >>> # Example with `NamedTuple` inside the batch: | |||
| >>> Point = namedtuple('Point', ['x', 'y']) | |||
| >>> default_collate([Point(0, 0), Point(1, 1)]) | |||
| Point(x=tensor([0, 1]), y=tensor([0, 1])) | |||
| >>> # Example with `Tuple` inside the batch: | |||
| >>> default_collate([(0, 1), (2, 3)]) | |||
| [tensor([0, 2]), tensor([1, 3])] | |||
| >>> # Example with `List` inside the batch: | |||
| >>> default_collate([[0, 1], [2, 3]]) | |||
| [tensor([0, 2]), tensor([1, 3])] | |||
| """ | |||
| elem = batch[0] | |||
| elem_type = type(elem) | |||
| if isinstance(elem, ms.Tensor): | |||
| return stack(batch, 0) | |||
| # return batch | |||
| elif elem_type.__module__ == 'numpy' and elem_type.__name__ != 'str_' \ | |||
| and elem_type.__name__ != 'string_': | |||
| if elem_type.__name__ == 'ndarray' or elem_type.__name__ == 'memmap': | |||
| # array of string classes and object | |||
| if np_str_obj_array_pattern.search(elem.dtype.str) is not None: | |||
| raise TypeError(default_collate_err_msg_format.format(elem.dtype)) | |||
| return default_collate([Tensor(b) for b in batch]) | |||
| elif elem.shape == (): # scalars | |||
| return Tensor(batch) | |||
| elif isinstance(elem, float): | |||
| return Tensor(batch, dtype=ms.float64) | |||
| elif isinstance(elem, int): | |||
| return Tensor(batch, inner=True) | |||
| elif isinstance(elem, string_classes): | |||
| return batch | |||
| elif isinstance(elem, collections.abc.Mapping): | |||
| try: | |||
| return elem_type({key: default_collate([d[key] for d in batch]) for key in elem}) | |||
| except TypeError: | |||
| # The mapping type may not support `__init__(iterable)`. | |||
| return {key: default_collate([d[key] for d in batch]) for key in elem} | |||
| elif isinstance(elem, tuple) and hasattr(elem, '_fields'): # namedtuple | |||
| return elem_type(*(default_collate(samples) for samples in zip(*batch))) | |||
| elif isinstance(elem, collections.abc.Sequence): | |||
| # check to make sure that the elements in batch have consistent size | |||
| it = iter(batch) | |||
| elem_size = len(next(it)) | |||
| if not all(len(elem) == elem_size for elem in it): | |||
| raise RuntimeError('each element in list of batch should be of equal size') | |||
| transposed = list(zip(*batch)) # It may be accessed twice, so we use a list. | |||
| if isinstance(elem, tuple): | |||
| return [default_collate(samples) for samples in transposed] # Backwards compatibility. | |||
| else: | |||
| try: | |||
| return elem_type([default_collate(samples) for samples in transposed]) | |||
| except TypeError: | |||
| # The sequence type may not support `__init__(iterable)` (e.g., `range`). | |||
| return [default_collate(samples) for samples in transposed] | |||
| raise TypeError(default_collate_err_msg_format.format(elem_type)) | |||
+ 0
- 17
ms_adapter/pytorch/utils/data/datapipes/map/__init__.py
View File
| @@ -1,17 +0,0 @@ | |||
| # Functional DataPipe | |||
| from ms_adapter.pytorch.utils.data.datapipes.map.callable import MapperMapDataPipe as Mapper | |||
| from ms_adapter.pytorch.utils.data.datapipes.map.combinatorics import ShufflerMapDataPipe as Shuffler | |||
| from ms_adapter.pytorch.utils.data.datapipes.map.combining import ( | |||
| ConcaterMapDataPipe as Concater, | |||
| ZipperMapDataPipe as Zipper | |||
| ) | |||
| from ms_adapter.pytorch.utils.data.datapipes.map.grouping import ( | |||
| BatcherMapDataPipe as Batcher | |||
| ) | |||
| from ms_adapter.pytorch.utils.data.datapipes.map.utils import SequenceWrapperMapDataPipe as SequenceWrapper | |||
| __all__ = ['Batcher', 'Concater', 'Mapper', 'SequenceWrapper', 'Shuffler', 'Zipper'] | |||
| # Please keep this list sorted | |||
| assert __all__ == sorted(__all__) | |||
+ 0
- 181
ms_adapter/torchvision/io/video_reader.py
View File
| @@ -1,181 +0,0 @@ | |||
| from typing import Any, Dict, Iterator | |||
| import torch | |||
| try: | |||
| from ._load_gpu_decoder import _HAS_GPU_VIDEO_DECODER | |||
| except ModuleNotFoundError: | |||
| _HAS_GPU_VIDEO_DECODER = False | |||
| from ._video_opt import ( | |||
| _HAS_VIDEO_OPT, | |||
| ) | |||
| if _HAS_VIDEO_OPT: | |||
| def _has_video_opt() -> bool: | |||
| return True | |||
| else: | |||
| def _has_video_opt() -> bool: | |||
| return False | |||
| class VideoReader: | |||
| """ | |||
| Fine-grained video-reading API. | |||
| Supports frame-by-frame reading of various streams from a single video | |||
| container. | |||
| .. betastatus:: VideoReader class | |||
| Example: | |||
| The following examples creates a :mod:`VideoReader` object, seeks into 2s | |||
| point, and returns a single frame:: | |||
| import torchvision | |||
| video_path = "path_to_a_test_video" | |||
| reader = torchvision.io.VideoReader(video_path, "video") | |||
| reader.seek(2.0) | |||
| frame = next(reader) | |||
| :mod:`VideoReader` implements the iterable API, which makes it suitable to | |||
| using it in conjunction with :mod:`itertools` for more advanced reading. | |||
| As such, we can use a :mod:`VideoReader` instance inside for loops:: | |||
| reader.seek(2) | |||
| for frame in reader: | |||
| frames.append(frame['data']) | |||
| # additionally, `seek` implements a fluent API, so we can do | |||
| for frame in reader.seek(2): | |||
| frames.append(frame['data']) | |||
| With :mod:`itertools`, we can read all frames between 2 and 5 seconds with the | |||
| following code:: | |||
| for frame in itertools.takewhile(lambda x: x['pts'] <= 5, reader.seek(2)): | |||
| frames.append(frame['data']) | |||
| and similarly, reading 10 frames after the 2s timestamp can be achieved | |||
| as follows:: | |||
| for frame in itertools.islice(reader.seek(2), 10): | |||
| frames.append(frame['data']) | |||
| .. note:: | |||
| Each stream descriptor consists of two parts: stream type (e.g. 'video') and | |||
| a unique stream id (which are determined by the video encoding). | |||
| In this way, if the video contaner contains multiple | |||
| streams of the same type, users can acces the one they want. | |||
| If only stream type is passed, the decoder auto-detects first stream of that type. | |||
| Args: | |||
| path (string): Path to the video file in supported format | |||
| stream (string, optional): descriptor of the required stream, followed by the stream id, | |||
| in the format ``{stream_type}:{stream_id}``. Defaults to ``"video:0"``. | |||
| Currently available options include ``['video', 'audio']`` | |||
| num_threads (int, optional): number of threads used by the codec to decode video. | |||
| Default value (0) enables multithreading with codec-dependent heuristic. The performance | |||
| will depend on the version of FFMPEG codecs supported. | |||
| device (str, optional): Device to be used for decoding. Defaults to ``"cpu"``. | |||
| To use GPU decoding, pass ``device="cuda"``. | |||
| """ | |||
| def __init__(self, path: str, stream: str = "video", num_threads: int = 0, device: str = "cpu") -> None: | |||
| # _log_api_usage_once(self) | |||
| self.is_cuda = False | |||
| device = torch.device(device) | |||
| if device.type == "cuda": | |||
| if not _HAS_GPU_VIDEO_DECODER: | |||
| raise RuntimeError("Not compiled with GPU decoder support.") | |||
| self.is_cuda = True | |||
| self._c = torch.classes.torchvision.GPUDecoder(path, device) | |||
| return | |||
| if not _has_video_opt(): | |||
| raise RuntimeError( | |||
| "Not compiled with video_reader support, " | |||
| + "to enable video_reader support, please install " | |||
| + "ffmpeg (version 4.2 is currently supported) and " | |||
| + "build torchvision from source." | |||
| ) | |||
| self._c = torch.classes.torchvision.Video(path, stream, num_threads) | |||
| def __next__(self) -> Dict[str, Any]: | |||
| """Decodes and returns the next frame of the current stream. | |||
| Frames are encoded as a dict with mandatory | |||
| data and pts fields, where data is a tensor, and pts is a | |||
| presentation timestamp of the frame expressed in seconds | |||
| as a float. | |||
| Returns: | |||
| (dict): a dictionary and containing decoded frame (``data``) | |||
| and corresponding timestamp (``pts``) in seconds | |||
| """ | |||
| if self.is_cuda: | |||
| frame = self._c.next() | |||
| if frame.numel() == 0: | |||
| raise StopIteration | |||
| return {"data": frame} | |||
| frame, pts = self._c.next() | |||
| if frame.numel() == 0: | |||
| raise StopIteration | |||
| return {"data": frame, "pts": pts} | |||
| def __iter__(self) -> Iterator[Dict[str, Any]]: | |||
| return self | |||
| def seek(self, time_s: float, keyframes_only: bool = False) -> "VideoReader": | |||
| """Seek within current stream. | |||
| Args: | |||
| time_s (float): seek time in seconds | |||
| keyframes_only (bool): allow to seek only to keyframes | |||
| .. note:: | |||
| Current implementation is the so-called precise seek. This | |||
| means following seek, call to :mod:`next()` will return the | |||
| frame with the exact timestamp if it exists or | |||
| the first frame with timestamp larger than ``time_s``. | |||
| """ | |||
| self._c.seek(time_s, keyframes_only) | |||
| return self | |||
| def get_metadata(self) -> Dict[str, Any]: | |||
| """Returns video metadata | |||
| Returns: | |||
| (dict): dictionary containing duration and frame rate for every stream | |||
| """ | |||
| return self._c.get_metadata() | |||
| def set_current_stream(self, stream: str) -> bool: | |||
| """Set current stream. | |||
| Explicitly define the stream we are operating on. | |||
| Args: | |||
| stream (string): descriptor of the required stream. Defaults to ``"video:0"`` | |||
| Currently available stream types include ``['video', 'audio']``. | |||
| Each descriptor consists of two parts: stream type (e.g. 'video') and | |||
| a unique stream id (which are determined by video encoding). | |||
| In this way, if the video contaner contains multiple | |||
| streams of the same type, users can acces the one they want. | |||
| If only stream type is passed, the decoder auto-detects first stream | |||
| of that type and returns it. | |||
| Returns: | |||
| (bool): True on succes, False otherwise | |||
| """ | |||
| if self.is_cuda: | |||
| print("GPU decoding only works with video stream.") | |||
| return self._c.set_current_stream(stream) | |||
+ 0
- 66
ms_adapter/torchvision/ops/_register_onnx_ops.py
View File
| @@ -1,66 +0,0 @@ | |||
| import sys | |||
| import warnings | |||
| import ms_adapter.pytorch as torch | |||
| _onnx_opset_version = 11 | |||
| # TODO: | |||
| # def _register_custom_op(): | |||
| # from torch.onnx.symbolic_helper import parse_args | |||
| # from torch.onnx.symbolic_opset11 import select, squeeze, unsqueeze | |||
| # from torch.onnx.symbolic_opset9 import _cast_Long | |||
| # | |||
| # @parse_args("v", "v", "f") | |||
| # def symbolic_multi_label_nms(g, boxes, scores, iou_threshold): | |||
| # boxes = unsqueeze(g, boxes, 0) | |||
| # scores = unsqueeze(g, unsqueeze(g, scores, 0), 0) | |||
| # max_output_per_class = g.op("Constant", value_t=torch.tensor([sys.maxsize], dtype=torch.long)) | |||
| # iou_threshold = g.op("Constant", value_t=torch.tensor([iou_threshold], dtype=torch.float)) | |||
| # nms_out = g.op("NonMaxSuppression", boxes, scores, max_output_per_class, iou_threshold) | |||
| # return squeeze(g, select(g, nms_out, 1, g.op("Constant", value_t=torch.tensor([2], dtype=torch.long))), 1) | |||
| # | |||
| # @parse_args("v", "v", "f", "i", "i", "i", "i") | |||
| # def roi_align(g, input, rois, spatial_scale, pooled_height, pooled_width, sampling_ratio, aligned): | |||
| # batch_indices = _cast_Long( | |||
| # g, squeeze(g, select(g, rois, 1, g.op("Constant", value_t=torch.tensor([0], dtype=torch.long))), 1), False | |||
| # ) | |||
| # rois = select(g, rois, 1, g.op("Constant", value_t=torch.tensor([1, 2, 3, 4], dtype=torch.long))) | |||
| # # TODO: Remove this warning after ONNX opset 16 is supported. | |||
| # if aligned: | |||
| # warnings.warn( | |||
| # "ROIAlign with aligned=True is not supported in ONNX, but will be supported in opset 16. " | |||
| # "The workaround is that the user need apply the patch " | |||
| # "https://github.com/microsoft/onnxruntime/pull/8564 " | |||
| # "and build ONNXRuntime from source." | |||
| # ) | |||
| # | |||
| # # ONNX doesn't support negative sampling_ratio | |||
| # if sampling_ratio < 0: | |||
| # warnings.warn( | |||
| # "ONNX doesn't support negative sampling ratio, therefore is set to 0 in order to be exported." | |||
| # ) | |||
| # sampling_ratio = 0 | |||
| # return g.op( | |||
| # "RoiAlign", | |||
| # input, | |||
| # rois, | |||
| # batch_indices, | |||
| # spatial_scale_f=spatial_scale, | |||
| # output_height_i=pooled_height, | |||
| # output_width_i=pooled_width, | |||
| # sampling_ratio_i=sampling_ratio, | |||
| # ) | |||
| # | |||
| # @parse_args("v", "v", "f", "i", "i") | |||
| # def roi_pool(g, input, rois, spatial_scale, pooled_height, pooled_width): | |||
| # roi_pool = g.op( | |||
| # "MaxRoiPool", input, rois, pooled_shape_i=(pooled_height, pooled_width), spatial_scale_f=spatial_scale | |||
| # ) | |||
| # return roi_pool, None | |||
| # | |||
| # from torch.onnx import register_custom_op_symbolic | |||
| # | |||
| # register_custom_op_symbolic("torchvision::nms", symbolic_multi_label_nms, _onnx_opset_version) | |||
| # register_custom_op_symbolic("torchvision::roi_align", roi_align, _onnx_opset_version) | |||
| # register_custom_op_symbolic("torchvision::roi_pool", roi_pool, _onnx_opset_version) | |||
+ 0
- 566
ms_adapter/torchvision/utils.py
View File
| @@ -1,566 +0,0 @@ | |||
| # import math | |||
| # import pathlib | |||
| # import warnings | |||
| # from types import FunctionType | |||
| # from typing import Any, BinaryIO, List, Optional, Tuple, Union | |||
| # | |||
| # import numpy as np | |||
| # import torch | |||
| # from PIL import Image, ImageColor, ImageDraw, ImageFont | |||
| # | |||
| # __all__ = [ | |||
| # "make_grid", | |||
| # "save_image", | |||
| # "draw_bounding_boxes", | |||
| # "draw_segmentation_masks", | |||
| # "draw_keypoints", | |||
| # "flow_to_image", | |||
| # ] | |||
| # | |||
| # | |||
| # @torch.no_grad() | |||
| # def make_grid( | |||
| # tensor: Union[torch.Tensor, List[torch.Tensor]], | |||
| # nrow: int = 8, | |||
| # padding: int = 2, | |||
| # normalize: bool = False, | |||
| # value_range: Optional[Tuple[int, int]] = None, | |||
| # scale_each: bool = False, | |||
| # pad_value: float = 0.0, | |||
| # **kwargs, | |||
| # ) -> torch.Tensor: | |||
| # """ | |||
| # Make a grid of images. | |||
| # | |||
| # Args: | |||
| # tensor (Tensor or list): 4D mini-batch Tensor of shape (B x C x H x W) | |||
| # or a list of images all of the same size. | |||
| # nrow (int, optional): Number of images displayed in each row of the grid. | |||
| # The final grid size is ``(B / nrow, nrow)``. Default: ``8``. | |||
| # padding (int, optional): amount of padding. Default: ``2``. | |||
| # normalize (bool, optional): If True, shift the image to the range (0, 1), | |||
| # by the min and max values specified by ``value_range``. Default: ``False``. | |||
| # value_range (tuple, optional): tuple (min, max) where min and max are numbers, | |||
| # then these numbers are used to normalize the image. By default, min and max | |||
| # are computed from the tensor. | |||
| # range (tuple. optional): | |||
| # .. warning:: | |||
| # This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``value_range`` | |||
| # instead. | |||
| # scale_each (bool, optional): If ``True``, scale each image in the batch of | |||
| # images separately rather than the (min, max) over all images. Default: ``False``. | |||
| # pad_value (float, optional): Value for the padded pixels. Default: ``0``. | |||
| # | |||
| # Returns: | |||
| # grid (Tensor): the tensor containing grid of images. | |||
| # """ | |||
| # if not torch.jit.is_scripting() and not torch.jit.is_tracing(): | |||
| # _log_api_usage_once(make_grid) | |||
| # if not torch.is_tensor(tensor): | |||
| # if isinstance(tensor, list): | |||
| # for t in tensor: | |||
| # if not torch.is_tensor(t): | |||
| # raise TypeError(f"tensor or list of tensors expected, got a list containing {type(t)}") | |||
| # else: | |||
| # raise TypeError(f"tensor or list of tensors expected, got {type(tensor)}") | |||
| # | |||
| # if "range" in kwargs.keys(): | |||
| # warnings.warn( | |||
| # "The parameter 'range' is deprecated since 0.12 and will be removed in 0.14. " | |||
| # "Please use 'value_range' instead." | |||
| # ) | |||
| # value_range = kwargs["range"] | |||
| # | |||
| # # if list of tensors, convert to a 4D mini-batch Tensor | |||
| # if isinstance(tensor, list): | |||
| # tensor = torch.stack(tensor, dim=0) | |||
| # | |||
| # if tensor.dim() == 2: # single image H x W | |||
| # tensor = tensor.unsqueeze(0) | |||
| # if tensor.dim() == 3: # single image | |||
| # if tensor.size(0) == 1: # if single-channel, convert to 3-channel | |||
| # tensor = torch.cat((tensor, tensor, tensor), 0) | |||
| # tensor = tensor.unsqueeze(0) | |||
| # | |||
| # if tensor.dim() == 4 and tensor.size(1) == 1: # single-channel images | |||
| # tensor = torch.cat((tensor, tensor, tensor), 1) | |||
| # | |||
| # if normalize is True: | |||
| # tensor = tensor.clone() # avoid modifying tensor in-place | |||
| # if value_range is not None and not isinstance(value_range, tuple): | |||
| # raise TypeError("value_range has to be a tuple (min, max) if specified. min and max are numbers") | |||
| # | |||
| # def norm_ip(img, low, high): | |||
| # img.clamp_(min=low, max=high) | |||
| # img.sub_(low).div_(max(high - low, 1e-5)) | |||
| # | |||
| # def norm_range(t, value_range): | |||
| # if value_range is not None: | |||
| # norm_ip(t, value_range[0], value_range[1]) | |||
| # else: | |||
| # norm_ip(t, float(t.min()), float(t.max())) | |||
| # | |||
| # if scale_each is True: | |||
| # for t in tensor: # loop over mini-batch dimension | |||
| # norm_range(t, value_range) | |||
| # else: | |||
| # norm_range(tensor, value_range) | |||
| # | |||
| # if not isinstance(tensor, torch.Tensor): | |||
| # raise TypeError("tensor should be of type torch.Tensor") | |||
| # if tensor.size(0) == 1: | |||
| # return tensor.squeeze(0) | |||
| # | |||
| # # make the mini-batch of images into a grid | |||
| # nmaps = tensor.size(0) | |||
| # xmaps = min(nrow, nmaps) | |||
| # ymaps = int(math.ceil(float(nmaps) / xmaps)) | |||
| # height, width = int(tensor.size(2) + padding), int(tensor.size(3) + padding) | |||
| # num_channels = tensor.size(1) | |||
| # grid = tensor.new_full((num_channels, height * ymaps + padding, width * xmaps + padding), pad_value) | |||
| # k = 0 | |||
| # for y in range(ymaps): | |||
| # for x in range(xmaps): | |||
| # if k >= nmaps: | |||
| # break | |||
| # # Tensor.copy_() is a valid method but seems to be missing from the stubs | |||
| # # https://pytorch.org/docs/stable/tensors.html#torch.Tensor.copy_ | |||
| # grid.narrow(1, y * height + padding, height - padding).narrow( # type: ignore[attr-defined] | |||
| # 2, x * width + padding, width - padding | |||
| # ).copy_(tensor[k]) | |||
| # k = k + 1 | |||
| # return grid | |||
| # | |||
| # | |||
| # @torch.no_grad() | |||
| # def save_image( | |||
| # tensor: Union[torch.Tensor, List[torch.Tensor]], | |||
| # fp: Union[str, pathlib.Path, BinaryIO], | |||
| # format: Optional[str] = None, | |||
| # **kwargs, | |||
| # ) -> None: | |||
| # """ | |||
| # Save a given Tensor into an image file. | |||
| # | |||
| # Args: | |||
| # tensor (Tensor or list): Image to be saved. If given a mini-batch tensor, | |||
| # saves the tensor as a grid of images by calling ``make_grid``. | |||
| # fp (string or file object): A filename or a file object | |||
| # format(Optional): If omitted, the format to use is determined from the filename extension. | |||
| # If a file object was used instead of a filename, this parameter should always be used. | |||
| # **kwargs: Other arguments are documented in ``make_grid``. | |||
| # """ | |||
| # | |||
| # if not torch.jit.is_scripting() and not torch.jit.is_tracing(): | |||
| # _log_api_usage_once(save_image) | |||
| # grid = make_grid(tensor, **kwargs) | |||
| # # Add 0.5 after unnormalizing to [0, 255] to round to nearest integer | |||
| # ndarr = grid.mul(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to("cpu", torch.uint8).numpy() | |||
| # im = Image.fromarray(ndarr) | |||
| # im.save(fp, format=format) | |||
| # | |||
| # | |||
| # @torch.no_grad() | |||
| # def draw_bounding_boxes( | |||
| # image: torch.Tensor, | |||
| # boxes: torch.Tensor, | |||
| # labels: Optional[List[str]] = None, | |||
| # colors: Optional[Union[List[Union[str, Tuple[int, int, int]]], str, Tuple[int, int, int]]] = None, | |||
| # fill: Optional[bool] = False, | |||
| # width: int = 1, | |||
| # font: Optional[str] = None, | |||
| # font_size: Optional[int] = None, | |||
| # ) -> torch.Tensor: | |||
| # | |||
| # """ | |||
| # Draws bounding boxes on given image. | |||
| # The values of the input image should be uint8 between 0 and 255. | |||
| # If fill is True, Resulting Tensor should be saved as PNG image. | |||
| # | |||
| # Args: | |||
| # image (Tensor): Tensor of shape (C x H x W) and dtype uint8. | |||
| # boxes (Tensor): Tensor of size (N, 4) containing bounding boxes in (xmin, ymin, xmax, ymax) format. Note that | |||
| # the boxes are absolute coordinates with respect to the image. In other words: `0 <= xmin < xmax < W` and | |||
| # `0 <= ymin < ymax < H`. | |||
| # labels (List[str]): List containing the labels of bounding boxes. | |||
| # colors (color or list of colors, optional): List containing the colors | |||
| # of the boxes or single color for all boxes. The color can be represented as | |||
| # PIL strings e.g. "red" or "#FF00FF", or as RGB tuples e.g. ``(240, 10, 157)``. | |||
| # By default, random colors are generated for boxes. | |||
| # fill (bool): If `True` fills the bounding box with specified color. | |||
| # width (int): Width of bounding box. | |||
| # font (str): A filename containing a TrueType font. If the file is not found in this filename, the loader may | |||
| # also search in other directories, such as the `fonts/` directory on Windows or `/Library/Fonts/`, | |||
| # `/System/Library/Fonts/` and `~/Library/Fonts/` on macOS. | |||
| # font_size (int): The requested font size in points. | |||
| # | |||
| # Returns: | |||
| # img (Tensor[C, H, W]): Image Tensor of dtype uint8 with bounding boxes plotted. | |||
| # """ | |||
| # | |||
| # if not torch.jit.is_scripting() and not torch.jit.is_tracing(): | |||
| # _log_api_usage_once(draw_bounding_boxes) | |||
| # if not isinstance(image, torch.Tensor): | |||
| # raise TypeError(f"Tensor expected, got {type(image)}") | |||
| # elif image.dtype != torch.uint8: | |||
| # raise ValueError(f"Tensor uint8 expected, got {image.dtype}") | |||
| # elif image.dim() != 3: | |||
| # raise ValueError("Pass individual images, not batches") | |||
| # elif image.size(0) not in {1, 3}: | |||
| # raise ValueError("Only grayscale and RGB images are supported") | |||
| # | |||
| # num_boxes = boxes.shape[0] | |||
| # | |||
| # if num_boxes == 0: | |||
| # warnings.warn("boxes doesn't contain any box. No box was drawn") | |||
| # return image | |||
| # | |||
| # if labels is None: | |||
| # labels: Union[List[str], List[None]] = [None] * num_boxes # type: ignore[no-redef] | |||
| # elif len(labels) != num_boxes: | |||
| # raise ValueError( | |||
| # f"Number of boxes ({num_boxes}) and labels ({len(labels)}) mismatch. Please specify labels for each box." | |||
| # ) | |||
| # | |||
| # if colors is None: | |||
| # colors = _generate_color_palette(num_boxes) | |||
| # elif isinstance(colors, list): | |||
| # if len(colors) < num_boxes: | |||
| # raise ValueError(f"Number of colors ({len(colors)}) is less than number of boxes ({num_boxes}). ") | |||
| # else: # colors specifies a single color for all boxes | |||
| # colors = [colors] * num_boxes | |||
| # | |||
| # colors = [(ImageColor.getrgb(color) if isinstance(color, str) else color) for color in colors] | |||
| # | |||
| # if font is None: | |||
| # if font_size is not None: | |||
| # warnings.warn("Argument 'font_size' will be ignored since 'font' is not set.") | |||
| # txt_font = ImageFont.load_default() | |||
| # else: | |||
| # txt_font = ImageFont.truetype(font=font, size=font_size or 10) | |||
| # | |||
| # # Handle Grayscale images | |||
| # if image.size(0) == 1: | |||
| # image = torch.tile(image, (3, 1, 1)) | |||
| # | |||
| # ndarr = image.permute(1, 2, 0).cpu().numpy() | |||
| # img_to_draw = Image.fromarray(ndarr) | |||
| # img_boxes = boxes.to(torch.int64).tolist() | |||
| # | |||
| # if fill: | |||
| # draw = ImageDraw.Draw(img_to_draw, "RGBA") | |||
| # else: | |||
| # draw = ImageDraw.Draw(img_to_draw) | |||
| # | |||
| # for bbox, color, label in zip(img_boxes, colors, labels): # type: ignore[arg-type] | |||
| # if fill: | |||
| # fill_color = color + (100,) | |||
| # draw.rectangle(bbox, width=width, outline=color, fill=fill_color) | |||
| # else: | |||
| # draw.rectangle(bbox, width=width, outline=color) | |||
| # | |||
| # if label is not None: | |||
| # margin = width + 1 | |||
| # draw.text((bbox[0] + margin, bbox[1] + margin), label, fill=color, font=txt_font) | |||
| # | |||
| # return torch.from_numpy(np.array(img_to_draw)).permute(2, 0, 1).to(dtype=torch.uint8) | |||
| # | |||
| # | |||
| # @torch.no_grad() | |||
| # def draw_segmentation_masks( | |||
| # image: torch.Tensor, | |||
| # masks: torch.Tensor, | |||
| # alpha: float = 0.8, | |||
| # colors: Optional[Union[List[Union[str, Tuple[int, int, int]]], str, Tuple[int, int, int]]] = None, | |||
| # ) -> torch.Tensor: | |||
| # | |||
| # """ | |||
| # Draws segmentation masks on given RGB image. | |||
| # The values of the input image should be uint8 between 0 and 255. | |||
| # | |||
| # Args: | |||
| # image (Tensor): Tensor of shape (3, H, W) and dtype uint8. | |||
| # masks (Tensor): Tensor of shape (num_masks, H, W) or (H, W) and dtype bool. | |||
| # alpha (float): Float number between 0 and 1 denoting the transparency of the masks. | |||
| # 0 means full transparency, 1 means no transparency. | |||
| # colors (color or list of colors, optional): List containing the colors | |||
| # of the masks or single color for all masks. The color can be represented as | |||
| # PIL strings e.g. "red" or "#FF00FF", or as RGB tuples e.g. ``(240, 10, 157)``. | |||
| # By default, random colors are generated for each mask. | |||
| # | |||
| # Returns: | |||
| # img (Tensor[C, H, W]): Image Tensor, with segmentation masks drawn on top. | |||
| # """ | |||
| # | |||
| # if not torch.jit.is_scripting() and not torch.jit.is_tracing(): | |||
| # _log_api_usage_once(draw_segmentation_masks) | |||
| # if not isinstance(image, torch.Tensor): | |||
| # raise TypeError(f"The image must be a tensor, got {type(image)}") | |||
| # elif image.dtype != torch.uint8: | |||
| # raise ValueError(f"The image dtype must be uint8, got {image.dtype}") | |||
| # elif image.dim() != 3: | |||
| # raise ValueError("Pass individual images, not batches") | |||
| # elif image.size()[0] != 3: | |||
| # raise ValueError("Pass an RGB image. Other Image formats are not supported") | |||
| # if masks.ndim == 2: | |||
| # masks = masks[None, :, :] | |||
| # if masks.ndim != 3: | |||
| # raise ValueError("masks must be of shape (H, W) or (batch_size, H, W)") | |||
| # if masks.dtype != torch.bool: | |||
| # raise ValueError(f"The masks must be of dtype bool. Got {masks.dtype}") | |||
| # if masks.shape[-2:] != image.shape[-2:]: | |||
| # raise ValueError("The image and the masks must have the same height and width") | |||
| # | |||
| # num_masks = masks.size()[0] | |||
| # if colors is not None and num_masks > len(colors): | |||
| # raise ValueError(f"There are more masks ({num_masks}) than colors ({len(colors)})") | |||
| # | |||
| # if num_masks == 0: | |||
| # warnings.warn("masks doesn't contain any mask. No mask was drawn") | |||
| # return image | |||
| # | |||
| # if colors is None: | |||
| # colors = _generate_color_palette(num_masks) | |||
| # | |||
| # if not isinstance(colors, list): | |||
| # colors = [colors] | |||
| # if not isinstance(colors[0], (tuple, str)): | |||
| # raise ValueError("colors must be a tuple or a string, or a list thereof") | |||
| # if isinstance(colors[0], tuple) and len(colors[0]) != 3: | |||
| # raise ValueError("It seems that you passed a tuple of colors instead of a list of colors") | |||
| # | |||
| # out_dtype = torch.uint8 | |||
| # | |||
| # colors_ = [] | |||
| # for color in colors: | |||
| # if isinstance(color, str): | |||
| # color = ImageColor.getrgb(color) | |||
| # colors_.append(torch.tensor(color, dtype=out_dtype)) | |||
| # | |||
| # img_to_draw = image.detach().clone() | |||
| # # TODO: There might be a way to vectorize this | |||
| # for mask, color in zip(masks, colors_): | |||
| # img_to_draw[:, mask] = color[:, None] | |||
| # | |||
| # out = image * (1 - alpha) + img_to_draw * alpha | |||
| # return out.to(out_dtype) | |||
| # | |||
| # | |||
| # @torch.no_grad() | |||
| # def draw_keypoints( | |||
| # image: torch.Tensor, | |||
| # keypoints: torch.Tensor, | |||
| # connectivity: Optional[List[Tuple[int, int]]] = None, | |||
| # colors: Optional[Union[str, Tuple[int, int, int]]] = None, | |||
| # radius: int = 2, | |||
| # width: int = 3, | |||
| # ) -> torch.Tensor: | |||
| # | |||
| # """ | |||
| # Draws Keypoints on given RGB image. | |||
| # The values of the input image should be uint8 between 0 and 255. | |||
| # | |||
| # Args: | |||
| # image (Tensor): Tensor of shape (3, H, W) and dtype uint8. | |||
| # keypoints (Tensor): Tensor of shape (num_instances, K, 2) the K keypoints location for each of the N instances, | |||
| # in the format [x, y]. | |||
| # connectivity (List[Tuple[int, int]]]): A List of tuple where, | |||
| # each tuple contains pair of keypoints to be connected. | |||
| # colors (str, Tuple): The color can be represented as | |||
| # PIL strings e.g. "red" or "#FF00FF", or as RGB tuples e.g. ``(240, 10, 157)``. | |||
| # radius (int): Integer denoting radius of keypoint. | |||
| # width (int): Integer denoting width of line connecting keypoints. | |||
| # | |||
| # Returns: | |||
| # img (Tensor[C, H, W]): Image Tensor of dtype uint8 with keypoints drawn. | |||
| # """ | |||
| # | |||
| # if not torch.jit.is_scripting() and not torch.jit.is_tracing(): | |||
| # _log_api_usage_once(draw_keypoints) | |||
| # if not isinstance(image, torch.Tensor): | |||
| # raise TypeError(f"The image must be a tensor, got {type(image)}") | |||
| # elif image.dtype != torch.uint8: | |||
| # raise ValueError(f"The image dtype must be uint8, got {image.dtype}") | |||
| # elif image.dim() != 3: | |||
| # raise ValueError("Pass individual images, not batches") | |||
| # elif image.size()[0] != 3: | |||
| # raise ValueError("Pass an RGB image. Other Image formats are not supported") | |||
| # | |||
| # if keypoints.ndim != 3: | |||
| # raise ValueError("keypoints must be of shape (num_instances, K, 2)") | |||
| # | |||
| # ndarr = image.permute(1, 2, 0).cpu().numpy() | |||
| # img_to_draw = Image.fromarray(ndarr) | |||
| # draw = ImageDraw.Draw(img_to_draw) | |||
| # img_kpts = keypoints.to(torch.int64).tolist() | |||
| # | |||
| # for kpt_id, kpt_inst in enumerate(img_kpts): | |||
| # for inst_id, kpt in enumerate(kpt_inst): | |||
| # x1 = kpt[0] - radius | |||
| # x2 = kpt[0] + radius | |||
| # y1 = kpt[1] - radius | |||
| # y2 = kpt[1] + radius | |||
| # draw.ellipse([x1, y1, x2, y2], fill=colors, outline=None, width=0) | |||
| # | |||
| # if connectivity: | |||
| # for connection in connectivity: | |||
| # start_pt_x = kpt_inst[connection[0]][0] | |||
| # start_pt_y = kpt_inst[connection[0]][1] | |||
| # | |||
| # end_pt_x = kpt_inst[connection[1]][0] | |||
| # end_pt_y = kpt_inst[connection[1]][1] | |||
| # | |||
| # draw.line( | |||
| # ((start_pt_x, start_pt_y), (end_pt_x, end_pt_y)), | |||
| # width=width, | |||
| # ) | |||
| # | |||
| # return torch.from_numpy(np.array(img_to_draw)).permute(2, 0, 1).to(dtype=torch.uint8) | |||
| # | |||
| # | |||
| # # Flow visualization code adapted from https://github.com/tomrunia/OpticalFlow_Visualization | |||
| # @torch.no_grad() | |||
| # def flow_to_image(flow: torch.Tensor) -> torch.Tensor: | |||
| # | |||
| # """ | |||
| # Converts a flow to an RGB image. | |||
| # | |||
| # Args: | |||
| # flow (Tensor): Flow of shape (N, 2, H, W) or (2, H, W) and dtype torch.float. | |||
| # | |||
| # Returns: | |||
| # img (Tensor): Image Tensor of dtype uint8 where each color corresponds | |||
| # to a given flow direction. Shape is (N, 3, H, W) or (3, H, W) depending on the input. | |||
| # """ | |||
| # | |||
| # if flow.dtype != torch.float: | |||
| # raise ValueError(f"Flow should be of dtype torch.float, got {flow.dtype}.") | |||
| # | |||
| # orig_shape = flow.shape | |||
| # if flow.ndim == 3: | |||
| # flow = flow[None] # Add batch dim | |||
| # | |||
| # if flow.ndim != 4 or flow.shape[1] != 2: | |||
| # raise ValueError(f"Input flow should have shape (2, H, W) or (N, 2, H, W), got {orig_shape}.") | |||
| # | |||
| # max_norm = torch.sum(flow ** 2, dim=1).sqrt().max() | |||
| # epsilon = torch.finfo((flow).dtype).eps | |||
| # normalized_flow = flow / (max_norm + epsilon) | |||
| # img = _normalized_flow_to_image(normalized_flow) | |||
| # | |||
| # if len(orig_shape) == 3: | |||
| # img = img[0] # Remove batch dim | |||
| # return img | |||
| # | |||
| # | |||
| # @torch.no_grad() | |||
| # def _normalized_flow_to_image(normalized_flow: torch.Tensor) -> torch.Tensor: | |||
| # | |||
| # """ | |||
| # Converts a batch of normalized flow to an RGB image. | |||
| # | |||
| # Args: | |||
| # normalized_flow (torch.Tensor): Normalized flow tensor of shape (N, 2, H, W) | |||
| # Returns: | |||
| # img (Tensor(N, 3, H, W)): Flow visualization image of dtype uint8. | |||
| # """ | |||
| # | |||
| # N, _, H, W = normalized_flow.shape | |||
| # device = normalized_flow.device | |||
| # flow_image = torch.zeros((N, 3, H, W), dtype=torch.uint8, device=device) | |||
| # colorwheel = _make_colorwheel().to(device) # shape [55x3] | |||
| # num_cols = colorwheel.shape[0] | |||
| # norm = torch.sum(normalized_flow ** 2, dim=1).sqrt() | |||
| # a = torch.atan2(-normalized_flow[:, 1, :, :], -normalized_flow[:, 0, :, :]) / torch.pi | |||
| # fk = (a + 1) / 2 * (num_cols - 1) | |||
| # k0 = torch.floor(fk).to(torch.long) | |||
| # k1 = k0 + 1 | |||
| # k1[k1 == num_cols] = 0 | |||
| # f = fk - k0 | |||
| # | |||
| # for c in range(colorwheel.shape[1]): | |||
| # tmp = colorwheel[:, c] | |||
| # col0 = tmp[k0] / 255.0 | |||
| # col1 = tmp[k1] / 255.0 | |||
| # col = (1 - f) * col0 + f * col1 | |||
| # col = 1 - norm * (1 - col) | |||
| # flow_image[:, c, :, :] = torch.floor(255 * col) | |||
| # return flow_image | |||
| # | |||
| # | |||
| # def _make_colorwheel() -> torch.Tensor: | |||
| # """ | |||
| # Generates a color wheel for optical flow visualization as presented in: | |||
| # Baker et al. "A Database and Evaluation Methodology for Optical Flow" (ICCV, 2007) | |||
| # URL: http://vision.middlebury.edu/flow/flowEval-iccv07.pdf. | |||
| # | |||
| # Returns: | |||
| # colorwheel (Tensor[55, 3]): Colorwheel Tensor. | |||
| # """ | |||
| # | |||
| # RY = 15 | |||
| # YG = 6 | |||
| # GC = 4 | |||
| # CB = 11 | |||
| # BM = 13 | |||
| # MR = 6 | |||
| # | |||
| # ncols = RY + YG + GC + CB + BM + MR | |||
| # colorwheel = torch.zeros((ncols, 3)) | |||
| # col = 0 | |||
| # | |||
| # # RY | |||
| # colorwheel[0:RY, 0] = 255 | |||
| # colorwheel[0:RY, 1] = torch.floor(255 * torch.arange(0, RY) / RY) | |||
| # col = col + RY | |||
| # # YG | |||
| # colorwheel[col : col + YG, 0] = 255 - torch.floor(255 * torch.arange(0, YG) / YG) | |||
| # colorwheel[col : col + YG, 1] = 255 | |||
| # col = col + YG | |||
| # # GC | |||
| # colorwheel[col : col + GC, 1] = 255 | |||
| # colorwheel[col : col + GC, 2] = torch.floor(255 * torch.arange(0, GC) / GC) | |||
| # col = col + GC | |||
| # # CB | |||
| # colorwheel[col : col + CB, 1] = 255 - torch.floor(255 * torch.arange(CB) / CB) | |||
| # colorwheel[col : col + CB, 2] = 255 | |||
| # col = col + CB | |||
| # # BM | |||
| # colorwheel[col : col + BM, 2] = 255 | |||
| # colorwheel[col : col + BM, 0] = torch.floor(255 * torch.arange(0, BM) / BM) | |||
| # col = col + BM | |||
| # # MR | |||
| # colorwheel[col : col + MR, 2] = 255 - torch.floor(255 * torch.arange(MR) / MR) | |||
| # colorwheel[col : col + MR, 0] = 255 | |||
| # return colorwheel | |||
| # | |||
| # | |||
| # def _generate_color_palette(num_objects: int): | |||
| # palette = torch.tensor([2 ** 25 - 1, 2 ** 15 - 1, 2 ** 21 - 1]) | |||
| # return [tuple((i * palette) % 255) for i in range(num_objects)] | |||
| # | |||
| # | |||
| # def _log_api_usage_once(obj: Any) -> None: | |||
| # | |||
| # """ | |||
| # Logs API usage(module and name) within an organization. | |||
| # In a large ecosystem, it's often useful to track the PyTorch and | |||
| # TorchVision APIs usage. This API provides the similar functionality to the | |||
| # logging module in the Python stdlib. It can be used for debugging purpose | |||
| # to log which methods are used and by default it is inactive, unless the user | |||
| # manually subscribes a logger via the `SetAPIUsageLogger method <https://github.com/pytorch/pytorch/blob/eb3b9fe719b21fae13c7a7cf3253f970290a573e/c10/util/Logging.cpp#L114>`_. | |||
| # Please note it is triggered only once for the same API call within a process. | |||
| # It does not collect any data from open-source users since it is no-op by default. | |||
| # For more information, please refer to | |||
| # * PyTorch note: https://pytorch.org/docs/stable/notes/large_scale_deployments.html#api-usage-logging; | |||
| # * Logging policy: https://github.com/pytorch/vision/issues/5052; | |||
| # | |||
| # Args: | |||
| # obj (class instance or method): an object to extract info from. | |||
| # """ | |||
| # if not obj.__module__.startswith("torchvision"): | |||
| # return | |||
| # name = obj.__class__.__name__ | |||
| # if isinstance(obj, FunctionType): | |||
| # name = obj.__name__ | |||
| # torch._C._log_api_usage_once(f"{obj.__module__}.{name}") | |||
+ 0
- 73
ms_adapter/utils.py
View File
| @@ -1,73 +0,0 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import mindspore as ms | |||
| from mindspore import context | |||
| from mindspore.ops import constexpr | |||
| def unsupported_attr(attr): | |||
| """ | |||
| To mark the attribute that is not currently supported. | |||
| """ | |||
| return attr | |||
| @constexpr | |||
| def pynative_mode_condition(): | |||
| return context.get_context("mode") == context.PYNATIVE_MODE | |||
| @constexpr | |||
| def graph_mode_condition(): | |||
| return context.get_context("mode") == context.GRAPH_MODE | |||
| @constexpr | |||
| def get_backend(): | |||
| return context.get_context("device_target") | |||
| @constexpr | |||
| def is_under_gpu_context(): | |||
| return get_backend() == 'GPU' | |||
| @constexpr | |||
| def is_under_ascend_context(): | |||
| return get_backend() == 'Ascend' | |||
| _AscendGenernalConvertDict = { | |||
| ms.float16: ms.float16, | |||
| ms.float32: ms.float32, | |||
| ms.float64: ms.float32, | |||
| ms.int8: ms.float16, | |||
| ms.int16: ms.float16, | |||
| ms.int32: ms.float32, | |||
| ms.int64: ms.float32, | |||
| ms.uint8: ms.float16, | |||
| ms.uint16: ms.float32, | |||
| ms.uint32: ms.float32, | |||
| ms.uint64: ms.float32, | |||
| ms.bool_: ms.float16, | |||
| # ms.complex64: mstype.complex64, | |||
| # ms.complex128: mstype.complex128, | |||
| ms.double: ms.float32, | |||
| } | |||
| def _ascend_tensor_general_cast(input, conver_dicts={}): | |||
| """ | |||
| Example: | |||
| >>> import ms_adapter.pytorch as torch | |||
| >>> from ms_adapter.utils import _ascend_tensor_general_cast | |||
| >>> a = torch.tensor(2) | |||
| >>> print(a.dtype) | |||
| Int64 | |||
| >>> b = _ascend_tensor_general_cast(a) | |||
| >>> print(b.dtype) | |||
| Float32 | |||
| >>> c = _ascend_tensor_general_cast(a, conver_dicts={torch.int64: torch.int32}) | |||
| >>> print(b.dtype) | |||
| Int32 | |||
| """ | |||
| value = conver_dicts.get(input.dtype) | |||
| if value: | |||
| return input.astype(value) | |||
| _to_dtype = _AscendGenernalConvertDict[input.dtype] | |||
| return input.astype(_to_dtype) | |||
+ 6
- 0
msadapter/__init__.py
View File
