100 changed files with 7024 additions and 1787 deletions
-
+1 -1.drone.yml
-
+104 -56ConstraintList.md
-
+80 -33ConstraintList_en.md
-
+73 -8Debugging_and_Tuning.md
-
+2 -2README.md
-
+1 -1README_en.md
-
+127 -54SupportedList.md
-
+129 -58SupportedList_en.md
-
+180 -138USER_GUIDE.md
-
+2 -0msadapter/pytorch/__init__.py
-
+2 -2msadapter/pytorch/_register_numpy_primitive.py
-
+3 -1msadapter/pytorch/autograd/__init__.py
-
+74 -0msadapter/pytorch/autograd/functional.py
-
+85 -0msadapter/pytorch/autograd/grad_mode.py
-
+7 -2msadapter/pytorch/common/dtype.py
-
+4 -4msadapter/pytorch/conflict_functional.py
-
+1 -0msadapter/pytorch/cuda/__init__.py
-
+4 -0msadapter/pytorch/cuda/amp/__init__.py
-
+267 -0msadapter/pytorch/cuda/amp/grad_scaler.py
-
+234 -111msadapter/pytorch/functional.py
-
+83 -3msadapter/pytorch/linalg/linalg.py
-
+47 -49msadapter/pytorch/nn/functional.py
-
+30 -53msadapter/pytorch/nn/modules/adaptive.py
-
+47 -1msadapter/pytorch/nn/modules/batchnorm.py
-
+28 -4msadapter/pytorch/nn/modules/channelshuffle.py
-
+40 -26msadapter/pytorch/nn/modules/conv.py
-
+14 -3msadapter/pytorch/nn/modules/dropout.py
-
+15 -18msadapter/pytorch/nn/modules/linear.py
-
+53 -20msadapter/pytorch/nn/modules/module.py
-
+11 -24msadapter/pytorch/nn/modules/padding.py
-
+405 -86msadapter/pytorch/nn/modules/rnn.py
-
+9 -8msadapter/pytorch/nn/modules/upsampling.py
-
+2 -13msadapter/pytorch/nn/modules/utils.py
-
+3 -1msadapter/pytorch/nn/parameter.py
-
+1 -1msadapter/pytorch/nn/utils/rnn.py
-
+6 -24msadapter/pytorch/optim/__init__.py
-
+26 -0msadapter/pytorch/optim/adam.py
-
+26 -0msadapter/pytorch/optim/adamw.py
-
+979 -0msadapter/pytorch/optim/lr_scheduler.py
-
+237 -0msadapter/pytorch/optim/optimizer.py
-
+19 -0msadapter/pytorch/optim/sgd.py
-
+26 -22msadapter/pytorch/serialization.py
-
+369 -105msadapter/pytorch/tensor.py
-
+4 -2msadapter/pytorch/utils/data/dataloader.py
-
+12 -2msadapter/pytorch/utils/data/dataset.py
-
+0 -4msadapter/pytorch/utils/data/readme.md
-
+10 -0msadapter/tools/readme.md
-
+10 -0msadapter/tools/replace_import_package.sh
-
+7 -7msadapter/torchvision/models/alexnet.py
-
+5 -5msadapter/torchvision/models/densenet.py
-
+1 -1msadapter/torchvision/models/detection/keypoint_rcnn.py
-
+2 -2msadapter/torchvision/models/detection/mask_rcnn.py
-
+12 -12msadapter/torchvision/models/detection/ssd.py
-
+2 -2msadapter/torchvision/models/googlenet.py
-
+1 -1msadapter/torchvision/models/inception.py
-
+8 -8msadapter/torchvision/models/mnasnet.py
-
+1 -1msadapter/torchvision/models/mobilenetv2.py
-
+3 -3msadapter/torchvision/models/mobilenetv3.py
-
+3 -3msadapter/torchvision/models/resnet.py
-
+1 -1msadapter/torchvision/models/segmentation/lraspp.py
-
+5 -5msadapter/torchvision/models/shufflenetv2.py
-
+6 -6msadapter/torchvision/models/squeezenet.py
-
+2 -2msadapter/torchvision/models/vgg.py
-
+9 -9msadapter/torchvision/models/video/resnet.py
-
+2 -1msadapter/torchvision/ops/roi_align.py
-
+8 -0msadapter/torchvision/transforms/transforms.py
-
+61 -1msadapter/utils.py
-
+305 -0testing/ut/pytorch/amp/test_grad_scaler.py
-
+331 -0testing/ut/pytorch/autograd/test_functional.py
-
+320 -0testing/ut/pytorch/autograd/test_grad_mode.py
-
+63 -62testing/ut/pytorch/data/test_dataloader.py
-
+119 -37testing/ut/pytorch/functional/test_activation.py
-
+22 -10testing/ut/pytorch/functional/test_arange.py
-
+20 -20testing/ut/pytorch/functional/test_cat.py
-
+1 -0testing/ut/pytorch/functional/test_cumsum.py
-
+3 -2testing/ut/pytorch/functional/test_diag.py
-
+13 -14testing/ut/pytorch/functional/test_diff.py
-
+3 -1testing/ut/pytorch/functional/test_empty.py
-
+5 -5testing/ut/pytorch/functional/test_eye.py
-
+13 -33testing/ut/pytorch/functional/test_flip.py
-
+532 -243testing/ut/pytorch/functional/test_function.py
-
+330 -69testing/ut/pytorch/functional/test_linalg.py
-
+3 -3testing/ut/pytorch/functional/test_mask.py
-
+433 -142testing/ut/pytorch/functional/test_math.py
-
+8 -14testing/ut/pytorch/functional/test_matmul.py
-
+21 -7testing/ut/pytorch/functional/test_mm.py
-
+42 -11testing/ut/pytorch/functional/test_reduction.py
-
+18 -12testing/ut/pytorch/functional/test_softmax.py
-
+15 -5testing/ut/pytorch/functional/test_stack.py
-
+14 -8testing/ut/pytorch/functional/test_zeros.py
-
+1 -1testing/ut/pytorch/nn/functional/test_avg_pooling.py
-
+5 -5testing/ut/pytorch/nn/functional/test_conv_transpose3d.py
-
+16 -16testing/ut/pytorch/nn/functional/test_dropout.py
-
+3 -2testing/ut/pytorch/nn/functional/test_functional.py
-
+61 -2testing/ut/pytorch/nn/functional/test_grid_sample.py
-
+13 -21testing/ut/pytorch/nn/functional/test_linear.py
-
+7 -13testing/ut/pytorch/nn/functional/test_normalize.py
-
+9 -11testing/ut/pytorch/nn/functional/test_one_hot.py
-
+240 -2testing/ut/pytorch/nn/functional/test_pad.py
-
+4 -6testing/ut/pytorch/nn/functional/test_pdist.py
+ 1
- 1
.drone.yml
View File
| @@ -11,7 +11,7 @@ trigger: | |||
| steps: | |||
| - name: Code Inspection | |||
| image: swr.cn-north-4.myhuaweicloud.com/hanjr/msadapter:mindspore2.0.0_torch1.12.1 | |||
| image: swr.cn-north-4.myhuaweicloud.com/hanjr/msadapter:mindspore2.1.0_0811_torch1.12.1 | |||
| commands: | |||
| - sh run.sh | |||
+ 104
- 56
ConstraintList.md
View File
| @@ -5,6 +5,7 @@ | |||
| - [Torch.nn](#jump4) | |||
| - [nn.functional](#jump5) | |||
| - [torch.linalg](#jump6) | |||
| - [torch.utils.data](#jump7) | |||
| ## <span id="jump1">接口约束列表</span> | |||
| @@ -20,49 +21,60 @@ | |||
| | torch.imag | 暂不支持图模式 | | |||
| | torch.max | 不支持other,不支持图模式 | | |||
| | torch.sum | 暂不支持图模式 | | |||
| | torch.lu | 暂不支持图模式, `get_infos=True`场景下,暂不支持错误扫描; 暂不支持`pivot=False`入参, 仅支持二维方阵输入,不支持(*,M,N)形式输入 | | |||
| | torch.lu_solve | 暂不支持图模式, 入参`left=False`暂不支持,入参`LU`仅支持二维方阵输入,不支持三维输入 | | |||
| | torch.lstsq | 暂时不支持返回第二个参数QR,暂不支持图模式,反向梯度暂不支持 | | |||
| | torch.lu | 暂不支持图模式, `get_infos=True`场景下,暂不支持错误扫描; 暂不支持`pivot=False`入参, 仅支持二维方阵输入,不支持(*, M, N)形式输入 | | |||
| | torch.lu_solve | 暂不支持图模式, 入参`left=False`暂不支持,入参`LU`仅支持二维方阵输入,不支持三维输入 | | |||
| | torch.lstsq | 暂时不支持返回第二个参数QR,暂不支持图模式,反向梯度暂不支持 | | |||
| | torch.svd | Ascend上暂不支持图模式,Ascend上反向梯度暂不支持 | | |||
| | torch.nextafter | CPU上暂不支持float32输入 | | |||
| | torch.matrix_power | GPU上暂不支持参数`n`小于0 | | |||
| | torch.i0 | Ascend上暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.i0 | Ascend上暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.index_add | 暂不支持二维以上的`input`或`dim`>=1,暂不支持图模式 | | |||
| | torch.index_copy | 暂不支持二维以上的`input`或`dim`>=1,暂不支持图模式 | | |||
| | torch.scatter_reduce | 暂不支持`reduce`="mean" | | |||
| | torch.histogramdd | 暂不支持float64类型输入 | | |||
| | torch.scatter_reduce | 暂不支持`reduce`="mean", Ascend上暂不支持`reduction='prod'`同时`dim`>0 | | |||
| | torch.asarray | 暂不支持输入`device`、 `copy`和`requires_grad`参数配置功能 | | |||
| | torch.complex | 暂不支持float16类型输入 | | |||
| | torch.fmin | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.fmin | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.kron | 暂不支持入参是不同复数类型 | | |||
| | torch.sort | 暂不支持`stable`入参 | | |||
| | torch.float_power | 不支持复数输入 | | |||
| | torch.add |暂不支持当两个输入都为bool类型时, 返回bool类型 | | |||
| | torch.polygamma | 当入参`n`为0时,结果可能不正确 | | |||
| | torch.matmul | GPU上暂不支持int类型输入 | | |||
| | torch.geqrf | 暂不支持大于2维的输入 | | |||
| | torch.repeat_interleave | 暂不支持`output_size`入参 | | |||
| | torch.index_reduce | 暂不支持`reduce`="mean" | | |||
| | torch.view_as_complex | 输出张量暂时以数据拷贝方式返回,无法提供视图模式 | | |||
| | torch.pad | 当`padding_mode`为'reflect'时,不支持5维的输入 | | |||
| | torch.pad | 当`padding_mode`为'reflect'时,不支持填充最后三维 | | |||
| | torch.corrcoef | 暂不支持复数类型入参 | | |||
| | torch.symeig | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.fmax | GPU和Ascend上暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.fft | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.rfft | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.symeig | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.fmax | GPU和Ascend上暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.fft | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.rfft | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | torch.norm | 1.当`p`为0/1/-1/-2时,矩阵范数不支持;2.不支持`p`为inf/-inf/0/1/-1/2/-2之外的int/float类型。| | |||
| | torch.poisson | Ascend上暂不支持反向梯度 | | |||
| | torch.poisson | Ascend上暂不支持反向梯度,暂不支持图模式 | | |||
| | torch.xlogy | Ascend 上当前只支持float16 和float32输入 | | |||
| | torch.digamma | Ascend上仅支持float16和float32类型入参 | | |||
| | torch.lgamma | Ascend上仅支持float16和float32类型入参 | | |||
| | torch.logspace | 暂不支持float型`base`入参,GPU上暂不支持 | | |||
| | torch.sgn | Ascend暂上不支持int16类型入参 | | |||
| | torch.mm | GPU上暂不支持int类型输入 | | |||
| | torch.inner | Ascend上暂不支持int类型输入 | | |||
| | torch.isclose | Ascend上, 暂不支持equal_nan=False | | |||
| | torch.matrix_rank | 暂不支持图模式,暂不支持复数类型输入,Ascend上不支持反向梯度 | | |||
| | torch.autograd.functional.vjp | `create_graph`, `strict`不支持 | | |||
| | torch.autograd.functional.jvp | `create_graph`, `strict`不支持 | | |||
| | torch.autograd.functional.jacobian | `create_graph`, `strict`不支持 | | |||
| | torch.inference_mode | 当前只支持相当于no_grad的功能 | | |||
| | torch.tensordot | GPU上暂不支持int类型输入 | | |||
| | torch.cuda.amp.GradScaler | 1.unscale方法需要传入对应的梯度: unscale_(optimizer, grads); 2.step方法需要传入对应的梯度: step(optimizer, grads); 3.unscale_ 方法不支持图模式 | | |||
| | torch.scatter_add | Ascend上仅支持 updates_shape = indices_shape + input_x_shape[1:]形式的入参 | | |||
| ### <span id="jump3">Tensor</span> | |||
| | MSAdapter接口 | 约束条件 | | |||
| | --------------- | -------------- | | |||
| | Tensor.bool | 不支持memory_format参数 | | |||
| | Tensor.expand | 类型限制,只支持Tensor[Float16], Tensor[Float32], Tensor[Int32], Tensor[Int8], Tensor[UInt8] | | |||
| | Tensor.float | 不支持memory_format | | |||
| | Tensor.scatter | 不支持reduce='mutiply', Ascend不支持reduce='add', 不支持indices.shape != src.shape | | |||
| | Tensor.bool | 不支持`memory_format` | | |||
| | Tensor.expand | 类型限制,只支持Tensor[Float16], Tensor[Float32], Tensor[Int32], Tensor[Int8], Tensor[UInt8] | | |||
| | Tensor.float | 不支持`memory_format` | | |||
| | Tensor.scatter | 不支持reduce='mutiply', Ascend不支持reduce='add', 不支持indices.shape != src.shape | | |||
| | Tensor.std | 不支持复数和float64输入 | | |||
| | Tensor.xlogy | Ascend 上当前只支持float16 和float32输入 | | |||
| | Tensor.abs_ | 暂不支持图模式 | | |||
| @@ -115,9 +127,9 @@ | |||
| | Tensor.logical_xor_ | 暂不支持图模式 | | |||
| | Tensor.lt_ | 暂不支持图模式 | | |||
| | Tensor.less_ | 暂不支持图模式 | | |||
| | Tensor.lu | 暂不支持图模式,入参`get_infos=True`时暂不支持扫描错误信息, 暂不支持`pivot=False`,仅支持二维方阵输入,不支持(*,M,N)形式输入 | | |||
| | Tensor.lu | 暂不支持图模式,入参`get_infos=True`时暂不支持扫描错误信息, 暂不支持`pivot=False`,仅支持二维方阵输入,不支持(*, M, N)形式输入 | | |||
| | Tensor.lu_solve | 暂不支持图模式,入参`left=False`暂不支持,入参`LU`仅支持二维方阵输入,不支持三维输入 | | |||
| | Tensor.lstsq | 暂时不支持返回第二个参数QR, 暂不支持图模式,反向梯度暂不支持 | | |||
| | Tensor.lstsq | 暂时不支持返回第二个参数QR, 暂不支持图模式,反向梯度暂不支持 | | |||
| | Tensor.mul_ | 暂不支持图模式 | | |||
| | Tensor.multiply_ | 暂不支持图模式 | | |||
| | Tensor.mvlgamma_ | 暂不支持图模式 | | |||
| @@ -151,17 +163,16 @@ | |||
| | Tensor.svd | Ascend上暂不支持图模式,Ascend上反向梯度暂不支持 | | |||
| | Tensor.nextafter | CPU上暂不支持float32输入 | | |||
| | Tensor.matrix_power | GPU上暂不支持参数`n`小于0 | | |||
| | Tensor.i0 | Ascend上暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.i0 | Ascend上暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.index_add | 暂不支持二维以上的`input`或`dim`为1 | | |||
| | Tensor.nextafter_ | CPU上暂不支持float32输入 | | |||
| | Tensor.fmin | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.fmin | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.imag | 暂不支持图模式 | | |||
| | Tensor.scatter_reduce | 暂不支持`reduce`="mean" | | |||
| | Tensor.scatter_reduce_ | 暂不支持`reduce`="mean"和图模式 | | |||
| | Tensor.scatter_reduce | 暂不支持`reduce`="mean", Ascend上暂不支持`reduction='prod'`同时`dim`>0 | | |||
| | Tensor.scatter_reduce_ | 暂不支持`reduce`="mean"和图模式, Ascend上暂不支持`reduction='prod'`同时`dim`>0 | | |||
| | Tensor.neg | 暂不支持uint32, uint64输入 | | |||
| | Tensor.add | 暂不支持当两个输入都为bool类型时, 返回bool类型 | | |||
| | Tensor.polygamma | 当入参`n`为0时,结果可能不正确 | | |||
| | Tensor.matmul | GPU上暂不支持int类型输入 | | |||
| | Tensor.geqrf | 暂不支持大于2维的输入 | | |||
| | Tensor.repeat_interleave | 暂不支持`output_size`入参 | | |||
| | Tensor.index_reduce | 暂不支持`reduce`="mean" | | |||
| @@ -170,15 +181,29 @@ | |||
| | Tensor.index_put | Ascend上暂不支持`accumulate`=False | | |||
| | Tensor.index_put_ | Ascend上暂不支持`accumulate`=False,暂不支持图模式 | | |||
| | Tensor.corrcoef | 暂不支持复数类型入参 | | |||
| | Tensor.exponential_ | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.geometric_ | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.log_normal_ | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.symeig | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.fmax | GPU和Ascend上暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.exponential_ | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.geometric_ | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.log_normal_ | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.symeig | 暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.fmax | GPU和Ascend上暂不支持反向梯度, 暂不支持图模式 | | |||
| | Tensor.norm | 1.当`p`为0/1/-1/-2时,矩阵范数不支持;2.不支持`p`为inf/-inf/0/1/-1/2/-2之外的int/float类型。| | |||
| | Tensor.digamma | Ascend上仅支持float16和float32类型入参 | | |||
| | Tensor.lgamma | Ascend上仅支持float16和float32类型入参 | | |||
| | Tensor.arcsinh_ | 暂不支持图模式 | | |||
| | Tensor.long | 不支持`memory_format` | | |||
| | Tensor.half | 不支持`memory_format` | | |||
| | Tensor.int | 不支持`memory_format` | | |||
| | Tensor.double | 不支持`memory_format` | | |||
| | Tensor.char | 不支持`memory_format` | | |||
| | Tensor.byte | 不支持`memory_format` | | |||
| | Tensor.short | 不支持`memory_format` | | |||
| | Tensor.new_full | 1.暂不支持`device`;2.暂不支持`requires_grad`;3.暂不支持`layout`;4.暂不支持`pin_memory`; | | |||
| | Tensor.new_zeros | 1.暂不支持`device`;2.暂不支持`requires_grad`; | | |||
| | Tensor.sgn | Ascend暂上不支持int16类型入参 | | |||
| | Tensor.mm | GPU上暂不支持int类型输入 | | |||
| | Tensor.inner | Ascend上暂不支持int类型输入 | | |||
| | Tensor.scatter_add | Ascend上仅支持 updates_shape = indices_shape + input_x_shape[1:]形式的入参 | | |||
| | Tensor.scatter_add_ | Ascend上仅支持 updates_shape = indices_shape + input_x_shape[1:]形式的入参,暂不支持图模式 | | |||
| ### <span id="jump4">Torch.nn</span> | |||
| | MSAdapter接口 | 约束条件 | | |||
| @@ -195,30 +220,32 @@ | |||
| | nn.RReLU | inplace不支持图模式 | | |||
| | nn.SELU | inplace不支持图模式 | | |||
| | nn.CELU | inplace不支持图模式 | | |||
| | nn.Mish | inplace不支持图模式 | | |||
| | nn.Mish | 1.`inplace`不支持图模式;2.不支持float64 | | |||
| | nn.Threshold | inplace不支持图模式 | | |||
| | nn.Softshrink | 不支持float64 | | |||
| | nn.LogSoftmax | 不支持float64,不支持8维及以上 | | |||
| | nn.Linear | device, dtype参数不支持 | | |||
| | nn.UpsamplingNearest2d | 不支持size为none | | |||
| | nn.Conv1d | 1.`padding_mode` 只支持'zeros';2.Ascend上,`groups`只支持1或者与`in_channels`相等 | | |||
| | nn.Conv2d | 1.`padding_mode` 只支持'zeros'; 2.Ascend上,`groups`只支持1或者与`in_channels`相等 | | |||
| | nn.Conv3d | 1.不支持复数;2.`padding_mode`只支持'zeros';3.Ascend上`groups`, `dialtion`参数只支持为1 | | |||
| | nn.Conv1d | Ascend上,`groups`只支持1或者与`in_channels`相等 | | |||
| | nn.Conv2d | Ascend上,`groups`只支持1或者与`in_channels`相等 | | |||
| | nn.Conv3d | 1.不支持复数;2.`padding_mode`不支持`reflect`模式;3.Ascend上`groups`, `dialtion`参数只支持为1 | | |||
| | nn.ConvTranspose1d | 1.`output_padding`,`output_size`不支持; 2.Ascend上`groups`只支持1或者与`in_channels`相等 | | |||
| | nn.ConvTranspose2d | 1.`output_padding`,`output_size`不支持; 2.Ascend上`groups`只支持1或者与`in_channels`相等 | | |||
| | nn.AdaptiveLogSoftmaxWithLoss | 不支持图模式 | | |||
| | nn.LSTM | 当前`proj_size`不支持 | | |||
| | nn.ReflectionPad1d |`padding`参数不支持负数取值 | | |||
| | nn.ReflectionPad2d | `padding`参数不支持负数取值 | | |||
| | nn.LSTM | 在图模式下,`input`不支持PackedSequence类型 | | |||
| | nn.ReflectionPad3d | `padding`参数不支持负数取值 | | |||
| | nn.Transformer | 不支持等号赋值关键字参数。不支持空tensor输入 | | |||
| | nn.TransformerEncoder | 不支持等号赋值关键字参数。不支持空tensor输入 | | |||
| | nn.TransformerDecoder | 不支持等号赋值关键字参数。不支持空tensor输入 | | |||
| | nn.TransformerEncoderLayer | 不支持等号赋值关键字参数。不支持空tensor输入 | | |||
| | nn.TransformerDecoderLayer | 不支持等号赋值关键字参数。不支持空tensor输入 | | |||
| | nn.Transformer | 不支持空tensor输入 | | |||
| | nn.TransformerEncoder | 不支持空tensor输入 | | |||
| | nn.TransformerDecoder | 不支持空tensor输入 | | |||
| | nn.TransformerEncoderLayer | 不支持空tensor输入 | | |||
| | nn.TransformerDecoderLayer | 不支持空tensor输入 | | |||
| | nn.AdaptiveMaxPool1d | Ascend上不支持`return_indices` | | |||
| | nn.AdaptiveMaxPool2d | Ascend上不支持`return_indices` | | |||
| | nn.Embedding | 1.`scale_grad_by_freq`, `sparse`不支持; 2.`norm_type`只能为2 | | |||
| | nn.Embedding | 1.`scale_grad_by_freq`, `sparse`不支持; 2.`norm_type`只能为2 | | |||
| | nn.Upsample | 不支持`recompute_scale_factor` | | |||
| | nn.RNN | 在图模式下,`input`不支持PackedSequence类型 | | |||
| | nn.GRU | 在图模式下,`input`不支持PackedSequence类型 | | |||
| | nn.CrossEntropyLoss | `target`类型为int64时,有溢出风险 | | |||
| ### <span id="jump5">nn.functional</span> | |||
| | MSAdapter接口 | 约束条件 | | |||
| @@ -232,7 +259,7 @@ | |||
| | functional.dropout1d | inplace不支持图模式 | | |||
| | functional.dropout2d | inplace不支持图模式 | | |||
| | functional.dropout3d | inplace不支持图模式 | | |||
| | functional.conv3d | Ascend上`groups`, `dialtion`参数只支持1 | | |||
| | functional.conv3d | Ascend上`groups`, `dialtion`参数只支持1 | | |||
| | functional.upsample_bilinear | 输入张量必须是4维 | | |||
| | functional.interpolate | `recompute_scale_factor` 及 `antialias` 入参不支持。 只支持以下三种模式, 其中,'nearest'只支持4D或5D输入, 'bilinear'只支持4D输入, 'linear'只支持3D输入。| | |||
| | functional.conv1d | Ascend上,`groups`只支持1或者与`input`的通道数相等 | | |||
| @@ -243,22 +270,43 @@ | |||
| | functional.adaptive_max_pool2d | Ascend上不支持`return_indices` | | |||
| | functional.instance_norm | 图模式下,训练模式时, 暂不支持`running_mean`和`running_var` | | |||
| | functional.batch_norm | 图模式下,训练模式时, 暂不支持`running_mean`及`running_var` | | |||
| | functional.embedding | 1.`scale_grad_by_freq`, `sparse`不支持; 2.`norm_type`只能为2 | | |||
| | functional.embedding | 1.`scale_grad_by_freq`, `sparse`不支持; 2.`norm_type`只能为2 | | |||
| | functional.mish | 1.`inplace`不支持图模式;2.不支持float64 | | |||
| | functional.selu | `inplace`不支持图模式 | | |||
| | functional.celu | 1.`inplace`不支持图模式;2.不支持float64 | | |||
| | functional.grid_sample | 不支持`mode='bicubic'` | | |||
| | functional.cross_entropy | `target`类型为int64时,有溢出风险 | | |||
| ### <span id="jump6">torch.linalg</span> | |||
| | MSAdapter接口 | 约束条件 | | |||
| | --------------- | -------------- | | |||
| | lu | 暂不支持图模式,暂不支持入参`pivot=False`, 仅支持二维方阵输入,不支持(*,M,N)形式输入 | | |||
| | lu | 暂不支持图模式,暂不支持入参`pivot=False`, 仅支持二维方阵输入,不支持(*, M, N)形式输入 | | |||
| | lu_solve | 暂不支持图模式,入参`left=False`不支持,入参`LU`不支持三维输入 | | |||
| | lu_factor | 暂不支持图模式,仅支持二维方阵输入,不支持(*,M,N)形式输入 | | |||
| | lu_factor_ex | 暂不支持图模式,入参`get_infos=True`时暂不支持扫描错误信息, 暂不支持`pivot=False`,仅支持二维方阵输入,不支持(*,M,N)形式输入 | | |||
| | lstsq| 暂不支持图模式,反向梯度暂不支持 | | |||
| | eigvals | 暂不支持图模式,反向梯度暂不支持 | | |||
| | svd | `driver`参数只支持None, Ascend上不支持反向梯度, Ascend上暂不支持图模式 | | |||
| | svdvals | `driver`参数只支持None,Ascend上不支持反向梯度, Ascend上暂不支持图模式 | | |||
| | norm | 暂不支持复数输入, `ord`参数暂不支持浮点型输入, Ascend上暂不支持ord为nuc模式、float(`inf`)模式和整形数输入 | | |||
| | lu_factor | 暂不支持图模式,仅支持二维方阵输入,不支持(*, M, N)形式输入 | | |||
| | lu_factor_ex | 暂不支持图模式,入参`get_infos=True`时暂不支持扫描错误信息, 暂不支持`pivot=False`,仅支持二维方阵输入,不支持(*, M, N)形式输入 | | |||
| | lstsq| 暂不支持图模式,反向梯度暂不支持 | | |||
| | eigvals | 暂不支持图模式,反向梯度暂不支持 | | |||
| | svd | `driver`参数只支持None, Ascend上不支持反向梯度, Ascend上暂不支持图模式 | | |||
| | svdvals | `driver`参数只支持None,Ascend上不支持反向梯度, Ascend上暂不支持图模式 | | |||
| | norm | 暂不支持复数输入, `ord`参数暂不支持浮点型输入, Ascend上暂不支持ord为nuc模式、float(`inf`)模式和整形数输入 | | |||
| | vector_norm | 暂不支持复数输入, `ord`参数暂不支持浮点型输入 | | |||
| | matrix_power | GPU上暂不支持参数`n`小于0 | | |||
| | eigvalsh | 反向梯度暂不支持 | | |||
| | eigh | 暂不支持图模式,反向梯度暂不支持 | | |||
| | solve | 反向梯度暂不支持 | | |||
| | eigvalsh | 暂不支持图模式,反向梯度暂不支持 | | |||
| | eigh | 暂不支持图模式,反向梯度暂不支持 | | |||
| | solve | 暂不支持图模式,反向梯度暂不支持 | | |||
| | cholesky | GPU上暂不支持int类型输入 | | |||
| | cholesky_ex | 入参`check_errors=True`时暂不支持扫描错误信息,GPU上暂不支持int类型输入 | | |||
| | inv_ex | 入参`check_errors=True`时暂不支持扫描错误信息 | | |||
| | matrix_norm | Ascend上暂不支持`ord`为nuc模式和+2/-2模式,暂不支持复数输入 | | |||
| | matrix_rank | 暂不支持图模式,暂不支持复数类型输入,Ascend上不支持反向梯度 | | |||
| | solve_triangular | Ascend上暂不支持, 暂不支持`left=False` | | |||
| | cond | 仅支持二维方阵输入,Ascend上暂不支持complex输入,float32类型输入仅支持`p=1/-1/'fro'/'inf'/'-inf'`,float64类型输入仅支持`p='fro'`;GPU和CPU上complex128类型输入仅支持`p=2/-2`, complex64类型输入仅支持`p='fro'/'nuc'` | | |||
| ### <span id="jump7">torch.utils.data</span> | |||
| | MSAdapter接口 | 约束条件 | | |||
| | --------------- |---------------------------------------------------------------------------------------------| | |||
| | DataLoader | pin_memory仅支持False,worker_init_fn不支持自定义初始化,不支持generator来控制随机状态,不支持指定pin_memory_device | | |||
| | random_split | 暂不支持传入Generator | | |||
| | RandomSampler | 暂不支持传入Generator| | |||
| | SubsetRandomSampler | 暂不支持传入Generator| | |||
| | WeightedRandomSampler | 暂不支持传入Generator| | |||
+ 80
- 33
ConstraintList_en.md
View File
| @@ -6,7 +6,7 @@ English | [简体中文](ConstraintList.md) | |||
| - [Torch.nn](#jump4) | |||
| - [nn.functional](#jump5) | |||
| - [torch.linalg](#jump6) | |||
| - [torch.utils.data](#jump7) | |||
| ## <span id="jump1">API Constraints List</span> | |||
| @@ -22,8 +22,8 @@ English | [简体中文](ConstraintList.md) | |||
| | torch.imag | Currently not support on GRAPH mode | | |||
| | torch.max | Currently not support other, Not support on GRAPH mode | | |||
| | torch.sum | Currently not support on GRAPH mode | | |||
| | torch.lu | Currently not support GRAPH mode, input `get_infos=True` currently cannot scan the error, mindspore not support `pivot=False`,, only support 2-D square matrix as input, not support (*,M,N) shape input | | |||
| | torch.lu_solve | Currently not support GRAPH mode, input `left=False` not support, only support 2-D square matrix as input, not support 3-D input | | |||
| | torch.lu | Currently not support GRAPH mode, not support gradient computation, input `get_infos=True` currently cannot scan the error, mindspore not support `pivot=False`,, only support 2-D square matrix as input, not support (*,M,N) shape input | | |||
| | torch.lu_solve | Currently not support GRAPH mode, not support gradient computation, input `left=False` not support, only support 2-D square matrix as input, not support 3-D input | | |||
| | torch.lstsq | Currently not support return the second result QR, not support on GRAPH mode, not support gradient computation | | |||
| | torch.svd | Currently not support GRAPH mode on Ascend, not support gradient computation on Ascend | | |||
| | torch.nextafter | Currently not support float32 on CPU | | |||
| @@ -31,8 +31,7 @@ English | [简体中文](ConstraintList.md) | |||
| | torch.i0 | Currently not support gradient computation on Ascend, currently not support GRAPH mode on Ascend | | |||
| | torch.index_add | Not support `input` of more than 2-D or `dim` >= 1. Not suppor GRAPH mode | | |||
| | torch.index_copy | Not support `input` of more than 2-D or `dim` >= 1. Not suppor GRAPH mode | | |||
| | torch.scatter_reduce | Currently not support `reduce`="mean" | | |||
| | torch.histogramdd | Currently not support float64 input | | |||
| | torch.scatter_reduce | Currently not support `reduce`="mean", not support `reduce`="prod" with `dim`>0 on Ascend | | |||
| | torch.asarray | Currently not support input `device`, `copy`, `requires_grad` as configuration | | |||
| | torch.complex | Currently not support float16 input | | |||
| | torch.fmin | Currently not support gradient computation, not support GRAPH mode | | |||
| @@ -41,29 +40,41 @@ English | [简体中文](ConstraintList.md) | |||
| | torch.float_power | Currently not support complex input | | |||
| | torch.add | Currently not support both bool type input and return bool output | | |||
| | torch.polygamma | When `n` is zero, the result may be wrong | | |||
| | torch.matmul | Currently not support int type input on GPU | | |||
| | torch.geqrf | Currently not support input ndim > 2 | | |||
| | torch.repeat_interleave | Currently not support `output_size` | | |||
| | torch.index_reduce | Currently not support `reduce`="mean" | | |||
| | torch.view_as_complex | Currently the output tensor is provided by data copying instead of a view of shared memory | | |||
| | torch.pad | when `padding_mode` is 'reflect', not support 5D input | | |||
| | torch.pad | when `padding_mode` is 'reflect', not support pad last 3 dimentions | | |||
| | torch.corrcoef | Currently not support complex inputs | | |||
| | torch.symeig | Currently not support gradient computation, not support GRAPH mode | | |||
| | torch.fmax | Currently not support gradient computation on GPU and Ascend, not support GRAPH mode on GPU and Ascend | | |||
| | torch.fft | Currently not support gradient computation, not support GRAPH mode | | |||
| | torch.rfft | Currently not support gradient computation, not support GRAPH mode | | |||
| | torch.poisson| Currently not support gradient computation on Ascend | | |||
| | torch.poisson| Currently not support gradient computation on Ascend, not support GRAPH mode on Ascend | | |||
| | torch.norm | 1.when `p` in 0/1/-1/-2,matrix-norm not support;2.not support `p` in int/float type beside inf/-inf/0/1/-1/2/-2 | | |||
| | torch.xlogy | Currently only support float16 and float32 on Ascend | | |||
| | torch.digamma | Currently only support float16 and float32 on Ascend | | |||
| | torch.lgamma | Currently only support float16 and float32 on Ascend | | |||
| | torch.logspace | Currently not support float type `base`. Currently only support GPU | | |||
| | torch.sgn | Currently not support int16 on Ascend | | |||
| | torch.mm | Currently not support int type input on GPU | | |||
| | torch.inner | Currently not support int type input on Ascend | | |||
| | torch.isclose | Currently not support equal_nan=False on Ascend | | |||
| | torch.matrix_rank | Currently not support complex input, not support GRAPH mode, not support gradient computation on Ascend | | |||
| | torch.autograd.functional.vjp | `create_graph`, `strict` not support | | |||
| | torch.autograd.functional.jvp | `create_graph`, `strict` not support | | |||
| | torch.autograd.functional.jacobian | `create_graph`, `strict` not support | | |||
| | torch.inference_mode | Currently equivalent to 'no_grad' | | |||
| | torch.tensordot | Currently not support int type input on GPU | | |||
| | torch.cuda.amp.GradScaler | 1.The unscale method needs to pass in the corresponding gradient: unscale_(optimizer, grads); 2.The step method needs to pass in the corresponding gradient: step(optimizer, grads); 3.The unscale_ method does not support graph mode | | |||
| | torch.scatter_add | Requires updates_shape = indices_shape + input_x_shape[1:] on Ascend | | |||
| ### <span id="jump3">Tensor</span> | |||
| | MSAdapter APIs | Constraint conditions | | |||
| | --------------- | -------------- | | |||
| | Tensor.bool | Not support parameter memory_format| | |||
| | Tensor.bool | Currently not support `memory_format` | | |||
| | Tensor.expand | Type is constrained, only support Tensor[Float16], Tensor[Float32], Tensor[Int32], Tensor[Int8], Tensor[UInt8] | | |||
| | Tensor.float | Currently not support memory_format | | |||
| | Tensor.float | Currently not support `memory_format` | | |||
| | Tensor.scatter | Currently not support reduce='mutiply', AscendNot support reduce='add', Not support indices.shape != src.shape | | |||
| | Tensor.std | Currently not support complex number and float64 input | | |||
| | Tensor.xlogy | Currently only support float16 and float32 on Ascend | | |||
| @@ -117,8 +128,8 @@ English | [简体中文](ConstraintList.md) | |||
| | Tensor.logical_xor_ | Currently not support on GRAPH mode | | |||
| | Tensor.lt_ | Currently not support on GRAPH mode | | |||
| | Tensor.less_ | Currently not support on GRAPH mode | | |||
| | Tensor.lu | Currently not support GRAPH mode, input `get_infos=True` currently cannot scan the error, not support `pivot=False`, only support 2-D square matrix as input, not support (*,M,N) shape input | | |||
| | Tensor.lu_solve | Currently not support GRAPH mode, input `left=False` not support, only support 2-D square matrix as input, not support 3-D input | | |||
| | Tensor.lu | Currently not support GRAPH mode, not support gradient computation, input `get_infos=True` currently cannot scan the error, not support `pivot=False`, only support 2-D square matrix as input, not support (*,M,N) shape input | | |||
| | Tensor.lu_solve | Currently not support GRAPH mode, not support gradient computation, input `left=False` not support, only support 2-D square matrix as input, not support 3-D input | | |||
| | Tensor.lstsq | Not support return the second result QR, not support on GRAPH mode, not support gradient computation | | |||
| | Tensor.mul_ | Currently not support on GRAPH mode | | |||
| | Tensor.multiply_ | Currently not support on GRAPH mode | | |||
| @@ -158,12 +169,11 @@ English | [简体中文](ConstraintList.md) | |||
| | Tensor.nextafter_ | Currently not support float32 on CPU | | |||
| | Tensor.fmin | Currently not support gradient computation, not support GRAPH mode | | |||
| | Tensor.imag | Currently not support on GRAPH mode | | |||
| | Tensor.scatter_reduce | Currently not support `reduce`="mean" | | |||
| | Tensor.scatter_reduce_ | Currently not support `reduce`="mean" and GRAPH mode | | |||
| | Tensor.scatter_reduce | Currently not support `reduce`="mean", not support `reduce`="prod" with `dim`>0 on Ascend | | |||
| | Tensor.scatter_reduce_ | Currently not support `reduce`="mean" and GRAPH mode, not support `reduce`="prod" with `dim`>0 on Ascend | | |||
| | Tensor.neg | Currently not support uint32, uint64 | | |||
| | Tensor.add | Currently not support both bool type input and return bool output | | |||
| | Tensor.polygamma | When `n` is zero, the result may be wrong | | |||
| | Tensor.matmul | Currently not support int type input on GPU | | |||
| | Tensor.geqrf | Currently not support input ndim > 2 | | |||
| | Tensor.repeat_interleave | Currently not support `output_size` | | |||
| | Tensor.index_reduce | Currently not support `reduce`="mean" | | |||
| @@ -181,6 +191,20 @@ English | [简体中文](ConstraintList.md) | |||
| | Tensor.digamma | Currently only support float16 and float32 on Ascend | | |||
| | Tensor.lgamma | Currently only support float16 and float32 on Ascend | | |||
| | Tensor.arcsinh_ | Currently not support on GRAPH mode | | |||
| | Tensor.long | Currently not support `memory_format` | | |||
| | Tensor.half | Currently not support `memory_format` | | |||
| | Tensor.int | Currently not support `memory_format` | | |||
| | Tensor.double | Currently not support `memory_format` | | |||
| | Tensor.char | Currently not support `memory_format` | | |||
| | Tensor.byte | Currently not support `memory_format` | | |||
| | Tensor.short | Currently not support `memory_format` | | |||
| | Tensor.new_full | 1.Currently not support `device`; 2.Currently not support `requires_grad`; 3.Currently not support `layout`; 4.Currently not support `pin_memory`; | | |||
| | Tensor.new_zeros | 1.Currently not support `device`; 2.Currently not support `requires_grad`; | | |||
| | Tensor.sgn | Currently not support int16 on Ascend | | |||
| | Tensor.mm | Currently not support int type input on GPU | | |||
| | Tensor.inner | Currently not support int type input on Ascend | | |||
| | Tensor.scatter_add | Requires updates_shape = indices_shape + input_x_shape[1:] on Ascend | | |||
| | Tensor.scatter_add_ | Requires updates_shape = indices_shape + input_shape[1:] on Ascend. Currently not supported on GPU | | |||
| ### <span id="jump4">Torch.nn</span> | |||
| | MSAdapter APIs | Constraint conditions | | |||
| @@ -197,30 +221,32 @@ English | [简体中文](ConstraintList.md) | |||
| | nn.RReLU | inplace not support GRAPH mode | | |||
| | nn.SELU | inplace not support GRAPH mode | | |||
| | nn.CELU | inplace not support GRAPH mode | | |||
| | nn.Mish | inplace not support GRAPH mode | | |||
| | nn.Mish | 1.`inplace` not support GRAPH mode; 2.Not support float64 | | |||
| | nn.Threshold | inplace not support GRAPH mode | | |||
| | nn.Softshrink | Not support float64 | | |||
| | nn.LogSoftmax | Not support float64, Not support 8D and higher dimension | | |||
| | nn.Linear | device, dtype parameter Not support | | |||
| | nn.UpsamplingNearest2d | Not support size=None | | |||
| | nn.Conv1d | 1.`padding_mode` only support 'zeros'; 2.On Ascend, `groups` can only support 1 or equal to `in_channels` | | |||
| | nn.Conv2d | 1.`padding_mode` only support 'zeros'; 2.On Ascend, `groups` can only support 1 or equal to `in_channels` | | |||
| | nn.Conv3d | 1.Not support complex number; 2. `padding_mode` only support 'zeros'; 3.`groups`,`dialtion` only support 1 on Ascend | | |||
| | nn.Conv1d | On Ascend, `groups` can only support 1 or equal to `in_channels` | | |||
| | nn.Conv2d | On Ascend, `groups` can only support 1 or equal to `in_channels` | | |||
| | nn.Conv3d | 1.Not support complex number; 2.`padding_mode` not support 'reflect'; 3.`groups`,`dialtion` only support 1 on Ascend | | |||
| | nn.ConvTranspose1d | 1.`output_padding`,`output_size` not support; 2.On Ascend, `groups` can only support 1 or equal to `in_channels` | | |||
| | nn.ConvTranspose2d | 1.`output_padding`,`output_size` not support. 2.On Ascend, `groups` can only support 1 or equal to `in_channels` | | |||
| | nn.AdaptiveLogSoftmaxWithLoss | Not support GRAPH mode | | |||
| | nn.LSTM | Currently `proj_size` not support | | |||
| | nn.ReflectionPad1d | `padding` not support negative values | | |||
| | nn.ReflectionPad2d | `padding` not support negative values | | |||
| | nn.LSTM | Under GRAPH mode, `input` not support PackedSequence type | | |||
| | nn.ReflectionPad3d | `padding` not support negative values | | |||
| | nn.Transformer | Not support assigning values to keyword arguments with `=` operator. Not support input tensors of shape 0 | | |||
| | nn.TransformerEncoder | Not support assigning values to keyword arguments with `=` operator. Not support input tensors of shape 0 | | |||
| | nn.TransformerDecoder | Not support assigning values to keyword arguments with `=` operator. Not support input tensors of shape 0 | | |||
| | nn.TransformerEncoderLayer | Not support assigning values to keyword arguments with `=` operator. Not support input tensors of shape 0 | | |||
| | nn.TransformerDecoderLayer | Not support assigning values to keyword arguments with `=` operator. Not support input tensors of shape 0 | | |||
| | nn.Transformer | Not support input tensors of shape 0 | | |||
| | nn.TransformerEncoder | Not support input tensors of shape 0 | | |||
| | nn.TransformerDecoder | Not support input tensors of shape 0 | | |||
| | nn.TransformerEncoderLayer | Not support input tensors of shape 0 | | |||
| | nn.TransformerDecoderLayer | Not support input tensors of shape 0 | | |||
| | nn.AdaptiveMaxPool1d | `return_indices` not support on Ascend | | |||
| | nn.AdaptiveMaxPool2d | `return_indices` not support on Ascend | | |||
| | nn.Embedding | 1. `scale_grad_by_freq`, `sparse` is not supported; 2. `norm_type` can only be 2 | | |||
| | nn.Upsample | Not support `recompute_scale_factor` | | |||
| | nn.RNN | Under GRAPH mode, `input` not support PackedSequence type | | |||
| | nn.GRU | Under GRAPH mode, `input` not support PackedSequence type | | |||
| | nn.CrossEntropyLoss | There is risk of overflow when `target` type is int64 | | |||
| ### <span id="jump5">nn.functional</span> | |||
| | MSAdapter APIs | Constraint conditions | | |||
| @@ -246,14 +272,19 @@ English | [简体中文](ConstraintList.md) | |||
| | functional.instance_norm | In graph mode, when training mode, `running_mean` and `running_var` are not supported | | |||
| | functional.batch_norm | In graph mode, when training mode, `running_mean` and `running_var` are not supported | | |||
| | functional.embedding | 1. 'scale_grad_by_freq', 'sparse' is not supported; 2. 'norm_type' can only be 2 | | |||
| | functional.mish | 1.`inplace` not support GRAPH mode; 2.Not support float64 | | |||
| | functional.selu | `inplace` not support GRAPH mode | | |||
| | functional.celu | 1.`inplace` not support GRAPH mode; 2.Not support float64 | | |||
| | functional.grid_sample | Not support `mode='bicubic'` | | |||
| | functional.cross_entropy | There is risk of overflow when `target` type is int64 | | |||
| ### <span id="jump6">torch.linalg</span> | |||
| | MSAdapter APIs | Constraint conditions | | |||
| | --------------- | -------------- | | |||
| | lu | Currently not support on GRAPH mode, not support `pivot=False`, only support 2-D square matrix as input, not support (*,M,N) shape input | | |||
| | lu_solve | Currently not support on GRAPH mode, input`left=False` not support, only support 2-D square matrix as input, not support 3-D input | | |||
| | lu_factor | Currently not support on GRAPH mode, only support 2-D square matrix as input, not support (*,M,N) shape input | | |||
| | lu_factor_ex | Currently not support on GRAPH mode,Input `get_infos=True` currently cannot scan the error, not support `pivot=False`, only support 2-D square matrix as input, not support (*,M,N) shape input | | |||
| | lu | Currently not support on GRAPH mode, not support gradient computation, not support `pivot=False`, only support 2-D square matrix as input, not support (*,M,N) shape input | | |||
| | lu_solve | Currently not support on GRAPH mode, not support gradient computation, input`left=False` not support, only support 2-D square matrix as input, not support 3-D input | | |||
| | lu_factor | Currently not support on GRAPH mode, not support gradient computation, only support 2-D square matrix as input, not support (*,M,N) shape input | | |||
| | lu_factor_ex | Currently not support on GRAPH mode, not support gradient computation. Input `get_infos=True` currently cannot scan the error, not support `pivot=False`, only support 2-D square matrix as input, not support (*,M,N) shape input | | |||
| | lstsq | Currently not support on GRAPH mode, not support gradient computation | | |||
| | eigvals | Currently not support GRAPH mode, not support gradient computation | | |||
| | svd | `driver` only support None as input, not support gradient computation on Ascend, currently not support GRAPH mode on Ascend | | |||
| @@ -261,6 +292,22 @@ English | [简体中文](ConstraintList.md) | |||
| | norm | Currently not support complex input, `ord` not support float input, not support ord is nuclear norm, float('inf') or int on Ascend | | |||
| | vector_norm | Currently not support complex input, `ord` not support float input | | |||
| | matrix_power | Currently not support `n` < 0 on GPU | | |||
| | eigvalsh | not support gradient computation | | |||
| | eigvalsh | Currently not support on GRAPH mode, not support gradient computation | | |||
| | eigh | Currently not support on GRAPH mode, not support gradient computation | | |||
| | solve | Currently not support gradient computation | | |||
| | solve | Currently not support on GRAPH mode, not support gradient computation | | |||
| | cholesky | Currently not support integer input on GPU | | |||
| | cholesky_ex | Input `check_errors=True` currently cannot scan the error, not support integer input on GPU | | |||
| | inv_ex | Input `check_errors=True` currently cannot scan the error | | |||
| | matrix_norm | Currently input `ord` not support +2/-2 norm and nuclear norm on Ascend, not support complex input | | |||
| | matrix_rank | Currently not support complex input, not support GRAPH mode, not support gradient computation on Ascend | | |||
| | solve_triangular | Currently not support on Ascend, not support `left=False` | | |||
| | cond | Currently only support 2-D square matrix as input,not support complex input on Ascend, float32 type input only support `p=1/-1/'fro'/'inf'/'-inf'`, float64 type input only support `p='fro'`; complex128 type input only support `p=2/-2`, complex64 type input only support `p='fro'/'nuc'` on GPU and CPU | | |||
| ### <span id="jump7">torch.utils.data</span> | |||
| | MSAdapter APIs | Constraint conditions | | |||
| | --------------- |-----------------------------------------------------------------------------------------| | |||
| | DataLoader | Currently not support input Generator, pin_memory, worker_init_fn and pin_memory_device | | |||
| | random_split | Currently not support input Generator | | |||
| | RandomSampler | Currently not support input Generator | | |||
| | SubsetRandomSampler | Currently not support input Generator | | |||
| | WeightedRandomSampler | Currently not support input Generator | | |||
+ 73
- 8
Debugging_and_Tuning.md
View File
| @@ -2,7 +2,7 @@ | |||
| ## 1.简介 | |||
| MSAdapter是一款将PyTorch训练脚本高效迁移至MindSpore框架执行的实用工具,旨在不改变原生PyTorch用户的编程使用习惯下,使得PyTorch风格代码能在昇腾硬件上获得高效性能。用户只需要将PyTorch源代码中`import torch`替换为`import msadapter.pytorch`,加上少量训练代码适配即可实现模型在昇腾硬件上的训练。 | |||
| MSAdapter是一款将PyTorch训练脚本高效迁移至MindSpore框架执行的实用工具,旨在不改变原生PyTorch用户的编程使用习惯下,使得PyTorch风格代码能在昇腾硬件上获得高效性能。用户只需要将PyTorch源代码中`torch`系列相关的包导入部分(如`torch、torchvision`等),替换为导入`msadapter.pytorch`系列相关的包(如`msadapter.pytorch、msadapter.torchvision`等),加上少量训练代码适配即可实现模型在昇腾硬件上的训练。 | |||
| 本教材旨在为开发者提供一个简明扼要的精度问题与性能问题初步定位指导。如果您还未完成模型迁移转换,可参考[MSAdapter用户使用指南](USER_GUIDE.md)。 | |||
| @@ -100,10 +100,10 @@ torch.save(net.state_dict(), 'model.pth') | |||
| Step2:将torch权重加载至MSAdapter迁移模型中 | |||
| ```python | |||
| net.load_state_dict(torch.load('model.pth',from_torch=True), strict=True) | |||
| net.load_state_dict(torch.load('model.pth'), strict=True) | |||
| ``` | |||
| 在MSAdapter迁移网络脚本中加载Step1保存的pth,同时配置`from_torch=True`,即可将torch的权重加载到迁移模型中,从而保证网络权重的一致性; | |||
| 在MSAdapter迁移网络脚本中加载Step1保存的pth,即可将torch的权重加载到迁移模型中,从而保证网络权重的一致性; | |||
| 如果输出误差过大情况,可以在PyNative模式下基于关键位置添加断点,逐步缩小范围,直至明确误差是否合理。 | |||
| @@ -121,23 +121,50 @@ import time | |||
| ... | |||
| train_data = DataLoader(train_set, batch_size=128, shuffle=True, num_workers=2, drop_last=True) | |||
| ... | |||
| from mindspore.common.api import _pynative_executor | |||
| # 数据迭代训练 | |||
| for i in range(epochs): | |||
| train_time = time.time() | |||
| for X, y in train_data: | |||
| X, y = X.to(config_args.device), y.to(config_args.device) | |||
| _pynative_executor.sync() # 调用同步接口 | |||
| date_time = time.time() | |||
| print("Data Time: ", date_time - train_time, flush=True) # 数据预处理部分耗时 | |||
| res = train_step(X, y) | |||
| print("------>epoch:{}, loss:{:.6f}".format(i, res.asnumpy())) | |||
| print("------>epoch:{}, loss:{:.6f}".format(i, res.numpy())) | |||
| _pynative_executor.sync() # 调用同步接口 | |||
| train_time = time.time() | |||
| print("Train Time: ", train_time - date_time, flush=True) # 网络执行更新部分耗时 | |||
| ``` | |||
| 与此同时,也可以查看PyTorch的 Data Time和 Train Time。(Tips:由于算子下发时间和算子执行时间是不同的,因此在记录时间之前,调用同步接口可以保证计算操作同步执行,让计时更加准确,例如 torch是调用`torch.cuda.synchronize()`,而MindSpore是调用`_pynative_executor.sync()`接口),下面代码为PyTorch代码记录Train Time和Data Time的示例。 | |||
| ```python | |||
| import time | |||
| ... | |||
| train_data = DataLoader(train_set, batch_size=128, shuffle=True, num_workers=2, drop_last=True) | |||
| ... | |||
| # 数据迭代训练 | |||
| for i in range(epochs): | |||
| train_time = time.time() | |||
| for X, y in train_data: | |||
| X, y = X.to(config_args.device), y.to(config_args.device) | |||
| torch.cuda.synchronize() # 调用同步接口 | |||
| date_time = time.time() | |||
| print("Data Time: ", date_time - train_time, flush=True) # 数据预处理部分耗时 | |||
| res = model(X) | |||
| loss = loss_func(res, y) | |||
| optimizer.zero_grad() | |||
| loss.backward() | |||
| print("------>epoch:{}, loss:{:.6f}".format(i, res.numpy())) | |||
| 一般情况下,Data Time基本可忽略不计,而Train Time基本等价于每迭代的总耗时。 | |||
| train_time = time.time() | |||
| print("Train Time: ", train_time - date_time, flush=True) # 网络执行更新部分耗时 | |||
| ``` | |||
| 正常情况下,Data Time应基本可忽略不计,如果出现了Data Time和 Train Time在相同或相邻数量级的情况,可参考[数据处理性能调优](#数据处理性能调优)来降低数据加载耗时。 | |||
| 在Data Time忽略不计的情况下,如果Train Time有明显差距,则同样需要进一步利用打点计时的方式,分析`前向`,`后向`以及`优化器`的耗时,进而定位性能问题原因。然后可参考[网络执行性能调优](#网络执行性能调优)以及[算子执行性能调优](#jumpch1)中的分析工具,查看具体算子的性能参数。 | |||
| #### 数据处理性能调优 | |||
| @@ -190,8 +217,46 @@ with open('time_log.txt', 'w+') as f: | |||
| #### <span id="jumpch1">算子执行性能调优</span> | |||
| - MindInsight工具 | |||
| [MindSpore Insight](https://mindspore.cn/mindinsight/docs/zh-CN/r2.0/performance_tuning_guide.html)是MindSpore原生框架提供的性能分析工具,从单机和集群的角度分别提供了多项指标,用于帮助用户进行性能调优。利用该工具用户可观察到硬件侧算子的执行耗时,昇腾环境可参考[性能调试(Ascend)](https://www.mindspore.cn/mindinsight/docs/zh-CN/r2.0/performance_profiling_ascend.html),GPU环境可参考[性能调试(GPU)](https://www.mindspore.cn/mindinsight/docs/zh-CN/r2.0/performance_profiling_gpu.html)。 | |||
| 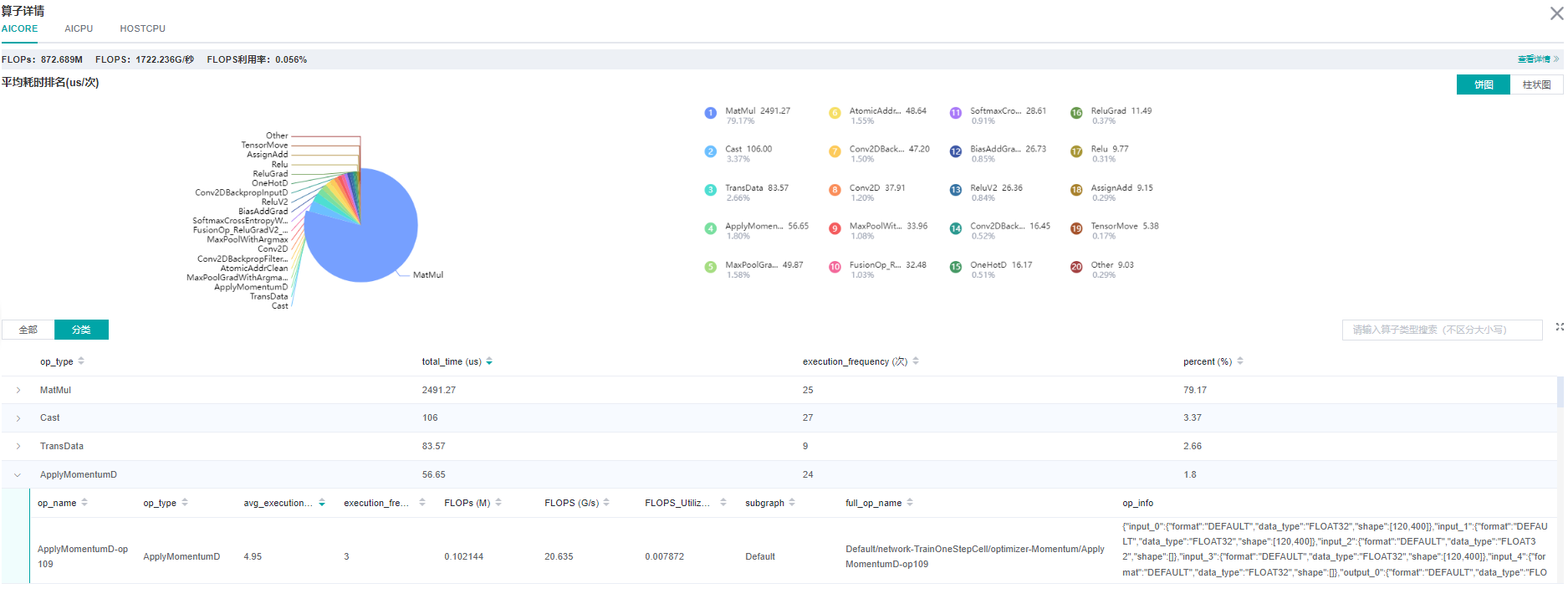 | |||
| 最终您将得到如图所示的算子性能分析看板,通过该看板可以明确算子总耗时/算子平均单次耗时/算子耗时占比等信息。 | |||
| 最终您将得到如图所示的算子性能分析看板,通过该看板可以明确算子总耗时/算子平均单次耗时/算子耗时占比等信息。 | |||
| - Runtime Profiler工具 | |||
| Runtime Profiler是MindSpore提供的一种性能调优工具,用于显示执行过程中每个step的各个模块耗时占比,快速定界性能问题。 | |||
| 使用Runtime Profiler分三步,设置环境变量、在代码中调用接口以及查看统计结果。 | |||
| 步骤 1-设置环境变量 | |||
| ```shell | |||
| export MS_ENABLE_RUNTIME_PROFILER=1 | |||
| ``` | |||
| 步骤 2-在代码中调用接口 | |||
| 在待分析程序运行的首尾调用Profiler工具接口`_framework_profiler_step_start()`,以及`_framework_profiler_step_end()`。如果您的网络脚本使用了model.train,则设置`MS_ENABLE_RUNTIME_PROFILER=1` 即可开启Profiler功能,可直接查看到[步骤 3](#profiler_step3)。 | |||
| ```python | |||
| form mindspore._c_expression import _framework_profiler_step_start | |||
| form mindspore._c_expression import _framework_profiler_step_end | |||
| for i, data in enumerate(data_loader): | |||
| if i == 0: | |||
| _framework_profiler_step_start() | |||
| """ | |||
| training | |||
| """ | |||
| if i == 20: | |||
| _framework_profiler_step_end() | |||
| exit() | |||
| ``` | |||
| 注意,使用Profiler工具需保证程序正常退出,因此在示例中的待测程序的尾部调用`exit()`函数退出。 | |||
| <span id="profiler_step3">步骤 3-查看统计结果</span> | |||
| 有两个途径可以查看Runtime Profiler的统计结果,第一种是执行代码界面直接输出; | |||
| 第二种是查看保存的名字为RuntimeProfilerSummary+当前时间戳.csv文件,此文件默认保存在当前执行目录,如果在代码中设置了`mindspore.context(save_graph_path='your path')`,则该文件将会保存在 `save_graph_path` 目录中。 | |||
+ 2
- 2
README.md
View File
| @@ -45,10 +45,10 @@ pip install msadapter | |||
| | **分支名** | **发布版本** | **发布时间** | **配套MindSpore版本** | 启智算力资源 | | |||
| |--------------|----------------|--------------------|-------------------------|------------------------------------------------| | |||
| | **release_0.1** | 0.1 | 2023-06-15 | [MindSpore 2.0.0](https://www.mindspore.cn/install) | [智算网络集群](https://openi.pcl.ac.cn/OpenI/MSAdapter/grampus/notebook/create?type=1) - 镜像:mindspore2.0rc_cann6.3_notebook | | |||
| | **release_0.1** | 0.1 | 2023-06-15 | [MindSpore 2.0.0](https://www.mindspore.cn/install) | [智算网络集群](https://openi.pcl.ac.cn/OpenI/MSAdapter/grampus/notebook/create?type=1) - 镜像:mindspore2.0.0_cann6.3_notebook | | |||
| | **release_0.1rc** | 0.1rc | 2023-04-23 | [MindSpore 2.0.0rc1](https://www.mindspore.cn/versions) | [智算网络集群](https://openi.pcl.ac.cn/OpenI/MSAdapter/grampus/notebook/create?type=1) - 镜像:mindspore2.0rc_cann6.3_notebook | | |||
| | **release_0.1beta** | 0.1beta | 2023-03-27 | [MindSpore Nightly(0205)](https://openi.pcl.ac.cn/attachments/63457dd2-5eb3-4a6b-a4e4-41b6dca8d0e9?type=0) | - | | |||
| | **master** | - | - | [MindSpore 2.0.0](https://www.mindspore.cn/install) | - | | |||
| | **master** | - | - | [MindSpore 2.1.0 8月11日及以后的版本](https://www.mindspore.cn/install) | - | | |||
| - MSAdapter已发布版本获取请参阅[RELEASE](https://openi.pcl.ac.cn/OpenI/MSAdapter/releases)。 | |||
+ 1
- 1
README_en.md
View File
| @@ -46,7 +46,7 @@ Refer to the [User Guide](USER_GUIDE.md), you will quickly get started and compl | |||
| | **release_0.1** | 0.1 | 2023-06-15 | [MindSpore 2.0.0](https://www.mindspore.cn/install/en) | [China Computing NET](https://openi.pcl.ac.cn/OpenI/MSAdapter/grampus/notebook/create?type=1) - Image:mindspore2.0rc_cann6.3_notebook | | |||
| | **release_0.1rc** | 0.1rc | 2023-04-23 | [MindSpore 2.0.0rc1](https://www.mindspore.cn/versions/en) | [China Computing NET](https://openi.pcl.ac.cn/OpenI/MSAdapter/grampus/notebook/create?type=1) - Image:mindspore2.0rc_cann6.3_notebook | | |||
| | **release_0.1beta** | 0.1beta | 2023-03-27 | [MindSpore Nightly(0205)](https://openi.pcl.ac.cn/attachments/63457dd2-5eb3-4a6b-a4e4-41b6dca8d0e9?type=0) | - | | |||
| | **master** | - | - | [MindSpore 2.0.0](https://www.mindspore.cn/install)| - | | |||
| | **master** | - | - | [MindSpore 2.1.0 August 11 and later releases](https://www.mindspore.cn/install)| - | | |||
| - For the released version of MSAdapter, please refer to [RELEASE](https://openi.pcl.ac.cn/OpenI/MSAdapter/releases). | |||
+ 127
- 54
SupportedList.md
View File
| @@ -8,6 +8,7 @@ | |||
| - [nn.functional](#jump5) | |||
| - [torch.linalg](#jump6) | |||
| - [torch.optim](#jump7) | |||
| - [torch.utils.data](#jump9) | |||
| ### <span id="jump8">通用限制</span> | |||
| @@ -16,10 +17,11 @@ | |||
| - 不支持七维及以上的计算。 | |||
| - 复数类型的支持正在完善。 | |||
| - Ascend上对float64类型的输入支持受限,部分接口无法处理float64类型入参,需转换为float32或float16类型之后输入。 | |||
| - Ascend上目前不支持输入为nan和inf的场景,如果输入包含nan或inf值,计算结果可能存在错误。 | |||
| - [PyTorch中具有视图操作的接口](https://pytorch.org/docs/1.12/tensor_view.html)功能受限,当前输入和输出张量不共享底层数据,而会进行数据拷贝。 | |||
| - 在Ascend和GPU上,部分数据类型(如int16和int32)在溢出的场景下,mindspore和pytorch处理的结果存在差异,因此不建议对具有类型限制的入参进行超出上限或下限的赋值,也不建议对明显超过数据类型的数据向范围更小的数据类型进行转换,以免获得预期之外的结果。 | |||
| - 下表中存在”功能存在限制“标注的接口,请查看[接口约束列表](ConstraintList.md),获取详细信息。 | |||
| - 优化器相关通用约束请参见[优化器统一约束](#jump10)及[lr_scheduler统一约束](#jump11) | |||
| ## <span id="jump1">MSAdapter支持API清单</span> | |||
| @@ -193,7 +195,7 @@ | |||
| | torch.prod | 支持 | | | |||
| | torch.qr | 支持 | | | |||
| | torch.std | 支持 | | | |||
| | torch.sgn | 支持 | | | |||
| | torch.sgn | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.unique_consecutive | 支持 | | | |||
| | torch.var | 支持 | | | |||
| | torch.count_nonzero | 支持 | | | |||
| @@ -246,7 +248,7 @@ | |||
| | torch.flatten | 支持 | | | |||
| | torch.flip | 支持 | | | |||
| | torch.flipud | 支持 | | | |||
| | torch.histc | 部分支持 | 暂不支持GPU后端 | | |||
| | torch.histc | 支持 | | | |||
| | torch.meshgrid | 支持 | | | |||
| | torch.ravel | 支持 | | | |||
| | torch.not_equal | 支持 | | | |||
| @@ -261,21 +263,22 @@ | |||
| | torch.bmm | 支持 | | | |||
| | torch.cholesky | 支持 | | | |||
| | torch.cholesky_inverse | 部分支持 | 暂不支持GPU后端 | | |||
| | torch.cholesky_solve | 支持 | | | |||
| | torch.dot | 支持 | | | |||
| | torch.repeat_interleave | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.addbmm | 支持 | | | |||
| | torch.det | 支持 | | | |||
| | torch.addmm | 支持 | | | |||
| | torch.matmul | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.matmul | 支持 | | | |||
| | torch.mv | 支持 | | | |||
| | torch.orgqr | 支持 | | | |||
| | torch.outer | 支持 | | | |||
| | torch.vdot | 支持 | | | |||
| | torch._assert | 支持 | | | |||
| | torch.inner | 支持 | | | |||
| | torch.inner | 支持 | | | |||
| | torch.logdet | 支持 | | | |||
| | torch.lstsq | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.mm | 支持 | | | |||
| | torch.mm | 支持 | | | |||
| | torch.cuda.is_available | 支持 | | | |||
| | torch.ByteTensor | 支持 | | | |||
| | torch.CharTensor | 支持 | | | |||
| @@ -317,7 +320,7 @@ | |||
| | torch.argsort | 支持 | | | |||
| | torch.cross | 部分支持 | 暂不支持GPU后端 | | |||
| | torch.cummax | 部分支持 | 暂不支持Ascend后端 | | |||
| | torch.einsum | 部分支持 | 仅支持GPU后端 | | |||
| | torch.einsum | 支持 | | | |||