| @@ -0,0 +1,6 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from msadapter import pytorch | |||
| from msadapter.utils import unsupported_attr, pynative_mode_condition | |||
| from msadapter.package_info import __version__, VERSION, version | |||
+ 11
- 0
msadapter/package_info.py
View File
| @@ -0,0 +1,11 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| MAJOR = 0 | |||
| MINOR = 1 | |||
| PATCH = 0 | |||
| PRE_RELEASE = '' | |||
| # Use the following formatting: (major, minor, patch, prerelease) | |||
| VERSION = (MAJOR, MINOR, PATCH, PRE_RELEASE) | |||
| __version__ = version = '.'.join(map(str, VERSION[:3])) + ''.join(VERSION[3:]) | |||
+ 54
- 0
msadapter/pytorch/__init__.py
View File
| @@ -0,0 +1,54 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| # Register MSAdapter Tensor/Parameter to MindSpore, it should be executed at the top of all. | |||
| from msadapter.pytorch._register import * | |||
| from msadapter.pytorch.common import * | |||
| from msadapter.pytorch.tensor import * | |||
| from msadapter.pytorch import nn | |||
| from msadapter.pytorch import optim | |||
| from msadapter.pytorch.functional import * | |||
| from msadapter.pytorch.utils import data | |||
| from msadapter.pytorch._ref import * | |||
| from msadapter.pytorch import cuda | |||
| from msadapter.pytorch.conflict_functional import * | |||
| import msadapter.pytorch.fft as fft | |||
| from msadapter.pytorch import autograd | |||
| from msadapter.pytorch.random import * | |||
| from msadapter.pytorch.storage import * | |||
| from msadapter.pytorch.serialization import * | |||
| import msadapter.pytorch.linalg as linalg | |||
| from msadapter.pytorch.common.dtype import ms_dtype as dtype | |||
| import msadapter.pytorch.amp as amp | |||
| def _assert(condition, message): | |||
| assert condition, message | |||
| def is_tensor(obj): | |||
| r"""Returns True if `obj` is a msadapter.pytorch tensor. | |||
| Note that this function is simply doing ``isinstance(obj, Tensor)``. | |||
| Using that ``isinstance`` check is better for typechecking with mypy, | |||
| and more explicit - so it's recommended to use that instead of | |||
| ``is_tensor``. | |||
| """ | |||
| return isinstance(obj, Tensor) | |||
| def is_floating_point(obj): | |||
| if not is_tensor(obj): | |||
| raise TypeError("is_floating_point(): argument 'input' (position 1) must be Tensor, not {}.".format(type(obj))) | |||
| return obj.is_floating_point() | |||
| class Size(tuple): | |||
| def __new__(cls, shape): | |||
| if isinstance(shape, Tensor): | |||
| _shape = shape.tolist() | |||
| else: | |||
| _shape = shape | |||
| if not isinstance(_shape, (tuple, list)): | |||
| raise TypeError("{} object is not supportted.".format(type(shape))) | |||
| return tuple.__new__(Size, _shape) | |||
| __version__ = version = "1.12.1" | |||
+ 22
- 0
msadapter/pytorch/_ref/__init__.py
View File
| @@ -0,0 +1,22 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from msadapter.pytorch.tensor import Tensor | |||
| def typename(o): | |||
| if isinstance(o, Tensor): | |||
| return o.type() | |||
| module = '' | |||
| class_name = '' | |||
| if hasattr(o, '__module__') and o.__module__ != 'builtins' \ | |||
| and o.__module__ != '__builtin__' and o.__module__ is not None: | |||
| module = o.__module__ + '.' | |||
| if hasattr(o, '__qualname__'): | |||
| class_name = o.__qualname__ | |||
| elif hasattr(o, '__name__'): | |||
| class_name = o.__name__ | |||
| else: | |||
| class_name = o.__class__.__name__ | |||
| return module + class_name | |||
+ 48
- 0
msadapter/pytorch/_register/__init__.py
View File
| @@ -0,0 +1,48 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from mindspore.common.api import set_adapter_config | |||
| from mindspore._extends.parse import trope as T | |||
| from mindspore._extends.parse.resources import convert_object_map | |||
| from msadapter.pytorch.tensor import Tensor | |||
| from msadapter.pytorch.nn import Parameter | |||
| from msadapter.pytorch._register import register_multitype_ops | |||
| from msadapter.pytorch._register import register_standard_method as S | |||
| from msadapter.pytorch._register.register_utils import create_tensor | |||
| convert_object_map[T.add] = register_multitype_ops.add # x+y | |||
| convert_object_map[T.sub] = register_multitype_ops.sub # x-y | |||
| convert_object_map[T.mul] = register_multitype_ops.mul # x*y | |||
| convert_object_map[T.truediv] = register_multitype_ops.div # x/y | |||
| convert_object_map[T.getitem] = register_multitype_ops.getitem # x[0] | |||
| convert_object_map[T.setitem] = register_multitype_ops.setitem # x[0]=y | |||
| convert_object_map[T.floordiv] = register_multitype_ops.floordiv # x//y | |||
| convert_object_map[T.mod] = register_multitype_ops.mod # x%y | |||
| convert_object_map[T.pow] = register_multitype_ops.pow_ # x**y | |||
| convert_object_map[T.and_] = register_multitype_ops.bitwise_and # x&y | |||
| convert_object_map[T.or_] = register_multitype_ops.bitwise_or # x|y | |||
| convert_object_map[T.xor] = register_multitype_ops.bitwise_xor # x^y | |||
| convert_object_map[T.neg] = register_multitype_ops.negative # -x | |||
| convert_object_map[T.not_] = register_multitype_ops.logical_not # not x | |||
| convert_object_map[T.eq] = register_multitype_ops.equal # x==y | |||
| convert_object_map[T.ne] = register_multitype_ops.not_equal # x!=y | |||
| convert_object_map[T.lt] = register_multitype_ops.less # x < y | |||
| convert_object_map[T.gt] = register_multitype_ops.greater # x > y | |||
| convert_object_map[T.le] = register_multitype_ops.less_equal # x <= y | |||
| convert_object_map[T.ge] = register_multitype_ops.greater_equal # x >= y | |||
| convert_object_map[T.contains] = register_multitype_ops.in_ # x in y | |||
| convert_object_map[T.not_contains] = register_multitype_ops.not_in_ # x not in y | |||
| convert_object_map[T.matmul] = S.adapter_matmul # x @ y | |||
| convert_object_map[T.invert] = S.adapter_invert # ~x | |||
| convert_object_map[T.abs] = S.adapter_abs # abs(x) | |||
| convert_object_map[T.round] = S.adapter_round # round(x) | |||
| convert_object_map[T.max] = S.adapter_max # max(x) | |||
| convert_object_map[T.min] = S.adapter_min # min(x) | |||
| convert_object_map[T.sum] = S.adapter_sum # sum(x) | |||
| # convert_object_map[Tensor] = create_tensor | |||
| def register_msadapter_tensor(): | |||
| adapter_config = {"Tensor": Tensor, "Parameter": Parameter, "convert_object_map": convert_object_map} | |||
| set_adapter_config(adapter_config) | |||
| register_msadapter_tensor() | |||
+ 45
- 0
msadapter/pytorch/_register/getitem_impl.py
View File
| @@ -0,0 +1,45 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import mindspore as ms | |||
| from mindspore import dtype as mstype | |||
| from mindspore.ops.composite.multitype_ops import _compile_utils as compile_utils | |||
| def _tensor_getitem_by_tensor(data, tensor_index): | |||
| if tensor_index.dtype == mstype.bool_: | |||
| ms_shape_len = len(data.shape) | |||
| index_shape_len = len(tensor_index.shape) | |||
| out_shape = [-1] | |||
| while index_shape_len < ms_shape_len: | |||
| out_shape.append(data.shape[index_shape_len]) | |||
| tensor_index = tensor_index.expand_dims(-1) | |||
| index_shape_len += 1 | |||
| out = ms.ops.masked_select(data, tensor_index) | |||
| if len(out_shape) > 1: | |||
| out = out.reshape(out_shape) | |||
| else: | |||
| out = compile_utils.tensor_index_by_tensor(data, tensor_index) | |||
| return out | |||
| def _tensor_getitem_by_number(data, number_index): | |||
| if isinstance(number_index, bool): | |||
| if number_index: | |||
| return data.expand_dims(0) | |||
| else: | |||
| index = ms.Tensor(False) | |||
| out = ms.ops.masked_select(data, index) | |||
| return out | |||
| return compile_utils.tensor_index_by_number(data, number_index) | |||
| def _tensor_getitem_by_tuple(data, tuple_index): | |||
| if isinstance(tuple_index[0], bool): | |||
| if False in tuple_index: | |||
| index = ms.Tensor(False) | |||
| out = ms.ops.masked_select(data, index) | |||
| return out | |||
| else: | |||
| return data.expand_dims(0) | |||
| return compile_utils.tensor_index_by_tuple(data, tuple_index) | |||
+ 162
- 0
msadapter/pytorch/_register/register_multitype_ops.py
View File
| @@ -0,0 +1,162 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from mindspore.ops.composite.multitype_ops.add_impl import add | |||
| from mindspore.ops.composite.multitype_ops.sub_impl import sub | |||
| from mindspore.ops.composite.multitype_ops.mul_impl import mul | |||
| from mindspore.ops.composite.multitype_ops.div_impl import div | |||
| from mindspore.ops.composite.multitype_ops.floordiv_impl import floordiv | |||
| from mindspore.ops.composite.multitype_ops.mod_impl import mod | |||
| from mindspore.ops.composite.multitype_ops.pow_impl import pow_ | |||
| from mindspore.ops.composite.multitype_ops.bitwise_and_impl import bitwise_and | |||
| from mindspore.ops.composite.multitype_ops.bitwise_or_impl import bitwise_or | |||
| from mindspore.ops.composite.multitype_ops.bitwise_xor_impl import bitwise_xor | |||
| from mindspore.ops.composite.multitype_ops.negative_impl import negative | |||
| from mindspore.ops.composite.multitype_ops.logic_not_impl import logical_not | |||
| from mindspore.ops.composite.multitype_ops.equal_impl import equal | |||
| from mindspore.ops.composite.multitype_ops.not_equal_impl import not_equal | |||
| from mindspore.ops.composite.multitype_ops.less_impl import less | |||
| from mindspore.ops.composite.multitype_ops.greater_impl import greater | |||
| from mindspore.ops.composite.multitype_ops.less_equal_impl import less_equal | |||
| from mindspore.ops.composite.multitype_ops.greater_equal_impl import greater_equal | |||
| from mindspore.ops.composite.multitype_ops.in_impl import in_ | |||
| from mindspore.ops.composite.multitype_ops.not_in_impl import not_in_ | |||
| from mindspore.ops.composite.multitype_ops.getitem_impl import getitem | |||
| from mindspore.ops.composite.multitype_ops.setitem_impl import setitem | |||
| from msadapter.pytorch._register import register_utils as utils | |||
| from msadapter.pytorch._register.getitem_impl import _tensor_getitem_by_tensor, _tensor_getitem_by_number, \ | |||
| _tensor_getitem_by_tuple | |||
| # multitype_ops.add | |||
| utils.update_multitype_ops_tensor_tensor(add) | |||
| utils.update_multitype_ops_number_tensor(add) | |||
| utils.update_multitype_ops_tensor_number(add) | |||
| utils.update_multitype_ops_tuple_tensor(add) | |||
| utils.update_multitype_ops_tensor_tuple(add) | |||
| utils.update_multitype_ops_list_tensor(add) | |||
| utils.update_multitype_ops_tensor_list(add) | |||
| # multitype_ops.sub | |||
| utils.update_multitype_ops_tensor_tensor(sub) | |||
| utils.update_multitype_ops_number_tensor(sub) | |||
| utils.update_multitype_ops_tensor_number(sub) | |||
| utils.update_multitype_ops_tuple_tensor(sub) | |||
| utils.update_multitype_ops_tensor_tuple(sub) | |||
| utils.update_multitype_ops_list_tensor(sub) | |||
| utils.update_multitype_ops_tensor_list(sub) | |||
| # multitype_ops.mul | |||
| utils.update_multitype_ops_tensor_tensor(mul) | |||
| utils.update_multitype_ops_number_tensor(mul) | |||
| utils.update_multitype_ops_tensor_number(mul) | |||
| utils.update_multitype_ops_tuple_tensor(mul) | |||
| utils.update_multitype_ops_tensor_tuple(mul) | |||
| utils.update_multitype_ops_list_tensor(mul) | |||
| utils.update_multitype_ops_tensor_list(mul) | |||
| # multitype_ops.div | |||
| utils.update_multitype_ops_tensor_tensor(div) | |||
| utils.update_multitype_ops_number_tensor(div) | |||
| utils.update_multitype_ops_tensor_number(div) | |||
| utils.update_multitype_ops_tuple_tensor(div) | |||
| utils.update_multitype_ops_tensor_tuple(div) | |||
| utils.update_multitype_ops_list_tensor(div) | |||
| utils.update_multitype_ops_tensor_list(div) | |||
| # multitype_ops.floordiv | |||
| utils.update_multitype_ops_tensor_tensor(floordiv) | |||
| utils.update_multitype_ops_number_tensor(floordiv) | |||
| utils.update_multitype_ops_tensor_number(floordiv) | |||
| utils.update_multitype_ops_tuple_tensor(floordiv) | |||
| utils.update_multitype_ops_tensor_tuple(floordiv) | |||
| utils.update_multitype_ops_list_tensor(floordiv) | |||
| utils.update_multitype_ops_tensor_list(floordiv) | |||
| # multitype_ops.mod | |||
| utils.update_multitype_ops_tensor_tensor(mod) | |||
| utils.update_multitype_ops_number_tensor(mod) | |||
| utils.update_multitype_ops_tensor_number(mod) | |||
| utils.update_multitype_ops_tuple_tensor(mod) | |||
| utils.update_multitype_ops_tensor_tuple(mod) | |||
| utils.update_multitype_ops_list_tensor(mod) | |||
| utils.update_multitype_ops_tensor_list(mod) | |||
| # multitype_ops.pow_ | |||
| utils.update_multitype_ops_tensor_tensor(pow_) | |||
| utils.update_multitype_ops_number_tensor(pow_) | |||
| utils.update_multitype_ops_tensor_number(pow_) | |||
| utils.update_multitype_ops_tuple_tensor(pow_) | |||
| utils.update_multitype_ops_tensor_tuple(pow_) | |||
| utils.update_multitype_ops_list_tensor(pow_) | |||
| utils.update_multitype_ops_tensor_list(pow_) | |||
| # multitype_ops.bitwise_and | |||
| utils.update_multitype_ops_tensor_tensor(bitwise_and) | |||
| utils.update_multitype_ops_number_tensor(bitwise_and) | |||
| utils.update_multitype_ops_tensor_number(bitwise_and) | |||
| # multitype_ops.bitwise_or | |||
| utils.update_multitype_ops_tensor_tensor(bitwise_or) | |||
| utils.update_multitype_ops_number_tensor(bitwise_or) | |||
| utils.update_multitype_ops_tensor_number(bitwise_or) | |||
| # multitype_ops.bitwise_xor | |||
| utils.update_multitype_ops_tensor_tensor(bitwise_xor) | |||
| utils.update_multitype_ops_number_tensor(bitwise_xor) | |||
| utils.update_multitype_ops_tensor_number(bitwise_xor) | |||
| # multitype_ops.negative | |||
| utils.update_multitype_ops_tensor(negative) | |||
| # multitype_ops.logical_not | |||
| # LogicalNot only support Tensor[Bool]. | |||
| utils.update_multitype_ops_tensor(logical_not) | |||
| # multitype_ops.equal | |||
| utils.update_multitype_ops_tensor_tensor(equal) | |||
| utils.update_multitype_ops_number_tensor(equal) | |||
| utils.update_multitype_ops_tensor_number(equal) | |||
| # multitype_ops.not_equal | |||
| utils.update_multitype_ops_tensor_tensor(not_equal) | |||
| utils.update_multitype_ops_number_tensor(not_equal) | |||
| utils.update_multitype_ops_tensor_number(not_equal) | |||
| # multitype_ops.less | |||
| utils.update_multitype_ops_tensor_tensor(less) | |||
| utils.update_multitype_ops_number_tensor(less) | |||
| utils.update_multitype_ops_tensor_number(less) | |||
| # multitype_ops.greater | |||
| utils.update_multitype_ops_tensor_tensor(greater) | |||
| utils.update_multitype_ops_number_tensor(greater) | |||
| utils.update_multitype_ops_tensor_number(greater) | |||
| # multitype_ops.less_equal | |||
| utils.update_multitype_ops_tensor_tensor(less_equal) | |||
| utils.update_multitype_ops_number_tensor(less_equal) | |||
| utils.update_multitype_ops_tensor_number(less_equal) | |||
| # multitype_ops.greater_equal | |||
| utils.update_multitype_ops_tensor_tensor(greater_equal) | |||
| utils.update_multitype_ops_number_tensor(greater_equal) | |||
| utils.update_multitype_ops_tensor_number(greater_equal) | |||
| # multitype_ops.in_ | |||
| utils.update_multitype_ops_tensor_tuple(in_) | |||
| utils.update_multitype_ops_tensor_list(in_) | |||
| # multitype_ops.not_in_ | |||
| utils.update_multitype_ops_tensor_tuple(not_in_) | |||
| utils.update_multitype_ops_tensor_list(not_in_) | |||
| # multitype_ops.getitem | |||
| utils.update_multitype_ops_tensor_list(getitem) | |||
| utils.update_multitype_ops_tensor_none(getitem) | |||
| utils.update_multitype_ops_tensor_slice(getitem) | |||
| utils.update_multitype_ops_tensor_tensor_with_fn(getitem, _tensor_getitem_by_tensor) | |||
| utils.update_multitype_ops_tensor_number_with_fn(getitem, _tensor_getitem_by_number) | |||
| utils.update_multitype_ops_tensor_tuple_with_fn(getitem, _tensor_getitem_by_tuple) | |||
| # multitype_ops.setitem | |||
| utils.update_multitype_ops_setitem_tensor(setitem) | |||
+ 98
- 0
msadapter/pytorch/_register/register_standard_method.py
View File
| @@ -0,0 +1,98 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from mindspore import dtype as mstype | |||
| from mindspore._extends.parse import trope as T | |||
| from mindspore._extends.parse.resources import convert_object_map | |||
| from msadapter.pytorch.tensor import Tensor as adapter_Tensor | |||
| from msadapter.pytorch._register.register_utils import convert_to_ms_tensor, convert_to_adapter_tensor | |||
| matmul_fn = convert_object_map.get(T.matmul) | |||
| invert_fn = convert_object_map.get(T.invert) | |||
| abs_fn = convert_object_map.get(T.abs) | |||
| round_fn = convert_object_map.get(T.round) | |||
| max_fn = convert_object_map.get(T.max) | |||
| min_fn = convert_object_map.get(T.min) | |||
| sum_fn = convert_object_map.get(T.sum) | |||
| def adapter_matmul(x, y): | |||
| if isinstance(x, adapter_Tensor) and isinstance(y, adapter_Tensor): | |||
| x = convert_to_ms_tensor(x) | |||
| y = convert_to_ms_tensor(y) | |||
| out = matmul_fn(x, y) | |||
| out = convert_to_adapter_tensor(out) | |||
| else: | |||
| out = matmul_fn(x, y) | |||
| return out | |||
| def adapter_invert(x): | |||
| if isinstance(x, adapter_Tensor): | |||
| x = convert_to_ms_tensor(x) | |||
| if x.dtype != mstype.bool_: | |||
| out = - 1 - x | |||
| else: | |||
| out = invert_fn(x) | |||
| out = convert_to_adapter_tensor(out) | |||
| else: | |||
| out = invert_fn(x) | |||
| return out | |||
| def adapter_abs(x): | |||
| if isinstance(x, adapter_Tensor): | |||
| x = convert_to_ms_tensor(x) | |||
| out = abs_fn(x) | |||
| out = convert_to_adapter_tensor(out) | |||
| else: | |||
| out = abs_fn(x) | |||
| return out | |||
| def adapter_round(*data): | |||
| if (len(data) == 1 and isinstance(data[0], adapter_Tensor)) or \ | |||
| (len(data) == 2 and isinstance(data[0], adapter_Tensor) and data[1] is None): | |||
| x = data[0] | |||
| x = convert_to_ms_tensor(x) | |||
| out = round_fn(x) | |||
| out = convert_to_adapter_tensor(out) | |||
| else: | |||
| out = round_fn(*data) | |||
| return out | |||
| def _has_adapter_tensor(*data): | |||
| if len(data) == 1 and isinstance(data[0], adapter_Tensor): | |||
| return True | |||
| for elem in data: | |||
| if isinstance(elem, adapter_Tensor): | |||
| return True | |||
| return False | |||
| def adapter_max(*data): | |||
| if _has_adapter_tensor(*data): | |||
| out = max_fn(*data) | |||
| out = convert_to_adapter_tensor(out) | |||
| else: | |||
| out = max_fn(*data) | |||
| return out | |||
| def adapter_min(*data): | |||
| if _has_adapter_tensor(*data): | |||
| out = min_fn(*data) | |||
| out = convert_to_adapter_tensor(out) | |||
| else: | |||
| out = min_fn(*data) | |||
| return out | |||
| def adapter_sum(*data): | |||
| if _has_adapter_tensor(*data): | |||
| out = sum_fn(*data) | |||
| out = convert_to_adapter_tensor(out) | |||
| else: | |||
| out = sum_fn(*data) | |||
| return out | |||
+ 254
- 0
msadapter/pytorch/_register/register_utils.py
View File
| @@ -0,0 +1,254 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import mindspore as ms | |||
| from mindspore import dtype as mstype | |||
| from mindspore.ops.operations import _inner_ops as inner | |||
| from msadapter.pytorch.tensor import Tensor as adapter_Tensor | |||
| def convert_to_ms_tensor(x): | |||
| return inner.convert_to_ms_tensor(x) | |||
| def convert_to_adapter_tensor(x): | |||
| return inner.convert_to_adapter_tensor(x) | |||
| def convert_output(out): | |||
| if isinstance(out, ms.Tensor): | |||
| out = convert_to_adapter_tensor(out) | |||
| return out | |||
| def get_registed_fn(ops, *type_names): | |||
| types = tuple(map(mstype.typing.str_to_type, type_names)) | |||
| for sigs, fn in ops.entries: | |||
| if len(sigs) != len(types): | |||
| continue | |||
| if any(not mstype._issubclass_(type_, sig) for sig, type_ in zip(sigs, types)): | |||
| continue | |||
| return fn | |||
| raise ValueError(f"For 'MultitypeFuncGraph', cannot find fn match given types: {types}.") | |||
| def _multitype_ops_tensor_calcu(ops, func1, func2): | |||
| @ops.register("Tensor") | |||
| def _tensor(x): | |||
| if isinstance(x, adapter_Tensor): | |||
| x = convert_to_ms_tensor(x) | |||
| out = func1(x) | |||
| out = convert_output(out) | |||
| else: | |||
| out = func2(x) | |||
| return out | |||
| def update_multitype_ops_tensor_with_fn(ops, func1): | |||
| func2 = get_registed_fn(ops, "Tensor") | |||
| _multitype_ops_tensor_calcu(ops, func1, func2) | |||
| def update_multitype_ops_tensor(ops): | |||
| func = get_registed_fn(ops, "Tensor") | |||
| _multitype_ops_tensor_calcu(ops, func, func) | |||
| def _multitype_ops_tensor_tensor_calcu(ops, func1, func2): | |||
| @ops.register("Tensor", "Tensor") | |||
| def _tensor_and_tensor(x, y): | |||
| if isinstance(x, adapter_Tensor) and isinstance(y, adapter_Tensor): | |||
| x = convert_to_ms_tensor(x) | |||
| y = convert_to_ms_tensor(y) | |||
| out = func1(x, y) | |||
| out = convert_output(out) | |||
| else: | |||
| out = func2(x, y) | |||
| return out | |||
| def update_multitype_ops_tensor_tensor_with_fn(ops, func1): | |||
| func2 = get_registed_fn(ops, "Tensor", "Tensor") | |||
| _multitype_ops_tensor_tensor_calcu(ops, func1, func2) | |||
| def update_multitype_ops_tensor_tensor(ops): | |||
| func = get_registed_fn(ops, "Tensor", "Tensor") | |||
| _multitype_ops_tensor_tensor_calcu(ops, func, func) | |||
| def _multitype_ops_number_tensor_calcu(ops, func1, func2): | |||
| @ops.register("Number", "Tensor") | |||
| def _number_and_tensor(x, y): | |||
| if isinstance(y, adapter_Tensor): | |||
| y = convert_to_ms_tensor(y) | |||
| out = func1(x, y) | |||
| out = convert_output(out) | |||
| else: | |||
| out = func2(x, y) | |||
| return out | |||
| def update_multitype_ops_number_tensor_with_fn(ops, func1): | |||
| func2 = get_registed_fn(ops, "Number", "Tensor") | |||
| _multitype_ops_number_tensor_calcu(ops, func1, func2) | |||
| def update_multitype_ops_number_tensor(ops): | |||
| func = get_registed_fn(ops, "Number", "Tensor") | |||
| _multitype_ops_number_tensor_calcu(ops, func, func) | |||
| def _multitype_ops_tensor_number_calcu(ops, func1, func2): | |||
| @ops.register("Tensor", "Number") | |||
| def _tensor_and_number(x, y): | |||
| if isinstance(x, adapter_Tensor): | |||
| x = convert_to_ms_tensor(x) | |||
| out = func1(x, y) | |||
| out = convert_output(out) | |||
| else: | |||
| out = func2(x, y) | |||
| return out | |||
| def update_multitype_ops_tensor_number_with_fn(ops, func1): | |||
| func2 = get_registed_fn(ops, "Tensor", "Number") | |||
| _multitype_ops_tensor_number_calcu(ops, func1, func2) | |||
| def update_multitype_ops_tensor_number(ops): | |||
| func = get_registed_fn(ops, "Tensor", "Number") | |||
| _multitype_ops_tensor_number_calcu(ops, func, func) | |||
| def _multitype_ops_tuple_tensor_calcu(ops, func1, func2): | |||
| @ops.register("Tuple", "Tensor") | |||
| def _tuple_and_tensor(x, y): | |||
| if isinstance(y, adapter_Tensor): | |||
| y = convert_to_ms_tensor(y) | |||
| out = func1(x, y) | |||
| out = convert_output(out) | |||
| else: | |||
| out = func2(x, y) | |||
| return out | |||
| def update_multitype_ops_tuple_tensor_with_fn(ops, func1): | |||
| func2 = get_registed_fn(ops, "Tuple", "Tensor") | |||
| _multitype_ops_tuple_tensor_calcu(ops, func1, func2) | |||
| def update_multitype_ops_tuple_tensor(ops): | |||
| func = get_registed_fn(ops, "Tuple", "Tensor") | |||
| _multitype_ops_tuple_tensor_calcu(ops, func, func) | |||
| def _multitype_ops_tensor_tuple_calcu(ops, func1, func2): | |||
| @ops.register("Tensor", "Tuple") | |||
| def _tensor_and_tuple(x, y): | |||
| if isinstance(x, adapter_Tensor): | |||
| x = convert_to_ms_tensor(x) | |||
| out = func1(x, y) | |||
| out = convert_output(out) | |||
| else: | |||
| out = func2(x, y) | |||
| return out | |||
| def update_multitype_ops_tensor_tuple_with_fn(ops, func1): | |||
| func2 = get_registed_fn(ops, "Tensor", "Tuple") | |||
| _multitype_ops_tensor_tuple_calcu(ops, func1, func2) | |||
| def update_multitype_ops_tensor_tuple(ops): | |||
| func = get_registed_fn(ops, "Tensor", "Tuple") | |||
| _multitype_ops_tensor_tuple_calcu(ops, func, func) | |||
| def _multitype_ops_list_tensor_calcu(ops, func1, func2): | |||
| @ops.register("List", "Tensor") | |||
| def _list_and_tensor(x, y): | |||
| if isinstance(y, adapter_Tensor): | |||
| y = convert_to_ms_tensor(y) | |||
| out = func1(x, y) | |||
| out = convert_output(out) | |||
| else: | |||
| out = func2(x, y) | |||
| return out | |||
| def update_multitype_ops_list_tensor_with_fn(ops, func1): | |||
| func2 = get_registed_fn(ops, "List", "Tensor") | |||
| _multitype_ops_list_tensor_calcu(ops, func1, func2) | |||
| def update_multitype_ops_list_tensor(ops): | |||
| func = get_registed_fn(ops, "List", "Tensor") | |||
| _multitype_ops_list_tensor_calcu(ops, func, func) | |||
| def _multitype_ops_tensor_list_calcu(ops, func1, func2): | |||
| @ops.register("Tensor", "List") | |||
| def _tensor_and_list(x, y): | |||
| if isinstance(x, adapter_Tensor): | |||
| x = convert_to_ms_tensor(x) | |||
| out = func1(x, y) | |||
| out = convert_output(out) | |||
| else: | |||
| out = func2(x, y) | |||
| return out | |||
| def update_multitype_ops_tensor_list_with_fn(ops, func1): | |||
| func2 = get_registed_fn(ops, "Tensor", "List") | |||
| _multitype_ops_tensor_list_calcu(ops, func1, func2) | |||
| def update_multitype_ops_tensor_list(ops): | |||
| func = get_registed_fn(ops, "Tensor", "List") | |||
| _multitype_ops_tensor_list_calcu(ops, func, func) | |||
| def _multitype_ops_tensor_none_calcu(ops, func1, func2): | |||
| @ops.register("Tensor", "None") | |||
| def _tensor_and_none(x, y): | |||
| if isinstance(x, adapter_Tensor): | |||
| x = convert_to_ms_tensor(x) | |||
| out = func1(x, y) | |||
| out = convert_output(out) | |||
| else: | |||
| out = func2(x, y) | |||
| return out | |||
| def update_multitype_ops_tensor_none_with_fn(ops, func1): | |||
| func2 = get_registed_fn(ops, "Tensor", "None") | |||
| _multitype_ops_tensor_none_calcu(ops, func1, func2) | |||
| def update_multitype_ops_tensor_none(ops): | |||
| func = get_registed_fn(ops, "Tensor", "None") | |||
| _multitype_ops_tensor_none_calcu(ops, func, func) | |||
| def _multitype_ops_tensor_slice_calcu(ops, func1, func2): | |||
| @ops.register("Tensor", "Slice") | |||
| def _tensor_and_slice(x, y): | |||
| if isinstance(x, adapter_Tensor): | |||
| x = convert_to_ms_tensor(x) | |||
| out = func1(x, y) | |||
| out = convert_output(out) | |||
| else: | |||
| out = func2(x, y) | |||
| return out | |||
| def update_multitype_ops_tensor_slice_with_fn(ops, func1): | |||
| func2 = get_registed_fn(ops, "Tensor", "Slice") | |||
| _multitype_ops_tensor_slice_calcu(ops, func1, func2) | |||
| def update_multitype_ops_tensor_slice(ops): | |||
| func = get_registed_fn(ops, "Tensor", "Slice") | |||
| _multitype_ops_tensor_slice_calcu(ops, func, func) | |||
| def update_multitype_ops_setitem_tensor(ops): | |||
| def register_for_setitem(sigs, fn): | |||
| @ops.register(*sigs) | |||
| def _tensor_setitem(data, index, value): | |||
| if isinstance(data, adapter_Tensor): | |||
| data = convert_to_ms_tensor(data) | |||
| out = fn(data, index, value) | |||
| out = convert_to_adapter_tensor(out) | |||
| else: | |||
| out = fn(data, index, value) | |||
| return out | |||
| entries = ops.entries.copy() | |||
| for sigs, fn in entries: | |||
| if mstype._issubclass_(sigs[0], mstype.tensor_type): | |||
| register_for_setitem(sigs, fn) | |||
| def create_tensor(*data): | |||
| return convert_to_adapter_tensor(ms.Tensor(*data)) | |||
+ 217
- 0
msadapter/pytorch/_register_numpy_primitive.py
View File
| @@ -0,0 +1,217 @@ | |||
| import numpy as np | |||
| import mindspore as ms | |||
| import mindspore.nn as nn | |||
| from scipy.linalg import lu, lu_factor, lu_solve | |||
| import msadapter.pytorch.common.dtype as msdapter_dtype | |||
| _error_msg = "[numpy backward issue.] For '{}', it can not backward, please use other function instead." | |||
| class NumpyCommon(nn.Cell): | |||
| def __init__(self, op_name=None): | |||
| super().__init__() | |||
| self.op_name = op_name | |||
| #TODO: NumpyLstsq constructs the same output that torch.lstsq generates | |||
| #Later, torch.lstsq will be deprecated and used linalg.lstsq instead, the NumpyLstsq will be deprecated as well | |||
| class NumpyLstsq(NumpyCommon): | |||
| def construct(self, input, A): | |||
| type_np = A.dtype | |||
| shape_np = A.shape | |||
| input_np = input.asnumpy() | |||
| A_np = A.asnumpy() | |||
| output = ms.Tensor(np.linalg.lstsq(A_np, input_np)[0]) | |||
| #TODO: linalg.lstsq not support qr as return, thus the qr will be set to zeros | |||
| qr = ms.ops.zeros(shape_np, type_np) | |||
| return output, qr | |||
| def bprop(self, input, A, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| #TODO: NumpyLstsq constructs the same output that torch.linalg.lstsq generates | |||
| class NumpyFullLstsq(NumpyCommon): | |||
| def __init__(self, op_name=None, rcond=None): | |||
| super().__init__() | |||
| self.op_name = op_name | |||
| self.rcond = rcond | |||
| def construct(self, a, b): | |||
| a = a.asnumpy() | |||
| b = b.asnumpy() | |||
| output = np.linalg.lstsq(a, b, rcond=self.rcond) | |||
| x = ms.Tensor(output[0]) | |||
| residuals = ms.Tensor(output[1]) | |||
| rank = ms.Tensor(output[2]) | |||
| s = ms.Tensor(output[3]) | |||
| return x, residuals, rank, s | |||
| def bprop(self, a, b, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| class NumpyEigvals(NumpyCommon): | |||
| def construct(self, A): | |||
| A_np = A.asnumpy() | |||
| output = np.linalg.eigvals(A_np) | |||
| if A_np.dtype is np.float64 or A_np.dtype is np.complex128: | |||
| output = output.astype(np.complex128) | |||
| else: | |||
| output = output.astype(np.complex64) | |||
| return ms.Tensor(output) | |||
| def bprop(self, A, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| def _svd_not_compute_uv(input, full_matrices=False): | |||
| input_np = input.asnumpy() | |||
| output = np.linalg.svd(input_np, full_matrices, compute_uv=False) | |||
| return ms.Tensor(output) | |||
| def _svd_compute_uv(input, full_matrices=False): | |||
| input_np = input.asnumpy() | |||
| output = np.linalg.svd(input_np, full_matrices, compute_uv=True) | |||
| u = ms.Tensor(output[0]) | |||
| s = ms.Tensor(output[1]) | |||
| v_np = output[2] | |||
| #TODO: Currently ms.ops.swapaxes has problem on GRAPH mode | |||
| v_np = np.swapaxes(v_np, -1, -2) | |||
| v = ms.Tensor(v_np) | |||
| return s, u, v | |||
| class NumpySvd(NumpyCommon): | |||
| def construct(self, input, full_matrices=False, compute_uv=True): | |||
| if compute_uv: | |||
| output = _svd_compute_uv(input, full_matrices) | |||
| else: | |||
| output = _svd_not_compute_uv(input, full_matrices) | |||
| return output | |||
| def bprop(self, input, full_matrices, compute_uv, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| class NumpySvdvals(NumpyCommon): | |||
| def construct(self, input, full_matrices=False): | |||
| output = _svd_not_compute_uv(input, full_matrices) | |||
| return output | |||
| def bprop(self, input, full_matrices, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| class NumpyI0(NumpyCommon): | |||
| def construct(self, A): | |||
| A_np = A.asnumpy() | |||
| output = ms.Tensor(np.i0(A_np)) | |||
| if A.dtype in msdapter_dtype.all_int_type: | |||
| output = output.astype(ms.float32) | |||
| return output | |||
| def bprop(self, A, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| class NumpyLU(NumpyCommon): | |||
| def construct(self, A, pivot): | |||
| A_np = A.asnumpy() | |||
| output = lu(A_np, permute_l=False, overwrite_a=False, check_finite=True) | |||
| p = ms.Tensor(output[0]).astype(A.dtype) | |||
| l = ms.Tensor(output[1]) | |||
| u = ms.Tensor(output[2]) | |||
| output = (p, l, u) if pivot else (l, u) | |||
| return output | |||
| def bprop(self, A, pivot, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| class NumpyLUSolve(NumpyCommon): | |||
| def construct(self, B, LU, pivots, adjoint=False): | |||
| B_np = B.asnumpy() | |||
| LU_np = LU.asnumpy() | |||
| pivots = pivots.asnumpy() - 1 | |||
| trans = 2 if adjoint else 0 | |||
| A = (LU_np, pivots) | |||
| output = lu_solve(A, B_np, trans) | |||
| return ms.Tensor(output) | |||
| def bprop(self, B, LU, pivots, adjoint, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| class NumpyLUFactor(NumpyCommon): | |||
| def construct(self, A): | |||
| A_np = A.asnumpy() | |||
| output = lu_factor(A_np, overwrite_a=False, check_finite=True) | |||
| lu = ms.Tensor(output[0]) | |||
| pivots = ms.Tensor(output[1]) + 1 | |||
| return lu, pivots | |||
| def bprop(self, A, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| class NumpyEigh(NumpyCommon): | |||
| def construct(self, A, lower=True, eigvals_only=True): | |||
| A_np = A.asnumpy() | |||
| UPLO = 'L' if lower else 'U' | |||
| output = np.linalg.eigh(A_np, UPLO=UPLO) | |||
| return ms.Tensor(output[0]) if eigvals_only else (ms.Tensor(output[0]), ms.Tensor(output[1])) | |||
| def bprop(self, A, lower, eigvals_only, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| class NumpyFmax(NumpyCommon): | |||
| def construct(self, input, other): | |||
| input = input.asnumpy() | |||
| other = other.asnumpy() | |||
| output = ms.Tensor(np.fmax(input, other)) | |||
| return output | |||
| def bprop(self, input, other, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| class NumpyFmin(NumpyCommon): | |||
| def construct(self, input, other): | |||
| input = input.asnumpy() | |||
| other = other.asnumpy() | |||
| output = ms.Tensor(np.fmin(input, other)) | |||
| return output | |||
| def bprop(self, input, other, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| class NumpyFft(NumpyCommon): | |||
| def construct(self, input, n, dim, norm): | |||
| input = input.asnumpy() | |||
| output = np.fft.fft(input, n, axis=dim, norm=norm) | |||
| if input.dtype not in (np.float64, np.complex128): | |||
| output = output.astype(np.complex64) | |||
| return ms.Tensor(output) | |||
| def bprop(self, input, n, dim, norm, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| class NumpyRfft(NumpyCommon): | |||
| def construct(self, input, n, dim, norm): | |||
| input = input.asnumpy() | |||
| output = np.fft.rfft(input, n, axis=dim, norm=norm) | |||
| if input.dtype not in (np.float64, np.complex128): | |||
| output = output.astype(np.complex64) | |||
| return ms.Tensor(output) | |||
| def bprop(self, input, n, dim, norm, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| class NumpySolve(NumpyCommon): | |||
| def construct(self, A, B): | |||
| A_np = A.asnumpy() | |||
| B_np = B.asnumpy() | |||
| output = ms.Tensor(np.linalg.solve(A_np, B_np)) | |||
| return output | |||
| def bprop(self, A, B, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| class NumpyPoisson(NumpyCommon): | |||
| def construct(self, input): | |||
| input_np = input.asnumpy() | |||
| output = ms.Tensor.from_numpy(np.random.poisson(input_np, None)).to(dtype=input.dtype) | |||
| return output | |||
| def bprop(self, input, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
| lstsq_op = NumpyLstsq('lstsq') | |||
| eigvals_op = NumpyEigvals('eigvals') | |||
| svd_op = NumpySvd('svd') | |||
| svdvals_op = NumpySvdvals('svdvals') | |||
| i0_op = NumpyI0('i0') | |||
| lu_op = NumpyLU('lu') | |||
| lu_solve_op = NumpyLUSolve('lu_solve') | |||
| lu_factor_op = NumpyLUFactor('lu_factor') | |||
| inner_lu_factor_op = NumpyLUFactor('lu') | |||
| lu_factor_ex_op = NumpyLUFactor('lu_factor_ex') | |||
| eigh_op = NumpyEigh('eigh') | |||
| symeig_op = NumpyEigh('symeig') | |||
| eigvalsh_op = NumpyEigh('eigvalsh') | |||
| fmax_op = NumpyFmax('fmax') | |||
| fmin_op = NumpyFmin('fmin') | |||
| fft_op = NumpyFft('fft') | |||
| rfft_op = NumpyRfft('rfft') | |||
| solve_op = NumpySolve('solve') | |||
| poisson_op = NumpyPoisson('poisson') | |||
ms_adapter/pytorch/_six.py → msadapter/pytorch/_six.py
View File
ms_adapter/pytorch/_utils.py → msadapter/pytorch/_utils.py
View File
+ 31
- 0
msadapter/pytorch/amp/__init__.py
View File
| @@ -0,0 +1,31 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import mindspore as ms | |||
| from msadapter.pytorch.nn import Module | |||
| from msadapter.pytorch.tensor import cast_to_adapter_tensor | |||
| all = [ | |||
| 'auto_mixed_precision' | |||
| ] | |||
| class _CastToAdapter(Module): | |||
| """Wrap amp net for msadapter, cast network from ms.nn.Cell to nn.Module.""" | |||
| def __init__(self, net): | |||
| super(_CastToAdapter, self).__init__() | |||
| self._ms_amp_net = net | |||
| def forward(self, *inputs): | |||
| output = self._ms_amp_net(*inputs) | |||
| return cast_to_adapter_tensor(output) | |||
| def auto_mixed_precision(network, amp_level="O0"): | |||
| """ | |||
| This API wraps ms.amp.auto_mixed_precision() for cast adapter type. | |||
| https://www.mindspore.cn/tutorials/zh-CN/r2.0/advanced/mixed_precision.html | |||
| """ | |||
| # This is an internal interface, only for debugging. | |||
| # After calling this API, use amp_net.trainable_params() to replace amp_net.parameters(). | |||
| amp_net = ms.amp.auto_mixed_precision(network, amp_level) | |||
| return _CastToAdapter(amp_net) | |||
ms_adapter/pytorch/autograd/__init__.py → msadapter/pytorch/autograd/__init__.py
View File
ms_adapter/pytorch/autograd/function.py → msadapter/pytorch/autograd/function.py
View File
| @@ -1,8 +1,8 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import warnings | |||
| from ms_adapter.utils import unsupported_attr | |||
| from ms_adapter.pytorch.nn import Module | |||
| from msadapter.utils import unsupported_attr | |||
| from msadapter.pytorch.nn import Module | |||
| class Function(Module): | |||
ms_adapter/pytorch/autograd/variable.py → msadapter/pytorch/autograd/variable.py
View File
| @@ -1,7 +1,7 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from ms_adapter.utils import unsupported_attr | |||
| from ms_adapter.pytorch.tensor import Tensor | |||
| from msadapter.utils import unsupported_attr | |||
| from msadapter.pytorch.tensor import Tensor | |||
| class Variable(Tensor): | |||
+ 29
- 0
msadapter/pytorch/common/__init__.py
View File
| @@ -0,0 +1,29 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from msadapter.pytorch.common.dtype import * | |||
| from msadapter.pytorch.common.device import * | |||
| # Variables with simple values, from math.py. | |||
| e = 2.718281828459045 | |||
| pi = 3.141592653589793 | |||
| tau = 6.28318530717958 | |||
| __all__ = ["float", "double", | |||
| "float16", "float32", | |||
| "float64", "int8", | |||
| "int16", "int32", | |||
| "int64", "uint8", | |||
| "bool_", "complex64", | |||
| "complex128", "long", | |||
| "bfloat16", "cfloat", | |||
| "cdouble", "half", | |||
| "short", "int", | |||
| "bool", "iinfo", | |||
| "finfo", "Device", | |||
| "nan", "inf", | |||
| "e", "pi", "tau", | |||
| ] | |||
ms_adapter/pytorch/common/_inner.py → msadapter/pytorch/common/_inner.py
View File
| @@ -1,8 +1,8 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from mindspore.ops import constexpr | |||
| from ms_adapter.pytorch.tensor import cast_to_adapter_tensor | |||
| from ms_adapter.utils import pynative_mode_condition, graph_mode_condition | |||
| from mindspore.ops.primitive import _primexpr | |||
| from msadapter.pytorch.tensor import cast_to_adapter_tensor, Tensor | |||
| from msadapter.utils import pynative_mode_condition, graph_mode_condition | |||
| def _out_limit_pynative(out, op_name): | |||
| @@ -11,17 +11,39 @@ def _out_limit_pynative(out, op_name): | |||
| 'please set out=None and use return value instead of `out`.'.format(op_name)) | |||
| def _out_inplace_assign(out, output, op_name): | |||
| if out is None: | |||
| return cast_to_adapter_tensor(output) | |||
| def _out_assign_with_output(out, output, op_name): | |||
| if pynative_mode_condition(): # TODO: ms_function | |||
| out.assign_value(output) | |||
| def _assign(out, output): | |||
| if isinstance(out, Tensor): | |||
| # Pass `cast_to_ms_tensor(output)` for performance, add it back when needed. | |||
| out.assign_value(output) | |||
| elif isinstance(out, (tuple, list)): | |||
| for item in zip(out, output): | |||
| _assign(item[0], item[1]) | |||
| _assign(out, output) | |||
| return out | |||
| raise ValueError('In MindSpore static graph mode, `out` in `{}` shoud be None, ' | |||
| 'please set out=None and use return value instead of `out`.'.format(op_name)) | |||
| def _out_inplace_assign_with_adapter_tensor(out, output, op_name): | |||
| r''' | |||
| Use for assign `out` with `output` when `output` is(are) Adapter Tensor(s). | |||
| ''' | |||
| if out is None: | |||
| return output | |||
| return _out_assign_with_output(out, output, op_name) | |||
| def _out_inplace_assign(out, output, op_name): | |||
| r''' | |||
| Use for assign `out` with `output` when `output` is(are) MindSpore Tensor(s) | |||
| ''' | |||
| if out is None: | |||
| return cast_to_adapter_tensor(output) | |||
| return _out_assign_with_output(out, output, op_name) | |||
| def _inplace_assign_pynative(input, inplace, output, op_name): | |||
| if inplace is True: | |||
| @@ -35,7 +57,16 @@ def _inplace_assign_pynative(input, inplace, output, op_name): | |||
| return cast_to_adapter_tensor(output) | |||
| @constexpr | |||
| def _nn_functional_inplace_assign(input, output, op_name, replace_op): | |||
| if pynative_mode_condition(): # TODO: ms_function | |||
| input.assign_value(output) | |||
| return input | |||
| raise RuntimeError('`nn.functional.{a}` is an in-place operation and "nn.functional.{a}(x)" is not supported ' | |||
| 'to use in MindSpore static graph mode. Please use "x = nn.functional.{b}(x)" or other API ' | |||
| 'instead.'.format(a=op_name, b=replace_op)) | |||
| @_primexpr | |||
| def _inplace_limit_pynative(inplace, op_name): | |||
| if inplace is True and graph_mode_condition(): # TODO: ms_function | |||
| raise ValueError('In MindSpore static graph mode, `inplace` in `{}` shoud not be Ture, ' | |||
ms_adapter/pytorch/common/device.py → msadapter/pytorch/common/device.py
View File
+ 129
- 0
msadapter/pytorch/common/dtype.py
View File
| @@ -0,0 +1,129 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import numpy as np | |||
| from mindspore import dtype as mstype | |||
| from mindspore.ops.primitive import _primexpr | |||
| ms_dtype = mstype.Type | |||
| inf = float('inf') | |||
| nan = float('nan') | |||
| float = mstype.float32 | |||
| double = mstype.float64 | |||
| float16 = mstype.float16 | |||
| # TODO: mindspore to support mstype.bfloat16 | |||
| bfloat16 = mstype.float32 | |||
| float32 = mstype.float32 | |||
| float64 = mstype.float64 | |||
| int8 = mstype.int8 | |||
| int16 = mstype.int16 | |||
| int32 = mstype.int32 | |||
| int64 = mstype.int64 | |||
| uint8 = mstype.uint8 | |||
| bool_ = mstype.bool_ | |||
| complex64 = mstype.complex64 | |||
| complex128 = mstype.complex128 | |||
| long = mstype.int64 | |||
| cfloat = mstype.complex64 | |||
| cdouble = mstype.complex128 | |||
| half = mstype.half | |||
| short = mstype.short | |||
| int = mstype.int32 | |||
| bool = mstype.bool_ | |||
| char = mstype.uint8 | |||
| all_int_type = (mstype.int8, mstype.int16, mstype.int32, mstype.int64, mstype.uint8, ) | |||
| all_int_type_with_bool = all_int_type + (mstype.bool_,) | |||
| all_float_type = (mstype.float16, mstype.float32, mstype.float64, ) | |||
| all_complex_type = (mstype.complex64, mstype.complex128, ) | |||
| _TypeDict = {mstype.float16: np.float16, | |||
| mstype.float32: np.float32, | |||
| mstype.float64: np.float64, | |||
| mstype.int8: np.int8, | |||
| mstype.int16: np.int16, | |||
| mstype.int32: np.int32, | |||
| mstype.int64: np.int64, | |||
| mstype.uint8: np.uint8} | |||
| class iinfo: | |||
| def __init__(self, dtype): | |||
| if dtype in (mstype.uint8, mstype.int8, mstype.int16, mstype.int32, mstype.int64): | |||
| np_iinfo = np.iinfo(_TypeDict[dtype]) | |||
| self.bits = np_iinfo.bits | |||
| self.max = np_iinfo.max | |||
| self.min = np_iinfo.min | |||
| else: | |||
| raise ValueError("iinfo currently only supports torch.uint8/torch.int8/torch.int16/torch.int32/" | |||
| "torch.int64 as the input, but get a", dtype) | |||
| class finfo: | |||
| def __init__(self, dtype): | |||
| if dtype in (mstype.float16, mstype.float32, mstype.float64): | |||
| np_finfo = np.finfo(_TypeDict[dtype]) | |||
| self.bits = np_finfo.bits | |||
| self.eps = np_finfo.eps.item() | |||
| self.max = np_finfo.max.item() | |||
| self.min = np_finfo.min.item() | |||
| self.tiny = np_finfo.tiny.item() | |||
| # TODO: numpy vision >= 1.23 | |||
| # self.smallest_normal = np_finfo.smallest_normal | |||
| self.resolution = np_finfo.resolution.item() | |||
| else: | |||
| raise ValueError("finfo currently only supports torch.float16/torch.float32/" | |||
| "torch.float64 as the input, but get a", dtype) | |||
| _dtype2typeDict = { | |||
| 'float32': 'FloatTensor', | |||
| 'float': 'FloatTensor', | |||
| 'float64': 'DoubleTensor', | |||
| 'double': 'DoubleTensor', | |||
| 'complex64': 'ComplexFloatTensor', | |||
| 'cfloat': 'ComplexFloatTensor', | |||
| 'complex128': 'ComplexDoubleTensor', | |||
| 'cdouble': 'ComplexDoubleTensor', | |||
| 'float16': 'HalfTensor', | |||
| 'half': 'HalfTensor', | |||
| 'bfloat16': 'BFloat16Tensor', | |||
| 'uint8': 'ByteTensor', | |||
| 'int8': 'CharTensor', | |||
| 'int16': 'ShortTensor', | |||
| 'short': 'ShortTensor', | |||
| 'int32': 'IntTensor', | |||
| 'int': 'IntTensor', | |||
| 'int64': 'LongTensor', | |||
| 'long': 'LongTensor', | |||
| 'bool': 'BoolTensor' | |||
| } | |||
| _type2dtypeDict = { | |||
| 'FloatTensor': float32, | |||
| 'DoubleTensor': float64, | |||
| 'ComplexFloatTensor': complex64, | |||
| 'ComplexDoubleTensor': complex128, | |||
| 'HalfTensor': float16, | |||
| 'BFloat16Tensor': bfloat16, | |||
| 'ByteTensor': uint8, | |||
| 'CharTensor' : int8, | |||
| 'ShortTensor': int16, | |||
| 'IntTensor': int32, | |||
| 'LongTensor': int64, | |||
| 'BoolTensor': bool | |||
| } | |||
| @_primexpr | |||
| def _get_type_from_dtype(dtype): | |||
| str_dtype = str(dtype).split('.')[-1].lower() | |||
| _type = _dtype2typeDict.get(str_dtype) | |||
| return _type | |||
| @_primexpr | |||
| def _get_dtype_from_type(type): | |||
| _dtype = _type2dtypeDict.get(type, 'None') | |||
| if _dtype == 'None': | |||
| _dtype = type | |||
| return _dtype | |||
ms_adapter/pytorch/conflict_functional.py → msadapter/pytorch/conflict_functional.py
View File
| @@ -2,9 +2,8 @@ | |||
| # -*- coding: utf-8 -*- | |||
| import mindspore as ms | |||
| from mindspore.common import dtype as mstype | |||
| from ms_adapter.utils import unsupported_attr | |||
| from ms_adapter.pytorch.common._inner import _out_inplace_assign | |||
| from msadapter.utils import unsupported_attr | |||
| from msadapter.pytorch.common._inner import _out_inplace_assign | |||
| def range(start, end, step=1, out=None, dtype=None, layout=None, device=None, requires_grad=False): | |||
| @@ -23,27 +22,13 @@ def range(start, end, step=1, out=None, dtype=None, layout=None, device=None, re | |||
| return _out_inplace_assign(out, output, "range") | |||
| def arange(start, end, step=1, *, out=None, dtype=None, | |||
| def arange(start, end=None, step=1, *, out=None, dtype=None, | |||
| layout=None, device=None, requires_grad=False): | |||
| unsupported_attr(layout) | |||
| unsupported_attr(device) | |||
| unsupported_attr(requires_grad) | |||
| # TODO: use code below in future version | |||
| # output = ms.ops.arange(start, end, step) | |||
| # return _out_inplace_assign(out, output, "arange") | |||
| if dtype is None: | |||
| if isinstance(start, float) or isinstance(end, float) or isinstance(step, float): | |||
| dtype = mstype.float32 | |||
| else: | |||
| #TODO | |||
| # For now, `range` do not support `mstype.int64`, it should be changed | |||
| # to 'dtype = mstype.int64' in mindspore 2.0 | |||
| dtype = mstype.int32 | |||
| start = ms.Tensor(start, dtype) | |||
| end = ms.Tensor(end, dtype) | |||
| step = ms.Tensor(step, dtype) | |||
| output = ms.ops.range(start=start, limit=end, delta=step) | |||
| if end is None: | |||
| end = start | |||
| start = 0 | |||
| output = ms.ops.arange(start=start, end=end, step=step, dtype=dtype) | |||
| return _out_inplace_assign(out, output, "arange") | |||
+ 36
- 0
msadapter/pytorch/cuda/__init__.py
View File
| @@ -0,0 +1,36 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import mindspore as ms | |||
| from mindspore.communication.management import init, get_group_size | |||
| from msadapter.utils import get_backend | |||
| from msadapter.pytorch.tensor import BoolTensor, ByteTensor, CharTensor, ShortTensor, IntTensor, HalfTensor, \ | |||
| FloatTensor, DoubleTensor, LongTensor | |||
| def is_available(): | |||
| backend = get_backend() | |||
| if backend in ('GPU', 'Ascend') : | |||
| return True | |||
| return False | |||
| def current_device(): | |||
| return 0 | |||
| def device_count(): | |||
| # TODO Use this method when supported | |||
| # init() | |||
| # return get_group_size() | |||
| return 1 | |||
| def set_device(device): | |||
| if isinstance(device, int): | |||
| ms.context.set_context(device_id=device) | |||
| elif device in ("gpu", 'GPU'): | |||
| ms.context.set_context(device_target="GPU") | |||
| elif device in ("cpu", "CPU"): | |||
| ms.context.set_context(device_target="CPU") | |||
| elif device in ("ascend", "Ascend"): | |||
| ms.context.set_context(device_target="Ascend") | |||
| else: | |||
| raise ValueError("device must be cpu, gpu, ascend or CPU, GPU, Ascend.") | |||
ms_adapter/pytorch/fft/__init__.py → msadapter/pytorch/fft/__init__.py
View File
| @@ -3,4 +3,5 @@ | |||
| from .fft import * | |||
| __all__ = ['fft'] | |||
| __all__ = ['fft', | |||
| 'rfft'] | |||
+ 18
- 0
msadapter/pytorch/fft/fft.py
View File
| @@ -0,0 +1,18 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import mindspore as ms | |||
| from msadapter.pytorch.common._inner import _out_inplace_assign | |||
| from msadapter.pytorch._register_numpy_primitive import fft_op, rfft_op | |||
| def fft(input, n=None, dim=-1, norm=None, out=None): | |||
| # TODO: To use ms.ops.fft after it support | |||
| output = fft_op(input, n, dim, norm) | |||
| return _out_inplace_assign(out, output, "fft") | |||
| def rfft(input, n=None, dim=-1, norm=None, *, out=None): | |||
| # TODO: To use ms.ops.rfft after it support | |||
| output = rfft_op(input, n, dim, norm) | |||
| return _out_inplace_assign(out, ms.Tensor(output), "rfft") | |||
+ 2993
- 0
msadapter/pytorch/functional.py
File diff suppressed because it is too large
View File
+ 104
- 0
msadapter/pytorch/hub.py
View File
| @@ -0,0 +1,104 @@ | |||
| import hashlib | |||
| import os | |||
| import shutil | |||
| import sys | |||
| import tempfile | |||
| from urllib.request import urlopen, Request | |||
| try: | |||
| from tqdm.auto import tqdm # automatically select proper tqdm submodule if available | |||
| except ImportError: | |||
| try: | |||
| from tqdm import tqdm | |||
| except ImportError: | |||
| # fake tqdm if it's not installed | |||
| class tqdm(): # type: ignore[no-redef] | |||
| def __init__(self, total=None, disable=False, | |||
| unit=None, unit_scale=None, unit_divisor=None): | |||
| self.total = total | |||
| self.disable = disable | |||
| self.n = 0 | |||
| self.unit = unit | |||
| self.unit_scale = unit_scale | |||
| self.unit_divisor = unit_divisor | |||
| # ignore unit, unit_scale, unit_divisor; they're just for real tqdm | |||
| def update(self, n): | |||
| if self.disable: | |||
| return | |||
| self.n += n | |||
| if self.total is None: | |||
| sys.stderr.write("\r{0:.1f} bytes".format(self.n)) | |||
| else: | |||
| sys.stderr.write("\r{0:.1f}%".format(100 * self.n / float(self.total))) | |||
| sys.stderr.flush() | |||
| def close(self): | |||
| self.disable = True | |||
| def __enter__(self): | |||
| return self | |||
| def __exit__(self, exc_type, exc_val, exc_tb): | |||
| if self.disable: | |||
| return | |||
| sys.stderr.write('\n') | |||
| def download_url_to_file(url, dst, hash_prefix=None, progress=True): | |||
| r"""Download object at the given URL to a local path. | |||
| Args: | |||
| url (string): URL of the object to download | |||
| dst (string): Full path where object will be saved, e.g. ``/tmp/temporary_file`` | |||
| hash_prefix (string, optional): If not None, the SHA256 downloaded file should start with ``hash_prefix``. | |||
| Default: None | |||
| progress (bool, optional): whether or not to display a progress bar to stderr | |||
| Default: True | |||
| """ | |||
| file_size = None | |||
| req = Request(url, headers={"User-Agent": "torch.hub"}) | |||
| u = urlopen(req) | |||
| meta = u.info() | |||
| if hasattr(meta, 'getheaders'): | |||
| content_length = meta.getheaders("Content-Length") | |||
| else: | |||
| content_length = meta.get_all("Content-Length") | |||
| if content_length is not None and len(content_length) > 0: | |||
| file_size = int(content_length[0]) | |||
| # We deliberately save it in a temp file and move it after | |||
| # download is complete. This prevents a local working checkpoint | |||
| # being overridden by a broken download. | |||
| dst = os.path.expanduser(dst) | |||
| dst_dir = os.path.dirname(dst) | |||
| f = tempfile.NamedTemporaryFile(delete=False, dir=dst_dir) | |||
| try: | |||
| if hash_prefix is not None: | |||
| sha256 = hashlib.sha256() | |||
| with tqdm(total=file_size, disable=not progress, | |||
| unit='B', unit_scale=True, unit_divisor=1024) as pbar: | |||
| while True: | |||
| buffer = u.read(8192) | |||
| if len(buffer) == 0: | |||
| break | |||
| f.write(buffer) | |||
| if hash_prefix is not None: | |||
| sha256.update(buffer) | |||
| pbar.update(len(buffer)) | |||
| f.close() | |||
| if hash_prefix is not None: | |||
| digest = sha256.hexdigest() | |||
| if digest[:len(hash_prefix)] != hash_prefix: | |||
| raise RuntimeError('invalid hash value (expected "{}", got "{}")' | |||
| .format(hash_prefix, digest)) | |||
| shutil.move(f.name, dst) | |||
| finally: | |||
| f.close() | |||
| if os.path.exists(f.name): | |||
| os.remove(f.name) | |||
+ 31
- 0
msadapter/pytorch/linalg/__init__.py
View File
| @@ -0,0 +1,31 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from .linalg import * | |||
| __all__ = ['eigh', | |||
| 'solve', | |||
| 'eig', | |||
| 'slogdet', | |||
| 'det', | |||
| 'cholesky', | |||
| 'inv', | |||
| 'matmul', | |||
| 'multi_dot', | |||
| 'householder_product', | |||
| 'diagonal', | |||
| 'lu', | |||
| 'lu_factor', | |||
| 'lu_factor_ex', | |||
| 'lu_solve', | |||
| 'lstsq', | |||
| 'qr', | |||
| 'vander', | |||
| 'eigvals', | |||
| 'svd', | |||
| 'svdvals', | |||
| 'matrix_power', | |||
| 'pinv', | |||
| 'eigvalsh', | |||
| 'norm', | |||
| 'vector_norm'] | |||
+ 230
- 0
msadapter/pytorch/linalg/linalg.py
View File
| @@ -0,0 +1,230 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import mindspore as ms | |||
| from mindspore.ops.primitive import _primexpr | |||
| from msadapter.pytorch.common._inner import _out_inplace_assign | |||
| from msadapter.utils import unsupported_attr, pynative_mode_condition, \ | |||
| is_under_gpu_context, is_under_ascend_context, set_multiple_name_tuple | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor, custom_matmul | |||
| from msadapter.pytorch.tensor import Tensor as adapter_tensor | |||
| from msadapter.pytorch._register_numpy_primitive import NumpyFullLstsq, eigvals_op, svd_op, svdvals_op, \ | |||
| lu_solve_op, lu_op, lu_factor_op, lu_factor_ex_op, \ | |||
| eigh_op, eigvalsh_op, solve_op | |||
| def eigh(A, UPLO='L', *, out=None): # TODO use numpy api now | |||
| lower = bool(UPLO == 'L') | |||
| output = eigh_op(A, lower, False) | |||
| return _out_inplace_assign(out, output, "eigh") | |||
| def solve(A, B, *, left=True, out=None):# TODO use numpy api now | |||
| unsupported_attr(left) | |||
| output = solve_op(A, B) | |||
| return _out_inplace_assign(out, output, "solve") | |||
| #TODO: eig currently not support on GPU | |||
| def eig(A, *, out=None): | |||
| if is_under_gpu_context(): | |||
| raise NotImplementedError("for adapter, eig not supported on GPU") | |||
| input = cast_to_ms_tensor(A) | |||
| output = ms.ops.eig(input) | |||
| return _out_inplace_assign(out, output, "eig") | |||
| def slogdet(A, *, out=None): | |||
| A = cast_to_ms_tensor(A) | |||
| sign, output = ms.ops.slogdet(A) | |||
| return _out_inplace_assign(out, (sign, output), "slogdet") | |||
| def det(A, *, out=None): | |||
| A = cast_to_ms_tensor(A) | |||
| output = ms.ops.det(A) | |||
| return _out_inplace_assign(out, output, "det") | |||
| def cholesky(A, *, upper=False, out=None): | |||
| # TODO: ms.ops.cholesky to support complex type | |||
| A = cast_to_ms_tensor(A) | |||
| output = ms.ops.cholesky(A, upper) | |||
| return _out_inplace_assign(out, output, "cholesky") | |||
| def inv(A, *, out=None): | |||
| A = cast_to_ms_tensor(A) | |||
| output = ms.ops.inverse(A) | |||
| return _out_inplace_assign(out, output, "inv") | |||
| def matmul(input, other, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| other = cast_to_ms_tensor(other) | |||
| # TODO: repalce with output = ms.ops.matmul(input, other) | |||
| output = custom_matmul(input, other) | |||
| return _out_inplace_assign(out, output, "matmul") | |||
| def diagonal(A, *, offset=0, dim1=-2, dim2=-1): | |||
| A = cast_to_ms_tensor(A) | |||
| output = ms.ops.diagonal(A, offset=offset, dim1=dim1, dim2=dim2) | |||
| return cast_to_adapter_tensor(output) | |||
| def multi_dot(tensors, *, out=None): | |||
| input = cast_to_ms_tensor(tensors) | |||
| output = ms.numpy.multi_dot(input) | |||
| return _out_inplace_assign(out, output, "multi_dot") | |||
| def householder_product(A, tau, *, out=None): | |||
| input = cast_to_ms_tensor(A) | |||
| input2 = cast_to_ms_tensor(tau) | |||
| output = ms.ops.orgqr(input, input2) | |||
| return _out_inplace_assign(out, output, "householder_product") | |||
| #TODO: Currently not support 3-D (*, M, N) input | |||
| def lu(A, *, pivot=True, out=None): | |||
| output = lu_op(A, pivot) | |||
| return _out_inplace_assign(out, output, "lu") | |||
| #TODO: Currently not support 3-D (*, M, N) input | |||
| def lu_factor(A, *, pivot=True, out=None): | |||
| #TODO: Mindspore does not support pivot=False condition | |||
| if not pivot: | |||
| raise NotImplementedError("lu_factor currently not supported pivot=False") | |||
| output = lu_factor_op(A) | |||
| return _out_inplace_assign(out, output, "lu_factor") | |||
| #TODO: Currently not support 3-D (*, M, N) input | |||
| #TODO: currently lu_factor not support check_errors | |||
| def lu_factor_ex(A, *, pivot=True, check_errors=False, out=None): | |||
| #TODO: Mindspore does not support pivot=False condition | |||
| if not pivot: | |||
| raise NotImplementedError("lu_factor_ex currently not supported pivot=False") | |||
| if check_errors: | |||
| raise NotImplementedError("lu_factor_ex currently not supported check_errors=True") | |||
| lu, pivots = lu_factor_ex_op(A) | |||
| output = (lu, pivots, 0) | |||
| return _out_inplace_assign(out, output, "lu_factor_ex") | |||
| def lu_solve(B, LU, pivots, *, left=True, adjoint=False, out=None): | |||
| #TODO: Currently does not support left | |||
| if not left: | |||
| raise NotImplementedError("lu_solve currently not supported left=False") | |||
| output = lu_solve_op(B, LU, pivots, adjoint=adjoint) | |||
| return _out_inplace_assign(out, output, "lu_solve") | |||
| def lstsq(a, b, rcond=None, *, out=None): | |||
| lstsq_op = NumpyFullLstsq('lstsq', rcond) | |||
| x, residuals, rank, s = lstsq_op(a, b) | |||
| rank = int(rank) | |||
| return _out_inplace_assign(out, (x, residuals, rank, s), "lstsq") | |||
| def qr(input, mode="reduced", *, out=None): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| output = ms.ops.qr(input_ms, mode) | |||
| return _out_inplace_assign(out, output, "qr") | |||
| def vander(x, N=None, *, out=None): | |||
| x = cast_to_ms_tensor(x) | |||
| #TODO: need to use ops func | |||
| output = ms.numpy.vander(x, N, increasing=True) | |||
| return _out_inplace_assign(out, output, "vander") | |||
| def eigvals(A, *, out=None): | |||
| A = cast_to_ms_tensor(A) | |||
| #TODO: eigvals currently not support | |||
| if not is_under_gpu_context(): | |||
| output, _ = ms.ops.eig(A) | |||
| else: | |||
| #TODO: not support backward | |||
| output = eigvals_op(A) | |||
| if A.dtype in (ms.float64, ms.complex128): | |||
| output = output.astype(ms.complex128) | |||
| return _out_inplace_assign(out, output, "eigvals") | |||
| def svd(A, full_matrices=True, *, driver=None, out=None): | |||
| #TODO: not support driver is not None | |||
| if driver is not None: | |||
| raise NotImplementedError("Currently only support driver equals to none") | |||
| input = cast_to_ms_tensor(A) | |||
| if is_under_ascend_context(): | |||
| s, u, v = svd_op(input, full_matrices) | |||
| else: | |||
| s, u, v = ms.ops.svd(input, full_matrices=full_matrices) | |||
| v = ms.ops.swapaxes(v, -1, -2) | |||
| output = (u, s, v) | |||
| if pynative_mode_condition(): | |||
| svd_namedtuple = set_multiple_name_tuple('svd', 'U, S, Vh') | |||
| output = svd_namedtuple(cast_to_adapter_tensor(u), cast_to_adapter_tensor(s), cast_to_adapter_tensor(v)) | |||
| return output | |||
| return _out_inplace_assign(out, output, "svd") | |||
| def svdvals(A, *, driver=None, out=None): | |||
| #TODO: not support driver is not None | |||
| if driver is not None: | |||
| raise NotImplementedError("Currently only support driver equals to none") | |||
| input = cast_to_ms_tensor(A) | |||
| if is_under_ascend_context(): | |||
| output = svdvals_op(input) | |||
| else: | |||
| output = ms.ops.svd(input, compute_uv=False) | |||
| return _out_inplace_assign(out, output, "svdvals") | |||
| def matrix_power(input, n, *, out=None): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| input_type = input_ms.dtype | |||
| if input_type not in (ms.float32, ms.float16): | |||
| input_ms = input_ms.astype(ms.float32) | |||
| if not is_under_gpu_context(): | |||
| output = ms.ops.matrix_power(input_ms, n) | |||
| else: | |||
| #TODO: used ops func on GPU | |||
| output = ms.numpy.matrix_power(input_ms, n) | |||
| if input_type not in (ms.float32, ms.float16): | |||
| output = output.astype(input_type) | |||
| return _out_inplace_assign(out, output, "matrix_power") | |||
| #TODO: pinv currently not support on Ascend | |||
| def pinv(A, *, atol=None, rtol=None, hermitian=False, out=None): | |||
| if is_under_ascend_context(): | |||
| raise NotImplementedError("pinverse currently not supported on Ascend") | |||
| A = cast_to_ms_tensor(A) | |||
| output = ms.ops.pinv(A, atol=atol, rtol=rtol, hermitian=hermitian) | |||
| return _out_inplace_assign(out, output, "pinv") | |||
| def eigvalsh(A, UPLO='L', *, out=None): | |||
| A = cast_to_ms_tensor(A) | |||
| lower = bool(UPLO == 'L') | |||
| output = eigvalsh_op(A, lower, True) | |||
| if output.dtype in (ms.complex64, ms.complex128): | |||
| output = output.real() | |||
| return _out_inplace_assign(out, output, "eigvalsh") | |||
| def norm(A, ord=None, dim=None, keepdim=False, *, out=None, dtype=None): | |||
| A = cast_to_ms_tensor(A) | |||
| output = ms.ops.norm(A, ord=ord, dim=dim, keepdim=keepdim, dtype=dtype) | |||
| output = output.astype(A.dtype) | |||
| return _out_inplace_assign(out, output, "norm") | |||
| def vector_norm(A, ord=2, dim=None, keepdim=False, *, dtype=None, out=None): | |||
| A = cast_to_ms_tensor(A) | |||
| if dim is None: | |||
| A = A.flatten() | |||
| output = ms.ops.norm(A, ord=ord, dim=dim, keepdim=keepdim, dtype=dtype) | |||
| return _out_inplace_assign(out, output, "vector_norm") | |||
| @_primexpr | |||
| # @lru_cache(_GLOBAL_LRU_CACHE_SIZE) | |||
| def _check_vecdot_input_validity(x, y, dim): | |||
| if not isinstance(x, adapter_tensor) or not isinstance(y, adapter_tensor): | |||
| raise TypeError("For vecdot, x or y must be Tensor.") | |||
| if not isinstance(dim, int): | |||
| raise TypeError(f"For vecdot, the dim should be int, but got {type(dim)}.") | |||
| ndim = x.ndim if x.ndim > y.ndim else y.ndim | |||
| if dim < -ndim or dim >= ndim: | |||
| raise ValueError("For vecdot, the dim is out of range.") | |||
| # TODO: vecdot is only supported in torch2.0 | |||
| def vecdot(x, y, *, dim=- 1, out=None): | |||
| _check_vecdot_input_validity(x, y, dim) | |||
| x = cast_to_ms_tensor(x) | |||
| y = cast_to_ms_tensor(y) | |||
| if x.dtype == ms.complex64 or x.dtype == ms.complex128: | |||
| x = x.conj() | |||
| output = x * y | |||
| output = output.sum(axis=dim) | |||
| return _out_inplace_assign(out, output, "vecdot") | |||
+ 8
- 0
msadapter/pytorch/nn/__init__.py
View File
| @@ -0,0 +1,8 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from .modules import * | |||
| from .parameter import Parameter, ParameterTuple | |||
| from . import init | |||
| from . import functional | |||
| from . import utils | |||
+ 2605
- 0
msadapter/pytorch/nn/functional.py
File diff suppressed because it is too large
View File
ms_adapter/pytorch/nn/init.py → msadapter/pytorch/nn/init.py
View File
| @@ -2,6 +2,8 @@ | |||
| # -*- coding: utf-8 -*- | |||
| import warnings | |||
| import math | |||
| import mindspore as ms | |||
| from mindspore.common.initializer import initializer, Dirac, Orthogonal | |||
| def _calculate_fan_in_and_fan_out(tensor): | |||
| @@ -22,27 +24,24 @@ def _calculate_fan_in_and_fan_out(tensor): | |||
| def calculate_gain(nonlinearity, param=None): | |||
| linear_fns = ['linear', 'conv1d', 'conv2d', 'conv3d', 'conv_transpose1d', 'conv_transpose2d', 'conv_transpose3d'] | |||
| if nonlinearity in linear_fns or nonlinearity == 'sigmoid': | |||
| res = 1 | |||
| return 1 | |||
| elif nonlinearity == 'tanh': | |||
| res = 5.0 / 3 | |||
| return 5.0 / 3 | |||
| elif nonlinearity == 'relu': | |||
| res = math.sqrt(2.0) | |||
| return math.sqrt(2.0) | |||
| elif nonlinearity == 'leaky_relu': | |||
| if param is None: | |||
| negative_slope = 0.01 | |||
| elif not isinstance(param, bool) and isinstance(param, int) or isinstance(param, float): | |||
| # True/False are instances of int, hence check above | |||
| negative_slope = param | |||
| else: | |||
| raise ValueError("For 'HeUniform', 'negative_slope' {} is not a valid number." | |||
| "When 'nonlinearity' has been set to " | |||
| "'leaky_relu', 'negative_slope' should be int or float type, but got " | |||
| "{}.".format(param, type(param))) | |||
| res = math.sqrt(2.0 / (1 + negative_slope ** 2)) | |||
| raise ValueError("negative_slope {} not a valid number".format(param)) | |||
| return math.sqrt(2.0 / (1 + negative_slope ** 2)) | |||
| elif nonlinearity == 'selu': | |||
| return 3.0 / 4 | |||
| else: | |||
| raise ValueError("For 'HeUniform', the argument 'nonlinearity' should be one of " | |||
| "['sigmoid', 'tanh', 'relu' or 'leaky_relu'], " | |||
| "but got {}.".format(nonlinearity)) | |||
| return res | |||
| raise ValueError("Unsupported nonlinearity {}".format(nonlinearity)) | |||
| def _no_grad_trunc_normal_(tensor, mean, std, a, b): | |||
| @@ -65,18 +64,19 @@ def _no_grad_trunc_normal_(tensor, mean, std, a, b): | |||
| # Uniformly fill tensor with values from [l, u], then translate to | |||
| # [2l-1, 2u-1]. | |||
| tensor = tensor.uniform_(2 * l - 1, 2 * u - 1) | |||
| tensor_outplace = tensor.uniform_adapter(2 * l - 1, 2 * u - 1) | |||
| # Use inverse cdf transform for normal distribution to get truncated | |||
| # standard normal | |||
| tensor.erfinv_() | |||
| tensor_outplace = tensor_outplace.erfinv() | |||
| # Transform to proper mean, std | |||
| tensor.mul_(std * math.sqrt(2.)) | |||
| tensor.add_(mean) | |||
| tensor_outplace = tensor_outplace.mul(std * math.sqrt(2.)) | |||
| tensor_outplace = tensor_outplace.add(mean) | |||
| # Clamp to ensure it's in the proper range | |||
| tensor.clamp_(min=a, max=b) | |||
| tensor_outplace = tensor_outplace.clamp(min=a, max=b) | |||
| tensor.assign_value(tensor_outplace) | |||
| return tensor | |||
| def _calculate_correct_fan(tensor, mode): | |||
| @@ -97,47 +97,68 @@ def kaiming_uniform_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu'): | |||
| gain = calculate_gain(nonlinearity, a) | |||
| std = gain / math.sqrt(fan) | |||
| bound = math.sqrt(3.0) * std # Calculate uniform bounds from standard deviation | |||
| return tensor.uniform_(-bound, bound) | |||
| tensor_outplace = tensor.uniform_adapter(-bound, bound) | |||
| return tensor.assign_value(tensor_outplace) | |||
| def kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu'): | |||
| if 0 in tensor.shape: | |||
| warnings.warn("Initializing zero-element tensors is a no-op") | |||
| return tensor | |||
| fan = _calculate_correct_fan(tensor, mode) | |||
| gain = calculate_gain(nonlinearity, a) | |||
| std = gain / math.sqrt(fan) | |||
| return tensor.normal_(0, std) | |||
| tensor_outplace = tensor.normal_adapter(0, std) | |||
| return tensor.assign_value(tensor_outplace) | |||
| def xavier_normal_(tensor, gain = 1.): | |||
| fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor) | |||
| std = gain * math.sqrt(2.0 / float(fan_in + fan_out)) | |||
| return tensor.normal_(0., std) | |||
| tensor_outplace = tensor.normal_adapter(0., std) | |||
| return tensor.assign_value(tensor_outplace) | |||
| def xavier_uniform_(tensor, gain = 1.): | |||
| fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor) | |||
| std = gain * math.sqrt(2.0 / float(fan_in + fan_out)) | |||
| a = math.sqrt(3.0) * std # Calculate uniform bounds from standard deviation | |||
| return tensor.uniform_(-a, a) | |||
| tensor_outplace = tensor.uniform_adapter(-a, a) | |||
| return tensor.assign_value(tensor_outplace) | |||
| def zeros_(tensor): | |||
| return tensor.zero_() | |||
| tensor_outplace = tensor.zero_adapter() | |||
| return tensor.assign_value(tensor_outplace) | |||
| def ones_(tensor): | |||
| return tensor.fill_(1.0) | |||
| tensor_outplace = tensor.fill_adapter(1.0) | |||
| return tensor.assign_value(tensor_outplace) | |||
| def constant_(tensor, val): | |||
| return tensor.fill_(val) | |||
| tensor_outplace = tensor.fill_adapter(val) | |||
| return tensor.assign_value(tensor_outplace) | |||
| def trunc_normal_(tensor, mean = 0., std = 1., a = -2., b = 2.): | |||
| return _no_grad_trunc_normal_(tensor, mean, std, a, b) | |||
| def normal_(tensor, mean = 0., std = 1.): | |||
| return tensor.normal_(mean, std) | |||
| tensor_outplace = tensor.normal_adapter(mean, std) | |||
| return tensor.assign_value(tensor_outplace) | |||
| def uniform_(tensor, a = 0., b = 1.): | |||
| return tensor.uniform_(a, b) | |||
| tensor_outplace = tensor.uniform_adapter(a, b) | |||
| return tensor.assign_value(tensor_outplace) | |||
| def dirac_(tensor, groups=1): | |||
| out = initializer(Dirac(groups=groups), tensor.shape, tensor.dtype).init_data() | |||
| tensor.assign_value(out) | |||
| return tensor | |||
| def orthogonal_(tensor, gain=1): | |||
| out = initializer(Orthogonal(gain=gain), tensor.shape, tensor.dtype).init_data() | |||
| tensor.assign_value(out) | |||
| return tensor | |||
| def eye_(tensor): | |||
| out = ms.ops.eye(tensor.shape[0], tensor.shape[1], dtype=tensor.dtype) | |||
| tensor.assign_value(out) | |||
| return tensor | |||
ms_adapter/pytorch/nn/modules/__init__.py → msadapter/pytorch/nn/modules/__init__.py
View File
| @@ -7,6 +7,7 @@ from .flatten import * | |||
| from .conv import * | |||
| from .distance import * | |||
| from .batchnorm import * | |||
| from .instancenorm import * | |||
| from .pooling import * | |||
| from .unpooling import * | |||
| from .loss import * | |||
| @@ -14,10 +15,15 @@ from .padding import * | |||
| from .rnn import * | |||
| from .sparse import * | |||
| from .module import Module | |||
| from .container import Sequential, ModuleList | |||
| from .container import Sequential, ModuleList, ModuleDict, ParameterList, ParameterDict | |||
| from .dropout import Dropout, Dropout1d, Dropout2d, Dropout3d, AlphaDropout, FeatureAlphaDropout | |||
| from .upsampling import * | |||
| from .normalization import * | |||
| from .pixelshuffle import * | |||
| from .channelshuffle import * | |||
| from .fold import * | |||
| from .adaptive import AdaptiveLogSoftmaxWithLoss | |||
| from .transformer import * | |||
| __all__ = [ | |||
| 'Linear', | |||
| @@ -32,26 +38,16 @@ __all__ = [ | |||
| 'ConvTranspose1d', | |||
| 'ConvTranspose2d', | |||
| 'ConvTranspose3d', | |||
| 'LazyConv1d', | |||
| 'LazyConv2d', | |||
| 'LazyConv3d', | |||
| 'LazyConvTranspose1d', | |||
| 'LazyConvTranspose2d', | |||
| 'LazyConvTranspose3d', | |||
| 'Fold', | |||
| 'Unfold', | |||
| 'BatchNorm1d', | |||
| 'BatchNorm2d', | |||
| 'BatchNorm3d', | |||
| 'LazyBatchNorm1d', | |||
| 'LazyBatchNorm2d', | |||
| 'LazyBatchNorm3d', | |||
| 'SyncBatchNorm', | |||
| 'InstanceNorm1d', | |||
| 'InstanceNorm2d', | |||
| 'InstanceNorm3d', | |||
| 'LazyInstanceNorm1d', | |||
| 'LazyInstanceNorm2d', | |||
| 'LazyInstanceNorm3d', | |||
| 'FractionalMaxPool2d', | |||
| 'FractionalMaxPool3d', | |||
| @@ -82,6 +78,7 @@ __all__ = [ | |||
| 'LeakyReLU', | |||
| 'Sigmoid', | |||
| 'RReLU', | |||
| 'PReLU', | |||
| 'SELU', | |||
| 'CELU', | |||
| 'GELU', | |||
| @@ -91,12 +88,14 @@ __all__ = [ | |||
| 'Tanh', | |||
| 'Tanhshrink', | |||
| 'Threshold', | |||
| 'Softplus', | |||
| 'Softsign', | |||
| 'Softmax', | |||
| 'LogSoftmax', | |||
| 'Softmax2d', | |||
| 'Softmin', | |||
| 'GLU', | |||
| 'AdaptiveLogSoftmaxWithLoss', | |||
| 'MultiheadAttention', | |||
| 'Hardsigmoid', | |||
| @@ -104,6 +103,10 @@ __all__ = [ | |||
| 'Module', | |||
| 'Sequential', | |||
| 'ModuleList', | |||
| "ParameterList", | |||
| "ParameterDict", | |||
| "ModuleDict", | |||
| 'Dropout', | |||
| 'Dropout1d', | |||
| @@ -126,6 +129,14 @@ __all__ = [ | |||
| 'CosineEmbeddingLoss', | |||
| 'MultiMarginLoss', | |||
| 'TripletMarginLoss', | |||
| 'PoissonNLLLoss', | |||
| 'GaussianNLLLoss', | |||
| 'HingeEmbeddingLoss', | |||
| 'MultiLabelMarginLoss', | |||
| 'MultiLabelSoftMarginLoss', | |||
| 'TripletMarginWithDistanceLoss', | |||
| 'MarginRankingLoss', | |||
| 'CTCLoss', | |||
| 'LogSigmoid', | |||
| 'ELU', | |||
| @@ -134,6 +145,7 @@ __all__ = [ | |||
| 'ConstantPad3d', | |||
| 'ReflectionPad1d', | |||
| 'ReflectionPad2d', | |||
| 'ReflectionPad3d', | |||
| 'ZeroPad2d', | |||
| 'ReplicationPad1d', | |||
| 'ReplicationPad2d', | |||
| @@ -156,5 +168,16 @@ __all__ = [ | |||
| 'PairwiseDistance', | |||
| 'CosineSimilarity', | |||
| 'Embedding' | |||
| 'Embedding', | |||
| 'PixelShuffle', | |||
| 'PixelUnshuffle', | |||
| 'ChannelShuffle', | |||
| 'TransformerEncoderLayer', | |||
| 'TransformerDecoderLayer', | |||
| 'TransformerEncoder', | |||
| 'TransformerDecoder', | |||
| 'Transformer' | |||
| ] | |||
ms_adapter/pytorch/nn/modules/activation.py → msadapter/pytorch/nn/modules/activation.py
View File
| @@ -1,22 +1,27 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import warnings | |||
| from mindspore.ops import functional as F | |||
| import numpy as np | |||
| from mindspore.ops import operations as P | |||
| from mindspore.common import dtype as mstype | |||
| import mindspore as ms | |||
| from mindspore import nn | |||
| import ms_adapter.pytorch.nn.functional as ms_torch_nn_func | |||
| from ms_adapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from ms_adapter.utils import unsupported_attr | |||
| from ms_adapter.pytorch.common._inner import _inplace_assign, _inplace_limit_pynative | |||
| import mindspore._checkparam as validator | |||
| from msadapter.pytorch.functional import empty | |||
| from msadapter.pytorch.nn.parameter import Parameter | |||
| import msadapter.pytorch.nn.functional as ms_torch_nn_func | |||
| from msadapter.pytorch.tensor import Tensor, tensor, cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from msadapter.utils import unsupported_attr | |||
| from msadapter.pytorch.common._inner import _inplace_assign, _inplace_limit_pynative | |||
| from .module import Module | |||
| from .linear import Linear | |||
| from ..init import constant_, xavier_normal_, xavier_uniform_ | |||
| __all__ = ['ReLU', 'Hardtanh', 'ReLU6', 'SiLU', 'Hardswish', 'LeakyReLU', 'Sigmoid', 'LogSigmoid', 'ELU', 'RReLU', | |||
| 'SELU', 'CELU', 'GELU', 'Mish', 'Softshrink', 'Tanh', 'Tanhshrink','Threshold', 'Softmax', 'LogSoftmax', | |||
| 'Softmin', 'Softsign', 'GLU', 'Hardshrink', 'MultiheadAttention', 'Hardsigmoid'] | |||
| 'Softmin', 'Softsign', 'GLU', 'Hardshrink', 'MultiheadAttention', 'Hardsigmoid', 'PReLU', 'Softplus', | |||
| 'Softmax2d'] | |||
| class ReLU(Module): | |||
| @@ -35,8 +40,8 @@ class ReLU(Module): | |||
| Examples:: | |||
| >>> import ms_adapter.pytorch as torch | |||
| >>> import ms_adapter.pytorch.nn as nn | |||
| >>> import msadapter.pytorch as torch | |||
| >>> import msadapter.pytorch.nn as nn | |||
| >>> m = nn.ReLU() | |||
| >>> input = torch.randn(2) | |||
| >>> output = m(input) | |||
| @@ -97,10 +102,16 @@ class Hardtanh(Module): | |||
| ) | |||
| class ReLU6(Hardtanh): | |||
| class ReLU6(Module): | |||
| def __init__(self, inplace=False): | |||
| super(ReLU6, self).__init__() | |||
| self.inplace = inplace | |||
| _inplace_limit_pynative(inplace, "ReLU6") | |||
| super(ReLU6, self).__init__(0., 6., inplace) | |||
| def forward(self, input): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| output = ms.ops.relu6(input_ms) | |||
| return _inplace_assign(input, self.inplace, output) | |||
| def extra_repr(self): | |||
| inplace_str = 'inplace=True' if self.inplace else '' | |||
| @@ -112,14 +123,13 @@ class SiLU(Module): | |||
| super(SiLU, self).__init__() | |||
| _inplace_limit_pynative(inplace, "SiLU") | |||
| self.inplace = inplace | |||
| self.sigmoid = P.Sigmoid() | |||
| def forward(self, input): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| output = self.sigmoid(input_ms) * input_ms | |||
| output = ms.ops.silu(input_ms) | |||
| return _inplace_assign(input, self.inplace, output) | |||
| def extra_repr(self) -> str: | |||
| def extra_repr(self): | |||
| inplace_str = 'inplace=True' if self.inplace else '' | |||
| return inplace_str | |||
| @@ -143,21 +153,13 @@ class LeakyReLU(Module): | |||
| _inplace_limit_pynative(inplace, "LeakyReLU") | |||
| self.negative_slope = negative_slope | |||
| self.inplace = inplace | |||
| self.greater_equal = P.GreaterEqual() | |||
| self.mul = P.Mul() | |||
| self.select_op = P.Maximum() | |||
| if self.negative_slope > 1: | |||
| self.select_op = P.Minimum() | |||
| self.cast = P.Cast() | |||
| def forward(self, input): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| alpha_array = self.cast(F.scalar_to_tensor(self.negative_slope), input_ms.dtype) | |||
| output = self.select_op(alpha_array * input_ms, input_ms) | |||
| output = ms.ops.leaky_relu(input_ms, self.negative_slope) | |||
| return _inplace_assign(input, self.inplace, output) | |||
| def extra_repr(self) -> str: | |||
| def extra_repr(self): | |||
| inplace_str = ', inplace=True' if self.inplace else '' | |||
| return 'negative_slope={}{}'.format(self.negative_slope, inplace_str) | |||
| @@ -183,7 +185,7 @@ class LogSigmoid(Module): | |||
| class ELU(Module): | |||
| def __init__(self, alpha: float=1., inplace: bool=False): | |||
| def __init__(self, alpha=1., inplace=False): | |||
| super(ELU, self).__init__() | |||
| _inplace_limit_pynative(inplace, "ELU") | |||
| self.elu = ms_torch_nn_func.elu | |||
| @@ -206,11 +208,10 @@ class RReLU(Module): | |||
| self.lower = lower | |||
| self.upper = upper | |||
| self.inplace = inplace | |||
| self.rrelu = ms.nn.RReLU(lower=self.lower, upper=self.upper) | |||
| def forward(self, input): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| out = self.rrelu(input_ms) | |||
| out = ms.ops.rrelu(input_ms, self.lower, self.upper) | |||
| return _inplace_assign(input, self.inplace, out) | |||
| def extra_repr(self): | |||
| @@ -284,12 +285,12 @@ class Mish(Module): | |||
| class Softshrink(Module): | |||
| def __init__(self, lambd=0.5): | |||
| super(Softshrink, self).__init__() | |||
| self.lambd = lambd | |||
| self.softshrink = P.SoftShrink(lambd=self.lambd) | |||
| self.lambd = float(lambd) | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| out = self.softshrink(input) | |||
| softshrink = P.SoftShrink(lambd=self.lambd) | |||
| out = softshrink(input) | |||
| return cast_to_adapter_tensor(out) | |||
| def extra_repr(self): | |||
| @@ -325,11 +326,11 @@ class Threshold(Module): | |||
| class Softmax(Module): | |||
| def __init__(self, dim=None): | |||
| super(Softmax, self).__init__() | |||
| self.softmax = ms_torch_nn_func.softmax | |||
| self.dim = dim | |||
| def forward(self, input): | |||
| return self.softmax(input, self.dim) | |||
| # TODO: not support fp64 on Ascend | |||
| return ms_torch_nn_func.softmax(input, self.dim) | |||
| def extra_repr(self): | |||
| return 'dim={dim}'.format(dim=self.dim) | |||