| | torch.fliplr | 支持 | | | |||
| | torch.hamming_window | 支持 | | | |||
| | torch.svd | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| @@ -334,9 +337,9 @@ | |||
| | torch.resolve_conj | 部分支持 | 暂不支持图模式 | | |||
| | torch.index_add | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.scatter_reduce | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.scatter_add | 支持 | | | |||
| | torch.scatter_add | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.index_copy | 支持 | | | |||
| | torch.histogramdd | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.histogramdd | 支持 | | | |||
| | torch.diag_embed | 支持 | | | |||
| | torch.resolve_neg | 部分支持 | 暂不支持图模式 | | |||
| | torch.pinverse | 部分支持 | 暂不支持Ascend后端 | | |||
| @@ -355,7 +358,7 @@ | |||
| | torch.gcd | 支持 | | | |||
| | torch.histogram | 支持 | | | |||
| | torch.lcm | 支持 | | | |||
| | torch.tensordot | 支持 | | | |||
| | torch.tensordot | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.tril_indices | 支持 | | | |||
| | torch.triu_indices | 支持 | | | |||
| | torch.geqrf | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| @@ -375,12 +378,27 @@ | |||
| | torch.cumulative_trapezoid | 支持 | | | |||
| | torch.can_cast | 支持 | | | |||
| | torch.diagonal_scatter | 支持 | | | |||
| | torch.rfft | 部分支持 | [功能存在限制](ConstraintList.md) | | | |||
| | torch.rfft | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.no_grad | 部分支持 | 不支持图模式 | | |||
| | torch.nanmedian | 部分支持 | 暂不支持Ascend和GPU后端 | | |||
| | torch.narrow_copy | 支持 | | | |||
| | torch.promote_types | 支持 | | | |||
| | torch.ormqr | 部分支持 | 暂不支持Ascend和CPU后端 | | |||
| | torch.matrix_rank | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.autograd.functional.vjp | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.autograd.functional.jvp | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.autograd.functional.jacobian | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.enable_grad | 部分支持 | 不支持图模式 | | |||
| | torch.set_grad_enable | 部分支持 | 不支持图模式 | | |||
| | torch.is_grad_enable | 部分支持 | 不支持图模式 | | |||
| | torch.inference_mode | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | torch.triangular_solve | 部分支持 | 暂不支持Ascend后端 | | |||
| | torch.cuda.amp.GradScalar | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| ### <span id="jump3">Tensor</span> | |||
| | MSAdapter接口 | 状态 | 约束 | | |||
| | --------------- | -------------------- | -------------- | | |||
| | Tensor.mm | 支持 | | | |||
| | Tensor.mm | 支持 | | | |||
| | Tensor.msort | 支持 | | | |||
| | Tensor.abs | 支持 | | | |||
| | Tensor.absolute | 支持 | | | |||
| @@ -388,10 +406,10 @@ | |||
| | Tensor.acosh | 支持 | | | |||
| | Tensor.new | 支持 | | | |||
| | Tensor.new_tensor | 支持 | | | |||
| | Tensor.new_full | 支持 | | | |||
| | Tensor.new_full | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.new_empty | 支持 | | | |||
| | Tensor.new_ones | 支持 | | | |||
| | Tensor.new_zeros | 支持 | | | |||
| | Tensor.new_zeros | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.is_cuda | 支持 | | | |||
| | Tensor.ndim | 支持 | | | |||
| | Tensor.add | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| @@ -430,11 +448,12 @@ | |||
| | Tensor.bmm | 支持 | | | |||
| | Tensor.bool | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.broadcast_to | 支持 | | | |||
| | Tensor.byte | 支持 | | | |||
| | Tensor.byte | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.ceil | 支持 | | | |||
| | Tensor.char | 支持 | | | |||
| | Tensor.char | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.cholesky | 支持 | | | |||
| | Tensor.cholesky_inverse | 部分支持 | 暂不支持GPU后端 | | |||
| | Tensor.cholesky_solve | 支持 | | | |||
| | Tensor.clamp | 支持 | | | |||
| | Tensor.clip | 支持 | | | |||
| | Tensor.clone | 支持 | | | |||
| @@ -459,7 +478,7 @@ | |||
| | Tensor.dist | 支持 | | | |||
| | Tensor.divide | 支持 | | | |||
| | Tensor.dot | 支持 | | | |||
| | Tensor.double | 支持 | | | |||
| | Tensor.double | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.dsplit | 支持 | | | |||
| | Tensor.eig | 部分支持 | 暂不支持GPU后端 | | |||
| | Tensor.eq | 支持 | | | |||
| @@ -483,13 +502,13 @@ | |||
| | Tensor.greater | 支持 | | | |||
| | Tensor.greater_equal | 支持 | | | |||
| | Tensor.gt | 支持 | | | |||
| | Tensor.half | 支持 | | | |||
| | Tensor.half | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.hardshrink | 支持 | | | |||
| | Tensor.heaviside | 支持 | | | |||
| | Tensor.hsplit | 支持 | | | |||
| | Tensor.hypot | 支持 | | | |||
| | Tensor.index_select | 支持 | | | |||
| | Tensor.int | 支持 | | | |||
| | Tensor.int | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.is_complex | 支持 | | | |||
| | Tensor.isclose | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.isfinite | 支持 | | | |||
| @@ -498,7 +517,6 @@ | |||
| | Tensor.isneginf | 支持 | | | |||
| | Tensor.isposinf | 支持 | | | |||
| | Tensor.isreal | 支持 | | | |||
| | Tensor.is_tensor | 支持 | | | |||
| | Tensor.item | 支持 | | | |||
| | Tensor.le | 支持 | | | |||
| | Tensor.less | 支持 | | | |||
| @@ -513,20 +531,20 @@ | |||
| | Tensor.logical_or | 支持 | | | |||
| | Tensor.logical_xor | 支持 | | | |||
| | Tensor.logsumexp | 支持 | | | |||
| | Tensor.long | 支持 | | | |||
| | Tensor.long | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.lt | 支持 | | | |||
| | Tensor.lu | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.lu_solve | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.lstsq | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.masked_fill | 支持 | | | |||
| | Tensor.matmul | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.matmul | 支持 | | | |||
| | Tensor.max | 支持 | | | |||
| | Tensor.maximum | 支持 | | | |||
| | Tensor.mean | 支持 | | | |||
| | Tensor.min | 支持 | | | |||
| | Tensor.fmax | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.fmin | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.histc | 部分支持 | 暂不支持GPU后端 | | |||
| | Tensor.histc | 支持 | | | |||
| | Tensor.minimum | 支持 | | | |||
| | Tensor.moveaxis | 支持 | | | |||
| | Tensor.movedim | 支持 | | | |||
| @@ -536,6 +554,7 @@ | |||
| | Tensor.nanmean | 支持 | | | |||
| | Tensor.nansum | 支持 | | | |||
| | Tensor.narrow | 支持 | | | |||
| | Tensor.narrow_copy | 支持 | | | |||
| | Tensor.ndimension | 支持 | | | |||
| | Tensor.ne | 支持 | | | |||
| | Tensor.neg | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| @@ -566,7 +585,7 @@ | |||
| | Tensor.rsqrt_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.rsqrt | 支持 | | | |||
| | Tensor.select | 支持 | | | |||
| | Tensor.short | 支持 | | | |||
| | Tensor.short | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.sigmoid | 支持 | | | |||
| | Tensor.sign | 支持 | | | |||
| | Tensor.signbit | 支持 | | | |||
| @@ -733,8 +752,8 @@ | |||
| | Tensor.index_fill_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.index_add | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.index_add_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.scatter_add | 支持 | | | |||
| | Tensor.scatter_add_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.scatter_add | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.scatter_add_ | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.index_copy | 支持 | | | |||
| | Tensor.index_copy_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.diag_embed | 支持 | | | |||
| @@ -764,7 +783,7 @@ | |||
| | Tensor.igammac_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.positive | 支持 | | | |||
| | Tensor.remainder_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.sgn | 支持 | | | |||
| | Tensor.sgn | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.sgn_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.subtract_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.argmax | 支持 | | | |||
| @@ -772,7 +791,7 @@ | |||
| | Tensor.histogram | 支持 | | | |||
| | Tensor.lcm | 支持 | | | |||
| | Tensor.geqrf | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | Tensor.inner | 支持 | | | |||
| | Tensor.inner | 支持 | | | |||
| | Tensor.kthvalue | 支持 | | | |||
| | Tensor.adjoint | 支持 | | | |||
| | Tensor.angle | 支持 | | | |||
| @@ -835,6 +854,12 @@ | |||
| | Tensor.map_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.diagonal_scatter | 支持 | | | |||
| | Tensor.apply_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.nanmedian | 部分支持 | 暂不支持Ascend和GPU后端 | | |||
| | Tensor.frexp | 支持 | | | |||
| | Tensor.ormqr | 部分支持 | 暂不支持Ascend和CPU后端 | | |||
| | Tensor.detach_ | 部分支持 | 暂不支持图模式 | | |||
| | Tensor.backward | 不支持 | 请使用mindspore的微分接口ms.grad(https://www.mindspore.cn/docs/zh-CN/r2.0/api_python/mindspore/mindspore.grad.html)或者 ms.value_and_grad(https://www.mindspore.cn/docs/zh-CN/r2.0/api_python/mindspore/mindspore.value_and_grad.html) 进行求导。实际网络用法可参考mobilenet_v2例子(https://openi.pcl.ac.cn/OpenI/MSAdapterModelZoo/src/branch/master/official/cv/mobilenet_v2/mobilenet_v2_adapter.py)| | |||
| | Tensor.triangular_solve | 部分支持 | 暂不支持Ascend后端 | | |||
| ### <span id="jump4">Torch.nn</span> | |||
| | MSAdapter接口 | 状态 | 约束 | | |||
| @@ -860,8 +885,8 @@ | |||
| | nn.AdaptiveAvgPool1d | 支持 | | | |||
| | nn.AdaptiveAvgPool2d | 支持 | | | |||
| | nn.AdaptiveAvgPool3d | 支持 | | | |||
| | nn.ReflectionPad1d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.ReflectionPad2d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.ReflectionPad1d | 支持 | | | |||
| | nn.ReflectionPad2d | 支持 | | | |||
| | nn.ReflectionPad3d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.ReplicationPad1d | 支持 | | | |||
| | nn.ReplicationPad2d | 支持 | | | |||
| @@ -886,7 +911,7 @@ | |||
| | nn.GELU | 支持 | | | |||
| | nn.Sigmoid | 支持 | | | |||
| | nn.SiLU | 支持 | | | |||
| | nn.Mish | 部分支持 | inplace不支持图模式 | | |||
| | nn.Mish | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.Softplus | 支持 | | | |||
| | nn.Softshrink | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.Softsign | 支持 | | | |||
| @@ -908,7 +933,7 @@ | |||
| | nn.LayerNorm | 支持 | | | |||
| | nn.LocalResponseNorm | 支持 | | | |||
| | nn.RNNBase | 支持 | | | |||
| | nn.RNN | 支持 | | | |||
| | nn.RNN | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.RNNCell | 支持 | | | |||
| | nn.LSTMCell | 支持 | | | |||
| | nn.GRUCell | 支持 | | | |||
| @@ -926,7 +951,7 @@ | |||
| | nn.PairwiseDistance | 支持 | | | |||
| | nn.L1Loss | 支持 | | | |||
| | nn.MSELoss | 支持 | | | |||
| | nn.CrossEntropyLoss | 支持 | | | |||
| | nn.CrossEntropyLoss | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.CTCLoss | 支持 | | | |||
| | nn.NLLLoss | 支持 | | | |||
| | nn.PoissonNLLLoss | 支持 | | | |||
| @@ -943,7 +968,7 @@ | |||
| | nn.TripletMarginWithDistanceLoss | 支持 | | | |||
| | nn.PixelShuffle | 支持 | | | |||
| | nn.PixelUnshuffle | 支持 | | | |||
| | nn.Upsample | 支持 | | | |||
| | nn.Upsample | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.UpsamplingNearest2d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.UpsamplingBilinear2d | 支持 | | | |||
| | nn.ChannelShuffle | 支持 | | | |||
| @@ -977,7 +1002,7 @@ | |||
| | nn.LazyInstanceNorm2d | 不支持 | | | |||
| | nn.LazyInstanceNorm3d | 不支持 | | | |||
| | nn.LSTM | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.GRU | 支持 | | | |||
| | nn.GRU | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.Embedding | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | nn.KLDivLoss | 支持 | | | |||
| | nn.MultiLabelMarginLoss | 部分支持 | 暂不支持CPU后端 | | |||
| @@ -1028,8 +1053,8 @@ | |||
| | functional.relu6 | 支持 | | | |||
| | functional.elu | 支持 | | | |||
| | functional.elu_ | 部分支持 | 暂不支持图模式 | | |||
| | functional.selu | 支持 | | | |||
| | functional.celu | 支持 | | | |||
| | functional.selu | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.celu | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.leaky_relu | 支持 | | | |||
| | functional.leaky_relu_ | 部分支持 | 暂不支持图模式 | | |||
| | functional.prelu | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| @@ -1051,7 +1076,7 @@ | |||
| | functional.sigmoid | 支持 | | | |||
| | functional.hardsigmoid | 支持 | | | |||
| | functional.silu | 支持 | | | |||
| | functional.mish | 支持 | | | |||
| | functional.mish | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.batch_norm | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.group_norm | 支持 | | | |||
| | functional.instance_norm | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| @@ -1074,7 +1099,7 @@ | |||
| | functional.binary_cross_entropy_with_logits | 支持 | | | |||
| | functional.poisson_nll_loss | 支持 | | | |||
| | functional.cosine_embedding_loss | 支持 | | | |||
| | functional.cross_entropy | 支持 | | | |||
| | functional.cross_entropy | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.gaussian_nll_loss | 支持 | | | |||
| | functional.hinge_embedding_loss | 支持 | | | |||
| | functional.l1_loss | 支持 | | | |||
| @@ -1088,7 +1113,7 @@ | |||
| | functional.triplet_margin_with_distance_loss | 支持 | | | |||
| | functional.pixel_shuffle | 支持 | | | |||
| | functional.pixel_unshuffle | 支持 | | | |||
| | functional.grid_sample | 支持 | | | |||
| | functional.grid_sample | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.huber_loss | 支持 | | | |||
| | functional.conv1d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | functional.conv2d | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| @@ -1117,13 +1142,13 @@ | |||
| | --------------- | -------------------- | -------------- | | |||
| | norm | 部分支持 | [功能存在限制](ConstraintList.md)| | |||
| | vector_norm | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | matrix_norm | 不支持 | | | |||
| | matrix_norm | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | diagonal | 支持 | | | |||
| | det | 支持 | | | |||
| | slogdet | 支持 | | | |||
| | cond | 不支持 | | | |||
| | matrix_rank | 不支持 | | | |||
| | cholesky | 不支持 | | | |||
| | cond | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | matrix_rank | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | cholesky | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | qr | 不支持 | | | |||
| | lu | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | lu_factor | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| @@ -1136,23 +1161,23 @@ | |||
| | svd | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | svdvals | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | solve | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | solve_triangular | 不支持 | | | |||
| | solve_triangular | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | lstsq | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | inv | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | pinv | 部分支持 | 暂不支持Ascend后端 | | |||
| | qr | 支持| | | |||
| | matrix_exp | 不支持 | | | |||
| | matrix_power | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | cross | 不支持 | | | |||
| | matmul | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | cross | 部分支持 | 暂不支持GPU后端 | | |||
| | matmul | 支持 | | | |||
| | vecdot | 不支持 | | | |||
| | multi_dot | 支持 | | | |||
| | householder_product | 支持 | | | |||
| | tensorinv | 不支持 | | | |||
| | tensorsolve | 不支持 | | | |||
| | vander | 支持 | | | |||
| | cholesky_ex | 不支持 | | | |||
| | inv_ex | 不支持 | | | |||
| | cholesky_ex | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | inv_ex | 部分支持 | [功能存在限制](ConstraintList.md) | | |||
| | solve_ex | 不支持 | | | |||
| | lu_factor_ex | 不支持 | | | |||
| | ldl_factor | 不支持 | | | |||
| @@ -1160,15 +1185,19 @@ | |||
| | ldl_solve | 不支持 | | | |||
| | eigh | 支持 | | | |||
| | solve | 支持 | | | |||
| ### <span id="jump7">torch.optim</span> | |||
| <span id="jump10">优化器统一约束:</span> | |||
| - 成员变量`param_group`中的属性,PyNative下支持所有的修改,但Graph下只支持修改`lr`。 | |||
| - 以下优化器,为了兼容MindSpore Graph模式,`param_group['lr']`初始化为MindSpore的`Parameters`类型。当需要修改`param_group['lr']`时,PyNative模式下支持`param_group['lr'] = lr`的写法,但在Graph模式下,需要使用`lr = mindspore.ops.depend(lr, mindspore.ops.assign(param_group['lr'], lr)`的写法。 | |||
| - 由于上述所示,`param_group['lr']`被初始化为`Parameters`类型,所以当需要打印时,如果`param_group['lr']`为`Parameters`类型,请使用`float(param_group['lr'])`进行转换。 | |||
| - 由于微分机制差异,使用`optimizer.step()`时,需要使用`optimizer.step(grads)`进行替换, 其中`grad`可由`mindspore.grad`或者`mindspore.value_and_grad`获取。 | |||
| | MSAdapter接口 | 状态 | 约束 | | |||
| | --------------- | -------------------- | -------------- | | |||
| | Optimizer | 不支持 | 请使用[mindspore.nn.Optimizer](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.Optimizer.html?highlight=optimizer#mindspore.nn.Optimizer)代替| | |||
| | Optimizer | 支持 | | | |||
| | Adadelta | 不支持 | 请使用[mindspore.nn.Adadelta](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.Adadelta.html?highlight=adadelta#mindspore.nn.Adadelta)代替| | |||
| | Adagrad | 不支持 | 请使用[mindspore.nn.Adagrad](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.Adagrad.html?highlight=adagrad#mindspore.nn.Adagrad)代替| | |||
| | Adam | 不支持 | 请使用[mindspore.nn.Adam](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.Adam.html?highlight=adam#mindspore.nn.Adam)代替| | |||
| | AdamW | 不支持 | 请使用[mindspore.nn.AdamWeightDecay](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.AdamWeightDecay.html?highlight=adamw#mindspore.nn.AdamWeightDecay)代替| | |||
| | Adam | 支持 | | | |||
| | AdamW | 支持 | | | |||
| | SparseAdam | 不支持 | | | |||
| | Adamax | 不支持 | 请使用[mindspore.nn.AdaMax](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.AdaMax.html?highlight=adamax#mindspore.nn.AdaMax)代替| | |||
| | ASGD | 不支持 | 请使用[mindspore.nn.ASGD](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.ASGD.html?highlight=asgd#mindspore.nn.ASGD)代替| | |||
| @@ -1177,5 +1206,49 @@ | |||
| | RAdam | 不支持 | | | |||
| | RMSprop | 不支持 | 请使用[mindspore.nn.RMSprop](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.RMSProp.html?highlight=rmsprop#mindspore.nn.RMSProp)代替| | |||
| | Rprop | 不支持 | 请使用[mindspore.nn.Rprop](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.Rprop.html?highlight=rprop#mindspore.nn.Rprop)代替 | | |||
| | SGD | 不支持 | 请使用[mindspore.nn.SGD](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.SGD.html?highlight=sgd#mindspore.nn.SGD)代替| | |||
| | SGD | 支持 | | | |||
| <span id="jump11">lr_scheduler统一约束:</span> | |||
| - 由于优化器的`lr`存在类型为`Parameter`的情况,所以lr_scheduler的`base_lr`及`_last_lr`可能也为`Parameter`类型。因此当需要保存或者恢复以上变量时,需要预先对其类型进行转换,才能正常保存或恢复。比如,在保存时,`state_dict`函数中,`return state_dict`应该改为`return self._process_state_dict(state_dict)`, 其中`_process_state_dict`是父类`LRScheduler`中定义的公共函数,可以将对应变量从`Parameter`类型转换为Python的数值类型。同理,恢复时可调用父类中的`_process_state_dict_revert`恢复到`Parameter`类型。 | |||
| | MSAdapter接口 | 状态 | 约束 | | |||
| | --------------- | -------------------- | -------------- | | |||
| | lr_scheduler.LRScheduler | 支持 | | | |||
| | lr_scheduler._LRScheduler | 支持 | | | |||
| | lr_scheduler.LambdaLR | 支持 | | | |||
| | lr_scheduler.MultiplicativeLR | 支持 | | | |||
| | lr_scheduler.StepLR | 支持 | | | |||
| | lr_scheduler.MultiStepLR | 支持 | | | |||
| | lr_scheduler.ConstantLR | 支持 | | | |||
| | lr_scheduler.LinearLR | 支持 | | | |||
| | lr_scheduler.ExponentialLR | 支持 | | | |||
| | lr_scheduler.PolynomialLR | 支持 | | | |||
| | lr_scheduler.CosineAnnealingLR | 支持 | | | |||
| | lr_scheduler.ChainedScheduler | 支持 | | | |||
| | lr_scheduler.SequentialLR | 支持 | | | |||
| | lr_scheduler.ReduceLROnPlateau | 支持 | | | |||
| | lr_scheduler.CyclicLR | 支持 | | | |||
| | lr_scheduler.OneCycleLR | 支持 | | | |||
| | lr_scheduler.CosineAnnealingWarmRestarts | 支持 | | | |||
| ### <span id="jump9">torch.utils.data</span> | |||
| | MSAdapter接口 | 状态 | 约束 | | |||
| | --------------- | ---- |------------------------------| | |||
| | DataLoader | 支持 | [功能存在限制](ConstraintList.md) | | |||
| | Dataset | 支持 | | | |||
| | IterableDataset | 支持 | | | |||
| | TensorDataset | 支持 | | | |||
| | ConcatDataset | 支持 | | | |||
| | ChainDataset | 支持 | | | |||
| | Subset | 支持 | | | |||
| | default_collate | 支持 | | | |||
| | default_convert | 支持 | | | |||
| | get_worker_info | 支持 | | | |||
| | random_split | 支持 | [功能存在限制](ConstraintList.md) | | |||
| | Sampler | 支持 | | | |||
| | SequentialSampler | 支持 | | | |||
| | RandomSampler | 支持 |[功能存在限制](ConstraintList.md)| | |||
| | SubsetRandomSampler | 支持 |[功能存在限制](ConstraintList.md)| | |||
| | WeightedRandomSampler | 支持 |[功能存在限制](ConstraintList.md)| | |||
| | BatchSampler | 支持 | | | |||
| | distributed.DistributedSampler | 支持 | | | |||
+ 129
- 58
SupportedList_en.md
View File
| @@ -7,18 +7,19 @@ English | [简体中文](SupportedList.md) | |||
| - [nn.functional](#jump5) | |||
| - [torch.linalg](#jump6) | |||
| - [torch.optim](#jump7) | |||
| - [torch.utils.data](#jump9) | |||
| ### <span id="jump8">General Constraint</span> | |||
| - Not support the function of configuration `layout`, `device`, `requires_grad`, `memory_format`. | |||
| - Not support `Generator` that manages the state of the algorithm which produces pseudo random numbers. | |||
| - Not support 7D and higher dimensions calculations. | |||
| - The Complex type function is being improved. | |||
| - Ascend not fully support float64 type value as input, if the function is not applicable for float64, please try float32 and float16 instead. | |||
| - Ascend not fully support float64 type value as input, if the function is not applicable for float64, please try float32 and float16 instead. | |||
| - Currently, inputs of nan and inf are not supported on Ascend. If the input contains nan or inf values, the results may be incorrect. | |||
| - The function of [PyTorch APIs that support tensor to be a view](https://pytorch.org/docs/1.12/tensor_view.html) is constrained. Currently MSAdapter does not support sharing memory between the input and output tensor, but copying the data. | |||
| - On Ascend and GPU, there are differences between mindspore and pytorch in the processing overflow results, such as the upper limits of int16 and int32. Therefore, it is not recommended to assign input parameters exceed the upper or lower limits, or to convert data that significantly exceeds the data type to a smaller range of data types to avoid unexpected results. | |||
| - For the function with note "Function is constrained", please check the [APIs Constraints List](ConstraintList_en.md) for more details. | |||
| - For general constraints related to optimizers, see [Optimizer General Constraints](#jump10) and [lr_scheduler General Constraints](#jump11) | |||
| ## <span id="jump1">List of PyTorch APIs supported by MSAdapter</span> | |||
| @@ -193,7 +194,7 @@ English | [简体中文](SupportedList.md) | |||
| | torch.prod | Supported | | | |||
| | torch.qr | Supported | | | |||
| | torch.std | Supported | | | |||
| | torch.sgn | Supported | | | |||
| | torch.sgn | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.unique_consecutive | Supported | | | |||
| | torch.var | Supported | | | |||
| | torch.count_nonzero | Supported | | | |||
| @@ -246,7 +247,7 @@ English | [简体中文](SupportedList.md) | |||
| | torch.flatten | Supported | | | |||
| | torch.flip | Supported | | | |||
| | torch.flipud | Supported | | | |||
| | torch.histc | Partly supported | Currently not support on GPU | | |||
| | torch.histc | Supported | | | |||
| | torch.meshgrid | Supported | | | |||
| | torch.ravel | Supported | | | |||
| | torch.not_equal | Supported | | | |||
| @@ -261,12 +262,13 @@ English | [简体中文](SupportedList.md) | |||
| | torch.bmm | Supported | | | |||
| | torch.cholesky | Supported | | | |||
| | torch.cholesky_inverse | Partly supported | Currently not support on GPU | | |||
| | torch.cholesky_solve | Supported | | | |||
| | torch.dot | Supported | | | |||
| | torch.repeat_interleave | Partly Supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.addbmm | Supported | | | |||
| | torch.det | Supported | | | |||
| | torch.addmm | Supported | | | |||
| | torch.matmul | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.matmul | Supported | | | |||
| | torch.mv | Supported | | | |||
| | torch.orgqr | Supported | | | |||
| | torch.outer | Supported | | | |||
| @@ -275,7 +277,7 @@ English | [简体中文](SupportedList.md) | |||
| | torch.inner | Supported | | | |||
| | torch.logdet | Supported | | | |||
| | torch.lstsq | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.mm | Supported | | | |||
| | torch.mm | Supported | | | |||
| | torch.cuda.is_available | Supported | | | |||
| | torch.ByteTensor | Supported | | | |||
| | torch.CharTensor | Supported | | | |||
| @@ -317,12 +319,12 @@ English | [简体中文](SupportedList.md) | |||
| | torch.argsort | Supported | | | |||
| | torch.cross | Partly supported | Currently not support on GPU | | |||
| | torch.cummax | Partly supported | Currently not support on Ascend | | |||
| | torch.einsum | Partly supported | Only support on GPU | | |||
| | torch.einsum | Supported | | | |||
| | torch.fliplr | Supported | | | |||
| | torch.hamming_window | Supported | | | |||
| | torch.svd | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.searchsorted | Supported | | | |||
| | torch.fmax | Partly supported | Only support on CPU | | |||
| | torch.fmax | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.fmin | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.inverse | Partly supported | Currently not support on Ascend | | |||
| | torch.poisson | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| @@ -335,9 +337,9 @@ English | [简体中文](SupportedList.md) | |||
| | torch.resolve_conj | Partly supported | Currently not support on GRAPH mode | | |||
| | torch.index_add | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.scatter_reduce | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.scatter_add | Supported | | | |||
| | torch.scatter_add | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.index_copy | Supported | | | |||
| | torch.histogramdd | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.histogramdd | Supported | | | |||
| | torch.diag_embed | Supported | | | |||
| | torch.resolve_neg | Partly supported | Currently not support on GRAPH mode | | |||
| | torch.pinverse | Partly supported | Currently not support on Ascend | | |||
| @@ -356,7 +358,7 @@ English | [简体中文](SupportedList.md) | |||
| | torch.gcd | Supported | | | |||
| | torch.histogram | Supported | | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.lcm | Supported | | | |||
| | torch.tensordot | Supported | | | |||
| | torch.tensordot | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.tril_indices | Supported | | | |||
| | torch.triu_indices | Supported | | | |||
| | torch.geqrf | Partly Supported | [Function is constrained](ConstraintList_en.md) | | |||
| @@ -376,12 +378,26 @@ English | [简体中文](SupportedList.md) | |||
| | torch.cumulative_trapezoid | Supported | | | |||
| | torch.can_cast | Supported | | | |||
| | torch.diagonal_scatter | Supported | | | |||
| | torch.rfft | Partly supported | [Function is constrained](ConstraintList_en.md) | | | |||
| | torch.rfft | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.no_grad | Partly supported | Currently not support on GRAPH mode | | |||
| | torch.nanmedian | Partly supported | Currently not support on GPU or Ascend | | |||
| | torch.narrow_copy | Supported | | | |||
| | torch.promote_types | Supported | | | |||
| | torch.matrix_rank | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | torch.autograd.functional.vjp | Partly supported | [Function is constrained](ConstraintList.md) | | |||
| | torch.autograd.functional.jvp | Partly supported | [Function is constrained](ConstraintList.md) | | |||
| | torch.autograd.functional.jacobian | Partly supported | [Function is constrained](ConstraintList.md) | | |||
| | torch.enable_grad | Partly supported | Currently not support on GRAPH mode | | |||
| | torch.set_grad_enable | Partly supported | Currently not support on GRAPH mode | | |||
| | torch.is_grad_enable | Partly supported | Currently not support on GRAPH mode | | |||
| | torch.inference_mode | Partly supported | [Function is constrained](ConstraintList.md) | | |||
| | torch.triangular_solve | Partly supported | Currently not support on Ascend | | |||
| | torch.cuda.amp.GradScalar | Partly supported | [Function is constrained](ConstraintList.md) | | |||
| ### <span id="jump3">Tensor</span> | |||
| | MSAdapter APIs | Status | Restrictions | | |||
| | --------------- | -------------------- | -------------- | | |||
| | Tensor.mm | Supported | | | |||
| | Tensor.mm | Supported | | | |||
| | Tensor.msort | Supported | | | |||
| | Tensor.abs | Supported | | | |||
| | Tensor.absolute | Supported | | | |||
| @@ -389,10 +405,10 @@ English | [简体中文](SupportedList.md) | |||
| | Tensor.acosh | Supported | | | |||
| | Tensor.new | Supported | | | |||
| | Tensor.new_tensor | Supported | | | |||
| | Tensor.new_full | Supported | | | |||
| | Tensor.new_full | Partly Supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.new_empty | Supported | | | |||
| | Tensor.new_ones | Supported | | | |||
| | Tensor.new_zeros | Supported | | | |||
| | Tensor.new_zeros | Partly Supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.is_cuda | Supported | | | |||
| | Tensor.ndim | Supported | | | |||
| | Tensor.add | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| @@ -431,11 +447,12 @@ English | [简体中文](SupportedList.md) | |||
| | Tensor.bmm | Supported | | | |||
| | Tensor.bool | Partly supported | [Function is constrained](ConstraintList_en.md)| | |||
| | Tensor.broadcast_to | Supported | | | |||
| | Tensor.byte | Supported | | | |||
| | Tensor.byte | Partly supported | [Function is constrained](ConstraintList_en.md)| | |||
| | Tensor.ceil | Supported | | | |||
| | Tensor.char | Supported | | | |||
| | Tensor.char | Partly supported | [Function is constrained](ConstraintList_en.md)| | |||
| | Tensor.cholesky | Supported | | | |||
| | Tensor.cholesky_inverse | Partly supported | Currently not support on GPU | | |||
| | Tensor.cholesky_solve | Supported | | | |||
| | Tensor.clamp | Supported | | | |||
| | Tensor.clip | Supported | | | |||
| | Tensor.clone | Supported | | | |||
| @@ -460,7 +477,7 @@ English | [简体中文](SupportedList.md) | |||
| | Tensor.dist | Supported | | | |||
| | Tensor.divide | Supported | | | |||
| | Tensor.dot | Supported | | | |||
| | Tensor.double | Supported | | | |||
| | Tensor.double | Partly supported | [Function is constrained](ConstraintList_en.md)| | |||
| | Tensor.dsplit | Supported | | | |||
| | Tensor.eig | Partly supported | Currently not support on GPU | | |||
| | Tensor.eq | Supported | | | |||
| @@ -484,13 +501,13 @@ English | [简体中文](SupportedList.md) | |||
| | Tensor.greater | Supported | | | |||
| | Tensor.greater_equal | Supported | | | |||
| | Tensor.gt | Supported | | | |||
| | Tensor.half | Supported | | | |||
| | Tensor.half | Partly supported | [Function is constrained](ConstraintList_en.md)| | |||
| | Tensor.hardshrink | Supported | | | |||
| | Tensor.heaviside | Supported | | | |||
| | Tensor.hsplit | Supported | | | |||
| | Tensor.hypot | Supported | | | |||
| | Tensor.index_select | Supported | | | |||
| | Tensor.int | Supported | | | |||
| | Tensor.int | Partly supported | [Function is constrained](ConstraintList_en.md)| | |||
| | Tensor.is_complex | Supported | | | |||
| | Tensor.isclose | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.isfinite | Supported | | | |||
| @@ -499,7 +516,6 @@ English | [简体中文](SupportedList.md) | |||
| | Tensor.isneginf | Supported | | | |||
| | Tensor.isposinf | Supported | | | |||
| | Tensor.isreal | Supported | | | |||
| | Tensor.is_tensor | Supported | | | |||
| | Tensor.item | Supported | | | |||
| | Tensor.le | Supported | | | |||
| | Tensor.less | Supported | | | |||
| @@ -514,20 +530,20 @@ English | [简体中文](SupportedList.md) | |||
| | Tensor.logical_or | Supported | | | |||
| | Tensor.logical_xor | Supported | | | |||
| | Tensor.logsumexp | Supported | | | |||
| | Tensor.long | Supported | | | |||
| | Tensor.long | Partly supported | [Function is constrained](ConstraintList_en.md)| | |||
| | Tensor.lt | Supported | | | |||
| | Tensor.lu | Partly supported | Currently not support on Ascend | | |||
| | Tensor.lu_solve | Partly supported | Currently not support on Ascend | | |||
| | Tensor.lstsq | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.masked_fill | Supported | | | |||
| | Tensor.matmul | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.matmul | Supported | | | |||
| | Tensor.max | Supported | | | |||
| | Tensor.maximum | Supported | | | |||
| | Tensor.mean | Supported | | | |||
| | Tensor.min | Supported | | | |||
| | Tensor.fmax | Partly supported | Only support on CPU | | |||
| | Tensor.fmax | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.fmin | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.histc | Partly supported | Currently not support on GPU | | |||
| | Tensor.histc | Supported | | | |||
| | Tensor.minimum | Supported | | | |||
| | Tensor.moveaxis | Supported | | | |||
| | Tensor.movedim | Supported | | | |||
| @@ -537,6 +553,7 @@ English | [简体中文](SupportedList.md) | |||
| | Tensor.nanmean | Supported | | | |||
| | Tensor.nansum | Supported | | | |||
| | Tensor.narrow | Supported | | | |||
| | Tensor.narrow_copy | Supported | | | |||
| | Tensor.ndimension | Supported | | | |||
| | Tensor.ne | Supported | | | |||
| | Tensor.neg | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| @@ -567,7 +584,7 @@ English | [简体中文](SupportedList.md) | |||
| | Tensor.rsqrt_ | Partly supported | Not support the GRAPH mode | | |||
| | Tensor.rsqrt | Supported | | | |||
| | Tensor.select | Supported | | | |||
| | Tensor.short | Supported | | | |||
| | Tensor.short | Partly supported | [Function is constrained](ConstraintList_en.md)| | |||
| | Tensor.sigmoid | Supported | | | |||
| | Tensor.sign | Supported | | | |||
| | Tensor.signbit | Supported | | | |||
| @@ -734,8 +751,8 @@ English | [简体中文](SupportedList.md) | |||
| | Tensor.index_fill_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.index_add | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.index_add_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.scatter_add | Supported | | | |||
| | Tensor.scatter_add_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.scatter_add | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.scatter_add_ | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.index_copy | Supported | | | |||
| | Tensor.index_copy_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.diag_embed | Supported | | | |||
| @@ -764,7 +781,7 @@ English | [简体中文](SupportedList.md) | |||
| | Tensor.igammac_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.positive | Supported | | | |||
| | Tensor.remainder_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.sgn | Supported | | | |||
| | Tensor.sgn | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.sgn_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.subtract_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.argmax | Supported | | | |||
| @@ -772,7 +789,7 @@ English | [简体中文](SupportedList.md) | |||
| | Tensor.histogram | Supported | | | |||
| | Tensor.lcm | Supported | | | |||
| | Tensor.geqrf | Partly Supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Tensor.inner | Supported | | | |||
| | Tensor.inner | Supported | | | |||
| | Tensor.kthvalue | Supported | | | |||
| | Tensor.adjoint | Supported | | | |||
| | Tensor.angle | Supported | | | |||
| @@ -836,6 +853,11 @@ English | [简体中文](SupportedList.md) | |||
| | Tensor.map_ | Partly supported | Currently not support on GRAPH mode | | |||
| | Tensor.diagonal_scatter | Supported | | | |||
| | Tensor.apply_ | Partly Supported | Currently not support on GRAPH mode | | |||
| | Tensor.nanmedian | Partly supported | Currently not support on GPU or Ascend | | |||
| | Tensor.frexp | Supported | | | |||
| | Tensor.detach_ | Partly Supported | Currently not support on GRAPH mode | | |||
| | Tensor.backward | Not supported | For derivation, use mindspore's differential interface ms.grad(https://www.mindspore.cn/docs/en/r2.0/api_python/mindspore/mindspore.grad.html) or ms.value_and_grad(https://www.mindspore.cn/docs/en/r2.0/api_python/mindspore/mindspore.value_and_grad.html). For actual network usage, please refer to mobilenet_v2 Examples (https://openi.pcl.ac.cn/OpenI/MSAdapterModelZoo/src/branch/master/official/cv/mobilenet_v2/mobilenet_v2_adapter.py) | | |||
| | Tensor.triangular_solve | Partly supported | Currently not support on Ascend | | |||
| ### <span id="jump4">Torch.nn</span> | |||
| | MSAdapter APIs | Status | Restrictions | | |||
| @@ -861,8 +883,8 @@ English | [简体中文](SupportedList.md) | |||
| | nn.AdaptiveAvgPool1d | Supported | | | |||
| | nn.AdaptiveAvgPool2d | Supported | | | |||
| | nn.AdaptiveAvgPool3d | Supported | | | |||
| | nn.ReflectionPad1d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.ReflectionPad2d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.ReflectionPad1d | Supported | | | |||
| | nn.ReflectionPad2d | Supported | | | |||
| | nn.ReflectionPad3d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.ReplicationPad1d | Supported | | | |||
| | nn.ReplicationPad2d | Supported | | | |||
| @@ -882,12 +904,12 @@ English | [简体中文](SupportedList.md) | |||
| | nn.ReLU | Supported | | | |||
| | nn.ReLU6 | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.RReLU | Partly supported | inplace not support on GRAPH mode | | |||
| | nn.SELU | Partly supported | inplace not support on GRAPH mode | | |||
| | nn.CELU | Partly supported | inplace not support on GRAPH mode | | |||
| | nn.SELU | Partly supported | inplace not support on GRAPH mode | | |||
| | nn.CELU | Partly supported | inplace not support on GRAPH mode | | |||
| | nn.GELU | Supported | | | |||
| | nn.Sigmoid | Supported | | | |||
| | nn.SiLU | Supported | | | |||
| | nn.Mish | Partly supported | inplace not support on GRAPH mode | | |||
| | nn.Mish | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.Softplus | Supported | | | |||
| | nn.Softshrink | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.Softsign | Supported | | | |||
| @@ -909,7 +931,7 @@ English | [简体中文](SupportedList.md) | |||
| | nn.LayerNorm | Supported | | | |||
| | nn.LocalResponseNorm | Supported | | | |||
| | nn.RNNBase | Supported | | | |||
| | nn.RNN | Supported | | | |||
| | nn.RNN | Partly Supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.RNNCell | Supported | | | |||
| | nn.LSTMCell | Supported | | | |||
| | nn.GRUCell | Supported | | | |||
| @@ -927,7 +949,7 @@ English | [简体中文](SupportedList.md) | |||
| | nn.PairwiseDistance | Supported | | | |||
| | nn.L1Loss | Supported | | | |||
| | nn.MSELoss | Supported | | | |||
| | nn.CrossEntropyLoss | Supported | | | |||
| | nn.CrossEntropyLoss | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.CTCLoss | Supported | | | |||
| | nn.NLLLoss | Supported | | | |||
| | nn.PoissonNLLLoss | Supported | | | |||
| @@ -944,7 +966,7 @@ English | [简体中文](SupportedList.md) | |||
| | nn.TripletMarginWithDistanceLoss | Supported | | | |||
| | nn.PixelShuffle | Supported | | | |||
| | nn.PixelUnshuffle | Supported | | | |||
| | nn.Upsample | Supported | | | |||
| | nn.Upsample | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.UpsamplingNearest2d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.UpsamplingBilinear2d | Supported | | | |||
| | nn.ChannelShuffle | Supported | | | |||
| @@ -978,7 +1000,7 @@ English | [简体中文](SupportedList.md) | |||
| | nn.LazyInstanceNorm2d | Unsupported | | | |||
| | nn.LazyInstanceNorm3d | Unsupported | | | |||
| | nn.LSTM | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.GRU | Supported | | | |||
| | nn.GRU | Partly Supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.Embedding | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | nn.KLDivLoss | Supported | | | |||
| | nn.MultiLabelMarginLoss | Partly supported | Currently not support on CPU | | |||
| @@ -1029,8 +1051,8 @@ English | [简体中文](SupportedList.md) | |||
| | functional.relu6 | Supported | | | |||
| | functional.elu | Supported | | | |||
| | functional.elu_ | Partly supported | Currently not support on GRAPH mode | | |||
| | functional.selu | Supported | | | |||
| | functional.celu | Supported | | | |||
| | functional.selu | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.celu | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.leaky_relu | Supported | | | |||
| | functional.leaky_relu_ | Partly supported | Currently not support on GRAPH mode | | |||
| | functional.prelu | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| @@ -1052,7 +1074,7 @@ English | [简体中文](SupportedList.md) | |||
| | functional.sigmoid | Supported | | | |||
| | functional.hardsigmoid | Supported | | | |||
| | functional.silu | Supported | | | |||
| | functional.mish | Supported | | | |||
| | functional.mish | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.batch_norm | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.group_norm | Supported | | | |||
| | functional.instance_norm | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| @@ -1075,7 +1097,7 @@ English | [简体中文](SupportedList.md) | |||
| | functional.binary_cross_entropy_with_logits | Supported | | | |||
| | functional.poisson_nll_loss | Supported | | | |||
| | functional.cosine_embedding_loss | Supported | | | |||
| | functional.cross_entropy | Supported | | | |||
| | functional.cross_entropy | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.gaussian_nll_loss | Supported | | | |||
| | functional.hinge_embedding_loss | Supported | | | |||
| | functional.l1_loss | Supported | | | |||
| @@ -1089,7 +1111,7 @@ English | [简体中文](SupportedList.md) | |||
| | functional.triplet_margin_with_distance_loss | Supported | | | |||
| | functional.pixel_shuffle | Supported | | | |||
| | functional.pixel_unshuffle | Supported | | | |||
| | functional.grid_sample | Supported | | | |||
| | functional.grid_sample | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.huber_loss | Supported | | | |||
| | functional.conv1d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | functional.conv2d | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| @@ -1118,13 +1140,13 @@ English | [简体中文](SupportedList.md) | |||
| | --------------- | -------------------- | -------------- | | |||
| | norm | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | vector_norm | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | matrix_norm | Unsupported | | | |||
| | matrix_norm | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | diagonal | Supported | | | |||
| | det | Supported | | | |||
| | slogdet | Supported | | | |||
| | cond | Unsupported | | | |||
| | matrix_rank | Unsupported | | | |||
| | cholesky | Unsupported | | | |||
| | cond | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | matrix_rank | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | cholesky | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | qr | Unsupported | | | |||
| | lu | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | lu_factor | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| @@ -1137,7 +1159,7 @@ English | [简体中文](SupportedList.md) | |||
| | svd | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | svdvals | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | solve | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | solve_triangular | Unsupported | | | |||
| | solve_triangular | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | lu_solve | Unsupported | | | |||
| | lstsq | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | inv | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| @@ -1145,16 +1167,16 @@ English | [简体中文](SupportedList.md) | |||
| | qr | Supported| | | |||
| | matrix_exp | Unsupported | | | |||
| | matrix_power | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | cross | Unsupported | | | |||
| | matmul | Partly supported | [Function is constrained](ConstraintList_en.md) | | |||
| | cross | Partly supported | Currently not support on GPU | | |||
| | matmul | Supported | | | |||
| | vecdot | Unsupported | | | |||
| | multi_dot | Supported | | | |||
| | householder_product | Supported | | | |||
| | tensorinv | Unsupported | | | |||
| | tensorsolve | Unsupported | | | |||
| | vander | Supported | | | |||
| | cholesky_ex | Unsupported | | | |||
| | inv_ex | Unsupported | | | |||
| | cholesky_ex | [Function is constrained](ConstraintList_en.md) | | |||
| | inv_ex | [Function is constrained](ConstraintList_en.md) | | |||
| | solve_ex | Unsupported | | | |||
| | lu_factor_ex | Unsupported | | | |||
| | ldl_factor | Unsupported | | | |||
| @@ -1165,13 +1187,18 @@ English | [简体中文](SupportedList.md) | |||
| ### <span id="jump7">torch.optim</span> | |||
| <span id="jump10">Optimizer General Constraints:</span> | |||
| - The properties in the member variable `param_group` can be all modified under PyNative mode, but only `lr` can be modified in Graph mode. | |||
| - The following optimizer, for compatibility with the MindSpore Graph mode, `param_group['lr']` is initialized to MindSpore's `Parameters` type. When `param_group['lr']` needs to be modified, the `param_group['lr'] = lr` is supported in PyNative mode, but in Graph mode, `lr = mindspore.ops.depend(lr, mindspore.ops.assign(param_group['lr'], lr)` is required. | |||
| - Since `param_group['lr']` is initialized to type `Parameters` as shown above, use `float(param_group['lr'])` to convert if `param_group['lr']` is of type `Parameters` when printing is required. | |||
| - Due to differences in differential mechanisms, 'optimizer.step()' needs to be replaced with 'optimizer.step(grads)', where 'grad' can be obtained by 'mindspore.grad' or 'mindspore.value_and_grad'. | |||
| | MSAdapter APIs | Status | Restrictions | | |||
| | --------------- | -------------------- | -------------- | | |||
| | Optimizer | Unsupported | Please use [mindspore.nn.Optimizer](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.Optimizer.html#mindspore.nn.Optimizer) instead| | |||
| | Optimizer | Supported | | | |||
| | Adadelta | Unsupported | Please use [mindspore.nn.Adadelta](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.Adadelta.html#mindspore.nn.Adadelta) instead| | |||
| | Adagrad | Unsupported | Please use [mindspore.nn.Adagrad](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.Adagrad.html#mindspore.nn.Adagrad) instead| | |||
| | Adam | Unsupported | Please use [mindspore.nn.Adam](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.Adam.html#mindspore.nn.Adam) instead| | |||
| | AdamW | Unsupported | Please use [mindspore.nn.AdamWeightDecay](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.AdamWeightDecay.html#mindspore.nn.AdamWeightDecay) instead| | |||
| | Adam | Supported | | | |||
| | AdamW | Supported | | | |||
| | SparseAdam | Unsupported | | | |||
| | Adamax | Unsupported | Please use [mindspore.nn.AdaMax](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.AdaMax.html#mindspore.nn.AdaMax) instead| | |||
| | ASGD | Unsupported | Please use [mindspore.nn.ASGD](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.ASGD.html#mindspore.nn.ASGD) instead| | |||
| @@ -1180,4 +1207,48 @@ English | [简体中文](SupportedList.md) | |||
| | RAdam | Unsupported | | | |||
| | RMSprop | Unsupported | Please use [mindspore.nn.RMSprop](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.RMSProp.html#mindspore.nn.RMSProp) instead| | |||
| | Rprop | Unsupported | Please use [mindspore.nn.Rprop](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.Rprop.html#mindspore.nn.Rprop) instead | | |||
| | SGD | Unsupported | Please use [mindspore.nn.SGD](https://www.mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.SGD.html#mindspore.nn.SGD) instead| | |||
| | SGD | Supported | | | |||
| <span id="jump11">lr_scheduler General Constraints:</span> | |||
| - Since the `lr` of the optimizer exists with type `Parameter`, the `base_lr` and `_last_lr` of the lr_scheduler may also be of type `Parameter`. Therefore, when you need to save or restore the above variables, you need to convert their types in advance to save or restore them normally. For example, when saving, in the `state_dict` function, `return state_dict` should be changed to `return self._process_state_dict(state_dict)`, where `_process_state_dict` is a public function defined in the parent class `LRScheduler`, and the corresponding variable can be changed from `Parameter` The type is converted to a numeric type in Python. Similarly, when recovering, you can call `_process_state_dict_revert` in the parent class to restore to the `Parameter` type. | |||
| | MSAdapter interface | Status | Constraints | | |||
| | --------------- | -------------------- | -------------- | | |||
| | lr_scheduler.LRScheduler | Supported | | | |||
| | lr_scheduler._LRScheduler | Supported | | | |||
| | lr_scheduler.LambdaLR | Supported | | | |||
| | lr_scheduler.MultiplicativeLR | Supported | | | |||
| | lr_scheduler.StepLR | Supported | | | |||
| | lr_scheduler.MultiStepLR | Supported | | | |||
| | lr_scheduler.ConstantLR | Supported | | | |||
| | lr_scheduler.LinearLR | Supported | | | |||
| | lr_scheduler.ExponentialLR | Supported | | | |||
| | lr_scheduler.PolynomialLR | Supported | | | |||
| | lr_scheduler.CosineAnnealingLR | Supported | | | |||
| | lr_scheduler.ChainedScheduler | Supported | | | |||
| | lr_scheduler.SequentialLR | Supported | | | |||
| | lr_scheduler.ReduceLROnPlateau | Supported | | | |||
| | lr_scheduler.CyclicLR | Supported | | | |||
| | lr_scheduler.OneCycleLR | Supported | | | |||
| | lr_scheduler.CosineAnnealingWarmRestarts | Supported | | | |||
| ### <span id="jump9">torch.utils.data</span> | |||
| | MSAdapter APIs | Status | Restrictions | | |||
| | --------------- | ---- |------------------------------| | |||
| | DataLoader | Supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Dataset | Supported | | | |||
| | IterableDataset | Supported | | | |||
| | TensorDataset | Supported | | | |||
| | ConcatDataset | Supported | | | |||
| | ChainDataset | Supported | | | |||
| | Subset | Supported | | | |||
| | default_collate | Supported | | | |||
| | default_convert | Supported | | | |||
| | get_worker_info | Supported | | | |||
| | random_split | Supported | [Function is constrained](ConstraintList_en.md) | | |||
| | Sampler | Supported | | | |||
| | SequentialSampler | Supported | | | |||
| | RandomSampler | Supported |[Function is constrained](ConstraintList_en.md)| | |||
| | SubsetRandomSampler | Supported |[Function is constrained](ConstraintList_en.md)| | |||
| | WeightedRandomSampler | Supported |[Function is constrained](ConstraintList_en.md)| | |||
| | BatchSampler | Supported | | | |||
| | distributed.DistributedSampler | Supported | | | |||
+ 180
- 138
USER_GUIDE.md
View File
| @@ -2,22 +2,32 @@ | |||
| ## 1.简介 | |||
| MSAdapter是一款将PyTorch训练脚本高效迁移至MindSpore框架执行的实用工具,旨在不改变原生PyTorch用户的编程使用习惯下,使得PyTorch风格代码能在昇腾硬件上获得高效性能。用户只需要将PyTorch源代码中`import torch`替换为`import msadapter.pytorch`,加上少量训练代码适配即可实现模型在昇腾硬件上的训练。 | |||
| MSAdapter是一款将PyTorch训练脚本高效迁移至MindSpore框架执行的实用工具,旨在不改变原生PyTorch用户的编程使用习惯下,使得PyTorch风格代码能在昇腾硬件上获得高效性能。用户只需要将PyTorch源代码中`torch`系列相关的包导入部分(如`torch、torchvision`等),替换为导入`msadapter.pytorch`系列相关的包(如`msadapter.pytorch、msadapter.torchvision`等),加上少量训练代码适配即可实现模型在昇腾硬件上的训练。 | |||
| 本教程旨在协助用户快速完成PyTorch脚本迁移工作,精度调优和性能调优可参考[MSAdapter调试调优指南](Debugging_and_Tuning.md)。 | |||
| ## 2.模型迁移入门指南 | |||
| 将现有PyTorch原生代码利用MSAdapter移植至MindSpore时,当前通常需要以下三个步骤: | |||