| @@ -337,11 +338,10 @@ class Softmax(Module): | |||
| class LogSoftmax(Module): | |||
| def __init__(self, dim=None): | |||
| super(LogSoftmax, self).__init__() | |||
| self.logsoftmax = ms_torch_nn_func.log_softmax | |||
| self.dim = dim | |||
| def forward(self, input): | |||
| return self.logsoftmax(input, self.dim) | |||
| return ms_torch_nn_func.log_softmax(input, self.dim) | |||
| def extra_repr(self): | |||
| return 'dim={dim}'.format(dim=self.dim) | |||
| @@ -349,11 +349,11 @@ class LogSoftmax(Module): | |||
| class Softmin(Module): | |||
| def __init__(self, dim=None): | |||
| super(Softmin, self).__init__() | |||
| self.softmin = ms_torch_nn_func.softmin | |||
| self.dim = dim | |||
| def forward(self, input): | |||
| return self.softmin(input, self.dim) | |||
| # TODO: not support fp64 on Ascend | |||
| return ms_torch_nn_func.softmin(input, self.dim) | |||
| def extra_repr(self): | |||
| return 'dim={dim}'.format(dim=self.dim) | |||
| @@ -361,10 +361,10 @@ class Softmin(Module): | |||
| class Softsign(Module): | |||
| def __init__(self): | |||
| super(Softsign, self).__init__() | |||
| self.softsign = ms_torch_nn_func.softsign | |||
| def forward(self, input): | |||
| return self.softsign(input) | |||
| # TODO: not support fp64 on Ascend | |||
| return ms_torch_nn_func.softsign(input) | |||
| class GLU(Module): | |||
| @@ -381,19 +381,19 @@ class GLU(Module): | |||
| class Hardshrink(Module): | |||
| def __init__(self, lambd: float=0.5): | |||
| def __init__(self, lambd=0.5): | |||
| super(Hardshrink, self).__init__() | |||
| self.lambd = lambd | |||
| def forward(self, input): | |||
| return ms_torch_nn_func.hardshrink(input, self.lambd) | |||
| def extra_repr(self) -> str: | |||
| def extra_repr(self): | |||
| return '{}'.format(self.lambd) | |||
| class Hardsigmoid(Module): | |||
| def __init__(self, inplace: bool=False): | |||
| def __init__(self, inplace=False): | |||
| super(Hardsigmoid, self).__init__() | |||
| _inplace_limit_pynative(inplace, "Hardsigmoid") | |||
| self.inplace = inplace | |||
| @@ -403,118 +403,200 @@ class Hardsigmoid(Module): | |||
| class MultiheadAttention(Module): | |||
| def __init__(self, embed_dim, num_heads, dropout=0.0, bias=True, add_bias_kv=False, \ | |||
| add_zero_attn=False, kdim=None, vdim=None, batch_first=False, device=None, dtype=None): | |||
| def __init__(self, embed_dim, num_heads, dropout=0., bias=True, add_bias_kv=False, add_zero_attn=False, | |||
| kdim=None, vdim=None, batch_first=False, device=None, dtype=None): | |||
| unsupported_attr(device) | |||
| super(MultiheadAttention, self).__init__() | |||
| if bias is not True: | |||
| raise ValueError(f"`bias` can only be set to 'True', but got {bias}") | |||
| self.embed_dim = embed_dim | |||
| self.kdim = kdim if kdim is not None else embed_dim | |||
| self.vdim = vdim if vdim is not None else embed_dim | |||
| self._qkv_same_embed_dim = self.kdim == embed_dim and self.vdim == embed_dim | |||
| if add_bias_kv: | |||
| raise ValueError(f"`add_bias_kv` can only be set to 'False', but got {add_bias_kv}") | |||
| self.num_heads = num_heads | |||
| self.dropout = dropout | |||
| self.batch_first = batch_first | |||
| self.head_dim = embed_dim // num_heads | |||
| if self.head_dim * num_heads != self.embed_dim: | |||
| raise ValueError("The init argument 'embed_dim' must be divisible by 'num_heads'.") | |||
| if self._qkv_same_embed_dim is False: | |||
| self.q_proj_weight = Parameter(empty((embed_dim, embed_dim), dtype=dtype)) | |||
| self.k_proj_weight = Parameter(empty((embed_dim, self.kdim), dtype=dtype)) | |||
| self.v_proj_weight = Parameter(empty((embed_dim, self.vdim), dtype=dtype)) | |||
| self.in_proj_weight = None | |||
| else: | |||
| self.in_proj_weight = Parameter(empty((3 * embed_dim, embed_dim), dtype=dtype)) | |||
| self.q_proj_weight = None | |||
| self.k_proj_weight = None | |||
| self.v_proj_weight = None | |||
| if add_zero_attn: | |||
| raise ValueError(f"`add_zero_attn` can only be set to 'False', but got {add_zero_attn}") | |||
| if bias: | |||
| self.in_proj_bias = Parameter(empty(3 * embed_dim, dtype=dtype)) | |||
| else: | |||
| self.in_proj_bias = None | |||
| self.out_proj = Linear(embed_dim, embed_dim, bias=bias, dtype=dtype) | |||
| unsupported_attr(kdim) | |||
| unsupported_attr(vdim) | |||
| unsupported_attr(device) | |||
| if add_bias_kv: | |||
| self.bias_k = Parameter(empty((1, 1, embed_dim), dtype=dtype)) | |||
| self.bias_v = Parameter(empty((1, 1, embed_dim), dtype=dtype)) | |||
| else: | |||
| self.bias_k = self.bias_v = None | |||
| self.embed_dim = embed_dim | |||
| self.num_heads = num_heads | |||
| self.dropout = dropout | |||
| self.add_bias_kv = add_bias_kv | |||
| self.add_zero_attn = add_zero_attn | |||
| self.kdim = kdim | |||
| self.vdim = vdim | |||
| self.batch_first = batch_first | |||
| self.dtype = dtype | |||
| self.reduce_mean = ms.ops.ReduceMean() | |||
| def forward(self, query, key, value, key_padding_mask=None, | |||
| need_weights: bool=True, attn_mask=None, | |||
| average_attn_weights: bool=True): | |||
| unsupported_attr(key_padding_mask) | |||
| unsupported_attr(average_attn_weights) | |||
| if need_weights is True: | |||
| raise ValueError("Until now, `need_weights`='True' is not supported") | |||
| query = self._batch_tensor(query, 'query') | |||
| key = self._batch_tensor(key, 'key') | |||
| value = self._batch_tensor(value, 'value') | |||
| _batch_size = query.shape[0] | |||
| _src_seq_length = query.shape[1] | |||
| _tgt_seq_length = key.shape[1] | |||
| if attn_mask: | |||
| _attn_mask = self._process_mask(attn_mask, _batch_size) | |||
| self.k_is_v = False | |||
| self.q_is_k = False | |||
| self._reset_parameters() | |||
| def _reset_parameters(self): | |||
| if self._qkv_same_embed_dim: | |||
| xavier_uniform_(self.in_proj_weight) | |||
| else: | |||
| _attn_mask = ms.ops.ones((_batch_size, _src_seq_length, _tgt_seq_length), mstype.float32) | |||
| self.ms_multihead_attention = ms.nn.transformer.MultiHeadAttention( | |||
| batch_size = _batch_size, | |||
| src_seq_length = _src_seq_length, | |||
| tgt_seq_length = _tgt_seq_length, | |||
| hidden_size=self.embed_dim, | |||
| num_heads=self.num_heads, | |||
| hidden_dropout_rate=self.dropout, | |||
| attention_dropout_rate=self.dropout, | |||
| compute_dtype=mstype.float32, | |||
| softmax_compute_type=mstype.float32, | |||
| param_init_type=mstype.float32, | |||
| use_past=False) | |||
| out, attn_output_weights = self.ms_multihead_attention(query, key, value, _attn_mask) | |||
| if not self.batch_first: | |||
| # ms default is (batch, seq, feature), batch_first | |||
| out = ms.ops.transpose(out, (1, 0, 2)) | |||
| # if need_weights: | |||
| # if average_attn_weights: | |||
| # attn_output_weights = self.reduce_mean(attn_output_weights, 1) | |||
| # if _batch_size == 1: | |||
| # attn_output_weights = self.reduce_mean(attn_output_weights, 0) | |||
| # else: | |||
| # attn_output_weights = None | |||
| if _batch_size == 1: | |||
| out = self.reduce_mean(out, 0) | |||
| # TODO | |||
| # Until Now, attn_output_weights is not the same as pytorch | |||
| attn_output_weights = None | |||
| return cast_to_adapter_tensor(out), cast_to_adapter_tensor(attn_output_weights) | |||
| def _batch_tensor(self, x, x_name: str): | |||
| x = cast_to_ms_tensor(x) | |||
| _rank = ms.ops.rank(x) | |||
| if _rank == 2: | |||
| out = ms.ops.expand_dims(x, 0) | |||
| return out | |||
| if _rank == 3: | |||
| if not self.batch_first: | |||
| out = ms.ops.transpose(x, (1, 0 ,2)) | |||
| xavier_uniform_(self.q_proj_weight) | |||
| xavier_uniform_(self.k_proj_weight) | |||
| xavier_uniform_(self.v_proj_weight) | |||
| if self.in_proj_bias is not None: | |||
| constant_(self.in_proj_bias, 0.) | |||
| constant_(self.out_proj.bias, 0.) | |||
| if self.bias_k is not None: | |||
| xavier_normal_(self.bias_k) | |||
| if self.bias_v is not None: | |||
| xavier_normal_(self.bias_v) | |||
| def __call__(self, *args, **kwargs): | |||
| query = kwargs.get('query', args[0]) | |||
| key = kwargs.get('key', args[1]) | |||
| value = kwargs.get('value', args[2]) | |||
| self.k_is_v = key is value | |||
| self.q_is_k = query is key | |||
| return super().__call__(*args, **kwargs) | |||
| def __setstate__(self, state): | |||
| # Support loading old MultiheadAttention checkpoints generated by v1.1.0 | |||
| if '_qkv_same_embed_dim' not in state[1]: | |||
| state[1]['_qkv_same_embed_dim'] = True | |||
| super(MultiheadAttention, self).__setstate__(state) | |||
| def forward(self, query, key, value, key_padding_mask=None, need_weights=True, attn_mask=None, | |||
| average_attn_weights=True): | |||
| query = cast_to_ms_tensor(query) | |||
| key = cast_to_ms_tensor(key) | |||
| value = cast_to_ms_tensor(value) | |||
| key_padding_mask = cast_to_ms_tensor(key_padding_mask) | |||
| attn_mask = cast_to_ms_tensor(attn_mask) | |||
| is_batched = query.dim() == 3 | |||
| if key_padding_mask is not None: | |||
| if key_padding_mask.dtype != ms.bool_ and not ms.ops.is_floating_point(key_padding_mask): | |||
| raise ValueError("only bool and floating types of key_padding_mask are supported") | |||
| if self.batch_first and is_batched: | |||
| # k_is_v and q_is_k preprocess in __call__ since Graph mode do not support `is` | |||
| if self.k_is_v: | |||
| if self.q_is_k: | |||
| query = key = value = query.swapaxes(1, 0) | |||
| else: | |||
| query, key = [x.swapaxes(1, 0) for x in (query, key)] | |||
| value = key | |||
| else: | |||
| out = x | |||
| return out | |||
| query, key, value = [x.swapaxes(1, 0) for x in (query, key, value)] | |||
| if not self._qkv_same_embed_dim: | |||
| # TODO: older ver of torch doesn't have is_causal arg | |||
| attn_output, attn_output_weights = ms_torch_nn_func.multi_head_attention_forward( | |||
| query, key, value, self.embed_dim, self.num_heads, | |||
| self.in_proj_weight, self.in_proj_bias, | |||
| self.bias_k, self.bias_v, self.add_zero_attn, | |||
| self.dropout, self.out_proj.weight, self.out_proj.bias, | |||
| training=self.training, | |||
| key_padding_mask=key_padding_mask, | |||
| attn_mask=attn_mask, use_separate_proj_weight=True, | |||
| q_proj_weight=self.q_proj_weight, k_proj_weight=self.k_proj_weight, | |||
| v_proj_weight=self.v_proj_weight, average_attn_weights=average_attn_weights, | |||
| k_is_v=self.k_is_v, q_is_k=self.q_is_k) | |||
| else: | |||
| attn_output, attn_output_weights = ms_torch_nn_func.multi_head_attention_forward( | |||
| query, key, value, self.embed_dim, self.num_heads, | |||
| self.in_proj_weight, self.in_proj_bias, | |||
| self.bias_k, self.bias_v, self.add_zero_attn, | |||
| self.dropout, self.out_proj.weight, self.out_proj.bias, | |||
| training=self.training, | |||
| key_padding_mask=key_padding_mask, | |||
| attn_mask=attn_mask, average_attn_weights=average_attn_weights, | |||
| k_is_v=self.k_is_v, q_is_k=self.q_is_k) | |||
| if self.batch_first and is_batched: | |||
| attn_output = attn_output.swapaxes(1, 0) | |||
| if need_weights: | |||
| return cast_to_adapter_tensor(attn_output), cast_to_adapter_tensor(attn_output_weights) | |||
| return (cast_to_adapter_tensor(attn_output),) | |||
| class PReLU(Module): | |||
| def __init__(self, num_parameters=1, init=0.25, device=None, dtype=None): | |||
| super(PReLU, self).__init__() | |||
| unsupported_attr(device) | |||
| validator.check_positive_int(num_parameters, 'num_parameters', self.cls_name) | |||
| if dtype is None: | |||
| dtype = mstype.float32 | |||
| w = init | |||
| if isinstance(w, (float, np.float32)): | |||
| tmp = np.empty((num_parameters,), dtype=np.float32) | |||
| tmp.fill(w) | |||
| w = tensor(tmp, dtype=dtype) | |||
| elif isinstance(w, list): | |||
| if len(w) != num_parameters: | |||
| raise ValueError(f"For '{self.cls_name}', the length of 'init' must be equal to the 'num_parameters'" | |||
| f"when the 'init' is a list, but got the length of 'num_parameters': {len(w)}, " | |||
| f"the 'num_parameters': {num_parameters}.") | |||
| for i in w: | |||
| if not isinstance(i, (float, np.float32)): | |||
| raise ValueError(f"For '{self.cls_name}', all elements in 'init' must be " | |||
| f"float when the 'init' is a list, but got {i}.") | |||
| w = tensor(w, dtype=dtype) | |||
| elif isinstance(w, Tensor): | |||
| if w.dtype not in (mstype.float16, mstype.float32): | |||
| raise ValueError(f"For '{self.cls_name}', the dtype of 'init' must be float16 or " | |||
| f"float32 when the 'init' is a tensor, but got {w.dtype}.") | |||
| if len(w.shape) != 1 or w.shape[0] != num_parameters: | |||
| raise ValueError(f"For '{self.cls_name}', the dimension of 'init' must be 1, and the elements number " | |||
| f"should be equal to the 'num_parameters' when the 'init' is a tensor, " | |||
| f"but got 'init' shape {w.shape}, the 'num_parameters' {num_parameters}.") | |||
| else: | |||
| raise TypeError(f"For '{self.cls_name}', the 'init' only supported float, list and tensor, " | |||
| f"but got {type(w).__name__}.") | |||
| raise ValueError(f"For MultiheadAttention, rank of {x_name} should be 2 or 3, but got {_rank}") | |||
| self.weight = Parameter(w) | |||
| self.num_parameters = num_parameters | |||
| def _process_mask(self, mask, batch_size): | |||
| mask = cast_to_ms_tensor(mask) | |||
| _rank = ms.ops.rank(mask) | |||
| if _rank == 2: | |||
| out = ms.ops.expand_dims(mask, 0) | |||
| return out | |||
| def forward(self, input): | |||
| return ms_torch_nn_func.prelu(input, self.weight) | |||
| def extra_repr(self) -> str: | |||
| return 'num_parameters={}'.format(self.num_parameters) | |||
| class Softplus(Module): | |||
| def __init__(self, beta=1, threshold=20): | |||
| super(Softplus, self).__init__() | |||
| self.beta = beta | |||
| self.threshold = threshold | |||
| if _rank == 3: | |||
| if mask.shape[0] != batch_size: | |||
| warnings.warn("Until now, `attn_mask` can only support shape (N, L, S)" | |||
| "when `attn_mask` shape is (N * num_heads, L, S), pick the first (N, L, S) mask") | |||
| def forward(self, input): | |||
| # TODO: not support fp64 on Ascend | |||
| return ms_torch_nn_func.softplus(input, self.beta, self.threshold) | |||
| def extra_repr(self): | |||
| return 'beta={}, threshold={}'.format(self.beta, self.threshold) | |||
| mask = mask[:batch_size,:] | |||
| return mask | |||
| raise ValueError(f"For MultiheadAttention, rank of mask should be 2 or 3, but got {_rank}") | |||
| class Softmax2d(Module): | |||
| def __init__(self): | |||
| super(Softmax2d, self).__init__() | |||
| def forward(self, input): | |||
| if input.dim() not in (3, 4): | |||
| raise RuntimeError("Softmax2d requires a 3D or 4D tensor as input") | |||
| # TODO: not support fp64 on Ascend | |||
| softmax2d = ms.nn.Softmax2d() | |||
| return softmax2d(input) | |||
+ 198
- 0
msadapter/pytorch/nn/modules/adaptive.py
View File
| @@ -0,0 +1,198 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from collections import namedtuple | |||
| import mindspore as ms | |||
| from mindspore.ops.primitive import _primexpr | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from msadapter.utils import unsupported_attr, pynative_mode_condition | |||
| from .container import Sequential, ModuleList | |||
| from .linear import Linear | |||
| from .module import Module | |||
| from ..functional import log_softmax | |||
| @_primexpr | |||
| def _ASMoutput(): | |||
| return namedtuple('_ASMoutput', ['output', 'loss']) | |||
| class AdaptiveLogSoftmaxWithLoss(Module): | |||
| def __init__(self, in_features, n_classes, cutoffs, div_value=4., head_bias=False, device=None, dtype=None): | |||
| super(AdaptiveLogSoftmaxWithLoss, self).__init__() | |||
| unsupported_attr(device) | |||
| cutoffs = list(cutoffs) | |||
| # #TODO: pylint | |||
| # if (cutoffs != sorted(cutoffs)) \ | |||
| # or (min(cutoffs) <= 0) \ | |||
| # or (max(cutoffs) > (n_classes - 1)) \ | |||
| # or (len(set(cutoffs)) != len(cutoffs)) \ | |||
| # or any([int(c) != c for c in cutoffs]): | |||
| # | |||
| # raise ValueError("cutoffs should be a sequence of unique, positive " | |||
| # "integers sorted in an increasing order, where " | |||
| # "each value is between 1 and n_classes-1") | |||
| self.in_features = in_features | |||
| self.n_classes = n_classes | |||
| self.cutoffs = cutoffs + [n_classes] | |||
| self.div_value = div_value | |||
| self.head_bias = head_bias | |||
| self.dtype = dtype | |||
| self.shortlist_size = self.cutoffs[0] | |||
| self.n_clusters = len(self.cutoffs) - 1 | |||
| self.head_size = self.shortlist_size + self.n_clusters | |||
| self.head = Linear(self.in_features, self.head_size, bias=self.head_bias, dtype=self.dtype) | |||
| self.tail = ModuleList() | |||
| for i in range(self.n_clusters): | |||
| hsz = int(self.in_features // (self.div_value ** (i + 1))) | |||
| osz = self.cutoffs[i + 1] - self.cutoffs[i] | |||
| projection = Sequential( | |||
| Linear(self.in_features, hsz, bias=False, dtype=self.dtype), | |||
| Linear(hsz, osz, bias=False, dtype=self.dtype), | |||
| ) | |||
| self.tail.append(projection) | |||
| def reset_parameters(self): | |||
| self.head.reset_parameters() | |||
| for i2h, h2o in self.tail: | |||
| i2h.reset_parameters() | |||
| h2o.reset_parameters() | |||
| def forward(self, input_, target_): | |||
| input_ = cast_to_ms_tensor(input_) | |||
| #target_ = cast_to_ms_tensor(target_) | |||
| targ_dim = target_.dim() | |||
| if targ_dim == 1: | |||
| if input_.shape[0] != target_.shape[0]: | |||
| raise RuntimeError('Input and target should have the same size ' | |||
| 'in the batch dimension.') | |||
| if input_.dim() != 2: | |||
| raise RuntimeError('1D target tensor expects 2D input tensors, ' | |||
| 'but found inputs with size', input_.shape()) | |||
| elif targ_dim == 0: | |||
| if input_.dim() != 1: | |||
| raise RuntimeError('0D target tensor expects 1D input tensors, ' | |||
| 'but found inputs with size', input_.shape()) | |||
| else: | |||
| raise RuntimeError('0D or 1D target tensor expected, ' | |||
| 'multi-target not supported') | |||
| is_batched = targ_dim > 0 | |||
| input = input_ if is_batched else input_.unsqueeze(0) | |||
| target = target_ if is_batched else target_.unsqueeze(0) | |||
| used_rows = 0 | |||
| batch_size = target.shape[0] | |||
| output = input.new_zeros(batch_size) | |||
| #gather_inds = ms.numpy.empty(batch_size, target.dtype) | |||
| gather_inds = target.new_empty(batch_size) | |||
| cutoff_values = [0] + self.cutoffs | |||
| for i in range(len(cutoff_values) - 1): | |||
| low_idx = cutoff_values[i] | |||
| high_idx = cutoff_values[i + 1] | |||
| target_mask = (target >= low_idx) & (target < high_idx) | |||
| row_indices = target_mask.nonzero().squeeze() | |||
| if row_indices.numel() == 0: | |||
| continue | |||
| if i == 0: | |||
| #gather_inds.index_copy_(0, row_indices, target[target_mask]) | |||
| gather_inds = index_copy_0dim(gather_inds, row_indices, target[target_mask]) | |||
| else: | |||
| relative_target = target[target_mask] - low_idx | |||
| #input_subset = input.index_select(0, row_indices) | |||
| input_subset = ms.ops.gather(input, row_indices, 0) | |||
| cluster_output = self.tail[i - 1](input_subset) | |||
| cluster_index = self.shortlist_size + i - 1 | |||
| gather_inds = gather_inds.index_fill(0, row_indices, cluster_index) | |||
| cluster_logprob = log_softmax(cluster_output, dim=1) | |||
| local_logprob = cluster_logprob.gather(1, relative_target.unsqueeze(1)) | |||
| #output.index_copy_(0, row_indices, local_logprob.squeeze(1)) | |||
| output = index_copy_0dim(output, row_indices, local_logprob.squeeze(1)) | |||
| used_rows += row_indices.numel() | |||
| if used_rows != batch_size: | |||
| raise RuntimeError("Target values should be in [0, {}], " | |||
| "but values in range [{}, {}] " | |||
| "were found. ".format(self.n_classes - 1, | |||
| target.min().item(), | |||
| target.max().item())) | |||
| head_output = self.head(input) | |||
| head_logprob = log_softmax(head_output, dim=1) | |||
| output += head_logprob.gather(1, gather_inds.unsqueeze(1)).squeeze() | |||
| loss = (-output).mean() | |||
| if not is_batched: | |||
| output = output.squeeze(0) | |||
| output = cast_to_adapter_tensor(output) | |||
| loss = cast_to_adapter_tensor(loss) | |||
| if pynative_mode_condition(): | |||
| return _ASMoutput()(output, loss) | |||
| return output, loss | |||
| def _get_full_log_prob(self, input, head_output): | |||
| input = cast_to_ms_tensor(input) | |||
| head_output = cast_to_ms_tensor(head_output) | |||
| out = input.new_empty((head_output.shape[0], self.n_classes)) | |||
| head_logprob = log_softmax(head_output, dim=1) | |||
| out[:, :self.shortlist_size] = head_logprob[:, :self.shortlist_size] | |||
| for i, (start_idx, stop_idx) in enumerate(zip(self.cutoffs, self.cutoffs[1:])): | |||
| cluster_output = self.tail[i](input) | |||
| cluster_logprob = log_softmax(cluster_output, dim=1) | |||
| output_logprob = cluster_logprob + head_logprob[:, self.shortlist_size + i].unsqueeze(1) | |||
| out[:, start_idx:stop_idx] = output_logprob | |||
| return cast_to_adapter_tensor(out) | |||
| def log_prob(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| head_output = self.head(input) | |||
| out = self._get_full_log_prob(input, head_output) | |||
| return cast_to_adapter_tensor(out) | |||
| def predict(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| head_output = self.head(input) | |||
| cast_to_adapter_tensor() | |||
| output = ms.ops.argmax(head_output, axis=1) | |||
| not_in_shortlist = (output >= self.shortlist_size) | |||
| any_in_shortlist = (output < self.shortlist_size) | |||
| if not not_in_shortlist: | |||
| return cast_to_adapter_tensor(output) | |||
| elif not any_in_shortlist: | |||
| log_prob = self._get_full_log_prob(input, head_output) | |||
| return cast_to_adapter_tensor(ms.ops.argmax(log_prob, axis=1)) | |||
| else: | |||
| log_prob = self._get_full_log_prob(input[not_in_shortlist], | |||
| head_output[not_in_shortlist]) | |||
| output[not_in_shortlist] = ms.ops.argmax(log_prob, axis=1) | |||
| return cast_to_adapter_tensor(output) | |||
| def index_copy_0dim(input, index, tensor): | |||
| for i in range(len(index)): | |||
| input[index[i]] = tensor[i] | |||
| return input | |||
ms_adapter/pytorch/nn/modules/batchnorm.py → msadapter/pytorch/nn/modules/batchnorm.py
View File
| @@ -5,24 +5,20 @@ import itertools | |||
| import mindspore.ops as P | |||
| from mindspore.ops.operations import _inner_ops as inner | |||
| from mindspore.communication.management import get_group_size, get_rank | |||
| from mindspore._checkparam import Validator as validator | |||
| from mindspore._checkparam import Rel | |||
| import mindspore._checkparam as validator | |||
| from mindspore.communication import management | |||
| import mindspore.context as context | |||
| from ms_adapter.pytorch.nn import init | |||
| from ms_adapter.pytorch.functional import empty | |||
| from ms_adapter.pytorch.nn.parameter import Parameter | |||
| from ms_adapter.utils import unsupported_attr | |||
| from ms_adapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from msadapter.pytorch.nn import init | |||
| from msadapter.pytorch.functional import empty | |||
| from msadapter.pytorch.nn.parameter import Parameter | |||
| from msadapter.utils import unsupported_attr | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from .module import Module | |||
| __all__ = ['BatchNorm1d', 'BatchNorm2d', 'BatchNorm3d', | |||
| 'LazyBatchNorm1d', 'LazyBatchNorm2d', 'LazyBatchNorm3d', | |||
| 'SyncBatchNorm', | |||
| 'InstanceNorm1d', 'InstanceNorm2d', 'InstanceNorm3d', | |||
| 'LazyInstanceNorm1d', 'LazyInstanceNorm2d', 'LazyInstanceNorm3d'] | |||
| 'SyncBatchNorm'] | |||
| class _NormBase(Module): | |||
| """Common base of _InstanceNorm and _BatchNorm""" | |||
| @@ -47,6 +43,9 @@ class _NormBase(Module): | |||
| self.track_running_stats = track_running_stats | |||
| self.weight = Parameter(empty(num_features), requires_grad=affine) | |||
| self.bias = Parameter(empty(num_features), requires_grad=affine) | |||
| # 'running_mean' and 'running_var' have to be Parameter | |||
| # because mindspore.ops.BatchNorm require them to be Parameter when 'is_training' is True | |||
| # so can not use register_buffer() for 'running_mean' and 'running_var' | |||
| self.running_mean = Parameter(empty(num_features), requires_grad=False) | |||
| self.running_var = Parameter(empty(num_features), requires_grad=False) | |||
| self.reset_parameters() | |||
| @@ -54,8 +53,8 @@ class _NormBase(Module): | |||
| self.momentum = 0.0 | |||
| def reset_running_stats(self): | |||
| self.running_mean.zero_() | |||
| self.running_var.fill_(1) | |||
| init.zeros_(self.running_mean) | |||
| init.ones_(self.running_var) | |||
| def reset_parameters(self): | |||
| self.reset_running_stats() | |||
| @@ -99,7 +98,7 @@ class _BatchNorm(_NormBase): | |||
| def _check_rank_ids(self, process_groups, rank_size): | |||
| seen = set() | |||
| for rid in itertools.chain(*process_groups): | |||
| validator.check_int_range(rid, 0, rank_size, Rel.INC_LEFT, "rank id in process_groups", self.cls_name) | |||
| validator.check_int_range(rid, 0, rank_size, validator.INC_LEFT, "rank id in process_groups", self.cls_name) | |||
| if rid in seen: | |||
| raise ValueError(f"For '{self.cls_name}', rank id in 'process_groups' must not be duplicated, " | |||
| f"but got {process_groups}.") | |||
| @@ -121,6 +120,7 @@ class _BatchNorm(_NormBase): | |||
| input = cast_to_ms_tensor(input) | |||
| # TODO cast Parameter | |||
| # Here use Ops instead of 'nn.functional.batch_norm', because latter may be poor performance. | |||
| if self.training or (not self.training and not self.track_running_stats): | |||
| output = self.bn_train(input, | |||
| self.weight, | |||
| @@ -138,9 +138,9 @@ class _BatchNorm(_NormBase): | |||
| class BatchNorm1d(_BatchNorm): | |||
| def _check_input_dim(self, input): | |||
| if len(input.shape) != 2: | |||
| if len(input.shape) not in (2, 3): | |||
| raise ValueError( | |||
| "expected 2D input (got {}D input)".format(input.dim()) | |||
| "expected 2D or 3D input (got {}D input)".format(input.dim()) | |||
| ) | |||
| return True | |||
| @@ -159,7 +159,7 @@ class BatchNorm2d(_BatchNorm): | |||
| the mini-batches and :math:`\gamma` and :math:`\beta` are learnable parameter vectors | |||
| of size `C` (where `C` is the input size). By default, the elements of :math:`\gamma` are set | |||
| to 1 and the elements of :math:`\beta` are set to 0. The standard-deviation is calculated | |||
| via the biased estimator, equivalent to `ms_adapter.pytorch.var(input, unbiased=False)`. | |||
| via the biased estimator, equivalent to `msadapter.pytorch.var(input, unbiased=False)`. | |||
| Also by default, during training this layer keeps running estimates of its | |||
| computed mean and variance, which are then used for normalization during | |||
| @@ -208,7 +208,7 @@ class BatchNorm2d(_BatchNorm): | |||
| >>> m = nn.BatchNorm2d(100) | |||
| >>> # Without Learnable Parameters | |||
| >>> m = nn.BatchNorm2d(100, affine=False) | |||
| >>> input = ms_adapter.pytorch.randn(20, 100, 35, 45) | |||
| >>> input = msadapter.pytorch.randn(20, 100, 35, 45) | |||
| >>> output = m(input) | |||
| """ | |||
| @@ -240,16 +240,16 @@ class BatchNorm3d(_BatchNorm): | |||
| if self.training or (not self.training and not self.track_running_stats): | |||
| bn2d_out = self.bn_train(input, | |||
| self.weight, | |||
| self.bias, | |||
| self.running_mean, | |||
| self.running_var)[0] | |||
| self.weight, | |||
| self.bias, | |||
| self.running_mean, | |||
| self.running_var)[0] | |||
| else: | |||
| bn2d_out = self.bn_infer(input, | |||
| self.weight, | |||
| self.bias, | |||
| self.running_mean, | |||
| self.running_var)[0] | |||
| self.weight, | |||
| self.bias, | |||
| self.running_mean, | |||
| self.running_var)[0] | |||
| bn3d_out = self.reshape(bn2d_out, x_shape) | |||
| return cast_to_adapter_tensor(bn3d_out) | |||
| @@ -308,74 +308,3 @@ class SyncBatchNorm(_BatchNorm): | |||
| "expected at least 2D input (got {}D input)".format(input.dim()) | |||
| ) | |||
| return True | |||
| class _InstanceNorm(_NormBase): | |||
| def __init__( | |||
| self, | |||
| num_features, | |||
| eps=1e-5, | |||
| momentum=0.1, | |||
| affine=False, | |||
| track_running_stats=False, | |||
| device=None, | |||
| dtype=None | |||
| ): | |||
| factory_kwargs = {'device': device, 'dtype': dtype} | |||
| super(_InstanceNorm, self).__init__( | |||
| num_features, eps, momentum, affine, track_running_stats, **factory_kwargs) | |||
| self.instance_bn = P.operations.InstanceNorm(epsilon=self.eps, momentum=self.momentum) | |||
| def _check_input_dim(self, input): | |||
| raise NotImplementedError | |||
| def forward(self, input): | |||
| self._check_input_dim(input) | |||
| input = cast_to_ms_tensor(input) | |||
| output = self.instance_bn(input, | |||
| self.weight, | |||
| self.bias, | |||
| self.running_mean, | |||
| self.running_var)[0] | |||
| output = cast_to_adapter_tensor(output) | |||
| return output | |||
| class InstanceNorm1d(_InstanceNorm): | |||
| def _check_input_dim(self, input): | |||
| if input.dim() == 2: | |||
| raise ValueError( | |||
| 'InstanceNorm1d returns 0-filled tensor to 2D tensor.' | |||
| 'This is because InstanceNorm1d reshapes inputs to' | |||
| '(1, N * C, ...) from (N, C,...) and this makes' | |||
| 'variances 0.' | |||
| ) | |||
| if input.dim() != 3: | |||
| raise ValueError('expected 3D input (got {}D input)' | |||
| .format(input.dim())) | |||
| return True | |||
| class InstanceNorm2d(_InstanceNorm): | |||
| def _check_input_dim(self, input): | |||
| if input.dim() != 4: | |||
| raise ValueError('expected 4D input (got {}D input)' | |||
| .format(input.dim())) | |||
| return True | |||
| class InstanceNorm3d(_InstanceNorm): | |||
| def _check_input_dim(self, input): | |||
| if input.dim() != 5: | |||
| raise ValueError('expected 5D input (got {}D input)' | |||
| .format(input.dim())) | |||
| return True | |||
| LazyBatchNorm1d = BatchNorm1d | |||
| LazyBatchNorm2d = BatchNorm2d | |||
| LazyBatchNorm3d = BatchNorm3d | |||
| LazyInstanceNorm1d = InstanceNorm1d | |||
| LazyInstanceNorm2d = InstanceNorm2d | |||
| LazyInstanceNorm3d = InstanceNorm3d | |||
+ 23
- 0
msadapter/pytorch/nn/modules/channelshuffle.py
View File
| @@ -0,0 +1,23 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import mindspore.nn as nn | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from .module import Module | |||
| __all__ = ['ChannelShuffle'] | |||
| class ChannelShuffle(Module): | |||
| def __init__(self, groups): | |||
| super(ChannelShuffle, self).__init__() | |||
| self.groups = groups | |||
| self.channel_shuffle = nn.ChannelShuffle(self.groups) | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| out = self.channel_shuffle(input) | |||
| return cast_to_adapter_tensor(out) | |||
| def extra_repr(self): | |||
| return 'groups={}'.format(self.groups) | |||
+ 1015
- 0
msadapter/pytorch/nn/modules/container.py
View File
| @@ -0,0 +1,1015 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from abc import abstractmethod | |||
| import operator | |||
| from itertools import chain | |||
| from typing import Dict | |||
| from collections import OrderedDict, abc as container_abcs | |||
| from mindspore.nn.layer.container import _get_prefix_and_index, _valid_index, _valid_cell | |||
| from msadapter.pytorch.tensor import Tensor, cast_to_adapter_tensor | |||
| from msadapter.pytorch.nn.parameter import Parameter | |||
| from msadapter.pytorch._ref import typename | |||
| from .module import Module | |||
| class Sequential(Module): | |||
| """ | |||
| Sequential Module container. For more details about Module, please refer to | |||
| A list of Cells will be added to it in the order they are passed in the constructor. | |||
| Alternatively, an ordered dict of cells can also be passed in. | |||
| Note: | |||
| Sequential and nn.ModuleList are different, ModuleList is a list for storing modules. However, | |||
| the layers in a Sequential are connected in a cascading way. | |||
| Args: | |||
| args (list, OrderedDict): List or OrderedDict of subclass of Module. | |||
| Inputs: | |||
| - **x** (Tensor) - Tensor with shape according to the first Module in the sequence. | |||
| Outputs: | |||
| Tensor, the output Tensor with shape depending on the input `x` and defined sequence of Cells. | |||
| Raises: | |||
| TypeError: If the type of the `args` is not list or OrderedDict. | |||
| Supported Platforms: | |||
| ``Ascend`` ``GPU`` ``CPU`` | |||
| Examples: | |||
| >>> conv = nn.Conv2d(3, 2, 3, pad_mode='valid', weight_init="ones") | |||
| >>> relu = nn.ReLU() | |||
| >>> seq = nn.Sequential([conv, relu]) | |||
| >>> x = Tensor(np.ones([1, 3, 4, 4]), dtype=mindspore.float32) | |||
| >>> output = seq(x) | |||
| >>> print(output) | |||
| [[[[27. 27.] | |||
| [27. 27.]] | |||
| [[27. 27.] | |||
| [27. 27.]]]] | |||
| >>> from collections import OrderedDict | |||
| >>> d = OrderedDict() | |||
| >>> d["conv"] = conv | |||
| >>> d["relu"] = relu | |||
| >>> seq = nn.Sequential(d) | |||
| >>> x = Tensor(np.ones([1, 3, 4, 4]), dtype=mindspore.float32) | |||
| >>> output = seq(x) | |||
| >>> print(output) | |||
| [[[[27. 27.] | |||
| [27. 27.]] | |||
| [[27. 27.] | |||
| [27. 27.]]]] | |||
| """ | |||
| def __init__(self, *args): | |||
| """Initialize Sequential.""" | |||
| super(Sequential, self).__init__() | |||
| self._is_dynamic_name = [] | |||
| if len(args) == 1: | |||
| cells = args[0] | |||
| if isinstance(cells, list): | |||
| for index, cell in enumerate(cells): | |||
| self.insert_child_to_cell(str(index), cell) | |||
| cell.update_parameters_name(str(index) + ".") | |||
| self._is_dynamic_name.append(True) | |||
| elif isinstance(cells, OrderedDict): | |||
| for name, cell in cells.items(): | |||
| self.insert_child_to_cell(name, cell) | |||
| cell.update_parameters_name(name + ".") | |||
| self._is_dynamic_name.append(False) | |||
| elif isinstance(cells, Module): | |||
| for index, cell in enumerate(args): | |||
| self.insert_child_to_cell(str(index), cell) | |||
| cell.update_parameters_name(str(index) + ".") | |||
| self._is_dynamic_name.append(True) | |||
| else: | |||
| raise TypeError(f"For '{self.__class__.__name__}', the 'args[0]' must be list or orderedDict, " | |||
| f"but got {type(cells).__name__}") | |||
| else: | |||
| for index, cell in enumerate(args): | |||
| self.insert_child_to_cell(str(index), cell) | |||
| cell.update_parameters_name(str(index) + ".") | |||
| self._is_dynamic_name.append(True) | |||
| self.cell_list = list(self._cells.values()) | |||
| def __getitem__(self, index): | |||
| if isinstance(index, slice): | |||
| return self.__class__( | |||
| OrderedDict(list(self._cells.items())[index])) | |||
| if isinstance(index, Tensor): | |||
| index = int(index) | |||
| index = _valid_index(len(self), index, self.__class__.__name__) | |||
| return list(self._cells.values())[index] | |||
| def __setitem__(self, index, module): | |||
| if isinstance(index, Tensor): | |||
| index = int(index) | |||
| cls_name = self.__class__.__name__ | |||
| if _valid_cell(module, cls_name): | |||
| prefix, _ = _get_prefix_and_index(self._cells) | |||
| index = _valid_index(len(self), index, cls_name) | |||
| key = list(self._cells.keys())[index] | |||
| self._cells[key] = module | |||
| module.update_parameters_name(prefix + key + ".") | |||
| self.cell_list = list(self._cells.values()) | |||
| def __delitem__(self, index): | |||
| cls_name = self.__class__.__name__ | |||
| if isinstance(index, int): | |||
| index = _valid_index(len(self), index, cls_name) | |||
| key = list(self._cells.keys())[index] | |||
| del self._cells[key] | |||
| del self._is_dynamic_name[index] | |||
| elif isinstance(index, slice): | |||
| keys = list(self._cells.keys())[index] | |||
| for key in keys: | |||
| del self._cells[key] | |||
| del self._is_dynamic_name[index] | |||
| else: | |||
| raise TypeError(f"For '{cls_name}', the type of index must be int type or slice type, " | |||
| f"but got {type(index).__name__}") | |||
| prefix, key_index = _get_prefix_and_index(self._cells) | |||
| temp_dict = OrderedDict() | |||
| for idx, key in enumerate(self._cells.keys()): | |||
| cell = self._cells[key] | |||
| if self._is_dynamic_name[idx]: | |||
| for _, param in cell.parameters_and_names(): | |||
| param.name = prefix + str(idx) + "." + ".".join(param.name.split(".")[key_index+1:]) | |||
| temp_dict[str(idx)] = cell | |||
| else: | |||
| temp_dict[key] = cell | |||
| self._cells = temp_dict | |||
| self.cell_list = list(self._cells.values()) | |||
| def __len__(self): | |||
| return len(self._cells) | |||
| def __bool__(self): | |||
| return len(self._cells) != 0 | |||
| def __add__(self, other): | |||
| if isinstance(other, Sequential): | |||
| ret = Sequential() | |||
| for layer in self: | |||
| self.append(ret, layer) | |||
| for layer in other: | |||
| self.append(ret, layer) | |||
| return ret | |||
| else: | |||
| raise ValueError('add operator supports only objects ' | |||
| 'of Sequential class, but {} is given.'.format( | |||
| str(type(other)))) | |||
| def __iadd__(self, other): | |||
| if isinstance(other, Sequential): | |||
| offset = len(self) | |||
| for i, module in enumerate(other): | |||
| self.add_module(str(i + offset), module) | |||
| return self | |||
| else: | |||
| raise ValueError('add operator supports only objects ' | |||
| 'of Sequential class, but {} is given.'.format( | |||
| str(type(other)))) | |||
| def __mul__(self, other): | |||
| if not isinstance(other, int): | |||
| raise TypeError(f"unsupported operand type(s) for *: {type(self)} and {type(other)}") | |||
| elif other <= 0: | |||
| raise ValueError(f"Non-positive multiplication factor {other} for {type(self)}") | |||
| else: | |||
| combined = Sequential() | |||
| offset = 0 | |||
| for _ in range(other): | |||
| for module in self: | |||
| combined.add_module(str(offset), module) | |||
| offset += 1 | |||
| return combined | |||
| def __rmul__(self, other): | |||
| return self.__mul__(other) | |||
| def __imul__(self, other): | |||
| if not isinstance(other, int): | |||
| raise TypeError(f"unsupported operand type(s) for *: {type(self)} and {type(other)}") | |||
| elif other <= 0: | |||
| raise ValueError(f"Non-positive multiplication factor {other} for {type(self)}") | |||
| else: | |||
| len_original = len(self) | |||
| offset = len(self) | |||
| for _ in range(other - 1): | |||
| for i in range(len_original): | |||
| self.add_module(str(i + offset), self._cells[str(i)]) | |||
| offset += len_original | |||
| return self | |||
| def __dir__(self): | |||
| keys = Module.__dir__(self) | |||
| keys = [key for key in keys if not key.isdigit()] | |||
| return keys | |||
| def __iter__(self): | |||
| return iter(self._cells.values()) | |||
| @property | |||
| def _modules(self): | |||
| return self._cells | |||
| def set_grad(self, flag=True): | |||
| self.requires_grad = flag | |||
| for cell in self._cells.values(): | |||
| cell.set_grad(flag) | |||
| def append(self, module): | |||
| """ | |||
| Appends a given Module to the end of the list. | |||
| Args: | |||
| module(Module): The Module to be appended. | |||
| Examples: | |||
| >>> conv = nn.Conv2d(3, 2, 3, pad_mode='valid', weight_init="ones") | |||
| >>> bn = nn.BatchNorm2d(2) | |||
| >>> relu = nn.ReLU() | |||
| >>> seq = nn.Sequential([conv, bn]) | |||
| >>> seq.append(relu) | |||
| >>> x = Tensor(np.ones([1, 3, 4, 4]), dtype=mindspore.float32) | |||
| >>> output = seq(x) | |||
| >>> print(output) | |||
| [[[[26.999863 26.999863] | |||
| [26.999863 26.999863]] | |||
| [[26.999863 26.999863] | |||
| [26.999863 26.999863]]]] | |||
| """ | |||
| if _valid_cell(module, self.__class__.__name__): | |||
| prefix, _ = _get_prefix_and_index(self._cells) | |||
| module.update_parameters_name(prefix + str(len(self)) + ".") | |||
| self._is_dynamic_name.append(True) | |||
| self._cells[str(len(self))] = module | |||
| self.cell_list = list(self._cells.values()) | |||
| return self | |||
| def add_module(self, name, module): | |||
| if not isinstance(module, Module) and module is not None: | |||
| raise TypeError("{} is not a Module subclass".format( | |||
| module.__name__)) | |||
| elif hasattr(self, name) and name not in self._cells: | |||
| raise KeyError("attribute '{}' already exists".format(name)) | |||
| elif '.' in name: | |||
| raise KeyError("module name can't contain \".\", got: {}".format(name)) | |||
| elif name == '': | |||