| 将现有PyTorch原生代码利用MSAdapter移植至MindSpore时,当前通常需要如下两个步骤,替换导入模块以及替换网络训练脚本: | |||
| **Step1: 替换导入模块** | |||
| **Step 1: 替换导入模块** | |||
| 首先替换代码中导入`torch`相关包的代码,如`import torch`或`from torchvision`等部分,这一步可以利用msadapter/tools下提供的replace_import_package工具可快速完成工程代码中torch及torchvision相关导入包的替换。 | |||
| ```shell | |||
| bash replace_import_package.sh [Project Path] | |||
| ``` | |||
| `Project Path`为需要进行替换的工程路经,默认为"./"。 | |||
| 或者,用户也可以手动的替换文件中的导入包部分代码,示例代码如下: | |||
| ```python | |||
| # 替换前 | |||
| # import torch | |||
| # import torch.nn as nn | |||
| # import torch.nn.functional as F | |||
| # from torchvision import datasets, transforms | |||
| # 替换后 | |||
| import msadapter.pytorch as torch | |||
| import msadapter.pytorch.nn as nn | |||
| import msadapter.pytorch.nn.functional as F | |||
| @@ -55,11 +65,12 @@ train_set = datasets.CIFAR10(root='./data', train=True, download=True, transform | |||
| train_data = DataLoader(train_set, batch_size=128, shuffle=True, num_workers=2, drop_last=True) | |||
| ``` | |||
| MSAdapter已经支持大部分PyTorch和torchvision的原生态表达,用户只需要替换导入包即可完成模型定义和数据初始化。模型中所使用的高阶API支持状态可以从这里找到 [Supported List](https://openi.pcl.ac.cn/OpenI/MSAdapter/src/branch/master/SupportedList.md)。如果有一些必要的接口和功能缺失可以通过[ISSUE](https://openi.pcl.ac.cn/OpenI/MSAdapter/issues) 向我们反馈,我们会优先支持。 | |||
| **Step2: 替换网络训练脚本** | |||
| 请根据以下示例进行适配修改: | |||
| MSAdapter目前已支持大部分PyTorch和torchvision的原生态表达接口,用户只需要替换导入包即可完成模型定义和数据初始化。模型中所使用的高阶API支持状态可以从这里找到 [Supported List](https://openi.pcl.ac.cn/OpenI/MSAdapter/src/branch/master/SupportedList.md)。如果有一些必要的接口和功能缺失可以通过[ISSUE](https://openi.pcl.ac.cn/OpenI/MSAdapter/issues) 向我们反馈,我们会优先支持。 | |||
| **Step 2: 替换网络训练脚本** | |||
| 由于MindSpore的自动微分采用函数式表达,和PyTorch的微分接口存在差异,目前需要用户手动适配训练部分的少量代码,即将PyTorch版本的训练流程代码转换为MindSpore的函数式编程写法,从而使能MindSpore动静统一、自动并行等竞争力功能。详细内容可参考[MindSpore使用文档](https://www.mindspore.cn/tutorials/zh-CN/master/beginner/autograd.html)。以下示例展示了如何将PyTorch训练流程转换为MindSpore函数式训练流程: | |||
| 迁移前网络表达: | |||
| ```python | |||
| @@ -79,13 +90,14 @@ for i in range(epochs): | |||
| print("------>epoch:{}, loss:{:.6f}".format(i, loss)) | |||
| ``` | |||
| 替换为Mindspore函数式迭代训练表达: | |||
| 替换为Mindspore函数式迭代训练表达,其中前向过程通常包含了`模型网络接口调用`以及`损失函数调用`,反向求导过程包含了`反向梯度接口调用`以及`优化器接口调用`部分,此外,MindSpore不需要调用`loss.backward()`以及`optimizer.zero_grad()`,具体示例如下: | |||
| ```python | |||
| import msadapter.pytorch as torch | |||
| import mindspore as ms | |||
| net = LeNet().to(config_args.device) | |||
| optimizer = ms.nn.SGD(net.trainable_params(), learning_rate=0.01, momentum=0.9, weight_decay=0.0005) | |||
| optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0005) | |||
| # 定义前向过程 | |||
| def forward_fn(data, label): | |||
| @@ -99,7 +111,7 @@ grad_fn = ms.ops.value_and_grad(forward_fn, None, optimizer.parameters, has_aux= | |||
| # 单步训练定义 | |||
| def train_step(data, label): | |||
| (loss, _), grads = grad_fn(data, label) | |||
| loss = ms.ops.depend(loss, optimizer(grads)) | |||
| optimizer(grads) | |||
| return loss | |||
| net.train() | |||
| @@ -108,12 +120,12 @@ for i in range(epochs): | |||
| for X, y in train_data: | |||
| X, y = X.to(config_args.device), y.to(config_args.device) | |||
| res = train_step(X, y) | |||
| print("------>epoch:{}, loss:{:.6f}".format(i, res.asnumpy())) | |||
| print("------>epoch:{}, loss:{:.6f}".format(i, res.numpy())) | |||
| ``` | |||
| 当前网络训练流程仍无法完全自动适配(自动适配特性开发中,敬请期待!),需要调用MindSpore的优化器接口和训练流程,如果您想了解更多当前流程与PyTorch原生流程的区别可参考[与PyTorch执行流程区别](https://www.mindspore.cn/docs/zh-CN/r2.0/migration_guide/typical_api_comparision.html#%E4%B8%8Epytorch%E6%89%A7%E8%A1%8C%E6%B5%81%E7%A8%8B%E5%8C%BA%E5%88%AB) 和[与PyTorch优化器的区别](https://www.mindspore.cn/docs/zh-CN/r2.0/migration_guide/typical_api_comparision.html#%E4%B8%8Epytorch%E4%BC%98%E5%8C%96%E5%99%A8%E7%9A%84%E5%8C%BA%E5%88%AB) 。 | |||
| 如果您想了解更多当前流程与PyTorch原生流程的区别可参考[与PyTorch执行流程区别](https://www.mindspore.cn/docs/zh-CN/master/migration_guide/typical_api_comparision.html#%E4%B8%8Epytorch%E6%89%A7%E8%A1%8C%E6%B5%81%E7%A8%8B%E5%8C%BA%E5%88%AB)。 | |||
| 如果您想要运用分布式训练、图模式加速、数据下沉和混合精度等更高阶的训练方式加速训练可以参考[3.进阶训练指南](#jumpch3)。如果在使用过程中遇到问题或无法对标的内容欢迎通过[ISSUE](https://openi.pcl.ac.cn/OpenI/MSAdapter/issues) 和我们反馈交流。当前存在部分接口暂时无法完全对标PyTorch(参考[Supported List](https://openi.pcl.ac.cn/OpenI/MSAdapter/src/branch/master/SupportedList.md)),针对这类接口我们正在积极优化中,您可以暂时参考[4.手动适配指南](#jumpch4)进行适配处理(不影响网络的正常执行训练)。 | |||
| 如果您想要运用静态图模式加速、分布式训练和混合精度等更高阶的训练方式加速训练可以参考[3.进阶训练指南](#jumpch3)。如果在使用过程中遇到问题或无法对标的内容欢迎通过[ISSUE](https://openi.pcl.ac.cn/OpenI/MSAdapter/issues) 和我们反馈交流。当前存在部分接口暂时无法完全对标PyTorch(参考[Supported List](https://openi.pcl.ac.cn/OpenI/MSAdapter/src/branch/master/SupportedList.md)),针对这类接口我们正在积极优化中,您可以暂时参考[4.手动适配指南](#jumpch4)进行适配处理(不影响网络的正常执行训练)。 | |||
| 更多迁移用例请参考[MSAdapterModelZoo](https://openi.pcl.ac.cn/OpenI/MSAdapterModelZoo)。 | |||
| @@ -121,158 +133,199 @@ for i in range(epochs): | |||
| ## 3.<span id="jumpch3">进阶训练指南</span> | |||
| ### 3.1 使用Graph模式加速训练 | |||
| 目前MSAdapte默认支持MindSpore的PyNative模式训练,如果想调用静态图模式进行训练加速(推荐您先在PyNative模式下完成功能调试后再尝试Graph模式执行),可参考[静态图](https://www.mindspore.cn/tutorials/zh-CN/master/advanced/compute_graph.html)使用教程调用Graph训练模式: | |||
| 方式一:全局设置Graph模式,更适合module表达 | |||
| ### 3.1 使用混合精度加速训练 | |||
| 混合精度训练是指在训练时,对神经网络不同的运算采用不同的数值精度的运算策略。对于conv、matmul等运算占比较大的神经网络,其训练速度通常会有较大的加速比。mindspore.amp模块提供了便捷的自动混合精度接口,用户可以在不同的硬件后端通过简单的接口调用获得训练加速。目前由于框架机制不同,用户需要将`torch.cuda.amp.autocast`接口替换成`mindspore.amp.auto_mixed_precision`接口,从而使能MindSpore的自动混合精度训练。 | |||
| 迁移前代码: | |||
| ```python | |||
| ms.set_context(mode=ms.GRAPH_MODE) | |||
| ``` | |||
| from torch.cuda.amp import autocast, GradScaler | |||
| 方式二:采用即时编译装饰器`jit`,使能部分函数粒度表达模块以静态图模式执行 | |||
| model = Net().cuda() | |||
| optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0005) | |||
| ```python | |||
| @ms.jit | |||
| def mul(x, y): | |||
| return x * y | |||
| ``` | |||
| scaler = GradScaler() | |||
| 注意,部分网络中Graph模式训练无法一键切换,可能需要对代码进行相应调整,当前主要体现在inplace类型操作和MindSpore原生框架用法限制,具体细节可参考[静态图语法支持](https://www.mindspore.cn/docs/zh-CN/master/note/static_graph_syntax_support.html)。 | |||
| model.train() | |||
| for epoch in epochs: | |||
| for inputs, target in data: | |||
| optimizer.zero_grad() | |||
| with autocast(): | |||
| output = model(input) | |||
| loss = loss_fn(output, target) | |||
| ### 3.2 使用混合精度加速训练 | |||
| loss = scaler.scale(loss) # 损失缩放 | |||
| loss.backward() | |||
| scaler.step(optimizer) # 梯度更新 | |||
| scaler.update() # 更新系数 | |||
| ... | |||
| ``` | |||
| 迁移后代码: | |||
| ```python | |||
| import msadapter.pytorch as torch | |||
| from msadapter.pytorch.cuda.amp import GradScaler | |||
| from mindspore.amp import auto_mixed_precision | |||
| ... | |||
| net = LeNet().to(config_args.device) | |||
| optimizer = ms.nn.SGD(net.trainable_params(), learning_rate=0.01, momentum=0.9, weight_decay=0.0005) | |||
| model = Net().cuda() | |||
| optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0005) | |||
| net.train() | |||
| net = auto_mixed_precision(net, 'O3') # Ascend环境推荐配置'O3',GPU环境推荐配置'O2'; | |||
| scaler = GradScaler() | |||
| # 定义前向过程 | |||
| def forward_fn(data, label): | |||
| logits = net(data) | |||
| logits = torch.cast_to_adapter_tensor(logits) # 可选 | |||
| loss = criterion(logits, label) | |||
| return loss, logits | |||
| model.train() # model的方法调用需放在混合精度模型转换前 | |||
| model = auto_mixed_precision(model, 'O3') # Ascend环境推荐配置'O3',GPU环境推荐配置'O2' | |||
| def forward_fn(data, target): | |||
| logits = model(data) | |||
| logits = torch.cast_to_adapter_tensor(logits) # model为混合精度模型,需要对输出tensor进行类型转换 | |||
| loss = criterion(logits, target) | |||
| loss = scaler.scale(loss) # 损失缩放 | |||
| return loss | |||
| grad_fn = ms.ops.value_and_grad(forward_fn, None, optimizer.parameters) | |||
| def train_step(data, target): | |||
| loss, grads = grad_fn(data, target) | |||
| scaler.step(optimizer, grads) # 梯度更新 | |||
| scaler.update() # 更新系数 | |||
| return loss | |||
| for epoch in epochs: | |||
| for inputs, target in data: | |||
| loss = train_step(input, target) | |||
| ... | |||
| ``` | |||
| Step1:调用`auto_mixed_precision`自动生成混合精度模型,如果需要调用原始模型的方法请在混合精度模型生成前执行,如`net.train()`; | |||
| Step1:调用`auto_mixed_precision`自动生成混合精度模型,如果需要调用原始模型的方法请在混合精度模型生成前执行,如`model.train()`; | |||
| Step2(可选):如果后续仍有对网络输出Tensor的操作,需调用`torch.cast_to_adapter_tensor`手动将输出 Tensor转换为MSAdater Tensor; | |||
| Step2(可选):如果后续有对网络输出Tensor的操作,需调用`cast_to_adapter_tensor`手动将输出Tensor转换为MSAdapter Tensor。 | |||
| 更多细节请参考[自动混合精度使用教程](https://www.mindspore.cn/tutorials/zh-CN/master/advanced/mixed_precision.html)。 | |||
| ### 3.3 使用分布式训练加速训练 | |||
| ### 3.2 使用静态图模式加速训练 | |||
| 请参考[快速入门分布式并行训练](https://www.mindspore.cn/tutorials/experts/zh-CN/master/parallel/parallel_training_quickstart.html)选择合适的分布式训练方式。推荐使用OpenMPI训练方式,其效果类似PyTorch的分布式数据并行[DistributedDataParallel](https://pytorch.org/docs/1.12/generated/torch.nn.parallel.DistributedDataParallel.html?highlight=distributeddataparallel#torch.nn.parallel.DistributedDataParallel)训练方式: | |||
| ```python | |||
| # 分布式数据处理 | |||
| from msadapter.pytorch.utils.data import DataLoader, DistributedSampler | |||
| # 初始化通信环境 | |||
| from mindspore.communication import init | |||
| MindSpore框架的执行模式有两种:动态图(PyNative)模式和静态图(Graph)模式: | |||
| - 动态图模式下,程序按照代码的编写顺序执行,在执行正向过程中根据反向传播的原理,动态生成反向执行图。动态图模式方便编写和调试神经网络模型。 | |||
| - 静态图模式下,程序在编译执行时先生成神经网络的图结构,然后再执行图中涉及的计算操作。静态图模式利用图优化等技术对执行图进行更大程度的优化,因此能获得较好的性能,但是执行图是从源码转换而来,因此在静态图下不是所有的Python语法都能支持。 | |||
| 更多详细信息请参考[MindSpore动静统一机制介绍](https://www.mindspore.cn/docs/zh-CN/master/design/dynamic_graph_and_static_graph.html)。 | |||
| ... | |||
| train_images = datasets.CIFAR10('./', train=True, download=True, transform=transform) | |||
| sampler = DistributedSampler(train_images) | |||
| train_data = DataLoader(train_images, batch_size=32, num_workers=2, drop_last=True, sampler=sampler) | |||
| ... | |||
| ``` | |||
| 目前MSAdapte默认支持PyNative模式,请首先在PyNative模式下完成功能调试。如果想调用静态图模式进行训练加速,再尝试切换到Graph模式执行。下面介绍两种切换静态图的方式: | |||
| 执行脚本命令为: | |||
| 方式一:采用即时编译装饰器`jit`,使能部分函数粒度表达模块以静态图模式执行。 | |||
| ```python | |||
| import mindspore as ms | |||
| @ms.jit | |||
| def mul(x, y): | |||
| return x * y | |||
| ``` | |||
| mpirun -n DEVICE_NUM python train.py | |||
| 方式二:全局设置Graph模式,更适合基于Module表达。 | |||
| ```python | |||
| import mindspore as ms | |||
| ms.set_context(mode=ms.GRAPH_MODE) | |||
| ``` | |||
| ### 3.4 分组学习率/动态学习率配置 | |||
| 由于Graph模式下不是所有的Python语法都能支持,通过上面两种方式切换到Graph模式后部分网络可能会出现语法不支持情况,需要根据报错信息对代码进行相应调整,当前主要体现在in-place类型操作和部分语法用法限制,具体可参考[静态图语法支持](https://www.mindspore.cn/docs/zh-CN/master/note/static_graph_syntax_support.html)。 | |||
| 请参考以下代码使用MindSpore的分组学习率配置策略: | |||
| ```python | |||
| net = Net() | |||
| ### 3.3 使用分布式训练加速训练 | |||
| # 卷积参数 | |||
| conv_params = list(filter(lambda x: 'conv' in x.name, net.trainable_params())) | |||
| # 非卷积参数 | |||
| no_conv_params = list(filter(lambda x: 'conv' not in x.name, net.trainable_params())) | |||
| 分布式并行训练可以降低对内存、计算性能等硬件的需求,是进行训练的重要优化手段。目前MSAdapter中对标`torch.distributed`相关分布式接口还在开发中,如果用户想要使用分布式训练进行加速训练,需要将`torch.distributed`相关接口替换成MindSpore提供的更简单易用的高阶API。MSAdapter基于MindSpore分布式并行能力提供两种并行模式: | |||
| - 数据并行:对数据进行切分的并行模式,一般按照batch维度切分,将数据分配到各个计算单元中,进行模型计算。 | |||
| - 自动并行:融合了数据并行、算子级模型并行的分布式并行模式,可以自动建立代价模型,找到训练时间较短的并行策略,为用户选择合适的并行模式。 | |||
| # 卷积参数使用固定学习率0.001,权重衰减为0.01 | |||
| # 非卷积参数使用固定学习率0.003,权重衰减为0.0 | |||
| group_params = [{'params': conv_params, 'weight_decay': 0.01, 'lr': 0.001}, | |||
| {'params': no_conv_params, 'lr': 0.003}] | |||
| optim = nn.Momentum(group_params, learning_rate=0.1, momentum=0.9, weight_decay=0.0) | |||
| ``` | |||
| 相关机制请参考[MindSpore原生分布式并行架构](https://mindspore.cn/docs/zh-CN/master/design/distributed_training_design.html)。 | |||
| 请参考以下代码使用MindSpore的动态学习率更新策略: | |||
| #### 数据并行 | |||
| ```python | |||
| def lr_cosine_policy(base_lr, warmup_length, epochs, iter_per_epoch): | |||
| def _lr_fn(epoch): | |||
| if epoch < warmup_length: | |||
| lr = base_lr * (epoch + 1) / warmup_length | |||
| else: | |||
| e = epoch - warmup_length | |||
| es = epochs - warmup_length | |||
| lr = 0.5 * (1 + np.cos(np.pi * e / es)) * base_lr | |||
| return lr | |||
| output = [] | |||
| for epoch in range(0, epochs): | |||
| lr = _lr_fn(epoch) | |||
| for iter in range(iter_per_epoch) | |||
| output.append(lr) | |||
| return output | |||
| lr_scheduler = lr_cosine_policy(args.lr, args.warmup, args.epochs, iter_per_epoch) | |||
| optimizer = ms.nn.SGD(net.trainable_params(), learning_rate=lr_scheduler, momentum=0.9, weight_decay=1e-4) | |||
| ``` | |||
| from msadapter.pytorch.utils.data import DataLoader, DistributedSampler | |||
| from mindspore.communication import init | |||
| import mindspore as ms | |||
| PyTorch提供了`torch.optim.lr_scheduler`包用于动态修改lr,使用的时候需要显式地调用`optimizer.step()`和`scheduler.step()`来更新lr(详情请参考[如何调整学习率](https://pytorch.org/docs/1.12/optim.html#how-to-adjust-learning-rate))。而MindSpore的学习率是在优化器中自动更新的,每调用一次优化器,学习率更新的step会自动更新一次(详情请参考[动态学习率使用教程](https://www.mindspore.cn/tutorials/zh-CN/master/advanced/modules/optimizer.html?highlight=%E5%8A%A8%E6%80%81%E5%AD%A6%E4%B9%A0%E7%8E%87#%E5%8A%A8%E6%80%81%E5%AD%A6%E4%B9%A0%E7%8E%87))。 | |||
| ... | |||
| init("hccl") # 初始化通信环境:"hccl"---Ascend, "nccl"---GPU, "mccl"---CPU | |||
| ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.DATA_PARALLEL, parameter_broadcast=True) # 配置数据并行模式 | |||
| ### 3.5 其他训练表达 | |||
| train_images = datasets.CIFAR10('./', train=True, download=True, transform=transform) | |||
| sampler = DistributedSampler(train_images) # 分布式数据处理 | |||
| train_data = DataLoader(train_images, batch_size=32, num_workers=2, drop_last=True, sampler=sampler) | |||
| 除前文推荐的函数式迭代训练表达外,还有两种训练表达形式可供选择: | |||
| ... | |||
| 方式二:使用MindSpore的Model.train训练 | |||
| ```python | |||
| import mindspore as ms | |||
| from mindspore.dataset import GeneratorDataset | |||
| from mindspore.train.callback import LossMonitor, TimeMonitor | |||
| def forward_fn(data, label): | |||
| logits = net(data) | |||
| loss = criterion(logits, label) | |||
| return loss, logits | |||
| model = LeNet() | |||
| criterion = nn.CrossEntropyLoss() | |||
| optimizer = ms.nn.SGD(model.trainable_params(), learning_rate=0.1, momentum=0.9, weight_decay=1e-4) | |||
| grad_fn = ms.ops.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True) | |||
| grad_reducer = nn.DistributedGradReducer(optimizer.parameters) # 定义分布式优化器 | |||
| def train_step(data, label): | |||
| (loss, _), grads = grad_fn(data, label) | |||
| grads = grad_reducer(grads) # 梯度聚合 | |||
| optimizer(grads) | |||
| return loss | |||
| model = ms.Model(model, criterion, optimizer, metrics={'accuracy'}) | |||
| dataset = GeneratorDataset(source=train_data, column_names=["data", "label"]) | |||
| model.train(epochs, dataset, callbacks=[TimeMonitor(), LossMonitor()]) | |||
| net.train() | |||
| for i in range(epochs): | |||
| for inputs, target in train_data: | |||
| res = train_step(inputs, target) | |||
| ... | |||
| ``` | |||
| 方式三:使用WithLossCell和TrainOneStepCell迭代训练 | |||
| #### 自动并行 | |||
| ```python | |||
| from msadapter.pytorch.utils.data import DataLoader, DistributedSampler | |||
| from mindspore.communication import init | |||
| import mindspore as ms | |||
| from msadapter.pytorch import nn | |||
| import msadapter.pytorch as torch | |||
| model = LeNet() | |||
| criterion = nn.CrossEntropyLoss() | |||
| optimizer = ms.nn.SGD(model.trainable_params(), learning_rate=0.1, momentum=0.9, weight_decay=1e-4) | |||
| ... | |||
| ms.set_context(mode=ms.GRAPH_MODE) # 自动并行仅支持静态图模式 | |||
| init("hccl") # 初始化通信环境:"hccl"---Ascend, "nccl"---GPU, "mccl"---CPU | |||
| ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.AUTO_PARALLEL, search_mode="sharding_propagation") # 配置自动并行模式 | |||
| train_images = datasets.CIFAR10('./', train=True, download=True, transform=transform) | |||
| sampler = DistributedSampler(train_images) # 分布式数据处理 | |||
| train_data = DataLoader(train_images, batch_size=32, num_workers=2, drop_last=True, sampler=sampler) | |||
| ... | |||
| def forward_fn(data, label): | |||
| logits = net(data) | |||
| loss = criterion(logits, label) | |||
| return loss, logits | |||
| grad_fn = ms.ops.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True) | |||
| @ms.jit | |||
| def train_step(data, label): | |||
| (loss, _), grads = grad_fn(data, label) | |||
| optimizer(grads) | |||
| return loss | |||
| loss_net = ms.nn.WithLossCell(model, criterion) | |||
| train_net = ms.nn.TrainOneStepCell(loss_net, optimizer) | |||
| net.train() | |||
| for i in range(epochs): | |||
| for X, y in train_data: | |||
| loss = train_net(X, y) | |||
| for inputs, target in train_data: | |||
| res = train_step(inputs, target) | |||
| ... | |||
| ``` | |||
| 自动并行功能目前在实验性阶段,仅支持部分场景。如果在使用过程中出现不支持的报错信息,可以通过[ISSUE](https://openi.pcl.ac.cn/OpenI/MSAdapter/issues)反馈。 | |||
| #### 分布式启动 | |||
| 通过OpenMPI的mpirun运行分布式脚本。下面以使用单机8卡的分布式训练为例,当执行该命令时, 脚本会在后台运行,日志文件会保存到当前目录下,不同卡上的日志会按rank_id分别保存在log_output/1/路径下对应的文件中。 | |||
| ``` | |||
| mpirun -n 8 --output-filename log_output --merge-stderr-to-stdout python train.py > train.log 2>&1 & | |||
| ``` | |||
| 多机多卡启动等更复杂的用法请参考[MindSpore分布式训练样例](https://www.mindspore.cn/tutorials/experts/zh-CN/r2.1/parallel/train_ascend.html#%E9%80%9A%E8%BF%87openmpi%E8%BF%90%E8%A1%8C%E8%84%9A%E6%9C%AC)。 | |||
| ## 4.<span id="jumpch4">手动适配指南</span> | |||
| @@ -317,7 +370,7 @@ class MLP(Module): | |||
| return x | |||
| ``` | |||
| 自定义module写法和PyTorch原生写法一致,但需要注意下述问题: | |||
| 自定义Module写法和PyTorch原生写法一致,但需要注意下述问题: | |||
| 1. 自定义module时可能出现变量名已被使用场景,如`self.phase`,需要用户自行变更变量名; | |||
| 2. 自定义反向传播函数差异,反向函数需要满足MindSpore自定义反向函数格式要求,请参考[自定义Cell反向](https://www.mindspore.cn/tutorials/zh-CN/master/advanced/modules/layer.html#%E8%87%AA%E5%AE%9A%E4%B9%89cell%E5%8F%8D%E5%90%91),以下是适配案例: | |||
| @@ -337,7 +390,7 @@ class GdnFunction(Function): | |||
| ... | |||
| return grad_input, grad_gamma, grad_beta | |||
| # MSadapter 写法 | |||
| # MSAdapter 写法 | |||
| class GdnFunction(nn.Module): | |||
| def __init__(self): | |||
| super(GdnFunction, self).__init__() | |||
| @@ -357,11 +410,7 @@ class GdnFunction(nn.Module): | |||
| #### 4.2.2 多态接口适配 | |||
| PyTorch存在一些多态接口,使用灵活。MSAdapter作为Python层适配中间件,暂时只能支持主流场景,部分场景可能需要用户补齐默认参数或替换接口实现,已经识别到的此类接口有: | |||
| 1. `torch.max(tensor1, tensor2)`需要替换为`torch.maximum(tensor1, tensor2)`等价实现; | |||
| 2. `torch.min(tensor1, tensor2)`需要替换为`torch.minimum(tensor1, tensor2)`等价实现; | |||
| 3. `torch.randint(10, (2, 2))`需要补齐默认参数`torch.randint(0, 10, (2, 2))`等价实现,类似的接口还有`torch.arange`/`torch.normal`/`torch.randint_like`; | |||
| PyTorch存在一些多态接口,使用灵活。MSAdapter作为Python层适配中间件,暂时只能支持主流场景,部分场景可能需要用户补齐默认参数或替换接口实现,如:`torch.randint(10, (2, 2))`需要补齐默认参数`torch.randint(0, 10, (2, 2))`等价实现,类似的接口还有`torch.arange`/`torch.normal`/`torch.randint_like`; | |||
| #### 4.2.3 view类接口和inplace类接口适配 | |||
| @@ -391,15 +440,7 @@ PyTorch原生接口通过`to`等接口将数据拷贝到指定硬件中执行, | |||
| ms.context.set_context(device_target="CPU") | |||
| ``` | |||
| #### 4.3.2 冗余代码删除 | |||
| 部分接口功能暂时无法对标,请将相关代码删除或进行相应适配,如: | |||
| 1. torch.cuda模块的相关操作在昇腾硬件上无实质作用,请删除; | |||
| 2. 请删除torch.no_grad接口。除非主动调用微分相关接口,MSAdapter默认不计算变量梯度; | |||
| 3. 请删除分布式并行训练的相关接口,并参考[3.3 使用分布式训练](#3.3-使用分布式训练)进行分布式训练; | |||
| #### 4.3.3 网络训练流程 | |||
| #### 4.3.2 网络训练流程 | |||
| 1. 当调用`ms.ops.value_and_grad`接口时,如果`has_aux`为True,不允许存在多层嵌套的输出(**优化中**),且求导位置必须为第一个输出; | |||
| 2. `torch.nn.utils.clip_grad_norm_` 可替换为 `ms.ops.clip_by_global_norm`等价实现梯度裁剪功能; | |||
| @@ -419,19 +460,12 @@ ms.context.set_context(device_target="CPU") | |||
| ```python | |||
| # 模型保存 | |||
| torch.save(net.state_dict(), 'epoch1.pth') | |||
| # 加载来自torch原生脚本保存的pth | |||
| net.load_state_dict(torch.load('troch_origin.pth',from_torch=True), strict=True) | |||
| # 加载来自MSAdapter迁移模型保存的pth | |||
| # 加载来自MSAdapter迁移模型保存的pth/torch原生脚本保存的pth | |||
| net.load_state_dict(torch.load('troch_origin.pth'), strict=True) | |||
| ``` | |||
| 我们支持PyTorch原生的模型保存语法,允许用户保存网络权重或以字典形式保存其他数据;对于模型加载阶段,当前暂不支持加载网络模型结构。 | |||
| 用户可以通过配置`from_torch=True`标志位加载来自PyTorch原生的pth文件,仅支持加载网络权重,不支持加载网络结构。基于MSAdapter保存的pth文件不支持PyTorch原生脚本使用。 | |||
| 我们支持PyTorch原生的模型保存语法,允许用户保存网络权重或以字典形式保存其他数据;对于模型加载阶段,当前暂不支持加载网络模型结构。用户同样可以加载来自PyTorch原生的pth文件,但仅支持加载网络权重,不支持加载网络结构。基于MSAdapter保存的pth文件不支持PyTorch原生脚本使用。 | |||
| ## FAQ | |||
| @@ -448,3 +482,11 @@ ms.context.set_context(device_target="CPU") | |||
| **A**:首先确定'xxx'是否为torch 1.12版本支持的接口,PyTorch官网明确已废弃或者即将废弃的接口和参数,MSAdapter不会兼容支持,请使用其他同等功能的接口代替。如果是PyTorch对应版本支持,而MSAdapter中暂时没有,欢迎参与[MSAdapter项目](https://openi.pcl.ac.cn/OpenI/MSAdapter)贡献你的代码,也可以通过[创建任务(New issue)](https://openi.pcl.ac.cn/OpenI/MSAdapter/issues/new)反馈需求。 | |||
| **Q**:为什么TensorDataset返回值为`numpy.ndarray`类型? | |||
| **A**:为了加速数据处理流程以及避免在GPU/Ascend中SyncDeviceToHost失败,TensorDataset返回值会被转换为`numpy.ndarray`类型。如果您结合DataLoader使用则无需关注返回值类型,如果您单独调用该接口则需要手动将输出转换为Tensor类型。 | |||
+ 2
- 0
msadapter/pytorch/__init__.py
View File
| @@ -14,6 +14,8 @@ from msadapter.pytorch import cuda | |||
| from msadapter.pytorch.conflict_functional import * | |||
| import msadapter.pytorch.fft as fft | |||
| from msadapter.pytorch import autograd | |||
| from msadapter.pytorch.autograd import ( | |||
| no_grad, enable_grad, set_grad_enabled, is_grad_enabled, inference_mode, is_inference_mode_enabled) | |||
| from msadapter.pytorch.random import * | |||
| from msadapter.pytorch.storage import * | |||
| from msadapter.pytorch.serialization import * | |||
+ 2
- 2
msadapter/pytorch/_register_numpy_primitive.py
View File
| @@ -90,10 +90,10 @@ class NumpySvdvals(NumpyCommon): | |||
| class NumpyI0(NumpyCommon): | |||
| def construct(self, A): | |||
| if A.dtype in msdapter_dtype.all_int_type: | |||
| A = A.astype(ms.float32) | |||
| A_np = A.asnumpy() | |||
| output = ms.Tensor(np.i0(A_np)) | |||
| if A.dtype in msdapter_dtype.all_int_type: | |||
| output = output.astype(ms.float32) | |||
| return output | |||
| def bprop(self, A, out, dout): | |||
| raise RuntimeError(_error_msg.format(self.op_name)) | |||
+ 3
- 1
msadapter/pytorch/autograd/__init__.py
View File
| @@ -3,8 +3,10 @@ | |||
| from .variable import Variable | |||
| from .function import Function | |||
| from .grad_mode import * | |||
| from . import functional | |||
| # MindSpore's autodiff mechanism is different from PyTorch' autograd, so it cannot be fully benchmarked. | |||
| # Users can directly use the autograd API of MindSpore. | |||
| __all__ = ["Variable", "Function"] | |||
| __all__ = ["Variable", "Function", 'grad_mode'] | |||
+ 74
- 0
msadapter/pytorch/autograd/functional.py
View File
| @@ -0,0 +1,74 @@ | |||
| import mindspore as ms | |||
| from msadapter.utils import unsupported_attr | |||
| from msadapter.pytorch.tensor import cast_to_adapter_tensor, cast_to_ms_tensor | |||
| __all__ = ['vjp', 'jvp', 'jacobian'] | |||
| def vjp(func, inputs, v=None, create_graph=False, strict=False): | |||
| if strict is True or create_graph is True: | |||
| raise NotImplementedError("vjp not support `strict` and `create_graph` yet.") | |||
| if not isinstance(inputs, (list, tuple)): | |||
| inputs = (inputs,) | |||
| if v is not None and not isinstance(v, (list, tuple)): | |||
| v = (v,) | |||
| # Can not cast to mindspore tensor, because ms.vjp will run forward operation of `func` | |||
| # In func, adapter api will be call. So need to ensure inputs to be adapter Tensor. | |||
| # inputs = cast_to_ms_tensor(inputs) | |||
| v = cast_to_ms_tensor(v) | |||
| func_output, fn = ms.vjp(func, *inputs) | |||
| if v is not None: | |||
| vjp_output = fn(*v) | |||
| else: | |||
| if ms.ops.size(func_output) != 1: | |||
| raise RuntimeError("The vector v can only be None if the user-provided " | |||
| "function returns a single Tensor with a single element.") | |||
| v = ms.ops.ones_like(func_output) | |||
| vjp_output = fn(v) | |||
| if len(vjp_output) == 1: | |||
| vjp_output = vjp_output[0] | |||
| return cast_to_adapter_tensor(func_output), cast_to_adapter_tensor(vjp_output) | |||
| def jvp(func, inputs, v=None, create_graph=False, strict=False): | |||
| if strict is True or create_graph is True: | |||
| raise NotImplementedError("jvp not support `strict` and `create_graph` yet.") | |||
| # Can not cast to mindspore tensor, because ms.jvp will run forward operation of `func` | |||
| # In func, adapter api will be call. So need to ensure inputs to be adapter Tensor. | |||
| # inputs = cast_to_ms_tensor(inputs) | |||
| v = cast_to_ms_tensor(v) | |||
| if v is None: | |||
| if isinstance(inputs, tuple) or inputs.nelement() != 1: | |||
| raise RuntimeError("The vector v can only be None if the input to " | |||
| "the user-provided function is a single Tensor " | |||
| "with a single element.") | |||
| v = ms.ops.ones_like(inputs) | |||
| func_output, jvp_output = ms.jvp(func, inputs, v) | |||
| return cast_to_adapter_tensor(func_output), cast_to_adapter_tensor(jvp_output) | |||
| def jacobian(func, inputs, create_graph=False, strict=False, vectorize=False, strategy="reverse-mode"): | |||
| if strict is True or create_graph is True: | |||
| raise NotImplementedError("jacobian not support `strict` and `create_graph` yet.") | |||
| unsupported_attr(vectorize) | |||
| # can not cast inputs to ms tensor, because ms.jacrev and ms.jacfwd will run forward of func. | |||
| # inputs = cast_to_ms_tensor(inputs) | |||
| if strategy == "reverse_mode": | |||
| _jacobian = ms.jacrev | |||
| else: | |||
| _jacobian = ms.jacfwd | |||
| if isinstance(inputs, (tuple, list)): | |||
| _op = _jacobian(func, grad_position=tuple(range(len(inputs)))) | |||
| output = _op(*inputs) | |||
| else: | |||
| _op = _jacobian(func, grad_position=0) | |||
| output = _op(inputs) | |||
| return cast_to_adapter_tensor(output) | |||
+ 85
- 0
msadapter/pytorch/autograd/grad_mode.py
View File
| @@ -0,0 +1,85 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import contextlib | |||
| from mindspore import _no_grad as no_grad | |||
| from mindspore import context | |||
| from mindspore.common.api import _pynative_executor | |||
| class enable_grad(contextlib.ContextDecorator): | |||
| """ | |||
| Context Manager to enable gradient calculation. When enter this context, we will enable calculate | |||
| gradient. When exit this context, we will resume its prev state. | |||
| Currently, it can only use in Pynative mode. It also can be used as decorator. | |||
| """ | |||
| def __init__(self): | |||
| if context.get_context("mode") == context.GRAPH_MODE: | |||
| raise RuntimeError("For enable_grad feature, currently only support Pynative mode, but got Graph mode.") | |||
| self.prev = False | |||
| def __enter__(self): | |||
| self.prev = _pynative_executor.enable_grad() | |||
| _pynative_executor.set_enable_grad(True) | |||
| def __exit__(self, exc_type, exc_value, traceback): | |||
| _pynative_executor.set_enable_grad(self.prev) | |||
| return False | |||
| class inference_mode(contextlib.ContextDecorator): | |||
| ''' | |||
| inference_mode is a more extreme version of no-grad mode, can speed up even more. | |||
| In torch, the different behavious between inference mode and no-grad is that, the tensor create under | |||
| inference mode context can not used in autograd later, and torch.is_inference() will return True on this tensor. | |||
| Here, mindspore can not retrict tensor to be used in autograd later and will still perform tensor tracking. | |||
| So here, inference_mode is equivalent to no-grad temporarily. | |||
| ''' | |||
| def __init__(self, mode=True): | |||
| if context.get_context("mode") == context.GRAPH_MODE: | |||
| raise RuntimeError("For inference_mode feature, currently only support Pynative mode, but got Graph mode.") | |||
| self.prev = False | |||
| self.mode = mode | |||
| def __enter__(self): | |||
| self.prev_state = _pynative_executor.enable_grad() | |||
| _pynative_executor.set_enable_grad(not self.mode) | |||
| def __exit__(self, exc_type, exc_value, traceback): | |||
| _pynative_executor.set_enable_grad(self.prev_state) | |||
| return False | |||
| def clone(self): | |||
| return self.__class__(self.mode) | |||
| class set_grad_enabled(contextlib.ContextDecorator): | |||
| def __init__(self, mode): | |||
| if context.get_context("mode") == context.GRAPH_MODE: | |||
| raise RuntimeError("For set_grad_enabled feature, currently only support Pynative mode, " | |||
| "but got Graph mode.") | |||
| self.prev = _pynative_executor.enable_grad() | |||
| _pynative_executor.set_enable_grad(mode) | |||
| self.mode = mode | |||
| def __enter__(self): | |||
| pass | |||
| def __exit__(self, exc_type, exc_value, traceback): | |||
| _pynative_executor.set_enable_grad(self.prev) | |||
| def clone(self): | |||
| return self.__class__(self.mode) | |||
| def is_grad_enabled(): | |||
| if context.get_context("mode") == context.GRAPH_MODE: | |||
| raise RuntimeError("For is_grad_enabled feature, currently only support Pynative mode, " | |||
| "but got Graph mode.") | |||
| return _pynative_executor.enable_grad() | |||
| def is_inference_mode_enabled(): | |||
| if context.get_context("mode") == context.GRAPH_MODE: | |||
| raise RuntimeError("For is_inference_mode_enabled feature, " | |||
| "currently only support Pynative mode, but got Graph mode.") | |||
| return not _pynative_executor.enable_grad() | |||
| __all__ = ['no_grad', 'enable_grad', 'set_grad_enabled', 'is_grad_enabled', 'inference_mode', | |||
| 'is_inference_mode_enabled'] | |||
+ 7
- 2
msadapter/pytorch/common/dtype.py
View File
| @@ -1,6 +1,7 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import warnings | |||
| import numpy as np | |||
| from mindspore import dtype as mstype | |||
| from mindspore.ops.primitive import _primexpr | |||
| @@ -69,8 +70,12 @@ class finfo: | |||
| self.max = np_finfo.max.item() | |||
| self.min = np_finfo.min.item() | |||
| self.tiny = np_finfo.tiny.item() | |||
| # TODO: numpy vision >= 1.23 | |||
| # self.smallest_normal = np_finfo.smallest_normal | |||
| # smallest_normal for NumPy was added in 1.23.0 | |||
| if np.lib.NumpyVersion(np.__version__) >= '1.23.0': | |||
| self.smallest_normal = np_finfo.smallest_normal.item() | |||
| else: | |||
| warnings.warn("If you want to obtain `smallest_normal` in finfo, " | |||
| "NumPy version must be greater or equal 1.23.0.") | |||
| self.resolution = np_finfo.resolution.item() | |||
| else: | |||
| raise ValueError("finfo currently only supports torch.float16/torch.float32/" | |||
+ 4
- 4
msadapter/pytorch/conflict_functional.py
View File
| @@ -4,7 +4,7 @@ | |||
| import mindspore as ms | |||
| from msadapter.utils import unsupported_attr | |||
| from msadapter.pytorch.common._inner import _out_inplace_assign | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor | |||
| def range(start, end, step=1, out=None, dtype=None, layout=None, device=None, requires_grad=False): | |||
| unsupported_attr(layout) | |||
| @@ -27,8 +27,8 @@ def arange(start, end=None, step=1, *, out=None, dtype=None, | |||
| unsupported_attr(layout) | |||
| unsupported_attr(device) | |||
| unsupported_attr(requires_grad) | |||
| if end is None: | |||
| end = start | |||
| start = 0 | |||
| start = cast_to_ms_tensor(start) | |||
| end = cast_to_ms_tensor(end) | |||
| step = cast_to_ms_tensor(step) | |||
| output = ms.ops.arange(start=start, end=end, step=step, dtype=dtype) | |||
| return _out_inplace_assign(out, output, "arange") | |||
+ 1
- 0
msadapter/pytorch/cuda/__init__.py
View File
| @@ -6,6 +6,7 @@ from mindspore.communication.management import init, get_group_size | |||
| from msadapter.utils import get_backend | |||
| from msadapter.pytorch.tensor import BoolTensor, ByteTensor, CharTensor, ShortTensor, IntTensor, HalfTensor, \ | |||
| FloatTensor, DoubleTensor, LongTensor | |||
| import msadapter.pytorch.cuda.amp as amp | |||
| def is_available(): | |||
+ 4
- 0
msadapter/pytorch/cuda/amp/__init__.py
View File
| @@ -0,0 +1,4 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from .grad_scaler import GradScaler | |||
+ 267
- 0
msadapter/pytorch/cuda/amp/grad_scaler.py
View File
| @@ -0,0 +1,267 @@ | |||
| import warnings | |||
| import inspect | |||
| from collections import defaultdict | |||
| from enum import Enum | |||
| import mindspore as ms | |||
| from mindspore.amp import DynamicLossScaler, all_finite | |||
| import mindspore.ops as ops | |||
| from msadapter.pytorch.nn.parameter import Parameter | |||
| from msadapter.pytorch.tensor import tensor | |||
| from msadapter.pytorch.common.dtype import float32, int32 | |||
| from msadapter.utils import graph_mode_condition | |||
| class OptState(Enum): | |||
| READY = 0 | |||
| UNSCALED = 1 | |||
| STEPPED = 2 | |||
| def _refresh_per_optimizer_state(): | |||
| return {"stage": OptState.READY, "found_inf_per_device": {}} | |||
| def _assign(x1, x2): | |||
| return x1.assign_value(x2) | |||
| _hypermap = ops.HyperMap() | |||
| class GradScaler(DynamicLossScaler): | |||
| def __init__(self, | |||
| init_scale=2.**16, | |||
| growth_factor=2.0, | |||
| backoff_factor=0.5, | |||
| growth_interval=2000, | |||
| enabled=True): | |||
| self._enabled = enabled | |||
| if self._enabled: | |||
| if init_scale < 1.0: | |||
| raise ValueError("The argument 'scale_value' must be > 1, but got {}".format(init_scale)) | |||
| if growth_factor <= 1.0: | |||
| raise ValueError("The growth factor must be > 1.0.") | |||
| if backoff_factor >= 1.0: | |||
| raise ValueError("The backoff factor must be < 1.0.") | |||
| if not isinstance(growth_interval, int) or growth_interval < 0: | |||
| raise ValueError(" The growth_interval must be int and > 0") | |||
| # init_scale -> scale_value | |||
| # growth_factor -> scale_factor | |||
| # growth_interval -> scale_window | |||
| # growth_tracker -> counter | |||
| self._init_scale = init_scale | |||
| self.scale_value = Parameter(tensor(init_scale, dtype=float32), name="scale_value", requires_grad=False) | |||
| self.scale_factor = growth_factor | |||
| self._backoff_factor = backoff_factor | |||
| self.scale_window = growth_interval | |||
| self._init_growth_tracker = 0 | |||
| # for mindspore | |||
| self.counter = Parameter(tensor(0, dtype=int32), name="counter", requires_grad=False) | |||
| self._per_optimizer_states = defaultdict(_refresh_per_optimizer_state) | |||
| def _check_inf(self, grads): | |||
| return {'all': ms.ops.logical_not(all_finite(grads))} | |||
| def scale(self, outputs): | |||
| if not self._enabled: | |||
| return outputs | |||
| return DynamicLossScaler.scale(self, outputs) | |||
| def unscale_(self, optimizer, grads): | |||
| if not self._enabled: | |||
| return | |||
| optimizer_state = self._per_optimizer_states[id(optimizer)] | |||
| if optimizer_state["stage"] is OptState.UNSCALED: | |||
| raise RuntimeError("unscale_() has already been called on this optimizer since the last update().") | |||
| elif optimizer_state["stage"] is OptState.STEPPED: | |||
| raise RuntimeError("unscale_() is being called after step().") | |||
| optimizer_state['found_inf_per_device'] = self._check_inf(grads) | |||
| if graph_mode_condition(): | |||
| raise RuntimeError("Under graph mode, GradScalar not support unscale_(), please use unscale(). " | |||
| "Example: change 'scaler.unscale_(optimizer, grads)' to " | |||
| "'grads = scaler.unscale(optimizer, grads)'") | |||
| _hypermap(_assign, grads, DynamicLossScaler.unscale(self, grads)) | |||
| optimizer_state["stage"] = OptState.UNSCALED | |||
| def unscale(self, optimizer, grads): | |||
| if not self._enabled: | |||
| return grads | |||
| optimizer_state = self._per_optimizer_states[id(optimizer)] | |||
| optimizer_state["found_inf_per_device"] = self._check_inf(grads) | |||
| optimizer_state["stage"] = OptState.UNSCALED | |||
| return DynamicLossScaler.unscale(self, grads) | |||
| def _maybe_opt_step(self, optimizer, grads, optimizer_state, *args, **kwargs): | |||
| retval = None | |||
| if not sum(v.asnumpy().tolist() for v in optimizer_state["found_inf_per_device"].values()): | |||
| retval = optimizer.step(grads, *args, **kwargs) | |||
| return retval | |||
| def step(self, optimizer, grads, *args, **kwargs): | |||
| if not self._enabled: | |||
| return optimizer.step(grads) | |||
| if "closure" in kwargs: | |||
| raise RuntimeError("Closure use is not currently supported if GradScaler is enabled.") | |||
| optimizer_state = self._per_optimizer_states[id(optimizer)] | |||
| if optimizer_state["stage"] is OptState.STEPPED: | |||
| raise RuntimeError("step() has already been called since the last update().") | |||
| retval = None | |||
| if (hasattr(optimizer, "_step_supports_amp_scaling") and optimizer._step_supports_amp_scaling): | |||
| kwargs_ = kwargs | |||
| has_grad_scaler_kwarg = "grad_scaler" in inspect.signature(optimizer.step).parameters | |||
| if has_grad_scaler_kwarg: | |||
| warnings.warn( | |||
| "GradScaler is going to stop passing itself as a keyword argument to the passed " | |||
| "optimizer. In the near future GradScaler registers `grad_scale: Tensor` and " | |||
| "`found_inf: Tensor` to the passed optimizer and let the optimizer use them directly.", | |||
| FutureWarning) | |||
| kwargs_.update({"grad_scaler": self}) | |||
| else: | |||
| scaler = self._get_scale_async() | |||
| found_inf = optimizer_state["found_inf_per_device"] | |||
| optimizer.grad_scale = None if optimizer_state["stage"] == OptState.UNSCALED else scaler | |||
| optimizer.found_inf = found_inf | |||
| retval = optimizer.step(grads, *args, **kwargs_) | |||
| optimizer_state["stage"] = OptState.STEPPED | |||
| if not has_grad_scaler_kwarg: | |||
| del optimizer.grad_scale | |||
| del optimizer.found_inf | |||
| return retval | |||
| if optimizer_state["stage"] is OptState.READY: | |||
| self.unscale_(optimizer, grads) | |||
| retval = self._maybe_opt_step(optimizer, grads, optimizer_state, *args, **kwargs) | |||
| optimizer_state["stage"] = OptState.STEPPED | |||
| return retval | |||
| def adjust(self, grads_finite): | |||
| one = ops.ones((), self.scale_value.dtype) | |||
| scale_mul_factor = self.scale_value * self.scale_factor | |||
| scale_value = ops.select( | |||
| grads_finite, | |||
| ops.select( | |||
| self.counter == (self.scale_window - 1), | |||
| ops.select(ops.isfinite(scale_mul_factor), | |||
| scale_mul_factor, | |||
| self.scale_value), | |||
| self.scale_value), | |||
| ops.maximum(one, self.scale_value * self._backoff_factor)) | |||
| ops.assign(self.scale_value, scale_value) | |||
| counter = ((self.counter + 1) % self.scale_window) * grads_finite | |||
| ops.assign(self.counter, counter) | |||
| return True | |||
| def update(self, new_scale=None): | |||
| if not self._enabled: | |||
| return | |||
| if new_scale is not None: | |||
| # Accept a new user-defined scale. | |||
| if isinstance(new_scale, float): | |||
| self.scale_value.set_data(ms.Tensor(new_scale)) | |||
| else: | |||
| self.scale_value.set_data(new_scale) | |||
| else: | |||
| found_infs = [found_inf | |||
| for state in self._per_optimizer_states.values() | |||
| for found_inf in state["found_inf_per_device"].values()] | |||
| found_inf_combined = found_infs[0] | |||
| if len(found_infs) > 1: | |||
| for i in range(1, len(found_infs)): | |||
| found_inf_combined = ms.ops.logical_or(found_inf_combined, found_infs[i]) | |||
| self.adjust(ms.ops.logical_not(found_inf_combined)) | |||
| def _get_scale_async(self): | |||
| return self.scale_value | |||
| def get_scale(self): | |||
| if self._enabled: | |||
| return self._init_scale if self.scale_value is None \ | |||
| else self._get_scale_async().item() | |||
| else: | |||
| return 1.0 | |||
| def get_growth_factor(self): | |||
| return self.scale_factor | |||
| def set_growth_factor(self, new_factor): | |||
| self.scale_factor = new_factor | |||
| def get_backoff_factor(self): | |||
| return self._backoff_factor | |||
| def set_backoff_factor(self, new_factor): | |||
| self._backoff_factor = new_factor | |||
| def get_growth_interval(self): | |||
| return self.scale_window | |||
| def set_growth_interval(self, new_interval): | |||
| self.scale_window = new_interval | |||
| def _get_growth_tracker(self): | |||
| if self._enabled: | |||
| return self._init_growth_tracker if self.counter is None else self.counter.item() | |||
| else: | |||
| return 0 | |||
| def is_enabled(self): | |||
| return self._enabled | |||
| def state_dict(self): | |||
| return {"scale": self.get_scale(), | |||
| "growth_factor": self.scale_factor, | |||
| "backoff_factor": self._backoff_factor, | |||
| "growth_interval": self.scale_window, | |||
| "_growth_tracker": self._get_growth_tracker()} if self._enabled else {} | |||
| def load_state_dict(self, state_dict): | |||
| if not self._enabled: | |||
| return | |||
| if len(state_dict) == 0: | |||
| raise RuntimeError("The source state dict is empty, possibly because it was saved " | |||
| "from a disabled instance of GradScaler.") | |||
| self._init_scale = state_dict["scale"] | |||
| if self.scale_value is not None: | |||
| self.scale_value.set_data(state_dict["scale"]) | |||
| self.scale_factor = state_dict["growth_factor"] | |||
| self._backoff_factor = state_dict["backoff_factor"] | |||
| self.scale_window = state_dict["growth_interval"] | |||
| if self.counter is not None: | |||
| self.counter.set_data(state_dict["_growth_tracker"]) | |||
| def __getstate__(self): | |||
| state = self.__dict__.copy() | |||
| if self._enabled: | |||
| state['scale_value'] = state['scale_value'].asnumpy() | |||
| state['counter'] = state['counter'].asnumpy() | |||
| return state | |||
| def __setstate__(self, state): | |||
| if 'init_scale' in state: | |||
| state['scale_value'] = Parameter(tensor(state['init_scale'].numpy()).to(float32)) | |||
| del state['init_scale'] | |||
| if 'scale_value' in state: | |||
| state['scale_value'] = Parameter(tensor(state['scale_value']).to(float32)) | |||
| if 'counter' in state: | |||
| state['counter'] = Parameter(tensor(state['counter']).to(int32)) | |||
| if 'growth_factor' in state: | |||
| state['scale_factor'] = state['growth_factor'] | |||
| del state['growth_factor'] | |||
| if 'growth_interval' in state: | |||
| state['scale_window'] = state['growth_interval'] | |||
| del state['growth_interval'] | |||
| self.__dict__.update(state) | |||
+ 234
- 111
msadapter/pytorch/functional.py
View File
| @@ -3,27 +3,28 @@ import warnings | |||
| import numbers | |||
| # from functools import lru_cache | |||
| from copy import deepcopy | |||
| from builtins import max as python_max | |||
| import numpy as np | |||
| from scipy import signal | |||
| import mindspore as ms | |||
| from mindspore import ops | |||
| from mindspore.common import dtype as mstype | |||
| from mindspore.scipy.ops import SolveTriangular | |||
| from mindspore.ops.primitive import _primexpr | |||
| from mindspore.ops._primitive_cache import _get_cache_prim | |||
| from msadapter.pytorch.tensor import tensor, cast_to_ms_tensor, cast_to_adapter_tensor, custom_matmul | |||
| from msadapter.utils import unsupported_attr, get_backend, pynative_mode_condition, is_under_gpu_context, \ | |||
| is_under_ascend_context, _infer_size, \ | |||
| set_name_tuple, set_multiple_name_tuple, _get_ms_type, INT32_MIN, INT64_MIN, \ | |||
| INT32_MAX, INT64_MAX | |||
| is_under_ascend_context, _infer_size, promote_type_lookup, bitwise_adapter, set_name_tuple, _get_ms_type, \ | |||
| set_multiple_name_tuple, INT32_MIN, INT64_MIN, INT32_MAX, INT64_MAX, FP64_MAX, FP64_MIN, FP32_MAX, FP32_MIN | |||
| from msadapter.pytorch.tensor import Tensor as adapter_tensor | |||
| from msadapter.pytorch.common._inner import _out_inplace_assign, _out_limit_pynative, \ | |||
| _out_inplace_assign_with_adapter_tensor | |||
| from msadapter.pytorch.common.dtype import _TypeDict, all_int_type, all_float_type, all_complex_type, \ | |||
| all_int_type_with_bool | |||
| _out_inplace_assign_with_adapter_tensor | |||
| from msadapter.pytorch.common.dtype import _TypeDict, all_int_type, all_float_type, all_complex_type, finfo | |||
| from msadapter.pytorch.common.device import Device | |||
| from msadapter.pytorch.linalg import lu_solve as linalg_lu_solve | |||
| from msadapter.pytorch.linalg import matrix_power as linalg_matrix_power | |||
| from msadapter.pytorch.linalg import svdvals | |||
| from msadapter.pytorch._register_numpy_primitive import poisson_op | |||
| def empty(*size, out=None, dtype=None, layout=None, \ | |||
| @@ -50,44 +51,57 @@ def eye(n, m=None, *, out=None, dtype=None, layout=None, \ | |||
| unsupported_attr(layout) | |||
| unsupported_attr(device) | |||
| unsupported_attr(requires_grad) | |||
| if m is None: | |||
| m = n | |||
| if dtype is None: | |||
| dtype = ms.float32 | |||
| output = ms.ops.eye(n, m, dtype) | |||
| return _out_inplace_assign(out, output, "eye") | |||
| @_primexpr | |||
| def _get_max_prec(dtypes): | |||
| all_dtypes_sorted = (mstype.bool_, mstype.uint8, mstype.int8, mstype.int16, mstype.int32, mstype.int64, \ | |||
| mstype.float16, mstype.float32, mstype.float64) | |||
| max_prec_rank = all_dtypes_sorted.index(dtypes[0]) | |||
| need_convert = False | |||
| # if dtypes contain both and only uint8 and int8 (i.e. max_prec = int8 && contains uint8), convert to int16 | |||
| uint8_flag = False | |||
| for tensor_dtype in dtypes: | |||
| if tensor_dtype == mstype.uint8: | |||
| uint8_flag = True | |||
| cur_prec_rank = all_dtypes_sorted.index(tensor_dtype) | |||
| need_convert = True if max_prec_rank != cur_prec_rank else need_convert | |||
| max_prec_rank = cur_prec_rank if max_prec_rank < cur_prec_rank else max_prec_rank | |||
| if max_prec_rank == all_dtypes_sorted.index(mstype.int8) and uint8_flag: | |||
| max_prec = mstype.int16 | |||
| else: | |||
| max_prec = all_dtypes_sorted[max_prec_rank] | |||
| return need_convert, max_prec | |||
| def cat(tensors, dim=0, *, out=None): | |||
| def _tensor_seq_input_warning(tensors, name): | |||
| if tensors is None: | |||
| raise ValueError('`tensors` in `{}` should not be None'.format(cat.__name__)) | |||
| raise ValueError('`tensors` in `{}` should not be None'.format(name)) | |||
| if not isinstance(tensors, (tuple, list)): | |||
| raise TypeError('`tensors` in `{}` should be tuple or list'.format(cat.__name__)) | |||
| if is_under_ascend_context(): | |||
| _rank = len(tensors[0].shape) | |||
| dim = dim if dim >= 0 else dim + _rank | |||
| raise TypeError('`tensors` in `{}` should be tuple or list'.format(name)) | |||
| def _get_inputs_of_same_max_dtype(inputs): | |||
| inputs = list(inputs) | |||
| input_dtypes = [] | |||
| for input in inputs: | |||
| input_dtypes += [input.dtype,] | |||
| need_convert, max_prec = _get_max_prec(input_dtypes) | |||
| if need_convert: | |||
| for i in range(len(inputs)): | |||
| inputs[i] = inputs[i].to(max_prec) | |||
| return inputs | |||
| def cat(tensors, dim=0, *, out=None): | |||
| _tensor_seq_input_warning(tensors, cat.__name__) | |||
| inputs = cast_to_ms_tensor(tensors) | |||
| output = ops.concat(inputs, dim) | |||
| output = ms.ops.cat(_get_inputs_of_same_max_dtype(inputs), axis=dim) | |||
| return _out_inplace_assign(out, output, "cat") | |||
| def concat(tensors, dim=0, *, out=None): | |||
| if tensors is None: | |||
| raise ValueError('`tensors` in `{}` should not be None'.format(concat.__name__)) | |||
| if not isinstance(tensors, (tuple, list)): | |||
| raise TypeError('`tensors` in `{}` should be tuple or list'.format(concat.__name__)) | |||
| if is_under_ascend_context(): | |||
| _rank = len(tensors[0].shape) | |||
| dim = dim if dim >= 0 else dim + _rank | |||
| _tensor_seq_input_warning(tensors, concat.__name__) | |||
| inputs = cast_to_ms_tensor(tensors) | |||
| output = ops.concat(inputs, dim) | |||
| output = ms.ops.concat(_get_inputs_of_same_max_dtype(inputs), axis=dim) | |||
| return _out_inplace_assign(out, output, "concat") | |||
| def ones(*size, out=None, dtype=None, layout=None, | |||
| @@ -103,8 +117,9 @@ def ones(*size, out=None, dtype=None, layout=None, | |||
| def stack(tensors, dim = 0, *, out=None): | |||
| _tensor_seq_input_warning(tensors, stack.__name__) | |||
| tensors = cast_to_ms_tensor(tensors) | |||
| output = ops.stack(tensors, dim) | |||
| output = ms.ops.stack(_get_inputs_of_same_max_dtype(tensors), dim) | |||
| return _out_inplace_assign(out, output, "stack") | |||
| @@ -134,8 +149,8 @@ def chunk(input, chunks, dim=0): | |||
| def diag(input, diagonal=0, *, out=None): | |||
| # TODO | |||
| # May be use mindspore.ops.diag instead. Nowadays, this operator do not support CPU. | |||
| input = cast_to_ms_tensor(input) | |||
| output = ms.numpy.diag(input, diagonal) | |||
| # ms.numpy.diag has bug on ascend, use ms.ops.diag for diagonal=None and 1D input | |||
| output = input.diag(diagonal) | |||
| return _out_inplace_assign(out, output, "diag") | |||
| @@ -154,12 +169,16 @@ def mm(input, mat2, *, out=None): | |||
| return _out_inplace_assign_with_adapter_tensor(out, output, "mm") | |||
| def zeros(*size, out=None, dtype=None, device=None, requires_grad=False): | |||
| #TODO: adapter needs to support both positional and keywords input size to be consistent with pytorch | |||
| #positional_size represents the positional arguments of size, size represents the keywords arguments input | |||
| def zeros(*positional_size, size=None, out=None, dtype=None, device=None, requires_grad=False): | |||
| unsupported_attr(device) | |||
| unsupported_attr(requires_grad) | |||
| if isinstance(size[0], (tuple, list)): | |||
| size = size[0] | |||
| if size is None: | |||
| if isinstance(positional_size[0], (tuple, list)): | |||
| size = positional_size[0] | |||
| else: | |||
| size = positional_size | |||
| output = ms.ops.zeros(size, dtype) | |||
| return _out_inplace_assign(out, output, "zeros") | |||
| @@ -390,7 +409,11 @@ def randn(*size, out=None, dtype=None, layout=None, | |||
| if dtype is None: | |||
| dtype = ms.float32 | |||
| output = from_numpy(np.random.randn(*_size)).to(dtype) | |||
| if not _size: | |||
| output = tensor(np.random.randn(*_size), dtype=dtype) | |||
| else: | |||
| output = from_numpy(np.random.randn(*_size)).to(dtype) | |||
| if not out: | |||
| return output | |||
| return _out_inplace_assign(out, output, "randn") | |||
| @@ -534,16 +557,25 @@ def sin(input, out=None): | |||
| return _out_inplace_assign(out, output, "sin") | |||
| def max(input, dim=None, keepdim=False, *, out=None): | |||
| #TODO: not supper max(input, other) | |||
| # To achieve the polymorphism torch.max(Tensor input, Tensor other, *, Tensor out) | |||
| # other=None is used to represent the keywords param input | |||
| def max(input, dim=None, keepdim=False, other=None, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| type = input.dtype | |||
| input = input.astype(ms.float32) | |||
| if other is not None: | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.maximum(input, other).astype(type) | |||
| return _out_inplace_assign(out, output, "max") | |||
| if isinstance(dim, adapter_tensor): | |||
| other = cast_to_ms_tensor(dim) | |||
| output = ms.ops.maximum(input, other).astype(type) | |||
| return _out_inplace_assign(out, output, "max") | |||
| if dim is None: | |||
| output = input.max(axis=dim, keepdims=keepdim).astype(type) | |||
| return _out_inplace_assign(out, output, "max") | |||
| value, indice = ms.ops.max(input, dim, keepdim) | |||
| value = value.astype(type) | |||
| indice = indice.astype(ms.int64) | |||
| if pynative_mode_condition(): | |||
| point = set_name_tuple('max') | |||
| rlt = point(cast_to_adapter_tensor(value), cast_to_adapter_tensor(indice)) | |||
| @@ -561,14 +593,23 @@ def max(input, dim=None, keepdim=False, *, out=None): | |||
| return cast_to_adapter_tensor(value), cast_to_adapter_tensor(indice) | |||
| def min(input, dim=None, keepdim=False, *, out=None): | |||
| # TODO: Right Now, not support 'min(input, other, *, out=None)' | |||
| # To achieve the polymorphism torch.min(Tensor input, Tensor other, *, Tensor out) | |||
| # other=None is used to represent the keywords param input | |||
| def min(input, dim=None, keepdim=False, other=None, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| type = input.dtype | |||
| input = input.astype(ms.float32) | |||
| if other is not None: | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.minimum(input, other).astype(type) | |||
| return _out_inplace_assign(out, output, "min") | |||
| if isinstance(dim, adapter_tensor): | |||
| dim = cast_to_ms_tensor(dim) | |||
| output = ms.ops.minimum(input, dim).astype(type) | |||
| return _out_inplace_assign(out, output, "min") | |||
| if dim is None: | |||
| output = input.min(dim, keepdim).astype(type) | |||
| return _out_inplace_assign(out, output, "min") | |||
| result, indices = ms.ops.min(input, dim, keepdim) | |||
| result = result.astype(type) | |||
| if pynative_mode_condition(): | |||
| @@ -646,10 +687,13 @@ def pow(input, exponent, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| exponent = cast_to_ms_tensor(exponent) | |||
| output = ms.ops.pow(input, exponent) | |||
| if output.dtype == ms.int64: | |||
| output = ms.ops.where(((output <= INT64_MIN) | (output >= INT64_MAX)), 0, output) | |||
| elif output.dtype == ms.int32: | |||
| output = ms.ops.where(((output <= INT32_MIN) | (output >= INT32_MAX)), 0, output) | |||
| if not is_under_ascend_context(): | |||
| #TODO: ((output <= MIN) | (output >= MAX)) compute returns error on Ascend. | |||
| # Because currently Ascend not support bool type input in [BitwiseOr] | |||
| if output.dtype == ms.int64: | |||
| output = ms.ops.where(((output <= INT64_MIN) | (output >= INT64_MAX)), 0, output) | |||
| elif output.dtype == ms.int32: | |||
| output = ms.ops.where(((output <= INT32_MIN) | (output >= INT32_MAX)), 0, output) | |||
| return _out_inplace_assign(out, output, "pow") | |||
| @@ -704,7 +748,6 @@ def median(input, dim=None, keepdim=False, *, out=None): | |||
| return _out_inplace_assign_with_adapter_tensor(out, output, "median") | |||
| def matmul(input, other, *, out=None): | |||
| # TODO: ms.ops.matmul not support int-dtype input on GPU, only support float dtype input | |||
| input = cast_to_ms_tensor(input) | |||
| other = cast_to_ms_tensor(other) | |||
| # TODO: repalce with output = ms.ops.matmul(input, other) | |||
| @@ -776,7 +819,7 @@ def cumsum(input, dim, *, dtype=None, out=None): | |||
| def einsum(equation, *operands): | |||
| output = _get_cache_prim(ms.ops.Einsum)(equation=equation)(operands) | |||
| output = ms.ops.einsum(equation=equation, *operands) | |||
| return cast_to_adapter_tensor(output) | |||
| @@ -792,9 +835,7 @@ def histogram(input, bins, *, range=None, weight=None, density=False, out=None): | |||
| def triu(input, diagonal=0, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| input = ms.numpy.array(input) | |||
| output = ms.numpy.triu(input, diagonal) | |||
| output = cast_to_adapter_tensor(output) | |||
| output = ms.ops.triu(input, diagonal) | |||
| return _out_inplace_assign(out, output, "triu") | |||
| def unbind(input, dim=0): | |||
| @@ -837,7 +878,14 @@ def view_as_real(input): | |||
| input = cast_to_ms_tensor(input) | |||
| real = ms.ops.expand_dims(ms.ops.real(input), axis=-1) | |||
| imag = ms.ops.expand_dims(ms.ops.imag(input), axis=-1) | |||
| output = ms.ops.cat((real, imag), axis=-1) | |||
| #TODO: Currently [Cat] not support float64 on Ascend | |||
| if is_under_ascend_context() and (real.dtype == ms.float64 or imag.dtype == ms.float64): | |||
| real = real.astype(ms.float32) | |||
| imag = imag.astype(ms.float32) | |||
| output = ms.ops.cat((real, imag), axis=-1) | |||
| output = output.astype(ms.float64) | |||
| else: | |||
| output = ms.ops.cat((real, imag), axis=-1) | |||
| return cast_to_adapter_tensor(output) | |||
| @@ -1060,21 +1108,39 @@ def bitwise_not(input, *, out=None): | |||
| def bitwise_and(input, other, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.bitwise_and(input, other) | |||
| #TODO: currently bitwise operations on Ascend not support bool type | |||
| if is_under_ascend_context(): | |||
| input, other, output_dtype = bitwise_adapter(input, other) | |||
| output = ms.ops.bitwise_and(input, other) | |||
| output = output.astype(output_dtype) | |||
| else: | |||
| output = ms.ops.bitwise_and(input, other) | |||
| return _out_inplace_assign(out, output, "bitwise_and") | |||
| def bitwise_or(input, other, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.bitwise_or(input, other) | |||
| #TODO: currently bitwise operations on Ascend not support bool type | |||
| if is_under_ascend_context(): | |||
| input, other, output_dtype = bitwise_adapter(input, other) | |||
| output = ms.ops.bitwise_or(input, other) | |||
| output = output.astype(output_dtype) | |||
| else: | |||
| output = ms.ops.bitwise_or(input, other) | |||
| return _out_inplace_assign(out, output, "bitwise_or") | |||
| def bitwise_xor(input, other, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.bitwise_xor(input, other) | |||
| #TODO: currently bitwise operations on Ascend not support bool type | |||
| if is_under_ascend_context(): | |||
| input, other, output_dtype = bitwise_adapter(input, other) | |||
| output = ms.ops.bitwise_xor(input, other) | |||
| output = output.astype(output_dtype) | |||
| else: | |||
| output = ms.ops.bitwise_xor(input, other) | |||
| return _out_inplace_assign(out, output, "bitwise_xor") | |||
| @@ -1240,10 +1306,17 @@ def floor_divide(input, other, *, out=None): | |||
| def frexp(input, *, out=None): | |||
| # TODO: to use ms.ops.frexp | |||
| input = cast_to_ms_tensor(input) | |||
| sign = ms.ops.sign(input) | |||
| input = ms.ops.abs(input) | |||
| exp = ms.ops.floor(ms.ops.log2(input)) + 1 | |||
| mantissa = input * sign / (2 ** exp) | |||
| if input.dtype == ms.float16: | |||
| input = input.astype(ms.float32) | |||
| sign = ms.ops.sign(input) | |||
| input = ms.ops.abs(input) | |||
| exp = ms.ops.floor(ms.ops.log2(input)) + 1 | |||
| mantissa = (input * sign / (2 ** exp)).astype(ms.float16) | |||
| else: | |||
| sign = ms.ops.sign(input) | |||
| input = ms.ops.abs(input) | |||
| exp = ms.ops.floor(ms.ops.log2(input)) + 1 | |||
| mantissa = input * sign / (2 ** exp) | |||
| output = (mantissa, exp.astype(ms.int32)) | |||
| return _out_inplace_assign(out, output, "frexp") | |||
| @@ -1518,27 +1591,13 @@ def nan_to_num(input, nan=0.0, posinf=None, neginf=None, *, out=None): | |||
| def neg(input, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| #TODO: currently [Neg] not support uint8, mindspore 2.1 will support | |||
| if input.dtype == ms.uint8: | |||
| input_dtype = input.dtype | |||
| input = input.astype(ms.float32) | |||
| output = ms.ops.neg(input) | |||
| output = output.astype(input_dtype) | |||
| else: | |||
| output = ms.ops.neg(input) | |||
| output = ms.ops.neg(input) | |||
| return _out_inplace_assign(out, output, "neg") | |||
| def negative(input, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| #TODO: currently [Neg] not support uint8, mindspore 2.1 will support | |||
| if input.dtype == ms.uint8: | |||
| input_dtype = input.dtype | |||
| input = input.astype(ms.float32) | |||
| output = input.negative() | |||
| output = output.astype(input_dtype) | |||
| else: | |||
| output = input.negative() | |||
| output = input.negative() | |||
| return _out_inplace_assign(out, output, "negative") | |||
| def nextafter(input, other, *, out=None): | |||
| @@ -1570,6 +1629,13 @@ def real(input): | |||
| def reciprocal(input, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| output = ms.ops.reciprocal(input) | |||
| #TODO: GPU has problem handling boundary value | |||
| if is_under_gpu_context(): | |||
| output_dtype = output.dtype | |||
| if output_dtype == ms.float32: | |||
| output = ms.ops.where((output <= FP32_MIN) | (output >= FP32_MAX), float('inf'), output) | |||
| if output_dtype == ms.float64: | |||
| output = ms.ops.where((output <= FP64_MIN) | (output >= FP64_MAX), float('inf'), output) | |||
| return _out_inplace_assign(out, output, "reciprocal") | |||
| @@ -1581,19 +1647,17 @@ def remainder(input, other, *, out=None): | |||
| def rsqrt(input, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| if input.dtype in all_int_type_with_bool: | |||
| input = input.astype(ms.float32) | |||
| output = ms.ops.rsqrt(input) | |||
| return _out_inplace_assign(out, output, "rsqrt") | |||
| output = input.rsqrt() | |||
| return _out_inplace_assign_with_adapter_tensor(out, output, "rsqrt") | |||
| def roll(input, shifts, dims=None, *, out=None): | |||
| output = input.roll(shifts, dims=dims) | |||
| return _out_inplace_assign_with_adapter_tensor(out, output, "roll") | |||
| def rot90(input, k, dims, *, out=None): | |||
| output = input.rot90(k, dims) | |||
| return _out_inplace_assign_with_adapter_tensor(out, output, "rot90") | |||
| input_ms = cast_to_ms_tensor(input) | |||
| output = ms.ops.rot90(input_ms, k, dims) | |||
| return _out_inplace_assign(out, output, "rot90") | |||
| def sgn(input, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| @@ -1802,8 +1866,6 @@ def diff(input, n=1, dim=-1, prepend=None, append=None): | |||
| def flip(input, dims): | |||
| input = cast_to_ms_tensor(input) | |||
| if isinstance(dims, list): | |||
| dims = tuple(dims) | |||
| output = ms.ops.flip(input, dims) | |||
| return cast_to_adapter_tensor(output) | |||
| @@ -1887,14 +1949,6 @@ def masked_select(input, mask, *, out=None): | |||
| output = ms.ops.masked_select(x, mask) | |||
| return _out_inplace_assign(out, output, "masked_select") | |||
| @_primexpr | |||
| # @lru_cache(_GLOBAL_LRU_CACHE_SIZE) | |||
| def _get_select_out_shape(input_shape, dim): | |||
| shape = [input_shape[i] for i in range(len(input_shape)) if i != dim] | |||
| return tuple(shape) | |||
| def select(input, dim, index): | |||
| return input.select(dim, index) | |||
| @@ -1995,9 +2049,7 @@ def count_nonzero(input, dim=None): | |||
| def all(input, dim=(), keepdim=False, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| if input.dtype != ms.bool_: | |||
| input = input.astype(ms.bool_) | |||
| output = input.all(axis=dim, keep_dims=keepdim) | |||
| output = ms.ops.all(input, axis=dim, keep_dims=keepdim) | |||
| return _out_inplace_assign(out, output, "all") | |||
| def scatter(input, dim, index, src): | |||
| @@ -2043,6 +2095,12 @@ def cholesky_inverse(input, upper=False, *, out=None): | |||
| output = input.cholesky_inverse(upper) | |||
| return _out_inplace_assign(out, output, "cholesky_inverse") | |||
| def cholesky_solve(input, input2, upper=False, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| input2 = cast_to_ms_tensor(input2) | |||
| output = ms.ops.cholesky_solve(input, input2, upper) | |||
| return _out_inplace_assign(out, output, "cholesky_solve") | |||
| def dist(input, other, p=2): | |||
| _input = cast_to_ms_tensor(input) | |||
| _other = cast_to_ms_tensor(other) | |||
| @@ -2201,14 +2259,20 @@ def vdot(input, other, *, out=None): | |||
| other = cast_to_ms_tensor(other) | |||
| if input.is_complex(): | |||
| input = ms.ops.conj(input) | |||
| output = ms.ops.inner(input, other) | |||
| if (is_under_gpu_context() and (input.dtype in all_int_type)) or \ | |||
| (is_under_ascend_context() and (input.dtype in (ms.float64,) + all_int_type)): | |||
| warnings.warn("For vdot, input with int64 type has risk of being truncated.") | |||
| input_dtype = input.dtype | |||
| input = input.astype(ms.float32) | |||
| other = other.astype(ms.float32) | |||
| output = ms.ops.inner(input, other).astype(input_dtype) | |||
| else: | |||
| output = ms.ops.inner(input, other) | |||
| return _out_inplace_assign(out, output, "vdot") | |||
| def inner(input, other, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| other = cast_to_ms_tensor(other) | |||
| # TODO: ms.ops.inner(ms.Tensor(2), ms.Tensor([3.2, 4.1])) will not return float type, but int type. | |||
| output = ms.ops.inner(input, other) | |||
| output = input.inner(other) | |||
| return _out_inplace_assign(out, output, "inner") | |||
| def repeat_interleave(input, repeats, dim=None, *, output_size=None): | |||
| @@ -2260,8 +2324,9 @@ def tile(input, dims): | |||
| return input.tile(dims) | |||
| def vstack(tensors, *, out=None): | |||
| _tensor_seq_input_warning(tensors, vstack.__name__) | |||
| tensors = cast_to_ms_tensor(tensors) | |||
| output = ms.ops.vstack(tensors) | |||
| output = ms.ops.vstack(_get_inputs_of_same_max_dtype(tensors)) | |||
| return _out_inplace_assign(out, output, "vstack") | |||
| def flipud(input): | |||
| @@ -2313,9 +2378,9 @@ def logspace(start, end, steps, base=10.0, *, out=None, dtype=None, layout=None, | |||
| unsupported_attr(layout) | |||
| unsupported_attr(device) | |||
| unsupported_attr(requires_grad) | |||
| # TODO: ms.ops.logspace to support float type `base`, number type `start` and `end | |||
| start = ms.Tensor(start, dtype=dtype) | |||
| end = ms.Tensor(end, dtype=dtype) | |||
| # TODO: ms.ops.logspace only support base is int type | |||
| if base % 1 != 0: | |||
| raise ValueError("For logspace, base only support integer") | |||
| base = int(base) | |||
| @@ -2332,13 +2397,15 @@ def logspace(start, end, steps, base=10.0, *, out=None, dtype=None, layout=None, | |||
| return _out_inplace_assign(out, output, "logspace") | |||
| def column_stack(tensors, *, out=None): | |||
| _tensor_seq_input_warning(tensors, column_stack.__name__) | |||
| tensors = cast_to_ms_tensor(tensors) | |||
| output = ms.ops.column_stack(tensors) | |||
| output = ms.ops.column_stack(_get_inputs_of_same_max_dtype(tensors)) | |||
| return _out_inplace_assign(out, output, "column_stack") | |||
| def hstack(tensors, *, out=None): | |||
| _tensor_seq_input_warning(tensors, hstack.__name__) | |||
| tensors = cast_to_ms_tensor(tensors) | |||
| output = ms.ops.hstack(tensors) | |||
| output = ms.ops.hstack(_get_inputs_of_same_max_dtype(tensors)) | |||
| return _out_inplace_assign(out, output, "hstack") | |||
| def movedim(input, source, destination): | |||
| @@ -2367,8 +2434,9 @@ def swapaxes(input, axis0, axis1): | |||
| return cast_to_adapter_tensor(output) | |||
| def row_stack(tensors, *, out=None): | |||
| _tensor_seq_input_warning(tensors, row_stack.__name__) | |||
| tensors = cast_to_ms_tensor(tensors) | |||
| output = ms.ops.vstack(tensors) | |||
| output = ms.ops.vstack(_get_inputs_of_same_max_dtype(tensors)) | |||
| return _out_inplace_assign(out, output, "row_stack") | |||
| def matrix_exp(A): | |||
| @@ -2561,9 +2629,9 @@ def select_scatter(input, src, dim, index): | |||
| return input.select_scatter(src, dim, index) | |||
| def dstack(tensors, *, out=None): | |||
| # TODO: set output dtype to the dtype of tensor with higher accuracy | |||
| _tensor_seq_input_warning(tensors, dstack.__name__) | |||
| tensors = cast_to_ms_tensor(tensors) | |||
| output = ms.ops.dstack(tensors) | |||
| output = ms.ops.dstack(_get_inputs_of_same_max_dtype(tensors)) | |||
| return _out_inplace_assign(out, output, "dstack") | |||
| def randint_like(input, low=None, high=None, *, dtype=None, | |||
| @@ -2704,14 +2772,21 @@ def bernoulli(input, *, generator=None, out=None): | |||
| output = input.bernoulli(generator=generator) | |||
| return _out_inplace_assign(out, output, "bernoulli") | |||
| #TODO: Currently not support float64 dtype | |||
| def histogramdd(input, bins=10, *, range=None, weight=None, density=False, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| input_dtype = input.dtype | |||
| #TODO: Currently not support ops func | |||
| if range is not None: | |||
| range = ms.ops.reshape(ms.Tensor(range), (-1, input.shape[1])) | |||
| range = cast_to_adapter_tensor(range).tolist() | |||
| hist, bin_edges = ms.numpy.histogramdd(input, bins=bins, range=range, weights=weight, density=density) | |||
| if input_dtype == ms.float64: | |||
| #TODO: histogramdd currently not support float64 dtype | |||
| input = input.astype(ms.float32) | |||
| hist, bin_edges = ms.numpy.histogramdd(input, bins=bins, range=range, weights=weight, density=density) | |||
| hist = hist.astype(input_dtype) | |||
| bin_edges = [bin_edge.to(ms.float64) for bin_edge in bin_edges] | |||
| else: | |||
| hist, bin_edges = ms.numpy.histogramdd(input, bins=bins, range=range, weights=weight, density=density) | |||
| output = (hist, bin_edges) | |||
| if pynative_mode_condition(): | |||
| svd_namedtuple = set_multiple_name_tuple('histogramdd', 'hist, bin_edges') | |||
| @@ -2989,5 +3064,53 @@ def use_deterministic_algorithms(mode, *, warn_only=False): | |||
| def diagonal_scatter(input, src, offset=0, dim1=0, dim2=1): | |||
| return input.diagonal_scatter(src, offset, dim1, dim2) | |||
| def narrow_copy(input, dim, start, length, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| output = ms.ops.narrow(input, dim, start, length) | |||
| return _out_inplace_assign(out, output, "narrow_copy") | |||
| lu_solve = linalg_lu_solve | |||
| matrix_power = linalg_matrix_power | |||
| def nanmedian(input, dim=None, keepdim=False, *, out=None): | |||
| output = input.nanmedian(dim=dim, keepdim=keepdim) | |||
| return _out_inplace_assign_with_adapter_tensor(out, output, "nanmedian") | |||
| def promote_types(type1, type2): | |||
| return promote_type_lookup(type1, type2) | |||
| def matrix_rank(A, *, tol=None, symmetric=False, out=None): | |||
| A = cast_to_ms_tensor(A) | |||
| # TODO: when symmetric=True, calculation will be complete using eigenvalue decomposition, which is consistent with | |||
| # the result returned by SVD decomposition. | |||
| unsupported_attr(symmetric) | |||
| s = svdvals(A) | |||
| if tol is None: | |||
| tol = s.max() * python_max(A.shape) * finfo(s.dtype).eps | |||
| output = ms.ops.sum((s > tol).astype(ms.int64), dim=-1) | |||
| return _out_inplace_assign(out, output, "matrix_rank") | |||
| def ormqr(input, tau, other, left=True, transpose=False, *, out=None): | |||
| if not is_under_gpu_context(): | |||
| raise NotImplementedError("ormqr currently not supported on CPU nor Ascend") | |||
| else: | |||
| input = cast_to_ms_tensor(input) | |||
| tau = cast_to_ms_tensor(tau) | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.ormqr(input, tau, other, left, transpose) | |||
| return _out_inplace_assign(out, output, "ormqr") | |||
| def triangular_solve(b, A, upper=True, transpose=False, unitriangular=False, *, out=None): | |||
| if is_under_ascend_context(): | |||
| raise NotImplementedError("triangular_solve currently not supported on Ascend") | |||
| B = cast_to_ms_tensor(b) | |||
| A = cast_to_ms_tensor(A) | |||
| trans = 'T' if transpose else 'N' | |||
| solve_op = _get_cache_prim(SolveTriangular)(lower=(not upper), unit_diagonal=unitriangular, trans=trans) | |||
| output = solve_op(A, B) | |||
| if pynative_mode_condition(): | |||
| triangular_solve_namedtuple = set_multiple_name_tuple('triangular_solve', 'solution, cloned_coefficient') | |||
| output = triangular_solve_namedtuple(cast_to_adapter_tensor(output), cast_to_adapter_tensor(A)) | |||
| return output | |||
| output = (output, A) | |||
| return _out_inplace_assign(out, output, "triangular_solve") | |||
+ 83
- 3
msadapter/pytorch/linalg/linalg.py
View File
| @@ -3,14 +3,16 @@ | |||
| import mindspore as ms | |||
| from mindspore.ops.primitive import _primexpr | |||
| from mindspore.ops._primitive_cache import _get_cache_prim | |||
| from mindspore.scipy.ops import SolveTriangular | |||
| from msadapter.pytorch.common._inner import _out_inplace_assign | |||
| from msadapter.utils import unsupported_attr, pynative_mode_condition, \ | |||
| is_under_gpu_context, is_under_ascend_context, set_multiple_name_tuple | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor, custom_matmul | |||
| from msadapter.pytorch.tensor import Tensor as adapter_tensor | |||
| from msadapter.pytorch._register_numpy_primitive import NumpyFullLstsq, eigvals_op, svd_op, svdvals_op, \ | |||
| lu_solve_op, lu_op, lu_factor_op, lu_factor_ex_op, \ | |||
| eigh_op, eigvalsh_op, solve_op | |||
| from msadapter.pytorch.common.dtype import finfo | |||
| from msadapter.pytorch._register_numpy_primitive import NumpyFullLstsq, eigvals_op, svd_op, svdvals_op, lu_solve_op, \ | |||
| lu_op, lu_factor_op, lu_factor_ex_op, eigh_op, eigvalsh_op, solve_op | |||
| def eigh(A, UPLO='L', *, out=None): # TODO use numpy api now | |||
| @@ -47,11 +49,38 @@ def cholesky(A, *, upper=False, out=None): | |||
| output = ms.ops.cholesky(A, upper) | |||
| return _out_inplace_assign(out, output, "cholesky") | |||
| def cholesky_ex(A, *, upper=False, check_errors=False, out=None): | |||
| #TODO: currently cholesky_ex not support check_errors=True | |||
| # TODO: ms.ops.cholesky to support complex type | |||
| if check_errors: | |||
| raise NotImplementedError("cholesky_ex currently not supported check_errors=True") | |||
| A = cast_to_ms_tensor(A) | |||
| if A.ndim > 2: | |||
| info = ms.ops.zeros(A.shape[:-2], dtype=ms.int32) | |||
| else: | |||
| info = 0 | |||
| output = ms.ops.cholesky(A, upper) | |||
| output = (output, info) | |||
| return _out_inplace_assign(out, output, "cholesky_ex") | |||
| def inv(A, *, out=None): | |||
| A = cast_to_ms_tensor(A) | |||
| output = ms.ops.inverse(A) | |||
| return _out_inplace_assign(out, output, "inv") | |||
| def inv_ex(A, *, check_errors=False, out=None): | |||
| #TODO: currently inv_ex not support check_errors=True | |||
| if check_errors: | |||
| raise NotImplementedError("inv_ex currently not supported check_errors=True") | |||
| A = cast_to_ms_tensor(A) | |||
| if A.ndim > 2: | |||
| info = ms.ops.zeros(A.shape[:-2], dtype=ms.int32) | |||
| else: | |||
| info = 0 | |||
| output = ms.ops.inverse(A) | |||
| output = (output, info) | |||
| return _out_inplace_assign(out, output, "inv_ex") | |||
| def matmul(input, other, *, out=None): | |||
| input = cast_to_ms_tensor(input) | |||
| other = cast_to_ms_tensor(other) | |||
| @@ -228,3 +257,54 @@ def vecdot(x, y, *, dim=- 1, out=None): | |||
| output = x * y | |||
| output = output.sum(axis=dim) | |||
| return _out_inplace_assign(out, output, "vecdot") | |||
| def matrix_norm(A, ord='fro', dim=(-2, -1), keepdim=False, *, dtype=None, out=None): | |||
| # `p` can not support value beside ['fro', 'nuc', inf, -inf, 0, 1, -1, 2, -2] | |||
| A = cast_to_ms_tensor(A) | |||
| if dtype is None: | |||
| dtype = A.dtype | |||
| output = ms.ops.matrix_norm(A, ord=ord, axis=dim, keepdims=keepdim, dtype=dtype) | |||
| output = output.astype(dtype) | |||
| return _out_inplace_assign(out, output, "matrix_norm") | |||
| def matrix_rank(A, *, atol=None, rtol=None, hermitian=False, out=None): | |||
| #TODO: If hermitian=True, torch will check whether the input A is a hermitian tensor, which is difficult in ms | |||
| unsupported_attr(hermitian) | |||
| A = cast_to_ms_tensor(A) | |||
| s = svdvals(A) | |||
| if atol is None: | |||
| atol = finfo(s.dtype).eps * max(A.shape) | |||
| if rtol is None: | |||
| rtol = finfo(s.dtype).eps | |||
| s1, _ = ms.ops.max(s) | |||
| s1 = s1.float() | |||
| tol = max(atol, rtol * s1) | |||
| output = ms.ops.sum((s > tol).astype(ms.int64), dim=-1) | |||
| return _out_inplace_assign(out, output, "matrix_rank") | |||
| def cross(input, other, *, dim=-1, out=None): | |||
| if is_under_gpu_context(): | |||
| raise NotImplementedError("cross currently not supported on GPU") | |||
| input = cast_to_ms_tensor(input) | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.cross(input, other, dim) | |||
| return _out_inplace_assign(out, output, "cross") | |||
| def solve_triangular(A, B, *, upper, left=True, unitriangular=False, out=None): | |||
| if is_under_ascend_context(): | |||
| raise NotImplementedError("solve_triangular currently not supported on Ascend") | |||
| if not left: | |||
| raise NotImplementedError("Currently only support left equals to True") | |||
| A = cast_to_ms_tensor(A) | |||
| B = cast_to_ms_tensor(B) | |||
| solve_op = _get_cache_prim(SolveTriangular)(lower=(not upper), unit_diagonal=unitriangular) | |||
| output = solve_op(A, B) | |||
| return _out_inplace_assign(out, output, "solve_triangular") | |||
| def cond(A, p=None, *, out=None): | |||
| A = cast_to_ms_tensor(A) | |||
| if A.dtype in (ms.float64, ms.complex128): | |||
| output = ms.ops.cond(A, p).astype(ms.float64) | |||
| else: | |||
| output = ms.ops.cond(A, p).astype(ms.float32) | |||
| return _out_inplace_assign(out, output, "cond") | |||
+ 47
- 49
msadapter/pytorch/nn/functional.py
View File
| @@ -12,7 +12,7 @@ from mindspore.ops.function.math_func import _expand, _check_same_type | |||
| # from msadapter.utils import unsupported_attr, is_under_ascend_context, _GLOBAL_LRU_CACHE_SIZE_NN | |||
| from msadapter.utils import unsupported_attr, is_under_ascend_context, is_under_gpu_context, graph_mode_condition | |||
| from msadapter.pytorch.tensor import Tensor, cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from msadapter.pytorch.tensor import Tensor, cast_to_ms_tensor, cast_to_adapter_tensor, _check_int_size | |||
| from msadapter.pytorch.common._inner import _inplace_assign_pynative, _nn_functional_inplace_assign | |||
| from msadapter.pytorch.common.dtype import all_int_type | |||
| from msadapter.pytorch.nn.modules.utils import _do_pad, _pair, _quadruple, _repeat_tuple, _single | |||
| @@ -262,21 +262,11 @@ def adaptive_max_pool3d(input, output_size, return_indices=False): | |||
| output = (output[0], output[1].astype(ms.int64)) | |||
| return cast_to_adapter_tensor(output) | |||
| def pad(input, pad, mode="constant", value=0): | |||
| if mode == "replicate": | |||
| mode = "edge" | |||
| value = ms.Tensor(value, dtype=input.dtype) | |||
| dims = len(input.shape) | |||
| list_pad = [pad[i:i+2] for i in range(0, len(pad), 2)] | |||
| list_pad.reverse() | |||
| new_pad = [[0,0],] * int((dims - len(pad) /2)) | |||
| new_pad.extend(list_pad) | |||
| def pad(input, pad, mode="constant", value=None): | |||
| # TODO: ms.ops.pad under 'reflect' do not support 3d padding | |||
| # TODO: pad---function name and input name is same will raise error on Graph mode. | |||
| input = cast_to_ms_tensor(input) | |||
| # TODO: -> ms.ops.PadV3, Padv3 is not supported on Ascend now. | |||
| # output = ms.ops.operations.nn_ops.PadV3(mode=mode)(input, pad, value) | |||
| output = ms.numpy.pad(input, new_pad, mode=mode, constant_values=value) | |||
| output = ms.ops.pad(input, pad, mode, value) | |||
| return cast_to_adapter_tensor(output) | |||
| @_primexpr | |||
| @@ -335,23 +325,24 @@ def rrelu_(input, lower=0.125, upper=0.3333333333333333, training=False): | |||
| return _nn_functional_inplace_assign(input, output, 'rrelu_', 'rrelu') | |||
| def selu(input, inplace=False): | |||
| if inplace and graph_mode_condition(): | |||
| raise ValueError("nn.selu(): inplace=True is not currently supported in GRAPH mode.") | |||
| input_ms = cast_to_ms_tensor(input) | |||
| out = ms.ops.selu(input_ms) | |||
| return _inplace_assign_pynative(input, inplace, out, "selu") | |||
| def celu(input, alpha=1.0, inplace=False): | |||
| if inplace and graph_mode_condition(): | |||
| raise ValueError("nn.celu(): inplace=True is not currently supported in GRAPH mode.") | |||
| input_ms = cast_to_ms_tensor(input) | |||
| out = ms.ops.celu(input_ms, alpha) | |||
| out = ms.ops.celu(input_ms, float(alpha)) | |||
| return _inplace_assign_pynative(input, inplace, out, "celu") | |||
| def gelu(input, approximate='none'): | |||
| input_x = cast_to_ms_tensor(input) | |||
| out = ms.ops.gelu(input_x, approximate) | |||
| return cast_to_adapter_tensor(out) | |||
| def mish(input, inplace=False): | |||
| input_ms = cast_to_ms_tensor(input) | |||
| out = ms.ops.mish(input_ms) | |||
| @@ -650,6 +641,11 @@ def cross_entropy(input, target, weight=None, size_average=None, ignore_index=-1 | |||
| input = cast_to_ms_tensor(input) | |||
| target = cast_to_ms_tensor(target) | |||
| #TODO: mindspore currently not support int64 | |||
| target_dtype = target.dtype | |||
| if target_dtype in all_int_type: | |||
| warnings.warn("cross_entropy: when target type is int64, there is risk of overflow") | |||
| target = target.astype(ms.int32) | |||
| weight = cast_to_ms_tensor(weight) | |||
| # unsupport float64 | |||
| result = ms.ops.cross_entropy(input, target, weight, ignore_index, reduction, label_smoothing) | |||
| @@ -863,41 +859,32 @@ def upsample_bilinear(input, size=None, scale_factor=None, *, align_corners=True | |||
| def pairwise_distance(x1, x2, p=2.0, eps=1e-06, keepdim=False): | |||
| x1 = cast_to_ms_tensor(x1) | |||
| x2 = cast_to_ms_tensor(x2) | |||
| input = x1-x2+eps | |||
| input = x1 - x2 + eps | |||
| input_p = ms.ops.pow(ms.ops.abs(input), p) | |||
| input_p_sum = input_p.sum(axis=-1, keepdims=keepdim) | |||
| out = ms.ops.pow(input_p_sum, 1.0 / p) | |||
| return cast_to_adapter_tensor(out) | |||
| @_primexpr | |||
| # @lru_cache(_GLOBAL_LRU_CACHE_SIZE_NN) | |||
| def get_broadcast_shape(x_shape, y_shape): | |||
| out = np.ones(x_shape) + np.ones(y_shape) | |||
| return out.shape | |||
| def cosine_similarity(x1, x2, dim=1, eps=1e-08): | |||
| # TODO: to use ms.ops.cosine_similarity, however the result of it is not as same as torch's. | |||
| x1 = cast_to_ms_tensor(x1) | |||
| x2 = cast_to_ms_tensor(x2) | |||
| while x1.ndim < x2.ndim: | |||
| x1 = x1.expand_dims(0) | |||
| while x2.ndim < x1.ndim: | |||
| x2 = x2.expand_dims(0) | |||
| if x1.size < x2.size: | |||
| x1 = ms.ops.broadcast_to(x1, x2.shape) | |||
| if x2.size < x1.size: | |||
| x2 = ms.ops.broadcast_to(x2, x1.shape) | |||
| min_value = ms.Tensor(eps, ms.float32) | |||
| x1_norm = ms.ops.pow(x1, 2) | |||
| x1_norm = x1_norm.sum(axis=dim) | |||
| x1_norm = ms.ops.pow(x1_norm, 1.0/2) | |||
| x1_norm = ms.ops.clip_by_value(x1_norm, min_value) | |||
| x2_norm = ms.ops.pow(x2, 2) | |||
| x2_norm = x2_norm.sum(axis=dim) | |||
| x2_norm = ms.ops.pow(x2_norm, 1.0/2) | |||
| x2_norm = ms.ops.clip_by_value(x2_norm, min_value) | |||
| denom = ms.ops.mul(x1_norm, x2_norm) | |||
| out = ms.ops.mul(x1, x2).sum(axis=dim)/denom | |||
| if x1.shape == x2.shape: | |||
| out = ms.ops.cosine_similarity(x1, x2, dim, eps) | |||
| return cast_to_adapter_tensor(out) | |||
| broadcast_shape = get_broadcast_shape(x1.shape, x2.shape) | |||
| x1 = ms.ops.broadcast_to(x1, broadcast_shape) | |||
| x2 = ms.ops.broadcast_to(x2, broadcast_shape) | |||
| out = ms.ops.cosine_similarity(x1, x2, dim, eps) | |||
| return cast_to_adapter_tensor(out) | |||
| def pdist(input, p=2): | |||
| #TODO: ms.ops.pdist is not on Ascend. | |||
| if is_under_ascend_context(): | |||
| @@ -919,6 +906,9 @@ def pdist(input, p=2): | |||
| select = np.triu(select, 1).astype(np.bool8) | |||
| select_t = ms.Tensor(select) | |||
| out = ms.ops.masked_select(norm, select_t) | |||
| if input.dtype == ms.float64: | |||
| warnings.warn("pdist: when input is float64, there is risk that the data will be truncated.") | |||
| out = out.astype(input.dtype) | |||
| else: | |||
| input = cast_to_ms_tensor(input) | |||
| out = ms.ops.pdist(input, float(p)) | |||
| @@ -1352,6 +1342,8 @@ def interpolate(input, | |||
| unsupported_attr(recompute_scale_factor) | |||
| unsupported_attr(antialias) | |||
| size = _check_int_size(size, "interpolate") | |||
| if mode in ("nearest", "area", "nearest-exact"): | |||
| if align_corners is not None: | |||
| raise ValueError( | |||
| @@ -1365,7 +1357,7 @@ def interpolate(input, | |||
| if recompute_scale_factor is not None and recompute_scale_factor: | |||
| # TODO: not support these two arguments until now | |||
| pass | |||
| raise NotImplementedError("recompute_scale_factor is not supported") | |||
| if antialias: | |||
| raise NotImplementedError("antialias in interpolate is not supported to True.") | |||
| @@ -1762,16 +1754,22 @@ def bilinear(input1, input2, weight, bias=None): | |||
| input1 = cast_to_ms_tensor(input1) | |||
| input2 = cast_to_ms_tensor(input2) | |||
| weight = cast_to_ms_tensor(weight) | |||
| input1_shape = input1.shape | |||
| input2_shape = input2.shape | |||
| if len(input1_shape) != 2: | |||
| input1 = input1.reshape((-1, input1_shape[-1])) | |||
| _matmul = _get_cache_prim(ms.ops.MatMul)(False, False) | |||
| x = _matmul(input1.reshape(-1, input1.shape[-1]), | |||
| weight.permute(1, 0, 2).reshape(weight.shape[1], -1)) | |||
| x = ms.ops.mul(x, ms.ops.tile(input2.reshape(-1, input2.shape[-1]), (1, weight.shape[0]))) | |||
| x = _matmul(input1, weight.permute(1, 0, 2).reshape(weight.shape[1], -1)) | |||
| if len(input2_shape) != 2: | |||
| input2 = input2.reshape((-1, input2_shape[-1])) | |||
| x = ms.ops.mul(x, ms.ops.tile(input2, (1, weight.shape[0]))) | |||
| x = x.reshape(x.shape[0], weight.shape[0], -1) | |||
| x = ms.ops.reduce_sum(x, -1) | |||
| if bias is not None: | |||
| bias = cast_to_ms_tensor(bias) | |||
| # not support float64 | |||
| x = ms.ops.bias_add(x, bias) | |||
| output = x.reshape(*input1.shape[:-1], -1) | |||
| output = x.reshape(*input1_shape[:-1], -1) | |||
| return cast_to_adapter_tensor(output) | |||
| @@ -2562,7 +2560,7 @@ def fold(input, output_size, kernel_size, dilation=1, padding=0, stride=1): | |||
| ndim = input_ms.ndim | |||
| if ndim == 2: | |||
| input_ms = input_ms.expand_dims(0) | |||
| output = ms.ops.fold(input_ms, ms.Tensor(output_size), kernel_size, dilation, padding, stride) | |||
| output = ms.ops.fold(input_ms, ms.Tensor(output_size, dtype=ms.int32), kernel_size, dilation, padding, stride) | |||
| if ndim == 2: | |||
| output = output.squeeze(0) | |||
| return cast_to_adapter_tensor(output) | |||
+ 30
- 53
msadapter/pytorch/nn/modules/adaptive.py
View File
| @@ -2,14 +2,13 @@ | |||
| # -*- coding: utf-8 -*- | |||
| from collections import namedtuple | |||
| import mindspore as ms | |||
| from mindspore.ops.primitive import _primexpr | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from msadapter.utils import unsupported_attr, pynative_mode_condition | |||
| from msadapter.utils import pynative_mode_condition | |||
| from .container import Sequential, ModuleList | |||
| from .linear import Linear | |||
| from .module import Module | |||
| from ..functional import log_softmax | |||
| from ...functional import argmax | |||
| @_primexpr | |||
| def _ASMoutput(): | |||
| @@ -17,19 +16,18 @@ def _ASMoutput(): | |||
| class AdaptiveLogSoftmaxWithLoss(Module): | |||
| def __init__(self, in_features, n_classes, cutoffs, div_value=4., head_bias=False, device=None, dtype=None): | |||
| factory_kwargs = {'device': device, 'dtype': dtype} | |||
| super(AdaptiveLogSoftmaxWithLoss, self).__init__() | |||
| unsupported_attr(device) | |||
| cutoffs = list(cutoffs) | |||
| # #TODO: pylint | |||
| # if (cutoffs != sorted(cutoffs)) \ | |||
| # or (min(cutoffs) <= 0) \ | |||
| # or (max(cutoffs) > (n_classes - 1)) \ | |||
| # or (len(set(cutoffs)) != len(cutoffs)) \ | |||
| # or any([int(c) != c for c in cutoffs]): | |||
| # | |||
| # raise ValueError("cutoffs should be a sequence of unique, positive " | |||
| # "integers sorted in an increasing order, where " | |||
| # "each value is between 1 and n_classes-1") | |||
| if (cutoffs != sorted(cutoffs)) \ | |||
| or (min(cutoffs) <= 0) \ | |||
| or (max(cutoffs) > (n_classes - 1)) \ | |||
| or (len(set(cutoffs)) != len(cutoffs)) \ | |||
| or any(int(c) != c for c in cutoffs): | |||
| raise ValueError("cutoffs should be a sequence of unique, positive " | |||
| "integers sorted in an increasing order, where " | |||
| "each value is between 1 and n_classes-1") | |||
| self.in_features = in_features | |||
| self.n_classes = n_classes | |||
| @@ -42,17 +40,17 @@ class AdaptiveLogSoftmaxWithLoss(Module): | |||
| self.n_clusters = len(self.cutoffs) - 1 | |||
| self.head_size = self.shortlist_size + self.n_clusters | |||
| self.head = Linear(self.in_features, self.head_size, bias=self.head_bias, dtype=self.dtype) | |||
| self.head = Linear(self.in_features, self.head_size, bias=self.head_bias, | |||
| **factory_kwargs) | |||
| self.tail = ModuleList() | |||
| for i in range(self.n_clusters): | |||
| hsz = int(self.in_features // (self.div_value ** (i + 1))) | |||
| osz = self.cutoffs[i + 1] - self.cutoffs[i] | |||
| projection = Sequential( | |||
| Linear(self.in_features, hsz, bias=False, dtype=self.dtype), | |||
| Linear(hsz, osz, bias=False, dtype=self.dtype), | |||
| Linear(self.in_features, hsz, bias=False, **factory_kwargs), | |||
| Linear(hsz, osz, bias=False, **factory_kwargs), | |||
| ) | |||
| self.tail.append(projection) | |||
| @@ -64,8 +62,6 @@ class AdaptiveLogSoftmaxWithLoss(Module): | |||
| h2o.reset_parameters() | |||
| def forward(self, input_, target_): | |||
| input_ = cast_to_ms_tensor(input_) | |||
| #target_ = cast_to_ms_tensor(target_) | |||
| targ_dim = target_.dim() | |||
| if targ_dim == 1: | |||
| @@ -91,12 +87,10 @@ class AdaptiveLogSoftmaxWithLoss(Module): | |||
| batch_size = target.shape[0] | |||
| output = input.new_zeros(batch_size) | |||
| #gather_inds = ms.numpy.empty(batch_size, target.dtype) | |||
| gather_inds = target.new_empty(batch_size) | |||
| cutoff_values = [0] + self.cutoffs | |||
| for i in range(len(cutoff_values) - 1): | |||
| low_idx = cutoff_values[i] | |||
| high_idx = cutoff_values[i + 1] | |||
| @@ -107,13 +101,11 @@ class AdaptiveLogSoftmaxWithLoss(Module): | |||
| continue | |||
| if i == 0: | |||
| #gather_inds.index_copy_(0, row_indices, target[target_mask]) | |||
| gather_inds = index_copy_0dim(gather_inds, row_indices, target[target_mask]) | |||
| gather_inds = gather_inds.index_copy(0, row_indices, target[target_mask]) | |||
| else: | |||
| relative_target = target[target_mask] - low_idx | |||
| #input_subset = input.index_select(0, row_indices) | |||
| input_subset = ms.ops.gather(input, row_indices, 0) | |||
| input_subset = input.index_select(0, row_indices) | |||
| cluster_output = self.tail[i - 1](input_subset) | |||
| cluster_index = self.shortlist_size + i - 1 | |||
| @@ -121,8 +113,7 @@ class AdaptiveLogSoftmaxWithLoss(Module): | |||
| gather_inds = gather_inds.index_fill(0, row_indices, cluster_index) | |||
| cluster_logprob = log_softmax(cluster_output, dim=1) | |||
| local_logprob = cluster_logprob.gather(1, relative_target.unsqueeze(1)) | |||
| #output.index_copy_(0, row_indices, local_logprob.squeeze(1)) | |||
| output = index_copy_0dim(output, row_indices, local_logprob.squeeze(1)) | |||
| output = output.index_copy(0, row_indices, local_logprob.squeeze(1)) | |||
| used_rows += row_indices.numel() | |||
| @@ -137,18 +128,15 @@ class AdaptiveLogSoftmaxWithLoss(Module): | |||
| head_logprob = log_softmax(head_output, dim=1) | |||
| output += head_logprob.gather(1, gather_inds.unsqueeze(1)).squeeze() | |||
| loss = (-output).mean() | |||
| if not is_batched: | |||
| output = output.squeeze(0) | |||
| output = cast_to_adapter_tensor(output) | |||
| loss = cast_to_adapter_tensor(loss) | |||
| if pynative_mode_condition(): | |||
| return _ASMoutput()(output, loss) | |||
| return output, loss | |||
| def _get_full_log_prob(self, input, head_output): | |||
| input = cast_to_ms_tensor(input) | |||
| head_output = cast_to_ms_tensor(head_output) | |||
| out = input.new_empty((head_output.shape[0], self.n_classes)) | |||
| head_logprob = log_softmax(head_output, dim=1) | |||
| @@ -161,38 +149,27 @@ class AdaptiveLogSoftmaxWithLoss(Module): | |||
| out[:, start_idx:stop_idx] = output_logprob | |||
| return cast_to_adapter_tensor(out) | |||
| return out | |||
| def log_prob(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| head_output = self.head(input) | |||
| out = self._get_full_log_prob(input, head_output) | |||
| return cast_to_adapter_tensor(out) | |||
| return self._get_full_log_prob(input, head_output) | |||
| def predict(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| head_output = self.head(input) | |||
| cast_to_adapter_tensor() | |||
| output = ms.ops.argmax(head_output, axis=1) | |||
| output = argmax(head_output, dim=1) | |||
| not_in_shortlist = (output >= self.shortlist_size) | |||
| any_in_shortlist = (output < self.shortlist_size) | |||
| all_in_shortlist = not not_in_shortlist.any() | |||
| if not not_in_shortlist: | |||
| return cast_to_adapter_tensor(output) | |||
| if all_in_shortlist: | |||
| return output | |||
| elif not any_in_shortlist: | |||
| elif not_in_shortlist.all(): | |||
| log_prob = self._get_full_log_prob(input, head_output) | |||
| return cast_to_adapter_tensor(ms.ops.argmax(log_prob, axis=1)) | |||
| return argmax(log_prob, dim=1) | |||
| else: | |||
| log_prob = self._get_full_log_prob(input[not_in_shortlist], | |||
| head_output[not_in_shortlist]) | |||
| output[not_in_shortlist] = ms.ops.argmax(log_prob, axis=1) | |||
| return cast_to_adapter_tensor(output) | |||
| def index_copy_0dim(input, index, tensor): | |||
| for i in range(len(index)): | |||
| input[index[i]] = tensor[i] | |||
| return input | |||
| output[not_in_shortlist] = argmax(log_prob, dim=1) | |||
| return output | |||
+ 47
- 1
msadapter/pytorch/nn/modules/batchnorm.py
View File
| @@ -13,7 +13,7 @@ from msadapter.pytorch.nn import init | |||
| from msadapter.pytorch.functional import empty | |||
| from msadapter.pytorch.nn.parameter import Parameter | |||
| from msadapter.utils import unsupported_attr | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor, tensor, Tensor | |||
| from .module import Module | |||
| @@ -55,6 +55,9 @@ class _NormBase(Module): | |||
| def reset_running_stats(self): | |||
| init.zeros_(self.running_mean) | |||
| init.ones_(self.running_var) | |||
| if self.track_running_stats: | |||
| # Not used, only for loading pth files saved from torch. | |||
| self.register_buffer('num_batches_tracked', tensor(0)) | |||
| def reset_parameters(self): | |||
| self.reset_running_stats() | |||
| @@ -68,6 +71,49 @@ class _NormBase(Module): | |||
| "track_running_stats={track_running_stats}".format(**self.__dict__) | |||
| ) | |||
| def _load_from_state_dict( | |||
| self, | |||
| state_dict, | |||
| prefix, | |||
| local_metadata, | |||
| strict, | |||
| missing_keys, | |||
| has_load, | |||
| error_msgs, | |||
| ): | |||
| if self.track_running_stats: | |||
| num_batches_tracked_key = prefix + "num_batches_tracked" | |||
| if num_batches_tracked_key not in state_dict: | |||
| state_dict[num_batches_tracked_key] = tensor(0) | |||
| if not self.track_running_stats: | |||
| running_mean_key = prefix + "running_mean" | |||
| if running_mean_key not in state_dict: | |||
| state_dict[running_mean_key] = init.ones_(Tensor(self.num_features)) | |||
| running_var_key = prefix + "running_var" | |||
| if running_var_key not in state_dict: | |||
| state_dict[running_var_key] = init.zeros_(Tensor(self.num_features)) | |||
| if not self.affine: | |||
| weight_key = prefix + "weight" | |||
| if weight_key not in state_dict: | |||
| state_dict[weight_key] = init.ones_(Tensor(self.num_features)) | |||
| bias_key = prefix + "bias" | |||
| if bias_key not in state_dict: | |||
| state_dict[bias_key] = init.zeros_(Tensor(self.num_features)) | |||
| super()._load_from_state_dict( | |||
| state_dict, | |||
| prefix, | |||
| local_metadata, | |||
| strict, | |||
| missing_keys, | |||
| has_load, | |||
| error_msgs, | |||
| ) | |||
| class _BatchNorm(_NormBase): | |||
| """Common base of BatchNorm""" | |||
+ 28
- 4
msadapter/pytorch/nn/modules/channelshuffle.py
View File
| @@ -1,7 +1,8 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import mindspore.nn as nn | |||
| import mindspore as ms | |||
| from mindspore.ops.primitive import _primexpr | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from .module import Module | |||
| @@ -11,12 +12,35 @@ __all__ = ['ChannelShuffle'] | |||
| class ChannelShuffle(Module): | |||
| def __init__(self, groups): | |||
| super(ChannelShuffle, self).__init__() | |||
| if not isinstance(groups, int): | |||
| raise TypeError("For ChannelShuffle, the param `groups` must be int, but got {}.".format(type(groups))) | |||
| if groups < 1: | |||
| raise ValueError(f"For ChannelShuffle, the param `groups` must be larger than 0, but got {groups}.") | |||
| self.groups = groups | |||
| self.channel_shuffle = nn.ChannelShuffle(self.groups) | |||
| self.reshape = ms.ops.Reshape() | |||
| self.transpose = ms.ops.Transpose() | |||
| @staticmethod | |||
| @_primexpr | |||
| def _check_input_dim(shape, channels, groups, cls_name): | |||
| """check input dim""" | |||
| dim = len(shape) | |||
| if dim < 3: | |||
| raise ValueError(f"For {cls_name}, the in_shape must have more than 2 dims, but got {dim}.") | |||
| if channels % groups != 0: | |||
| raise ValueError(f"For {cls_name}, number of channels must be divisible by groups, " | |||
| f"but got {channels} channels and {groups} groups.") | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| out = self.channel_shuffle(input) | |||
| x = cast_to_ms_tensor(input) | |||
| x_shape = x.shape | |||
| n, c = x_shape[0], x_shape[1] | |||
| self._check_input_dim(x_shape, c, self.groups, self.cls_name) | |||
| out = self.reshape(x, (n, self.groups, c // self.groups, -1)) | |||
| out = self.transpose(out, (0, 2, 1, 3)) | |||
| out = self.reshape(out, x_shape) | |||
| return cast_to_adapter_tensor(out) | |||
| def extra_repr(self): | |||
+ 40
- 26
msadapter/pytorch/nn/modules/conv.py
View File
| @@ -13,7 +13,6 @@ from msadapter.utils import unsupported_attr | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from msadapter.pytorch.nn.functional import conv2d, conv_transpose3d, conv1d, conv3d, \ | |||
| _deconv_output_length, _process_conv_transpose1d_const | |||
| # from .utils import _triple, _pair, _single, _reverse_repeat_tuple, _GLOBAL_LRU_CACHE_SIZE_NN | |||
| from .utils import _triple, _pair, _single, _reverse_repeat_tuple | |||
| from .module import Module | |||
| @@ -154,21 +153,25 @@ class Conv1d(_ConvNd): | |||
| super(Conv1d, self).__init__(in_channels, out_channels, kernel_size_, stride_, padding_, dilation_, | |||
| False, _single(0), groups, bias, padding_mode, **factory_kwargs) | |||
| #TODO pad_mode in ['zeros', 'reflect', 'replicate', 'circular'] | |||
| if padding_mode in {'reflect', 'replicate', 'circular'}: | |||
| raise ValueError("Pad mode '{}' is not currently supported.".format(padding_mode)) | |||
| def forward(self, input): | |||
| x = cast_to_ms_tensor(input) | |||
| ndim = x.ndim | |||
| def _conv_forward(self, input, padding): | |||
| ndim = input.ndim | |||
| if ndim == 2: | |||
| x = x.expand_dims(0) | |||
| output = conv1d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups) | |||
| input = input.expand_dims(0) | |||
| output = conv1d(input, self.weight, self.bias, self.stride, padding, self.dilation, self.groups) | |||
| output = output.squeeze(0) | |||
| else: | |||
| output = conv1d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups) | |||
| output = conv1d(input, self.weight, self.bias, self.stride, padding, self.dilation, self.groups) | |||
| return output | |||
| def forward(self, input): | |||
| x = cast_to_ms_tensor(input) | |||
| if self.padding_mode == 'zeros': | |||
| return self._conv_forward(x, self.padding) | |||
| x = ms.ops.pad(x, self._reversed_padding_repeated_twice, self.padding_mode) | |||
| return self._conv_forward(x, 0) | |||
| class Conv2d(_ConvNd): | |||
| def __init__(self, | |||
| in_channels, | |||
| @@ -191,24 +194,28 @@ class Conv2d(_ConvNd): | |||
| super(Conv2d, self).__init__(in_channels, out_channels, kernel_size_, stride_, padding_, dilation_, | |||
| False, _pair(0), groups, bias, padding_mode, **factory_kwargs) | |||
| #TODO pad_mode in ['zeros', 'reflect', 'replicate', 'circular'] | |||
| if padding_mode in {'reflect', 'replicate', 'circular'}: | |||
| raise ValueError("Pad mode '{}' is not currently supported.".format(padding_mode)) | |||
| def forward(self, input): | |||
| x = cast_to_ms_tensor(input) | |||
| def _conv_forward(self, x, padding): | |||
| ndim = x.ndim | |||
| if ndim == 3: | |||
| x = x.expand_dims(0) | |||
| # Under pynative-mode, self.stride, etc can be changed at any time. | |||
| # However, under graph-mode, the graph will be generated at first time running and can not | |||
| # be altered anymore. After that, self.stride, etc are not supported to be changed dynamically. | |||
| output = conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups) | |||
| output = conv2d(x, self.weight, self.bias, self.stride, padding, self.dilation, self.groups) | |||
| output = output.squeeze(0) | |||
| else: | |||
| output = conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups) | |||
| output = conv2d(x, self.weight, self.bias, self.stride, padding, self.dilation, self.groups) | |||
| return output | |||
| def forward(self, input): | |||
| x = cast_to_ms_tensor(input) | |||
| if self.padding_mode == 'zeros': | |||
| return self._conv_forward(x, self.padding) | |||
| x = ms.ops.pad(x, self._reversed_padding_repeated_twice, self.padding_mode) | |||
| return self._conv_forward(x, 0) | |||
| class Conv3d(_ConvNd): | |||
| r""" | |||
| @@ -250,21 +257,28 @@ class Conv3d(_ConvNd): | |||
| super(Conv3d, self).__init__(in_channels, out_channels, kernel_size_, stride_, padding_, dilation_, | |||
| False, _triple(0), groups, bias, padding_mode, **factory_kwargs) | |||
| #TODO pad_mode in ['zeros', 'reflect', 'replicate', 'circular'] | |||
| if padding_mode in {'reflect', 'replicate', 'circular'}: | |||
| if padding_mode == 'reflect': | |||
| raise ValueError("Pad mode '{}' is not currently supported.".format(padding_mode)) | |||
| def forward(self, input): | |||
| x = cast_to_ms_tensor(input) | |||
| def _conv_forward(self, input, padding): | |||
| ndim = input.ndim | |||
| if ndim == 4: | |||
| x = x.expand_dims(0) | |||
| output = conv3d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups) | |||
| input = input.expand_dims(0) | |||
| output = conv3d(input, self.weight, self.bias, self.stride, padding, self.dilation, self.groups) | |||
| output = output.squeeze(0) | |||
| else: | |||
| output = conv3d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups) | |||
| output = conv3d(input, self.weight, self.bias, self.stride, padding, self.dilation, self.groups) | |||
| return output | |||
| def forward(self, input): | |||
| x = cast_to_ms_tensor(input) | |||
| if self.padding_mode == 'zeros': | |||
| return self._conv_forward(x, self.padding) | |||