| raise KeyError("module name can't be empty string \"\"") | |||
| if _valid_cell(module, self.__class__.__name__): | |||
| module.update_parameters_name(name + ".") | |||
| self._is_dynamic_name.append(False) | |||
| self._cells[name] = module | |||
| self.cell_list = list(self._cells.values()) | |||
| def forward(self, input): | |||
| for cell in self.cell_list: | |||
| input = cell(input) | |||
| return cast_to_adapter_tensor(input) | |||
| def pop(self, key): | |||
| v = self[key] | |||
| del self[key] | |||
| return v | |||
| def extend(self, sequential): | |||
| for layer in sequential: | |||
| self.append(layer) | |||
| return self | |||
| def insert(self, index, module): | |||
| """ | |||
| Inserts a given Cell before a given index in the list. | |||
| Args: | |||
| index(int): The Insert index in the CellList. | |||
| cell(Cell): The Cell to be inserted. | |||
| """ | |||
| cls_name = self.__class__.__name__ | |||
| idx = _valid_index(len(self), index, cls_name) | |||
| _valid_cell(module, cls_name) | |||
| length = len(self) | |||
| prefix, key_index = _get_prefix_and_index(self._cells) | |||
| while length > idx: | |||
| if self._auto_prefix: | |||
| tmp_cell = self._cells[str(length-1)] | |||
| for _, param in tmp_cell.parameters_and_names(): | |||
| param.name = f'{prefix}{str(length)}{"."}{".".join(param.name.split(".")[key_index+1:])}' | |||
| self._cells[str(length)] = self._cells[str(length - 1)] | |||
| length -= 1 | |||
| self._cells[str(idx)] = module | |||
| if self._auto_prefix: | |||
| module.update_parameters_name(prefix + str(idx) + ".") | |||
| self.cell_list = list(self._cells.values()) | |||
| self._is_dynamic_name.insert(index, True) | |||
| #_ModuleListBase is similar to ms.nn._CellListBase | |||
| class _ModuleListBase: | |||
| """ | |||
| An interface for base the Module as list. | |||
| The sequential Module may be iterated using the construct method using for-in statement. | |||
| But there are some scenarios that the construct method built-in does not fit. | |||
| For convenience, we provide an interface that indicates the sequential | |||
| Module may be interpreted as list of Cells, so it can be accessed using | |||
| iterator or subscript when a sequential Module instantiate is accessed | |||
| by iterator or subscript, it will be interpreted as a list of Cells. | |||
| """ | |||
| def __init__(self): | |||
| """Initialize _ModuleListBase.""" | |||
| self.__cell_as_list__ = True #for ms jit parse | |||
| @abstractmethod | |||
| def __len__(self): | |||
| pass | |||
| @abstractmethod | |||
| def __getitem__(self, index): | |||
| pass | |||
| def construct(self): | |||
| raise NotImplementedError | |||
| class ModuleList(_ModuleListBase, Module): | |||
| """ | |||
| Holds Cells in a list. | |||
| ModuleList can be used like a regular Python list, the Cells it contains have been initialized. | |||
| Args: | |||
| modules (iterable, optional): an iterable of modules to add | |||
| Examples: | |||
| class MyModule(nn.Module): | |||
| def __init__(self): | |||
| super(MyModule, self).__init__() | |||
| self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(10)]) | |||
| def forward(self, x): | |||
| # ModuleList can act as an iterable, or be indexed using ints | |||
| for i, l in enumerate(self.linears): | |||
| x = self.linears[i // 2](x) + l(x) | |||
| return x | |||
| """ | |||
| def __init__(self, modules=None): | |||
| """Initialize ModuleList.""" | |||
| _ModuleListBase.__init__(self) | |||
| Module.__init__(self) | |||
| if modules is not None: | |||
| self.extend(modules) | |||
| def __getitem__(self, idx): | |||
| if isinstance(idx, Tensor): | |||
| idx = int(idx) | |||
| cls_name = self.__class__.__name__ | |||
| if isinstance(idx, slice): | |||
| return self.__class__(list(self._cells.values())[idx]) | |||
| if isinstance(idx, int): | |||
| idx = _valid_index(len(self), idx, cls_name) | |||
| return self._cells[str(idx)] | |||
| raise TypeError(f"For '{cls_name}', the type of 'idx' must be int or slice, " | |||
| f"but got {type(idx).__name__}.") | |||
| def __setitem__(self, idx, module): | |||
| if isinstance(idx, Tensor): | |||
| idx = int(idx) | |||
| cls_name = self.__class__.__name__ | |||
| if not isinstance(idx, int) and _valid_cell(module, cls_name): | |||
| raise TypeError(f"For '{cls_name}', the type of 'idx' must be int, " | |||
| f"but got {type(idx).__name__}.") | |||
| idx = _valid_index(len(self), idx, cls_name) | |||
| if self._auto_prefix: | |||
| prefix, _ = _get_prefix_and_index(self._cells) | |||
| module.update_parameters_name(prefix + str(idx) + ".") | |||
| self._cells[str(idx)] = module | |||
| def __delitem__(self, idx): | |||
| if isinstance(idx, Tensor): | |||
| idx = int(idx) | |||
| cls_name = self.__class__.__name__ | |||
| if isinstance(idx, int): | |||
| idx = _valid_index(len(self), idx, cls_name) | |||
| del self._cells[str(idx)] | |||
| elif isinstance(idx, slice): | |||
| keys = list(self._cells.keys())[idx] | |||
| for key in keys: | |||
| del self._cells[key] | |||
| else: | |||
| raise TypeError(f"For '{cls_name}', the type of 'index' must be int or slice, " | |||
| f"but got {type(idx).__name__}.") | |||
| # adjust orderedDict | |||
| prefix, key_index = _get_prefix_and_index(self._cells) | |||
| temp_dict = OrderedDict() | |||
| for id, cell in enumerate(self._cells.values()): | |||
| if self._auto_prefix: | |||
| for _, param in cell.parameters_and_names(): | |||
| param.name = prefix + str(id) + "." + ".".join(param.name.split(".")[key_index+1:]) | |||
| temp_dict[str(id)] = cell | |||
| self._cells = temp_dict | |||
| def __len__(self): | |||
| return len(self._cells) | |||
| def __iter__(self): | |||
| return iter(self._cells.values()) | |||
| def __iadd__(self, modules): | |||
| return self.extend(modules) | |||
| def __add__(self, other): | |||
| combined = ModuleList() | |||
| for _, module in enumerate(chain(self, other)): | |||
| combined.append(module) | |||
| return combined | |||
| def __dir__(self): | |||
| keys = super(ModuleList, self).__dir__() | |||
| keys = [key for key in keys if not key.isdigit()] | |||
| return keys | |||
| def pop(self, key): | |||
| v = self[key] | |||
| del self[key] | |||
| return v | |||
| def insert(self, index, module): | |||
| """ | |||
| Inserts a given Module before a given index in the list. | |||
| Args: | |||
| index(int): The Insert index in the ModuleList. | |||
| module(Module): The Module to be inserted. | |||
| """ | |||
| cls_name = self.__class__.__name__ | |||
| idx = _valid_index(len(self), index, cls_name) | |||
| _valid_cell(module, cls_name) | |||
| length = len(self) | |||
| prefix, key_index = _get_prefix_and_index(self._cells) | |||
| while length > idx: | |||
| if self._auto_prefix: | |||
| tmp_cell = self._cells[str(length-1)] | |||
| for _, param in tmp_cell.parameters_and_names(): | |||
| param.name = prefix + str(length) + "." + ".".join(param.name.split(".")[key_index+1:]) | |||
| self._cells[str(length)] = self._cells[str(length - 1)] | |||
| length -= 1 | |||
| self._cells[str(idx)] = module | |||
| if self._auto_prefix: | |||
| module.update_parameters_name(prefix + str(idx) + ".") | |||
| def extend(self, modules): | |||
| """ | |||
| Appends Cells from a Python iterable to the end of the list. | |||
| Args: | |||
| cells(list): The Cells to be extended. | |||
| Raises: | |||
| TypeError: If the argument cells are not a list of Cells. | |||
| """ | |||
| cls_name = self.__class__.__name__ | |||
| if not isinstance(modules, container_abcs.Iterable): | |||
| raise TypeError("ModuleList.extend should be called with an " | |||
| "iterable, but got " + type(modules).__name__) | |||
| prefix, _ = _get_prefix_and_index(self._cells) | |||
| for module in modules: | |||
| if _valid_cell(module, cls_name): | |||
| if self._auto_prefix: | |||
| module.update_parameters_name(prefix + str(len(self)) + ".") | |||
| self._cells[str(len(self))] = module | |||
| return self | |||
| def append(self, module): | |||
| """ | |||
| Appends a given Module to the end of the list. | |||
| Args: | |||
| module(Module): The subcell to be appended. | |||
| """ | |||
| if _valid_cell(module, self.__class__.__name__): | |||
| if self._auto_prefix: | |||
| prefix, _ = _get_prefix_and_index(self._cells) | |||
| module.update_parameters_name(prefix + str(len(self)) + ".") | |||
| self._cells[str(len(self))] = module | |||
| def set_grad(self, flag=True): | |||
| self.requires_grad = flag | |||
| for cell in self._cells.values(): | |||
| cell.set_grad(flag) | |||
| def construct(self, *inputs): | |||
| raise NotImplementedError | |||
| class ModuleDict(Module): | |||
| r"""Holds submodules in a dictionary. | |||
| :class:`nn.ModuleDict` can be indexed like a regular Python dictionary, | |||
| but modules it contains are properly registered, and will be visible by all | |||
| :class:`nn.Module` methods. | |||
| :class:`nn.ModuleDict` is an **ordered** dictionary that respects | |||
| * the order of insertion, and | |||
| * in :meth:`nn.ModuleDict.update`, the order of the merged | |||
| ``OrderedDict``, ``dict`` (started from Python 3.6) or another | |||
| :class:`nn.ModuleDict` (the argument to | |||
| :meth:`nn.ModuleDict.update`). | |||
| Note that :meth:`nn.ModuleDict.update` with other unordered mapping | |||
| types (e.g., Python's plain ``dict`` before Python version 3.6) does not | |||
| preserve the order of the merged mapping. | |||
| Args: | |||
| modules (iterable, optional): a mapping (dictionary) of (string: module) | |||
| or an iterable of key-value pairs of type (string, module) | |||
| Example:: | |||
| class MyModule(nn.Module): | |||
| def __init__(self): | |||
| super(MyModule, self).__init__() | |||
| self.choices = nn.ModuleDict({ | |||
| 'conv': nn.Conv2d(10, 10, 3), | |||
| 'pool': nn.MaxPool2d(3) | |||
| }) | |||
| self.activations = nn.ModuleDict([ | |||
| ['lrelu', nn.LeakyReLU()], | |||
| ['prelu', nn.PReLU()] | |||
| ]) | |||
| def forward(self, x, choice, act): | |||
| x = self.choices[choice](x) | |||
| x = self.activations[act](x) | |||
| return x | |||
| """ | |||
| def __init__(self, modules=None): | |||
| super(ModuleDict, self).__init__() | |||
| if modules is not None: | |||
| self.update(modules) | |||
| def __getitem__(self, key): | |||
| return self._cells[key] | |||
| def __setitem__(self, key, module): | |||
| self.add_module(key, module) | |||
| def __delitem__(self, key): | |||
| del self._cells[key] | |||
| def __len__(self): | |||
| return len(self._cells) | |||
| def __iter__(self): | |||
| return iter(self._cells) | |||
| def __contains__(self, key): | |||
| return key in self._cells | |||
| def clear(self): | |||
| """Remove all items from the ModuleDict. | |||
| """ | |||
| self._cells.clear() | |||
| def pop(self, key): | |||
| r"""Remove key from the ModuleDict and return its module. | |||
| Args: | |||
| key (str): key to pop from the ModuleDict | |||
| """ | |||
| v = self[key] | |||
| del self[key] | |||
| return v | |||
| def keys(self): | |||
| r"""Return an iterable of the ModuleDict keys. | |||
| """ | |||
| return self._cells.keys() | |||
| def items(self): | |||
| r"""Return an iterable of the ModuleDict key/value pairs. | |||
| """ | |||
| return self._cells.items() | |||
| def values(self): | |||
| r"""Return an iterable of the ModuleDict values. | |||
| """ | |||
| return self._cells.values() | |||
| def update(self, modules): | |||
| r"""Update the :class:`nn.ModuleDict` with the key-value pairs from a | |||
| mapping or an iterable, overwriting existing keys. | |||
| .. note:: | |||
| If :attr:`modules` is an ``OrderedDict``, a :class:`nn.ModuleDict`, or | |||
| an iterable of key-value pairs, the order of new elements in it is preserved. | |||
| Args: | |||
| modules (iterable): a mapping (dictionary) from string to :class:`nn.Module`, | |||
| or an iterable of key-value pairs of type (string, :class:`nn.Module`) | |||
| """ | |||
| if not isinstance(modules, container_abcs.Iterable): | |||
| raise TypeError("ModuleDict.update should be called with an " | |||
| "iterable of key/value pairs, but got " + | |||
| type(modules).__name__) | |||
| if isinstance(modules, (OrderedDict, ModuleDict, container_abcs.Mapping)): | |||
| for key, module in modules.items(): | |||
| self[key] = module | |||
| else: | |||
| # modules here can be a list with two items | |||
| for j, m in enumerate(modules): | |||
| if not isinstance(m, container_abcs.Iterable): | |||
| raise TypeError("ModuleDict update sequence element " | |||
| "#" + str(j) + " should be Iterable; is" + | |||
| type(m).__name__) | |||
| if not len(m) == 2: | |||
| raise ValueError("ModuleDict update sequence element " | |||
| "#" + str(j) + " has length " + str(len(m)) + | |||
| "; 2 is required") | |||
| # modules can be Mapping (what it's typed at), or a list: [(name1, module1), (name2, module2)] | |||
| # that's too cumbersome to type correctly with overloads, so we add an ignore here | |||
| self[m[0]] = m[1] # type: ignore[assignment] | |||
| # remove forward alltogether to fallback on Module's _forward_unimplemented | |||
| class ParameterList(Module): | |||
| """Holds parameters in a list. | |||
| :class:`nn.ParameterList` can be used like a regular Python | |||
| list, but Tensors that are :class:`nn.Parameter` are properly registered, | |||
| and will be visible by all :class:`nn.Module` methods. | |||
| Note that the constructor, assigning an element of the list, the | |||
| :meth:`nn.ParameterDict.append` method and the :meth:`nn.ParameterDict.extend` | |||
| method will convert any :class:`Tensor` into :class:`nn.Parameter`. | |||
| Args: | |||
| parameters (iterable, optional): an iterable of elements to add to the list. | |||
| Example:: | |||
| class MyModule(nn.Module): | |||
| def __init__(self): | |||
| super(MyModule, self).__init__() | |||
| self.params = nn.ParameterList([nn.Parameter(ms_torch.randn(10, 10)) for i in range(10)]) | |||
| def forward(self, x): | |||
| # ParameterList can act as an iterable, or be indexed using ints | |||
| for i, p in enumerate(self.params): | |||
| x = self.params[i // 2].mm(x) + p.mm(x) | |||
| return x | |||
| """ | |||
| def __init__(self, values=None): | |||
| super(ParameterList, self).__init__() | |||
| self._size = 0 | |||
| if values is not None: | |||
| self += values | |||
| def _get_abs_string_index(self, idx): | |||
| """Get the absolute index for the list of modules""" | |||
| idx = operator.index(idx) | |||
| if not -len(self) <= idx < len(self): | |||
| raise IndexError('index {} is out of range'.format(idx)) | |||
| if idx < 0: | |||
| idx += len(self) | |||
| return str(idx) | |||
| def __getitem__(self, idx): | |||
| if isinstance(idx, slice): | |||
| start, stop, step = idx.indices(len(self)) | |||
| out = self.__class__() | |||
| for i in range(start, stop, step): | |||
| out.append(self[i]) | |||
| return out | |||
| else: | |||
| idx = self._get_abs_string_index(idx) | |||
| return getattr(self, str(idx)) | |||
| def __setitem__(self, idx, param): | |||
| # Note that all other function that add an entry to the list part of | |||
| # the ParameterList end up here. So this is the only place where we need | |||
| # to wrap things into Parameter if needed. | |||
| # Objects added via setattr() are not in the list part and thus won't | |||
| # call into this function. | |||
| idx = self._get_abs_string_index(idx) | |||
| if isinstance(param, Tensor) and not isinstance(param, Parameter): | |||
| param = Parameter(param) | |||
| return setattr(self, str(idx), param) | |||
| def __len__(self): | |||
| return self._size | |||
| def __iter__(self): | |||
| return iter(self[i] for i in range(len(self))) | |||
| def __iadd__(self, parameters): | |||
| return self.extend(parameters) | |||
| def __dir__(self): | |||
| keys = super(ParameterList, self).__dir__() | |||
| keys = [key for key in keys if not key.isdigit()] | |||
| return keys | |||
| def append(self, value): | |||
| """Appends a given value at the end of the list. | |||
| Args: | |||
| value (Any): value to append | |||
| """ | |||
| new_idx = len(self) | |||
| self._size += 1 | |||
| self[new_idx] = value | |||
| return self | |||
| def extend(self, values): | |||
| """Appends values from a Python iterable to the end of the list. | |||
| Args: | |||
| values (iterable): iterable of values to append | |||
| """ | |||
| # Tensor is an iterable but we never want to unpack it here | |||
| if not isinstance(values, container_abcs.Iterable) or isinstance(values, Tensor): | |||
| raise TypeError("ParameterList.extend should be called with an " | |||
| "iterable, but got " + type(values).__name__) | |||
| for value in values: | |||
| self.append(value) | |||
| return self | |||
| def extra_repr(self): | |||
| child_lines = [] | |||
| for k, p in enumerate(self): | |||
| if isinstance(p, Tensor): | |||
| size_str = 'x'.join(str(size) for size in p.size()) | |||
| device_str = '' if not p.is_cuda else ' (GPU {})'.format(p.get_device()) | |||
| parastr = '{} containing: [{} of size {}{}]'.format( | |||
| "Parameter" if isinstance(p, Parameter) else "Tensor", | |||
| p.dtype, size_str, device_str) | |||
| child_lines.append(' (' + str(k) + '): ' + parastr) | |||
| else: | |||
| child_lines.append(' (' + str(k) + '): Object of type: ' + type(p).__name__) | |||
| tmpstr = '\n'.join(child_lines) | |||
| return tmpstr | |||
| def __call__(self, *args, **kwargs): | |||
| raise RuntimeError('ParameterList should not be called.') | |||
| # adpater api, to convert ParameterList to list[Parameter] | |||
| def to_list(self): | |||
| list_params = [] | |||
| for i, p in enumerate(self): | |||
| p.name = str(i) + "." + p.name | |||
| list_params.append(p) | |||
| return list_params | |||
| class ParameterDict(Module): | |||
| """Holds parameters in a dictionary. | |||
| ParameterDict can be indexed like a regular Python dictionary, but Parameters it | |||
| contains are properly registered, and will be visible by all Module methods. | |||
| Other objects are treated as would be done by a regular Python dictionary | |||
| :class:`nn.ParameterDict` is an **ordered** dictionary. | |||
| :meth:`nn.ParameterDict.update` with other unordered mapping | |||
| types (e.g., Python's plain ``dict``) does not preserve the order of the | |||
| merged mapping. On the other hand, ``OrderedDict`` or another :class:`nn.ParameterDict` | |||
| will preserve their ordering. | |||
| Note that the constructor, assigning an element of the dictionary and the | |||
| :meth:`nn.ParameterDict.update` method will convert any :class:`Tensor` into | |||
| :class:`nn.Parameter`. | |||
| Args: | |||
| values (iterable, optional): a mapping (dictionary) of | |||
| (string : Any) or an iterable of key-value pairs | |||
| of type (string, Any) | |||
| Example:: | |||
| class MyModule(nn.Module): | |||
| def __init__(self): | |||
| super(MyModule, self).__init__() | |||
| self.params = nn.ParameterDict({ | |||
| 'left': nn.Parameter(ms_torch.randn(5, 10)), | |||
| 'right': nn.Parameter(ms_torch.randn(5, 10)) | |||
| }) | |||
| def forward(self, x, choice): | |||
| x = self.params[choice].mm(x) | |||
| return x | |||
| """ | |||
| def __init__(self, parameters = None): | |||
| super(ParameterDict, self).__init__() | |||
| self._keys: Dict[str, None] = {} | |||
| if parameters is not None: | |||
| self.update(parameters) | |||
| def _key_to_attr(self, key): | |||
| if not isinstance(key, str): | |||
| raise TypeError("Index given to ParameterDict cannot be used as a key as it is " | |||
| f"not a string (type is '{type(key).__name__}'). Open an issue on " | |||
| "github if you need non-string keys.") | |||
| else: | |||
| # Use the key as-is so that `.named_parameters()` returns the right thing | |||
| return key | |||
| def __getitem__(self, key): | |||
| attr = self._key_to_attr(key) | |||
| return getattr(self, attr) | |||
| def __setitem__(self, key, value): | |||
| # Note that all other function that add an entry to the dictionary part of | |||
| # the ParameterDict end up here. So this is the only place where we need | |||
| # to wrap things into Parameter if needed. | |||
| # Objects added via setattr() are not in the dictionary part and thus won't | |||
| # call into this function. | |||
| self._keys[key] = None | |||
| attr = self._key_to_attr(key) | |||
| if isinstance(value, Tensor) and not isinstance(value, Parameter): | |||
| value = Parameter(value) | |||
| setattr(self, attr, value) | |||
| def __delitem__(self, key): | |||
| del self._keys[key] | |||
| attr = self._key_to_attr(key) | |||
| delattr(self, attr) | |||
| def __len__(self): | |||
| return len(self._keys) | |||
| def __iter__(self): | |||
| return iter(self._keys) | |||
| def __reversed__(self): | |||
| return reversed(list(self._keys)) | |||
| def copy(self): | |||
| """Returns a copy of this :class:`nn.ParameterDict` instance. | |||
| """ | |||
| # We have to use an OrderedDict because the ParameterDict constructor | |||
| # behaves differently on plain dict vs OrderedDict | |||
| return ParameterDict(OrderedDict((k, self[k]) for k in self._keys)) | |||
| def __contains__(self, key): | |||
| return key in self._keys | |||
| def setdefault(self, key, default = None): | |||
| """If key is in the ParameterDict, return its value. | |||
| If not, insert `key` with a parameter `default` and return `default`. | |||
| `default` defaults to `None`. | |||
| Args: | |||
| key (str): key to set default for | |||
| default (Any): the parameter set to the key | |||
| """ | |||
| if key not in self: | |||
| self[key] = default | |||
| return self[key] | |||
| def clear(self): | |||
| """Remove all items from the ParameterDict. | |||
| """ | |||
| for k in self._keys.copy(): | |||
| del self[k] | |||
| def pop(self, key): | |||
| r"""Remove key from the ParameterDict and return its parameter. | |||
| Args: | |||
| key (str): key to pop from the ParameterDict | |||
| """ | |||
| v = self[key] | |||
| del self[key] | |||
| return v | |||
| def popitem(self): | |||
| """Remove and return the last inserted `(key, parameter)` pair | |||
| from the ParameterDict | |||
| """ | |||
| k, _ = self._keys.popitem() | |||
| # We need the key in the _keys to be able to access/del | |||
| self._keys[k] = None | |||
| val = self[k] | |||
| del self[k] | |||
| return k, val | |||
| def get(self, key, default = None): | |||
| r"""Return the parameter associated with key if present. | |||
| Otherwise return default if provided, None if not. | |||
| Args: | |||
| key (str): key to get from the ParameterDict | |||
| default (Parameter, optional): value to return if key not present | |||
| """ | |||
| return self[key] if key in self else default | |||
| def fromkeys(self, keys, default = None): | |||
| r"""Return a new ParameterDict with the keys provided | |||
| Args: | |||
| keys (iterable, string): keys to make the new ParameterDict from | |||
| default (Parameter, optional): value to set for all keys | |||
| """ | |||
| return ParameterDict(((k, default) for k in keys)) | |||
| def keys(self): | |||
| r"""Return an iterable of the ParameterDict keys. | |||
| """ | |||
| return self._keys.keys() | |||
| def items(self): | |||
| r"""Return an iterable of the ParameterDict key/value pairs. | |||
| """ | |||
| return ((k, self[k]) for k in self._keys) | |||
| def values(self): | |||
| r"""Return an iterable of the ParameterDict values. | |||
| """ | |||
| return (self[k] for k in self._keys) | |||
| def update(self, parameters): | |||
| r"""Update the :class:`~nn.ParameterDict` with the key-value pairs from a | |||
| mapping or an iterable, overwriting existing keys. | |||
| .. note:: | |||
| If :attr:`parameters` is an ``OrderedDict``, a :class:`~nn.ParameterDict`, or | |||
| an iterable of key-value pairs, the order of new elements in it is preserved. | |||
| Args: | |||
| parameters (iterable): a mapping (dictionary) from string to | |||
| :class:`~nn.Parameter`, or an iterable of | |||
| key-value pairs of type (string, :class:`~nn.Parameter`) | |||
| """ | |||
| if not isinstance(parameters, container_abcs.Iterable): | |||
| raise TypeError("ParametersDict.update should be called with an " | |||
| "iterable of key/value pairs, but got " + | |||
| type(parameters).__name__) | |||
| if isinstance(parameters, (OrderedDict, ParameterDict)): | |||
| for key, parameter in parameters.items(): | |||
| self[key] = parameter | |||
| elif isinstance(parameters, container_abcs.Mapping): | |||
| for key, parameter in sorted(parameters.items()): | |||
| self[key] = parameter | |||
| else: | |||
| for j, p in enumerate(parameters): | |||
| if not isinstance(p, container_abcs.Iterable): | |||
| raise TypeError("ParameterDict update sequence element " | |||
| "#" + str(j) + " should be Iterable; is" + | |||
| type(p).__name__) | |||
| if not len(p) == 2: | |||
| raise ValueError("ParameterDict update sequence element " | |||
| "#" + str(j) + " has length " + str(len(p)) + | |||
| "; 2 is required") | |||
| # parameters as length-2 list too cumbersome to type, see ModuleDict.update comment | |||
| self[p[0]] = p[1] # type: ignore[assignment] | |||
| def extra_repr(self): | |||
| child_lines = [] | |||
| for k, p in self.items(): | |||
| if isinstance(p, Tensor): | |||
| size_str = 'x'.join(str(size) for size in p.size()) | |||
| device_str = '' if not p.is_cuda else ' (GPU {})'.format(p.get_device()) | |||
| parastr = '{} containing: [{} of size {}{}]'.format( | |||
| "Parameter" if isinstance(p, Parameter) else "Tensor", | |||
| typename(p), size_str, device_str) | |||
| child_lines.append(' (' + str(k) + '): ' + parastr) | |||
| else: | |||
| child_lines.append(' (' + str(k) + '): Object of type: ' + type(p).__name__) | |||
| tmpstr = '\n'.join(child_lines) | |||
| return tmpstr | |||
| def __call__(self, input): | |||
| raise RuntimeError('ParameterDict should not be called.') | |||
| def __or__(self, other): | |||
| copy = self.copy() | |||
| copy.update(other) | |||
| return copy | |||
| def __ror__(self, other): | |||
| copy = other.copy() | |||
| copy.update(self) | |||
| return copy | |||
| def __ior__(self, other): | |||
| self.update(other) | |||
| return self | |||
| def to_dict(self): | |||
| new_dict = {} | |||
| for key in self._keys: | |||
| new_dict[key] = self[key] | |||
| return new_dict | |||
+ 601
- 0
msadapter/pytorch/nn/modules/conv.py
View File
| @@ -0,0 +1,601 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import math | |||
| # from functools import lru_cache | |||
| import mindspore as ms | |||
| from mindspore.ops.primitive import _primexpr | |||
| from msadapter.pytorch.nn.parameter import Parameter | |||
| from msadapter.pytorch.nn import init | |||
| from msadapter.pytorch.functional import empty | |||
| from msadapter.utils import unsupported_attr | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from msadapter.pytorch.nn.functional import conv2d, conv_transpose3d, conv1d, conv3d, \ | |||
| _deconv_output_length, _process_conv_transpose1d_const | |||
| # from .utils import _triple, _pair, _single, _reverse_repeat_tuple, _GLOBAL_LRU_CACHE_SIZE_NN | |||
| from .utils import _triple, _pair, _single, _reverse_repeat_tuple | |||
| from .module import Module | |||
| __all__ = ['Conv1d', 'Conv2d', 'Conv3d', | |||
| 'ConvTranspose1d', 'ConvTranspose2d', 'ConvTranspose3d'] | |||
| class _ConvNd(Module): | |||
| def __init__(self, | |||
| in_channels, | |||
| out_channels, | |||
| kernel_size, | |||
| stride, | |||
| padding, | |||
| dilation, | |||
| transposed, | |||
| output_padding, | |||
| groups, | |||
| bias, | |||
| padding_mode, | |||
| device=None, | |||
| dtype=None, | |||
| ): | |||
| """Initialize _Conv.""" | |||
| unsupported_attr(device) | |||
| unsupported_attr(dtype) | |||
| super(_ConvNd, self).__init__() | |||
| self.in_channels = in_channels | |||
| self.out_channels = out_channels | |||
| self.kernel_size = kernel_size | |||
| self.stride = stride | |||
| self.padding = padding | |||
| self.dilation = dilation | |||
| self.transposed = transposed | |||
| self.output_padding = output_padding | |||
| self.groups = groups | |||
| self.padding_mode = padding_mode | |||
| # MS add | |||
| self.has_bias = bias | |||
| if in_channels % groups != 0: | |||
| raise ValueError('in_channels must be divisible by groups') | |||
| if out_channels % groups != 0: | |||
| raise ValueError('out_channels must be divisible by groups') | |||
| valid_padding_strings = {'same', 'valid'} | |||
| if isinstance(padding, str): | |||
| if padding not in valid_padding_strings: | |||
| raise ValueError( | |||
| "Invalid padding string {!r}, should be one of {}".format( | |||
| padding, valid_padding_strings)) | |||
| if padding == 'same' and any(s != 1 for s in stride): | |||
| raise ValueError("padding='same' is not supported for strided convolutions") | |||
| if isinstance(self.padding, str): | |||
| self._reversed_padding_repeated_twice = [0, 0] * len(kernel_size) | |||
| if padding == 'same': | |||
| for d, k, i in zip(dilation, kernel_size, | |||
| range(len(kernel_size) - 1, -1, -1)): | |||
| total_padding = d * (k - 1) | |||
| left_pad = total_padding // 2 | |||
| self._reversed_padding_repeated_twice[2 * i] = left_pad | |||
| self._reversed_padding_repeated_twice[2 * i + 1] = ( | |||
| total_padding - left_pad) | |||
| else: | |||
| self._reversed_padding_repeated_twice = _reverse_repeat_tuple(self.padding, 2) | |||
| if transposed: | |||
| self.weight = Parameter(empty((in_channels, out_channels // groups, *kernel_size))) | |||
| else: | |||
| self.weight = Parameter(empty((out_channels, in_channels // groups, *kernel_size))) | |||
| if bias: | |||
| self.bias = Parameter(empty(out_channels)) | |||
| else: | |||
| self.bias = None | |||
| self.reset_parameters() | |||
| def reset_parameters(self): | |||
| init.kaiming_uniform_(self.weight, a=math.sqrt(5)) | |||
| if self.bias is not None: | |||
| fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight) | |||
| if fan_in != 0: | |||
| bound = 1 / math.sqrt(fan_in) | |||
| init.uniform_(self.bias, -bound, bound) | |||
| def extra_repr(self): | |||
| s = 'input_channels={}, output_channels={}, kernel_size={}, ' \ | |||
| 'stride={}, padding={}, dilation={}, ' \ | |||
| 'group={}, has_bias={}'.format(self.in_channels, | |||
| self.out_channels, | |||
| self.kernel_size, | |||
| self.stride, | |||
| self.padding, | |||
| self.dilation, | |||
| self.groups, | |||
| self.has_bias) | |||
| return s | |||
| class Conv1d(_ConvNd): | |||
| r""" | |||
| 1D convolution layer. | |||
| Calculates the 1D convolution on the input tensor which is typically of shape :math:`(N, C_{in}, L_{in})`, | |||
| where :math:`N` is batch size, :math:`C_{in}` is a number of channels and :math:`L_{in}` is a length of | |||
| sequence. For the tensor of each batch, its shape is :math:`(C_{in}, L_{in})`, the formula is defined as: | |||
| Supported Platforms: | |||
| ``Ascend`` ``GPU`` ``CPU`` | |||
| Examples: | |||
| >>> net = nn.Conv1d(120, 240, 4, has_bias=False, weight_init='normal') | |||
| >>> x = Tensor(np.ones([1, 120, 640]), mindspore.float32) | |||
| >>> output = net(x).shape | |||
| >>> print(output) | |||
| (1, 240, 640) | |||
| """ | |||
| def __init__( | |||
| self, | |||
| in_channels, | |||
| out_channels, | |||
| kernel_size, | |||
| stride=1, | |||
| padding=0, | |||
| dilation=1, | |||
| groups=1, | |||
| bias=True, | |||
| padding_mode='zeros', | |||
| device=None, | |||
| dtype=None | |||
| ): | |||
| factory_kwargs = {'device': device, 'dtype': dtype} | |||
| kernel_size_ = _single(kernel_size) | |||
| stride_ = _single(stride) | |||
| padding_ = padding if isinstance(padding, str) else _single(padding) | |||
| dilation_ = _single(dilation) | |||
| super(Conv1d, self).__init__(in_channels, out_channels, kernel_size_, stride_, padding_, dilation_, | |||
| False, _single(0), groups, bias, padding_mode, **factory_kwargs) | |||
| #TODO pad_mode in ['zeros', 'reflect', 'replicate', 'circular'] | |||
| if padding_mode in {'reflect', 'replicate', 'circular'}: | |||
| raise ValueError("Pad mode '{}' is not currently supported.".format(padding_mode)) | |||
| def forward(self, input): | |||
| x = cast_to_ms_tensor(input) | |||
| ndim = x.ndim | |||
| if ndim == 2: | |||
| x = x.expand_dims(0) | |||
| output = conv1d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups) | |||
| output = output.squeeze(0) | |||
| else: | |||
| output = conv1d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups) | |||
| return output | |||
| class Conv2d(_ConvNd): | |||
| def __init__(self, | |||
| in_channels, | |||
| out_channels, | |||
| kernel_size, | |||
| stride=1, | |||
| padding=0, | |||
| dilation=1, | |||
| groups=1, | |||
| bias=True, | |||
| padding_mode='zeros', | |||
| device=None, | |||
| dtype=None): | |||
| """Initialize Conv2d.""" | |||
| factory_kwargs = {'device': device, 'dtype': dtype} | |||
| kernel_size_ = _pair(kernel_size) | |||
| stride_ = _pair(stride) | |||
| padding_ = padding if isinstance(padding, str) else _pair(padding) | |||
| dilation_ = _pair(dilation) | |||
| super(Conv2d, self).__init__(in_channels, out_channels, kernel_size_, stride_, padding_, dilation_, | |||
| False, _pair(0), groups, bias, padding_mode, **factory_kwargs) | |||
| #TODO pad_mode in ['zeros', 'reflect', 'replicate', 'circular'] | |||
| if padding_mode in {'reflect', 'replicate', 'circular'}: | |||
| raise ValueError("Pad mode '{}' is not currently supported.".format(padding_mode)) | |||
| def forward(self, input): | |||
| x = cast_to_ms_tensor(input) | |||
| ndim = x.ndim | |||
| if ndim == 3: | |||
| x = x.expand_dims(0) | |||
| # Under pynative-mode, self.stride, etc can be changed at any time. | |||
| # However, under graph-mode, the graph will be generated at first time running and can not | |||
| # be altered anymore. After that, self.stride, etc are not supported to be changed dynamically. | |||
| output = conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups) | |||
| output = output.squeeze(0) | |||
| else: | |||
| output = conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups) | |||
| return output | |||
| class Conv3d(_ConvNd): | |||
| r""" | |||
| 3D convolution layer. | |||
| Calculates the 3D convolution on the input tensor which is typically of shape | |||
| Supported Platforms: | |||
| ``Ascend`` ``GPU`` ``CPU`` | |||
| Examples: | |||
| >>> x = Tensor(np.ones([16, 3, 10, 32, 32]), mindspore.float32) | |||
| >>> conv3d = nn.Conv3d(in_channels=3, out_channels=32, kernel_size=(4, 3, 3)) | |||
| >>> output = conv3d(x) | |||
| >>> print(output.shape) | |||
| (16, 32, 10, 32, 32) | |||
| """ | |||
| def __init__( | |||
| self, | |||
| in_channels, | |||
| out_channels, | |||
| kernel_size, | |||
| stride=1, | |||
| padding=0, | |||
| dilation=1, | |||
| groups=1, | |||
| bias=True, | |||
| padding_mode='zeros', | |||
| device=None, | |||
| dtype=None | |||
| ): | |||
| factory_kwargs = {'device': device, 'dtype': dtype} | |||
| kernel_size_ = _triple(kernel_size) | |||
| stride_ = _triple(stride) | |||
| padding_ = padding if isinstance(padding, str) else _triple(padding) | |||
| dilation_ = _triple(dilation) | |||
| super(Conv3d, self).__init__(in_channels, out_channels, kernel_size_, stride_, padding_, dilation_, | |||
| False, _triple(0), groups, bias, padding_mode, **factory_kwargs) | |||
| #TODO pad_mode in ['zeros', 'reflect', 'replicate', 'circular'] | |||
| if padding_mode in {'reflect', 'replicate', 'circular'}: | |||
| raise ValueError("Pad mode '{}' is not currently supported.".format(padding_mode)) | |||
| def forward(self, input): | |||
| x = cast_to_ms_tensor(input) | |||
| ndim = input.ndim | |||
| if ndim == 4: | |||
| x = x.expand_dims(0) | |||
| output = conv3d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups) | |||
| output = output.squeeze(0) | |||
| else: | |||
| output = conv3d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups) | |||
| return output | |||
| @_primexpr | |||
| # @lru_cache(_GLOBAL_LRU_CACHE_SIZE_NN) | |||
| def _output_padding(output_padding, input_ndim, input_shape, output_size, | |||
| stride, padding, kernel_size, | |||
| num_spatial_dims, dilation=None): | |||
| if output_size is None: | |||
| ret = _single(output_padding) | |||
| else: | |||
| has_batch_dim = input_ndim == num_spatial_dims + 2 | |||
| num_non_spatial_dims = 2 if has_batch_dim else 1 | |||
| if len(output_size) == num_non_spatial_dims + num_spatial_dims: | |||
| output_size = output_size[num_non_spatial_dims:] | |||
| if len(output_size) != num_spatial_dims: | |||
| raise ValueError( | |||
| f"ConvTranspose{num_spatial_dims}D: for {input.dim()}D input, " | |||
| f"output_size must have {num_spatial_dims} " | |||
| f"or {num_non_spatial_dims + num_spatial_dims} elements (got {len(output_size)})") | |||
| min_sizes = [] | |||
| max_sizes = [] | |||
| for d in range(num_spatial_dims): | |||
| dim_size = ((input_shape[d + num_non_spatial_dims] - 1) * stride[d] - | |||
| 2 * padding[d] + | |||
| (dilation[d] if dilation is not None else 1) * (kernel_size[d] - 1) + 1) | |||
| min_sizes.append(dim_size) | |||
| max_sizes.append(min_sizes[d] + stride[d] - 1) | |||
| for i in range(len(output_size)): | |||
| size = output_size[i] | |||
| min_size = min_sizes[i] | |||
| max_size = max_sizes[i] | |||
| if size < min_size or size > max_size: | |||
| raise ValueError(( | |||
| "requested an output size of {}, but valid sizes range " | |||
| "from {} to {} (for an input of {})").format( | |||
| output_size, min_sizes, max_sizes, input_shape[2:])) | |||
| res = [] | |||
| for d in range(num_spatial_dims): | |||
| res.append(output_size[d] - min_sizes[d]) | |||
| ret = tuple(res) | |||
| return ret | |||
| class _ConvTransposeNd(_ConvNd): | |||
| def __init__(self, in_channels, out_channels, kernel_size, stride, | |||
| padding, dilation, transposed, output_padding, | |||
| groups, bias, padding_mode, device=None, dtype=None): | |||
| if padding_mode != 'zeros': | |||
| raise ValueError('Only "zeros" padding mode is supported for {}'.format(self.__class__.__name__)) | |||
| factory_kwargs = {'device': device, 'dtype': dtype} | |||
| super().__init__( | |||
| in_channels, out_channels, kernel_size, stride, | |||
| padding, dilation, transposed, output_padding, | |||
| groups, bias, padding_mode, **factory_kwargs) | |||
| class ConvTranspose1d(_ConvTransposeNd): | |||
| r""" | |||
| 1D transposed convolution layer. | |||
| Calculates a 1D transposed convolution, which can be regarded as Conv1d for the gradient of the input. | |||
| It also called deconvolution (although it is not an actual deconvolution). | |||
| Supported Platforms: | |||
| ``Ascend`` ``GPU`` ``CPU`` | |||
| Examples: | |||
| >>> net = nn.ConvTranspose1d(3, 64, 4, has_bias=False) | |||
| >>> x = Tensor(np.ones([1, 3, 50]), mindspore.float32) | |||
| >>> output = net(x).shape | |||
| >>> print(output) | |||
| (1, 64, 53) | |||
| """ | |||
| def __init__( | |||
| self, | |||
| in_channels, | |||
| out_channels, | |||
| kernel_size, | |||
| stride=1, | |||
| padding=0, | |||
| output_padding=0, | |||
| groups=1, | |||
| bias=True, | |||
| dilation=1, | |||
| padding_mode='zeros', | |||
| device=None, | |||
| dtype=None, | |||
| ): | |||
| if output_padding > 0: | |||
| raise ValueError("output_padding '{}' is not currently supported.".format(output_padding)) | |||
| factory_kwargs = {'device': device, 'dtype': dtype} | |||
| kernel_size = _single(kernel_size) | |||
| stride = _single(stride) | |||
| padding = _single(padding) | |||
| dilation = _single(dilation) | |||
| output_padding = _single(output_padding) | |||
| super().__init__( | |||
| in_channels, out_channels, kernel_size, stride, padding, dilation, | |||
| True, output_padding, groups, bias, padding_mode, **factory_kwargs) | |||
| if stride[0] != 1 and padding[0] == (kernel_size[0] - 1) // 2 and output_padding[0] == stride[0] - 1: | |||
| _pad_mode = 'same' | |||
| _padding = 0 | |||
| raise Warning("pad_mode = same is some thing wrong, please switch to others") | |||
| elif padding[0] == 0 and output_padding[0] == 0: | |||
| _pad_mode = 'valid' | |||
| _padding = 0 | |||
| else: | |||
| _pad_mode = 'pad' | |||
| _padding = self.padding | |||
| _kernel_size, _stride, _dilation, _padding = \ | |||
| _process_conv_transpose1d_const(self.kernel_size, self.stride, self.dilation, _padding) | |||
| self._ms_pad_mode = _pad_mode | |||
| self._ms_kernel_size = _kernel_size | |||
| self._ms_stride = _stride | |||