| x = ms.ops.pad(x, self._reversed_padding_repeated_twice, self.padding_mode) | |||
| return self._conv_forward(x, 0) | |||
| @_primexpr | |||
| # @lru_cache(_GLOBAL_LRU_CACHE_SIZE_NN) | |||
+ 14
- 3
msadapter/pytorch/nn/modules/dropout.py
View File
| @@ -1,5 +1,6 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from mindspore.common.seed import _get_graph_seed | |||
| import mindspore as ms | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor | |||
| import msadapter.pytorch.nn.functional as ms_torch_nn_func | |||
| @@ -57,12 +58,22 @@ class Dropout(_DropoutNd): | |||
| def __init__(self, p=0.5, inplace=False): | |||
| _inplace_limit_pynative(inplace, "Dropout") | |||
| super(Dropout, self).__init__(p, inplace) | |||
| if p < 0 or p > 1: | |||
| raise ValueError("dropout probability has to be between 0 and 1, " | |||
| "but got {}".format(p)) | |||
| self.keep_prob = 1.0 - self.p | |||
| seed0, seed1 = _get_graph_seed(0, "dropout") | |||
| self.seed0 = seed0 | |||
| self.seed1 = seed1 | |||
| self.dropout = ms.ops.Dropout(self.keep_prob, seed0, seed1) | |||
| def forward(self, input): | |||
| if self.p == 1.: | |||
| return input.zero_adapter() | |||
| if not self.training or self.keep_prob == 1.0: | |||
| return input | |||
| input_ms = cast_to_ms_tensor(input) | |||
| output = ms.ops.dropout(input_ms, p=self.p, training=self.training) | |||
| # ms.ops.dropout will cause the graph to be dynamic. | |||
| output, _ = self.dropout(input_ms) | |||
| return _inplace_assign(input, self.inplace, output) | |||
+ 15
- 18
msadapter/pytorch/nn/modules/linear.py
View File
| @@ -50,25 +50,19 @@ class Linear(Module): | |||
| >>> print(output.size()) | |||
| torch.Size([128, 30]) | |||
| """ | |||
| def __init__(self, in_features, out_features, bias=True, device=None, dtype=None): | |||
| super(Linear, self).__init__() | |||
| self.in_features = in_features | |||
| self.out_features = out_features | |||
| # self.matmul = P.MatMul(transpose_b=True) | |||
| self.has_bias = False | |||
| self.bias = None | |||
| self.weight = Parameter(empty((self.out_features, self.in_features)), requires_grad=True) | |||
| self.weight = Parameter(empty((self.out_features, self.in_features), dtype=dtype, device=device), | |||
| requires_grad=True) | |||
| if bias: | |||
| # self.bias_add = P.BiasAdd() | |||
| self.bias = Parameter(empty(self.out_features), requires_grad=True) | |||
| self.bias = Parameter(empty(self.out_features, dtype=dtype, device=device), requires_grad=True) | |||
| self.has_bias = True | |||
| self.reset_parameters() | |||
| unsupported_attr(device) | |||
| unsupported_attr(dtype) | |||
| def reset_parameters(self): | |||
| # Setting a=sqrt(5) in kaiming_uniform is the same as initializing with | |||
| # uniform(-1/sqrt(in_features), 1/sqrt(in_features)). | |||
| @@ -110,16 +104,14 @@ class Bilinear(Module): | |||
| self.reducesum = P.ReduceSum() | |||
| self.has_bias = False | |||
| self.weight = Parameter(empty((self.out_features, self.in1_features, self.in2_features)), requires_grad=True) | |||
| self.weight = Parameter(empty((self.out_features, self.in1_features, self.in2_features), | |||
| dtype=dtype, device=device), requires_grad=True) | |||
| if bias: | |||
| self.bias_add = P.BiasAdd() | |||
| self.bias = Parameter(empty(self.out_features), requires_grad=True) | |||
| self.bias = Parameter(empty(self.out_features, dtype=dtype, device=device), requires_grad=True) | |||
| self.has_bias = True | |||
| self.reset_parameters() | |||
| unsupported_attr(device) | |||
| unsupported_attr(dtype) | |||
| def reset_parameters(self): | |||
| bound = 1 / math.sqrt(self.weight.shape[1]) | |||
| init.uniform_(self.weight, -bound, bound) | |||
| @@ -129,14 +121,19 @@ class Bilinear(Module): | |||
| def forward(self, input1, input2): | |||
| input1 = cast_to_ms_tensor(input1) | |||
| input2 = cast_to_ms_tensor(input2) | |||
| x = self.matmul(input1.reshape(-1, input1.shape[-1]), | |||
| self.weight.permute(1, 0, 2).reshape(self.weight.shape[1], -1)) | |||
| x = self.mul(x, self.tile(input2.reshape(-1, input2.shape[-1]), (1, self.out_features))) | |||
| input1_shape = input1.shape | |||
| input2_shape = input2.shape | |||
| if len(input1_shape) != 2: | |||
| input1 = input1.reshape((-1, input1_shape[-1])) | |||
| x = self.matmul(input1, self.weight.permute(1, 0, 2).reshape(self.weight.shape[1], -1)) | |||
| if len(input2_shape) != 2: | |||
| input2 = input2.reshape((-1, input2_shape[-1])) | |||
| x = self.mul(x, self.tile(input2, (1, self.out_features))) | |||
| x = x.reshape(x.shape[0], self.out_features, -1) | |||
| x = self.reducesum(x, -1) | |||
| if self.has_bias: | |||
| x = self.bias_add(x, self.bias) | |||
| x = x.reshape(*input1.shape[:-1], -1) | |||
| x = x.reshape(*input1_shape[:-1], -1) | |||
| return cast_to_adapter_tensor(x) | |||
| def extra_repr(self): | |||
+ 53
- 20
msadapter/pytorch/nn/modules/module.py
View File
| @@ -168,22 +168,29 @@ class Module(Cell): | |||
| ms_state_dict[name] = param | |||
| return ms_state_dict | |||
| def _load_buffer_into_net(self, state_dict, strict): | |||
| def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, | |||
| missing_keys, has_load, error_msgs): | |||
| unsupported_attr(local_metadata) | |||
| unsupported_attr(error_msgs) | |||
| persistent_buffers = {k: v for k, v in self._buffers.items() | |||
| if k not in self._non_persistent_buffers_set and | |||
| v is not None} | |||
| for name, buf in persistent_buffers.items(): | |||
| key = prefix + name | |||
| if key in state_dict: | |||
| input_buf = state_dict[key] | |||
| buf.assign_value(input_buf.astype(buf.dtype)) | |||
| has_load.append(key) | |||
| elif strict: | |||
| missing_keys.append(key) | |||
| def _load_buffer_into_net(self, state_dict, strict, error_msgs): | |||
| missing_key = [] | |||
| has_load = [] | |||
| def load(module, local_state_dict, prefix=''): | |||
| persistent_buffers = {k: v for k, v in module._buffers.items() | |||
| if k not in module._non_persistent_buffers_set and | |||
| v is not None} | |||
| for name, buf in persistent_buffers.items(): | |||
| key = prefix + name | |||
| if key in local_state_dict: | |||
| input_buf = local_state_dict[key] | |||
| buf = buf.copy_adapter(input_buf) | |||
| has_load.append(key) | |||
| elif strict: | |||
| missing_key.append(name) | |||
| def load(module, local_state_dict, metadata, prefix=''): | |||
| local_metadata = {} if metadata is None else metadata.get(prefix[:-1], {}) | |||
| module._load_from_state_dict(local_state_dict, prefix, local_metadata, strict, missing_key, | |||
| has_load, error_msgs) | |||
| extra_state_key = prefix + _EXTRA_STATE_KEY_SUFFIX | |||
| if getattr(module.__class__, "set_extra_state", Module.set_extra_state) is not Module.set_extra_state: | |||
| if extra_state_key in state_dict: | |||
| @@ -196,9 +203,10 @@ class Module(Cell): | |||
| if child is not None and isinstance(child, Module): | |||
| child_prefix = prefix + name + '.' | |||
| child_state_dict = {k: v for k, v in local_state_dict.items() if k.startswith(child_prefix)} | |||
| load(child, child_state_dict, child_prefix) | |||
| load(child, child_state_dict, metadata, child_prefix) | |||
| load(self, state_dict) | |||
| metadata = getattr(state_dict, '_metadata', None) | |||
| load(self, state_dict, metadata) | |||
| del load | |||
| return missing_key, has_load | |||
| @@ -206,7 +214,7 @@ class Module(Cell): | |||
| if not isinstance(state_dict, Mapping): | |||
| raise TypeError("Expected state_dict to be dict-like, got {}.".format(type(state_dict))) | |||
| error_msgs = [] | |||
| buffers_not_load, buffers_has_load = self._load_buffer_into_net(state_dict, strict) | |||
| buffers_not_load, buffers_has_load = self._load_buffer_into_net(state_dict, strict, error_msgs) | |||
| ms_state_dict = self._convert_state_dict(state_dict) | |||
| param_not_load, ckpt_not_load = load_param_into_net(self, ms_state_dict, strict_load=False) | |||
| @@ -235,6 +243,23 @@ class Module(Cell): | |||
| def construct(self, *inputs, **kwargs): | |||
| return self.forward(*inputs, **kwargs) | |||
| def _run_forward_pre_hook(self, inputs): | |||
| for fn in self._forward_pre_hook.values(): | |||
| ret = fn(self, inputs) | |||
| if ret is not None: | |||
| if not isinstance(ret, tuple): | |||
| inputs = (ret,) | |||
| else: | |||
| inputs = ret | |||
| return inputs | |||
| def _run_forward_hook(self, inputs, output): | |||
| for fn in self._forward_hook.values(): | |||
| ret = fn(self, inputs, output) | |||
| if ret is not None: | |||
| output = ret | |||
| return output | |||
| def _run_construct(self, cast_inputs, kwargs): | |||
| """Run the construct function""" | |||
| if self._enable_forward_pre_hook: | |||
| @@ -422,9 +447,6 @@ class Module(Cell): | |||
| """Alias for :func:`add_module`.""" | |||
| self.add_module(name, module) | |||
| def parameters_and_names(self, name_prefix='', expand=True): | |||
| return self._parameters_and_names(name_prefix=name_prefix, expand=expand) | |||
| def named_parameters(self, prefix='', recurse=True, remove_duplicate=True): | |||
| gen = self._named_members( | |||
| lambda module: module._params.items(), | |||
| @@ -642,3 +664,14 @@ class Module(Cell): | |||
| keys = [key for key in keys if not key[0].isdigit()] | |||
| return sorted(keys) | |||
| def register_forward_hook(self, hook): | |||
| return ms.nn.Cell.register_forward_hook(self, hook) | |||
| def register_forward_pre__hook(self, hook): | |||
| return ms.nn.Cell.register_forward_pre_hook(self, hook) | |||
| # TODO: | |||
| # to support modifying Module inside hook func | |||
| def register_backward_hook(self, hook): | |||
| return ms.nn.Cell.register_backward_hook(self, hook) | |||
+ 11
- 24
msadapter/pytorch/nn/modules/padding.py
View File
| @@ -3,7 +3,8 @@ | |||
| from itertools import repeat | |||
| from mindspore import nn | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| from .module import Module | |||
| from msadapter.pytorch.nn.functional import pad | |||
| from msadapter.pytorch.nn.modules.module import Module | |||
| __all__ = ['ConstantPad1d', 'ConstantPad2d', 'ConstantPad3d', 'ReflectionPad1d', 'ReflectionPad2d', 'ReflectionPad3d', | |||
| 'ZeroPad2d', 'ReplicationPad1d', 'ReplicationPad2d', 'ReplicationPad3d'] | |||
| @@ -33,8 +34,7 @@ class _ConstantPadNd(Module): | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| #Todo: replace with 'F.pad(input, self.padding, 'constant', self.value)' | |||
| output = self.pad_fun(input) | |||
| output = pad(input, self.padding, 'constant', self.value) | |||
| return cast_to_adapter_tensor(output) | |||
| def extra_repr(self) -> str: | |||
| @@ -66,7 +66,6 @@ class ConstantPad1d(_ConstantPadNd): | |||
| def __init__(self, padding, value): | |||
| super(ConstantPad1d, self).__init__(padding, value) | |||
| self.padding = _check_padding(padding, 2, "ConstantPad1d") | |||
| self.pad_fun = nn.ConstantPad1d(self.padding, self.value) # todo: to be deleted | |||
| class ConstantPad2d(_ConstantPadNd): | |||
| r"""Pads the input tensor boundaries with a constant value. | |||
| @@ -96,7 +95,6 @@ class ConstantPad2d(_ConstantPadNd): | |||
| def __init__(self, padding, value): | |||
| super(ConstantPad2d, self).__init__(padding, value) | |||
| self.padding = _check_padding(padding, 4, "ConstantPad2d") | |||
| self.pad_fun = nn.ConstantPad2d(self.padding, self.value) # todo: to be deleted | |||
| class ConstantPad3d(_ConstantPadNd): | |||
| r"""Pads the input tensor boundaries with a constant value. | |||
| @@ -131,7 +129,6 @@ class ConstantPad3d(_ConstantPadNd): | |||
| def __init__(self, padding, value): | |||
| super(ConstantPad3d, self).__init__(padding, value) | |||
| self.padding = _check_padding(padding, 6, "ConstantPad3d") | |||
| self.pad_fun = nn.ConstantPad3d(self.padding, self.value) # todo: to be deleted | |||
| class _ReflectionPadNd(Module): | |||
| def __init__(self, padding): | |||
| @@ -140,10 +137,7 @@ class _ReflectionPadNd(Module): | |||
| self.pad_fun = None | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| #todo: replace with 'F.pad(input, self.padding, 'reflect')' | |||
| output = self.pad_fun(input) | |||
| return cast_to_adapter_tensor(output) | |||
| return pad(input, self.padding, 'reflect') | |||
| def extra_repr(self) -> str: | |||
| return '{}'.format(self.padding) | |||
| @@ -176,7 +170,6 @@ class ReflectionPad1d(_ReflectionPadNd): | |||
| def __init__(self, padding): | |||
| super(ReflectionPad1d, self).__init__(padding) | |||
| self.padding = _check_padding(padding, 2, "ReflectionPad1d") | |||
| self.pad_fun = nn.ReflectionPad1d(self.padding) # todo: to be deleted | |||
| class ReflectionPad2d(_ReflectionPadNd): | |||
| @@ -208,7 +201,6 @@ class ReflectionPad2d(_ReflectionPadNd): | |||
| def __init__(self, padding): | |||
| super(ReflectionPad2d, self).__init__(padding) | |||
| self.padding = _check_padding(padding, 4, "ReflectionPad2d") | |||
| self.pad_fun = nn.ReflectionPad2d(self.padding) # todo: to be deleted | |||
| class ReflectionPad3d(_ReflectionPadNd): | |||
| @@ -248,14 +240,14 @@ class ReflectionPad3d(_ReflectionPadNd): | |||
| self.pad_fun = nn.ReflectionPad3d(self.padding) # todo: to be deleted | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| if input.ndim == 5: | |||
| input_shape = input.shape | |||
| input = input.reshape((-1,) + input_shape[2:]) | |||
| output = self.pad_fun(input) | |||
| input_ms = cast_to_ms_tensor(input) | |||
| if input_ms.ndim == 5: | |||
| input_shape = input_ms.shape | |||
| input_ms = input_ms.reshape((-1,) + input_shape[2:]) | |||
| output = self.pad_fun(input_ms) | |||
| output = output.reshape(input_shape[0:2] + output.shape[1:]) | |||
| else: | |||
| output = self.pad_fun(input) | |||
| output = self.pad_fun(input_ms) | |||
| return cast_to_adapter_tensor(output) | |||
| @@ -288,7 +280,6 @@ class ZeroPad2d(_ConstantPadNd): | |||
| def __init__(self, padding): | |||
| super(ZeroPad2d, self).__init__(padding, 0.) | |||
| self.padding = _check_padding(padding, 4, "ZeroPad2d") | |||
| self.pad_fun = nn.ConstantPad2d(self.padding, self.value) # todo: to be deleted | |||
| class _ReplicationPadNd(Module): | |||
| def __init__(self, padding): | |||
| @@ -298,8 +289,7 @@ class _ReplicationPadNd(Module): | |||
| def forward(self, input): | |||
| input = cast_to_ms_tensor(input) | |||
| #TODO: replace with F.pad(input, self.padding, 'replicate') | |||
| output = self.pad_fun(input) | |||
| output = pad(input, self.padding, 'replicate') | |||
| return cast_to_adapter_tensor(output) | |||
| def extra_repr(self) -> str: | |||
| @@ -309,16 +299,13 @@ class ReplicationPad1d(_ReplicationPadNd): | |||
| def __init__(self, padding): | |||
| super(ReplicationPad1d, self).__init__(padding) | |||
| self.padding = _check_padding(padding, 2, "ReplicationPad1d") | |||
| self.pad_fun = nn.ReplicationPad1d(padding) # todo: to be deleted | |||
| class ReplicationPad2d(_ReplicationPadNd): | |||
| def __init__(self, padding): | |||
| super(ReplicationPad2d, self).__init__(padding) | |||
| self.padding = _check_padding(padding, 4, "ReplicationPad2d") | |||
| self.pad_fun = nn.ReplicationPad2d(padding) # todo: to be deleted | |||
| class ReplicationPad3d(_ReplicationPadNd): | |||
| def __init__(self, padding): | |||
| super(ReplicationPad3d, self).__init__(padding) | |||
| self.padding = _check_padding(padding, 6, "ReplicationPad3d") | |||
| self.pad_fun = nn.ReplicationPad3d(padding) # todo: to be deleted | |||
+ 405
- 86
msadapter/pytorch/nn/modules/rnn.py
View File
| @@ -8,6 +8,7 @@ import mindspore as ms | |||
| from mindspore.nn.layer.rnns import _DynamicRNNRelu, _DynamicRNNTanh, _DynamicLSTMCPUGPU, _DynamicLSTMAscend, \ | |||
| _DynamicGRUAscend, _DynamicGRUCPUGPU | |||
| from mindspore.nn.layer.rnn_cells import _rnn_tanh_cell, _rnn_relu_cell, _lstm_cell, _gru_cell | |||
| from mindspore.ops._primitive_cache import _get_cache_prim | |||
| from msadapter.pytorch.nn.modules.module import Module | |||
| from msadapter.pytorch.tensor import cast_to_ms_tensor, cast_to_adapter_tensor | |||
| @@ -15,8 +16,12 @@ from msadapter.pytorch.nn.parameter import Parameter | |||
| from msadapter.pytorch.functional import empty, zeros | |||
| from msadapter.pytorch.nn import init | |||
| from msadapter.utils import unsupported_attr, is_under_ascend_context | |||
| from msadapter.pytorch.nn.utils.rnn import PackedSequence, pad_packed_sequence | |||
| def _apply_permutation(tensor, permutation, dim=1): | |||
| return tensor.index_select(dim, permutation) | |||
| class RNNBase(Module): | |||
| def __init__(self, mode, input_size, hidden_size, | |||
| num_layers=1, bias=True, batch_first=False, | |||
| @@ -117,6 +122,41 @@ class RNNBase(Module): | |||
| for weight in self.parameters(): | |||
| init.uniform_(weight, -stdv, stdv) | |||
| def check_input(self, input, batch_sizes): | |||
| expected_input_dim = 2 if batch_sizes is not None else 3 | |||
| if input.ndim != expected_input_dim: | |||
| raise RuntimeError( | |||
| 'input must have {} dimensions, got {}'.format(expected_input_dim, input.ndim)) | |||
| if self.input_size != input.shape[-1]: | |||
| raise RuntimeError( | |||
| 'input.size(-1) must be equal to input_size. Expected {}, got {}'.format( | |||
| self.input_size, input.shape[-1])) | |||
| def get_expected_hidden_size(self, input, batch_sizes): | |||
| if batch_sizes is not None: | |||
| mini_batch = int(batch_sizes[0]) | |||
| else: | |||
| mini_batch = input.shape[0] if self.batch_first else input.shape[1] | |||
| num_directions = 2 if self.bidirectional else 1 | |||
| if self.proj_size > 0: | |||
| expected_hidden_size = (self.num_layers * num_directions, | |||
| mini_batch, self.proj_size) | |||
| else: | |||
| expected_hidden_size = (self.num_layers * num_directions, | |||
| mini_batch, self.hidden_size) | |||
| return expected_hidden_size | |||
| def check_hidden_size(self, hx, expected_hidden_size, | |||
| msg: str = 'Expected hidden size {}, got {}'): | |||
| if hx.shape != expected_hidden_size: | |||
| raise RuntimeError(msg.format(expected_hidden_size, list(hx.shape))) | |||
| def check_forward_args(self, input, hidden, batch_sizes): | |||
| self.check_input(input, batch_sizes) | |||
| expected_hidden_size = self.get_expected_hidden_size(input, batch_sizes) | |||
| self.check_hidden_size(hidden, expected_hidden_size) | |||
| def extra_repr(self): | |||
| s = '{input_size}, {hidden_size}' | |||
| if self.proj_size != 0: | |||
| @@ -190,40 +230,16 @@ class RNNBase(Module): | |||
| param += tuple(self._flat_weights[offset:offset + _param_nums_per_directions]) | |||
| param += (None, None) | |||
| offset = offset + _param_nums_per_directions | |||
| # cast parameter to ms.Tensor before call ms function. | |||
| return cast_to_ms_tensor(param) | |||
| def forward(self, input, hx=None): | |||
| if len(input.shape) not in (2, 3): | |||
| raise RuntimeError(f"For RNN, input should be 2D or 3D, but got {len(input.shape)}D.") | |||
| is_batched = len(input.shape) == 3 | |||
| input = cast_to_ms_tensor(input) | |||
| if not is_batched: | |||
| input = ms.ops.unsqueeze(input, 1) | |||
| else: | |||
| if self.batch_first: | |||
| input = ms.ops.transpose(input, (1, 0, 2)) | |||
| def permute_hidden(self, hx, permutation): | |||
| if permutation is None: | |||
| return hx | |||
| return _apply_permutation(hx, permutation) | |||
| x_dtype = input.dtype | |||
| max_batch_size = input.shape[1] | |||
| def _run_recurrent(self, input, hx, length=None): | |||
| num_directions = 2 if self.bidirectional else 1 | |||
| if hx is None: | |||
| hx = zeros(self.num_layers * num_directions, | |||
| max_batch_size, self.hidden_size, | |||
| dtype=x_dtype) | |||
| hx = cast_to_ms_tensor(hx) | |||
| else: | |||
| hx = cast_to_ms_tensor(hx) | |||
| if len(hx.shape) not in (2, 3): | |||
| raise RuntimeError(f"For RNN, hx should be 2D or 3D, but got {len(hx.shape)}D.") | |||
| if not is_batched: | |||
| if len(hx.shape) != 2: | |||
| raise RuntimeError("For RNN, hx ndim should be equal to input") | |||
| hx = ms.ops.unsqueeze(hx, 1) | |||
| pre_layer = input | |||
| h_n = () | |||
| @@ -232,38 +248,136 @@ class RNNBase(Module): | |||
| if num_directions == 1: | |||
| for i in range(self.num_layers): | |||
| w_ih, w_hh, b_ih, b_hh = self._get_weight_and_bias(num_directions, i, self.bias) | |||
| output, h_t = self.rnn_cell(pre_layer, hx[i], None, w_ih, w_hh, b_ih, b_hh) | |||
| layer_params = self._get_weight_and_bias(num_directions, i, self.bias) | |||
| output, h_t = self.rnn_cell(pre_layer, hx[i], length, *layer_params) | |||
| h_n += (h_t,) | |||
| pre_layer = ms.ops.dropout(output, 1 - self.dropout) \ | |||
| pre_layer = ms.ops.dropout(output, self.dropout) \ | |||
| if (self.dropout != 0 and i < self.num_layers - 1) else output | |||
| else: | |||
| for i in range(self.num_layers): | |||
| w_ih, w_hh, b_ih, b_hh, w_ih_b, w_hh_b, b_ih_b, b_hh_b = \ | |||
| layer_params = \ | |||
| self._get_weight_and_bias(num_directions, i, self.bias) | |||
| x_b = ms.ops.reverse(pre_layer, [0]) | |||
| output, h_t = self.rnn_cell(pre_layer, hx[2 * i], None, w_ih, w_hh, b_ih, b_hh) | |||
| output_b, h_t_b = self.rnn_cell(x_b, hx[2 * i + 1], None, w_ih_b, w_hh_b, b_ih_b, b_hh_b) | |||
| if length is None: | |||
| x_b = ms.ops.reverse(pre_layer, [0]) | |||
| else: | |||
| x_b = ms.ops.reverse_sequence(pre_layer, length, 0, 1) | |||
| output, h_t = self.rnn_cell(pre_layer, hx[2 * i], length, *layer_params[0:4]) | |||
| output_b, h_t_b = self.rnn_cell(x_b, hx[2 * i + 1], length, *layer_params[4:]) | |||
| output_b = ms.ops.reverse(output_b, [0]) | |||
| if length is None: | |||
| output_b = ms.ops.reverse(output_b, [0]) | |||
| else: | |||
| output_b = ms.ops.reverse_sequence(output_b, length, 0, 1) | |||
| output = ms.ops.concat((output, output_b), 2) | |||
| h_n += (h_t,) | |||
| h_n += (h_t_b,) | |||
| pre_layer = ms.ops.dropout(output, 1 - self.dropout) \ | |||
| pre_layer = ms.ops.dropout(output, self.dropout) \ | |||
| if (self.dropout != 0 and i < self.num_layers - 1) else output | |||
| h_n = ms.ops.concat(h_n, 0) | |||
| h_n = h_n.view(hx.shape) | |||
| return output, h_n | |||
| def _get_hx(self, input, hx, max_batch_size, is_batched, dtype): | |||
| num_directions = 2 if self.bidirectional else 1 | |||
| if hx is not None: | |||
| hx = cast_to_ms_tensor(hx) | |||
| if is_batched: | |||
| if hx.ndim != 3: | |||
| raise RuntimeError( | |||
| f"For batched 3-D input, hx should also be 3-D but got {hx.ndim}-D tensor") | |||
| else: | |||
| if hx.ndim != 2: | |||
| raise RuntimeError( | |||
| f"For unbatched 2-D input, hx should also be 2-D but got {hx.ndim}-D tensor") | |||
| hx = ms.ops.unsqueeze(hx, 1) | |||
| else: | |||
| hx = ms.ops.zeros((self.num_layers * num_directions, | |||
| max_batch_size, self.hidden_size), | |||
| dtype=dtype) | |||
| self.check_forward_args(input, hx, None) | |||
| return hx | |||
| def _get_sequence_output(self, output, batch_sizes): | |||
| num_directions = 2 if self.bidirectional else 1 | |||
| batch_sizes_tensor = ms.Tensor(batch_sizes) | |||
| _masked = ms.ops.arange(output.shape[1]) | |||
| _masked = ms.ops.tile(_masked, (output.shape[0], 1)) | |||
| masked = _masked < batch_sizes_tensor[:, None] | |||
| for _ in range(masked.ndim, output.ndim): | |||
| masked = masked.unsqueeze(-1) | |||
| masked = masked.broadcast_to(output.shape) | |||
| output = ms.ops.masked_select(output, masked) | |||
| _out_size = self.hidden_size if self.proj_size <= 0 else self.proj_size | |||
| output = output.reshape(-1, _out_size * num_directions) | |||
| return output | |||
| def forward(self, input, hx=None): | |||
| orig_input = input | |||
| length = None | |||
| # For jit | |||
| sorted_indices = None | |||
| unsorted_indices = None | |||
| is_batched = None | |||
| if isinstance(orig_input, PackedSequence): | |||
| _, batch_sizes, sorted_indices, unsorted_indices = orig_input | |||
| # mindspore can not process packed_sequence, should recover to normal tensor type | |||
| input, length = pad_packed_sequence(orig_input, batch_first=False) | |||
| input = cast_to_ms_tensor(input) | |||
| x_dtype = input.dtype | |||
| length = cast_to_ms_tensor(length) | |||
| input = input.index_select(1, ms.Tensor(sorted_indices)) | |||
| length = length.index_select(0, ms.Tensor(sorted_indices)) | |||
| if hx is None: | |||
| hx = self._get_hx(input, hx, input.shape[1], True, x_dtype) | |||
| else: | |||
| # Each batch of the hidden state should match the input sequence that | |||
| # the user believes he/she is passing in. | |||
| hx = cast_to_ms_tensor(hx) | |||
| hx = self.permute_hidden(hx, sorted_indices) | |||
| self.check_forward_args(input, hx, None) | |||
| output, h_n = self._run_recurrent(input, hx, length) | |||
| output = self._get_sequence_output(output, batch_sizes) | |||
| output = cast_to_adapter_tensor(output.astype(x_dtype)) | |||
| h_n = cast_to_adapter_tensor(h_n.astype(x_dtype)) | |||
| output_packed = PackedSequence(output, batch_sizes, sorted_indices, unsorted_indices) | |||
| return output_packed, self.permute_hidden(h_n, unsorted_indices) | |||
| batch_sizes = None | |||
| input = cast_to_ms_tensor(orig_input) | |||
| x_dtype = input.dtype | |||
| if input.ndim not in (2, 3): | |||
| raise ValueError(f"Expected input to be 2-D or 3-D but received {input.ndim}-D tensor") | |||
| is_batched = input.ndim == 3 | |||
| if not is_batched: | |||
| # self.rnn_cell do not support batch-first, so can only unsuqeeze at second dimention. | |||
| input = ms.ops.unsqueeze(input, 1) | |||
| hx = self._get_hx(input, hx, 1, is_batched, input.dtype) | |||
| output, h_n = self._run_recurrent(input, hx) | |||
| output = ms.ops.squeeze(output, 1) | |||
| h_n = ms.ops.squeeze(h_n, 1) | |||
| else: | |||
| max_batch_size = input.shape[0] if self.batch_first else input.shape[1] | |||
| hx = self._get_hx(input, hx, max_batch_size, is_batched, input.dtype) | |||
| if self.batch_first: | |||
| # self.rnn_cell do not support batch-first input, so need to transpose. | |||
| input = ms.ops.transpose(input, (1, 0, 2)) | |||
| output, h_n = self._run_recurrent(input, hx) | |||
| output = ms.ops.transpose(output, (1, 0, 2)) | |||
| else: | |||
| output, h_n = self._run_recurrent(input, hx) | |||
| return cast_to_adapter_tensor(output.astype(x_dtype)), cast_to_adapter_tensor(h_n.astype(x_dtype)) | |||
| class RNN(RNNBase): | |||
| @@ -280,9 +394,9 @@ class RNN(RNNBase): | |||
| super(RNN, self).__init__(mode, *args, **kwargs) | |||
| if mode == 'RNN_TANH': | |||
| self.rnn_cell = _DynamicRNNRelu() | |||
| elif mode == 'RNN_RELU': | |||
| self.rnn_cell = _DynamicRNNTanh() | |||
| elif mode == 'RNN_RELU': | |||
| self.rnn_cell = _DynamicRNNRelu() | |||
| class GRU(RNNBase): | |||
| def __init__(self, *args, **kwargs): | |||
| @@ -296,56 +410,150 @@ class GRU(RNNBase): | |||
| else: | |||
| self.rnn_cell = _DynamicGRUCPUGPU() | |||
| def _lstm_proj_unit(inputs, hidden, w_ih, w_hh, b_ih, b_hh, w_hr): | |||
| # ms.ops.matmul not support transpose input, and ms.ops.split do not support spilt to certain number. | |||
| # so, here use ms.ops.MatMul and ms.ops.Split | |||
| _matmul = _get_cache_prim(ms.ops.MatMul)(False, True) | |||
| _spilt = _get_cache_prim(ms.ops.Split)(1, 4) | |||
| hx, cx = hidden | |||
| if b_ih is None: | |||
| gates = _matmul(inputs, w_ih) + _matmul(hx, w_hh) | |||
| else: | |||
| gates = _matmul(inputs, w_ih) + _matmul(hx, w_hh) + b_ih + b_hh | |||
| ingate, forgetgate, cellgate, outgate = _spilt(gates) | |||
| ingate = ms.ops.sigmoid(ingate) | |||
| forgetgate = ms.ops.sigmoid(forgetgate) | |||
| cellgate = ms.ops.tanh(cellgate) | |||
| outgate = ms.ops.sigmoid(outgate) | |||
| cy = (forgetgate * cx) + (ingate * cellgate) | |||
| hy = outgate * ms.ops.tanh(cy) | |||
| hy = _matmul(hy, w_hr) | |||
| return hy, cy | |||
| def _lstm_proj_recurrent(x, h_0, w_ih, w_hh, b_ih, b_hh, w_hr): | |||
| time_step = x.shape[0] | |||
| outputs = [] | |||
| t = 0 | |||
| h = h_0 | |||
| while t < time_step: | |||
| x_t = x[t:t + 1:1] | |||
| x_t = ms.ops.squeeze(x_t, 0) | |||
| h = _lstm_proj_unit(x_t, h, w_ih, w_hh, b_ih, b_hh, w_hr) | |||
| outputs.append(h[0]) | |||
| t += 1 | |||
| outputs = ms.ops.stack(outputs, 0) | |||
| return outputs, h | |||
| def _lstm_proj_variable_recurrent(x, h, seq_length, w_ih, w_hh, b_ih, b_hh, w_hr): | |||
| '''recurrent steps with sequence length''' | |||
| time_step = x.shape[0] | |||
| h_t = h | |||
| proj_size = h[0].shape[-1] | |||
| hidden_size = h[1].shape[-1] | |||
| zero_output = ms.ops.zeros_like(h_t[0]) | |||
| h_seq_length = ms.ops.cast(seq_length, ms.float32) | |||
| h_seq_length = ms.ops.broadcast_to(h_seq_length, (proj_size, -1)) | |||
| h_seq_length = ms.ops.cast(h_seq_length, ms.int32) | |||
| h_seq_length = ms.ops.transpose(h_seq_length, (1, 0)) | |||
| c_seq_length = ms.ops.cast(seq_length, ms.float32) | |||
| c_seq_length = ms.ops.broadcast_to(c_seq_length, (hidden_size, -1)) | |||
| c_seq_length = ms.ops.cast(c_seq_length, ms.int32) | |||
| c_seq_length = ms.ops.transpose(c_seq_length, (1, 0)) | |||
| outputs = [] | |||
| state_t = h_t | |||
| t = 0 | |||
| while t < time_step: | |||
| x_t = x[t:t + 1:1] | |||
| x_t = ms.ops.squeeze(x_t, 0) | |||
| h_t = _lstm_proj_unit(x_t, state_t, w_ih, w_hh, b_ih, b_hh, w_hr) | |||
| h_seq_cond = h_seq_length > t | |||
| c_seq_cond = c_seq_length > t | |||
| state_t_0 = ms.ops.select(h_seq_cond, h_t[0], state_t[0]) | |||
| state_t_1 = ms.ops.select(c_seq_cond, h_t[1], state_t[1]) | |||
| output = ms.ops.select(h_seq_cond, h_t[0], zero_output) | |||
| state_t = (state_t_0, state_t_1) | |||
| outputs.append(output) | |||
| t += 1 | |||
| outputs = ms.ops.stack(outputs) | |||
| return outputs, state_t | |||
| def _lstm_proj(x, h, seq_length, w_ih, w_hh, b_ih, b_hh, w_hr): | |||
| x_dtype = x.dtype | |||
| w_ih = w_ih.astype(x_dtype) | |||
| w_hh = w_hh.astype(x_dtype) | |||
| w_hr = w_hr.astype(x_dtype) | |||
| if b_ih is not None: | |||
| b_ih = b_ih.astype(x_dtype) | |||
| b_hh = b_hh.astype(x_dtype) | |||
| if seq_length is None: | |||
| return _lstm_proj_recurrent(x, h, w_ih, w_hh, b_ih, b_hh, w_hr) | |||
| return _lstm_proj_variable_recurrent(x, h, seq_length, w_ih, w_hh, b_ih, b_hh, w_hr) | |||
| class LSTM(RNNBase): | |||
| def __init__(self, *args, **kwargs): | |||
| super(LSTM, self).__init__('LSTM', *args, **kwargs) | |||
| if self.proj_size > 0: | |||
| raise NotImplementedError("For LSTM, proj_size > 0 is not supported yet.") | |||
| if is_under_ascend_context(): | |||
| self.lstm_cell = _DynamicLSTMAscend() | |||
| else: | |||
| self.lstm_cell = _DynamicLSTMCPUGPU() | |||
| def forward(self, input, hx=None): | |||
| if len(input.shape) not in (2, 3): | |||
| raise RuntimeError(f"For LSTM, input should be 2D or 3D, but got {len(input.shape)}D.") | |||
| is_batched = len(input.shape) == 3 | |||
| self.lstm_cell_proj= _lstm_proj | |||
| input = cast_to_ms_tensor(input) | |||
| if not is_batched: | |||
| input = ms.ops.unsqueeze(input, 1) | |||
| def get_expected_cell_size(self, input, batch_sizes): | |||
| if batch_sizes is not None: | |||
| mini_batch = int(batch_sizes[0]) | |||
| else: | |||
| if self.batch_first: | |||
| input = ms.ops.transpose(input, (1, 0, 2)) | |||
| x_dtype = input.dtype | |||
| max_batch_size = input.shape[1] | |||
| mini_batch = input.shape[0] if self.batch_first else input.shape[1] | |||
| num_directions = 2 if self.bidirectional else 1 | |||
| real_hidden_size = self.proj_size if self.proj_size > 0 else self.hidden_size | |||
| if hx is None: | |||
| h_zeros = zeros(self.num_layers * num_directions, | |||
| max_batch_size, real_hidden_size, | |||
| dtype=x_dtype) | |||
| c_zeros = zeros(self.num_layers * num_directions, | |||
| max_batch_size, self.hidden_size, | |||
| dtype=x_dtype) | |||
| hx = (h_zeros, c_zeros) | |||
| hx = cast_to_ms_tensor(hx) | |||
| expected_hidden_size = (self.num_layers * num_directions, | |||
| mini_batch, self.hidden_size) | |||
| return expected_hidden_size | |||
| def check_forward_args(self, input, hidden, batch_sizes): | |||
| self.check_input(input, batch_sizes) | |||
| self.check_hidden_size(hidden[0], self.get_expected_hidden_size(input, batch_sizes), | |||
| 'Expected hidden[0] size {}, got {}') | |||
| self.check_hidden_size(hidden[1], self.get_expected_cell_size(input, batch_sizes), | |||
| 'Expected hidden[1] size {}, got {}') | |||
| def permute_hidden(self, hx, permutation): | |||
| if permutation is None: | |||
| return hx | |||
| return _apply_permutation(hx[0], permutation), _apply_permutation(hx[1], permutation) | |||
| def _get_weight_and_bias(self, num_directions, layer, bias, proj_size): | |||
| if proj_size: | |||
| _param_nums_per_directions = 5 if bias else 3 | |||
| else: | |||
| hx = cast_to_ms_tensor(hx) | |||
| if is_batched: | |||
| if (len(hx[0].shape) != 3 or len(hx[1].shape) != 3): | |||
| msg = ("For batched 3-D input, hx and cx should " | |||
| f"also be 3-D but got ({len(hx[0].shape)}-D, {len(hx[1].shape)}-D) tensors") | |||
| raise RuntimeError(msg) | |||
| _param_nums_per_directions = 4 if bias else 2 | |||
| _param_nums_per_layer = num_directions * _param_nums_per_directions | |||
| offset = _param_nums_per_layer * layer | |||
| param = () | |||
| for _ in range(num_directions): | |||
| if bias: | |||
| param += tuple(self._flat_weights[offset:offset + _param_nums_per_directions]) | |||
| else: | |||
| if len(hx[0].shape) != 2 or len(hx[1].shape) != 2: | |||
| msg = ("For unbatched 2-D input, hx and cx should " | |||
| f"also be 2-D but got ({len(hx[0].shape)}-D, {len(hx[1].shape)}-D) tensors") | |||
| raise RuntimeError(msg) | |||
| hx = (ms.ops.unsqueeze(hx[0], 1), ms.ops.unsqueeze(hx[1], 1)) | |||
| param += tuple(self._flat_weights[offset:offset + 2]) | |||
| param += (None, None) | |||
| param += tuple(self._flat_weights[offset + 2:offset+_param_nums_per_directions]) | |||
| offset = offset + _param_nums_per_directions | |||
| # cast parameter to ms.Tensor before call ms function. | |||
| return cast_to_ms_tensor(param) | |||
| def _run_recurrent(self, input, hx, length=None): | |||
| num_directions = 2 if self.bidirectional else 1 | |||
| pre_layer = input | |||
| h_n = () | |||
| @@ -355,28 +563,54 @@ class LSTM(RNNBase): | |||
| if num_directions == 1: | |||
| for i in range(self.num_layers): | |||
| w_ih, w_hh, b_ih, b_hh = self._get_weight_and_bias(num_directions, i, self.bias) | |||
| if self.proj_size: | |||
| layer_params = self._get_weight_and_bias(num_directions, i, self.bias, True) | |||
| else: | |||
| layer_params = self._get_weight_and_bias(num_directions, i, self.bias, False) | |||
| h_i = (hx[0][i], hx[1][i]) | |||
| output, hc_t = self.lstm_cell(pre_layer, h_i, None, w_ih, w_hh, b_ih, b_hh) | |||
| if self.proj_size: | |||
| output, hc_t = self.lstm_cell_proj(pre_layer, h_i, length, *layer_params) | |||
| else: | |||
| output, hc_t = self.lstm_cell(pre_layer, h_i, length, *layer_params) | |||
| h_t, c_t = hc_t | |||
| h_n += (h_t,) | |||
| c_n += (c_t,) | |||
| pre_layer = ms.ops.dropout(output, 1 - self.dropout) \ | |||
| pre_layer = ms.ops.dropout(output, self.dropout) \ | |||
| if (self.dropout != 0 and i < self.num_layers - 1) else output | |||
| else: | |||
| for i in range(self.num_layers): | |||
| w_ih, w_hh, b_ih, b_hh, w_ih_b, w_hh_b, b_ih_b, b_hh_b = \ | |||
| self._get_weight_and_bias(num_directions, i, self.bias) | |||
| if self.proj_size > 0: | |||
| layer_params = self._get_weight_and_bias(num_directions, i, self.bias, True) | |||
| else: | |||
| layer_params = self._get_weight_and_bias(num_directions, i, self.bias, False) | |||
| x_b = ms.ops.reverse(pre_layer, [0]) | |||
| h_i = (hx[0][2 * i], hx[1][2 * i]) | |||
| h_b_i = (hx[0][2 * i + 1], hx[1][2 * i + 1]) | |||
| output, hc_t = self.lstm_cell(pre_layer, h_i, None, w_ih, w_hh, b_ih, b_hh) | |||
| output_b, hc_t_b = self.lstm_cell(x_b, h_b_i, None, w_ih_b, w_hh_b, b_ih_b, b_hh_b) | |||
| output_b = ms.ops.reverse(output_b, [0]) | |||
| if length is None: | |||
| x_b = ms.ops.reverse(pre_layer, [0]) | |||
| else: | |||
| x_b = ms.ops.reverse_sequence(pre_layer, length, 0, 1) | |||
| if self.proj_size > 0: | |||
| output, hc_t = self.lstm_cell_proj( | |||
| pre_layer, h_i, length, *layer_params[:5]) | |||
| output_b, hc_t_b = self.lstm_cell_proj( | |||
| x_b, h_b_i, length, *layer_params[5:]) | |||
| else: | |||
| output, hc_t = self.lstm_cell(pre_layer, h_i, length, *layer_params[:4]) | |||
| output_b, hc_t_b = self.lstm_cell(x_b, h_b_i, length, *layer_params[4:]) | |||
| if length is None: | |||
| output_b = ms.ops.reverse(output_b, [0]) | |||
| else: | |||
| output_b = ms.ops.reverse_sequence(output_b, length, 0, 1) | |||
| output = ms.ops.concat((output, output_b), 2) | |||
| h_t, c_t = hc_t | |||
| h_t_b, c_t_b = hc_t_b | |||
| @@ -385,20 +619,105 @@ class LSTM(RNNBase): | |||
| c_n += (c_t,) | |||
| c_n += (c_t_b,) | |||
| pre_layer = ms.ops.dropout(output, 1 - self.dropout) \ | |||
| pre_layer = ms.ops.dropout(output, self.dropout) \ | |||
| if (self.dropout != 0 and i < self.num_layers - 1) else output | |||
| h_n = ms.ops.concat(h_n, 0) | |||
| h_n = h_n.view(hx[0].shape) | |||
| c_n = ms.ops.concat(c_n, 0) | |||
| c_n = c_n.view(hx[1].shape) | |||
| return output, h_n, c_n | |||
| def _get_hx(self, input, hx, max_batch_size,real_hidden_size, is_batched, dtype): | |||
| num_directions = 2 if self.bidirectional else 1 | |||
| if hx is None: | |||
| h_zeros = ms.ops.zeros((self.num_layers * num_directions, | |||
| max_batch_size, real_hidden_size), | |||
| dtype=dtype) | |||
| c_zeros = ms.ops.zeros((self.num_layers * num_directions, | |||
| max_batch_size, self.hidden_size), | |||
| dtype=dtype) | |||
| hx = (h_zeros, c_zeros) | |||
| else: | |||
| hx = cast_to_ms_tensor(hx) | |||
| if is_batched: | |||
| if (hx[0].ndim != 3 or hx[1].ndim != 3): | |||
| msg = ("For batched 3-D input, hx and cx should " | |||
| f"also be 3-D but got ({hx[0].ndim}-D, {hx[1].ndim}-D) tensors") | |||
| raise RuntimeError(msg) | |||
| else: | |||
| if hx[0].ndim != 2 or hx[1].ndim != 2: | |||
| msg = ("For unbatched 2-D input, hx and cx should " | |||
| f"also be 2-D but got ({hx[0].ndim}-D, {hx[1].ndim}-D) tensors") | |||
| raise RuntimeError(msg) | |||
| hx = (hx[0].unsqueeze(1), hx[1].unsqueeze(1)) | |||
| self.check_forward_args(input, hx, None) | |||
| return hx | |||
| def forward(self, input, hx=None): | |||
| orig_input = input | |||
| real_hidden_size = self.proj_size if self.proj_size > 0 else self.hidden_size | |||
| length = None | |||
| # for jit | |||
| sorted_indices = None | |||
| unsorted_indices = None | |||
| is_batched = None | |||
| if isinstance(orig_input, PackedSequence): | |||
| _, batch_sizes, sorted_indices, unsorted_indices = orig_input | |||
| # mindspore can not process packed_sequence, should recover to normal tensor type | |||
| input, length = pad_packed_sequence(orig_input, batch_first=False) | |||
| input = cast_to_ms_tensor(input) | |||
| x_dtype = input.dtype | |||
| length = cast_to_ms_tensor(length) | |||
| input = input.index_select(1, ms.Tensor(sorted_indices)) | |||
| length = length.index_select(0, ms.Tensor(sorted_indices)) | |||
| if hx is None: | |||
| hx = self._get_hx(input, hx, input.shape[1], real_hidden_size, True, x_dtype) | |||
| else: | |||
| # Each batch of the hidden state should match the input sequence that | |||
| # the user believes he/she is passing in. | |||
| hx = cast_to_ms_tensor(hx) | |||
| hx = self.permute_hidden(hx, sorted_indices) | |||
| self.check_forward_args(input, hx, None) | |||
| output, h_n, c_n = self._run_recurrent(input, hx, length) | |||
| output = self._get_sequence_output(output, batch_sizes) | |||
| output = cast_to_adapter_tensor(output.astype(x_dtype)) | |||
| h_n = cast_to_adapter_tensor(h_n.astype(x_dtype)) | |||
| c_n = cast_to_adapter_tensor(c_n.astype(x_dtype)) | |||
| output_packed = PackedSequence(output, batch_sizes, sorted_indices, unsorted_indices) | |||
| return output_packed, self.permute_hidden((h_n, c_n), unsorted_indices) | |||
| batch_sizes = None | |||
| input = cast_to_ms_tensor(orig_input) | |||
| x_dtype = input.dtype | |||
| if input.ndim not in (2, 3): | |||
| raise ValueError(f"Expected input to be 2-D or 3-D but received {input.ndim}-D tensor") | |||
| is_batched = input.ndim == 3 | |||
| if not is_batched: | |||
| input = input.unsqueeze(1) | |||
| hx = self._get_hx(input, hx, 1, real_hidden_size, False, input.dtype) | |||
| output, h_n, c_n = self._run_recurrent(input, hx) | |||
| output = ms.ops.squeeze(output, 1) | |||
| h_n = ms.ops.squeeze(h_n, 1) | |||
| c_n = ms.ops.squeeze(c_n, 1) | |||
| else: | |||
| max_batch_size = input.shape[0] if self.batch_first else input.shape[1] | |||
| hx = self._get_hx(input, hx, max_batch_size, real_hidden_size, True, input.dtype) | |||
| if self.batch_first: | |||
| input = ms.ops.transpose(input, (1, 0, 2)) | |||
| output, h_n, c_n = self._run_recurrent(input, hx) | |||
| output = ms.ops.transpose(output, (1, 0, 2)) | |||
| else: | |||
| output, h_n, c_n = self._run_recurrent(input, hx) | |||
| return cast_to_adapter_tensor(output.astype(x_dtype)), \ | |||
| cast_to_adapter_tensor((h_n.astype(x_dtype), c_n.astype(x_dtype))) | |||
+ 9
- 8
msadapter/pytorch/nn/modules/upsampling.py
View File
| @@ -37,21 +37,22 @@ class Upsample(Module): | |||
| """ | |||
| def __init__(self, size=None, scale_factor=None, mode='bilinear', align_corners=None, recompute_scale_factor=None): | |||
| def __init__(self, size=None, scale_factor=None, mode='nearest', align_corners=None, recompute_scale_factor=None): | |||
| super(Upsample, self).__init__() | |||
| self.name = type(self).__name__ | |||
| self.size = size | |||
| self.scale_factor = scale_factor | |||
| if isinstance(scale_factor, tuple): | |||
| self.scale_factor = tuple(float(factor) for factor in scale_factor) | |||
| else: | |||
| self.scale_factor = float(scale_factor) if scale_factor else None | |||
| self.mode = mode | |||
| self.align_corners = align_corners | |||
| if recompute_scale_factor is not None: | |||
| raise ValueError("recompute_scale_factor is not supported") | |||
| self.recompute_scale_factor = recompute_scale_factor | |||
| def forward(self, input): | |||
| return adapter_F.interpolate( | |||
| input, size=self.size, scale_factor=self.scale_factor, mode=self.mode, | |||
| align_corners=self.align_corners | |||
| ) | |||
| return adapter_F.interpolate(input, size=self.size, scale_factor=self.scale_factor, | |||
| mode=self.mode, align_corners=self.align_corners, | |||
| recompute_scale_factor=self.recompute_scale_factor) | |||
| def extra_repr(self) -> str: | |||
| if self.scale_factor is not None: | |||
+ 2
- 13
msadapter/pytorch/nn/modules/utils.py
View File
| @@ -4,10 +4,8 @@ import collections | |||
| from itertools import repeat | |||
| # from functools import lru_cache | |||
| import mindspore as ms | |||
| from mindspore.ops._primitive_cache import _get_cache_prim | |||
| from mindspore.ops.primitive import _primexpr | |||
| # from msadapter.utils import unsupported_attr,_GLOBAL_LRU_CACHE_SIZE, _GLOBAL_LRU_CACHE_SIZE_NN | |||
| from msadapter.utils import unsupported_attr | |||
| def _ntuple(n, name="parse"): | |||
| @@ -113,14 +111,5 @@ def _reverse_padding(network_padding): | |||
| def _do_pad(input, network_padding, *, mode='constant', value=None): | |||
| unsupported_attr(mode) | |||
| unsupported_attr(value) | |||
| if _is_zero_paddings(network_padding): | |||
| return input | |||
| rank_op = _get_cache_prim(ms.ops.Rank)() | |||
| x_ndim = rank_op(input) | |||
| _pad = _expand_padding_for_padv1(network_padding, x_ndim) | |||
| return _get_cache_prim(ms.ops.Pad)(_pad)(input) | |||
| # TODO: switch to code below aften ms.ops.pad support on Ascend | |||
| # _pad = _reverse_padding(network_padding) | |||
| # return ms.ops.pad(input, _pad, mode, value) | |||
| _pad = _reverse_padding(network_padding) | |||
| return ms.ops.pad(input, _pad, mode, value) | |||
+ 3
- 1
msadapter/pytorch/nn/parameter.py
View File
| @@ -61,6 +61,7 @@ class Parameter(ms.Parameter): | |||
| Parameter, (data, self.requires_grad, self.name, self.layerwise_parallel)) | |||
| def __init__(self, data, requires_grad=True, name=None, layerwise_parallel=False, parallel_optimizer=True): | |||
| self.adapter_flag = True | |||
| super().__init__(default_input=data, name=name, requires_grad=requires_grad, | |||
| layerwise_parallel=layerwise_parallel, parallel_optimizer=parallel_optimizer) | |||
| @@ -71,9 +72,10 @@ class Parameter(ms.Parameter): | |||
| return new_obj | |||
| def __str__(self): | |||
| if self.init_finished: | |||
| Tensor_.data_sync(self.data, True) | |||
| return f'Parameter containing: {Tensor_.__repr__(self.data)}, requires_grad={self.requires_grad})' | |||
| @staticmethod | |||
| def _get_base_class(input_class): | |||
| input_class_name = Parameter.__name__ | |||
+ 1
- 1
msadapter/pytorch/nn/utils/rnn.py
View File
| @@ -205,7 +205,7 @@ def _pack_padded_sequence(_input, _lengths, batch_first): | |||
| batch_sizes_i = batch_sizes_i + 1 | |||
| prev_l = l | |||
| return (ms.ops.cat(steps), batch_sizes_t) | |||
| return cast_to_adapter_tensor(ms.ops.cat(steps)), batch_sizes_t | |||
| def _packed_sequence_init(data, batch_sizes=None, sorted_indices=None, unsorted_indices=None): | |||
| data, batch_sizes, sorted_indices, unsorted_indices = _packed_sequence_init_args( | |||
+ 6
- 24
msadapter/pytorch/optim/__init__.py
View File
| @@ -1,27 +1,9 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| from msadapter.pytorch.optim.optimizer import Optimizer | |||
| from msadapter.pytorch.optim.sgd import SGD | |||
| from msadapter.pytorch.optim.adam import Adam | |||
| from msadapter.pytorch.optim.adamw import AdamW | |||
| from msadapter.pytorch.optim import lr_scheduler | |||
| from mindspore.nn.optim import SGD | |||
| from mindspore.nn.optim import Adam | |||
| from mindspore.nn.optim import Momentum | |||
| from mindspore.nn.optim import LARS | |||
| from mindspore.nn.optim import AdamWeightDecay | |||
| from mindspore.nn.optim import LazyAdam | |||
| from mindspore.nn.optim import AdamOffload | |||
| from mindspore.nn.optim import Lamb | |||
| from mindspore.nn.optim import ASGD | |||
| from mindspore.nn.optim import RMSProp | |||
| from mindspore.nn.optim import Rprop | |||
| from mindspore.nn.optim import FTRL | |||
| from mindspore.nn.optim import ProximalAdagrad | |||
| from mindspore.nn.optim import Adagrad | |||
| from mindspore.nn.optim import thor | |||
| from mindspore.nn.optim import AdaFactor | |||
| from mindspore.nn.optim import AdaSumByDeltaWeightWrapCell | |||
| from mindspore.nn.optim import AdaSumByGradWrapCell | |||
| from mindspore.nn.optim import AdaMax | |||
| from mindspore.nn.optim import Adadelta | |||
| __all__ = ['Momentum', 'LARS', 'Adam', 'AdamWeightDecay', 'LazyAdam', 'AdamOffload', | |||
| 'Lamb', 'SGD', 'ASGD', 'Rprop', 'FTRL', 'RMSProp', 'ProximalAdagrad', 'Adagrad', 'thor', 'AdaFactor', | |||
| 'AdaSumByDeltaWeightWrapCell', 'AdaSumByGradWrapCell', 'AdaMax', 'Adadelta'] | |||
| __all__ = ['Optimizer', 'SGD', 'Adam', 'AdamW'] | |||
+ 26
- 0
msadapter/pytorch/optim/adam.py
View File
| @@ -0,0 +1,26 @@ | |||
| from mindspore.experimental.optim import Adam as Adam_MS | |||
| from msadapter.pytorch.optim.optimizer import _Optimizer, _is_tensor | |||
| from msadapter.pytorch.tensor import tensor | |||
| class Adam(_Optimizer, Adam_MS): | |||
| def __init__(self, *args, **kwargs): | |||
| Adam_MS.__init__(self, *args, **kwargs) | |||
| _Optimizer.__init__(self) | |||
| def __setstate__(self, state): | |||
| _Optimizer.__setstate__(self, state) | |||
| for group in self.param_groups: | |||
| group.setdefault('amsgrad', False) | |||
| group.setdefault('maximize', False) | |||
| state_values = list(self.state.values()) | |||
| step_is_tensor = (len(state_values) != 0) and _is_tensor(state_values[0]['step']) | |||
| if not step_is_tensor: | |||
| for s in state_values: | |||
| s['step'] = tensor(float(s['step'])) | |||
| def state_dict(self): | |||
| return super()._ms_state_dict('exp_avg', 'exp_avg_sq', 'max_exp_avg_sq', 'state_step') | |||
| def load_state_dict(self, state_dict): | |||
| return super()._ms_load_state_dict(state_dict, 'exp_avg', 'exp_avg_sq', 'max_exp_avg_sq', 'state_step') | |||
+ 26
- 0
msadapter/pytorch/optim/adamw.py
View File
| @@ -0,0 +1,26 @@ | |||
| from mindspore.experimental.optim import AdamW as AdamW_MS | |||
| from msadapter.pytorch.optim.optimizer import _Optimizer, _is_tensor | |||
| from msadapter.pytorch.tensor import tensor | |||
| class AdamW(_Optimizer, AdamW_MS): | |||
| def __init__(self, *args, **kwargs): | |||
| AdamW_MS.__init__(self, *args, **kwargs) | |||
| _Optimizer.__init__(self) | |||
| def __setstate__(self, state): | |||
| _Optimizer.__setstate__(self, state) | |||
| for group in self.param_groups: | |||
| group.setdefault('amsgrad', False) | |||
| group.setdefault('maximize', False) | |||
| state_values = list(self.state.values()) | |||
| step_is_tensor = (len(state_values) != 0) and _is_tensor(state_values[0]['step']) | |||
| if not step_is_tensor: | |||
| for s in state_values: | |||
| s['step'] = tensor(float(s['step'])) | |||
| def state_dict(self): | |||
| return super()._ms_state_dict('exp_avg', 'exp_avg_sq', 'max_exp_avg_sq', 'state_step') | |||
| def load_state_dict(self, state_dict): | |||
| return super()._ms_load_state_dict(state_dict, 'exp_avg', 'exp_avg_sq', 'max_exp_avg_sq', 'state_step') | |||
+ 979
- 0
msadapter/pytorch/optim/lr_scheduler.py
View File
| @@ -0,0 +1,979 @@ | |||
| import types | |||
| import warnings | |||
| from collections import Counter | |||
| from bisect import bisect_right | |||
| import math | |||
| import mindspore as ms | |||
| from msadapter.utils import graph_mode_condition, unsupported_attr | |||
| from msadapter.pytorch.optim.optimizer import Optimizer | |||
| __all__ = ['StepLR', 'LRScheduler', 'LambdaLR', 'MultiplicativeLR', 'StepLR', 'MultiStepLR', | |||
| 'ConstantLR', 'LinearLR', 'ExponentialLR', 'CosineAnnealingLR'] | |||
| EPOCH_DEPRECATION_WARNING = ( | |||
| "The epoch parameter in `scheduler.step()` was not necessary and is being " | |||
| "deprecated where possible. Please use `scheduler.step()` to step the " | |||
| "scheduler. During the deprecation, if epoch is different from None, the " | |||
| "closed form is used instead of the new chainable form, where available. " | |||
| ) | |||
| class LRScheduler: | |||
| def __init__(self, optimizer, last_epoch=-1, verbose=False): | |||
| if not isinstance(optimizer, Optimizer): | |||
| raise TypeError('{} is not an Optimizer'.format( | |||
| type(optimizer).__name__)) | |||
| self.optimizer = optimizer | |||
| if last_epoch == -1: | |||
| for group in optimizer.param_groups: | |||
| if isinstance(group['lr'], ms.Parameter): | |||
| group.setdefault('initial_lr', group['lr'].value()) # Tensor | |||
| else: | |||
| group.setdefault('initial_lr', group['lr']) | |||
| else: | |||
| for i, group in enumerate(optimizer.param_groups): | |||
| if 'initial_lr' not in group: | |||
| raise KeyError("param 'initial_lr' is not specified " | |||
| "in param_groups[{}] when resuming an optimizer".format(i)) | |||
| self.base_lrs = [group['initial_lr'] for group in optimizer.param_groups] | |||
| self.last_epoch = last_epoch | |||
| self.verbose = verbose | |||
| self._initial_step() | |||
| def _initial_step(self): | |||
| self._step_count = 0 | |||
| self.step() | |||
| def _process_state_dict(self, state_d): | |||
| if 'base_lrs' in state_d: | |||
| for i, base_lr in enumerate(state_d['base_lrs']): | |||
| if isinstance(base_lr, ms.Tensor): | |||
| state_d['base_lrs'][i] = base_lr.asnumpy().tolist() | |||
| if '_last_lr' in state_d: | |||
| for i, base_lr in enumerate(state_d['_last_lr']): | |||
| if isinstance(base_lr, ms.Tensor): | |||
| state_d['_last_lr'][i] = base_lr.asnumpy().tolist() | |||
| return state_d | |||
| def _process_state_dict_revert(self, state_d): | |||
| pg = self.optimizer.param_groups | |||
| if 'base_lrs' in state_d: | |||
| for i, base_lr in enumerate(state_d['base_lrs']): | |||
| _lr = pg[i]['lr'] | |||
| if isinstance(_lr, ms.Tensor): | |||
| state_d['base_lrs'][i] = ms.Tensor(base_lr, dtype=_lr.dtype) | |||
| if '_last_lr' in state_d: | |||
| for i, base_lr in enumerate(state_d['_last_lr']): | |||
| _lr = pg[i]['lr'] | |||
| if isinstance(_lr, ms.Tensor): | |||
| state_d['_last_lr'][i] = ms.Tensor(base_lr, dtype=_lr.dtype) | |||
| return state_d | |||
| def state_dict(self): | |||
| ret = {key: value for key, value in self.__dict__.items() if key != 'optimizer'} | |||
| ret = self._process_state_dict(ret) | |||
| return ret | |||
| def load_state_dict(self, state_dict): | |||
| state_dict = self._process_state_dict_revert(state_dict) | |||
| self.__dict__.update(state_dict) | |||
| def get_last_lr(self): | |||
| for i, lr in enumerate(self._last_lr): | |||
| if isinstance(lr, ms.Tensor): | |||
| self._last_lr[i] = lr.asnumpy().tolist() | |||
| return self._last_lr | |||
| def get_lr(self): | |||
| raise NotImplementedError | |||
| def print_lr(self, is_verbose, group, lr, epoch=None): | |||
| if isinstance(lr, ms.Tensor): | |||
| lr = lr.asnumpy().tolist() | |||
| if is_verbose: | |||
| if epoch is None: | |||
| print('Adjusting learning rate' | |||
| ' of group {} to {:.4e}.'.format(group, lr)) | |||
| else: | |||
| epoch_str = ("%.2f" if isinstance(epoch, float) else | |||
| "%.5d") % epoch | |||
| print('Epoch {}: adjusting learning rate' | |||
| ' of group {} to {:.4e}.'.format(epoch_str, group, lr)) | |||
| def step(self, epoch=None): | |||
| self._step_count += 1 | |||
| if epoch is None: | |||
| self.last_epoch += 1 | |||
| values = self.get_lr() | |||
| else: | |||
| warnings.warn(EPOCH_DEPRECATION_WARNING, UserWarning) | |||
| self.last_epoch = epoch | |||
| if hasattr(self, "_get_closed_form_lr"): | |||
| values = self._get_closed_form_lr() | |||
| else: | |||
| values = self.get_lr() | |||
| for i, data in enumerate(zip(self.optimizer.param_groups, values)): | |||
| param_group, lr = data | |||
| if isinstance(param_group['lr'], ms.Parameter): | |||
| if not isinstance(lr, ms.Tensor): | |||
| lr = ms.ops.scalar_to_tensor(lr) | |||
| lr = ms.ops.depend(lr, ms.ops.assign(param_group['lr'], lr)) | |||
| else: | |||
| param_group['lr'] = lr | |||
| self.print_lr(self.verbose, i, lr, epoch) | |||
| self._last_lr = [group['lr'] for group in self.optimizer.param_groups] | |||
| class _LRScheduler(LRScheduler): | |||
| pass | |||
| class LambdaLR(LRScheduler): | |||
| def __init__(self, optimizer, lr_lambda, last_epoch=-1, verbose=False): | |||
| self.optimizer = optimizer | |||
| if not isinstance(lr_lambda, list) and not isinstance(lr_lambda, tuple): | |||
| self.lr_lambdas = [lr_lambda] * len(optimizer.param_groups) | |||
| else: | |||
| if len(lr_lambda) != len(optimizer.param_groups): | |||
| raise ValueError("Expected {} lr_lambdas, but got {}".format( | |||
| len(optimizer.param_groups), len(lr_lambda))) | |||
| self.lr_lambdas = list(lr_lambda) | |||
| super().__init__(optimizer, last_epoch, verbose) | |||
| def state_dict(self): | |||
| state_dict = {key: value for key, value in self.__dict__.items() if key not in ('optimizer', 'lr_lambdas')} | |||
| state_dict['lr_lambdas'] = [None] * len(self.lr_lambdas) | |||
| for idx, fn in enumerate(self.lr_lambdas): | |||
| if not isinstance(fn, types.FunctionType): | |||
| state_dict['lr_lambdas'][idx] = fn.__dict__.copy() | |||
| state_dict = self._process_state_dict(state_dict) | |||
| return state_dict | |||
| def load_state_dict(self, state_dict): | |||
| lr_lambdas = state_dict.pop('lr_lambdas') | |||
| state_dict = self._process_state_dict_revert(state_dict) | |||
| self.__dict__.update(state_dict) | |||
| state_dict['lr_lambdas'] = lr_lambdas | |||
| for idx, fn in enumerate(lr_lambdas): | |||
| if fn is not None: | |||
| self.lr_lambdas[idx].__dict__.update(fn) | |||
| def get_lr(self): | |||
| return [base_lr * lmbda(self.last_epoch) | |||
| for lmbda, base_lr in zip(self.lr_lambdas, self.base_lrs)] | |||
| class MultiplicativeLR(LRScheduler): | |||
| def __init__(self, optimizer, lr_lambda, last_epoch=-1, verbose=False): | |||
| self.optimizer = optimizer | |||
| if not isinstance(lr_lambda, list) and not isinstance(lr_lambda, tuple): | |||
| self.lr_lambdas = [lr_lambda] * len(optimizer.param_groups) | |||
| else: | |||
| if len(lr_lambda) != len(optimizer.param_groups): | |||
| raise ValueError("Expected {} lr_lambdas, but got {}".format( | |||
| len(optimizer.param_groups), len(lr_lambda))) | |||
| self.lr_lambdas = list(lr_lambda) | |||
| super().__init__(optimizer, last_epoch, verbose) | |||
| def state_dict(self): | |||
| state_dict = {key: value for key, value in self.__dict__.items() if key not in ('optimizer', 'lr_lambdas')} | |||
| state_dict['lr_lambdas'] = [None] * len(self.lr_lambdas) | |||
| for idx, fn in enumerate(self.lr_lambdas): | |||
| if not isinstance(fn, types.FunctionType): | |||
| state_dict['lr_lambdas'][idx] = fn.__dict__.copy() | |||
| state_dict = self._process_state_dict(state_dict) | |||
| return state_dict | |||
| def load_state_dict(self, state_dict): | |||
| lr_lambdas = state_dict.pop('lr_lambdas') | |||
| state_dict = self._process_state_dict_revert(state_dict) | |||
| self.__dict__.update(state_dict) | |||
| state_dict['lr_lambdas'] = lr_lambdas | |||
| for idx, fn in enumerate(lr_lambdas): | |||
| if fn is not None: | |||
| self.lr_lambdas[idx].__dict__.update(fn) | |||
| def get_lr(self): | |||
| if self.last_epoch > 0: | |||
| return [group['lr'] * lmbda(self.last_epoch) | |||
| for lmbda, group in zip(self.lr_lambdas, self.optimizer.param_groups)] | |||
| else: | |||
| return [group['lr'] for group in self.optimizer.param_groups] | |||
| class StepLR(LRScheduler): | |||
| def __init__(self, optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False): | |||
| self.step_size = step_size | |||
| self.gamma = gamma | |||
| super().__init__(optimizer, last_epoch, verbose) | |||
| def get_lr(self): | |||
| if (self.last_epoch == 0) or (self.last_epoch % self.step_size != 0): | |||
| return [group['lr'] for group in self.optimizer.param_groups] | |||
| return [group['lr'] * self.gamma | |||
| for group in self.optimizer.param_groups] | |||
| def _get_closed_form_lr(self): | |||
| return [base_lr * self.gamma ** (self.last_epoch // self.step_size) | |||
| for base_lr in self.base_lrs] | |||
| class MultiStepLR(LRScheduler): | |||
| def __init__(self, optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False): | |||
| self.milestones = Counter(milestones) | |||
| self.gamma = gamma | |||
| super().__init__(optimizer, last_epoch, verbose) | |||
| def get_lr(self): | |||
| if self.last_epoch not in self.milestones: | |||
| return [group['lr'] for group in self.optimizer.param_groups] | |||
| return [group['lr'] * self.gamma ** self.milestones[self.last_epoch] | |||
| for group in self.optimizer.param_groups] | |||
| def _get_closed_form_lr(self): | |||
| milestones = sorted(self.milestones.elements()) | |||
| return [base_lr * self.gamma ** bisect_right(milestones, self.last_epoch) | |||
| for base_lr in self.base_lrs] | |||
| class ConstantLR(LRScheduler): | |||
| def __init__(self, optimizer, factor=1.0 / 3, total_iters=5, last_epoch=-1, verbose=False): | |||
| if factor > 1.0 or factor < 0: | |||
| raise ValueError('Constant multiplicative factor expected to be between 0 and 1.') | |||
| self.factor = factor | |||
| self.total_iters = total_iters | |||
| super().__init__(optimizer, last_epoch, verbose) | |||
| def get_lr(self): | |||
| if self.last_epoch == 0: | |||
| return [group['lr'] * self.factor for group in self.optimizer.param_groups] | |||
| if self.last_epoch == self.total_iters: | |||
| return [group['lr'] * (1.0 / self.factor) for group in self.optimizer.param_groups] | |||
| return [group['lr'] for group in self.optimizer.param_groups] | |||
| def _get_closed_form_lr(self): | |||
| return [base_lr * (self.factor + (self.last_epoch >= self.total_iters) * (1 - self.factor)) | |||
| for base_lr in self.base_lrs] | |||
| class LinearLR(LRScheduler): | |||
| def __init__(self, optimizer, start_factor=1.0 / 3, end_factor=1.0, total_iters=5, last_epoch=-1, | |||
| verbose=False): | |||
| if start_factor > 1.0 or start_factor <= 0: | |||
| raise ValueError('Starting multiplicative factor expected to be greater than 0 and less or equal to 1.') | |||
| if end_factor > 1.0 or end_factor < 0: | |||
| raise ValueError('Ending multiplicative factor expected to be between 0 and 1.') | |||
| self.start_factor = start_factor | |||
| self.end_factor = end_factor | |||
| self.total_iters = total_iters | |||
| super().__init__(optimizer, last_epoch, verbose) | |||
| def get_lr(self): | |||
| if self.last_epoch == 0: | |||
| return [group['lr'] * self.start_factor for group in self.optimizer.param_groups] | |||
| if self.last_epoch > self.total_iters: | |||
| return [group['lr'] for group in self.optimizer.param_groups] | |||
| return [group['lr'] * (1. + (self.end_factor - self.start_factor) / | |||
| (self.total_iters * self.start_factor + (self.last_epoch - 1) * (self.end_factor - self.start_factor))) | |||
| for group in self.optimizer.param_groups] | |||
| def _get_closed_form_lr(self): | |||
| return [base_lr * (self.start_factor + | |||
| (self.end_factor - self.start_factor) * min(self.total_iters, self.last_epoch) / self.total_iters) | |||
| for base_lr in self.base_lrs] | |||
| class ExponentialLR(LRScheduler): | |||
| def __init__(self, optimizer, gamma, last_epoch=-1, verbose=False): | |||
| self.gamma = gamma | |||
| super().__init__(optimizer, last_epoch, verbose) | |||
| def get_lr(self): | |||
| if self.last_epoch == 0: | |||
| return [group['lr'] for group in self.optimizer.param_groups] | |||
| return [group['lr'] * self.gamma | |||
| for group in self.optimizer.param_groups] | |||
| def _get_closed_form_lr(self): | |||
| return [base_lr * self.gamma ** self.last_epoch | |||
| for base_lr in self.base_lrs] | |||
| class SequentialLR(LRScheduler): | |||
| def __init__(self, optimizer, schedulers, milestones, last_epoch=-1, verbose=False): | |||
| for scheduler_idx in range(len(schedulers)): | |||
| if schedulers[scheduler_idx].optimizer != optimizer: | |||
| raise ValueError( | |||
| "Sequential Schedulers expects all schedulers to belong to the same optimizer, but " | |||
| f"got schedulers at index {scheduler_idx} to be different than the optimizer passed in." | |||
| ) | |||
| if schedulers[scheduler_idx].optimizer != schedulers[0].optimizer: | |||
| raise ValueError( | |||
| "Sequential Schedulers expects all schedulers to belong to the same optimizer, but " | |||
| f"got schedulers at index {0} and {scheduler_idx} to be different." | |||
| ) | |||
| if len(milestones) != len(schedulers) - 1: | |||
| raise ValueError( | |||
| "Sequential Schedulers expects number of schedulers provided to be one more " | |||
| "than the number of milestone points, but got number of schedulers {} and the " | |||
| "number of milestones to be equal to {}".format(len(schedulers), len(milestones)) | |||
| ) | |||
| self._schedulers = schedulers | |||
| self._milestones = milestones | |||
| self.last_epoch = last_epoch + 1 | |||
| self.optimizer = optimizer | |||
| # Reset learning rates back to initial values | |||
| for group in self.optimizer.param_groups: | |||
| if isinstance(group["lr"], ms.Tensor): | |||
| ms.ops.assign(group["lr"], group["initial_lr"]) | |||
| else: | |||
| group["lr"] = group["initial_lr"] | |||
| # "Undo" the step performed by other schedulers | |||
| for scheduler in self._schedulers: | |||
| scheduler.last_epoch -= 1 | |||
| # Perform the initial step for only the first scheduler | |||
| self._schedulers[0]._initial_step() | |||
| self._last_lr = schedulers[0].get_last_lr() | |||
| def step(self): | |||
| self.last_epoch += 1 | |||
| idx = bisect_right(self._milestones, self.last_epoch) | |||
| scheduler = self._schedulers[idx] | |||
| if idx > 0 and self._milestones[idx - 1] == self.last_epoch: | |||
| scheduler.step(0) | |||
| else: | |||
| scheduler.step() | |||
| self._last_lr = scheduler.get_last_lr() | |||
| def state_dict(self): | |||
| state_dict = {key: value for key, value in self.__dict__.items() if key not in ('optimizer', '_schedulers')} | |||
| state_dict['_schedulers'] = [None] * len(self._schedulers) | |||
| for idx, s in enumerate(self._schedulers): | |||
| state_dict['_schedulers'][idx] = self._process_state_dict(s.state_dict()) | |||
| return state_dict | |||
| def load_state_dict(self, state_dict): | |||
| _schedulers = state_dict.pop('_schedulers') | |||
| self.__dict__.update(state_dict) | |||
| state_dict['_schedulers'] = _schedulers | |||
| for idx, s in enumerate(_schedulers): | |||
| self._schedulers[idx].load_state_dict(s) | |||
| class PolynomialLR(LRScheduler): | |||
| def __init__(self, optimizer, total_iters=5, power=1.0, last_epoch=-1, verbose=False): | |||
| self.total_iters = total_iters | |||
| self.power = power | |||
| super().__init__(optimizer, last_epoch, verbose) | |||
| def get_lr(self): | |||
| if self.last_epoch == 0 or self.last_epoch > self.total_iters: | |||
| return [group["lr"] for group in self.optimizer.param_groups] | |||
| decay_factor = ((1.0 - self.last_epoch / self.total_iters) / | |||
| (1.0 - (self.last_epoch - 1) / self.total_iters)) ** self.power | |||
| return [group["lr"] * decay_factor for group in self.optimizer.param_groups] | |||
| def _get_closed_form_lr(self): | |||
| return [ | |||
| ( | |||
| base_lr * (1.0 - min(self.total_iters, self.last_epoch) / self.total_iters) ** self.power | |||
| ) | |||
| for base_lr in self.base_lrs | |||
| ] | |||
| class CosineAnnealingLR(LRScheduler): | |||
| def __init__(self, optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False): | |||
| self.T_max = T_max | |||
| self.eta_min = eta_min | |||
| super().__init__(optimizer, last_epoch, verbose) | |||
| def get_lr(self): | |||
| if self.last_epoch == 0: | |||
| return [group['lr'] for group in self.optimizer.param_groups] | |||
| elif self._step_count == 1 and self.last_epoch > 0: | |||
| return [self.eta_min + (base_lr - self.eta_min) * | |||
| (1 + math.cos((self.last_epoch) * math.pi / self.T_max)) / 2 | |||
| for base_lr, group in | |||
| zip(self.base_lrs, self.optimizer.param_groups)] | |||
| elif (self.last_epoch - 1 - self.T_max) % (2 * self.T_max) == 0: | |||
| return [group['lr'] + (base_lr - self.eta_min) * | |||
| (1 - math.cos(math.pi / self.T_max)) / 2 | |||
| for base_lr, group in | |||
| zip(self.base_lrs, self.optimizer.param_groups)] | |||
| return [(1 + math.cos(math.pi * self.last_epoch / self.T_max)) / | |||
| (1 + math.cos(math.pi * (self.last_epoch - 1) / self.T_max)) * | |||
| (group['lr'] - self.eta_min) + self.eta_min | |||
| for group in self.optimizer.param_groups] | |||
| def _get_closed_form_lr(self): | |||
| return [self.eta_min + (base_lr - self.eta_min) * | |||
| (1 + math.cos(math.pi * self.last_epoch / self.T_max)) / 2 | |||
| for base_lr in self.base_lrs] | |||
| class ChainedScheduler(LRScheduler): | |||
| def __init__(self, schedulers): | |||
| for scheduler_idx in range(1, len(schedulers)): | |||
| if schedulers[scheduler_idx].optimizer != schedulers[0].optimizer: | |||
| raise ValueError( | |||
| "ChainedScheduler expects all schedulers to belong to the same optimizer, but " | |||
| "got schedulers at index {} and {} to be different".format(0, scheduler_idx) | |||
| ) | |||
| self._schedulers = list(schedulers) | |||
| self.optimizer = schedulers[0].optimizer | |||
| self._last_lr = [group['lr'] for group in self._schedulers[-1].optimizer.param_groups] | |||
| def step(self): | |||
| for scheduler in self._schedulers: | |||
| scheduler.step() | |||
| self._last_lr = [group['lr'] for group in self._schedulers[-1].optimizer.param_groups] | |||
| def state_dict(self): | |||
| state_dict = {key: value for key, value in self.__dict__.items() if key not in ('optimizer', '_schedulers')} | |||
| state_dict['_schedulers'] = [None] * len(self._schedulers) | |||
| state_dict = self._process_state_dict(state_dict) | |||
| for idx, s in enumerate(self._schedulers): | |||
| state_dict['_schedulers'][idx] = s.state_dict() | |||
| return state_dict | |||
| def load_state_dict(self, state_dict): | |||
| _schedulers = state_dict.pop('_schedulers') | |||
| state_dict = self._process_state_dict_revert(state_dict) | |||
| self.__dict__.update(state_dict) | |||
| state_dict['_schedulers'] = _schedulers | |||
| for idx, s in enumerate(_schedulers): | |||
| self._schedulers[idx].load_state_dict(s) | |||
| class ReduceLROnPlateau: | |||
| def __init__(self, optimizer, mode='min', factor=0.1, patience=10, | |||
| threshold=1e-4, threshold_mode='rel', cooldown=0, | |||
| min_lr=0, eps=1e-8, verbose=False): | |||
| if factor >= 1.0: | |||
| raise ValueError('Factor should be < 1.0.') | |||
| self.factor = factor | |||
| # Attach optimizer | |||
| if not isinstance(optimizer, Optimizer): | |||
| raise TypeError('{} is not an Optimizer'.format( | |||
| type(optimizer).__name__)) | |||
| self.optimizer = optimizer | |||
| if isinstance(min_lr, (list, tuple)): | |||
| if len(min_lr) != len(optimizer.param_groups): | |||
| raise ValueError("expected {} min_lrs, got {}".format( | |||
| len(optimizer.param_groups), len(min_lr))) | |||
| self.min_lrs = list(min_lr) | |||
| else: | |||
| self.min_lrs = [min_lr] * len(optimizer.param_groups) | |||
| self.patience = patience | |||
| self.verbose = verbose | |||
| self.cooldown = cooldown | |||
| self.cooldown_counter = 0 | |||
| self.mode = mode | |||
| self.threshold = threshold | |||
| self.threshold_mode = threshold_mode | |||
| self.best = None | |||
| self.num_bad_epochs = None | |||
| self.mode_worse = None # the worse value for the chosen mode | |||
| self.eps = eps | |||
| self.last_epoch = 0 | |||
| self._init_is_better(mode=mode, threshold=threshold, | |||
| threshold_mode=threshold_mode) | |||
| self._reset() | |||
| def _reset(self): | |||
| """Resets num_bad_epochs counter and cooldown counter.""" | |||
| self.best = self.mode_worse | |||
| self.cooldown_counter = 0 | |||
| self.num_bad_epochs = 0 | |||
| def step(self, metrics, epoch=None): | |||
| # convert `metrics` to float, in case it's a zero-dim Tensor | |||
| current = float(metrics) | |||
| if epoch is None: | |||
| epoch = self.last_epoch + 1 | |||
| else: | |||
| warnings.warn(EPOCH_DEPRECATION_WARNING, UserWarning) | |||
| self.last_epoch = epoch | |||
| if self.is_better(current, self.best): | |||
| self.best = current | |||
| self.num_bad_epochs = 0 | |||
| else: | |||
| self.num_bad_epochs += 1 | |||
| if self.in_cooldown: | |||
| self.cooldown_counter -= 1 | |||
| self.num_bad_epochs = 0 # ignore any bad epochs in cooldown | |||
| if self.num_bad_epochs > self.patience: | |||
| self._reduce_lr(epoch) | |||
| self.cooldown_counter = self.cooldown | |||
| self.num_bad_epochs = 0 | |||
| self._last_lr = [group['lr'] for group in self.optimizer.param_groups] | |||
| def _reduce_lr(self, epoch): | |||
| for i, param_group in enumerate(self.optimizer.param_groups): | |||
| old_lr = float(param_group['lr']) | |||
| new_lr = max(old_lr * self.factor, self.min_lrs[i]) | |||
| if old_lr - new_lr > self.eps: | |||
| if isinstance(param_group['lr'], ms.Parameter): | |||
| lr = ms.ops.scalar_to_tensor(lr) | |||
| lr = ms.ops.depend(lr, ms.ops.assign(param_group['lr'], lr)) | |||
| else: | |||
| param_group['lr'] = lr | |||
| if self.verbose: | |||
| epoch_str = ("%.2f" if isinstance(epoch, float) else | |||
| "%.5d") % epoch | |||
| print('Epoch {}: reducing learning rate' | |||
| ' of group {} to {:.4e}.'.format(epoch_str, i, new_lr)) | |||
| @property | |||
| def in_cooldown(self): | |||
| return self.cooldown_counter > 0 | |||
| def is_better(self, a, best): | |||
| if self.mode == 'min' and self.threshold_mode == 'rel': | |||
| rel_epsilon = 1. - self.threshold | |||
| return a < best * rel_epsilon | |||
| elif self.mode == 'min' and self.threshold_mode == 'abs': | |||
| return a < best - self.threshold | |||
| elif self.mode == 'max' and self.threshold_mode == 'rel': | |||
| rel_epsilon = self.threshold + 1. | |||
| return a > best * rel_epsilon | |||
| else: # mode == 'max' and epsilon_mode == 'abs': | |||
| return a > best + self.threshold | |||
| def _init_is_better(self, mode, threshold, threshold_mode): | |||
| if mode not in {'min', 'max'}: | |||
| raise ValueError('mode ' + mode + ' is unknown!') | |||
| if threshold_mode not in {'rel', 'abs'}: | |||
| raise ValueError('threshold mode ' + threshold_mode + ' is unknown!') | |||
| if mode == 'min': | |||
| self.mode_worse = math.inf | |||
| else: # mode == 'max': | |||
| self.mode_worse = -math.inf | |||
| self.mode = mode | |||
| self.threshold = threshold | |||
| self.threshold_mode = threshold_mode | |||
| def state_dict(self): | |||
| state_d = {key: value for key, value in self.__dict__.items() if key != 'optimizer'} | |||
| if '_last_lr' in state_d: | |||
| for i, base_lr in enumerate(state_d['_last_lr']): | |||
| if isinstance(base_lr, ms.Tensor): | |||
| state_d['_last_lr'][i] = base_lr.asnumpy().tolist() | |||
| return state_d | |||
| def load_state_dict(self, state_dict): | |||
| self.__dict__.update(state_dict) | |||
| self._init_is_better(mode=self.mode, threshold=self.threshold, threshold_mode=self.threshold_mode) | |||
| class CyclicLR(LRScheduler): | |||
| def __init__(self, | |||
| optimizer, | |||
| base_lr, | |||
| max_lr, | |||
| step_size_up=2000, | |||
| step_size_down=None, | |||
| mode='triangular', | |||
| gamma=1., | |||
| scale_fn=None, | |||
| scale_mode='cycle', | |||
| cycle_momentum=True, | |||
| base_momentum=0.8, | |||
| max_momentum=0.9, | |||
| last_epoch=-1, | |||
| verbose=False): | |||
| # Attach optimizer | |||
| if not isinstance(optimizer, Optimizer): | |||
| raise TypeError('{} is not an Optimizer'.format( | |||
| type(optimizer).__name__)) | |||
| self.optimizer = optimizer | |||
| base_lrs = self._format_param('base_lr', optimizer, base_lr) | |||
| if last_epoch == -1: | |||
| for lr, group in zip(base_lrs, optimizer.param_groups): | |||
| if isinstance(group['lr'], ms.Parameter): | |||
| lr = ms.ops.scalar_to_tensor(lr) | |||
| lr = ms.ops.depend(lr, ms.ops.assign(group['lr'], lr)) | |||
| else: | |||
| group['lr'] = lr | |||
| self.max_lrs = self._format_param('max_lr', optimizer, max_lr) | |||
| step_size_up = float(step_size_up) | |||
| step_size_down = float(step_size_down) if step_size_down is not None else step_size_up | |||
| self.total_size = step_size_up + step_size_down | |||
| self.step_ratio = step_size_up / self.total_size | |||
| if mode not in ['triangular', 'triangular2', 'exp_range'] \ | |||
| and scale_fn is None: | |||
| raise ValueError('mode is invalid and scale_fn is None') | |||
| self.mode = mode | |||
| self.gamma = gamma | |||
| self._scale_fn_ref = None | |||
| self._scale_fn_custom = scale_fn | |||
| self.scale_mode = scale_mode | |||
| self._init_scale_fn() | |||
| self.cycle_momentum = cycle_momentum | |||
| if cycle_momentum: | |||
| if 'momentum' not in optimizer.defaults: | |||
| raise ValueError('optimizer must support momentum with `cycle_momentum` option enabled') | |||
| base_momentums = self._format_param('base_momentum', optimizer, base_momentum) | |||
| if last_epoch == -1: | |||
| for momentum, group in zip(base_momentums, optimizer.param_groups): | |||
| group['momentum'] = momentum | |||
| self.base_momentums = [group['momentum'] for group in optimizer.param_groups] | |||
| self.max_momentums = self._format_param('max_momentum', optimizer, max_momentum) | |||
| super().__init__(optimizer, last_epoch, verbose) | |||
| self.base_lrs = base_lrs | |||
| def _init_scale_fn(self): | |||
| if self._scale_fn_custom is not None: | |||
| return | |||
| if self.mode == 'triangular': | |||
| self._scale_fn_ref = self._triangular_scale_fn | |||
| self.scale_mode = 'cycle' | |||
| elif self.mode == 'triangular2': | |||
| self._scale_fn_ref = self._triangular2_scale_fn | |||
| self.scale_mode = 'cycle' | |||
| elif self.mode == 'exp_range': | |||
| self._scale_fn_ref = self._exp_range_scale_fn | |||
| self.scale_mode = 'iterations' | |||
| def _format_param(self, name, optimizer, param): | |||
| if isinstance(param, (list, tuple)): | |||
| if len(param) != len(optimizer.param_groups): | |||
| raise ValueError("expected {} values for {}, got {}".format( | |||
| len(optimizer.param_groups), name, len(param))) | |||
| return param | |||
| else: | |||
| return [param] * len(optimizer.param_groups) | |||
| def scale_fn(self, x): | |||
| if self._scale_fn_custom is not None: | |||
| return self._scale_fn_custom(x) | |||
| else: | |||
| return self._scale_fn_ref(x) | |||
| def _triangular_scale_fn(self, x): | |||
| unsupported_attr(x) | |||
| return 1. | |||
| def _triangular2_scale_fn(self, x): | |||
| return 1 / (2. ** (x - 1)) | |||
| def _exp_range_scale_fn(self, x): | |||
| return self.gamma**(x) | |||
| def get_lr(self): | |||
| cycle = math.floor(1 + self.last_epoch / self.total_size) | |||
| x = 1. + self.last_epoch / self.total_size - cycle | |||
| if x <= self.step_ratio: | |||
| scale_factor = x / self.step_ratio | |||
| else: | |||
| scale_factor = (x - 1) / (self.step_ratio - 1) | |||
| lrs = [] | |||
| for base_lr, max_lr in zip(self.base_lrs, self.max_lrs): | |||
| base_height = (max_lr - base_lr) * scale_factor | |||
| if self.scale_mode == 'cycle': | |||
| lr = base_lr + base_height * self.scale_fn(cycle) | |||
| else: | |||
| lr = base_lr + base_height * self.scale_fn(self.last_epoch) | |||
| lrs.append(lr) | |||
| if self.cycle_momentum: | |||
| momentums = [] | |||
| for base_momentum, max_momentum in zip(self.base_momentums, self.max_momentums): | |||
| base_height = (max_momentum - base_momentum) * scale_factor | |||
| if self.scale_mode == 'cycle': | |||
| momentum = max_momentum - base_height * self.scale_fn(cycle) | |||
| else: | |||
| momentum = max_momentum - base_height * self.scale_fn(self.last_epoch) | |||
| momentums.append(momentum) | |||
| for param_group, momentum in zip(self.optimizer.param_groups, momentums): | |||
| if isinstance(param_group['momentum'], ms.Parameter): | |||
| momentum = ms.ops.scalar_to_tensor(momentum) | |||
| momentum = ms.ops.depend(momentum, ms.ops.assign(param_group['momentum'], momentum)) | |||
| else: | |||
| param_group['momentum'] = momentum | |||
| return lrs | |||
| def state_dict(self): | |||
| state = super().state_dict() | |||
| state.pop("_scale_fn_ref") | |||
| state = self._process_state_dict(state) | |||
| return state | |||
| def load_state_dict(self, state_dict): | |||
| state_dict = self._process_state_dict_revert(state_dict) | |||
| super().load_state_dict(state_dict) | |||
| self._init_scale_fn() | |||
| class CosineAnnealingWarmRestarts(LRScheduler): | |||
| def __init__(self, optimizer, T_0, T_mult=1, eta_min=0, last_epoch=-1, verbose=False): | |||
| if T_0 <= 0 or not isinstance(T_0, int): | |||
| raise ValueError("Expected positive integer T_0, but got {}".format(T_0)) | |||
| if T_mult < 1 or not isinstance(T_mult, int): | |||
| raise ValueError("Expected integer T_mult >= 1, but got {}".format(T_mult)) | |||
| self.T_0 = T_0 | |||
| self.T_i = T_0 | |||
| self.T_mult = T_mult | |||
| self.eta_min = eta_min | |||
| self.T_cur = last_epoch | |||
| super().__init__(optimizer, last_epoch, verbose) | |||
| def get_lr(self): | |||
| return [self.eta_min + (base_lr - self.eta_min) * (1 + math.cos(math.pi * self.T_cur / self.T_i)) / 2 | |||
| for base_lr in self.base_lrs] | |||
| def step(self, epoch=None): | |||
| if epoch is None and self.last_epoch < 0: | |||
| epoch = 0 | |||
| if epoch is None: | |||
| epoch = self.last_epoch + 1 | |||
| self.T_cur = self.T_cur + 1 | |||
| if self.T_cur >= self.T_i: | |||
| self.T_cur = self.T_cur - self.T_i | |||
| self.T_i = self.T_i * self.T_mult | |||
| else: | |||
| if epoch < 0: | |||
| raise ValueError("Expected non-negative epoch, but got {}".format(epoch)) | |||
| if epoch >= self.T_0: | |||
| if self.T_mult == 1: | |||
| self.T_cur = epoch % self.T_0 | |||
| else: | |||
| n = int(math.log((epoch / self.T_0 * (self.T_mult - 1) + 1), self.T_mult)) | |||
| self.T_cur = epoch - self.T_0 * (self.T_mult ** n - 1) / (self.T_mult - 1) | |||
| self.T_i = self.T_0 * self.T_mult ** (n) | |||
| else: | |||
| self.T_i = self.T_0 | |||
| self.T_cur = epoch | |||
| self.last_epoch = math.floor(epoch) | |||
| for i, data in enumerate(zip(self.optimizer.param_groups, self.get_lr())): | |||
| param_group, lr = data | |||
| if isinstance(param_group['lr'], ms.Parameter): | |||
| if not isinstance(lr, ms.Tensor): | |||
| lr = ms.ops.scalar_to_tensor(lr) | |||
| lr = ms.ops.depend(lr, ms.ops.assign(param_group['lr'], lr)) | |||
| else: | |||
| param_group['lr'] = lr | |||
| self.print_lr(self.verbose, i, lr, epoch) | |||
| self._last_lr = [group['lr'] for group in self.optimizer.param_groups] | |||
| class OneCycleLR(LRScheduler): | |||
| def __init__(self, | |||
| optimizer, | |||
| max_lr, | |||
| total_steps=None, | |||
| epochs=None, | |||
| steps_per_epoch=None, | |||
| pct_start=0.3, | |||
| anneal_strategy='cos', | |||
| cycle_momentum=True, | |||
| base_momentum=0.85, | |||
| max_momentum=0.95, | |||
| div_factor=25., | |||
| final_div_factor=1e4, | |||
| three_phase=False, | |||
| last_epoch=-1, | |||
| verbose=False): | |||
| if not isinstance(optimizer, Optimizer): | |||
| raise TypeError('{} is not an Optimizer'.format(type(optimizer).__name__)) | |||
| self.optimizer = optimizer | |||
| if total_steps is None and epochs is None and steps_per_epoch is None: | |||
| raise ValueError("You must define either total_steps OR (epochs AND steps_per_epoch)") | |||
| elif total_steps is not None: | |||
| if total_steps <= 0 or not isinstance(total_steps, int): | |||
| raise ValueError("Expected positive integer total_steps, but got {}".format(total_steps)) | |||
| self.total_steps = total_steps | |||
| else: | |||
| if epochs <= 0 or not isinstance(epochs, int): | |||
| raise ValueError("Expected positive integer epochs, but got {}".format(epochs)) | |||
| if steps_per_epoch <= 0 or not isinstance(steps_per_epoch, int): | |||
| raise ValueError("Expected positive integer steps_per_epoch, but got {}".format(steps_per_epoch)) | |||
| self.total_steps = epochs * steps_per_epoch | |||
| if three_phase: | |||
| self._schedule_phases = [ | |||
| { | |||
| 'end_step': float(pct_start * self.total_steps) - 1, | |||
| 'start_lr': 'initial_lr', | |||
| 'end_lr': 'max_lr', | |||
| 'start_momentum': 'max_momentum', | |||
| 'end_momentum': 'base_momentum', | |||
| }, | |||
| { | |||
| 'end_step': float(2 * pct_start * self.total_steps) - 2, | |||
| 'start_lr': 'max_lr', | |||
| 'end_lr': 'initial_lr', | |||
| 'start_momentum': 'base_momentum', | |||
| 'end_momentum': 'max_momentum', | |||
| }, | |||
| { | |||
| 'end_step': self.total_steps - 1, | |||
| 'start_lr': 'initial_lr', | |||
| 'end_lr': 'min_lr', | |||
| 'start_momentum': 'max_momentum', | |||
| 'end_momentum': 'max_momentum', | |||
| }, | |||
| ] | |||
| else: | |||
| self._schedule_phases = [ | |||
| { | |||
| 'end_step': float(pct_start * self.total_steps) - 1, | |||
| 'start_lr': 'initial_lr', | |||
| 'end_lr': 'max_lr', | |||
| 'start_momentum': 'max_momentum', | |||
| 'end_momentum': 'base_momentum', | |||
| }, | |||
| { | |||
| 'end_step': self.total_steps - 1, | |||
| 'start_lr': 'max_lr', | |||
| 'end_lr': 'min_lr', | |||
| 'start_momentum': 'base_momentum', | |||
| 'end_momentum': 'max_momentum', | |||
| }, | |||
| ] | |||
| if pct_start < 0 or pct_start > 1 or not isinstance(pct_start, float): | |||
| raise ValueError("Expected float between 0 and 1 pct_start, but got {}".format(pct_start)) | |||
| if anneal_strategy not in ['cos', 'linear']: | |||
| raise ValueError("anneal_strategy must by one of 'cos' or 'linear', instead got {}".format(anneal_strategy)) | |||
| elif anneal_strategy == 'cos': | |||
| self.anneal_func = self._annealing_cos | |||
| elif anneal_strategy == 'linear': | |||
| self.anneal_func = self._annealing_linear | |||
| max_lrs = self._format_param('max_lr', self.optimizer, max_lr) | |||
| if last_epoch == -1: | |||
| for idx, group in enumerate(self.optimizer.param_groups): | |||
| group['initial_lr'] = max_lrs[idx] / div_factor | |||
| group['max_lr'] = max_lrs[idx] | |||
| group['min_lr'] = group['initial_lr'] / final_div_factor | |||
| self.cycle_momentum = cycle_momentum | |||
| if self.cycle_momentum: | |||
| if graph_mode_condition(): | |||
| raise RuntimeError('not support change momentum or betas under graph-mode') | |||
| if 'momentum' not in self.optimizer.defaults and 'betas' not in self.optimizer.defaults: | |||
| raise ValueError('optimizer must support momentum with `cycle_momentum` option enabled') | |||
| self.use_beta1 = 'betas' in self.optimizer.defaults | |||
| max_momentums = self._format_param('max_momentum', optimizer, max_momentum) | |||
| base_momentums = self._format_param('base_momentum', optimizer, base_momentum) | |||
| if last_epoch == -1: | |||
| for m_momentum, b_momentum, group in zip(max_momentums, base_momentums, optimizer.param_groups): | |||
| if self.use_beta1: | |||
| group['betas'] = (m_momentum, *group['betas'][1:]) | |||
| else: | |||
| group['momentum'] = m_momentum | |||
| group['max_momentum'] = m_momentum | |||
| group['base_momentum'] = b_momentum | |||
| super().__init__(optimizer, last_epoch, verbose) | |||
| def _format_param(self, name, optimizer, param): | |||
| if isinstance(param, (list, tuple)): | |||
| if len(param) != len(optimizer.param_groups): | |||
| raise ValueError("expected {} values for {}, got {}".format( | |||
| len(optimizer.param_groups), name, len(param))) | |||
| return param | |||
| else: | |||
| return [param] * len(optimizer.param_groups) | |||
| def _annealing_cos(self, start, end, pct): | |||
| cos_out = math.cos(math.pi * pct) + 1 | |||
| return end + (start - end) / 2.0 * cos_out | |||
| def _annealing_linear(self, start, end, pct): | |||
| return (end - start) * pct + start | |||
| def get_lr(self): | |||
| lrs = [] | |||
| _step_num = self.last_epoch | |||
| if _step_num > self.total_steps: | |||
| raise ValueError("Tried to step {} times. The specified number of total steps is {}" | |||
| .format(_step_num, self.total_steps)) | |||
| for group in self.optimizer.param_groups: | |||
| start_step = 0 | |||
| for i, phase in enumerate(self._schedule_phases): | |||
| end_step = phase['end_step'] | |||
| if _step_num <= end_step or i == len(self._schedule_phases) - 1: | |||
| pct = (_step_num - start_step) / (end_step - start_step) | |||
| _new_lr = self.anneal_func(group[phase['start_lr']], group[phase['end_lr']], pct) | |||
| if self.cycle_momentum: | |||
| __new_momentum = self.anneal_func(group[phase['start_momentum']], | |||
| group[phase['end_momentum']], pct) | |||
| break | |||
| start_step = phase['end_step'] | |||
| lrs.append(_new_lr) | |||
| if self.cycle_momentum: | |||
| if self.use_beta1: | |||
| group['betas'] = (__new_momentum, *group['betas'][1:]) | |||
| else: | |||
| group['momentum'] = __new_momentum | |||
| return lrs | |||
+ 237
- 0
msadapter/pytorch/optim/optimizer.py
View File
| @@ -0,0 +1,237 @@ | |||
| import abc | |||
| from collections import OrderedDict, defaultdict | |||
| from collections.abc import Iterable | |||
| from copy import deepcopy | |||
| from itertools import chain | |||
| import mindspore as ms | |||
| from mindspore.experimental.optim import Optimizer as Optimizer_MS | |||
| from msadapter.pytorch.tensor import Tensor, tensor, cast_to_ms_tensor | |||
| from msadapter.utils import unsupported_attr | |||
| class _Optimizer: | |||
| def __init__(self): | |||
| self._optimizer_step_pre_hooks=OrderedDict() | |||
| self._optimizer_step_post_hooks=OrderedDict() | |||
| self._patch_step_function() | |||
| def _is_inner_optimizer(self): | |||
| return True | |||
| def __getstate__(self): | |||
| return { | |||
| 'defaults': self.defaults, | |||
| 'state': self.state, | |||
| 'param_groups': self.param_groups, | |||
| } | |||
| def __setstate__(self, state): | |||
| self.__dict__.update(state) | |||
| if '_optimizer_step_pre_hooks' not in self.__dict__: | |||
| self._optimizer_step_pre_hooks = OrderedDict() | |||
| if '_optimizer_step_post_hooks' not in self.__dict__: | |||
| self._optimizer_step_post_hooks = OrderedDict() | |||
| self._patch_step_function() | |||
| self.defaults.setdefault('differentiable', False) | |||
| def __repr__(self): | |||
| format_string = self.__class__.__name__ + ' (' | |||
| for i, group in enumerate(self.param_groups): | |||
| format_string += '\n' | |||
| format_string += 'Parameter Group {0}\n'.format(i) | |||
| for key in sorted(group.keys()): | |||
| if key != 'params': | |||
| format_string += ' {0}: {1}\n'.format(key, group[key]) | |||
| format_string += ')' | |||
| return format_string | |||
| @staticmethod | |||
| def profile_hook_step(func): | |||
| unsupported_attr(func) | |||
| raise NotImplementedError("For Optimizer, 'profile_hook_step' not support yet.") | |||
| def _patch_step_function(self): | |||
| self._zero_grad_profile_name = "Optimizer.zero_grad#{}.zero_grad".format(self.__class__.__name__) | |||
| # hook not support yet. | |||
| # hooked = getattr(self.__class__.step, "hooked", None) | |||
| # if not hooked: | |||
| # self.__class__.step = self.profile_hook_step(self.__class__.step) | |||
| # self.__class__.step.hooked = True | |||
| def register_step_pre_hook(self): | |||
| raise NotImplementedError("For optimizer, 'register_step_pre_hook' is not supported yet.") | |||
| def register_step_post_hook(self): | |||
| raise NotImplementedError("For optimizer, 'register_step_post_hook' is not supported yet.") | |||
| def state_dict(self): | |||
| r"""Returns the state of the optimizer as a :class:`dict`. | |||
| It contains two entries: | |||
| * state - a dict holding current optimization state. Its content | |||
| differs between optimizer classes. | |||
| * param_groups - a list containing all parameter groups where each | |||
| parameter group is a dict | |||
| """ | |||
| # Save order indices instead of Tensors | |||
| param_mappings = {} | |||
| start_index = 0 | |||
| def pack_group(group): | |||
| nonlocal start_index | |||
| packed = {k: v for k, v in group.items() if k != 'params'} | |||
| if 'lr' in packed.keys(): | |||
| if isinstance(packed['lr'], ms.Tensor): | |||
| packed['lr'] = packed['lr'].asnumpy().tolist() | |||
| param_mappings.update({id(p): i for i, p in enumerate(group['params'], start_index) | |||
| if id(p) not in param_mappings}) | |||
| packed['params'] = [param_mappings[id(p)] for p in group['params']] | |||
| start_index += len(packed['params']) | |||
| return packed | |||
| param_groups = [pack_group(g) for g in self.param_groups] | |||
| # Remap state to use order indices as keys | |||
| packed_state = {(param_mappings[id(k)] if isinstance(k, Tensor) else k): v | |||
| for k, v in self.state.items()} | |||
| return { | |||
| 'state': packed_state, | |||
| 'param_groups': param_groups, | |||
| } | |||
| def load_state_dict(self, state_dict): | |||
| r"""Loads the optimizer state. | |||
| Args: | |||
| state_dict (dict): optimizer state. Should be an object returned | |||
| from a call to :meth:`state_dict`. | |||
| """ | |||
| # deepcopy, to be consistent with module API | |||
| state_dict = deepcopy(state_dict) | |||
| # Validate the state_dict | |||
| groups = self.param_groups | |||
| saved_groups = state_dict['param_groups'] | |||
| if len(groups) != len(saved_groups): | |||
| raise ValueError("loaded state dict has a different number of " | |||
| "parameter groups") | |||
| param_lens = (len(g['params']) for g in groups) | |||
| saved_lens = (len(g['params']) for g in saved_groups) | |||
| if any(p_len != s_len for p_len, s_len in zip(param_lens, saved_lens)): | |||
| raise ValueError("loaded state dict contains a parameter group " | |||
| "that doesn't match the size of optimizer's group") | |||
| # Update the state | |||
| id_map = dict(zip(chain.from_iterable((g['params'] for g in saved_groups)), | |||
| chain.from_iterable((g['params'] for g in groups)))) | |||
| def cast(param, value, key=None): | |||
| r"""Make a deep copy of value, casting all tensors to device of param.""" | |||
| if isinstance(value, Tensor): | |||
| # Floating-point types are a bit special here. They are the only ones | |||
| # that are assumed to always match the type of params. | |||
| # Make sure state['step'] is not casted https://github.com/pytorch/pytorch/issues/74424 | |||
| if key != "step": | |||
| if param.is_floating_point(): | |||
| value = value.to(param.dtype) | |||
| value = value.to(param.device) | |||
| return value | |||
| elif isinstance(value, dict): | |||
| return {k: cast(param, v, key=k) for k, v in value.items()} | |||
| elif isinstance(value, Iterable): | |||
| return type(value)(cast(param, v) for v in value) | |||
| else: | |||
| return value | |||
| # Copy state assigned to params (and cast tensors to appropriate types). | |||
| # State that is not assigned to params is copied as is (needed for | |||
| # backward compatibility). | |||
| state = defaultdict(dict) | |||
| for k, v in state_dict['state'].items(): | |||
| if k in id_map: | |||
| param = id_map[k] | |||
| state[param] = cast(param, v) | |||
| else: | |||
| state[k] = v | |||
| # Update parameter groups, setting their 'params' value | |||
| def update_group(group, new_group): | |||
| new_group['params'] = group['params'] | |||
| if 'lr' in group.keys(): | |||
| if isinstance(group['lr'], ms.Parameter): | |||
| new_group['lr'] = ms.Parameter(ms.Tensor(new_group['lr'], ms.float32), group['lr'].name) | |||
| return new_group | |||
| param_groups = [ | |||
| update_group(g, ng) for g, ng in zip(groups, saved_groups)] | |||
| self.__setstate__({'state': state, 'param_groups': param_groups}) | |||
| def _ms_state_dict(self, *ms_params_name): | |||
| _state_dict = _Optimizer.state_dict(self) | |||
| def _save(ms_params): | |||
| if isinstance(ms_params, Iterable): | |||
| _state = [] | |||
| for p in ms_params: | |||
| _state.append(_save(p)) | |||
| else: | |||
| _state = tensor(ms_params.asnumpy()) | |||
| return _state | |||
| for name in ms_params_name: | |||
| ms_params = getattr(self, name) | |||
| _state_dict[name] = _save(ms_params) | |||
| return _state_dict | |||
| def _ms_load_state_dict(self, state_dict, *ms_params_name): | |||
| _Optimizer.load_state_dict(self, state_dict) | |||
| def _load(ms_params, state_tensor, name): | |||
| if isinstance(ms_params, Iterable): | |||
| if not isinstance(state_tensor, Iterable): | |||
| raise ValueError(f"state_dict of ms_param '{name}' is not correct. please check. " | |||
| f"(ms_param '{name}' is Iterable, but state_dict['{name}'] is not.)") | |||
| if len(ms_params) != len(state_tensor): | |||
| raise ValueError(f"state_dict of ms_param '{name}' is not correct. please check. " | |||
| f"(length of ms_param '{name}' and state_dict['{name}'] are not equal, " | |||
| f"get {len(ms_params)} and {len(state_tensor)}") | |||
| for i, _ in enumerate(ms_params): | |||
| _load(ms_params[i], state_tensor[i], name) | |||
| else: | |||
| _data = cast_to_ms_tensor(state_tensor) | |||
| try: | |||
| ms_params.set_data(_data) | |||
| except Exception as e: | |||
| raise ValueError(f"state_dict of ms_param '{name}' is not correct. please check. " | |||
| f"({e})") from e | |||
| for name in ms_params_name: | |||
| _params = state_dict[name] | |||
| ms_params = getattr(self, name) | |||
| _load(ms_params, _params, name) | |||
| def step(self, grads, closure=None): | |||
| loss = None | |||
| if closure is not None: | |||
| loss = closure() | |||
| self.construct(grads) | |||
| return loss | |||
| class _OptimizerMeta(abc.ABCMeta, type(Optimizer_MS)): | |||
| """ | |||
| Meta class for Optimizer. Used internally. | |||
| """ | |||
| class Optimizer(_Optimizer, Optimizer_MS, metaclass=_OptimizerMeta): | |||
| def __init__(self, *args, **kwargs): | |||
| Optimizer_MS.__init__(self, *args, **kwargs) | |||
| _Optimizer.__init__(self) | |||
| @classmethod | |||
| def __subclasshook__(cls, sub): | |||
| """ | |||
| Subclass with _is_inner_optimizer attr will be instance of Optimizer | |||
| """ | |||
| if cls is Optimizer: | |||
| if any("_is_inner_optimizer" in s.__dict__ for s in sub.__mro__): | |||
| return True | |||
| return NotImplemented | |||
| def _is_tensor(obj): | |||
| return isinstance(obj, Tensor) | |||
+ 19
- 0
msadapter/pytorch/optim/sgd.py
View File
| @@ -0,0 +1,19 @@ | |||
| from mindspore.experimental.optim import SGD as SGD_MS | |||
| from msadapter.pytorch.optim.optimizer import _Optimizer | |||
| class SGD(_Optimizer, SGD_MS): | |||
| def __init__(self, *args, **kwargs): | |||
| SGD_MS.__init__(self, *args, **kwargs) | |||
| _Optimizer.__init__(self) | |||
| def __setstate__(self, state): | |||
| _Optimizer.__setstate__(self, state) | |||
| for group in self.param_groups: | |||
| group.setdefault('nesterov', False) | |||
| group.setdefault('maximize', False) | |||
| def state_dict(self): | |||
| return super()._ms_state_dict('accum') | |||
| def load_state_dict(self, state_dict): | |||
| return super()._ms_load_state_dict(state_dict, 'accum') | |||
+ 26
- 22
msadapter/pytorch/serialization.py
View File
| @@ -7,7 +7,8 @@ import importlib | |||
| import pickle | |||
| import pathlib | |||
| from collections.abc import Mapping, Sequence | |||
| from typing import Any, BinaryIO, Optional, Union, IO | |||
| from typing import Any, BinaryIO, Union, IO | |||
| from pickle import UnpicklingError | |||
| from typing_extensions import TypeAlias | |||
| from msadapter.pytorch.tensor import msdapter_dtype, tensor | |||
| from msadapter.utils import unsupported_attr | |||
| @@ -276,7 +277,6 @@ def _legacy_save(obj, f, pickle_module, pickle_protocol) -> None: | |||
| def load( | |||
| f: FILE_LIKE, | |||
| from_torch : Optional = False, | |||
| map_location = None, | |||
| pickle_module: Any = pickle, | |||
| **pickle_load_args: Any | |||
| @@ -329,35 +329,39 @@ def load( | |||
| Example: | |||
| >>> # xdoctest: +SKIP("undefined filepaths") | |||
| >>> torch.load('tensors.pt') | |||
| # Load all tensors | |||
| >>> torch.load('tensors.pt', from_torch=True) | |||
| # Load all tensors from PyTorch, and return MSAdapter tensors. | |||
| """ | |||
| if from_torch: | |||
| pt = try_import('torch') | |||
| state = pt.load( | |||
| f, map_location = map_location, pickle_module=pickle_module, **pickle_load_args | |||
| ) | |||
| if isinstance(state, pt.nn.Module): | |||
| raise TypeError("Importing torch model file into MSAdapter is not supported now.") | |||
| return dict_convert(state) | |||
| if map_location is not None: | |||
| unsupported_attr(map_location) | |||
| try: | |||
| _check_dill_version(pickle_module) | |||
| _check_dill_version(pickle_module) | |||
| if map_location: | |||
| unsupported_attr(map_location) | |||
| if 'encoding' not in pickle_load_args.keys(): | |||
| pickle_load_args['encoding'] = 'utf-8' | |||
| if 'encoding' not in pickle_load_args.keys(): | |||
| pickle_load_args['encoding'] = 'utf-8' | |||
| with _open_file_like(f, 'rb') as opened_file: | |||
| with _open_file_like(f, 'rb') as opened_file: | |||
| # The zipfile reader is going to advance the current file position. | |||
| # If we want to actually tail call to torch.jit.load, we need to | |||
| # reset back to the original position. | |||
| return _legacy_load(opened_file, pickle_module, **pickle_load_args) | |||
| return _legacy_load(opened_file, pickle_module, **pickle_load_args) | |||
| except UnpicklingError: | |||
| pt = try_import('torch') | |||
| state = pt.load( | |||
| f, map_location ='cpu', pickle_module=pickle_module, **pickle_load_args | |||
| ) | |||
| if isinstance(state, pt.nn.Module): | |||
| print("Importing torch model file into MSAdapter is not supported now.") | |||
| return dict_convert(state) | |||
| except Exception as e: # pylint: disable=broad-except | |||
| template = "An exception of type {0} occurred. Arguments:\n{1!r}" | |||
| message = template.format(type(e).__name__, e.args) | |||
| print(message) | |||
| print("The load function currently only supports Torch model files and MSAdapter model files now.") | |||
| return None | |||
| def _legacy_load(f, pickle_module, **pickle_load_args): | |||
+ 369
- 105
msadapter/pytorch/tensor.py
View File
| @@ -10,26 +10,26 @@ from functools import reduce | |||
| import numpy as np | |||
| import mindspore as ms | |||
| from mindspore import Tensor as ms_Tensor | |||
| from mindspore.scipy.ops import SolveTriangular | |||
| from mindspore.common import dtype as mstype | |||
| import mindspore.ops as P | |||
| from mindspore.ops.primitive import _primexpr | |||
| from mindspore.ops._primitive_cache import _get_cache_prim | |||
| from mindspore.ops.operations import _inner_ops as inner | |||
| from mindspore.common.initializer import _init_random_normal, _init_random_uniform, Zero | |||
| from mindspore.common.initializer import Zero | |||
| from mindspore._c_expression import Tensor as Tensor_ | |||
| from mindspore.common._stub_tensor import StubTensor | |||
| from msadapter.utils import unsupported_attr, is_under_gpu_context, get_backend, \ | |||
| is_under_ascend_context, _infer_size, _ascend_tensor_general_cast,\ | |||
| is_under_cpu_context, pynative_mode_condition, set_name_tuple, \ | |||
| set_multiple_name_tuple, graph_mode_condition | |||
| from msadapter.utils import unsupported_attr, is_under_gpu_context, get_backend, is_under_ascend_context, _infer_size, \ | |||
| _ascend_tensor_general_cast, is_under_cpu_context, pynative_mode_condition, set_multiple_name_tuple, \ | |||