| self._ms_dilation = _dilation | |||
| self._ms_padding = _padding | |||
| self._conv_transpose2d = ms.ops.Conv2DBackpropInput(out_channel=self.in_channels, | |||
| kernel_size=_kernel_size, | |||
| mode=1, | |||
| pad_mode=_pad_mode, | |||
| pad=_padding, | |||
| stride=_stride, | |||
| dilation=_dilation, | |||
| group=groups) | |||
| self._bias_add = ms.ops.BiasAdd() | |||
| self._expand_dims = ms.ops.ExpandDims() | |||
| self._squeeze_0 = ms.ops.Squeeze(0) | |||
| self._squeeze_2 = ms.ops.Squeeze(2) | |||
| self._shape = ms.ops.Shape() | |||
| def forward(self, input, output_size=None): | |||
| # TODO: to support `output_size` | |||
| if output_size is not None: | |||
| raise ValueError("output_size '{}' is not currently supported.".format(output_size)) | |||
| x = cast_to_ms_tensor(input) | |||
| ndim = x.ndim | |||
| _weight = self._expand_dims(self.weight, 2) | |||
| if ndim == 2: | |||
| x = self._expand_dims(x, 0) | |||
| x = self._expand_dims(x, 2) | |||
| n, _, h, w = self._shape(x) | |||
| h_out = _deconv_output_length(self._ms_pad_mode, h, self._ms_kernel_size[0], self._ms_stride[0], | |||
| self._ms_dilation[0], self._ms_padding[0] + self._ms_padding[1]) | |||
| w_out = _deconv_output_length(self._ms_pad_mode, w, self._ms_kernel_size[1], self._ms_stride[1], | |||
| self._ms_dilation[1], self._ms_padding[2] + self._ms_padding[3]) | |||
| output = self._conv_transpose2d(x, _weight, (n, self.out_channels, h_out, w_out)) | |||
| if self.bias is not None: | |||
| output = self._bias_add(output, self.bias) | |||
| output = self._squeeze_2(output) | |||
| output = self._squeeze_0(output) | |||
| else: | |||
| x = self._expand_dims(x, 2) | |||
| n, _, h, w = self._shape(x) | |||
| h_out = _deconv_output_length(self._ms_pad_mode, h, self._ms_kernel_size[0], self._ms_stride[0], | |||
| self._ms_dilation[0], self._ms_padding[0] + self._ms_padding[1]) | |||
| w_out = _deconv_output_length(self._ms_pad_mode, w, self._ms_kernel_size[1], self._ms_stride[1], | |||
| self._ms_dilation[1], self._ms_padding[2] + self._ms_padding[3]) | |||
| output = self._conv_transpose2d(x, _weight, (n, self.out_channels, h_out, w_out)) | |||
| if self.bias is not None: | |||
| output = self._bias_add(output, self.bias) | |||
| output = self._squeeze_2(output) | |||
| return cast_to_adapter_tensor(output) | |||
| class ConvTranspose2d(_ConvTransposeNd): | |||
| r""" | |||
| 2D transposed convolution layer. | |||
| Calculates a 2D transposed convolution, which can be regarded as Conv2d for the gradient of the input. | |||
| It also called deconvolution (although it is not an actual deconvolution). | |||
| Supported Platforms: | |||
| ``Ascend`` ``GPU`` ``CPU`` | |||
| Examples: | |||
| >>> net = nn.ConvTranspose2d(3, 64, 4, has_bias=False) | |||
| >>> x = Tensor(np.ones([1, 3, 16, 50]), mindspore.float32) | |||
| >>> output = net(x).shape | |||
| >>> print(output) | |||
| (1, 64, 19, 53) | |||
| """ | |||
| def __init__( | |||
| self, | |||
| in_channels, | |||
| out_channels, | |||
| kernel_size, | |||
| stride=1, | |||
| padding=0, | |||
| output_padding=0, | |||
| groups=1, | |||
| bias=True, | |||
| dilation=1, | |||
| padding_mode='zeros', | |||
| device=None, | |||
| dtype=None | |||
| ): | |||
| factory_kwargs = {'device': device, 'dtype': dtype} | |||
| kernel_size = _pair(kernel_size) | |||
| stride = _pair(stride) | |||
| padding = _pair(padding) | |||
| dilation = _pair(dilation) | |||
| output_padding = _pair(output_padding) | |||
| if output_padding != (0, 0): | |||
| raise ValueError("output_padding '{}' is not currently supported.".format(output_padding)) | |||
| super().__init__( | |||
| in_channels, out_channels, kernel_size, stride, padding, dilation, | |||
| True, output_padding, groups, bias, padding_mode, **factory_kwargs) | |||
| if padding == (0, 0): | |||
| _pad_mode = 'valid' | |||
| else: | |||
| _pad_mode = 'pad' | |||
| self._ms_padding = (padding[0], padding[0], padding[1], padding[1]) | |||
| self._ms_pad_mode = _pad_mode | |||
| self._conv_transpose2d = ms.ops.Conv2DTranspose(out_channel=self.in_channels, | |||
| kernel_size=self.kernel_size, | |||
| mode=1, | |||
| pad_mode=self._ms_pad_mode, | |||
| pad=self._ms_padding, | |||
| stride=self.stride, | |||
| dilation=self.dilation, | |||
| group=groups) | |||
| self._bias_add = ms.ops.BiasAdd() | |||
| self._expand_dims = ms.ops.ExpandDims() | |||
| self._squeeze_0 = ms.ops.Squeeze(0) | |||
| self._shape = ms.ops.Shape() | |||
| def forward(self, input, output_size=None): | |||
| # TODO: To support output_size after ms.ops.Conv2DTranspose support `out_padding` | |||
| if output_size is not None: | |||
| raise ValueError("output_size '{}' is not currently supported.".format(output_size)) | |||
| x = cast_to_ms_tensor(input) | |||
| ndim = x.ndim | |||
| if ndim == 3: | |||
| x = self._expand_dims(x, 0) | |||
| n, _, h, w = self._shape(x) | |||
| h_out = _deconv_output_length(self._ms_pad_mode, h, self.kernel_size[0], self.stride[0], | |||
| self.dilation[0], self._ms_padding[0] + self._ms_padding[1]) | |||
| w_out = _deconv_output_length(self._ms_pad_mode, w, self.kernel_size[1], self.stride[1], | |||
| self.dilation[1], self._ms_padding[2] + self._ms_padding[3]) | |||
| output = self._conv_transpose2d(x, self.weight, (n, self.out_channels, h_out, w_out)) | |||
| if self.bias is not None: | |||
| output = self._bias_add(output, self.bias) | |||
| output = self._squeeze_0(output) | |||
| else: | |||
| n, _, h, w = self._shape(x) | |||
| h_out = _deconv_output_length(self._ms_pad_mode, h, self.kernel_size[0], self.stride[0], | |||
| self.dilation[0], self._ms_padding[0] + self._ms_padding[1]) | |||
| w_out = _deconv_output_length(self._ms_pad_mode, w, self.kernel_size[1], self.stride[1], | |||
| self.dilation[1], self._ms_padding[2] + self._ms_padding[3]) | |||
| output = self._conv_transpose2d(x, self.weight, (n, self.out_channels, h_out, w_out)) | |||
| if self.bias is not None: | |||
| output = self._bias_add(output, self.bias) | |||
| return cast_to_adapter_tensor(output) | |||
| class ConvTranspose3d(_ConvTransposeNd): | |||
| r""" | |||
| 3D transposed convolution layer. | |||
| Calculates a 3D transposed convolution, which can be regarded as Conv3d for the gradient of the input. | |||
| It also called deconvolution (although it is not an actual deconvolution). | |||
| Examples: | |||
| >>> x = Tensor(np.ones([32, 16, 10, 32, 32]), mindspore.float32) | |||
| >>> conv3d_transpose = nn.ConvTranspose3d(in_channels=16, out_channels=3, kernel_size=(4, 6, 2), | |||
| ... pad_mode='pad') | |||
| >>> output = conv3d_transpose(x) | |||
| >>> print(output.shape) | |||
| (32, 3, 13, 37, 33) | |||
| """ | |||
| def __init__( | |||
| self, | |||
| in_channels, | |||
| out_channels, | |||
| kernel_size, | |||
| stride = 1, | |||
| padding = 0, | |||
| output_padding = 0, | |||
| groups = 1, | |||
| bias = True, | |||
| dilation = 1, | |||
| padding_mode = 'zeros', | |||
| device=None, | |||
| dtype=None | |||
| ): | |||
| factory_kwargs = {'device': device, 'dtype': dtype} | |||
| _kernel_size = _triple(kernel_size) | |||
| _stride = _triple(stride) | |||
| _padding = _triple(padding) | |||
| _dilation = _triple(dilation) | |||
| output_padding = _triple(output_padding) | |||
| super(ConvTranspose3d, self).__init__(in_channels, out_channels, _kernel_size, _stride, _padding, _dilation, | |||
| True, output_padding, groups, bias, padding_mode, **factory_kwargs) | |||
| def forward(self, input, output_size = None): | |||
| if self.padding_mode != 'zeros': | |||
| raise ValueError('Only `zeros` padding mode is supported for ConvTranspose3d') | |||
| ndim = input.ndim | |||
| input_shape = input.size() | |||
| num_spatial_dims = 3 | |||
| if output_size is not None: | |||
| output_size = tuple(output_size) | |||
| _out_padding = _output_padding(self.output_padding, ndim, input_shape, output_size, | |||
| self.stride, self.padding, self.kernel_size, num_spatial_dims, | |||
| self.dilation) | |||
| if ndim == 4: | |||
| input = input.unsqueeze(0) | |||
| output = conv_transpose3d(input, self.weight, self.bias, self.stride, | |||
| self.padding, _out_padding, self.groups, self.dilation) | |||
| output = output.squeeze(0) | |||
| else: | |||
| output = conv_transpose3d(input, self.weight, self.bias, self.stride, | |||
| self.padding, _out_padding, self.groups, self.dilation) | |||
| return cast_to_adapter_tensor(output) | |||
ms_adapter/pytorch/nn/modules/distance.py → msadapter/pytorch/nn/modules/distance.py
View File
| @@ -1,7 +1,7 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import ms_adapter.pytorch.nn.functional as ms_torch_nn_func | |||
| import msadapter.pytorch.nn.functional as ms_torch_nn_func | |||
| from .module import Module | |||
| __all__ = ['PairwiseDistance', 'CosineSimilarity'] | |||
ms_adapter/pytorch/nn/modules/dropout.py → msadapter/pytorch/nn/modules/dropout.py
View File
| @@ -1,18 +1,20 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from mindspore.common.seed import _get_graph_seed | |||
| from mindspore.ops import operations as P | |||
| from ms_adapter.pytorch.tensor import cast_to_ms_tensor | |||
| import ms_adapter.pytorch.nn.functional as ms_torch_nn_func | |||
| from ms_adapter.pytorch.common._inner import _inplace_assign, _inplace_limit_pynative | |||
| import mindspore as ms | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor | |||
| import msadapter.pytorch.nn.functional as ms_torch_nn_func | |||
| from msadapter.pytorch.common._inner import _inplace_assign, _inplace_limit_pynative | |||
| from .module import Module | |||
| __all__ = ['Dropout', 'Dropout2d', 'Dropout3d', 'AlphaDropout', 'FeatureAlphaDropout'] | |||
| __all__ = ['Dropout', 'Dropout1d', 'Dropout2d', 'Dropout3d', 'AlphaDropout', 'FeatureAlphaDropout'] | |||
| class _DropoutNd(Module): | |||
| def __init__(self, p=0.5, inplace=False): | |||
| super(_DropoutNd, self).__init__() | |||
| if p < 0 or p > 1: | |||
| raise ValueError("dropout probability has to be between 0 and 1, " | |||
| "but got {}".format(p)) | |||
| self.p = p | |||
| self.inplace = inplace | |||
| @@ -46,38 +48,33 @@ class Dropout(_DropoutNd): | |||
| Examples:: | |||
| >>> m = nn.Dropout(p=0.2) | |||
| >>> input = ms_adapter.pytorch.randn(20, 16) | |||
| >>> input = msadapter.pytorch.randn(20, 16) | |||
| >>> output = m(input) | |||
| .. _Improving neural networks by preventing co-adaptation of feature | |||
| detectors: https://arxiv.org/abs/1207.0580 | |||
| """ | |||
| def __init__(self, p=0.5, inplace=False): | |||
| _inplace_limit_pynative(inplace, "Dropout") | |||
| super(Dropout, self).__init__(p, inplace) | |||
| if p < 0 or p > 1: | |||
| raise ValueError("dropout probability has to be between 0 and 1, " | |||
| "but got {}".format(p)) | |||
| self.keep_prob = 1.0 - self.p | |||
| seed0, seed1 = _get_graph_seed(0, "dropout") | |||
| self.seed0 = seed0 | |||
| self.seed1 = seed1 | |||
| self.dropout = P.Dropout(self.keep_prob, seed0, seed1) | |||
| def forward(self, input): | |||
| if not self.training: | |||
| return input | |||
| if self.keep_prob == 1.0: | |||
| return input | |||
| if self.p == 1.: | |||
| return input.zero_adapter() | |||
| input_ms = cast_to_ms_tensor(input) | |||
| output, _ = self.dropout(input_ms) | |||
| output = ms.ops.dropout(input_ms, p=self.p, training=self.training) | |||
| return _inplace_assign(input, self.inplace, output) | |||
| class Dropout1d(_DropoutNd): | |||
| def __init__(self, p=0.5, inplace=False): | |||
| _inplace_limit_pynative(inplace, "Dropout1d") | |||
| super(Dropout1d, self).__init__(p, inplace) | |||
| def forward(self, input): | |||
| return ms_torch_nn_func.dropout1d(input, self.p, self.training, self.inplace) | |||
| class Dropout2d(_DropoutNd): | |||
| r"""Randomly zero out entire channels (a channel is a 2D feature map, | |||
| e.g., the :math:`j`-th channel of the :math:`i`-th sample in the | |||
| @@ -109,7 +106,7 @@ class Dropout2d(_DropoutNd): | |||
| Examples:: | |||
| >>> m = nn.Dropout2d(p=0.2) | |||
| >>> input = ms_adapter.randn(20, 16, 32, 32) | |||
| >>> input = msadapter.randn(20, 16, 32, 32) | |||
| >>> output = m(input) | |||
| .. _Efficient Object Localization Using Convolutional Networks: | |||
| @@ -118,23 +115,9 @@ class Dropout2d(_DropoutNd): | |||
| def __init__(self, p=0.5, inplace=False): | |||
| _inplace_limit_pynative(inplace, "Dropout2d") | |||
| super(Dropout2d, self).__init__(p, inplace) | |||
| if p < 0 or p > 1: | |||
| raise ValueError("dropout probability has to be between 0 and 1, " | |||
| "but got {}".format(p)) | |||
| self.keep_prob = 1.0 - self.p | |||
| self.dropout2d = P.Dropout2D(self.keep_prob) | |||
| def forward(self, input): | |||
| if not self.training: | |||
| return input | |||
| if self.keep_prob == 1: | |||
| return input | |||
| input_ms = cast_to_ms_tensor(input) | |||
| output, _ = self.dropout2d(input_ms) | |||
| return _inplace_assign(input, self.inplace, output) | |||
| return ms_torch_nn_func.dropout2d(input, self.p, self.training, self.inplace) | |||
| class Dropout3d(_DropoutNd): | |||
| @@ -168,7 +151,7 @@ class Dropout3d(_DropoutNd): | |||
| Examples:: | |||
| >>> m = nn.Dropout3d(p=0.2) | |||
| >>> input = ms_adapter.randn(20, 16, 4, 32, 32) | |||
| >>> input = msadapter.randn(20, 16, 4, 32, 32) | |||
| >>> output = m(input) | |||
| .. _Efficient Object Localization Using Convolutional Networks: | |||
| @@ -178,32 +161,15 @@ class Dropout3d(_DropoutNd): | |||
| def __init__(self, p=0.5, inplace=False): | |||
| _inplace_limit_pynative(inplace, "Dropout3d") | |||
| super(Dropout3d, self).__init__(p, inplace) | |||
| if p < 0 or p > 1: | |||
| raise ValueError("dropout probability has to be between 0 and 1, " | |||
| "but got {}".format(p)) | |||
| self.keep_prob = 1.0 - self.p | |||
| self.dropout3d = P.Dropout3D(self.keep_prob) | |||
| def forward(self, input): | |||
| if not self.training: | |||
| return input | |||
| if self.keep_prob == 1: | |||
| return input | |||
| input_ms = cast_to_ms_tensor(input) | |||
| output, _ = self.dropout3d(input_ms) | |||
| return _inplace_assign(input, self.inplace, output) | |||
| return ms_torch_nn_func.dropout3d(input, self.p, self.training, self.inplace) | |||
| class AlphaDropout(_DropoutNd): | |||
| def __init__(self, p=0.5, inplace=False): | |||
| _inplace_limit_pynative(inplace, "AlphaDropout") | |||
| super(AlphaDropout, self).__init__(p, inplace) | |||
| if p < 0 or p > 1: | |||
| raise ValueError("dropout probability has to be between 0 and 1, " | |||
| "but got {}".format(p)) | |||
| def forward(self, input): | |||
| return ms_torch_nn_func.alpha_dropout(input, self.p, self.training, self.inplace) | |||
| @@ -212,21 +178,6 @@ class FeatureAlphaDropout(_DropoutNd): | |||
| def __init__(self, p=0.5, inplace=False): | |||
| _inplace_limit_pynative(inplace, "FeatureAlphaDropout") | |||
| super(FeatureAlphaDropout, self).__init__(p, inplace) | |||
| if p < 0 or p > 1: | |||
| raise ValueError("dropout probability has to be between 0 and 1, " | |||
| "but got {}".format(p)) | |||
| def forward(self, input): | |||
| return ms_torch_nn_func.feature_alpha_dropout(input, self.p, self.training, self.inplace) | |||
| class Dropout1d(_DropoutNd): | |||
| def __init__(self, p=0.5, inplace=False): | |||
| _inplace_limit_pynative(inplace, "Dropout1d") | |||
| super(Dropout1d, self).__init__(p, inplace) | |||
| if p < 0 or p > 1: | |||
| raise ValueError("dropout probability has to be between 0 and 1, " | |||
| "but got {}".format(p)) | |||
| def forward(self, input): | |||
| return ms_torch_nn_func.dropout1d(input, self.p, self.training, self.inplace) | |||
ms_adapter/pytorch/nn/modules/flatten.py → msadapter/pytorch/nn/modules/flatten.py
View File
| @@ -1,6 +1,6 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import ms_adapter.pytorch.functional as adapter_F | |||
| import msadapter.pytorch.functional as adapter_F | |||
| from .module import Module | |||
| __all__ = ['Flatten', 'Unflatten'] | |||
+ 42
- 0
msadapter/pytorch/nn/modules/fold.py
View File
| @@ -0,0 +1,42 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from msadapter.pytorch.nn.functional import fold, unfold | |||
| from .module import Module | |||
| __all__ = ['Fold', 'Unfold'] | |||
| class Fold(Module): | |||
| #TODO: do not support on Ascend | |||
| def __init__(self, output_size, kernel_size, dilation=1, padding=0, stride=1): | |||
| super(Fold, self).__init__() | |||
| self.output_size = output_size | |||
| self.kernel_size = kernel_size | |||
| self.dilation = dilation | |||
| self.padding = padding | |||
| self.stride = stride | |||
| def forward(self, input): | |||
| return fold(input, self.output_size, self.kernel_size, self.dilation, self.padding, self.stride) | |||
| def extra_repr(self): | |||
| return 'output_size={output_size}, kernel_size={kernel_size}, ' \ | |||
| 'dilation={dilation}, padding={padding}, stride={stride}'.format( | |||
| **self.__dict__ | |||
| ) | |||
| class Unfold(Module): | |||
| def __init__(self, kernel_size, dilation=1, padding=0, stride=1): | |||
| super(Unfold, self).__init__() | |||
| self.kernel_size = kernel_size | |||
| self.dilation = dilation | |||
| self.padding = padding | |||
| self.stride = stride | |||
| def forward(self, input): | |||
| return unfold(input, self.kernel_size, self.dilation, self.padding, self.stride) | |||
| def extra_repr(self): | |||
| return 'kernel_size={kernel_size}, dilation={dilation}, padding={padding},' \ | |||
| ' stride={stride}'.format(**self.__dict__) | |||
+ 81
- 0
msadapter/pytorch/nn/modules/instancenorm.py
View File
| @@ -0,0 +1,81 @@ | |||
| import mindspore as ms | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from msadapter.pytorch.nn.modules.batchnorm import _NormBase | |||
| __all__ = ['InstanceNorm1d', 'InstanceNorm2d', 'InstanceNorm3d'] | |||
| class _InstanceNorm(_NormBase): | |||
| def __init__( | |||
| self, | |||
| num_features, | |||
| eps=1e-5, | |||
| momentum=0.1, | |||
| affine=False, | |||
| track_running_stats=False, | |||
| device=None, | |||
| dtype=None | |||
| ): | |||
| factory_kwargs = {'device': device, 'dtype': dtype} | |||
| super(_InstanceNorm, self).__init__( | |||
| num_features, eps, momentum, affine, track_running_stats, **factory_kwargs) | |||
| self.instance_bn = ms.ops.operations.InstanceNorm(epsilon=self.eps, momentum=self.momentum) | |||
| def _check_input_dim(self, ndim): | |||
| raise NotImplementedError | |||
| def _get_no_batch_dim(self): | |||
| raise NotImplementedError | |||
| def forward(self, input): | |||
| # here should not use 'nn.functional.instance_norm', because it has worse performance. | |||
| input = cast_to_ms_tensor(input) | |||
| ndim = input.ndim | |||
| self._check_input_dim(ndim) | |||
| if ndim == self._get_no_batch_dim(): | |||
| input = input.unsqueeze(0) | |||
| output = self.instance_bn(input, | |||
| self.weight, | |||
| self.bias, | |||
| self.running_mean, | |||
| self.running_var)[0] | |||
| output = output.squeeze(0) | |||
| else: | |||
| output = self.instance_bn(input, | |||
| self.weight, | |||
| self.bias, | |||
| self.running_mean, | |||
| self.running_var)[0] | |||
| output = cast_to_adapter_tensor(output) | |||
| return output | |||
| class InstanceNorm1d(_InstanceNorm): | |||
| def _get_no_batch_dim(self): | |||
| return 2 | |||
| def _check_input_dim(self, ndim): | |||
| if ndim not in (2, 3): | |||
| raise ValueError('expected 2D or 3D input (got {}D input)' | |||
| .format(ndim)) | |||
| class InstanceNorm2d(_InstanceNorm): | |||
| def _get_no_batch_dim(self): | |||
| return 3 | |||
| def _check_input_dim(self, ndim): | |||
| if ndim not in (3, 4): | |||
| raise ValueError('expected 3D or 4D input (got {}D input)' | |||
| .format(ndim)) | |||
| class InstanceNorm3d(_InstanceNorm): | |||
| def _get_no_batch_dim(self): | |||
| return 4 | |||
| def _check_input_dim(self, ndim): | |||
| if ndim not in (4, 5): | |||
| raise ValueError('expected 4D or 5D input (got {}D input)' | |||
| .format(ndim)) | |||
ms_adapter/pytorch/nn/modules/linear.py → msadapter/pytorch/nn/modules/linear.py
View File
| @@ -4,12 +4,12 @@ | |||
| import math | |||
| import mindspore.ops as P | |||
| from ms_adapter.pytorch.nn import init | |||
| from ms_adapter.pytorch.nn.functional import linear | |||
| from ms_adapter.pytorch.functional import empty | |||
| from ms_adapter.pytorch.nn.parameter import Parameter | |||
| from ms_adapter.utils import unsupported_attr | |||
| from ms_adapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from msadapter.pytorch.nn import init | |||
| from msadapter.pytorch.nn.functional import linear | |||
| from msadapter.pytorch.functional import empty | |||
| from msadapter.pytorch.nn.parameter import Parameter | |||
| from msadapter.utils import unsupported_attr | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from .module import Module | |||
| __all__ = ['Linear', 'LazyLinear', 'Identity', 'Bilinear'] | |||
| @@ -42,8 +42,8 @@ class Linear(Module): | |||
| Examples:: | |||
| >>> import ms_adapter.pytorch as torch | |||
| >>> import ms_adapter.pytorch.nn as nn | |||
| >>> import msadapter.pytorch as torch | |||
| >>> import msadapter.pytorch.nn as nn | |||
| >>> m = nn.Linear(20, 30) | |||
| >>> input = torch.randn(128, 20) | |||
| >>> output = m(input) | |||
| @@ -88,14 +88,13 @@ class Linear(Module): | |||
| class Identity(Module): | |||
| def __init__(self): | |||
| def __init__(self, *args, **kwargs): | |||
| super(Identity, self).__init__() | |||
| self.identity = P.Identity() | |||
| unsupported_attr(args) | |||
| unsupported_attr(kwargs) | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| output = self.identity(input) | |||
| return cast_to_adapter_tensor(output) | |||
| return input | |||
| LazyLinear = Linear | |||
ms_adapter/pytorch/nn/modules/loss.py → msadapter/pytorch/nn/modules/loss.py
View File
| @@ -2,9 +2,7 @@ | |||
| # -*- coding: utf-8 -*- | |||
| import warnings | |||
| from ms_adapter.utils import unsupported_attr | |||
| from ms_adapter.pytorch.tensor import Tensor | |||
| import ms_adapter.pytorch.nn.functional as F | |||
| import msadapter.pytorch.nn.functional as F | |||
| from .module import Module | |||
| @@ -13,6 +11,7 @@ __all__ = [ | |||
| 'L1Loss', | |||
| 'MSELoss', | |||
| 'CrossEntropyLoss', | |||
| 'CTCLoss', | |||
| 'NLLLoss', | |||
| 'KLDivLoss', | |||
| 'BCELoss', | |||
| @@ -22,6 +21,13 @@ __all__ = [ | |||
| 'CosineEmbeddingLoss', | |||
| 'MultiMarginLoss', | |||
| 'TripletMarginLoss', | |||
| 'PoissonNLLLoss', | |||
| 'GaussianNLLLoss', | |||
| 'HingeEmbeddingLoss', | |||
| 'MarginRankingLoss', | |||
| 'MultiLabelMarginLoss', | |||
| 'MultiLabelSoftMarginLoss', | |||
| 'TripletMarginWithDistanceLoss', | |||
| ] | |||
| class _Loss(Module): | |||
| @@ -49,13 +55,6 @@ class _Loss(Module): | |||
| warnings.warn(warning.format(ret)) | |||
| return ret | |||
| def cuda(self, *args, **kwargs): | |||
| ## TODO No practical effect | |||
| unsupported_attr(args) | |||
| unsupported_attr(kwargs) | |||
| return self | |||
| class _WeightedLoss(_Loss): | |||
| def __init__(self, weight=None, size_average=None, reduce=None, reduction='mean'): | |||
| super(_WeightedLoss, self).__init__(size_average, reduce, reduction) | |||
| @@ -149,12 +148,12 @@ class BCEWithLogitsLoss(_WeightedLoss): | |||
| followed by a `BCELoss` as, by combining the operations into one layer, | |||
| we take advantage of the log-sum-exp trick for numerical stability. | |||
| """ | |||
| def __init__(self, weight=None, size_average=None, reduce=None, reduction='mean', pos_weight= None): | |||
| def __init__(self, weight=None, size_average=None, reduce=None, reduction='mean', pos_weight=None): | |||
| super(BCEWithLogitsLoss, self).__init__(weight, size_average, reduce, reduction) | |||
| if pos_weight is not None: | |||
| self.register_buffer('pos_weight', pos_weight) | |||
| else: | |||
| self.pos_weight = pos_weight | |||
| self.pos_weight = None | |||
| def forward(self, input, target): | |||
| return F.binary_cross_entropy_with_logits(input, target, self.weight, | |||
| @@ -182,26 +181,26 @@ class CosineEmbeddingLoss(_Loss): | |||
| super(CosineEmbeddingLoss, self).__init__(size_average, reduce, reduction) | |||
| self.margin = margin | |||
| def forward(self, input1: Tensor, input2: Tensor, target: Tensor) -> Tensor: | |||
| def forward(self, input1, input2, target): | |||
| return F.cosine_embedding_loss(input1, input2, target, margin=self.margin, reduction=self.reduction) | |||
| class MultiMarginLoss(_WeightedLoss): | |||
| # TODO: Until Now, mindspore do not support `margin` is 'float' type | |||
| def __init__(self, p=1, margin=1, weight=None, size_average=None, | |||
| reduce=None, reduction: str='mean'): | |||
| super(MultiMarginLoss, self).__init__(weight, size_average, reduce, reduction) | |||
| if p not in (1, 2): | |||
| raise ValueError("only p == 1 and p == 2 supported") | |||
| assert weight is None or weight.dim() == 1 | |||
| if weight is not None and weight.dim() != 1: | |||
| raise ValueError(f"For MultiMarginLoss, `weight` must be 1-D, but got {weight.dim()}-D.") | |||
| self.p = p | |||
| self.margin = margin | |||
| def forward(self, input: Tensor, target: Tensor) -> Tensor: | |||
| def forward(self, input, target): | |||
| return F.multi_margin_loss(input, target, p=self.p, margin=self.margin, | |||
| weight=self.weight, reduction=self.reduction) | |||
| class TripletMarginLoss(_Loss): | |||
| def __init__(self, margin=1.0, p=2., eps=1e-6, swap=False, size_average=None, | |||
| reduce=None, reduction: str='mean'): | |||
| @@ -214,3 +213,77 @@ class TripletMarginLoss(_Loss): | |||
| def forward(self, anchor, positive, negative): | |||
| return F.triplet_margin_loss(anchor, positive, negative, margin=self.margin, p=self.p, | |||
| eps=self.eps, swap=self.swap, reduction=self.reduction) | |||
| class PoissonNLLLoss(_Loss): | |||
| def __init__(self, log_input=True, full=False, size_average=None, eps=1e-8, reduce=None, reduction='mean'): | |||
| super(PoissonNLLLoss, self).__init__(size_average, reduce, reduction) | |||
| self.log_input = log_input | |||
| self.full = full | |||
| self.eps = eps | |||
| def forward(self, log_input, target): | |||
| return F.poisson_nll_loss(log_input, target, log_input=self.log_input, full=self.full, | |||
| eps=self.eps, reduction=self.reduction) | |||
| class GaussianNLLLoss(_Loss): | |||
| def __init__(self, *, full=False, eps=1e-6, reduction='mean'): | |||
| super(GaussianNLLLoss, self).__init__(None, None, reduction) | |||
| self.full = full | |||
| self.eps = eps | |||
| def forward(self, input, target, var): | |||
| return F.gaussian_nll_loss(input, target, var, full=self.full, eps=self.eps, reduction=self.reduction) | |||
| class MarginRankingLoss(_Loss): | |||
| def __init__(self, margin=0., size_average=None, reduce=None, reduction='mean'): | |||
| super(MarginRankingLoss, self).__init__(size_average, reduce, reduction) | |||
| self.margin = margin | |||
| def forward(self, input1, input2, target): | |||
| return F.margin_ranking_loss(input1, input2, target, self.margin, reduction=self.reduction) | |||
| class HingeEmbeddingLoss(_Loss): | |||
| def __init__(self, margin=1.0, size_average=None, reduce=None, reduction='mean'): | |||
| super(HingeEmbeddingLoss, self).__init__(size_average, reduce, reduction) | |||
| self.margin = margin | |||
| def forward(self, input, target): | |||
| return F.hinge_embedding_loss(input, target, self.margin, reduction=self.reduction) | |||
| class MultiLabelMarginLoss(_Loss): | |||
| def forward(self, input, target): | |||
| return F.multilabel_margin_loss(input, target, reduction=self.reduction) | |||
| class MultiLabelSoftMarginLoss(_WeightedLoss): | |||
| def forward(self, input, target): | |||
| return F.multilabel_soft_margin_loss(input, target, self.weight, reduction=self.reduction) | |||
| class TripletMarginWithDistanceLoss(_Loss): | |||
| def __init__(self, *, distance_function=None, | |||
| margin: float = 1.0, swap: bool = False, reduction: str = 'mean'): | |||
| super(TripletMarginWithDistanceLoss, self).__init__(size_average=None, reduce=None, reduction=reduction) | |||
| self.distance_function = distance_function | |||
| self.margin = margin | |||
| self.swap = swap | |||
| def forward(self, anchor, positive, negative): | |||
| return F.triplet_margin_with_distance_loss(anchor, positive, negative, | |||
| distance_function=self.distance_function, | |||
| margin=self.margin, swap=self.swap, reduction=self.reduction) | |||
| class CTCLoss(_Loss): | |||
| def __init__(self, blank=0, reduction='mean', zero_infinity=False): | |||
| super(CTCLoss, self).__init__(reduction=reduction) | |||
| self.blank = blank | |||
| self.zero_infinity = zero_infinity | |||
| def forward(self, log_probs, targets, input_lengths, target_lengths): | |||
| return F.ctc_loss(log_probs, targets, input_lengths, target_lengths, self.blank, self.reduction, | |||
| self.zero_infinity) | |||
+ 644
- 0
msadapter/pytorch/nn/modules/module.py
View File
| @@ -0,0 +1,644 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from collections import OrderedDict, namedtuple | |||
| from typing import Mapping | |||
| import mindspore as ms | |||
| from mindspore.nn import Cell | |||
| from mindspore import Tensor as ms_Tensor | |||
| from mindspore.train.serialization import load_param_into_net | |||
| from msadapter.pytorch.tensor import Tensor | |||
| from msadapter.pytorch.nn.parameter import Parameter | |||
| from msadapter.utils import unsupported_attr | |||
| from msadapter.pytorch.common.device import Device | |||
| from msadapter.pytorch.functional import empty_like | |||
| __all__ = ['Module'] | |||
| _global_parameter_registration_hooks = OrderedDict() | |||
| _global_module_registration_hooks = OrderedDict() | |||
| _global_buffer_registration_hooks = OrderedDict() | |||
| _EXTRA_STATE_KEY_SUFFIX = '_extra_state' | |||
| class _IncompatibleKeys(namedtuple('IncompatibleKeys', ['missing_keys', 'unexpected_keys'])): | |||
| def __repr__(self): | |||
| if not self.missing_keys and not self.unexpected_keys: | |||
| return '<All keys matched successfully>' | |||
| return super().__repr__() | |||
| __str__ = __repr__ | |||
| class Module(Cell): | |||
| def __init__(self, auto_prefix=True, flags=None): | |||
| super(Module, self).__init__(auto_prefix, flags) | |||
| # Some class members in same usage are defined in mindspore.nn.Cell, so Module reuses them | |||
| # If re-difine these members with different names, Module should deal with data synchronization issue, | |||
| # which is easy to make mistakes and unnecessary. Belows are the two different of members name | |||
| # refers to torch.nn.Module | |||
| # _parameters -> _params | |||
| # _modules -> _cells | |||
| # use object.__setattr__ to accelerate, because self.__setattr__ has too much procedure | |||
| object.__setattr__(self, 'training', True) | |||
| object.__setattr__(self, '_buffers', OrderedDict()) | |||
| object.__setattr__(self, '_non_persistent_buffers_set', set()) | |||
| object.__setattr__(self, '_state_dict_hooks', OrderedDict()) | |||
| object.__setattr__(self, '_state_dict_pre_hooks', OrderedDict()) | |||
| object.__setattr__(self, '_version', 1) | |||
| def __del__(self): | |||
| pass | |||
| def __repr__(self): | |||
| extra_str = self.extra_repr() | |||
| info_str = self.__class__.__name__ + '(' | |||
| if self._cells: | |||
| sub_str = '\n' | |||
| if extra_str: | |||
| sub_str += '{}\n'.format(self.extra_repr()) | |||
| for key, value in self._cells.items(): | |||
| sub_str += ' ({}): {}\n'.format(key, repr(value)) | |||
| sub_str = sub_str.replace('\n', '\n') + ')' | |||
| info_str += sub_str | |||
| else: | |||
| info_str += extra_str + ')' | |||
| return info_str | |||
| def __delattr__(self, name): | |||
| if name in self._buffers: | |||
| del self._buffers[name] | |||
| else: | |||
| super().__delattr__(name) | |||
| def __getattr__(self, name): | |||
| if '_buffers' in self.__dict__: | |||
| buffers = self.__dict__['_buffers'] | |||
| if name in buffers: | |||
| return buffers[name] | |||
| return super().__getattr__(name) | |||
| def __setattr__(self, name, value): | |||
| def remove_from(*dicts_or_sets): | |||
| for d in dicts_or_sets: | |||
| if name in d: | |||
| if isinstance(d, dict): | |||
| del d[name] | |||
| else: | |||
| d.discard(name) | |||
| buffers = self.__dict__.get('_buffers') | |||
| if buffers is not None and name in buffers: | |||
| _is_buffer = True | |||
| if value is not None: | |||
| if isinstance(value, (Parameter, Module)): | |||
| _is_buffer = False | |||
| remove_from(self._buffers, self._non_persistent_buffers_set) | |||
| elif not isinstance(value, Tensor): | |||
| raise TypeError("cannot assign '{}' as buffer '{}' " | |||
| "(torch.Tensor or None expected)" | |||
| .format(type(value), name)) | |||
| if _is_buffer: | |||
| for hook in _global_buffer_registration_hooks.values(): | |||
| output = hook(self, name, value) | |||
| if output is not None: | |||
| value = output | |||
| buffers[name] = value | |||
| else: | |||
| super().__setattr__(name, value) | |||
| else: | |||
| super().__setattr__(name, value) | |||
| def _save_to_state_dict(self, destination, prefix, keep_vars): | |||
| for hook in self._state_dict_pre_hooks.values(): | |||
| hook(self, prefix, keep_vars) | |||
| for name, param in self.parameters_and_names(expand=False): | |||
| if param is not None: | |||
| destination[prefix + name] = param if keep_vars else param.detach() | |||
| for name, buf in self._buffers.items(): | |||
| if buf is not None and name not in self._non_persistent_buffers_set: | |||
| destination[prefix + name] = buf if keep_vars else buf.detach() | |||
| extra_state_key = prefix + _EXTRA_STATE_KEY_SUFFIX | |||
| if getattr(self.__class__, "get_extra_state", Module.get_extra_state) is not Module.get_extra_state: | |||
| destination[extra_state_key] = self.get_extra_state() | |||
| def state_dict(self, *args, destination=None, prefix='', keep_vars=False): | |||
| # TODO: Remove `args` and the parsing logic when BC allows. | |||
| if len(args) > 0: | |||
| if destination is None: | |||
| destination = args[0] | |||
| if len(args) > 1 and prefix == '': | |||
| prefix = args[1] | |||
| if len(args) > 2 and keep_vars is False: | |||
| keep_vars = args[2] | |||
| if destination is None: | |||
| destination = OrderedDict() | |||
| destination._metadata = OrderedDict() | |||
| local_metadata = dict(version=self._version) | |||
| if hasattr(destination, "_metadata"): | |||
| destination._metadata[prefix[:-1]] = local_metadata | |||
| self._save_to_state_dict(destination, prefix, keep_vars) | |||
| # name_cells() will filter the same cells. | |||
| # for name, module in self.name_cells().items(): | |||
| for name, module in self._cells.items(): | |||
| # Add 'isinstance(module, Module)' conditions to go into mindspore.nn.Cell. | |||
| # In some case we will use api from mindspore.nn to do the computations | |||
| if module is not None and isinstance(module, Module): | |||
| module.state_dict(destination=destination, prefix=prefix + name + '.', keep_vars=keep_vars) | |||
| for hook in self._state_dict_hooks.values(): | |||
| hook_result = hook(self, destination, prefix, local_metadata) | |||
| if hook_result is not None: | |||
| destination = hook_result | |||
| return destination | |||
| def _convert_state_dict(self, state_dict): | |||
| ms_state_dict = {} | |||
| for name, param in state_dict.items(): | |||
| if isinstance(param, ms.Tensor): | |||
| param = Parameter(param, name=name) | |||
| ms_state_dict[name] = param | |||
| return ms_state_dict | |||
| def _load_buffer_into_net(self, state_dict, strict): | |||
| missing_key = [] | |||
| has_load = [] | |||
| def load(module, local_state_dict, prefix=''): | |||
| persistent_buffers = {k: v for k, v in module._buffers.items() | |||
| if k not in module._non_persistent_buffers_set and | |||
| v is not None} | |||
| for name, buf in persistent_buffers.items(): | |||
| key = prefix + name | |||
| if key in local_state_dict: | |||
| input_buf = local_state_dict[key] | |||
| buf = buf.copy_adapter(input_buf) | |||
| has_load.append(key) | |||
| elif strict: | |||
| missing_key.append(name) | |||
| extra_state_key = prefix + _EXTRA_STATE_KEY_SUFFIX | |||
| if getattr(module.__class__, "set_extra_state", Module.set_extra_state) is not Module.set_extra_state: | |||
| if extra_state_key in state_dict: | |||
| module.set_extra_state(state_dict[extra_state_key]) | |||
| has_load.append(extra_state_key) | |||
| elif strict: | |||
| missing_key.append(extra_state_key) | |||
| for name, child in module._cells.items(): | |||
| if child is not None and isinstance(child, Module): | |||
| child_prefix = prefix + name + '.' | |||
| child_state_dict = {k: v for k, v in local_state_dict.items() if k.startswith(child_prefix)} | |||
| load(child, child_state_dict, child_prefix) | |||
| load(self, state_dict) | |||
| del load | |||
| return missing_key, has_load | |||
| def load_state_dict(self, state_dict, strict=True): | |||
| if not isinstance(state_dict, Mapping): | |||
| raise TypeError("Expected state_dict to be dict-like, got {}.".format(type(state_dict))) | |||
| error_msgs = [] | |||
| buffers_not_load, buffers_has_load = self._load_buffer_into_net(state_dict, strict) | |||
| ms_state_dict = self._convert_state_dict(state_dict) | |||
| param_not_load, ckpt_not_load = load_param_into_net(self, ms_state_dict, strict_load=False) | |||
| ckpt_not_load = [elem for elem in ckpt_not_load if elem not in buffers_has_load] | |||
| missing_keys = param_not_load + buffers_not_load | |||
| unexpected_keys = ckpt_not_load | |||
| if strict: | |||
| if len(unexpected_keys) > 0: | |||
| error_msgs.insert( | |||
| 0, 'Unexpected key(s) in state_dict: {}. '.format( | |||
| ', '.join('"{}"'.format(k) for k in unexpected_keys))) | |||
| if len(missing_keys) > 0: | |||
| error_msgs.insert( | |||
| 0, 'Missing key(s) in state_dict: {}. '.format( | |||
| ', '.join('"{}"'.format(k) for k in missing_keys))) | |||
| if len(error_msgs) > 0: | |||
| raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format( | |||
| self.__class__.__name__, "\n\t".join(error_msgs))) | |||
| return _IncompatibleKeys(missing_keys, unexpected_keys) | |||
| def extra_repr(self): | |||
| r"""Set the extra representation of the module""" | |||
| return '' | |||
| def construct(self, *inputs, **kwargs): | |||
| return self.forward(*inputs, **kwargs) | |||
| def _run_construct(self, cast_inputs, kwargs): | |||
| """Run the construct function""" | |||
| if self._enable_forward_pre_hook: | |||
| cast_inputs = self._run_forward_pre_hook(cast_inputs) | |||
| if self._enable_backward_hook: | |||
| output = self._backward_hook_construct(*cast_inputs) | |||
| elif hasattr(self, "_shard_fn"): | |||
| output = self._shard_fn(*cast_inputs, **kwargs) | |||
| else: | |||
| output = self.construct(*cast_inputs, **kwargs) | |||
| if self._enable_forward_hook: | |||
| output = self._run_forward_hook(cast_inputs, output) | |||
| return output | |||
| def forward(self, *inputs, **kwargs): | |||
| raise NotImplementedError("The forward method must be implemented by inherited class") | |||
| def train(self, mode=True): | |||
| self.set_train(mode) | |||
| return self | |||
| def eval(self): | |||
| self.set_train(False) | |||
| return self | |||
| def requires_grad_(self, requires_grad=True): | |||
| for p in self.parameters(): | |||
| p.requires_grad_(requires_grad) | |||
| return self | |||
| def modules(self): | |||
| for _, module in self.named_modules(): | |||
| yield module | |||
| def named_modules(self, memo=None, prefix='', remove_duplicate=True): | |||
| if memo is None: | |||
| memo = set() | |||
| if self not in memo: | |||
| if remove_duplicate: | |||
| memo.add(self) | |||
| yield prefix, self | |||
| for name, module in self._cells.items(): | |||
| if module is None or not isinstance(module, Module): | |||
| continue | |||
| submodule_prefix = prefix + ('.' if prefix else '') + name | |||
| for m in module.named_modules(memo, submodule_prefix, remove_duplicate): | |||
| yield m | |||
| def _parameters_and_names(self, name_prefix='', expand=True): | |||
| cells = [] | |||
| if expand: | |||
| cells = self.cells_and_names(name_prefix=name_prefix) | |||
| else: | |||
| cells.append((name_prefix, self)) | |||
| params_set = set() | |||
| for cell_name, cell in cells: | |||
| params = cell._params.items() | |||
| for par_name, par in params: | |||