| set_name_tuple, graph_mode_condition, bitwise_adapter, FP64_MAX, FP64_MIN, FP32_MAX, FP32_MIN | |||
| import msadapter.pytorch.common.dtype as msdapter_dtype | |||
| from msadapter.pytorch.common.dtype import all_int_type_with_bool, finfo, iinfo, all_int_type, \ | |||
| _get_type_from_dtype, _get_dtype_from_type | |||
| from msadapter.pytorch.common.dtype import all_int_type_with_bool, finfo, iinfo, all_int_type, _get_type_from_dtype, \ | |||
| _get_dtype_from_type | |||
| from msadapter.pytorch.common.device import Device | |||
| from msadapter.pytorch.storage import _TypedStorage | |||
| from msadapter.pytorch._register_numpy_primitive import lstsq_op, svd_op, i0_op, inner_lu_factor_op, \ | |||
| symeig_op, lu_solve_op, fmax_op, fmin_op | |||
| symeig_op, lu_solve_op, fmax_op, fmin_op | |||
| _dtypeDict = { | |||
| @@ -125,18 +125,49 @@ def _get_unfold_indices(input_shape, dimension, size, step): | |||
| return indices, dimension | |||
| @_primexpr | |||
| def _check_int_size(size, op_name): | |||
| # Check whether 'size' is an integer or a tensor with Int type, or a tuple/list composed of them, | |||
| # while converting them uniformly to integer. | |||
| if isinstance(size, Tensor) and size.dtype in all_int_type: | |||
| size = int(size) | |||
| elif isinstance(size, (tuple, list)): | |||
| size_ = () | |||
| for item in size: | |||
| if isinstance(item, int): | |||
| size_ = size_ + (item,) | |||
| elif isinstance(item, Tensor) and item.dtype in all_int_type: | |||
| size_ = size_ + (int(item),) | |||
| else: | |||
| raise ValueError(f"For '{op_name}', the component of 'size' must be of type int, " \ | |||
| f"but got {type(item)}.") | |||
| size = size_ | |||
| elif size and not isinstance(size, int): | |||
| raise ValueError(f"For '{op_name}', the 'size' must be of type int, but got {type(size)}.") | |||
| return size | |||
| def custom_matmul(input, other): | |||
| # TODO: ms.ops.matmul not support int-dtype input on GPU, only support float16/float32 dtype input. | |||
| input_dtype = input.dtype | |||
| other_dtype = other.dtype | |||
| if input_dtype != other_dtype: | |||
| RuntimeError("For matmul, expected scalar type {}, but found {}.".format(input_dtype, other_dtype)) | |||
| if is_under_gpu_context() and input_dtype not in (ms.float32, ms.float16): | |||
| input = input.astype(ms.float32) | |||
| other = other.astype(ms.float32) | |||
| ndim1_orig = ms.ops.rank(input) | |||
| ndim2_orig = ms.ops.rank(other) | |||
| if ndim1_orig == ndim2_orig: | |||
| if ndim1_orig == 2: | |||
| _matmul = _get_cache_prim(P.MatMul)(False, False) | |||
| return _matmul(input, other) | |||
| return _matmul(input, other).astype(input_dtype) | |||
| if ndim1_orig > 2: | |||
| _batch_matmul = _get_cache_prim(P.BatchMatMul)(False, False) | |||
| return _batch_matmul(input, other) | |||
| return ms.ops.matmul(input, other) | |||
| return _batch_matmul(input, other).astype(input_dtype) | |||
| return ms.ops.matmul(input, other).astype(input_dtype) | |||
| @_primexpr | |||
| def _get_diagonal_scatter_index(input_shape, offset, dim1, dim2): | |||
| @@ -208,6 +239,7 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| super(Tensor, self).__init__(tensor=input_data) | |||
| else: | |||
| raise ValueError(f"Tensor init data type is invaild: {type(input_data)}") | |||
| self.adapter_flag = True | |||
| return | |||
| if dtype is not None: | |||
| @@ -230,6 +262,7 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| dtype = mstype.float32 | |||
| init_tensor = ms_Tensor(input_data=_input_data, dtype=dtype) | |||
| super(Tensor, self).__init__(tensor=init_tensor) | |||
| self.adapter_flag = True | |||
| def _process_data(self, data): | |||
| @@ -484,6 +517,18 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| out = tensor_ms.__eq__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __matmul__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__matmul__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __rmatmul__(self, other): | |||
| tensor_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| out = tensor_ms.__rmatmul__(other_ms) | |||
| return cast_to_adapter_tensor(out) | |||
| def __hash__(self): | |||
| return hash(id(self)) | |||
| @@ -542,7 +587,7 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| def normal_adapter(self, mean=0, std=1, *, generator=None): | |||
| if generator is not None: | |||
| raise ValueError("`generator` can not be supportted.") | |||
| output = ms.Tensor(_init_random_normal(mean, std, self.shape), self.dtype) | |||
| output = ms.ops.normal(self.shape, mean, std).astype(self.dtype) | |||
| return cast_to_adapter_tensor(output) | |||
| def normal_(self, mean=0, std=1, *, generator=None): | |||
| @@ -559,8 +604,9 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| return self.shape[dim] | |||
| def uniform_adapter(self, from_alias=0, to=1): #TODO: from_alias->from | |||
| self_dtype = self.dtype | |||
| output = ms.Tensor(_init_random_uniform(from_alias, to, self.shape), self_dtype) | |||
| from_alias = ms.Tensor(from_alias, ms.float32) | |||
| to = ms.Tensor(to, ms.float32) | |||
| output = ms.ops.uniform(self.shape, from_alias, to).astype(self.dtype) | |||
| return cast_to_adapter_tensor(output) | |||
| def uniform_(self, from_alias=0, to=1): | |||
| @@ -591,6 +637,7 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| return self.uniform_adapter(from_alias, kMaxInt16) | |||
| elif self_dtype == ms.int8: | |||
| return self.uniform_adapter(from_alias, kMaxInt8) | |||
| to = to - 1 if to > 1 else to | |||
| return self.uniform_adapter(from_alias, to) | |||
| def random_(self, from_alias=0, to=None, *, generator=None): #TODO: from_alias->from | |||
| @@ -605,13 +652,19 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| output = self.zero_adapter() | |||
| return _tensor_inplace_assign(self, output, "zero_", "zero_adapter") | |||
| def new_zeros(self, *size, dtype=None, device=None, requires_grad=False): | |||
| #TODO: adapter needs to support both positional and keywords input size to be consistent with pytorch | |||
| #positional_size represents the positional arguments of size, size represents the keywords arguments input | |||
| def new_zeros(self, *positional_size, size=None, dtype=None, device=None, requires_grad=False): | |||
| unsupported_attr(device) | |||
| unsupported_attr(requires_grad) | |||
| if not dtype: | |||
| dtype = self.dtype | |||
| if size is None: | |||
| if isinstance(positional_size[0], (tuple, list)): | |||
| size = positional_size[0] | |||
| else: | |||
| size = positional_size | |||
| if isinstance(size[0], tuple): | |||
| size = size[0] | |||
| @@ -632,6 +685,7 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| if not dtype: | |||
| dtype = self.dtype | |||
| size = _check_int_size(size, "new_full") | |||
| output = ms.ops.fill(dtype, size, fill_value) | |||
| return cast_to_adapter_tensor(output) | |||
| @@ -677,14 +731,20 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| def copy_adapter(self, src, non_blocking=False): | |||
| unsupported_attr(non_blocking) | |||
| input_ms = cast_to_ms_tensor(src) | |||
| output = ms.ops.broadcast_to(input_ms, self.shape) | |||
| if len(self.shape) > 0: | |||
| output = ms.ops.broadcast_to(input_ms, self.shape) | |||
| else: | |||
| output = input_ms | |||
| output = output.astype(self.dtype) | |||
| return cast_to_adapter_tensor(output) | |||
| def copy_(self, src, non_blocking=False): | |||
| unsupported_attr(non_blocking) | |||
| input_ms = cast_to_ms_tensor(src) | |||
| output = ms.ops.broadcast_to(input_ms, self.shape) | |||
| if len(self.shape) > 0: | |||
| output = ms.ops.broadcast_to(input_ms, self.shape) | |||
| else: | |||
| output = input_ms | |||
| output = output.astype(self.dtype) | |||
| return _tensor_inplace_assign(self, output, "copy_", "copy_adapter") | |||
| @@ -719,9 +779,11 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| return cast_to_adapter_tensor(input_ms.float()) | |||
| def flip(self, dims): # TODO ms.numpy.flip -> Tensor.flip | |||
| def flip(self, dims): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| output = ms.numpy.flip(input_ms, dims) | |||
| if not isinstance(dims, (list, tuple)): | |||
| dims = (dims,) | |||
| output = input_ms.flip(dims) | |||
| return cast_to_adapter_tensor(output) | |||
| def sign(self): | |||
| @@ -873,54 +935,56 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| #TODO | |||
| return self | |||
| def min(self, dim=None, keepdim=False): | |||
| # To achieve the polymorphism Tensor.min(Tensor input, Tensor other, *, Tensor out) | |||
| # other=None is used to represent the keywords param input | |||
| def min(self, dim=None, keepdim=False, other=None): | |||
| input = cast_to_ms_tensor(self) | |||
| type = input.dtype | |||
| input = input.astype(ms.float32) | |||
| if other is not None: | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.minimum(input, other).astype(type) | |||
| return cast_to_adapter_tensor(output) | |||
| if isinstance(dim, Tensor): | |||
| other = cast_to_ms_tensor(dim) | |||
| output = ms.ops.minimum(input, other).astype(type) | |||
| return cast_to_adapter_tensor(output) | |||
| if dim is None: | |||
| output = input.min().astype(type) | |||
| output = input.min(axis=dim, keepdims=keepdim).astype(type) | |||
| return cast_to_adapter_tensor(output) | |||
| #TODO | |||
| # Until now, P.min do not support when `input` is type of `int32`, `int64``. | |||
| if self.dtype == mstype.int64 or self.dtype == mstype.int32: | |||
| if self.dtype == mstype.int64: | |||
| dtype_name = 'torch.int64' | |||
| else: | |||
| dtype_name = 'torch.int32' | |||
| raise TypeError("For 'Tensor.min', the type of `input` do not support `torch.int64` and " | |||
| "`torch.int32`, got {}.".format(dtype_name)) | |||
| result, indices = ms.ops.min(input, dim, keepdim) | |||
| result = result.astype(type) | |||
| value, indice = ms.ops.min(input, dim, keepdim) | |||
| value = value.astype(type) | |||
| indice = indice.astype(ms.int64) | |||
| if pynative_mode_condition(): | |||
| point = set_name_tuple('min') | |||
| rlt = point(cast_to_adapter_tensor(result), cast_to_adapter_tensor(indices)) | |||
| rlt = point(cast_to_adapter_tensor(value), cast_to_adapter_tensor(indice)) | |||
| return rlt | |||
| return cast_to_adapter_tensor(result), cast_to_adapter_tensor(indices) | |||
| return cast_to_adapter_tensor(value), cast_to_adapter_tensor(indice) | |||
| def max(self, dim=None, keepdim=False): | |||
| # To achieve the polymorphism Tensor.max(Tensor input, Tensor other, *, Tensor out) | |||
| # other=None is used to represent the keywords param input | |||
| def max(self, dim=None, keepdim=False, other=None): | |||
| input = cast_to_ms_tensor(self) | |||
| type = input.dtype | |||
| input = input.astype(ms.float32) | |||
| if other is not None: | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.maximum(input, other).astype(type) | |||
| return cast_to_adapter_tensor(output) | |||
| if isinstance(dim, Tensor): | |||
| other = cast_to_ms_tensor(dim) | |||
| output = ms.ops.maximum(input, other).astype(type) | |||
| return cast_to_adapter_tensor(output) | |||
| if dim is None: | |||
| output = input.max().astype(type) | |||
| output = input.max(axis=dim, keepdims=keepdim).astype(type) | |||
| return cast_to_adapter_tensor(output) | |||
| # TODO: Until now, P.max do not support when `input` is type of `int32`, `int64``. | |||
| if self.dtype == mstype.int64 or self.dtype == mstype.int32: | |||
| if self.dtype == mstype.int64: | |||
| dtype_name = 'torch.int64' | |||
| else: | |||
| dtype_name = 'torch.int32' | |||
| raise TypeError("For 'Tensor.max', the type of `input` do not support `torch.int64` and " | |||
| "`torch.int32`, got {}.".format(dtype_name)) | |||
| result, indices = ms.ops.max(input, dim, keepdim) | |||
| result = result.astype(type) | |||
| value, indice = ms.ops.max(input, dim, keepdim) | |||
| value = value.astype(type) | |||
| indice = indice.astype(ms.int64) | |||
| if pynative_mode_condition(): | |||
| point = set_name_tuple('max') | |||
| rlt = point(cast_to_adapter_tensor(result), cast_to_adapter_tensor(indices)) | |||
| rlt = point(cast_to_adapter_tensor(value), cast_to_adapter_tensor(indice)) | |||
| return rlt | |||
| return cast_to_adapter_tensor(result), cast_to_adapter_tensor(indices) | |||
| return cast_to_adapter_tensor(value), cast_to_adapter_tensor(indice) | |||
| def numel(self): | |||
| input = cast_to_ms_tensor(self) | |||
| @@ -931,6 +995,9 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| output = ms.ops.stop_gradient(input_ms) | |||
| return cast_to_adapter_tensor(output) | |||
| def detach_(self): | |||
| return _tensor_inplace_assign(self, self.detach(), "detach_", "detach") | |||
| def sum(self, dim=None, keepdim=False, dtype=None): | |||
| input = cast_to_ms_tensor(self) | |||
| # TODO: mindspore tensor.sum can not automatically promote dtype yet, will cause overflow. | |||
| @@ -991,7 +1058,7 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| shape = tuple(shape) | |||
| input_size = self.shape | |||
| if input_size[0] == 0: # only support first element is 0 | |||
| if ms.ops.isconstant(input_size) and input_size[0] == 0: # only support first element is 0 | |||
| numel = ms.ops.size(self) | |||
| shape = _infer_size(shape, numel) | |||
| #TODO: ms.ops.zeros() currently has problem handling input shape including 0 | |||
| @@ -1033,6 +1100,13 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| def reciprocal(self): | |||
| input = cast_to_ms_tensor(self) | |||
| output = ms.ops.reciprocal(input) | |||
| #TODO: GPU has problem handling boundary value | |||
| if is_under_gpu_context(): | |||
| output_dtype = output.dtype | |||
| if output_dtype == ms.float32: | |||
| output = ms.ops.where((output <= FP32_MIN) | (output >= FP32_MAX), float('inf'), output) | |||
| if output_dtype == ms.float64: | |||
| output = ms.ops.where((output <= FP64_MIN) | (output >= FP64_MAX), float('inf'), output) | |||
| return cast_to_adapter_tensor(output) | |||
| def reciprocal_(self): | |||
| @@ -1072,7 +1146,7 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| def reshape(self, *shape): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| input_size = input_ms.shape | |||
| if input_size[0] == 0: # only support first element is 0 | |||
| if ms.ops.isconstant(input_size) and input_size[0] == 0: # only support first element is 0 | |||
| numel = ms.ops.size(input_ms) | |||
| shape = _infer_size(shape, numel) | |||
| #TODO: ms.ops.zeros() currently has preblem handling input shape including 0 | |||
| @@ -1220,7 +1294,6 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| return cast_to_adapter_tensor((output, qr)) | |||
| def matmul(self, tensor2): | |||
| # TODO: ms.ops.matmul not support int-dtype input on GPU, only support float dtype input | |||
| input_ms = cast_to_ms_tensor(self) | |||
| tensor2_ms = cast_to_ms_tensor(tensor2) | |||
| # TODO: repalce with output = ms.ops.matmul(input_ms, tensor2_ms) | |||
| @@ -1393,9 +1466,9 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| def rsqrt(self): | |||
| input = cast_to_ms_tensor(self) | |||
| if 'Bool' in str(input.dtype) or 'Int' in str(input.dtype): | |||
| if input.dtype in all_int_type_with_bool: | |||
| input = input.astype(ms.float32) | |||
| output = _get_cache_prim(ms.ops.Rsqrt)()(input) | |||
| output = ms.ops.rsqrt(input) | |||
| return cast_to_adapter_tensor(output) | |||
| def rsqrt_(self): | |||
| @@ -1457,6 +1530,11 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| def data(self): | |||
| return self.detach() | |||
| @data.setter | |||
| def data(self, data): | |||
| ms_data = cast_to_ms_tensor(data) | |||
| self.assign_value(ms_data) | |||
| def new(self, *size): | |||
| if len(size) > 0 and isinstance(size[0], tuple): | |||
| size = size[0] | |||
| @@ -1516,10 +1594,37 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| else: | |||
| return self.transpose(0, 1) | |||
| @property | |||
| def is_quantized(self): | |||
| warnings.warn("tensor.is_quantized only suppport set to False now. So It is always False.") | |||
| return False | |||
| @is_quantized.setter | |||
| def is_quantized(self, flag): | |||
| raise AttributeError("attribute 'is_quantized' of 'torch.Tensor' objects is not writable.") | |||
| @property | |||
| def requires_grad(self): | |||
| warnings.warn("tensor.requires_grad only suppport set to True now. So It is always True.") | |||
| return True | |||
| @requires_grad.setter | |||
| def requires_grad(self, flag): | |||
| if not isinstance(flag, bool): | |||
| raise RuntimeError("requires_grad must be a bool") | |||
| if flag is False: | |||
| raise NotImplementedError("tensor.requires_grad can not set to False yet. " | |||
| "If tensor is not leaf Tensor, can try tensor.detach() instead. " | |||
| "If tensor is leaf Tensor, can replaces tensor with Parameter, because " | |||
| "Parameter.requires_grad work with mindspore autograd mechanism, " | |||
| "when it set to False, the gradient return by ms.grad" | |||
| "(https://www.mindspore.cn/docs/zh-CN/r2.0/" | |||
| "api_python/mindspore/mindspore.grad.html) " | |||
| "or ms.value_and_grad" | |||
| "(https://www.mindspore.cn/docs/zh-CN/r2.0/" | |||
| "api_python/mindspore/mindspore.value_and_grad.html)" | |||
| " is zero. ") | |||
| def requires_grad_(self, requires_grad=True): | |||
| if requires_grad is False: | |||
| warnings.warn("requires_grad is always True in Tensor.") | |||
| @@ -1582,7 +1687,7 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| def masked_fill(self, mask, value): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| output = input_ms.masked_fill(mask, value) | |||
| output = input_ms.masked_fill(mask.bool(), value) | |||
| return cast_to_adapter_tensor(output) | |||
| def masked_fill_(self, mask, value): | |||
| @@ -2056,8 +2161,9 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| input = cast_to_ms_tensor(self) | |||
| input2 = cast_to_ms_tensor(mat2) | |||
| input_type = input.dtype | |||
| if input_type in (mstype.int32,mstype.int64) and is_under_gpu_context(): | |||
| input = self.astype(mstype.float32) | |||
| if input_type in all_int_type and is_under_gpu_context(): | |||
| input = input.astype(mstype.float32) | |||
| input2 = input2.astype(mstype.float32) | |||
| # TODO: repalce with output = ms.ops.matmul(input, input2) | |||
| output = custom_matmul(input, input2) | |||
| output = ms.ops.cast(output, input_type) | |||
| @@ -2301,7 +2407,13 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| def bitwise_and(self, other): | |||
| input = cast_to_ms_tensor(self) | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.bitwise_and(input, other) | |||
| #TODO: currently bitwise operations on Ascend not support bool type | |||
| if is_under_ascend_context(): | |||
| input, other, output_dtype = bitwise_adapter(input, other) | |||
| output = ms.ops.bitwise_and(input, other) | |||
| output = output.astype(output_dtype) | |||
| else: | |||
| output = ms.ops.bitwise_and(input, other) | |||
| return cast_to_adapter_tensor(output) | |||
| def bitwise_and_(self, other): | |||
| @@ -2311,7 +2423,13 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| def bitwise_or(self, other): | |||
| input = cast_to_ms_tensor(self) | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.bitwise_or(input, other) | |||
| #TODO: currently bitwise operations on Ascend not support bool type | |||
| if is_under_ascend_context(): | |||
| input, other, output_dtype = bitwise_adapter(input, other) | |||
| output = ms.ops.bitwise_or(input, other) | |||
| output = output.astype(output_dtype) | |||
| else: | |||
| output = ms.ops.bitwise_or(input, other) | |||
| return cast_to_adapter_tensor(output) | |||
| def bitwise_or_(self, other): | |||
| @@ -2321,7 +2439,13 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| def bitwise_xor(self, other): | |||
| input = cast_to_ms_tensor(self) | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.bitwise_xor(input, other) | |||
| #TODO: currently bitwise operations on Ascend not support bool type | |||
| if is_under_ascend_context(): | |||
| input, other, output_dtype = bitwise_adapter(input, other) | |||
| output = ms.ops.bitwise_xor(input, other) | |||
| output = output.astype(output_dtype) | |||
| else: | |||
| output = ms.ops.bitwise_xor(input, other) | |||
| return cast_to_adapter_tensor(output) | |||
| def bitwise_xor_(self, other): | |||
| @@ -2357,9 +2481,8 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| def all(self, dim=(), keepdim=False): | |||
| input = cast_to_ms_tensor(self) | |||
| if input.dtype != ms.bool_: | |||
| input = input.astype(ms.bool_) | |||
| output = input.all(axis=dim, keep_dims=keepdim) | |||
| # tensor.all only support bool dtype | |||
| output = ms.ops.all(input, axis=dim, keep_dims=keepdim) | |||
| return cast_to_adapter_tensor(output) | |||
| def isclose(self, other, rtol=1e-05, atol=1e-08, equal_nan=False): | |||
| @@ -2383,6 +2506,12 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| output = input.cholesky_inverse(upper) | |||
| return cast_to_adapter_tensor(output) | |||
| def cholesky_solve(self, input2, upper=False): | |||
| input = cast_to_ms_tensor(self) | |||
| input2 = cast_to_ms_tensor(input2) | |||
| output = ms.ops.cholesky_solve(input, input2, upper) | |||
| return cast_to_adapter_tensor(output) | |||
| def nelement(self): | |||
| input = cast_to_ms_tensor(self) | |||
| output = input.nelement() | |||
| @@ -2518,9 +2647,14 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| return cast_to_adapter_tensor(output) | |||
| def diag(self, diagonal=0): | |||
| # TODO: ms.ops.diag do not support diagonal | |||
| # TODO | |||
| # May be use mindspore.ops.diag instead. Nowadays, this operator do not support CPU. | |||
| # ms.numpy.diag has bug on ascend, use ms.ops.diag for diagonal=None and 1D input | |||
| input = cast_to_ms_tensor(self) | |||
| output = ms.numpy.diag(input, diagonal) | |||
| if is_under_ascend_context() and input.ndim == 1 and diagonal == 0: | |||
| output = ms.ops.diag(input) | |||
| else: | |||
| output = ms.numpy.diag(input, diagonal) | |||
| return cast_to_adapter_tensor(output) | |||
| def diagflat(self, offset=0): | |||
| @@ -2698,6 +2832,11 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| output = ms.ops.narrow(input, dimension, start, length) | |||
| return cast_to_adapter_tensor(output) | |||
| def narrow_copy(self, dimension, start, length): | |||
| input = cast_to_ms_tensor(self) | |||
| output = ms.ops.narrow(input, dimension, start, length) | |||
| return cast_to_adapter_tensor(output) | |||
| def norm(self, p='fro', dim=None, keepdim=False, dtype=None): | |||
| # TODO: ms.ops.norm benchmarking torch.linalg.norm. some matrix-norm result not right. | |||
| # `p` can not support value beside ['fro', 'nuc', inf, -inf, 0, 1, -1, 2, -2] | |||
| @@ -2742,7 +2881,15 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| other = cast_to_ms_tensor(other) | |||
| if input.is_complex(): | |||
| input = ms.ops.conj(input) | |||
| output = ms.ops.inner(input, other) | |||
| if (is_under_gpu_context() and (input.dtype in all_int_type)) or \ | |||
| (is_under_ascend_context() and (input.dtype in (ms.float64,) + all_int_type)): | |||
| warnings.warn("For vdot, input with int64 type has risk of being truncated.") | |||
| input_dtype = input.dtype | |||
| input = input.astype(ms.float32) | |||
| other = other.astype(ms.float32) | |||
| output = ms.ops.inner(input, other).astype(input_dtype) | |||
| else: | |||
| output = ms.ops.inner(input, other) | |||
| return cast_to_adapter_tensor(output) | |||
| def where(self, condition, y): | |||
| @@ -3121,15 +3268,21 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| def inner(self, other): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| other_ms = cast_to_ms_tensor(other) | |||
| # TODO: ms.ops.inner(ms.Tensor(2), ms.Tensor([3.2, 4.1])) will not return float type, but int type. | |||
| output = ms.ops.inner(input_ms, other_ms) | |||
| input_type = input_ms.dtype | |||
| if self.dtype in all_int_type and is_under_gpu_context(): | |||
| input_ms = input_ms.astype(mstype.float32) | |||
| other_ms = other_ms.astype(mstype.float32) | |||
| output = ms.ops.inner(input_ms, other_ms) | |||
| output = ms.ops.cast(output, input_type) | |||
| else: | |||
| output = ms.ops.inner(input_ms, other_ms) | |||
| return cast_to_adapter_tensor(output) | |||
| def roll(self, shifts, dims=None): | |||
| input_ms = cast_to_ms_tensor(self) | |||
| #TODO: support roll on CPU platform. Currently use numpy func | |||
| # TODO: support roll on CPU and Ascend platform. Currently use numpy func | |||
| # TODO: on Ascend, ms.ops.roll can only accept shifts with single number. | |||
| if is_under_cpu_context(): | |||
| if not is_under_gpu_context(): | |||
| output = ms.numpy.roll(input_ms, shifts, dims) | |||
| else: | |||
| output = ms.ops.roll(input_ms, shifts, dims) | |||
| @@ -3303,7 +3456,6 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| _op.set_device("CPU") | |||
| output = _op(input, other) | |||
| else: | |||
| #TODO: ops.cross not support on Ascend. | |||
| output = ms.ops.cross(input, other, dim) | |||
| return cast_to_adapter_tensor(output) | |||
| @@ -3323,16 +3475,18 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| def histc(self, bins=100, min=0, max=0): | |||
| input = cast_to_ms_tensor(self) | |||
| input_dtype = input.dtype | |||
| if input.dtype in msdapter_dtype.all_int_type: | |||
| input = input.astype(ms.int32) | |||
| elif input_dtype not in (ms.float16, ms.float32): | |||
| input = input.astype(ms.float32) | |||
| # TODO: ms.ops.histc only support Ascend and cpu, not gpu | |||
| output = ms.ops.histc(input, bins, min, max) | |||
| return cast_to_adapter_tensor(output) | |||
| #TODO: currently not support histc on GPU | |||
| if is_under_gpu_context(): | |||
| if max == min: | |||
| max, _ = ms.ops.max(input) | |||
| min, _ = ms.ops.min(input) | |||
| output, _ = ms.numpy.histogram(input, bins, (min, max)) | |||
| else: | |||
| if input_dtype not in (ms.float16, ms.float32, ms.int32): | |||
| input = input.astype(ms.float32) | |||
| output = ms.ops.histc(input, bins, min, max) | |||
| return cast_to_adapter_tensor(output.astype(input_dtype)) | |||
| def histogram(self, bins, *, range=None, weight=None, density=False): | |||
| input = cast_to_ms_tensor(self) | |||
| @@ -3466,6 +3620,7 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| output = input_copy.index_add(dim, index, source) | |||
| return cast_to_adapter_tensor(output) | |||
| def index_add_(self, dim, index, source, *, alpha=1): | |||
| # TODO: to support input of more than 2-D & dim >= 1, to support GRAPH mode | |||
| output = self.index_add(dim, index, source, alpha=alpha) | |||
| @@ -3477,7 +3632,15 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| input = cast_to_ms_tensor(self) | |||
| index = cast_to_ms_tensor(index) | |||
| src = cast_to_ms_tensor(src) | |||
| output = ms.ops.tensor_scatter_elements(input, index, src, axis=dim, reduction="add") | |||
| # TODO: ascend does not support tensor_scatter_elements | |||
| if is_under_ascend_context(): | |||
| if dim > 0: | |||
| nd_idx, nd_input, nd_src = self._get_scatter_ndim_input(input, index, src, dim) | |||
| output = ms.ops.scatter_nd_add(nd_input, nd_idx, nd_src).squeeze(-1) | |||
| else: | |||
| output = ms.ops.scatter_add(input, index, src) | |||
| else: | |||
| output = ms.ops.tensor_scatter_elements(input, index, src, axis=dim, reduction="add") | |||
| return cast_to_adapter_tensor(output) | |||
| def scatter_add_(self, dim, index, src): | |||
| @@ -3555,12 +3718,11 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| def nan_to_num(self, nan=0.0, posinf=None, neginf=None): | |||
| # TODO: ms.ops.nan_to_num to support float64 input | |||
| input = cast_to_ms_tensor(self) | |||
| if is_under_ascend_context(): | |||
| #TODO: ascend currently not support int input | |||
| if neginf is not None: | |||
| neginf = float(neginf) | |||
| if posinf is not None: | |||
| posinf = float(posinf) | |||
| #TODO: 2.1 not support neginf/posinf int input | |||
| if neginf is not None: | |||
| neginf = float(neginf) | |||
| if posinf is not None: | |||
| posinf = float(posinf) | |||
| input_dtype = input.dtype | |||
| if is_under_gpu_context() or input_dtype == mstype.float64: | |||
| output = input.masked_fill(input.isnan(), nan) | |||
| @@ -3606,13 +3768,17 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| index = index.flatten() | |||
| source = source.flatten() | |||
| if is_under_ascend_context() and input.dtype in msdapter_dtype.all_int_type: | |||
| input = input.astype(ms.float32) | |||
| source = source.astype(ms.float32) | |||
| # behavior is undefined when accumulate=False and index contain duplicate elements, same as torch | |||
| if accumulate is False: | |||
| output = ms.ops.scatter_update(input, index, source).reshape(input_shape).astype(input_type) | |||
| else: | |||
| # IndexAdd supports only Float16 Float32 Float64 Int16 Int32 Int8 UInt8 input and Int32 index | |||
| index = index.astype(mstype.int32) | |||
| output = ms.ops.index_add(input.astype(mstype.float64), index, source, 0) \ | |||
| output = ms.ops.index_add(input.astype(mstype.float32), index, source, 0) \ | |||
| .reshape(input_shape).astype(input_type) | |||
| output = cast_to_adapter_tensor(output) | |||
| @@ -3633,6 +3799,9 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| input = cast_to_ms_tensor(self) | |||
| indices = cast_to_ms_tensor(indices) | |||
| values = cast_to_ms_tensor(values) | |||
| for index in indices: | |||
| if index.numel() == 0: | |||
| return cast_to_adapter_tensor(input) | |||
| # TODO: ms.ops.index_put does not support values input with rank>1 | |||
| idx = ms.ops.dstack(indices)[0] | |||
| if accumulate is False: | |||
| @@ -3684,6 +3853,20 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| return rlt | |||
| return cast_to_adapter_tensor(values), cast_to_adapter_tensor(indices) | |||
| def _get_scatter_ndim_input(self, input, index, src, dim): | |||
| index_stk = () | |||
| for i in range(len(index.shape)): | |||
| new_shape=(index.shape[i],) + (1,) * (len(index.shape) - 1 - i) | |||
| if i == dim: | |||
| index_stk = index_stk + (index.float(),) | |||
| else: | |||
| index_stk = index_stk + \ | |||
| (ms.ops.arange(0, index.shape[i]).float().reshape(new_shape).broadcast_to(index.shape),) | |||
| nd_idx = ms.ops.stack(index_stk, -1).long() | |||
| nd_input = input.unsqueeze(-1) | |||
| nd_src = src[..., :index.shape[-2], :index.shape[-1]].unsqueeze(-1) | |||
| return nd_idx, nd_input, nd_src | |||
| def scatter_reduce(self, dim, index, src, reduce, *, include_self=True): | |||
| # TODO: to support reduce='mean' | |||
| if reduce == 'mean': | |||
| @@ -3700,28 +3883,22 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| input = cast_to_ms_tensor(input) | |||
| index = cast_to_ms_tensor(index) | |||
| src = cast_to_ms_tensor(src) | |||
| index_stk = () | |||
| if dim > 0: | |||
| for i in range(len(index.shape)): | |||
| new_shape=(index.shape[i],) + (1,) * (len(index.shape) - 1 - i) | |||
| expand_input = ms.Tensor(index.shape) | |||
| if i == dim: | |||
| index_stk = index_stk + (index.float(),) | |||
| else: | |||
| index_stk = index_stk + \ | |||
| (ms.ops.arange(0, index.shape[i]).float().reshape(new_shape).expand(expand_input),) | |||
| nd_idx = ms.ops.stack(index_stk, -1).long() | |||
| nd_input = input.unsqueeze(-1) | |||
| nd_src = src[..., :index.shape[-2], :index.shape[-1]].unsqueeze(-1) | |||
| nd_idx, nd_input, nd_src = self._get_scatter_ndim_input(input, index, src, dim) | |||
| if reduce == 'sum': | |||
| if include_self is False: | |||
| input = input.scatter(dim, index, ms.ops.zeros_like(index, dtype=input.dtype)) | |||
| output = ms.ops.tensor_scatter_elements(input, index, src, axis=dim, reduction="add") | |||
| if dim > 0: | |||
| output = ms.ops.scatter_nd_add(nd_input, nd_idx, nd_src).squeeze(-1) | |||
| else: | |||
| output = ms.ops.scatter_add(input, index, src) | |||
| elif reduce == 'prod': | |||
| if include_self is False: | |||
| input = input.scatter(dim, index, ms.ops.ones_like(index, dtype=input.dtype)) | |||
| if dim > 0: | |||
| # TODO: ms.ops.scatter_nd_mul to support Ascend | |||
| output = ms.ops.scatter_nd_mul(nd_input, nd_idx, nd_src).squeeze(-1) | |||
| else: | |||
| output = ms.ops.scatter_mul(input, index, src) | |||
| @@ -3913,6 +4090,93 @@ class Tensor(StubTensor, metaclass=_TensorMeta): | |||
| output = ms.ops.softmax(input, dim) | |||
| return cast_to_adapter_tensor(output) | |||
| def nanmedian(self, dim=None, keepdim=False): | |||
| input = cast_to_ms_tensor(self) | |||
| if dim is None: | |||
| # ms.ops.median can not compute the median value along all dimentions | |||
| # only ms.ops.Median(global_median=True) can do that. | |||
| # so can not replace ms.ops.Median to ms.ops.median | |||
| output, _ = _get_cache_prim(ms.ops.Median)(global_median=True, ignore_nan=True)(input) | |||
| return cast_to_adapter_tensor(output) | |||
| else: | |||
| # TODO: On GPU, ms.ops.median the return indices may be wrong. | |||
| nanmedian_ = _get_cache_prim(ms.ops.Median)(global_median=False, axis=dim, keep_dims=keepdim, | |||
| ignore_nan=True) | |||
| value, indices = nanmedian_(input) | |||
| if pynative_mode_condition(): | |||
| point = set_name_tuple('nanmedian') | |||
| rlt = point(cast_to_adapter_tensor(value), cast_to_adapter_tensor(indices)) | |||
| return rlt | |||
| return cast_to_adapter_tensor(value), cast_to_adapter_tensor(indices) | |||
| def backward(self, gradient=None, retain_graph=None, create_graph=False, inputs=None): | |||
| unsupported_attr(gradient) | |||
| unsupported_attr(retain_graph) | |||
| unsupported_attr(create_graph) | |||
| unsupported_attr(inputs) | |||
| raise NotImplementedError( | |||
| "tensor.backward() not support yet. please use " | |||
| "mindspore.value_and_grad" | |||
| "(https://www.mindspore.cn/docs/zh-CN/r2.0/api_python/mindspore/mindspore.value_and_grad.html) " | |||
| "or mindspore.grad" | |||
| "(https://www.mindspore.cn/docs/zh-CN/r2.0/api_python/mindspore/mindspore.grad.html) " | |||
| "to compute gradient and send the gradient to the optimizer. " | |||
| "please refer to mobilenet_v2 example: " | |||
| "https://openi.pcl.ac.cn/OpenI/MSAdapterModelZoo/src/branch/master/official/cv/" | |||
| "mobilenet_v2/mobilenet_v2_adapter.py") | |||
| @property | |||
| def grad(self): | |||
| raise NotImplementedError( | |||
| "tensor.grad not support yet. pleause use " | |||
| "mindspore.value_and_grad" | |||
| "(https://www.mindspore.cn/docs/zh-CN/r2.0/api_python/mindspore/mindspore.value_and_grad.html) " | |||
| "or mindspore.grad" | |||
| "(https://www.mindspore.cn/docs/zh-CN/r2.0/api_python/mindspore/mindspore.grad.html) " | |||
| "to get the gradient. And take out the corresponding element as grad." | |||
| ) | |||
| def frexp(self): | |||
| # TODO: to use ms.ops.frexp | |||
| input = cast_to_ms_tensor(self) | |||
| if input.dtype == ms.float16: | |||
| input = input.astype(ms.float32) | |||
| sign = ms.ops.sign(input) | |||
| input = ms.ops.abs(input) | |||
| exp = ms.ops.floor(ms.ops.log2(input)) + 1 | |||
| mantissa = (input * sign / (2 ** exp)).astype(ms.float16) | |||
| else: | |||
| sign = ms.ops.sign(input) | |||
| input = ms.ops.abs(input) | |||
| exp = ms.ops.floor(ms.ops.log2(input)) + 1 | |||
| mantissa = input * sign / (2 ** exp) | |||
| output = (mantissa, exp.astype(ms.int32)) | |||
| return cast_to_adapter_tensor(output) | |||
| def ormqr(self, tau, other, left=True, transpose=False): | |||
| if not is_under_gpu_context(): | |||
| raise NotImplementedError("ormqr currently not supported on CPU nor Ascend") | |||
| else: | |||
| input = cast_to_ms_tensor(self) | |||
| tau = cast_to_ms_tensor(tau) | |||
| other = cast_to_ms_tensor(other) | |||
| output = ms.ops.ormqr(input, tau, other, left, transpose) | |||
| return cast_to_adapter_tensor(output) | |||
| def triangular_solve(self, A, upper=True, transpose=False, unitriangular=False): | |||
| if is_under_ascend_context(): | |||
| raise NotImplementedError("triangular_solve currently not supported on Ascend") | |||
| B = cast_to_ms_tensor(self) | |||
| A = cast_to_ms_tensor(A) | |||
| trans = 'T' if transpose else 'N' | |||
| solve_op = _get_cache_prim(SolveTriangular)(lower=(not upper), unit_diagonal=unitriangular, trans=trans) | |||
| output = solve_op(A, B) | |||
| if pynative_mode_condition(): | |||
| triangular_solve_namedtuple = set_multiple_name_tuple('triangular_solve', 'solution, cloned_coefficient') | |||
| output = triangular_solve_namedtuple(cast_to_adapter_tensor(output), cast_to_adapter_tensor(A)) | |||
| return output | |||
| return cast_to_adapter_tensor(output), cast_to_adapter_tensor(A) | |||
| class _TypeTensor(Tensor): | |||
| def __init__(self, *input_data, dtype_name): | |||
| super(_TypeTensor, self).__init__(*input_data, dtype=dtype_name, inner=False) | |||
+ 4
- 2
msadapter/pytorch/utils/data/dataloader.py
View File
| @@ -214,7 +214,7 @@ class DataLoader(Generic[T_co]): | |||
| def __init__(self, dataset: Dataset[T_co], batch_size: Optional[int] = 1, | |||
| shuffle: Optional[bool] = None, sampler: Union[Sampler, Iterable, None] = None, | |||
| batch_sampler: Union[Sampler[Sequence], Iterable[Sequence], None] = None, | |||
| num_workers: int = 0, collate_fn: Optional[_collate_fn_t] = None, | |||
| num_workers: int = 1, collate_fn: Optional[_collate_fn_t] = None, | |||
| pin_memory: bool = False, drop_last: bool = False, | |||
| timeout: float = 0, worker_init_fn: Optional[_worker_init_fn_t] = None, | |||
| multiprocessing_context=None, generator=None, | |||
| @@ -959,7 +959,9 @@ class _MultiProcessingDataLoaderIter(_BaseDataLoaderIter): | |||
| else: | |||
| # not found (i.e., didn't break) | |||
| return | |||
| if isinstance(index[0], torch.Tensor): | |||
| if isinstance(index, torch.Tensor): | |||
| index = index.asnumpy() | |||
| elif isinstance(index, (tuple, list)) and isinstance(index[0], torch.Tensor): | |||
| index = [i.asnumpy() for i in index] | |||
| self._index_queues[worker_queue_idx].put((self._send_idx, index)) | |||
| self._task_info[self._send_idx] = (worker_queue_idx,) | |||
+ 12
- 2
msadapter/pytorch/utils/data/dataset.py
View File
| @@ -197,8 +197,18 @@ class TensorDataset(Dataset[Tuple[Tensor, ...]]): | |||
| tensors: Tuple[Tensor, ...] | |||
| def __init__(self, *tensors: Tensor) -> None: | |||
| assert all(tensors[0].shape[0] == tensor.shape[0] for tensor in tensors), "Size mismatch between tensors" | |||
| self.tensors = tensors | |||
| ref_shape = tensors[0].shape[0] | |||
| tensors_tuple = () | |||
| for tensor in tensors: | |||
| if ref_shape != tensor.shape[0]: | |||
| raise ValueError("Size mismatch between tensors") | |||
| if isinstance(tensor, torch.Tensor): | |||
| # To accelerate and avoiding SyncDeviceToHost failed in GPU/Ascend, the return value is converted | |||
| # to `numpy.ndarray`. | |||
| tensor = tensor.asnumpy() | |||
| tensors_tuple = tensors_tuple + (tensor,) | |||
| self.tensors = tensors_tuple | |||
| def __getitem__(self, index): | |||
| return tuple(tensor[index] for tensor in self.tensors) | |||
+ 0
- 4
msadapter/pytorch/utils/data/readme.md
View File
| @@ -1,4 +0,0 @@ | |||
| #torch data | |||
| torch data模块是迁移自torch官方实现的数据集处理与加载模块,延用torch官方api设计与使用习惯,内部计算调用MindSpore算子和numpy算子,实现与torch.utils.data模块相同功能。 | |||
| 在dataloader模块中不支持pin_memory相关功能。 | |||
+ 10
- 0
msadapter/tools/readme.md
View File
| @@ -1,5 +1,15 @@ | |||
| # quick start | |||
| ## replace_import_package | |||
| 利用replace_import_package工具可快速完成工程代码中torch及torchvision相关导入包的替换。使用方法如下: | |||
| ```shell | |||
| bash replace_import_package.sh [Project Path] | |||
| ``` | |||
| `Project Path`为需要进行替换的工程路经,默认为"./"。 | |||
| ## pth2ckpt | |||
| `pth2ckpt.py`文件中的`pth2ckpt`接口可以将Torch的权重文件转换为MindSpore的权重文件。使用方法如下: | |||
+ 10
- 0
msadapter/tools/replace_import_package.sh
View File
| @@ -0,0 +1,10 @@ | |||
| echo "Current Replacement Directory:${1:-./}" | |||
| find $1 -name "*.py" -print0 | xargs -0 sed -i "s/import\s\+torchvision.\b/import msadapter.torchvision./g" | |||
| find $1 -name "*.py" -print0 | xargs -0 sed -i "s/import\s\+torchvision\b/import msadapter.torchvision as torchvision/g" | |||
| find $1 -name "*.py" -print0 | xargs -0 sed -i "s/from\s\+torchvision\b/from msadapter.torchvision/g" | |||
| find $1 -name "*.py" -print0 | xargs -0 sed -i "s/import\s\+torch.\b/import msadapter.pytorch./g" | |||
| find $1 -name "*.py" -print0 | xargs -0 sed -i "s/import\s\+torch\b/import msadapter.pytorch as torch/g" | |||
| find $1 -name "*.py" -print0 | xargs -0 sed -i "s/from\s\+torch\b/from msadapter.pytorch/g" | |||
| echo "Replacement torch/torchvision completed!" | |||
+ 7
- 7
msadapter/torchvision/models/alexnet.py
View File
| @@ -15,27 +15,27 @@ class AlexNet(nn.Module): | |||
| super(AlexNet, self).__init__() | |||
| self.features = nn.Sequential( | |||
| nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.MaxPool2d(kernel_size=3, stride=2), | |||
| nn.Conv2d(64, 192, kernel_size=5, padding=2), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.MaxPool2d(kernel_size=3, stride=2), | |||
| nn.Conv2d(192, 384, kernel_size=3, padding=1), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.Conv2d(384, 256, kernel_size=3, padding=1), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.Conv2d(256, 256, kernel_size=3, padding=1), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.MaxPool2d(kernel_size=3, stride=2), | |||
| ) | |||
| self.avgpool = nn.AdaptiveAvgPool2d((6, 6)) | |||
| self.classifier = nn.Sequential( | |||
| nn.Dropout(), | |||
| nn.Linear(256 * 6 * 6, 4096), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.Dropout(), | |||
| nn.Linear(4096, 4096), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.Linear(4096, num_classes), | |||
| ) | |||
+ 5
- 5
msadapter/torchvision/models/densenet.py
View File
| @@ -35,7 +35,7 @@ class _DenseLayer(nn.Module): | |||
| self.norm1: nn.BatchNorm2d | |||
| self.add_module('norm1', nn.BatchNorm2d(num_input_features)) | |||
| self.relu1: nn.ReLU | |||
| self.add_module('relu1', nn.ReLU(inplace=True)) | |||
| self.add_module('relu1', nn.ReLU(inplace=False)) | |||
| self.conv1: nn.Conv2d | |||
| self.add_module('conv1', nn.Conv2d(num_input_features, bn_size * | |||
| growth_rate, kernel_size=1, stride=1, | |||
| @@ -43,7 +43,7 @@ class _DenseLayer(nn.Module): | |||
| self.norm2: nn.BatchNorm2d | |||
| self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)) | |||
| self.relu2: nn.ReLU | |||
| self.add_module('relu2', nn.ReLU(inplace=True)) | |||
| self.add_module('relu2', nn.ReLU(inplace=False)) | |||
| self.conv2: nn.Conv2d | |||
| self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate, | |||
| kernel_size=3, stride=1, padding=1, | |||
| @@ -136,7 +136,7 @@ class _Transition(nn.Sequential): | |||
| def __init__(self, num_input_features: int, num_output_features: int) -> None: | |||
| super(_Transition, self).__init__() | |||
| self.add_module('norm', nn.BatchNorm2d(num_input_features)) | |||
| self.add_module('relu', nn.ReLU(inplace=True)) | |||
| self.add_module('relu', nn.ReLU(inplace=False)) | |||
| self.add_module('conv', nn.Conv2d(num_input_features, num_output_features, | |||
| kernel_size=1, stride=1, bias=False)) | |||
| self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2)) | |||
| @@ -176,7 +176,7 @@ class DenseNet(nn.Module): | |||
| ('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, | |||
| padding=3, bias=False)), | |||
| ('norm0', nn.BatchNorm2d(num_init_features)), | |||
| ('relu0', nn.ReLU(inplace=True)), | |||
| ('relu0', nn.ReLU(inplace=False)), | |||
| ('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)), | |||
| ])) | |||
| @@ -217,7 +217,7 @@ class DenseNet(nn.Module): | |||
| def forward(self, x: Tensor) -> Tensor: | |||
| features = self.features(x) | |||
| out = F.relu(features, inplace=True) | |||
| out = F.relu(features, inplace=False) | |||
| out = F.adaptive_avg_pool2d(out, (1, 1)) | |||
| out = torch.flatten(out, 1) | |||
| out = self.classifier(out) | |||
+ 1
- 1
msadapter/torchvision/models/detection/keypoint_rcnn.py
View File
| @@ -235,7 +235,7 @@ class KeypointRCNNHeads(nn.Sequential): | |||
| next_feature = in_channels | |||
| for out_channels in layers: | |||
| d.append(nn.Conv2d(next_feature, out_channels, 3, stride=1, padding=1)) | |||
| d.append(nn.ReLU(inplace=True)) | |||
| d.append(nn.ReLU(inplace=False)) | |||
| next_feature = out_channels | |||
| super(KeypointRCNNHeads, self).__init__(*d) | |||
| for m in self.children(): | |||
+ 2
- 2
msadapter/torchvision/models/detection/mask_rcnn.py
View File
| @@ -238,7 +238,7 @@ class MaskRCNNHeads(nn.Sequential): | |||
| d["mask_fcn{}".format(layer_idx)] = nn.Conv2d( | |||
| next_feature, layer_features, kernel_size=3, | |||
| stride=1, padding=dilation, dilation=dilation) | |||
| d["relu{}".format(layer_idx)] = nn.ReLU(inplace=True) | |||
| d["relu{}".format(layer_idx)] = nn.ReLU(inplace=False) | |||
| next_feature = layer_features | |||
| super(MaskRCNNHeads, self).__init__(d) | |||
| @@ -253,7 +253,7 @@ class MaskRCNNPredictor(nn.Sequential): | |||
| def __init__(self, in_channels, dim_reduced, num_classes): | |||
| super(MaskRCNNPredictor, self).__init__(OrderedDict([ | |||
| ("conv5_mask", nn.ConvTranspose2d(in_channels, dim_reduced, 2, 2, 0)), | |||
| ("relu", nn.ReLU(inplace=True)), | |||
| ("relu", nn.ReLU(inplace=False)), | |||
| ("mask_fcn_logits", nn.Conv2d(dim_reduced, num_classes, 1, 1, 0)), | |||
| ])) | |||
+ 12
- 12
msadapter/torchvision/models/detection/ssd.py
View File
| @@ -433,45 +433,45 @@ class SSDFeatureExtractorVGG(nn.Module): | |||
| extra = nn.ModuleList([ | |||
| nn.Sequential( | |||
| nn.Conv2d(1024, 256, kernel_size=1), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.Conv2d(256, 512, kernel_size=3, padding=1, stride=2), # conv8_2 | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| ), | |||
| nn.Sequential( | |||
| nn.Conv2d(512, 128, kernel_size=1), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.Conv2d(128, 256, kernel_size=3, padding=1, stride=2), # conv9_2 | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| ), | |||
| nn.Sequential( | |||
| nn.Conv2d(256, 128, kernel_size=1), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.Conv2d(128, 256, kernel_size=3), # conv10_2 | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| ), | |||
| nn.Sequential( | |||
| nn.Conv2d(256, 128, kernel_size=1), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.Conv2d(128, 256, kernel_size=3), # conv11_2 | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| ) | |||
| ]) | |||
| if highres: | |||
| # Additional layers for the SSD512 case. See page 11, footernote 5. | |||
| extra.append(nn.Sequential( | |||
| nn.Conv2d(256, 128, kernel_size=1), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.Conv2d(128, 256, kernel_size=4), # conv12_2 | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| )) | |||
| _xavier_init(extra) | |||
| fc = nn.Sequential( | |||
| nn.MaxPool2d(kernel_size=3, stride=1, padding=1, ceil_mode=False), # add modified maxpool5 | |||
| nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, padding=6, dilation=6), # FC6 with atrous | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.Conv2d(in_channels=1024, out_channels=1024, kernel_size=1), # FC7 | |||
| nn.ReLU(inplace=True) | |||
| nn.ReLU(inplace=False) | |||
| ) | |||
| _xavier_init(fc) | |||
| extra.insert(0, nn.Sequential( | |||
+ 2
- 2
msadapter/torchvision/models/googlenet.py
View File
| @@ -291,7 +291,7 @@ class InceptionAux(nn.Module): | |||
| # N x 128 x 4 x 4 | |||
| x = torch.flatten(x, 1) | |||
| # N x 2048 | |||
| x = F.relu(self.fc1(x), inplace=True) | |||
| x = F.relu(self.fc1(x), inplace=False) | |||
| # N x 1024 | |||
| x = F.dropout(x, 0.7, training=self.training) | |||
| # N x 1024 | |||
| @@ -316,4 +316,4 @@ class BasicConv2d(nn.Module): | |||
| def forward(self, x: Tensor) -> Tensor: | |||
| x = self.conv(x) | |||
| x = self.bn(x) | |||
| return F.relu(x, inplace=True) | |||
| return F.relu(x, inplace=False) | |||
+ 1
- 1
msadapter/torchvision/models/inception.py
View File
| @@ -462,4 +462,4 @@ class BasicConv2d(nn.Module): | |||
| def forward(self, x: Tensor) -> Tensor: | |||
| x = self.conv(x) | |||
| x = self.bn(x) | |||
| return F.relu(x, inplace=True) | |||
| return F.relu(x, inplace=False) | |||
+ 8
- 8
msadapter/torchvision/models/mnasnet.py
View File
| @@ -42,12 +42,12 @@ class _InvertedResidual(nn.Module): | |||
| # Pointwise | |||
| nn.Conv2d(in_ch, mid_ch, 1, bias=False), | |||
| nn.BatchNorm2d(mid_ch, momentum=bn_momentum), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| # Depthwise | |||
| nn.Conv2d(mid_ch, mid_ch, kernel_size, padding=kernel_size // 2, | |||
| stride=stride, groups=mid_ch, bias=False), | |||
| nn.BatchNorm2d(mid_ch, momentum=bn_momentum), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| # Linear pointwise. Note that there's no activation. | |||
| nn.Conv2d(mid_ch, out_ch, 1, bias=False), | |||
| nn.BatchNorm2d(out_ch, momentum=bn_momentum)) | |||
| @@ -119,12 +119,12 @@ class MNASNet(torch.nn.Module): | |||
| # First layer: regular conv. | |||
| nn.Conv2d(3, depths[0], 3, padding=1, stride=2, bias=False), | |||
| nn.BatchNorm2d(depths[0], momentum=_BN_MOMENTUM), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| # Depthwise separable, no skip. | |||
| nn.Conv2d(depths[0], depths[0], 3, padding=1, stride=1, | |||
| groups=depths[0], bias=False), | |||
| nn.BatchNorm2d(depths[0], momentum=_BN_MOMENTUM), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.Conv2d(depths[0], depths[1], 1, padding=0, stride=1, bias=False), | |||
| nn.BatchNorm2d(depths[1], momentum=_BN_MOMENTUM), | |||
| # MNASNet blocks: stacks of inverted residuals. | |||
| @@ -137,10 +137,10 @@ class MNASNet(torch.nn.Module): | |||
| # Final mapping to classifier input. | |||
| nn.Conv2d(depths[7], 1280, 1, padding=0, stride=1, bias=False), | |||
| nn.BatchNorm2d(1280, momentum=_BN_MOMENTUM), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| ] | |||
| self.layers = nn.Sequential(*layers) | |||
| self.classifier = nn.Sequential(nn.Dropout(p=dropout, inplace=True), | |||
| self.classifier = nn.Sequential(nn.Dropout(p=dropout, inplace=False), | |||
| nn.Linear(1280, num_classes)) | |||
| self._initialize_weights() | |||
| @@ -179,11 +179,11 @@ class MNASNet(torch.nn.Module): | |||
| v1_stem = [ | |||
| nn.Conv2d(3, 32, 3, padding=1, stride=2, bias=False), | |||
| nn.BatchNorm2d(32, momentum=_BN_MOMENTUM), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.Conv2d(32, 32, 3, padding=1, stride=1, groups=32, | |||
| bias=False), | |||
| nn.BatchNorm2d(32, momentum=_BN_MOMENTUM), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.Conv2d(32, 16, 1, padding=0, stride=1, bias=False), | |||