| if par.inited_param is not None: | |||
| par = par.inited_param | |||
| if par is not None and id(par) not in params_set: | |||
| params_set.add(id(par)) | |||
| par_new_name = par_name | |||
| if cell_name: | |||
| par_new_name = cell_name + '.' + par_new_name | |||
| # TODO Update parameter names to avoid duplicates | |||
| par.name = par_new_name | |||
| yield par_new_name, par | |||
| def add_module(self, name, module): | |||
| for hook in _global_module_registration_hooks.values(): | |||
| output = hook(self, name, module) | |||
| if output is not None: | |||
| module = output | |||
| self.insert_child_to_cell(name, module) | |||
| def _get_name(self): | |||
| return self.__class__.__name__ | |||
| def get_submodule(self, target): | |||
| if target == "": | |||
| return self | |||
| atoms = target.split(".") | |||
| mod = self | |||
| for item in atoms: | |||
| if not hasattr(mod, item): | |||
| raise AttributeError(mod._get_name() + " has no " | |||
| "attribute `" + item + "`") | |||
| mod = getattr(mod, item) | |||
| if not isinstance(mod, Module): | |||
| raise AttributeError("`" + item + "` is not " | |||
| "an nn.Module") | |||
| return mod | |||
| def get_parameter(self, target): | |||
| module_path, _, param_name = target.rpartition(".") | |||
| mod = self.get_submodule(module_path) | |||
| if not hasattr(mod, param_name): | |||
| raise AttributeError(mod._get_name() + " has no attribute `" | |||
| + param_name + "`") | |||
| param = getattr(mod, param_name) | |||
| if not isinstance(param, Parameter): | |||
| raise AttributeError("`" + param_name + "` is not an " | |||
| "nn.Parameter") | |||
| return param | |||
| def get_buffer(self, target): | |||
| module_path, _, buffer_name = target.rpartition(".") | |||
| mod = self.get_submodule(module_path) | |||
| if not hasattr(mod, buffer_name): | |||
| raise AttributeError(mod._get_name() + " has no attribute `" | |||
| + buffer_name + "`") | |||
| buffer = getattr(mod, buffer_name) | |||
| if buffer_name not in mod._buffers: | |||
| raise AttributeError("`" + buffer_name + "` is not a buffer") | |||
| return buffer | |||
| def get_extra_state(self): | |||
| raise RuntimeError( | |||
| "Reached a code path in Module.get_extra_state() that should never be called.") | |||
| def set_extra_state(self, state): | |||
| raise RuntimeError( | |||
| "Reached a code path in Module.set_extra_state() that should never be called.") | |||
| def _apply(self, fn): | |||
| for module in self.children(): | |||
| module._apply(fn) | |||
| def compute_should_use_set_data(tensor, tensor_applied): | |||
| if tensor.dtype != tensor_applied.dtype: | |||
| return False | |||
| return True | |||
| for key, param in self.parameters_and_names(expand=False): | |||
| if param is None: | |||
| continue | |||
| # Do not use _apply in computation, just for init usage, because can not avoid gradient now. | |||
| param_applied = fn(param) | |||
| should_use_set_data = compute_should_use_set_data(param, param_applied) | |||
| if should_use_set_data: | |||
| param.set_data(param_applied) | |||
| out_param = param | |||
| else: | |||
| out_param = Parameter(param_applied, param.requires_grad) | |||
| self.insert_param_to_cell(key, out_param) | |||
| for key, buf in self._buffers.items(): | |||
| if buf is not None: | |||
| self._buffers[key] = fn(buf) | |||
| return self | |||
| def float(self): | |||
| return self._apply(lambda t: t.float() if t.is_floating_point() else t) | |||
| def double(self): | |||
| return self._apply(lambda t: t.double() if t.is_floating_point() else t) | |||
| def half(self): | |||
| return self._apply(lambda t: t.half() if t.is_floating_point() else t) | |||
| def to_empty(self, *, device=None): | |||
| return self._apply(lambda t: empty_like(t, device=device)) | |||
| def register_module(self, name, module): | |||
| """Alias for :func:`add_module`.""" | |||
| self.add_module(name, module) | |||
| def parameters_and_names(self, name_prefix='', expand=True): | |||
| return self._parameters_and_names(name_prefix=name_prefix, expand=expand) | |||
| def named_parameters(self, prefix='', recurse=True, remove_duplicate=True): | |||
| gen = self._named_members( | |||
| lambda module: module._params.items(), | |||
| prefix=prefix, recurse=recurse, remove_duplicate=remove_duplicate) | |||
| yield from gen | |||
| def named_children(self): | |||
| r"""Returns an iterator over immediate children modules, yielding both | |||
| the name of the module as well as the module itself. | |||
| Yields: | |||
| (string, Module): Tuple containing a name and child module | |||
| Example:: | |||
| >>> for name, module in model.named_children(): | |||
| >>> if name in ['conv4', 'conv5']: | |||
| >>> print(module) | |||
| """ | |||
| memo = set() | |||
| for name, module in self._cells.items(): | |||
| if module is not None and module not in memo: | |||
| memo.add(module) | |||
| yield name, module | |||
| def children(self): | |||
| r"""Returns an iterator over immediate children modules. | |||
| Yields: | |||
| Module: a child module | |||
| """ | |||
| for _, module in self.named_children(): | |||
| yield module | |||
| def apply(self, fn=None): | |||
| r"""Applies ``fn`` recursively to every submodule (as returned by ``.children()``) | |||
| as well as self. Typical use includes initializing the parameters of a model | |||
| (see also :ref:`nn-init-doc`). | |||
| Args: | |||
| fn (:class:`Module` -> None): function to be applied to each submodule | |||
| Returns: | |||
| Module: self | |||
| Example:: | |||
| >>> def init_weights(m): | |||
| >>> print(m) | |||
| >>> if type(m) == nn.Linear: | |||
| >>> m.weight.fill_(1.0) | |||
| >>> print(m.weight) | |||
| >>> net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2)) | |||
| >>> net.apply(init_weights) | |||
| """ | |||
| for module in self.children(): | |||
| module.apply(fn) | |||
| fn(self) | |||
| return self | |||
| def parameters(self, recurse = True): | |||
| for _, param in self.named_parameters(recurse=recurse): | |||
| yield param | |||
| def register_buffer(self, name, tensor, persistent=True): | |||
| r"""Adds a buffer to the module. | |||
| This is typically used to register a buffer that should not to be | |||
| considered a model parameter. For example, BatchNorm's ``running_mean`` | |||
| is not a parameter, but is part of the module's state. Buffers, by | |||
| default, are persistent and will be saved alongside parameters. This | |||
| behavior can be changed by setting :attr:`persistent` to ``False``. The | |||
| only difference between a persistent buffer and a non-persistent buffer | |||
| is that the latter will not be a part of this module's | |||
| :attr:`state_dict`. | |||
| Buffers can be accessed as attributes using given names. | |||
| Args: | |||
| name (string): name of the buffer. The buffer can be accessed | |||
| from this module using the given name | |||
| tensor (Tensor or None): buffer to be registered. If ``None``, then operations | |||
| that run on buffers, such as :attr:`cuda`, are ignored. If ``None``, | |||
| the buffer is **not** included in the module's :attr:`state_dict`. | |||
| persistent (bool): whether the buffer is part of this module's | |||
| :attr:`state_dict`. | |||
| """ | |||
| unsupported_attr(persistent) | |||
| if '_buffers' not in self.__dict__: | |||
| raise AttributeError("cannot assign buffer before Module.__init__() call.") | |||
| elif not isinstance(name, str): | |||
| raise TypeError("buffer name should be a string. " | |||
| "Got {}".format(type(name))) | |||
| elif '.' in name: | |||
| raise KeyError("buffer name can't contain \".\"") | |||
| elif name == '': | |||
| raise KeyError("buffer name can't be empty string \"\"") | |||
| elif hasattr(self, name) and name not in self._buffers: | |||
| raise KeyError("attribute '{}' already exists".format(name)) | |||
| elif tensor is not None and not isinstance(tensor, ms_Tensor): | |||
| raise TypeError("cannot assign '{}' object to buffer '{}' " | |||
| "(Tensor or None required)" | |||
| .format(type(tensor), name)) | |||
| else: | |||
| self._buffers[name] = tensor | |||
| if persistent: | |||
| self._non_persistent_buffers_set.discard(name) | |||
| else: | |||
| self._non_persistent_buffers_set.add(name) | |||
| def _named_members(self, get_members_fn, prefix='', recurse=True, remove_duplicate=True): | |||
| r"""Helper method for yielding various names + members of modules.""" | |||
| memo = set() | |||
| modules = self.named_modules(prefix=prefix, remove_duplicate=remove_duplicate) if recurse else [(prefix, self)] | |||
| for module_prefix, module in modules: | |||
| members = get_members_fn(module) | |||
| for k, v in members: | |||
| if v is None or v in memo: | |||
| continue | |||
| if remove_duplicate: | |||
| memo.add(v) | |||
| name = module_prefix + ('.' if module_prefix else '') + k | |||
| yield name, v | |||
| def named_buffers(self, prefix='', recurse=True, remove_duplicate=True): | |||
| gen = self._named_members( | |||
| lambda module: module._buffers.items(), | |||
| prefix=prefix, recurse=recurse, remove_duplicate=remove_duplicate) | |||
| yield from gen | |||
| def buffers(self, recurse=True): | |||
| for _, buf in self.named_buffers(recurse=recurse): | |||
| yield buf | |||
| def to(self, *args, **kwargs): | |||
| # TODO: | |||
| # Note that this API requires the user to ensure the correctness of the input currently, | |||
| # and only the function of modifying device is available. | |||
| args_len = len(args) | |||
| kwargs_len = len(kwargs) | |||
| if args_len == 0 and kwargs_len == 0: | |||
| raise ValueError("Module.to is missing inputs, please check.") | |||
| elif (args_len + kwargs_len > 1) or (kwargs_len > 0 and "device" not in kwargs): | |||
| raise ValueError("Currently only the function of modifying device is available.") | |||
| elif (args_len > 0 and not isinstance(args[0], (str, Device))) or \ | |||
| (kwargs_len > 0 and not isinstance(kwargs.get("device"), (str, Device))): | |||
| raise ValueError("Currently only the function of modifying device is available, " | |||
| "which via a string or torch.device.") | |||
| return self | |||
| def register_parameter(self, name, param): | |||
| """Adds a parameter to the module. | |||
| The parameter can be accessed as an attribute using given name. | |||
| Args: | |||
| name (string): name of the parameter. The parameter can be accessed | |||
| from this module using the given name | |||
| param (Parameter or None): parameter to be added to the module. If | |||
| ``None``, then operations that run on parameters, such as :attr:`cuda`, | |||
| are ignored. If ``None``, the parameter is **not** included in the | |||
| module's :attr:`state_dict`. | |||
| """ | |||
| # Until now, input check use the check below before mindspore check in 'insert_param_to_cell' | |||
| # because the check order in mindspore has some problem. | |||
| if '_params' not in self.__dict__: | |||
| raise AttributeError("cannot assign parameter before Module.__init__() call") | |||
| elif not isinstance(name, str): | |||
| raise TypeError("parameter name should be a string. Got {}".format(type(name))) | |||
| elif '.' in name: | |||
| raise KeyError("parameter name can't contain \".\"") | |||
| elif name == '': | |||
| raise KeyError("parameter name can't be empty string \"\"") | |||
| elif hasattr(self, name) and name not in self._params: | |||
| raise KeyError("attribute '{}' already exists".format(name)) | |||
| for hook in _global_parameter_registration_hooks.values(): | |||
| output = hook(self, name, param) | |||
| if output is not None: | |||
| param = output | |||
| # self.insert_param_to_cell() has more procedure than self._params[name] = param. | |||
| # so call self.insert_param_to_cell() rather than self._params[name] | |||
| self.insert_param_to_cell(name, param) | |||
| def type(self, dst_type): | |||
| return self._apply(lambda t: t.type(dst_type)) | |||
| def cuda(self, device=None): | |||
| unsupported_attr(device) | |||
| return self | |||
| def cpu(self, device=None): | |||
| unsupported_attr(device) | |||
| return self | |||
| def share_memory(self): | |||
| # share_memory mindspore do not support, do nothings | |||
| return self | |||
| def __dir__(self): | |||
| module_attrs = dir(self.__class__) | |||
| attrs = list(self.__dict__.keys()) | |||
| parameters = list(self._params.keys()) | |||
| modules = list(self._cells.keys()) | |||
| buffers = list(self._buffers.keys()) | |||
| keys = module_attrs + attrs + parameters + modules + buffers | |||
| # Eliminate attrs that are not legal Python variable names | |||
| keys = [key for key in keys if not key[0].isdigit()] | |||
| return sorted(keys) | |||
ms_adapter/pytorch/nn/modules/normalization.py → msadapter/pytorch/nn/modules/normalization.py
View File
| @@ -6,12 +6,12 @@ import mindspore.ops.functional as F | |||
| import mindspore.ops.operations as P | |||
| from mindspore.ops._primitive_cache import _get_cache_prim | |||
| from ms_adapter.pytorch.tensor import cast_to_adapter_tensor, cast_to_ms_tensor | |||
| from ms_adapter.pytorch.nn.parameter import Parameter | |||
| from ms_adapter.utils import unsupported_attr | |||
| from ms_adapter.pytorch.nn import init | |||
| import ms_adapter.pytorch.functional as torch_func | |||
| import ms_adapter.pytorch.nn.functional as torch_nn_func | |||
| from msadapter.pytorch.tensor import cast_to_adapter_tensor, cast_to_ms_tensor | |||
| from msadapter.pytorch.nn.parameter import Parameter | |||
| from msadapter.utils import unsupported_attr | |||
| from msadapter.pytorch.nn import init | |||
| import msadapter.pytorch.functional as torch_func | |||
| import msadapter.pytorch.nn.functional as torch_nn_func | |||
| from .module import Module | |||
| @@ -53,8 +53,8 @@ class LayerNorm(Module): | |||
| input = cast_to_ms_tensor(input) | |||
| begin_axis = ms.ops.rank(input) - self.normalized_shape_rank | |||
| layer_norm_ops = _get_cache_prim(ms.ops.LayerNorm)(begin_norm_axis=begin_axis, | |||
| begin_params_axis=begin_axis, | |||
| epsilon=self.eps) | |||
| begin_params_axis=begin_axis, | |||
| epsilon=self.eps) | |||
| output_x, _, _ = layer_norm_ops(input, self.weight, self.bias) | |||
| return cast_to_adapter_tensor(output_x) | |||
ms_adapter/pytorch/nn/modules/padding.py → msadapter/pytorch/nn/modules/padding.py
View File
| @@ -1,13 +1,29 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from itertools import repeat | |||
| from mindspore import nn | |||
| from ms_adapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from .module import Module | |||
| __all__ = ['ConstantPad1d', 'ConstantPad2d', 'ConstantPad3d', 'ReflectionPad1d', 'ReflectionPad2d', | |||
| __all__ = ['ConstantPad1d', 'ConstantPad2d', 'ConstantPad3d', 'ReflectionPad1d', 'ReflectionPad2d', 'ReflectionPad3d', | |||
| 'ZeroPad2d', 'ReplicationPad1d', 'ReplicationPad2d', 'ReplicationPad3d'] | |||
| def _check_padding(padding, n, op_name): | |||
| if isinstance(padding, int): | |||
| padding = tuple(repeat(padding, n)) | |||
| elif isinstance(padding, tuple): | |||
| if len(padding) % 2 != 0: | |||
| raise ValueError(f"For '{op_name}', the length of 'padding' with tuple type must be a multiple of 2, " | |||
| f"but got {len(padding)}") | |||
| if not all(isinstance(i, int) for i in padding): | |||
| raise TypeError(f"For '{op_name}' every element in 'padding' must be integer, but got {padding}. ") | |||
| else: | |||
| raise TypeError(f"For '{op_name}', the type of parameter 'padding' must be in [int, tuple], " | |||
| f"but got {type(padding)}") | |||
| return padding | |||
| class _ConstantPadNd(Module): | |||
| def __init__(self, padding, value): | |||
| super(_ConstantPadNd, self).__init__() | |||
| @@ -17,6 +33,7 @@ class _ConstantPadNd(Module): | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| #Todo: replace with 'F.pad(input, self.padding, 'constant', self.value)' | |||
| output = self.pad_fun(input) | |||
| return cast_to_adapter_tensor(output) | |||
| @@ -42,14 +59,14 @@ class ConstantPad1d(_ConstantPadNd): | |||
| Examples:: | |||
| >>> m = nn.ConstantPad1d(2, 3.5) | |||
| >>> input = ms_adapter.pytorch.ones(1, 2, 4) | |||
| >>> input = msadapter.pytorch.ones(1, 2, 4) | |||
| >>> m(input) | |||
| """ | |||
| def __init__(self, padding, value: float): | |||
| def __init__(self, padding, value): | |||
| super(ConstantPad1d, self).__init__(padding, value) | |||
| self.pad_fun = nn.ConstantPad1d(self.padding, self.value) | |||
| self.padding = _check_padding(padding, 2, "ConstantPad1d") | |||
| self.pad_fun = nn.ConstantPad1d(self.padding, self.value) # todo: to be deleted | |||
| class ConstantPad2d(_ConstantPadNd): | |||
| r"""Pads the input tensor boundaries with a constant value. | |||
| @@ -72,14 +89,14 @@ class ConstantPad2d(_ConstantPadNd): | |||
| Examples:: | |||
| >>> m = nn.ConstantPad2d(2, 3.5) | |||
| >>> input = ms_adapter.pytorch.ones(1, 2, 2) | |||
| >>> input = msadapter.pytorch.ones(1, 2, 2) | |||
| >>> m(input) | |||
| """ | |||
| def __init__(self, padding, value): | |||
| super(ConstantPad2d, self).__init__(padding, value) | |||
| self.pad_fun = nn.ConstantPad2d(self.padding, self.value) | |||
| self.padding = _check_padding(padding, 4, "ConstantPad2d") | |||
| self.pad_fun = nn.ConstantPad2d(self.padding, self.value) # todo: to be deleted | |||
| class ConstantPad3d(_ConstantPadNd): | |||
| r"""Pads the input tensor boundaries with a constant value. | |||
| @@ -107,14 +124,14 @@ class ConstantPad3d(_ConstantPadNd): | |||
| Examples:: | |||
| >>> m = nn.ConstantPad3d(3, 3.5) | |||
| >>> input = ms_adapter.pytorch.ones(16, 3, 10, 20, 30) | |||
| >>> input = msadapter.pytorch.ones(16, 3, 10, 20, 30) | |||
| >>> output = m(input) | |||
| """ | |||
| def __init__(self, padding, value): | |||
| super(ConstantPad3d, self).__init__(padding, value) | |||
| self.pad_fun = nn.ConstantPad3d(self.padding, self.value) | |||
| self.padding = _check_padding(padding, 6, "ConstantPad3d") | |||
| self.pad_fun = nn.ConstantPad3d(self.padding, self.value) # todo: to be deleted | |||
| class _ReflectionPadNd(Module): | |||
| def __init__(self, padding): | |||
| @@ -124,6 +141,7 @@ class _ReflectionPadNd(Module): | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| #todo: replace with 'F.pad(input, self.padding, 'reflect')' | |||
| output = self.pad_fun(input) | |||
| return cast_to_adapter_tensor(output) | |||
| @@ -150,14 +168,15 @@ class ReflectionPad1d(_ReflectionPadNd): | |||
| Examples:: | |||
| >>> m = nn.ReflectionPad1d(2) | |||
| >>> input = ms_adapter.pytorch.ones(1, 2, 4) | |||
| >>> input = msadapter.pytorch.ones(1, 2, 4) | |||
| >>> m(input) | |||
| """ | |||
| def __init__(self, padding): | |||
| super(ReflectionPad1d, self).__init__(padding) | |||
| self.pad_fun = nn.ReflectionPad1d(self.padding) | |||
| self.padding = _check_padding(padding, 2, "ReflectionPad1d") | |||
| self.pad_fun = nn.ReflectionPad1d(self.padding) # todo: to be deleted | |||
| class ReflectionPad2d(_ReflectionPadNd): | |||
| @@ -181,14 +200,15 @@ class ReflectionPad2d(_ReflectionPadNd): | |||
| Examples:: | |||
| >>> m = nn.ReflectionPad2d(2) | |||
| >>> input = ms_adapter.pytorch.ones(1, 1, 3, 3) | |||
| >>> input = msadapter.pytorch.ones(1, 1, 3, 3) | |||
| >>> m(input) | |||
| """ | |||
| def __init__(self, padding): | |||
| super(ReflectionPad2d, self).__init__(padding) | |||
| self.pad_fun = nn.ReflectionPad2d(self.padding) | |||
| self.padding = _check_padding(padding, 4, "ReflectionPad2d") | |||
| self.pad_fun = nn.ReflectionPad2d(self.padding) # todo: to be deleted | |||
| class ReflectionPad3d(_ReflectionPadNd): | |||
| @@ -217,18 +237,29 @@ class ReflectionPad3d(_ReflectionPadNd): | |||
| Examples:: | |||
| >>> m = nn.ReflectionPad3d(1) | |||
| >>> input = ms_adapter.pytorch.ones(1, 1, 2, 2, 2) | |||
| >>> input = msadapter.pytorch.ones(1, 1, 2, 2, 2) | |||
| >>> m(input) | |||
| """ | |||
| # def __init__(self, padding): | |||
| # super(ReflectionPad3d, self).__init__(padding) | |||
| # TODO: mindspore don't has nn.ReflectionPad3d API now. | |||
| # self.pad_fun = nn.ReflectionPad3d(self.padding) | |||
| def __init__(self, padding): | |||
| super(ReflectionPad3d, self).__init__(padding) | |||
| self.padding = _check_padding(padding, 6, "ReflectionPad3d") | |||
| self.pad_fun = nn.ReflectionPad3d(self.padding) # todo: to be deleted | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| if input.ndim == 5: | |||
| input_shape = input.shape | |||
| input = input.reshape((-1,) + input_shape[2:]) | |||
| output = self.pad_fun(input) | |||
| output = output.reshape(input_shape[0:2] + output.shape[1:]) | |||
| else: | |||
| output = self.pad_fun(input) | |||
| return cast_to_adapter_tensor(output) | |||
| class ZeroPad2d(ConstantPad2d): | |||
| class ZeroPad2d(_ConstantPadNd): | |||
| r"""Pads the input tensor boundaries with zero. | |||
| For `N`-dimensional padding, use :func:`torch.nn.functional.pad()`. | |||
| @@ -249,13 +280,15 @@ class ZeroPad2d(ConstantPad2d): | |||
| Examples:: | |||
| >>> m = nn.ZeroPad2d(2) | |||
| >>> input = ms_adapter.pytorch.ones(1, 1, 3, 3) | |||
| >>> input = msadapter.pytorch.ones(1, 1, 3, 3) | |||
| >>> m(input) | |||
| """ | |||
| def __init__(self, padding) -> None: | |||
| def __init__(self, padding): | |||
| super(ZeroPad2d, self).__init__(padding, 0.) | |||
| self.padding = _check_padding(padding, 4, "ZeroPad2d") | |||
| self.pad_fun = nn.ConstantPad2d(self.padding, self.value) # todo: to be deleted | |||
| class _ReplicationPadNd(Module): | |||
| def __init__(self, padding): | |||
| @@ -265,6 +298,7 @@ class _ReplicationPadNd(Module): | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| #TODO: replace with F.pad(input, self.padding, 'replicate') | |||
| output = self.pad_fun(input) | |||
| return cast_to_adapter_tensor(output) | |||
| @@ -274,14 +308,17 @@ class _ReplicationPadNd(Module): | |||
| class ReplicationPad1d(_ReplicationPadNd): | |||
| def __init__(self, padding): | |||
| super(ReplicationPad1d, self).__init__(padding) | |||
| self.pad_fun = nn.ReplicationPad1d(padding) | |||
| self.padding = _check_padding(padding, 2, "ReplicationPad1d") | |||
| self.pad_fun = nn.ReplicationPad1d(padding) # todo: to be deleted | |||
| class ReplicationPad2d(_ReplicationPadNd): | |||
| def __init__(self, padding): | |||
| super(ReplicationPad2d, self).__init__(padding) | |||
| self.pad_fun = nn.ReplicationPad2d(padding) | |||
| self.padding = _check_padding(padding, 4, "ReplicationPad2d") | |||
| self.pad_fun = nn.ReplicationPad2d(padding) # todo: to be deleted | |||
| class ReplicationPad3d(_ReplicationPadNd): | |||
| def __init__(self, padding): | |||
| super(ReplicationPad3d, self).__init__(padding) | |||
| self.pad_fun = nn.ReplicationPad3d(padding) | |||
| self.padding = _check_padding(padding, 6, "ReplicationPad3d") | |||
| self.pad_fun = nn.ReplicationPad3d(padding) # todo: to be deleted | |||
+ 26
- 0
msadapter/pytorch/nn/modules/pixelshuffle.py
View File
| @@ -0,0 +1,26 @@ | |||
| from msadapter.pytorch.nn.modules.module import Module | |||
| from msadapter.pytorch.nn.functional import pixel_shuffle, pixel_unshuffle | |||
| __all__ = ['PixelShuffle', 'PixelUnshuffle'] | |||
| class PixelShuffle(Module): | |||
| def __init__(self, upscale_factor): | |||
| super(PixelShuffle, self).__init__() | |||
| self.upscale_factor = upscale_factor | |||
| def forward(self, input): | |||
| return pixel_shuffle(input, self.upscale_factor) | |||
| def extra_repr(self) -> str: | |||
| return 'upscale_factor={}'.format(self.upscale_factor) | |||
| class PixelUnshuffle(Module): | |||
| def __init__(self, downscale_factor): | |||
| super(PixelUnshuffle, self).__init__() | |||
| self.downscale_factor = downscale_factor | |||
| def forward(self, input): | |||
| return pixel_unshuffle(input, self.downscale_factor) | |||
| def extra_repr(self) -> str: | |||
| return 'downscale_factor={}'.format(self.downscale_factor) | |||
+ 202
- 0
msadapter/pytorch/nn/modules/pooling.py
View File
| @@ -0,0 +1,202 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import msadapter.pytorch.nn.functional as Adapter_F | |||
| from .module import Module | |||
| __all__ = ['MaxPool1d', 'MaxPool2d', 'MaxPool3d', | |||
| 'AvgPool1d', 'AvgPool2d', 'AvgPool3d', | |||
| 'AdaptiveAvgPool1d', 'AdaptiveAvgPool2d', 'AdaptiveAvgPool3d', | |||
| 'AdaptiveMaxPool1d', 'AdaptiveMaxPool2d', 'AdaptiveMaxPool3d', | |||
| 'LPPool1d', 'LPPool2d', 'FractionalMaxPool2d', 'FractionalMaxPool3d'] | |||
| class _MaxPoolNd(Module): | |||
| def __init__(self, kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False): | |||
| super(_MaxPoolNd, self).__init__() | |||
| self.kernel_size = kernel_size | |||
| self.stride = stride if (stride is not None) else kernel_size | |||
| self.padding = padding | |||
| self.dilation = dilation | |||
| self.return_indices = return_indices | |||
| self.ceil_mode = ceil_mode | |||
| def extra_repr(self): | |||
| return 'kernel_size={kernel_size}, stride={stride}, padding={padding}' \ | |||
| ', dilation={dilation}, ceil_mode={ceil_mode}'.format(**self.__dict__) | |||
| class MaxPool1d(_MaxPoolNd): | |||
| def forward(self, input): | |||
| return Adapter_F.max_pool1d(input, self.kernel_size, self.stride, self.padding, self.dilation, | |||
| self.ceil_mode, self.return_indices) | |||
| class MaxPool2d(_MaxPoolNd): | |||
| def forward(self, input): | |||
| return Adapter_F.max_pool2d(input, self.kernel_size, self.stride, self.padding, self.dilation, | |||
| self.ceil_mode, self.return_indices) | |||
| class MaxPool3d(_MaxPoolNd): | |||
| def forward(self, input): | |||
| return Adapter_F.max_pool3d(input, self.kernel_size, self.stride, self.padding, self.dilation, | |||
| self.ceil_mode, self.return_indices) | |||
| class _AvgPoolNd(Module): | |||
| def __init__(self, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, | |||
| divisor_override = None): | |||
| super(_AvgPoolNd, self).__init__() | |||
| self.kernel_size = kernel_size | |||
| self.stride = stride if (stride is not None) else kernel_size | |||
| self.padding = padding | |||
| self.ceil_mode = ceil_mode | |||
| self.count_include_pad = count_include_pad | |||
| self.divisor_override = divisor_override | |||
| def extra_repr(self): | |||
| return 'kernel_size={}, stride={}, padding={}'.format( | |||
| self.kernel_size, self.stride, self.padding | |||
| ) | |||
| class AvgPool1d(_AvgPoolNd): | |||
| def __init__(self, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True): | |||
| super(AvgPool1d, self).__init__(kernel_size, stride, padding, ceil_mode, count_include_pad) | |||
| def forward(self, input): | |||
| return Adapter_F.avg_pool1d(input, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, | |||
| ceil_mode=self.ceil_mode, count_include_pad=self.count_include_pad) | |||
| class AvgPool2d(_AvgPoolNd): | |||
| def forward(self, input): | |||
| return Adapter_F.avg_pool2d(input, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, | |||
| ceil_mode=self.ceil_mode, count_include_pad=self.count_include_pad, | |||
| divisor_override=self.divisor_override) | |||
| class AvgPool3d(_AvgPoolNd): | |||
| def forward(self, input): | |||
| return Adapter_F.avg_pool3d(input, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, | |||
| ceil_mode=self.ceil_mode, count_include_pad=self.count_include_pad, | |||
| divisor_override=self.divisor_override) | |||
| class _AdaptiveAvgPoolNd(Module): | |||
| def __init__(self, output_size): | |||
| super(_AdaptiveAvgPoolNd, self).__init__() | |||
| self.output_size = output_size | |||
| def extra_repr(self): | |||
| return 'output_size={}'.format(self.output_size) | |||
| class AdaptiveAvgPool1d(_AdaptiveAvgPoolNd): | |||
| def forward(self, input): | |||
| return Adapter_F.adaptive_avg_pool1d(input, self.output_size) | |||
| class AdaptiveAvgPool2d(_AdaptiveAvgPoolNd): | |||
| def forward(self, input): | |||
| return Adapter_F.adaptive_avg_pool2d(input, self.output_size) | |||
| class AdaptiveAvgPool3d(_AdaptiveAvgPoolNd): | |||
| def forward(self, input): | |||
| return Adapter_F.adaptive_avg_pool3d(input, self.output_size) | |||
| class _AdaptiveMaxPoolNd(Module): | |||
| def __init__(self, output_size, return_indices=False): | |||
| super(_AdaptiveMaxPoolNd, self).__init__() | |||
| self.output_size = output_size | |||
| self.return_indices = return_indices | |||
| def extra_repr(self) -> str: | |||
| return 'output_size={}'.format(self.output_size) | |||
| class AdaptiveMaxPool1d(_AdaptiveMaxPoolNd): | |||
| def forward(self, input): | |||
| return Adapter_F.adaptive_max_pool1d(input, self.output_size, self.return_indices) | |||
| class AdaptiveMaxPool2d(_AdaptiveMaxPoolNd): | |||
| def forward(self, input): | |||
| return Adapter_F.adaptive_max_pool2d(input, self.output_size, self.return_indices) | |||
| class AdaptiveMaxPool3d(_AdaptiveMaxPoolNd): | |||
| def forward(self, input): | |||
| outputs = Adapter_F.adaptive_max_pool3d(input, self.output_size, self.return_indices) | |||
| return outputs | |||
| class _LPPoolNd(Module): | |||
| def __init__(self, norm_type, kernel_size, stride=None, ceil_mode=False): | |||
| super(_LPPoolNd, self).__init__() | |||
| self.norm_type = norm_type | |||
| self.kernel_size = kernel_size | |||
| self.stride = stride if (stride is not None) else kernel_size | |||
| self.ceil_mode = ceil_mode | |||
| def extra_repr(self): | |||
| return 'norm_type={norm_type}, kernel_size={kernel_size}, stride={stride}, ' \ | |||
| 'ceil_mode={ceil_mode}'.format(**self.__dict__) | |||
| class LPPool1d(_LPPoolNd): | |||
| def forward(self, input): | |||
| return Adapter_F.lp_pool1d(input, self.norm_type, self.kernel_size, self.stride, self.ceil_mode) | |||
| class LPPool2d(_LPPoolNd): | |||
| def forward(self, input): | |||
| return Adapter_F.lp_pool2d(input, self.norm_type, self.kernel_size, self.stride, self.ceil_mode) | |||
| class FractionalMaxPool2d(Module): | |||
| def __init__(self, kernel_size, output_size=None, output_ratio=None, return_indices=False, | |||
| _random_samples=None): | |||
| super(FractionalMaxPool2d, self).__init__() | |||
| self.kernel_size = kernel_size | |||
| self.return_indices = return_indices | |||
| self.output_size = output_size | |||
| self.output_ratio = output_ratio | |||
| self._random_samples = _random_samples | |||
| if output_size is None and output_ratio is None: | |||
| raise ValueError("FractionalMaxPool2d requires specifying either " | |||
| "an output size, or a pooling ratio") | |||
| if output_size is not None and output_ratio is not None: | |||
| raise ValueError("only one of output_size and output_ratio may be specified") | |||
| if self.output_ratio is not None: | |||
| if not (0 < self.output_ratio[0] < 1 and 0 < self.output_ratio[1] < 1): | |||
| raise ValueError("output_ratio must be between 0 and 1 (got {})" | |||
| .format(output_ratio)) | |||
| def forward(self, input): | |||
| return Adapter_F.fractional_max_pool2d(input, self.kernel_size, self.output_size, self.output_ratio, | |||
| self.return_indices, self._random_samples) | |||
| class FractionalMaxPool3d(Module): | |||
| def __init__(self, kernel_size, output_size=None, output_ratio=None, return_indices=False, | |||
| _random_samples=None): | |||
| super(FractionalMaxPool3d, self).__init__() | |||
| self.kernel_size = kernel_size | |||
| self.return_indices = return_indices | |||
| self.output_size = output_size | |||
| self.output_ratio = output_ratio | |||
| self._random_samples = _random_samples | |||
| if output_size is None and output_ratio is None: | |||
| raise ValueError("FractionalMaxPool3d requires specifying either " | |||
| "an output size, or a pooling ratio") | |||
| if output_size is not None and output_ratio is not None: | |||
| raise ValueError("only one of output_size and output_ratio may be specified") | |||
| if self.output_ratio is not None: | |||
| if not (0 < self.output_ratio[0] < 1 and 0 < self.output_ratio[1] < 1): | |||
| raise ValueError("output_ratio must be between 0 and 1 (got {})" | |||
| .format(output_ratio)) | |||
| def forward(self, input): | |||
| return Adapter_F.fractional_max_pool3d(input, self.kernel_size, self.output_size, self.output_ratio, | |||
| self.return_indices, self._random_samples) | |||
+ 504
- 0
msadapter/pytorch/nn/modules/rnn.py
View File
| @@ -0,0 +1,504 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import numbers | |||
| import warnings | |||
| import math | |||
| import mindspore as ms | |||
| from mindspore.nn.layer.rnns import _DynamicRNNRelu, _DynamicRNNTanh, _DynamicLSTMCPUGPU, _DynamicLSTMAscend, \ | |||
| _DynamicGRUAscend, _DynamicGRUCPUGPU | |||
| from mindspore.nn.layer.rnn_cells import _rnn_tanh_cell, _rnn_relu_cell, _lstm_cell, _gru_cell | |||
| from msadapter.pytorch.nn.modules.module import Module | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from msadapter.pytorch.nn.parameter import Parameter | |||
| from msadapter.pytorch.functional import empty, zeros | |||
| from msadapter.pytorch.nn import init | |||
| from msadapter.utils import unsupported_attr, is_under_ascend_context | |||
| class RNNBase(Module): | |||
| def __init__(self, mode, input_size, hidden_size, | |||
| num_layers=1, bias=True, batch_first=False, | |||
| dropout=0., bidirectional=False, proj_size=0, | |||
| device=None, dtype=None): | |||
| unsupported_attr(device) | |||
| super(RNNBase, self).__init__() | |||
| self.mode = mode | |||
| self.input_size = input_size | |||
| self.hidden_size = hidden_size | |||
| self.num_layers = num_layers | |||
| self.bias = bias | |||
| self.batch_first = batch_first | |||
| self.dropout = float(dropout) | |||
| self.bidirectional = bidirectional | |||
| self.proj_size = proj_size | |||
| self.num_directions = 2 if bidirectional else 1 | |||
| if not isinstance(dropout, numbers.Number) or not 0 <= dropout <= 1 or \ | |||
| isinstance(dropout, bool): | |||
| raise ValueError("dropout should be a number in range [0, 1] " | |||
| "representing the probability of an element being " | |||
| "zeroed") | |||
| if dropout > 0 and num_layers == 1: | |||
| warnings.warn("dropout option adds dropout after all but last " | |||
| "recurrent layer, so non-zero dropout expects " | |||
| "num_layers greater than 1, but got dropout={} and " | |||
| "num_layers={}".format(dropout, num_layers)) | |||
| if proj_size < 0: | |||
| raise ValueError("proj_size should be a positive integer or zero to disable projections") | |||
| if proj_size >= hidden_size: | |||
| raise ValueError("proj_size has to be smaller than hidden_size") | |||
| if mode == 'LSTM': | |||
| gate_size = 4 * hidden_size | |||
| elif mode == 'GRU': | |||
| if is_under_ascend_context() and hidden_size % 16 != 0: | |||
| raise ValueError(f"GRU on ascend do not support hidden size that is not divisible by 16, " | |||
| f"but get hidden size {hidden_size}, please reset the argument.") | |||
| gate_size = 3 * hidden_size | |||
| elif mode == 'RNN_TANH': | |||
| gate_size = hidden_size | |||
| elif mode == 'RNN_RELU': | |||
| gate_size = hidden_size | |||
| else: | |||
| raise ValueError("Unrecognized RNN mode: " + mode) | |||
| self._flat_weights_names = [] | |||
| self._all_weights = [] | |||
| for layer in range(num_layers): | |||
| for direction in range(self.num_directions): | |||
| real_hidden_size = proj_size if proj_size > 0 else hidden_size | |||
| layer_input_size = input_size if layer == 0 else real_hidden_size * self.num_directions | |||
| w_ih = Parameter(empty((gate_size, layer_input_size), dtype=dtype)) | |||
| w_hh = Parameter(empty((gate_size, real_hidden_size), dtype=dtype)) | |||
| b_ih = Parameter(empty(gate_size, dtype=dtype)) | |||
| b_hh = Parameter(empty(gate_size, dtype=dtype)) | |||
| layer_params = () | |||
| if self.proj_size == 0: | |||
| if bias: | |||
| layer_params = (w_ih, w_hh, b_ih, b_hh) | |||
| else: | |||
| layer_params = (w_ih, w_hh) | |||
| else: | |||
| w_hr = Parameter(empty((proj_size, hidden_size), dtype=dtype)) | |||
| if bias: | |||
| layer_params = (w_ih, w_hh, b_ih, b_hh, w_hr) | |||
| else: | |||
| layer_params = (w_ih, w_hh, w_hr) | |||
| suffix = '_reverse' if direction == 1 else '' | |||
| param_names = ['weight_ih_l{}{}', 'weight_hh_l{}{}'] | |||
| if bias: | |||
| param_names += ['bias_ih_l{}{}', 'bias_hh_l{}{}'] | |||
| if self.proj_size > 0: | |||
| param_names += ['weight_hr_l{}{}'] | |||
| param_names = [x.format(layer, suffix) for x in param_names] | |||
| for name, param in zip(param_names, layer_params): | |||
| setattr(self, name, param) | |||
| self._flat_weights_names.extend(param_names) | |||
| self._all_weights.append(param_names) | |||
| self._flat_weights = \ | |||
| [(lambda wn: getattr(self, wn) if hasattr(self, wn) else None)(wn) for wn in self._flat_weights_names] | |||
| self.reset_parameters() | |||
| def __setattr__(self, attr, value): | |||
| if hasattr(self, "_flat_weights_names") and attr in self._flat_weights_names: | |||
| # keep self._flat_weights up to date if you do self.weight = ... | |||
| idx = self._flat_weights_names.index(attr) | |||
| self._flat_weights[idx] = value | |||
| super(RNNBase, self).__setattr__(attr, value) | |||
| def reset_parameters(self) -> None: | |||
| stdv = 1.0 / math.sqrt(self.hidden_size) if self.hidden_size > 0 else 0 | |||
| for weight in self.parameters(): | |||
| init.uniform_(weight, -stdv, stdv) | |||
| def extra_repr(self): | |||
| s = '{input_size}, {hidden_size}' | |||
| if self.proj_size != 0: | |||
| s += ', proj_size={proj_size}' | |||
| if self.num_layers != 1: | |||
| s += ', num_layers={num_layers}' | |||
| if self.bias is not True: | |||
| s += ', bias={bias}' | |||
| if self.batch_first is not False: | |||
| s += ', batch_first={batch_first}' | |||
| if self.dropout != 0: | |||
| s += ', dropout={dropout}' | |||
| if self.bidirectional is not False: | |||
| s += ', bidirectional={bidirectional}' | |||
| return s.format(**self.__dict__) | |||
| @property | |||
| def all_weights(self): | |||
| return [[getattr(self, weight) for weight in weights] for weights in self._all_weights] | |||
| def __setstate__(self, d): | |||
| super(RNNBase, self).__setstate__(d) | |||
| if 'all_weights' in d: | |||
| self._all_weights = d['all_weights'] | |||
| # In PyTorch 1.8 we added a proj_size member variable to LSTM. | |||
| # LSTMs that were serialized via torch.save(module) before PyTorch 1.8 | |||
| # don't have it, so to preserve compatibility we set proj_size here. | |||
| if 'proj_size' not in d: | |||
| self.proj_size = 0 | |||
| if isinstance(self._all_weights[0][0], str): | |||
| return | |||
| num_layers = self.num_layers | |||
| num_directions = 2 if self.bidirectional else 1 | |||
| self._flat_weights_names = [] | |||
| self._all_weights = [] | |||
| for layer in range(num_layers): | |||
| for direction in range(num_directions): | |||
| suffix = '_reverse' if direction == 1 else '' | |||
| weights = ['weight_ih_l{}{}', 'weight_hh_l{}{}', 'bias_ih_l{}{}', | |||
| 'bias_hh_l{}{}', 'weight_hr_l{}{}'] | |||
| weights = [x.format(layer, suffix) for x in weights] | |||
| if self.bias: | |||
| if self.proj_size > 0: | |||
| self._all_weights += [weights] | |||
| self._flat_weights_names.extend(weights) | |||
| else: | |||
| self._all_weights += [weights[:4]] | |||
| self._flat_weights_names.extend(weights[:4]) | |||
| else: | |||
| if self.proj_size > 0: | |||
| self._all_weights += [weights[:2]] + [weights[-1:]] | |||
| self._flat_weights_names.extend(weights[:2] + [weights[-1:]]) | |||
| else: | |||
| self._all_weights += [weights[:2]] | |||
| self._flat_weights_names.extend(weights[:2]) | |||
| self._flat_weights = \ | |||
| [(lambda wn: getattr(self, wn) if hasattr(self, wn) else None)(wn) for wn in self._flat_weights_names] | |||
| def _get_weight_and_bias(self, num_directions, layer, bias): | |||
| _param_nums_per_directions = 4 if bias else 2 | |||
| _param_nums_per_layer = num_directions * _param_nums_per_directions | |||
| offset = _param_nums_per_layer * layer | |||
| param = () | |||
| for _ in range(num_directions): | |||
| if bias: | |||
| param += tuple(self._flat_weights[offset:offset + _param_nums_per_directions]) | |||
| else: | |||
| param += tuple(self._flat_weights[offset:offset + _param_nums_per_directions]) | |||
| param += (None, None) | |||
| offset = offset + _param_nums_per_directions | |||
| # cast parameter to ms.Tensor before call ms function. | |||
| return cast_to_ms_tensor(param) | |||
| def forward(self, input, hx=None): | |||
| if len(input.shape) not in (2, 3): | |||
| raise RuntimeError(f"For RNN, input should be 2D or 3D, but got {len(input.shape)}D.") | |||
| is_batched = len(input.shape) == 3 | |||
| input = cast_to_ms_tensor(input) | |||
| if not is_batched: | |||
| input = ms.ops.unsqueeze(input, 1) | |||
| else: | |||
| if self.batch_first: | |||
| input = ms.ops.transpose(input, (1, 0, 2)) | |||
| x_dtype = input.dtype | |||
| max_batch_size = input.shape[1] | |||
| num_directions = 2 if self.bidirectional else 1 | |||
| if hx is None: | |||
| hx = zeros(self.num_layers * num_directions, | |||
| max_batch_size, self.hidden_size, | |||
| dtype=x_dtype) | |||
| hx = cast_to_ms_tensor(hx) | |||
| else: | |||
| hx = cast_to_ms_tensor(hx) | |||
| if len(hx.shape) not in (2, 3): | |||
| raise RuntimeError(f"For RNN, hx should be 2D or 3D, but got {len(hx.shape)}D.") | |||
| if not is_batched: | |||
| if len(hx.shape) != 2: | |||
| raise RuntimeError("For RNN, hx ndim should be equal to input") | |||
| hx = ms.ops.unsqueeze(hx, 1) | |||
| pre_layer = input | |||
| h_n = () | |||
| # For jit | |||
| output = None | |||
| if num_directions == 1: | |||
| for i in range(self.num_layers): | |||
| w_ih, w_hh, b_ih, b_hh = self._get_weight_and_bias(num_directions, i, self.bias) | |||
| output, h_t = self.rnn_cell(pre_layer, hx[i], None, w_ih, w_hh, b_ih, b_hh) | |||
| h_n += (h_t,) | |||
| pre_layer = ms.ops.dropout(output, 1 - self.dropout) \ | |||
| if (self.dropout != 0 and i < self.num_layers - 1) else output | |||
| else: | |||
| for i in range(self.num_layers): | |||
| w_ih, w_hh, b_ih, b_hh, w_ih_b, w_hh_b, b_ih_b, b_hh_b = \ | |||
| self._get_weight_and_bias(num_directions, i, self.bias) | |||
| x_b = ms.ops.reverse(pre_layer, [0]) | |||
| output, h_t = self.rnn_cell(pre_layer, hx[2 * i], None, w_ih, w_hh, b_ih, b_hh) | |||
| output_b, h_t_b = self.rnn_cell(x_b, hx[2 * i + 1], None, w_ih_b, w_hh_b, b_ih_b, b_hh_b) | |||
| output_b = ms.ops.reverse(output_b, [0]) | |||
| output = ms.ops.concat((output, output_b), 2) | |||
| h_n += (h_t,) | |||
| h_n += (h_t_b,) | |||
| pre_layer = ms.ops.dropout(output, 1 - self.dropout) \ | |||
| if (self.dropout != 0 and i < self.num_layers - 1) else output | |||
| h_n = ms.ops.concat(h_n, 0) | |||
| h_n = h_n.view(hx.shape) | |||
| if not is_batched: | |||
| output = ms.ops.squeeze(output, 1) | |||
| h_n = ms.ops.squeeze(h_n, 1) | |||
| else: | |||
| if self.batch_first: | |||
| output = ms.ops.transpose(output, (1, 0, 2)) | |||
| return cast_to_adapter_tensor(output.astype(x_dtype)), cast_to_adapter_tensor(h_n.astype(x_dtype)) | |||
| class RNN(RNNBase): | |||
| def __init__(self, *args, **kwargs): | |||
| if 'proj_size' in kwargs: | |||
| raise ValueError("proj_size argument is only supported for LSTM, not RNN or GRU") | |||
| self.nonlinearity = kwargs.pop('nonlinearity', 'tanh') | |||
| if self.nonlinearity == 'tanh': | |||
| mode = 'RNN_TANH' | |||
| elif self.nonlinearity == 'relu': | |||
| mode = 'RNN_RELU' | |||
| else: | |||
| raise ValueError("Unknown nonlinearity '{}'".format(self.nonlinearity)) | |||
| super(RNN, self).__init__(mode, *args, **kwargs) | |||
| if mode == 'RNN_TANH': | |||
| self.rnn_cell = _DynamicRNNRelu() | |||
| elif mode == 'RNN_RELU': | |||
| self.rnn_cell = _DynamicRNNTanh() | |||
| class GRU(RNNBase): | |||
| def __init__(self, *args, **kwargs): | |||
| if 'proj_size' in kwargs: | |||
| raise ValueError("proj_size argument is only supported for LSTM, not RNN or GRU") | |||
| super(GRU, self).__init__('GRU', *args, **kwargs) | |||
| if is_under_ascend_context(): | |||
| self.rnn_cell = _DynamicGRUAscend() | |||
| else: | |||
| self.rnn_cell = _DynamicGRUCPUGPU() | |||
| class LSTM(RNNBase): | |||
| def __init__(self, *args, **kwargs): | |||
| super(LSTM, self).__init__('LSTM', *args, **kwargs) | |||
| if self.proj_size > 0: | |||
| raise NotImplementedError("For LSTM, proj_size > 0 is not supported yet.") | |||
| if is_under_ascend_context(): | |||
| self.lstm_cell = _DynamicLSTMAscend() | |||
| else: | |||
| self.lstm_cell = _DynamicLSTMCPUGPU() | |||
| def forward(self, input, hx=None): | |||
| if len(input.shape) not in (2, 3): | |||
| raise RuntimeError(f"For LSTM, input should be 2D or 3D, but got {len(input.shape)}D.") | |||
| is_batched = len(input.shape) == 3 | |||
| input = cast_to_ms_tensor(input) | |||
| if not is_batched: | |||
| input = ms.ops.unsqueeze(input, 1) | |||
| else: | |||
| if self.batch_first: | |||
| input = ms.ops.transpose(input, (1, 0, 2)) | |||
| x_dtype = input.dtype | |||
| max_batch_size = input.shape[1] | |||
| num_directions = 2 if self.bidirectional else 1 | |||
| real_hidden_size = self.proj_size if self.proj_size > 0 else self.hidden_size | |||
| if hx is None: | |||
| h_zeros = zeros(self.num_layers * num_directions, | |||
| max_batch_size, real_hidden_size, | |||
| dtype=x_dtype) | |||
| c_zeros = zeros(self.num_layers * num_directions, | |||
| max_batch_size, self.hidden_size, | |||
| dtype=x_dtype) | |||
| hx = (h_zeros, c_zeros) | |||
| hx = cast_to_ms_tensor(hx) | |||
| else: | |||
| hx = cast_to_ms_tensor(hx) | |||
| if is_batched: | |||
| if (len(hx[0].shape) != 3 or len(hx[1].shape) != 3): | |||
| msg = ("For batched 3-D input, hx and cx should " | |||
| f"also be 3-D but got ({len(hx[0].shape)}-D, {len(hx[1].shape)}-D) tensors") | |||
| raise RuntimeError(msg) | |||
| else: | |||
| if len(hx[0].shape) != 2 or len(hx[1].shape) != 2: | |||
| msg = ("For unbatched 2-D input, hx and cx should " | |||
| f"also be 2-D but got ({len(hx[0].shape)}-D, {len(hx[1].shape)}-D) tensors") | |||
| raise RuntimeError(msg) | |||
| hx = (ms.ops.unsqueeze(hx[0], 1), ms.ops.unsqueeze(hx[1], 1)) | |||
| pre_layer = input | |||
| h_n = () | |||
| c_n = () | |||
| # For jit | |||
| output = None | |||
| if num_directions == 1: | |||
| for i in range(self.num_layers): | |||
| w_ih, w_hh, b_ih, b_hh = self._get_weight_and_bias(num_directions, i, self.bias) | |||
| h_i = (hx[0][i], hx[1][i]) | |||
| output, hc_t = self.lstm_cell(pre_layer, h_i, None, w_ih, w_hh, b_ih, b_hh) | |||
| h_t, c_t = hc_t | |||
| h_n += (h_t,) | |||
| c_n += (c_t,) | |||
| pre_layer = ms.ops.dropout(output, 1 - self.dropout) \ | |||
| if (self.dropout != 0 and i < self.num_layers - 1) else output | |||
| else: | |||
| for i in range(self.num_layers): | |||
| w_ih, w_hh, b_ih, b_hh, w_ih_b, w_hh_b, b_ih_b, b_hh_b = \ | |||
| self._get_weight_and_bias(num_directions, i, self.bias) | |||
| x_b = ms.ops.reverse(pre_layer, [0]) | |||
| h_i = (hx[0][2 * i], hx[1][2 * i]) | |||
| h_b_i = (hx[0][2 * i + 1], hx[1][2 * i + 1]) | |||
| output, hc_t = self.lstm_cell(pre_layer, h_i, None, w_ih, w_hh, b_ih, b_hh) | |||
| output_b, hc_t_b = self.lstm_cell(x_b, h_b_i, None, w_ih_b, w_hh_b, b_ih_b, b_hh_b) | |||
| output_b = ms.ops.reverse(output_b, [0]) | |||
| output = ms.ops.concat((output, output_b), 2) | |||
| h_t, c_t = hc_t | |||
| h_t_b, c_t_b = hc_t_b | |||
| h_n += (h_t,) | |||
| h_n += (h_t_b,) | |||
| c_n += (c_t,) | |||
| c_n += (c_t_b,) | |||
| pre_layer = ms.ops.dropout(output, 1 - self.dropout) \ | |||
| if (self.dropout != 0 and i < self.num_layers - 1) else output | |||
| h_n = ms.ops.concat(h_n, 0) | |||
| h_n = h_n.view(hx[0].shape) | |||
| c_n = ms.ops.concat(c_n, 0) | |||
| c_n = c_n.view(hx[1].shape) | |||
| if not is_batched: | |||
| output = ms.ops.squeeze(output, 1) | |||
| h_n = ms.ops.squeeze(h_n, 1) | |||
| c_n = ms.ops.squeeze(c_n, 1) | |||
| else: | |||
| if self.batch_first: | |||
| output = ms.ops.transpose(output, (1, 0, 2)) | |||
| return cast_to_adapter_tensor(output.astype(x_dtype)), \ | |||
| cast_to_adapter_tensor((h_n.astype(x_dtype), c_n.astype(x_dtype))) | |||
| class RNNCellBase(Module): | |||
| def __init__(self, input_size, hidden_size, bias, num_chunks, device=None, dtype=None): | |||
| unsupported_attr(device) | |||
| super(RNNCellBase, self).__init__() | |||
| self.input_size = input_size | |||
| self.hidden_size = hidden_size | |||
| self.bias = bias | |||
| self.weight_ih = Parameter(empty((num_chunks * hidden_size, input_size), dtype=dtype)) | |||
| self.weight_hh = Parameter(empty((num_chunks * hidden_size, hidden_size), dtype=dtype)) | |||
| if bias: | |||
| self.bias_ih = Parameter(empty(num_chunks * hidden_size, dtype=dtype)) | |||
| self.bias_hh = Parameter(empty(num_chunks * hidden_size, dtype=dtype)) | |||
| else: | |||
| self.register_parameter('bias_ih', None) | |||
| self.register_parameter('bias_hh', None) | |||
| self._rnn_cell = None | |||
| self.reset_parameters() | |||
| def extra_repr(self) -> str: | |||
| s = '{input_size}, {hidden_size}' | |||
| if 'bias' in self.__dict__ and self.bias is not True: | |||
| s += ', bias={bias}' | |||
| if 'nonlinearity' in self.__dict__ and self.nonlinearity != "tanh": | |||
| s += ', nonlinearity={nonlinearity}' | |||
| return s.format(**self.__dict__) | |||
| def reset_parameters(self) -> None: | |||
| stdv = 1.0 / math.sqrt(self.hidden_size) if self.hidden_size > 0 else 0 | |||
| for weight in self.parameters(): | |||
| init.uniform_(weight, -stdv, stdv) | |||
| def forward(self, input, hx=None): | |||
| input = cast_to_ms_tensor(input) | |||
| if len(input.shape) not in (1, 2): | |||
| raise RuntimeError(f"RNNCell: Expected input to be 1-D or 2-D but received {len(input.shape)}-D tensor") | |||
| is_batched = len(input.shape) == 2 | |||
| if not is_batched: | |||
| input = ms.ops.unsqueeze(input, 0) | |||
| if hx is None: | |||
| hx = zeros(input.shape[0], self.hidden_size, dtype=input.dtype) | |||
| hx = cast_to_ms_tensor(hx) | |||
| else: | |||
| hx = cast_to_ms_tensor(hx) | |||
| hx = ms.ops.unsqueeze(hx, 0) if not is_batched else hx | |||
| ret = self._rnn_cell(input, hx, self.weight_ih, self.weight_hh, self.bias_ih, self.bias_hh) | |||
| if not is_batched: | |||
| ret = ms.ops.squeeze(ret, 0) | |||
| return cast_to_adapter_tensor(ret) | |||
| class RNNCell(RNNCellBase): | |||
| def __init__(self, input_size, hidden_size, bias=True, nonlinearity="tanh", | |||
| device=None, dtype=None): | |||
| super(RNNCell, self).__init__(input_size, hidden_size, bias, num_chunks=1, device=device, dtype=dtype) | |||
| self.nonlinearity = nonlinearity | |||
| if self.nonlinearity == "tanh": | |||
| self._rnn_cell = _rnn_tanh_cell | |||
| elif self.nonlinearity == "relu": | |||
| self._rnn_cell = _rnn_relu_cell | |||
| else: | |||
| raise RuntimeError( | |||
| "Unknown nonlinearity: {}".format(self.nonlinearity)) | |||
| class LSTMCell(RNNCellBase): | |||
| def __init__(self, input_size, hidden_size, bias=True, device=None, dtype=None): | |||
| super(LSTMCell, self).__init__(input_size, hidden_size, bias, num_chunks=4, device=device, dtype=dtype) | |||
| def forward(self, input, hx=None): | |||
| input = cast_to_ms_tensor(input) | |||
| if len(input.shape) not in (1, 2): | |||
| raise RuntimeError(f"LSTMCell: Expected input to be 1-D or 2-D but received {len(input.shape)}-D tensor") | |||
| is_batched = len(input.shape) == 2 | |||
| if not is_batched: | |||
| input = ms.ops.unsqueeze(input, 0) | |||
| if hx is None: | |||
| _zeros = zeros(input.shape[0], self.hidden_size, dtype=input.dtype) | |||
| hx = (_zeros, _zeros) | |||
| hx = cast_to_ms_tensor(hx) | |||
| else: | |||
| hx = cast_to_ms_tensor(hx) | |||
| hx = (ms.ops.unsqueeze(hx[0], 0), ms.ops.unsqueeze(hx[1], 0)) if not is_batched else hx | |||
| hx = cast_to_ms_tensor(hx) | |||
| ret = _lstm_cell(input, hx, self.weight_ih, self.weight_hh, self.bias_ih, self.bias_hh) | |||
| if not is_batched: | |||
| ret = (ms.ops.squeeze(ret[0], 0), ms.ops.squeeze(ret[1], 0)) | |||
| return cast_to_adapter_tensor(ret) | |||
| class GRUCell(RNNCellBase): | |||
| def __init__(self, input_size, hidden_size, bias=True, device=None, dtype=None): | |||
| super(GRUCell, self).__init__(input_size, hidden_size, bias, num_chunks=3, device=device, dtype=dtype) | |||
| self._rnn_cell = _gru_cell | |||
ms_adapter/pytorch/nn/modules/sparse.py → msadapter/pytorch/nn/modules/sparse.py
View File
| @@ -1,9 +1,9 @@ | |||
| import ms_adapter.pytorch.nn.functional as Adapter_F | |||
| from ms_adapter.pytorch.functional import empty | |||
| from ms_adapter.pytorch.nn.parameter import Parameter | |||
| from ms_adapter.utils import unsupported_attr | |||
| from ms_adapter.pytorch.nn.modules.module import Module | |||
| from ms_adapter.pytorch.nn.init import normal_ | |||
| import msadapter.pytorch.nn.functional as Adapter_F | |||
| from msadapter.pytorch.functional import empty | |||
| from msadapter.pytorch.nn.parameter import Parameter | |||
| from msadapter.utils import unsupported_attr | |||
| from msadapter.pytorch.nn.modules.module import Module | |||
| from msadapter.pytorch.nn.init import normal_ | |||
| __all__ = ['Embedding'] | |||
| @@ -14,10 +14,6 @@ class Embedding(Module): | |||
| unsupported_attr(scale_grad_by_freq) | |||
| unsupported_attr(sparse) | |||
| unsupported_attr(device) | |||
| #TODO: padding_idx is not supported, because can not not updating the gradient of | |||
| # weight[padding_idx] | |||
| if padding_idx: | |||
| raise NotImplementedError("nn.Embedding: `padding_idx` is not supported until now.") | |||
| super(Embedding, self).__init__() | |||
| self.num_embeddings = num_embeddings | |||
| @@ -49,8 +45,8 @@ class Embedding(Module): | |||
| self._fill_padding_idx_with_zero() | |||
| def _fill_padding_idx_with_zero(self): | |||
| # TODO: to support `padding_idx` in the future | |||
| return | |||
| if self.padding_idx is not None: | |||
| self.weight[self.padding_idx] = 0 | |||
| def forward(self, input): | |||
| return Adapter_F.embedding( | |||
+ 288
- 0
msadapter/pytorch/nn/modules/transformer.py
View File
| @@ -0,0 +1,288 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import copy | |||
| import mindspore as ms | |||
| import mindspore.ops as ops | |||
| from msadapter.utils import unsupported_attr | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from .module import Module | |||
| from .activation import MultiheadAttention | |||
| from .container import ModuleList | |||
| from .dropout import Dropout | |||
| from .linear import Linear | |||
| from .normalization import LayerNorm | |||
| from .. import functional as F | |||
| from ..init import xavier_uniform_ | |||
| __all__ = ['TransformerEncoderLayer', 'TransformerDecoderLayer', 'TransformerEncoder', 'TransformerDecoder', | |||
| 'Transformer'] | |||
| class Transformer(Module): | |||
| def __init__(self, d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=2048, | |||
| dropout=0.1, activation='relu', custom_encoder=None, custom_decoder=None, layer_norm_eps=1e-5, | |||
| batch_first=False, norm_first=False, device=None, dtype=None): | |||
| unsupported_attr(device) | |||
| super(Transformer, self).__init__() | |||
| if custom_encoder is not None: | |||
| self.encoder = custom_encoder | |||
| else: | |||
| encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout, activation, | |||
| layer_norm_eps, batch_first, norm_first, dtype=dtype) | |||
| encoder_norm = LayerNorm(d_model, eps=layer_norm_eps, dtype=dtype) | |||
| self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm) | |||
| if custom_decoder is not None: | |||
| self.decoder = custom_decoder | |||
| else: | |||
| decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout, activation, | |||
| layer_norm_eps, batch_first, norm_first, dtype=dtype) | |||
| decoder_norm = LayerNorm(d_model, eps=layer_norm_eps, dtype=dtype) | |||
| self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm) | |||
| self._reset_parameters() | |||
| self.d_model = d_model | |||
| self.nhead = nhead | |||
| self.batch_first = batch_first | |||
| def forward(self, src, tgt, src_mask=None, tgt_mask=None, memory_mask=None, src_key_padding_mask=None, | |||
| tgt_key_padding_mask=None, memory_key_padding_mask=None): | |||
| src = cast_to_ms_tensor(src) | |||
| tgt = cast_to_ms_tensor(tgt) | |||
| src_mask = cast_to_ms_tensor(src_mask) | |||
| tgt_mask = cast_to_ms_tensor(tgt_mask) | |||
| memory_mask = cast_to_ms_tensor(memory_mask) | |||
| src_key_padding_mask = cast_to_ms_tensor(src_key_padding_mask) | |||
| tgt_key_padding_mask = cast_to_ms_tensor(tgt_key_padding_mask) | |||
| memory_key_padding_mask = cast_to_ms_tensor(memory_key_padding_mask) | |||
| is_batched = src.dim() == 3 | |||
| if not self.batch_first and src.shape[1] != tgt.shape[1] and is_batched: | |||
| raise ValueError("the batch number of src and tgt must be equal") | |||
| elif self.batch_first and src.shape[0] != tgt.shape[0] and is_batched: | |||
| raise ValueError("the batch number of src and tgt must be equal") | |||
| if src.shape[-1] != self.d_model or tgt.shape[-1] != self.d_model: | |||
| raise ValueError("the feature number of src and tgt must be equal to d_model") | |||
| memory = self.encoder(src, mask=src_mask, src_key_padding_mask=src_key_padding_mask) | |||
| output = self.decoder(tgt, memory, tgt_mask=tgt_mask, memory_mask=memory_mask, | |||
| tgt_key_padding_mask=tgt_key_padding_mask, | |||
| memory_key_padding_mask=memory_key_padding_mask) | |||
| return cast_to_adapter_tensor(output) | |||
| @staticmethod | |||
| def generate_square_subsequent_mask(sz): | |||
| #TODO: replace with ms.ops.triu and ms.ops.full | |||
| # does not support ascend now | |||
| return ms.numpy.full((sz, sz), float('-inf')).triu(diagonal=1) | |||
| def _reset_parameters(self): | |||
| for p in self.parameters(): | |||
| if p.dim() > 1: | |||
| xavier_uniform_(p) | |||
| class TransformerEncoder(Module): | |||
| def __init__(self, encoder_layer, num_layers, norm=None, enable_nested_tensor=False): | |||
| unsupported_attr(enable_nested_tensor) | |||
| super(TransformerEncoder, self).__init__() | |||
| self.layers = _get_clones(encoder_layer, num_layers) | |||
| self.num_layers = num_layers | |||
| self.norm = norm | |||
| def forward(self, src, mask=None, src_key_padding_mask=None): | |||
| src = cast_to_ms_tensor(src) | |||
| mask = cast_to_ms_tensor(mask) | |||
| src_key_padding_mask = cast_to_ms_tensor(src_key_padding_mask) | |||
| if src_key_padding_mask is not None: | |||
| _skpm_dtype = src_key_padding_mask.dtype | |||
| if _skpm_dtype != ms.bool_ and not ops.is_floating_point(src_key_padding_mask): | |||
| raise AssertionError("only bool and floating types of key_padding_mask are supported") | |||
| output = src | |||
| for mod in self.layers: | |||
| output = mod(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask) | |||
| if self.norm is not None: | |||
| output = self.norm(output) | |||
| return cast_to_adapter_tensor(output) | |||
| class TransformerDecoder(Module): | |||
| def __init__(self, decoder_layer, num_layers, norm=None): | |||
| super(TransformerDecoder, self).__init__() | |||
| self.layers = _get_clones(decoder_layer, num_layers) | |||
| self.num_layers = num_layers | |||
| self.norm = norm | |||
| def forward(self, tgt, memory, tgt_mask=None, memory_mask=None, tgt_key_padding_mask=None, | |||
| memory_key_padding_mask=None): | |||
| tgt = cast_to_ms_tensor(tgt) | |||
| memory = cast_to_ms_tensor(memory) | |||
| tgt_mask = cast_to_ms_tensor(tgt_mask) | |||
| memory_mask = cast_to_ms_tensor(memory_mask) | |||
| tgt_key_padding_mask = cast_to_ms_tensor(tgt_key_padding_mask) | |||
| memory_key_padding_mask = cast_to_ms_tensor(memory_key_padding_mask) | |||
| output = tgt | |||
| for mod in self.layers: | |||
| output = mod(output, memory, tgt_mask=tgt_mask, memory_mask=memory_mask, | |||
| tgt_key_padding_mask=tgt_key_padding_mask, memory_key_padding_mask=memory_key_padding_mask) | |||
| if self.norm is not None: | |||
| output = self.norm(output) | |||
| return cast_to_adapter_tensor(output) | |||
| class TransformerEncoderLayer(Module): | |||
| def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation='relu', layer_norm_eps=1e-5, | |||
| batch_first=False, norm_first=False, device=None, dtype=None): | |||
| unsupported_attr(device) | |||
| super(TransformerEncoderLayer, self).__init__() | |||
| self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first, dtype=dtype) | |||
| # Implementation of Feedforward model | |||
| self.linear1 = Linear(d_model, dim_feedforward, dtype=dtype) | |||
| self.dropout = Dropout(dropout) | |||
| self.linear2 = Linear(dim_feedforward, d_model, dtype=dtype) | |||
| self.norm_first = norm_first | |||
| self.norm1 = LayerNorm(d_model, eps=layer_norm_eps, dtype=dtype) | |||
| self.norm2 = LayerNorm(d_model, eps=layer_norm_eps, dtype=dtype) | |||
| self.dropout1 = Dropout(dropout) | |||
| self.dropout2 = Dropout(dropout) | |||
| #TODO: other types of activation should be considered | |||
| if isinstance(activation, str): | |||
| activation = _get_activation_fn(activation) | |||
| if activation is F.relu: | |||
| self.activation_relu_or_gelu = 1 | |||
| elif activation is F.gelu: | |||
| self.activation_relu_or_gelu = 2 | |||
| else: | |||
| self.activation_relu_or_gelu = 0 | |||
| self.activation = activation | |||
| def __setstate__(self, state): | |||
| if 'activation' not in state[1]: | |||
| state[1]['activation'] = F.relu | |||
| super(TransformerEncoderLayer, self).__setstate__(state) | |||
| def forward(self, src, src_mask=None, src_key_padding_mask=None): | |||
| src = cast_to_ms_tensor(src) | |||
| src_mask = cast_to_ms_tensor(src_mask) | |||
| src_key_padding_mask = cast_to_ms_tensor(src_key_padding_mask) | |||
| if src_key_padding_mask is not None: | |||
| _skpm_dtype = src_key_padding_mask.dtype | |||
| if _skpm_dtype != ms.bool_ and not ops.is_floating_point(src_key_padding_mask): | |||
| raise AssertionError("only bool and floating types of key_padding_mask are supported") | |||
| x = src | |||
| if self.norm_first: | |||
| x = x + self._sa_block(self.norm1(x), src_mask, src_key_padding_mask) | |||
| x = x + self._ff_block(self.norm2(x)) | |||
| else: | |||
| x = self.norm1(x + self._sa_block(x, src_mask, src_key_padding_mask)) | |||
| x = self.norm2(x + self._ff_block(x)) | |||
| return cast_to_adapter_tensor(x) | |||
| # self-attention block | |||
| def _sa_block(self, x, attn_mask=None, key_padding_mask=None): | |||
| x = self.self_attn(x, x, x, attn_mask=attn_mask, key_padding_mask=key_padding_mask, need_weights=False)[0] | |||
| return self.dropout1(x) | |||
| # feed forward block | |||
| def _ff_block(self, x): | |||
| x = self.linear2(self.dropout(self.activation(self.linear1(x)))) | |||
| return self.dropout2(x) | |||
| class TransformerDecoderLayer(Module): | |||
| def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation='relu', layer_norm_eps=1e-5, | |||
| batch_first=False, norm_first=False, device=None, dtype=None): | |||
| unsupported_attr(device) | |||
| super(TransformerDecoderLayer, self).__init__() | |||
| self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first, dtype=dtype) | |||
| self.multihead_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first, dtype=dtype) | |||
| # Implementation of Feedforward model | |||
| self.linear1 = Linear(d_model, dim_feedforward, dtype=dtype) | |||
| self.dropout = Dropout(dropout) | |||
| self.linear2 = Linear(dim_feedforward, d_model, dtype=dtype) | |||
| self.norm_first = norm_first | |||
| self.norm1 = LayerNorm(d_model, eps=layer_norm_eps, dtype=dtype) | |||
| self.norm2 = LayerNorm(d_model, eps=layer_norm_eps, dtype=dtype) | |||
| self.norm3 = LayerNorm(d_model, eps=layer_norm_eps, dtype=dtype) | |||
| self.dropout1 = Dropout(dropout) | |||
| self.dropout2 = Dropout(dropout) | |||
| self.dropout3 = Dropout(dropout) | |||
| #TODO: other types of activation should be considered | |||
| # Legacy string support for activation function. | |||
| if isinstance(activation, str): | |||
| self.activation = _get_activation_fn(activation) | |||
| else: | |||
| self.activation = activation | |||
| def __setstate__(self, state): | |||
| if 'activation' not in state[1]: | |||
| state[1]['activation'] = F.relu | |||
| super(TransformerDecoderLayer, self).__setstate__(state) | |||
| def forward(self, tgt, memory, tgt_mask=None, memory_mask=None, tgt_key_padding_mask=None, | |||
| memory_key_padding_mask=None): | |||
| tgt = cast_to_ms_tensor(tgt) | |||
| memory = cast_to_ms_tensor(memory) | |||
| tgt_mask = cast_to_ms_tensor(tgt_mask) | |||
| memory_mask = cast_to_ms_tensor(memory_mask) | |||
| tgt_key_padding_mask = cast_to_ms_tensor(tgt_key_padding_mask) | |||
| memory_key_padding_mask = cast_to_ms_tensor(memory_key_padding_mask) | |||
| x = tgt | |||
| if self.norm_first: | |||
| x = x + self._sa_block(self.norm1(x), tgt_mask, tgt_key_padding_mask) | |||
| x = x + self._mha_block(self.norm2(x), memory, memory_mask, memory_key_padding_mask) | |||
| x = x + self._ff_block(self.norm3(x)) | |||
| else: | |||
| x = self.norm1(x + self._sa_block(x, tgt_mask, tgt_key_padding_mask)) | |||
| x = self.norm2(x + self._mha_block(x, memory, memory_mask, memory_key_padding_mask)) | |||
| x = self.norm3(x + self._ff_block(x)) | |||
| return cast_to_adapter_tensor(x) | |||
| # self-attention block | |||
| def _sa_block(self, x, attn_mask=None, key_padding_mask=None): | |||
| x = self.self_attn(x, x, x, attn_mask=attn_mask, key_padding_mask=key_padding_mask, need_weights=False)[0] | |||
| return self.dropout1(x) | |||
| # multihead attention block | |||
| def _mha_block(self, x, mem, attn_mask=None, key_padding_mask=None): | |||
| x = self.multihead_attn(x, mem, mem, attn_mask=attn_mask, key_padding_mask=key_padding_mask, | |||
| need_weights=False)[0] | |||
| return self.dropout2(x) | |||
| # feed forward block | |||
| def _ff_block(self, x): | |||
| x = self.linear2(self.dropout(self.activation(self.linear1(x)))) | |||
| return self.dropout3(x) | |||
| def _get_clones(module, N): | |||
| #TODO: CellList? | |||
| return ModuleList([copy.deepcopy(module) for i in range(N)]) | |||
| def _get_activation_fn(activation): | |||
| if activation == "relu": | |||
| return F.relu | |||
| elif activation == "gelu": | |||
| return F.gelu | |||
| raise RuntimeError("activation should be relu/gelu, not {}".format(activation)) | |||
ms_adapter/pytorch/nn/modules/unpooling.py → msadapter/pytorch/nn/modules/unpooling.py
View File
| @@ -1,6 +1,6 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import ms_adapter.pytorch.nn.functional as Adapter_F | |||
| import msadapter.pytorch.nn.functional as Adapter_F | |||
| from .module import Module | |||
| __all__ = ['MaxUnpool1d', 'MaxUnpool2d', 'MaxUnpool3d'] | |||
| @@ -12,6 +12,7 @@ class _MaxUnpoolNd(Module): | |||
| self.kernel_size = kernel_size | |||
| self.stride = stride if (stride is not None) else kernel_size | |||
| self.padding = padding | |||
| def extra_repr(self) -> str: | |||
| return 'kernel_size={}, stride={}, padding={}'.format( | |||
| self.kernel_size, self.stride, self.padding | |||
| @@ -22,7 +23,6 @@ class MaxUnpool1d(_MaxUnpoolNd): | |||
| return Adapter_F.max_unpool1d(input, indices, | |||
| self.kernel_size, self.stride, self.padding, output_size) | |||
| class MaxUnpool2d(_MaxUnpoolNd): | |||
| def forward(self, input, indices, output_size = None): | |||
| return Adapter_F.max_unpool2d(input, indices, | |||
ms_adapter/pytorch/nn/modules/upsampling.py → msadapter/pytorch/nn/modules/upsampling.py
View File
| @@ -1,6 +1,6 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from ms_adapter.pytorch.nn import functional as adapter_F | |||
| from msadapter.pytorch.nn import functional as adapter_F | |||
| from .module import Module | |||
| @@ -37,13 +37,15 @@ class Upsample(Module): | |||
| """ | |||
| def __init__(self, size=None, scale_factor=None, mode='bilinear', align_corners=None): | |||
| def __init__(self, size=None, scale_factor=None, mode='bilinear', align_corners=None, recompute_scale_factor=None): | |||
| super(Upsample, self).__init__() | |||
| self.name = type(self).__name__ | |||
| self.size = size | |||
| self.scale_factor = scale_factor | |||
| self.mode = mode | |||
| self.align_corners = align_corners | |||
| if recompute_scale_factor is not None: | |||
| raise ValueError("recompute_scale_factor is not supported") | |||
| def forward(self, input): | |||
| return adapter_F.interpolate( | |||
+ 126
- 0
msadapter/pytorch/nn/modules/utils.py
View File
| @@ -0,0 +1,126 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import collections | |||
| from itertools import repeat | |||
| # from functools import lru_cache | |||
| import mindspore as ms | |||
| from mindspore.ops._primitive_cache import _get_cache_prim | |||
| from mindspore.ops.primitive import _primexpr | |||
| # from msadapter.utils import unsupported_attr,_GLOBAL_LRU_CACHE_SIZE, _GLOBAL_LRU_CACHE_SIZE_NN | |||
| from msadapter.utils import unsupported_attr | |||
| def _ntuple(n, name="parse"): | |||
| def parse(x): | |||
| if isinstance(x, (list, tuple)) and len(x) == 1: | |||
| x = x[0] | |||
| if isinstance(x, collections.abc.Iterable): | |||
| return tuple(x) | |||
| return tuple(repeat(x, n)) | |||
| parse.__name__ = name | |||
| return parse | |||
| _single = _ntuple(1, "_single") | |||
| _pair = _ntuple(2, "_pair") | |||
| _triple = _ntuple(3, "_triple") | |||
| _quadruple = _ntuple(4, "_quadruple") | |||
| def _reverse_repeat_tuple(t, n): | |||
| r"""Reverse the order of `t` and repeat each element for `n` times. | |||
| This can be used to translate padding arg used by Conv and Pooling modules | |||
| to the ones used by `F.pad`. | |||
| Only support paddding like (padH, padW), not support ((padW0, padW1), (padH0, padH1)) | |||
| Example: | |||
| network-type padding: (padH, padW) | |||
| function-pad-type padding: (padW, padW, padH, padH) | |||
| """ | |||
| return tuple(x for x in reversed(t) for _ in range(n)) | |||
| def _repeat_tuple(t, n): | |||
| r"""Reverse the order of `t` and repeat each element for `n` times. | |||
| This can be used to translate padding arg used by Conv and Pooling modules | |||
| to the ones used by `F.pad`. | |||
| Only support paddding like (padH, padW), not support ((padW0, padW1), (padH0, padH1)) | |||
| Example: | |||
| network-type padding: (padH, padW) | |||
| function-pad-type padding: (padH, padH, padW, padW) | |||
| """ | |||
| return tuple(x for x in t for _ in range(n)) | |||
| @_primexpr | |||
| # @lru_cache(_GLOBAL_LRU_CACHE_SIZE) | |||
| def _is_zero_paddings(padding): | |||
| if isinstance(padding, int): | |||
| if padding == 0: | |||
| return True | |||
| elif isinstance(padding, (tuple, list)): | |||
| if not any(padding): | |||
| return True | |||
| return False | |||
| @_primexpr | |||
| # @lru_cache(_GLOBAL_LRU_CACHE_SIZE_NN) | |||
| def _expand_padding_for_padv1(network_padding, x_ndim): | |||
| r""" | |||
| use for to get expand padding for ms.ops.Pad. | |||
| `network_padding` must be type of iterable. | |||
| Example: | |||
| x_ndim = 4 | |||
| network_padding: (padW, padH) | |||
| padding_for_padv1: ((0, 0), (0, 0), (padW, padW), (padH, padH)) | |||
| network_padding: ((padW0, padW1), (padH0, padH1)) | |||
| padding_for_padv1: ((0, 0), (0, 0), (padW0, padW1), (padH0, padH1)) | |||
| """ | |||
| _pad = [] | |||
| for p in network_padding: | |||
| _pad.append(_pair(p)) | |||
| for _ in range(len(_pad), x_ndim): | |||
| _pad.insert(0, (0, 0)) | |||
| return tuple(_pad) | |||
| @_primexpr | |||
| # @lru_cache(_GLOBAL_LRU_CACHE_SIZE_NN) | |||
| def _reverse_padding(network_padding): | |||
| r""" | |||
| Reverse padding from network-type padding to functional.pad type padding. | |||
| Example: | |||
| network-type padding: (padH, padW) | |||
| function-pad-type padding: (padW, padW, padH, padH) | |||
| network-type padding: ((padH0, padH1), (padW0, padW1)) | |||
| function-pad-type padding: (padW0, padW1, padH0, padH1) | |||
| """ | |||
| _pad = () | |||
| for p in reversed(network_padding): | |||
| _pad += _pair(p) | |||
| return _pad | |||
| def _do_pad(input, network_padding, *, mode='constant', value=None): | |||
| unsupported_attr(mode) | |||
| unsupported_attr(value) | |||
| if _is_zero_paddings(network_padding): | |||
| return input | |||
| rank_op = _get_cache_prim(ms.ops.Rank)() | |||
| x_ndim = rank_op(input) | |||
| _pad = _expand_padding_for_padv1(network_padding, x_ndim) | |||
| return _get_cache_prim(ms.ops.Pad)(_pad)(input) | |||
| # TODO: switch to code below aften ms.ops.pad support on Ascend | |||
| # _pad = _reverse_padding(network_padding) | |||
| # return ms.ops.pad(input, _pad, mode, value) | |||
+ 232
- 0
msadapter/pytorch/nn/parameter.py
View File
| @@ -0,0 +1,232 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| """Parameter interface""" | |||
| import sys | |||
| import numbers | |||
| import inspect | |||
| from functools import reduce | |||
| import mindspore as ms | |||
| import mindspore._checkparam as validator | |||
| from mindspore.common import dtype as mstype | |||
| from mindspore._c_expression import Tensor as Tensor_ | |||
| from mindspore.parallel._ps_context import _is_role_worker, _clone_hash_table | |||
| from mindspore.parallel._ps_context import _insert_accumu_init_info | |||
| from msadapter.pytorch.tensor import Tensor, cast_to_ms_tensor, cast_to_adapter_tensor | |||
| __all__ = ['Parameter', 'ParameterTuple'] | |||
| def init_to_value(init): | |||
| """ | |||
| Get value of initializer. | |||
| Returns: | |||
| Value of the initializer. | |||
| Raises: | |||
| ValueError: The value of the argument 'init' is not correct. | |||
| """ | |||
| if isinstance(init, str): | |||
| if init == 'zeros': | |||
| return 0.0 | |||
| if init == 'ones': | |||
| return 1.0 | |||
| raise ValueError("The argument 'init' should be one of values in ['zeros', 'ones'].") | |||
| if isinstance(init, numbers.Number): | |||
| return float(init) | |||
| raise ValueError("The argument 'init' should be number or string, but got {}.".format(type(init))) | |||
| class Parameter(ms.Parameter): | |||
| _base_type = {} | |||
| def __new__(cls, data, *args, **kwargs): | |||
| init_data_flag = bool(isinstance(data, ms.Tensor) and data.has_init) | |||
| rc = sys.getrefcount(data) | |||
| input_class, *class_init_args = Parameter._get_parameter_new_args(data, rc) | |||
| new_type = Parameter._get_base_class(input_class) | |||
| obj = input_class.__new__(new_type) | |||
| input_class.__init__(obj, *class_init_args) | |||
| obj.init_mode = None | |||
| obj.is_default_input_init = init_data_flag | |||
| if obj.has_init: | |||
| obj.init_mode = data | |||
| return obj | |||
| def __reduce_ex__(self, _): | |||
| data = self | |||
| if self.init_mode is not None: | |||
| data = self.init_mode | |||
| else: | |||
| # cast to break deep infinite loop while deepcopy | |||
| data = ms.Tensor(self) | |||
| return ( | |||
| Parameter, (data, self.requires_grad, self.name, self.layerwise_parallel)) | |||
| def __init__(self, data, requires_grad=True, name=None, layerwise_parallel=False, parallel_optimizer=True): | |||
| super().__init__(default_input=data, name=name, requires_grad=requires_grad, | |||
| layerwise_parallel=layerwise_parallel, parallel_optimizer=parallel_optimizer) | |||
| def __deepcopy__(self, memodict): | |||
| new_obj = Parameter(self) | |||
| new_obj.name = self.name | |||
| new_obj._inited_param = self._inited_param | |||
| return new_obj | |||
| def __str__(self): | |||
| return f'Parameter containing: {Tensor_.__repr__(self.data)}, requires_grad={self.requires_grad})' | |||
| @staticmethod | |||
| def _get_base_class(input_class): | |||
| input_class_name = Parameter.__name__ | |||
| if input_class_name in Parameter._base_type: | |||
| new_type = Parameter._base_type.get(input_class_name) | |||
| else: | |||
| new_type = type(input_class_name, (Parameter, input_class), {}) | |||
| Parameter._base_type[input_class_name] = new_type | |||
| return new_type | |||
| @property | |||
| def data(self): | |||
| """Return the parameter object.""" | |||
| return self | |||
| @data.setter | |||
| def data(self, data): | |||
| ms_data = cast_to_ms_tensor(data) | |||
| self.set_data(ms_data) | |||
| def _update_tensor_data(self, data): | |||
| """Update the parameter by a Tensor.""" | |||
| if isinstance(self, ms.Tensor): | |||
| self.init_flag = False | |||
| self.init = None | |||
| return self.assign_value(data) | |||
| new_param = Parameter(data, self.name, self.requires_grad) | |||
| new_param.param_info = self.param_info | |||
| return new_param | |||
| @staticmethod | |||
| def _from_tensor(tensor, *args, **kwargs): | |||
| """Create a `Parameter` that data is shared from a `Tensor`.""" | |||
| if not isinstance(tensor, Tensor_): | |||
| raise TypeError(f"The type of input must be Tensor, but got {type(tensor)}.") | |||
| param = Tensor_.__new__(Parameter) | |||
| Tensor_.__init__(param, tensor) | |||
| param.init = None | |||
| param.init_mode = None | |||
| param.is_default_input_init = False | |||
| Parameter.__init__(param, tensor, *args, **kwargs) | |||
| return param | |||
| def requires_grad_(self, requires_grad=True): | |||
| self.requires_grad = requires_grad | |||
| def detach(self): | |||
| return cast_to_adapter_tensor(ms.Parameter.value(self)) | |||
| def numel(self): | |||
| shape = self.shape | |||
| return reduce((lambda x, y: x * y), shape) if shape else 1 | |||
| def nelement(self): | |||
| return self.numel() | |||
| def item(self): | |||
| if self.numel() > 1: | |||
| raise ValueError("only one element tensors can be converted to Python scalars") | |||
| output = self.asnumpy().reshape(-1).tolist() | |||
| return output[0] | |||
| def stride(self, dim=None): | |||
| bytelen = self.itemsize | |||
| output = list(self.strides) | |||
| for i in range(len(output)): | |||
| output[i] = output[i]//bytelen | |||
| output = tuple(output) | |||
| if dim is not None: | |||
| output = output[dim] | |||
| return output | |||
| def is_signed(self): | |||
| return self.dtype in mstype.signed_type | |||
| def is_complex(self): | |||
| return self.dtype in mstype.complex_type | |||
| def is_floating_point(self): | |||
| return self.dtype in [mstype.float32, mstype.float16, mstype.float64] | |||
| def _init_parameter_api(): | |||
| param_func = dir(Parameter) | |||
| tensor_dict = Tensor.__dict__ | |||
| for attr in tensor_dict: | |||
| if attr not in param_func: | |||
| func = inspect.getattr_static(Tensor, attr) | |||
| setattr(Parameter, attr, func) | |||
| _init_parameter_api() | |||
| class ParameterTuple(tuple): | |||
| """ | |||
| Inherited from tuple, ParameterTuple is used to save multiple parameter. | |||
| Note: | |||
| It is used to store the parameters of the network into the parameter tuple collection. | |||
| """ | |||
| def __new__(cls, iterable): | |||
| """Create instance object of ParameterTuple.""" | |||
| data = tuple(iterable) | |||
| ids = set() | |||
| names = set() | |||
| for x in data: | |||
| if not isinstance(x, Parameter): | |||
| raise TypeError(f"For ParameterTuple initialization, " | |||
| f"ParameterTuple input should be 'Parameter' collection, " | |||
| f"but got a {type(iterable)}. ") | |||
| if id(x) not in ids: | |||
| if x.name in names: | |||
| raise ValueError("The value {} , its name '{}' already exists. " | |||
| "Please set a unique name for the parameter.".format(x, x.name)) | |||
| names.add(x.name) | |||
| ids.add(id(x)) | |||
| return tuple.__new__(ParameterTuple, tuple(data)) | |||
| def clone(self, prefix, init='same'): | |||
| """ | |||
| Clone the parameters in ParameterTuple element-wisely to generate a new ParameterTuple. | |||
| Args: | |||
| prefix (str): Namespace of parameter, the prefix string will be added to the names of parameters | |||
| in parametertuple. | |||
| init (Union[Tensor, str, numbers.Number]): Clone the shape and dtype of Parameters in ParameterTuple and | |||
| set data according to `init`. Default: 'same'. | |||
| If `init` is a `Tensor` , set the new Parameter data to the input Tensor. | |||
| If `init` is `numbers.Number` , set the new Parameter data to the input number. | |||
| If `init` is a `str`, data will be seted according to the initialization method of the same name in | |||
| the `Initializer`. | |||
| If `init` is 'same', the new Parameter has the same value with the original Parameter. | |||
| Returns: | |||
| Tuple, the new Parameter tuple. | |||
| """ | |||
| validator.check_str_by_regular(prefix) | |||
| new = [] | |||
| for x in self: | |||
| x1 = x.clone(init) | |||
| x1.name = prefix + "." + x1.name | |||
| new.append(x1) | |||
| if not x1.cache_enable: | |||
| continue | |||
| if _is_role_worker(): | |||
| _clone_hash_table(x.name, x.key, x1.name, x1.key) | |||
| _insert_accumu_init_info(x1.name, init_to_value(init)) | |||
| return ParameterTuple(new) | |||
| def __parameter_tuple__(self): | |||
| """For parse check.""" | |||