| nn.BatchNorm2d(16, momentum=_BN_MOMENTUM), | |||
| _stack(16, depths[2], 3, 2, 3, 3, _BN_MOMENTUM), | |||
+ 1
- 1
msadapter/torchvision/models/mobilenetv2.py
View File
| @@ -51,7 +51,7 @@ class ConvBNActivation(nn.Sequential): | |||
| nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, dilation=dilation, groups=groups, | |||
| bias=False), | |||
| norm_layer(out_planes), | |||
| activation_layer(inplace=True) | |||
| activation_layer(inplace=False) | |||
| ) | |||
| self.out_channels = out_planes | |||
+ 3
- 3
msadapter/torchvision/models/mobilenetv3.py
View File
| @@ -24,7 +24,7 @@ class SqueezeExcitation(nn.Module): | |||
| super().__init__() | |||
| squeeze_channels = _make_divisible(input_channels // squeeze_factor, 8) | |||
| self.fc1 = nn.Conv2d(input_channels, squeeze_channels, 1) | |||
| self.relu = nn.ReLU(inplace=True) | |||
| self.relu = nn.ReLU(inplace=False) | |||
| self.fc2 = nn.Conv2d(squeeze_channels, input_channels, 1) | |||
| def _scale(self, input: Tensor, inplace: bool) -> Tensor: | |||
| @@ -154,8 +154,8 @@ class MobileNetV3(nn.Module): | |||
| self.avgpool = nn.AdaptiveAvgPool2d(1) | |||
| self.classifier = nn.Sequential( | |||
| nn.Linear(lastconv_output_channels, last_channel), | |||
| nn.Hardswish(inplace=True), | |||
| nn.Dropout(p=0.2, inplace=True), | |||
| nn.Hardswish(inplace=False), | |||
| nn.Dropout(p=0.2, inplace=False), | |||
| nn.Linear(last_channel, num_classes), | |||
| ) | |||
+ 3
- 3
msadapter/torchvision/models/resnet.py
View File
| @@ -57,7 +57,7 @@ class BasicBlock(nn.Module): | |||
| # Both self.conv1 and self.downsample layers downsample the input when stride != 1 | |||
| self.conv1 = conv3x3(inplanes, planes, stride) | |||
| self.bn1 = norm_layer(planes) | |||
| self.relu = nn.ReLU(inplace=True) | |||
| self.relu = nn.ReLU(inplace=False) | |||
| self.conv2 = conv3x3(planes, planes) | |||
| self.bn2 = norm_layer(planes) | |||
| self.downsample = downsample | |||
| @@ -113,7 +113,7 @@ class Bottleneck(nn.Module): | |||
| self.bn2 = norm_layer(width) | |||
| self.conv3 = conv1x1(width, planes * self.expansion) | |||
| self.bn3 = norm_layer(planes * self.expansion) | |||
| self.relu = nn.ReLU(inplace=True) | |||
| self.relu = nn.ReLU(inplace=False) | |||
| self.downsample = downsample | |||
| self.stride = stride | |||
| @@ -172,7 +172,7 @@ class ResNet(nn.Module): | |||
| self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, | |||
| bias=False) | |||
| self.bn1 = norm_layer(self.inplanes) | |||
| self.relu = nn.ReLU(inplace=True) | |||
| self.relu = nn.ReLU(inplace=False) | |||
| self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) | |||
| self.layer1 = self._make_layer(block, 64, layers[0]) | |||
| self.layer2 = self._make_layer(block, 128, layers[1], stride=2, | |||
+ 1
- 1
msadapter/torchvision/models/segmentation/lraspp.py
View File
| @@ -47,7 +47,7 @@ class LRASPPHead(nn.Module): | |||
| self.cbr = nn.Sequential( | |||
| nn.Conv2d(high_channels, inter_channels, 1, bias=False), | |||
| nn.BatchNorm2d(inter_channels), | |||
| nn.ReLU(inplace=True) | |||
| nn.ReLU(inplace=False) | |||
| ) | |||
| self.scale = nn.Sequential( | |||
| nn.AdaptiveAvgPool2d(1), | |||
+ 5
- 5
msadapter/torchvision/models/shufflenetv2.py
View File
| @@ -57,7 +57,7 @@ class InvertedResidual(nn.Module): | |||
| nn.BatchNorm2d(inp), | |||
| nn.Conv2d(inp, branch_features, kernel_size=1, stride=1, padding=0, bias=False), | |||
| nn.BatchNorm2d(branch_features), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| ) | |||
| else: | |||
| self.branch1 = nn.Sequential() | |||
| @@ -66,12 +66,12 @@ class InvertedResidual(nn.Module): | |||
| nn.Conv2d(inp if (self.stride > 1) else branch_features, | |||
| branch_features, kernel_size=1, stride=1, padding=0, bias=False), | |||
| nn.BatchNorm2d(branch_features), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| self.depthwise_conv(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1), | |||
| nn.BatchNorm2d(branch_features), | |||
| nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False), | |||
| nn.BatchNorm2d(branch_features), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| ) | |||
| @staticmethod | |||
| @@ -118,7 +118,7 @@ class ShuffleNetV2(nn.Module): | |||
| self.conv1 = nn.Sequential( | |||
| nn.Conv2d(input_channels, output_channels, 3, 2, 1, bias=False), | |||
| nn.BatchNorm2d(output_channels), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| ) | |||
| input_channels = output_channels | |||
| @@ -141,7 +141,7 @@ class ShuffleNetV2(nn.Module): | |||
| self.conv5 = nn.Sequential( | |||
| nn.Conv2d(input_channels, output_channels, 1, 1, 0, bias=False), | |||
| nn.BatchNorm2d(output_channels), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| ) | |||
| self.fc = nn.Linear(output_channels, num_classes) | |||
+ 6
- 6
msadapter/torchvision/models/squeezenet.py
View File
| @@ -25,13 +25,13 @@ class Fire(nn.Module): | |||
| super(Fire, self).__init__() | |||
| self.inplanes = inplanes | |||
| self.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1) | |||
| self.squeeze_activation = nn.ReLU(inplace=True) | |||
| self.squeeze_activation = nn.ReLU(inplace=False) | |||
| self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes, | |||
| kernel_size=1) | |||
| self.expand1x1_activation = nn.ReLU(inplace=True) | |||
| self.expand1x1_activation = nn.ReLU(inplace=False) | |||
| self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes, | |||
| kernel_size=3, padding=1) | |||
| self.expand3x3_activation = nn.ReLU(inplace=True) | |||
| self.expand3x3_activation = nn.ReLU(inplace=False) | |||
| def forward(self, x: torch.Tensor) -> torch.Tensor: | |||
| x = self.squeeze_activation(self.squeeze(x)) | |||
| @@ -53,7 +53,7 @@ class SqueezeNet(nn.Module): | |||
| if version == '1_0': | |||
| self.features = nn.Sequential( | |||
| nn.Conv2d(3, 96, kernel_size=7, stride=2), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True), | |||
| Fire(96, 16, 64, 64), | |||
| Fire(128, 16, 64, 64), | |||
| @@ -69,7 +69,7 @@ class SqueezeNet(nn.Module): | |||
| elif version == '1_1': | |||
| self.features = nn.Sequential( | |||
| nn.Conv2d(3, 64, kernel_size=3, stride=2), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True), | |||
| Fire(64, 16, 64, 64), | |||
| Fire(128, 16, 64, 64), | |||
| @@ -94,7 +94,7 @@ class SqueezeNet(nn.Module): | |||
| self.classifier = nn.Sequential( | |||
| nn.Dropout(p=0.5), | |||
| final_conv, | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.AdaptiveAvgPool2d((1, 1)) | |||
| ) | |||
+ 2
- 2
msadapter/torchvision/models/vgg.py
View File
| @@ -75,9 +75,9 @@ def make_layers(cfg: List[Union[str, int]], batch_norm: bool = False) -> nn.Sequ | |||
| v = cast(int, v) | |||
| conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1) | |||
| if batch_norm: | |||
| layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)] | |||
| layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=False)] | |||
| else: | |||
| layers += [conv2d, nn.ReLU(inplace=True)] | |||
| layers += [conv2d, nn.ReLU(inplace=False)] | |||
| in_channels = v | |||
| return nn.Sequential(*layers) | |||
+ 9
- 9
msadapter/torchvision/models/video/resnet.py
View File
| @@ -48,7 +48,7 @@ class Conv2Plus1D(nn.Sequential): | |||
| stride=(1, stride, stride), padding=(0, padding, padding), | |||
| bias=False), | |||
| nn.BatchNorm3d(midplanes), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.Conv3d(midplanes, out_planes, kernel_size=(3, 1, 1), | |||
| stride=(stride, 1, 1), padding=(padding, 0, 0), | |||
| bias=False)) | |||
| @@ -91,13 +91,13 @@ class BasicBlock(nn.Module): | |||
| self.conv1 = nn.Sequential( | |||
| conv_builder(inplanes, planes, midplanes, stride), | |||
| nn.BatchNorm3d(planes), | |||
| nn.ReLU(inplace=True) | |||
| nn.ReLU(inplace=False) | |||
| ) | |||
| self.conv2 = nn.Sequential( | |||
| conv_builder(planes, planes, midplanes), | |||
| nn.BatchNorm3d(planes) | |||
| ) | |||
| self.relu = nn.ReLU(inplace=True) | |||
| self.relu = nn.ReLU(inplace=False) | |||
| self.downsample = downsample | |||
| self.stride = stride | |||
| @@ -127,13 +127,13 @@ class Bottleneck(nn.Module): | |||
| self.conv1 = nn.Sequential( | |||
| nn.Conv3d(inplanes, planes, kernel_size=1, bias=False), | |||
| nn.BatchNorm3d(planes), | |||
| nn.ReLU(inplace=True) | |||
| nn.ReLU(inplace=False) | |||
| ) | |||
| # Second kernel | |||
| self.conv2 = nn.Sequential( | |||
| conv_builder(planes, planes, midplanes, stride), | |||
| nn.BatchNorm3d(planes), | |||
| nn.ReLU(inplace=True) | |||
| nn.ReLU(inplace=False) | |||
| ) | |||
| # 1x1x1 | |||
| @@ -141,7 +141,7 @@ class Bottleneck(nn.Module): | |||
| nn.Conv3d(planes, planes * self.expansion, kernel_size=1, bias=False), | |||
| nn.BatchNorm3d(planes * self.expansion) | |||
| ) | |||
| self.relu = nn.ReLU(inplace=True) | |||
| self.relu = nn.ReLU(inplace=False) | |||
| self.downsample = downsample | |||
| self.stride = stride | |||
| @@ -169,7 +169,7 @@ class BasicStem(nn.Sequential): | |||
| nn.Conv3d(3, 64, kernel_size=(3, 7, 7), stride=(1, 2, 2), | |||
| padding=(1, 3, 3), bias=False), | |||
| nn.BatchNorm3d(64), | |||
| nn.ReLU(inplace=True)) | |||
| nn.ReLU(inplace=False)) | |||
| class R2Plus1dStem(nn.Sequential): | |||
| @@ -181,12 +181,12 @@ class R2Plus1dStem(nn.Sequential): | |||
| stride=(1, 2, 2), padding=(0, 3, 3), | |||
| bias=False), | |||
| nn.BatchNorm3d(45), | |||
| nn.ReLU(inplace=True), | |||
| nn.ReLU(inplace=False), | |||
| nn.Conv3d(45, 64, kernel_size=(3, 1, 1), | |||
| stride=(1, 1, 1), padding=(1, 0, 0), | |||
| bias=False), | |||
| nn.BatchNorm3d(64), | |||
| nn.ReLU(inplace=True)) | |||
| nn.ReLU(inplace=False)) | |||
| class VideoResNet(nn.Module): | |||
+ 2
- 1
msadapter/torchvision/ops/roi_align.py
View File
| @@ -62,7 +62,8 @@ def roi_align( | |||
| roi_end_mode = 1 | |||
| if sampling_ratio <= 0: | |||
| # sampling_ratio = int(np.ceil(rois.shape[1] / output_size[1])) | |||
| # For a batch, the number of sampling_ratio corresponding to each index may be different, cannot be | |||
| # calculated uniformly by ``ceil(roi_width / output_width)``. | |||
| raise NotImplementedError("sampling_ratio is not supported negative number.") | |||
| roi_align = _get_cache_prim(ms.ops.ROIAlign)(output_size[0], output_size[1], float(spatial_scale), sampling_ratio, roi_end_mode) | |||
+ 8
- 0
msadapter/torchvision/transforms/transforms.py
View File
| @@ -98,16 +98,24 @@ class Compose: | |||
| self.transforms = transforms | |||
| def __call__(self, img): | |||
| # To accelerate the transform process, maintain the type `numpy.ndarray` or `PIL Image`, and if necessary, | |||
| # only convert to a tensor at the end. | |||
| return_tensor = False | |||
| for t in self.transforms: | |||
| if t.__class__.__name__ == "ToTensor": | |||
| return_tensor = True | |||
| img = ToTensorV2()(img) | |||
| elif t.__class__.__name__ == "PILToTensor": | |||
| return_tensor = True | |||
| img = PILToTensorV2()(img) | |||
| else: | |||
| img = t(img) | |||
| if _is_numpy(img) and _is_numpy_image(img): | |||
| img = img.transpose((2, 0, 1)) | |||
| if return_tensor: | |||
| img = torch.from_numpy(img) | |||
| return img | |||
| def __repr__(self) -> str: | |||
+ 61
- 1
msadapter/utils.py
View File
| @@ -14,7 +14,10 @@ INT32_MIN = -2147483648 | |||
| INT32_MAX = 2147483647 | |||
| INT64_MIN = -9223372036854775808 | |||
| INT64_MAX = 9223372036854775807 | |||
| FP64_MAX = 1.79869313e+308 | |||
| FP64_MIN = -1.79869313e+308 | |||
| FP32_MAX = 3.4028235e+38 | |||
| FP32_MIN = -3.4028235e+38 | |||
| def unsupported_attr(attr): | |||
| """ | |||
| @@ -59,6 +62,19 @@ def set_name_tuple(name): | |||
| def set_multiple_name_tuple(name, tags): | |||
| return collections.namedtuple(name, tags) | |||
| @_primexpr | |||
| def bitwise_adapter(input, other): | |||
| if (not isinstance(input, ms.Tensor)) and (not isinstance(other, ms.Tensor)): | |||
| raise ValueError("Expected at least one tensor argument in the inputs") | |||
| elif not isinstance(other, ms.Tensor): | |||
| other = ms.Tensor(other) | |||
| elif not isinstance(input, ms.Tensor): | |||
| input = ms.Tensor(input) | |||
| output_dtype = ms.numpy.result_type(input, other) | |||
| input = input.astype(ms.int32) | |||
| other = other.astype(ms.int32) | |||
| return input, other, output_dtype | |||
| _AscendGenernalConvertDict = { | |||
| ms.float64: ms.float32, | |||
| ms.int8: ms.float16, | |||
| @@ -137,3 +153,47 @@ def _get_ms_type(dtype): | |||
| if _to_dtype: | |||
| return _to_dtype | |||
| return dtype | |||
| @_primexpr | |||
| def promote_type_lookup(type1, type2): | |||
| _promoteTypesLookup = [[bool, ms.bool_, ms.uint8, ms.uint16, ms.uint32, ms.uint64, ms.int8, ms.int16, ms.int32, \ | |||
| ms.int64, int, ms.float16, ms.float32, float, ms.float64, complex, ms.complex64, ms.complex128], | |||
| [bool, ms.bool_, ms.uint8, ms.uint16, ms.uint32, ms.uint64, ms.int8, ms.int16, ms.int32, ms.int64, int, \ | |||
| ms.float16, ms.float32, float, ms.float64, complex, ms.complex64, ms.complex128], | |||
| [ms.uint8, ms.uint8, ms.uint8, ms.uint16, ms.uint32, ms.uint64, ms.int16, ms.int16, ms.int32, ms.int64, int, \ | |||
| ms.float16, ms.float32, float, ms.float64, complex, ms.complex64, ms.complex128], | |||
| [ms.uint16, ms.uint16, ms.uint16, ms.uint16, ms.uint32, ms.uint64, ms.int8, ms.int16, ms.int32, ms.int64, int, \ | |||
| ms.float16, ms.float32, float, ms.float64, complex, ms.complex64, ms.complex128], | |||
| [ms.uint32, ms.uint32, ms.uint32, ms.uint32, ms.uint32, ms.uint64, ms.int8, ms.int16, ms.int32, ms.int64, int, \ | |||
| ms.float16, ms.float32, float, ms.float64, complex, ms.complex64, ms.complex128], | |||
| [ms.uint64, ms.uint64, ms.uint64, ms.uint64, ms.uint64, ms.uint64, ms.int8, ms.int16, ms.int32, ms.int64, int, \ | |||
| ms.float16, ms.float32, float, ms.float64, complex, ms.complex64, ms.complex128], | |||
| [ms.int8, ms.int8, ms.int16, ms.int8, ms.int8, ms.int8, ms.int8, ms.int16, ms.int32, ms.int64, int, \ | |||
| ms.float16, ms.float32, float, ms.float64, complex, ms.complex64, ms.complex128], | |||
| [ms.int16, ms.int16, ms.int16, ms.int16, ms.int16, ms.int16, ms.int16, ms.int16, ms.int32, ms.int64, int, \ | |||
| ms.float16, ms.float32, float, ms.float64, complex, ms.complex64, ms.complex128], | |||
| [ms.int32, ms.int32, ms.int32, ms.int32, ms.int32, ms.int32, ms.int32, ms.int32, ms.int32, ms.int64, int, \ | |||
| ms.float16, ms.float32, float, ms.float64, complex, ms.complex64, ms.complex128], | |||
| [ms.int64, ms.int64, ms.int64, ms.int64, ms.int64, ms.int64, ms.int64, ms.int64, ms.int64, ms.int64, int, \ | |||
| ms.float16, ms.float32, float, ms.float64, complex, ms.complex64, ms.complex128], | |||
| [int, int, int, int, int, int, int, int, int, int, int, ms.float16, ms.float32, float, ms.float64, complex, \ | |||
| ms.complex64, ms.complex128], | |||
| [ms.float16, ms.float16, ms.float16, ms.float16, ms.float16, ms.float16, ms.float16, ms.float16, ms.float16, \ | |||
| ms.float16, ms.float16, ms.float16, ms.float32, float, ms.float64, complex, ms.complex64, ms.complex128], | |||
| [ms.float32, ms.float32, ms.float32, ms.float32, ms.float32, ms.float32, ms.float32, ms.float32, ms.float32, \ | |||
| ms.float32, ms.float32, ms.float32, ms.float32, float, ms.float64, complex, ms.complex64, ms.complex128], | |||
| [float, float, float, float, float, float, float, float, float, float, float, float, float, float, ms.float64, \ | |||
| complex, ms.complex64, ms.complex128], | |||
| [ms.float64, ms.float64, ms.float64, ms.float64, ms.float64, ms.float64, ms.float64, ms.float64, ms.float64, \ | |||
| ms.float64, ms.float64, ms.float64, ms.float64, ms.float64, ms.float64, complex, ms.complex128, ms.complex128], | |||
| [complex, complex, complex, complex, complex, complex, complex, complex, complex, complex, complex,complex, \ | |||
| complex, complex, ms.complex128, complex, ms.complex64, ms.complex128], | |||
| [ms.complex64, ms.complex64, ms.complex64, ms.complex64, ms.complex64, ms.complex64, ms.complex64, ms.complex64, \ | |||
| ms.complex64, ms.complex64, ms.complex64, ms.complex64, ms.complex64, ms.complex64, ms.complex128, ms.complex64, \ | |||
| ms.complex64, ms.complex128], | |||
| [ms.complex128, ms.complex128, ms.complex128, ms.complex128, ms.complex128, ms.complex128, ms.complex128, \ | |||
| ms.complex128, ms.complex128, ms.complex128, ms.complex128, ms.complex128, ms.complex128, ms.complex128, \ | |||
| ms.complex128, ms.complex128, ms.complex128, ms.complex128]] | |||
| type1_index = _promoteTypesLookup[0].index(type1) | |||
| type2_index = _promoteTypesLookup[0].index(type2) | |||
| return _promoteTypesLookup[type1_index][type2_index]; | |||
+ 305
- 0
testing/ut/pytorch/amp/test_grad_scaler.py
View File
| @@ -0,0 +1,305 @@ | |||
| import pickle | |||
| import numpy as np | |||
| import torch | |||
| import mindspore as ms | |||
| from mindspore import context | |||
| import msadapter.pytorch as ms_torch | |||
| from ...utils import set_mode_by_env_config, SKIP_ENV_GRAPH_MODE, param_compare, \ | |||
| SKIP_ENV_CPU, SKIP_ENV_ASCEND | |||
| set_mode_by_env_config() | |||
| @SKIP_ENV_CPU(reason="torch only support GradScaler on GPU.") | |||
| @SKIP_ENV_ASCEND(reason="torch only support GradScaler on GPU.") | |||
| @SKIP_ENV_GRAPH_MODE(reason="unscale_() not support in GraphMode") | |||
| def test_grad_scalar(): | |||
| _inputs = np.random.randn(3, 3).astype(np.float32) | |||
| _target = 2.0 | |||
| def torch_scaler(): | |||
| class Model(torch.nn.Module): | |||
| def __init__(self, *args, **kwargs): | |||
| super().__init__() | |||
| self.a = torch.nn.Parameter(torch.tensor(2.0).to(torch.float32)) | |||
| def forward(self, inputs): | |||
| return (inputs * self.a).sum() | |||
| class Cri(torch.nn.Module): | |||
| def forward(self, out, target): | |||
| return out - target | |||
| model = Model().cuda() | |||
| # model = Pt_Model() | |||
| critirion = Cri() | |||
| inputs = torch.tensor(_inputs).to("cuda") | |||
| target = torch.tensor(_target).to(torch.float32).to("cuda") | |||
| # inputs = torch.tensor(_inputs) | |||
| # target = torch.tensor(_target).to(torch.float32) | |||
| optimizer = torch.optim.SGD(model.parameters(), lr=0.1) | |||
| scaler = torch.cuda.amp.GradScaler(init_scale=2.**8, growth_factor=1.6, growth_interval=1) | |||
| # with torch.autocast(device_type="cpu", dtype=torch.bfloat16): | |||
| with torch.autocast(device_type="cuda", dtype=torch.float16): | |||
| out = model(inputs) | |||
| loss = critirion(out, target) | |||
| scaler.scale(loss).backward() | |||
| scaler.unscale_(optimizer) # unscale the gradients | |||
| scaler.step(optimizer) # optimizer.step() | |||
| scaler.update() # 更新scaler | |||
| pt_result = model.a.cpu().detach() | |||
| pt_scale = scaler.get_scale() | |||
| return pt_result, pt_scale | |||
| # adapter | |||
| def ms_scaler(): | |||
| class Model(ms_torch.nn.Module): | |||
| def __init__(self, *args, **kwargs): | |||
| super().__init__() | |||
| self.a = ms_torch.nn.Parameter(ms_torch.tensor(2.0).to(ms_torch.float32)) | |||
| def forward(self, inputs): | |||
| return (inputs * self.a).sum() | |||
| class Cri(ms_torch.nn.Module): | |||
| def forward(self, out, target): | |||
| return out - target | |||
| model = Model() | |||
| critirion = Cri() | |||
| inputs = ms_torch.tensor(_inputs) | |||
| target = ms_torch.tensor(_target).to(ms_torch.float32) | |||
| optimizer = ms_torch.optim.SGD(model.parameters(), lr=0.1) | |||
| scaler = ms_torch.cuda.amp.GradScaler(init_scale=2.**8, growth_factor=1.6, growth_interval=1) | |||
| class Net(ms_torch.nn.Module): | |||
| def __init__(self, model, critirion): | |||
| super().__init__() | |||
| self.model = model | |||
| self.critirion = critirion | |||
| def forward(self, inputs, target): | |||
| out = self.model(inputs) | |||
| loss = self.critirion(out, target) | |||
| return loss | |||
| net = Net(model, critirion) | |||
| net = ms.amp.auto_mixed_precision(net) | |||
| def func(inputs, target): | |||
| loss = net(inputs, target) | |||
| out = scaler.scale(loss) | |||
| return out | |||
| grad_fn = ms.ops.grad(func, None, net.trainable_params()) | |||
| grads = grad_fn(inputs, target) | |||
| scaler.unscale_(optimizer, grads) | |||
| scaler.step(optimizer, grads) | |||
| scaler.update() | |||
| ms_result = model.a.detach() | |||
| ms_scale = scaler.get_scale() | |||
| return ms_result, ms_scale | |||
| pt_result, pt_scale = torch_scaler() | |||
| ms_result, ms_scale = ms_scaler() | |||
| param_compare(pt_result, ms_result) | |||
| assert pt_scale == ms_scale | |||
| @SKIP_ENV_CPU(reason="torch only support GradScaler on GPU.") | |||
| @SKIP_ENV_ASCEND(reason="torch only support GradScaler on GPU.") | |||
| def test_get_scale(): | |||
| pt_scaler = torch.cuda.amp.GradScaler() | |||
| ms_scaler = ms_torch.cuda.amp.GradScaler() | |||
| assert pt_scaler.get_scale() == ms_scaler.get_scale() | |||
| assert pt_scaler.get_growth_factor() == ms_scaler.get_growth_factor() | |||
| assert pt_scaler.get_backoff_factor() == ms_scaler.get_backoff_factor() | |||
| assert pt_scaler.get_growth_interval() == ms_scaler.get_growth_interval() | |||
| pt_scaler.set_growth_factor(4.) | |||
| pt_scaler.set_backoff_factor(0.25) | |||
| pt_scaler.set_growth_interval(1000) | |||
| ms_scaler.set_growth_factor(4.) | |||
| ms_scaler.set_backoff_factor(0.25) | |||
| ms_scaler.set_growth_interval(1000) | |||
| assert pt_scaler.get_growth_factor() == ms_scaler.get_growth_factor() | |||
| assert pt_scaler.get_backoff_factor() == ms_scaler.get_backoff_factor() | |||
| assert pt_scaler.get_growth_interval() == ms_scaler.get_growth_interval() | |||
| @SKIP_ENV_CPU(reason="torch only support GradScaler on GPU.") | |||
| @SKIP_ENV_ASCEND(reason="torch only support GradScaler on GPU.") | |||
| def test_state_dict(): | |||
| pt_scaler = torch.cuda.amp.GradScaler(init_scale=2.**3, | |||
| growth_factor=5.0, | |||
| backoff_factor=0.1, | |||
| growth_interval=100,) | |||
| ms_scaler = ms_torch.cuda.amp.GradScaler() | |||
| pt_state = pt_scaler.state_dict() | |||
| pt_state['_growth_tracker'] = 2 | |||
| ms_scaler.load_state_dict(pt_state) | |||
| assert pt_scaler.get_scale() == ms_scaler.get_scale() | |||
| assert pt_scaler.get_growth_factor() == ms_scaler.get_growth_factor() | |||
| assert pt_scaler.get_backoff_factor() == ms_scaler.get_backoff_factor() | |||
| assert pt_scaler.get_growth_interval() == ms_scaler.get_growth_interval() | |||
| assert ms_scaler._get_growth_tracker() == 2 | |||
| def test_get_state_set_state(): | |||
| a = ms_torch.cuda.amp.GradScaler(3, 1.4, 0.2, 6) | |||
| data = pickle.dumps(a) | |||
| b = pickle.loads(data) | |||
| assert b.is_enabled() == a.is_enabled() | |||
| assert b.get_scale() == 3 | |||
| assert b.get_growth_factor() == 1.4 | |||
| assert b.get_backoff_factor() == 0.2 | |||
| assert b.get_growth_interval() == 6 | |||
| def test_grad_scaling_scale(): | |||
| scaler = ms_torch.cuda.amp.GradScaler(init_scale=2.) | |||
| t0 = ms_torch.full((1,), 4.0, dtype=ms_torch.float32) | |||
| t1 = ms_torch.full((1,), 4.0, dtype=ms_torch.float32) | |||
| # Create some nested iterables of tensors on different devices. | |||
| outputs = (t1.clone(), (t0.clone(), t1.clone()), [t0.clone(), (t1.clone(), t0.clone())]) | |||
| outputs = scaler.scale(outputs) | |||
| assert (outputs[0] == 8.0 and outputs[1][0] == 8.0 and outputs[1][1] == 8.0 and | |||
| outputs[2][0] == 8.0 and outputs[2][1][0] == 8.0 and outputs[2][1][1] == 8.0) | |||
| @SKIP_ENV_ASCEND(reason='torch.cuda.amp.GradScaler only support on GPU') | |||
| @SKIP_ENV_CPU(reason='torch.cuda.amp.GradScaler only support on GPU') | |||
| @SKIP_ENV_GRAPH_MODE(reason='scaler.unscale_ not support GRAPH_MODE') | |||
| def test_grad_inf_not_step(): | |||
| scaler = torch.cuda.amp.GradScaler(init_scale=2**5.) | |||
| _param1 = torch.nn.Parameter(torch.tensor(2.).to(torch.float32).to('cuda')) | |||
| _param2 = torch.nn.Parameter(torch.tensor(3.).to(torch.float32).to('cuda')) | |||
| _param = (_param1, _param2) | |||
| optimizer = torch.optim.SGD(_param, lr=0.3) | |||
| y = _param1 + _param2 | |||
| scaler.scale(y) | |||
| _param1.grad = torch.tensor(3333.).to(torch.float32).to('cuda') | |||
| _param2.grad = torch.tensor(np.inf).to(torch.float32).to('cuda') | |||
| scaler.unscale_(optimizer) | |||
| scaler.step(optimizer) | |||
| scaler.update() | |||
| pt_result1 = _param1.cpu().detach() | |||
| pt_result2 = _param2.cpu().detach() | |||
| pt_result_scale = scaler.get_scale() | |||
| scaler = ms_torch.cuda.amp.GradScaler(init_scale=2**5.) | |||
| _param1 = ms_torch.nn.Parameter(ms_torch.tensor(2.).to(ms_torch.float32).to('cuda')) | |||
| _param2 = ms_torch.nn.Parameter(ms_torch.tensor(3.).to(ms_torch.float32).to('cuda')) | |||
| _param = (_param1, _param2) | |||
| optimizer = ms_torch.optim.SGD(_param, lr=0.3) | |||
| y = _param1 + _param2 | |||
| scaler.scale(y) | |||
| grads = [ms_torch.tensor(3333.).to(ms_torch.float32).to('cuda'), | |||
| ms_torch.tensor(np.inf).to(ms_torch.float32).to('cuda')] | |||
| scaler.unscale_(optimizer, grads) | |||
| scaler.step(optimizer, grads) | |||
| scaler.update() | |||
| ms_result1 = _param1.cpu().detach() | |||
| ms_result2 = _param2.cpu().detach() | |||
| ms_result_scale = scaler.get_scale() | |||
| param_compare(pt_result1, ms_result1) # pt_result1 = 2 | |||
| param_compare(pt_result2, ms_result2) # pt_result2 = 3 | |||
| assert pt_result_scale == ms_result_scale # pt_result_scale = 16 | |||
| @SKIP_ENV_ASCEND(reason='torch.cuda.amp.GradScaler only support on GPU') | |||
| @SKIP_ENV_CPU(reason='torch.cuda.amp.GradScaler only support on GPU') | |||
| @SKIP_ENV_GRAPH_MODE(reason='scaler.unscale_ not support GRAPH_MODE') | |||
| def test_one_gradscaler_two_optimizer(): | |||
| scaler = torch.cuda.amp.GradScaler(init_scale=2**5.) | |||
| _param1 = torch.nn.Parameter(torch.tensor(2.).to(torch.float32).to('cuda')) | |||
| _param2 = torch.nn.Parameter(torch.tensor(3.).to(torch.float32).to('cuda')) | |||
| param1 = (_param1, _param2) | |||
| _param3 = torch.nn.Parameter(torch.tensor(2.).to(torch.float32).to('cuda')) | |||
| _param4 = torch.nn.Parameter(torch.tensor(3.).to(torch.float32).to('cuda')) | |||
| param2 = (_param3, _param4) | |||
| optimizer1 = torch.optim.SGD(param1, lr=0.3) | |||
| optimizer2 = torch.optim.Adam(param2, lr=0.1) | |||
| y1 = _param1 + _param2 | |||
| y2 = _param3 + _param4 | |||
| scaler.scale(y1) | |||
| scaler.scale(y2) | |||
| _param1.grad = torch.tensor(3333.).to(torch.float32).to('cuda') | |||
| _param2.grad = torch.tensor(np.inf).to(torch.float32).to('cuda') | |||
| _param3.grad = torch.tensor(3333.).to(torch.float32).to('cuda') | |||
| _param4.grad = torch.tensor(2222.).to(torch.float32).to('cuda') | |||
| scaler.unscale_(optimizer1) | |||
| scaler.unscale_(optimizer2) | |||
| scaler.step(optimizer1) | |||
| scaler.step(optimizer2) | |||
| scaler.update() | |||
| pt_result1 = _param1.cpu().detach() | |||
| pt_result2 = _param2.cpu().detach() | |||
| pt_result3 = _param3.cpu().detach() | |||
| pt_result4 = _param4.cpu().detach() | |||
| pt_result_scale = scaler.get_scale() | |||
| scaler = ms_torch.cuda.amp.GradScaler(init_scale=2**5.) | |||
| _param1 = ms_torch.nn.Parameter(ms_torch.tensor(2.).to(ms_torch.float32).to('cuda')) | |||
| _param2 = ms_torch.nn.Parameter(ms_torch.tensor(3.).to(ms_torch.float32).to('cuda')) | |||
| param1 = (_param1, _param2) | |||
| _param3 = ms_torch.nn.Parameter(ms_torch.tensor(2.).to(ms_torch.float32).to('cuda')) | |||
| _param4 = ms_torch.nn.Parameter(ms_torch.tensor(3.).to(ms_torch.float32).to('cuda')) | |||
| param2 = (_param3, _param4) | |||
| optimizer1 = ms_torch.optim.SGD(param1, lr=0.3) | |||
| optimizer2 = ms_torch.optim.Adam(param2, lr=0.1) | |||
| y1 = _param1 + _param2 | |||
| y2 = _param3 + _param4 | |||
| scaler.scale(y1) | |||
| scaler.scale(y2) | |||
| grads1 = [ms_torch.tensor(3333.).to(ms_torch.float32).to('cuda'), | |||
| ms_torch.tensor(np.inf).to(ms_torch.float32).to('cuda')] | |||
| grads2 = [ms_torch.tensor(3333.).to(ms_torch.float32).to('cuda'), | |||
| ms_torch.tensor(2222.).to(ms_torch.float32).to('cuda')] | |||
| scaler.unscale_(optimizer1, grads1) | |||
| scaler.unscale_(optimizer2, grads2) | |||
| scaler.step(optimizer1, grads1) | |||
| scaler.step(optimizer2, grads2) | |||
| scaler.update() | |||
| ms_result1 = _param1.cpu().detach() | |||
| ms_result2 = _param2.cpu().detach() | |||
| ms_result3 = _param3.cpu().detach() | |||
| ms_result4 = _param4.cpu().detach() | |||
| ms_result_scale = scaler.get_scale() | |||
| param_compare(pt_result1, ms_result1) # pt_result1 = 2 | |||
| param_compare(pt_result2, ms_result2) # pt_result2 = 3 | |||
| param_compare(pt_result3, ms_result3) # pt_result1 = 1.9 | |||
| param_compare(pt_result4, ms_result4) # pt_result2 = 2.9 | |||
| assert pt_result_scale == ms_result_scale # pt_result_scale = 16 | |||
| def test_gradscaler_disable(): | |||
| pt_scaler = torch.cuda.amp.GradScaler(enabled=False) | |||
| ms_scaler = ms_torch.cuda.amp.GradScaler(enabled=False) | |||
| pt_a = torch.tensor(2.) | |||
| ms_a = ms_torch.tensor(2.) | |||
| param_compare(pt_scaler.scale(pt_a), ms_scaler.scale(ms_a)) | |||
| assert pt_scaler.state_dict() == ms_scaler.state_dict() | |||
| pt_scaler.update() | |||
| ms_scaler.update() | |||
| assert pt_scaler.get_scale() == ms_scaler.get_scale() | |||
| if __name__ == '__main__': | |||
| test_grad_scalar() | |||
| test_get_scale() | |||
| test_state_dict() | |||
| test_get_state_set_state() | |||
| test_grad_scaling_scale() | |||
| test_grad_inf_not_step() | |||
| test_grad_scalar() | |||
| test_one_gradscaler_two_optimizer() | |||
| test_gradscaler_disable() | |||
+ 331
- 0
testing/ut/pytorch/autograd/test_functional.py
View File
| @@ -0,0 +1,331 @@ | |||
| import torch | |||
| import msadapter.pytorch as ms_torch | |||
| import numpy as np | |||
| from ...utils import set_mode_by_env_config, param_compare, SKIP_ENV_GRAPH_MODE, SKIP_ENV_PYNATIVE_MODE | |||
| import mindspore as ms | |||
| from msadapter.pytorch.tensor import cast_to_adapter_tensor | |||
| set_mode_by_env_config() | |||
| def test_vjp(): | |||
| data = np.random.randn(4, 4).astype(np.float32) | |||
| def exp_reducer(x): | |||
| return x.exp().sum(dim=1) | |||
| inputs = ms_torch.tensor(data) | |||
| v = ms_torch.ones(4) | |||
| ms_out, ms_vjp_out = ms_torch.autograd.functional.vjp(exp_reducer, inputs, v) | |||
| inputs = torch.tensor(data) | |||
| v = torch.ones(4) | |||
| torch_out, torch_vjp_out = torch.autograd.functional.vjp(exp_reducer, inputs, v) | |||
| param_compare(ms_out, torch_out) | |||
| param_compare(ms_vjp_out, torch_vjp_out) | |||
| def test_vjp_None(): | |||
| data = np.random.randn(4, 4).astype(np.float32) | |||
| def exp_reducer(x): | |||
| return x.exp().sum() | |||
| inputs = ms_torch.tensor(data) | |||
| ms_out, ms_vjp_out = ms_torch.autograd.functional.vjp(exp_reducer, inputs, None) | |||
| inputs = torch.tensor(data) | |||
| torch_out, torch_vjp_out = torch.autograd.functional.vjp(exp_reducer, inputs, None) | |||
| param_compare(ms_out, torch_out) | |||
| param_compare(ms_vjp_out, torch_vjp_out) | |||
| def test_vjp_None_jit(): | |||
| data = np.random.randn(4, 4).astype(np.float32) | |||
| def exp_reducer(x): | |||
| return x.exp().sum() | |||
| inputs = ms_torch.tensor(data) | |||
| @ms.jit | |||
| def func(inputs): | |||
| return ms_torch.autograd.functional.vjp(exp_reducer, inputs, None) | |||
| ms_out, ms_vjp_out = func(inputs) | |||
| inputs = torch.tensor(data) | |||
| torch_out, torch_vjp_out = torch.autograd.functional.vjp(exp_reducer, inputs, None) | |||
| param_compare(ms_out, torch_out) | |||
| param_compare(ms_vjp_out, torch_vjp_out) | |||
| @SKIP_ENV_GRAPH_MODE(reason="torch result not correct") | |||
| @SKIP_ENV_PYNATIVE_MODE(reason="torch result not correct") | |||
| def test_vjp_vjp(): | |||
| data = np.random.randn(4, 4).astype(np.float32) | |||
| def exp_reducer(x): | |||
| return x.sum(1) | |||
| inputs = torch.tensor(data) | |||
| v = torch.ones(4) | |||
| _, torch_vjp_out = torch.autograd.functional.vjp(exp_reducer, inputs, v, create_graph=True) | |||
| _, pt_out = torch.autograd.functional.vjp(exp_reducer, torch_vjp_out, v) | |||
| inputs = ms_torch.tensor(data) | |||
| v = ms_torch.ones(4) | |||
| def exp_reducer_wrap(inputs): | |||
| _, ms_vjp_out = ms_torch.autograd.functional.vjp(exp_reducer, inputs, v, create_graph=True) | |||
| return exp_reducer(ms_vjp_out) | |||
| _, ms_vjp_out = ms_torch.autograd.functional.vjp(exp_reducer_wrap, inputs, v) | |||
| param_compare(pt_out, ms_vjp_out) | |||
| def test_vjp_2_input(): | |||
| data1 = np.random.randn(4, 4).astype(np.float32) | |||
| data2 = np.random.randn(4, 4).astype(np.float32) | |||
| def exp_reducer(x1, x2): | |||
| return x1.exp().sum(dim=1) + x2.exp().sum(dim=1) | |||
| inputs = (torch.tensor(data1), torch.tensor(data2)) | |||
| v = torch.ones(4) | |||
| torch_out, torch_vjp_out = torch.autograd.functional.vjp(exp_reducer, inputs, v) | |||
| inputs = (ms_torch.tensor(data1), ms_torch.tensor(data2)) | |||
| v = ms_torch.ones(4) | |||
| ms_out, ms_vjp_out = ms_torch.autograd.functional.vjp(exp_reducer, inputs, v) | |||
| param_compare(ms_out, torch_out) | |||
| param_compare(ms_vjp_out, torch_vjp_out) | |||
| def test_vjp_2_output(): | |||
| data1 = np.random.randn(4, 4).astype(np.float32) | |||
| data2 = np.random.randn(4, 4).astype(np.float32) | |||
| def exp_reducer(x1, x2): | |||
| return x1.exp().sum(dim=1), x2.exp().sum(dim=1) | |||
| inputs = (torch.tensor(data1), torch.tensor(data2)) | |||
| v = (torch.ones(4), torch.ones(4)) | |||
| torch_out, torch_vjp_out = torch.autograd.functional.vjp(exp_reducer, inputs, v) | |||
| inputs = (ms_torch.tensor(data1), ms_torch.tensor(data2)) | |||
| v = (ms_torch.ones(4), ms_torch.ones(4)) | |||
| ms_out, ms_vjp_out = ms_torch.autograd.functional.vjp(exp_reducer, inputs, v) | |||
| param_compare(ms_out, torch_out) | |||
| param_compare(ms_vjp_out, torch_vjp_out) | |||
| def test_jvp(): | |||
| data = np.random.randn(4, 4).astype(np.float32) | |||
| def exp_reducer(x): | |||
| return x.exp().sum(dim=1) | |||
| inputs = ms_torch.tensor(data) | |||
| v = ms_torch.ones(4, 4) | |||
| ms_out, ms_jvp_out = ms_torch.autograd.functional.jvp(exp_reducer, inputs, v) | |||
| inputs = torch.tensor(data) | |||
| v = torch.ones(4, 4) | |||
| torch_out, torch_jvp_out = torch.autograd.functional.jvp(exp_reducer, inputs, v) | |||
| param_compare(ms_out, torch_out) | |||
| param_compare(ms_jvp_out, torch_jvp_out) | |||
| def test_jvp_jit(): | |||
| data = np.random.randn(4, 4).astype(np.float32) | |||
| def exp_reducer(x): | |||
| return x.exp().sum(dim=1) | |||
| inputs = ms_torch.tensor(data) | |||
| v = ms_torch.ones(4, 4) | |||
| @ms.jit | |||
| def func(inputs, v): | |||
| return ms_torch.autograd.functional.jvp(exp_reducer, inputs, v) | |||
| ms_out, ms_jvp_out = func(inputs, v) | |||
| inputs = torch.tensor(data) | |||
| v = torch.ones(4, 4) | |||
| torch_out, torch_jvp_out = torch.autograd.functional.jvp(exp_reducer, inputs, v) | |||
| param_compare(ms_out, torch_out) | |||
| param_compare(ms_jvp_out, torch_jvp_out) | |||
| def test_jvp_v_None(): | |||
| data = np.random.randn(1).astype(np.float32) | |||
| def exp_reducer(x): | |||
| return x.exp().sum() | |||
| inputs = ms_torch.tensor(data) | |||
| ms_out, ms_jvp_out = ms_torch.autograd.functional.jvp(exp_reducer, inputs, None) | |||
| inputs = torch.tensor(data) | |||
| torch_out, torch_jvp_out = torch.autograd.functional.jvp(exp_reducer, inputs, None) | |||
| param_compare(ms_out, torch_out) | |||
| param_compare(ms_jvp_out, torch_jvp_out) | |||
| def test_jvp_2_input(): | |||
| data1 = np.random.randn(4, 4).astype(np.float32) | |||
| data2 = np.random.randn(4, 4).astype(np.float32) | |||
| def exp_reducer(x1, x2): | |||
| return x1.exp().sum(dim=1) + x2.exp().sum(dim=1) | |||
| inputs = (torch.tensor(data1), torch.tensor(data2)) | |||
| v = torch.ones(4, 4) | |||
| torch_out, torch_vjp_out = torch.autograd.functional.jvp(exp_reducer, inputs, (v, v)) | |||
| inputs = (ms_torch.tensor(data1), ms_torch.tensor(data2)) | |||
| v = ms_torch.ones(4, 4) | |||
| ms_out, ms_vjp_out = ms_torch.autograd.functional.jvp(exp_reducer, inputs, (v, v)) | |||
| param_compare(ms_out, torch_out) | |||
| param_compare(ms_vjp_out, torch_vjp_out) | |||
| def test_jvp_2_output(): | |||
| data1 = np.random.randn(4, 4).astype(np.float32) | |||
| data2 = np.random.randn(4, 4).astype(np.float32) | |||
| def exp_reducer(x1, x2): | |||
| return x1.exp().sum(dim=1), x2.exp().sum(dim=1) | |||
| inputs = (torch.tensor(data1), torch.tensor(data2)) | |||
| v = (torch.ones(4, 4), torch.ones(4, 4)) | |||
| torch_out, torch_jvp_out = torch.autograd.functional.jvp(exp_reducer, inputs, v) | |||
| inputs = (ms_torch.tensor(data1), ms_torch.tensor(data2)) | |||
| v = (ms_torch.ones(4, 4), ms_torch.ones(4, 4)) | |||
| ms_out, ms_jvp_out = ms_torch.autograd.functional.jvp(exp_reducer, inputs, v) | |||
| param_compare(ms_out, torch_out) | |||
| param_compare(ms_jvp_out, torch_jvp_out) | |||
| def test_jacobian_reverse_mode(): | |||
| data1 = np.random.randn(2, 2).astype(np.float32) | |||
| data2 = np.random.randn(2, 2).astype(np.float32) | |||
| def exp_reducer(x, x2): | |||
| return x.exp().mean(1) + x2.exp().mean(1) | |||
| inputs1 = torch.tensor(data1, requires_grad=True) | |||
| inputs2 = torch.tensor(data2, requires_grad=True) | |||
| pt_j1, pt_j2 = torch.autograd.functional.jacobian(exp_reducer, (inputs1, inputs2)) | |||
| inputs1 = ms_torch.tensor(data1, requires_grad=True) | |||
| inputs2 = ms_torch.tensor(data2, requires_grad=True) | |||
| ms_j1, ms_j2 = ms_torch.autograd.functional.jacobian(exp_reducer, (inputs1, inputs2)) | |||
| param_compare(pt_j1, ms_j1) | |||
| param_compare(pt_j2, ms_j2) | |||
| def test_jacobian_reverse_mode_2_input_2_output(): | |||
| data1 = np.random.randn(2, 2).astype(np.float32) | |||
| data2 = np.random.randn(2, 2).astype(np.float32) | |||
| def exp_reducer(x, x2): | |||
| return x.exp().mean(1), x2.exp().mean(1) | |||
| inputs1 = torch.tensor(data1, requires_grad=True) | |||
| inputs2 = torch.tensor(data2, requires_grad=True) | |||
| pt_j1, pt_j2 = torch.autograd.functional.jacobian(exp_reducer, (inputs1, inputs2)) | |||
| inputs1 = ms_torch.tensor(data1, requires_grad=True) | |||
| inputs2 = ms_torch.tensor(data2, requires_grad=True) | |||
| ms_j1, ms_j2 = ms_torch.autograd.functional.jacobian(exp_reducer, (inputs1, inputs2)) | |||
| param_compare(pt_j1, ms_j1) | |||
| param_compare(pt_j2, ms_j2) | |||
| @SKIP_ENV_GRAPH_MODE(reason="RuntimeError: The pointer[abs] is null.") | |||
| def test_jacobian_reverse_mode_jit(): | |||
| # ms.set_context(save_graphs=2, save_graphs_path='./ir') | |||
| data1 = np.random.randn(2, 2).astype(np.float32) | |||
| data2 = np.random.randn(2, 2).astype(np.float32) | |||
| def exp_reducer(x, x2): | |||
| return x.exp().mean(1) + x2.exp().mean(1) | |||
| inputs1 = torch.tensor(data1, requires_grad=True) | |||
| inputs2 = torch.tensor(data2, requires_grad=True) | |||
| pt_j1, pt_j2 = torch.autograd.functional.jacobian(exp_reducer, (inputs1, inputs2)) | |||
| inputs1 = ms_torch.tensor(data1, requires_grad=True) | |||
| inputs2 = ms_torch.tensor(data2, requires_grad=True) | |||
| @ms.jit | |||
| def func(inputs): | |||
| return ms_torch.autograd.functional.jacobian(exp_reducer, inputs) | |||
| ms_j1, ms_j2 = func((inputs1, inputs2)) | |||
| param_compare(pt_j1, ms_j1) | |||
| param_compare(pt_j2, ms_j2) | |||
| def test_jacobian_forward_mode(): | |||
| data1 = np.random.randn(2, 2).astype(np.float32) | |||
| data2 = np.random.randn(2, 2).astype(np.float32) | |||
| def exp_reducer(x, x2): | |||
| return x.exp().mean(1) + x2.exp().mean(1) | |||
| inputs1 = torch.tensor(data1, requires_grad=True) | |||
| inputs2 = torch.tensor(data2, requires_grad=True) | |||
| pt_j1, pt_j2 = torch.autograd.functional.jacobian( | |||
| exp_reducer, (inputs1, inputs2), vectorize=True, strategy="forward-mode") | |||
| inputs1 = ms_torch.tensor(data1, requires_grad=True) | |||
| inputs2 = ms_torch.tensor(data2, requires_grad=True) | |||
| ms_j1, ms_j2 = ms_torch.autograd.functional.jacobian( | |||
| exp_reducer, (inputs1, inputs2), vectorize=True, strategy="forward-mode") | |||
| param_compare(pt_j1.detach(), ms_j1) | |||
| param_compare(pt_j2.detach(), ms_j2) | |||
| @SKIP_ENV_GRAPH_MODE(reason="second_grad compile raise 'The pointer[abs] is null'") | |||
| def test_jacobian_second_grad(): | |||
| data1 = np.random.randn(2, 2).astype(np.float32) | |||
| data2 = np.random.randn(2, 2).astype(np.float32) | |||
| def exp_reducer(x, x2): | |||
| return x.exp().mean(1) + x2.exp().mean(1) | |||
| inputs1 = torch.tensor(data1, requires_grad=True) | |||
| inputs2 = torch.tensor(data2, requires_grad=True) | |||
| pt_j1, pt_j2 = torch.autograd.functional.jacobian(exp_reducer, (inputs1, inputs2), create_graph=True) | |||
| pt_j1 = pt_j1.sum() | |||
| pt_j2 = pt_j2.sum() | |||
| pt_j1.backward() | |||
| pt_j2.backward() | |||
| pt_grads1 = inputs1.grad | |||
| pt_grads2 = inputs2.grad | |||
| inputs1 = ms_torch.tensor(data1, requires_grad=True) | |||
| inputs2 = ms_torch.tensor(data2, requires_grad=True) | |||
| def func(input1, input2): | |||
| ms_j1, ms_j2 = ms_torch.autograd.functional.jacobian(exp_reducer, (input1, input2)) | |||
| return ms_j1.sum(), ms_j2.sum() | |||
| ms_grad1, ms_grad2 = ms.ops.grad(func, grad_position=(0, 1))(inputs1, inputs2) | |||
| param_compare(pt_grads1, ms_grad1) | |||
| param_compare(pt_grads2, ms_grad2) | |||
| if __name__ == '__main__': | |||
| test_vjp() | |||
| test_vjp_vjp() | |||
| test_vjp_None() | |||
| test_vjp_2_input() | |||
| test_vjp_2_output() | |||
| test_vjp_None_jit() | |||
| test_jvp() | |||
| test_jvp_v_None() | |||
| test_jvp_2_input() | |||
| test_jvp_2_output() | |||
| test_jvp_jit() | |||
| test_jacobian_reverse_mode() | |||
| test_jacobian_second_grad() | |||
| test_jacobian_forward_mode() | |||
| test_jacobian_reverse_mode_jit() | |||
+ 320
- 0
testing/ut/pytorch/autograd/test_grad_mode.py
View File
| @@ -0,0 +1,320 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import torch | |||
| import mindspore as ms | |||
| import msadapter.pytorch as ms_torch | |||
| from ...utils import set_mode_by_env_config, param_compare, SKIP_ENV_GRAPH_MODE, SKIP_ENV_PYNATIVE_MODE | |||
| set_mode_by_env_config() | |||
| ''' | |||
| # requires_grad is currently not effective. | |||
| def test_no_grad1(): | |||
| x = torch.tensor([1.], requires_grad=True) | |||
| with torch.no_grad(): | |||
| y = x * 2 | |||
| assert y.requires_grad == False | |||
| @torch.no_grad() | |||
| def doubler(x): | |||
| return x * 2 | |||
| z = doubler(x) | |||
| assert z.requires_grad == False | |||
| ''' | |||
| def adapter_no_grad(): | |||
| @ms_torch.no_grad() | |||
| def doubler(x): | |||
| return x * 2 | |||
| class Net(ms_torch.nn.Module): | |||
| def __init__(self): | |||
| super(Net, self).__init__() | |||
| def forward(self, x, y, z): | |||
| y = doubler(y) | |||
| with ms_torch.no_grad(): | |||
| z = z * 2 | |||
| out = ms_torch.matmul(x, y) + z | |||
| return out | |||
| x = ms_torch.tensor([[0.5, 0.6, 0.4]], dtype=ms_torch.float32) | |||
| y = ms_torch.tensor([[0.01], [0.2], [3.3]], dtype=ms_torch.float32) | |||
| z = ms_torch.tensor([[0.01]], dtype=ms_torch.float32, requires_grad=True) | |||
| net = Net() | |||
| out = net(x, y, z) | |||
| grad_out = ms.grad(net, grad_position=(0, 1, 2))(x, y, z) | |||
| return out, grad_out | |||
| def torch_no_grad(): | |||
| @torch.no_grad() | |||
| def doubler(x): | |||
| return x * 2 | |||
| class Net(torch.nn.Module): | |||
| def __init__(self): | |||
| super(Net, self).__init__() | |||
| def forward(self, x, y, z): | |||
| y = doubler(y) | |||
| with torch.no_grad(): | |||
| z = z * 2 | |||
| result = torch.matmul(x, y) + z | |||
| return result | |||
| x = torch.tensor([[0.5, 0.6, 0.4]], dtype=torch.float32, requires_grad=True) | |||
| y = torch.tensor([[0.01], [0.2], [3.3]], dtype=torch.float32, requires_grad=True) | |||
| z = torch.tensor([[0.01]], dtype=torch.float32, requires_grad=True) | |||
| out = Net()(x, y, z) | |||
| out.backward() | |||
| grad_out = x.grad, y.grad, z.grad | |||
| return out, grad_out | |||
| @SKIP_ENV_GRAPH_MODE(reason="no_grad only support on pynative mode.") | |||
| def test_no_grad(): | |||
| ms_out, ms_grad_out = adapter_no_grad() | |||
| pt_out, pt_grad_out = torch_no_grad() | |||
| param_compare(ms_out, pt_out.detach()) | |||
| param_compare(ms_grad_out[0], pt_grad_out[0].detach()) | |||
| param_compare(ms_grad_out[1], ms_torch.zeros_like(ms_grad_out[1])) | |||
| param_compare(ms_grad_out[2], ms_torch.zeros_like(ms_grad_out[2])) | |||
| @SKIP_ENV_GRAPH_MODE(reason="enable_grad grad only support on pynative mode.") | |||
| def test_enbale_grad_func(): | |||
| @ms_torch.enable_grad() | |||
| def ms_doubler(input): | |||
| return input * 2 | |||
| def ms_func(input1): | |||
| with ms_torch.no_grad(): | |||
| with ms_torch.enable_grad(): | |||
| a = input1 ** 2 | |||
| a = ms_doubler(a) | |||
| with ms_torch.enable_grad(): | |||
| a = ms_torch.mean(a) | |||
| return a | |||
| input1 = ms_torch.tensor([2, 3.], requires_grad=True).to(ms_torch.float32) | |||
| ms_out, ms_grads = ms.ops.value_and_grad(ms_func, grad_position=0)(input1) | |||
| @torch.enable_grad() | |||
| def torch_doubler(input): | |||
| return input * 2 | |||
| def torch_func(input1): | |||
| with torch.no_grad(): | |||
| with torch.enable_grad(): | |||
| a = input1 ** 2 | |||
| a = torch_doubler(a) | |||
| with torch.enable_grad(): | |||
| a = torch.mean(a) | |||
| return a | |||
| input1 = torch.tensor([2, 3.], requires_grad=True).to(torch.float32) | |||
| pt_out = torch_func(input1) | |||
| pt_out.backward() | |||
| pt_grads = input1.grad | |||
| param_compare(ms_out, pt_out.detach()) | |||
| param_compare(ms_grads, pt_grads.detach()) | |||
| @SKIP_ENV_GRAPH_MODE(reason="set_grad_enable grad only support on pynative mode.") | |||
| def test_set_grad_enable_func(): | |||
| def ms_torch_func(input1, input2, input3): | |||
| input1 = input1 ** 2 | |||
| with ms_torch.set_grad_enabled(False): | |||
| input2 = input2 * 2 | |||
| _ = ms_torch.set_grad_enabled(False) | |||
| input3 = input3 * 2 | |||
| _ = ms_torch.set_grad_enabled(True) | |||
| result = input1 + input2 + input3 | |||
| result = ms_torch.mean(result) | |||
| return result | |||
| input1 = ms_torch.tensor([1, 2.], requires_grad=True).to(ms_torch.float32) | |||
| input2 = ms_torch.tensor([3, 4.], requires_grad=True).to(ms_torch.float32) | |||
| input3 = ms_torch.tensor([5, 6.], requires_grad=True).to(ms_torch.float32) | |||
| ms_out, ms_grad_out = ms.ops.value_and_grad(ms_torch_func, (0, 1, 2))(input1, input2, input3) | |||
| def torch_func(input1, input2, input3): | |||
| input1 = input1 ** 2 | |||
| with torch.set_grad_enabled(False): | |||
| input2 = input2 * 2 | |||
| _ = torch.set_grad_enabled(False) | |||
| input3 = input3 * 2 | |||
| _ = torch.set_grad_enabled(True) | |||
| result = input1 + input2 + input3 | |||
| result = torch.mean(result) | |||
| return result | |||
| input1 = torch.tensor([1, 2.], requires_grad=True).to(torch.float32) | |||
| input2 = torch.tensor([3, 4.], requires_grad=True).to(torch.float32) | |||
| input3 = torch.tensor([5, 6.], requires_grad=True).to(torch.float32) | |||
| pt_out = torch_func(input1, input2, input3) | |||
| pt_out.backward() | |||
| pt_grad_out = input1.grad | |||
| param_compare(ms_out, pt_out.detach()) | |||
| param_compare(ms_grad_out[0], pt_grad_out.detach()) | |||
| param_compare(ms_grad_out[1], ms_torch.zeros_like(ms_grad_out[1])) | |||
| param_compare(ms_grad_out[2], ms_torch.zeros_like(ms_grad_out[2])) | |||
| @SKIP_ENV_GRAPH_MODE(reason="tensor.require_grad not actually support yet") | |||
| @SKIP_ENV_PYNATIVE_MODE(reason="tensor.require_grad not actually support yet") | |||
| def test_require_grad(): | |||
| a = torch.tensor(2.).to(torch.float32) | |||
| b = torch.tensor(3.).to(torch.float32) | |||
| d = torch.tensor(4.).to(torch.float32) | |||
| d.requires_grad = True | |||
| c = a * b | |||
| pt_ret_1 = c.requires_grad # pt_ret_1 = False | |||
| c = c * b | |||
| pt_ret_2 = c.requires_grad # pt_ret_2 = False | |||
| c = c + d | |||
| pt_ret_3 = c.requires_grad # pt_ret_3 = True | |||
| a = ms_torch.tensor(2.).to(ms_torch.float32) | |||
| b = ms_torch.tensor(3.).to(ms_torch.float32) | |||
| d = ms_torch.tensor(4.).to(ms_torch.float32) | |||
| d.requires_grad = True | |||
| c = a * b | |||
| ms_ret_1 = c.requires_grad | |||
| c = c * b | |||
| ms_ret_2 = c.requires_grad | |||
| c = c + d | |||
| ms_ret_3 = c.requires_grad | |||
| assert pt_ret_1 == ms_ret_1 | |||
| assert pt_ret_2 == ms_ret_2 | |||
| assert pt_ret_3 == ms_ret_3 | |||
| @SKIP_ENV_GRAPH_MODE(reason="tensor.detach_() not support under graph-mode") | |||
| def test_detach_(): | |||
| a = torch.tensor(1.).to(torch.float32) | |||
| a.requires_grad = True | |||
| b = torch.tensor(2.).to(torch.float32) | |||
| b.requires_grad = True | |||
| c = a ** 2 | |||
| c = c * b | |||
| c.detach_() | |||
| d = c + a | |||
| d.backward() | |||
| pt_grad_0 = a.grad.detach() | |||
| a = ms_torch.tensor(1.).to(ms_torch.float32) | |||
| a.requires_grad = True | |||
| b = ms_torch.tensor(2.).to(ms_torch.float32) | |||
| b.requires_grad = True | |||
| def func(a, b): | |||
| c = a ** 2 | |||
| c = c * b | |||
| c.detach_() | |||
| d = c + a | |||
| return d | |||
| ms_grads = ms.ops.grad(func, (0, 1))(a, b) | |||
| param_compare(pt_grad_0, ms_grads[0]) | |||
| param_compare(ms_grads[1], ms_torch.zeros_like(ms_grads[1])) | |||
| @SKIP_ENV_GRAPH_MODE(reason="tensor.fill_ not support graph mode") | |||
| def test_parameter_data_grad(): | |||
| a = torch.nn.Parameter(torch.tensor(1.)) | |||
| a.data.fill_(2.) | |||
| c = a * 3 | |||
| c.backward() | |||
| pt_grad = a.grad.detach() | |||
| a = ms_torch.nn.Parameter(ms_torch.tensor(1.)) | |||
| a.data.fill_(2.) | |||
| def func(x): | |||
| return x * 3 | |||
| ms_grads = ms.ops.grad(func)(a) | |||
| param_compare(pt_grad, ms_grads) | |||
| @SKIP_ENV_GRAPH_MODE(reason="is_grad_enabled not support graph mode") | |||
| def test_is_grad_enable(): | |||
| @ms_torch.no_grad() | |||
| class Foo(): | |||
| def __init__(self): | |||
| assert not ms_torch.is_grad_enabled() | |||
| def foo(self): | |||
| # Not applied to methods | |||
| assert ms_torch.is_grad_enabled() | |||
| # Show that we can actually construct the class | |||
| foo = Foo() | |||
| foo.foo() | |||
| @SKIP_ENV_GRAPH_MODE(reason="is_grad_enabled not support graph mode") | |||
| def test_is_grad_enable_nested(): | |||
| x = ms_torch.randn([3, 4]) | |||
| before = ms_torch.is_grad_enabled() | |||
| with ms_torch.set_grad_enabled(False): | |||
| with ms_torch.set_grad_enabled(True): | |||
| x = ms_torch.mul(x, 5) | |||
| x = ms_torch.sqrt(x) | |||
| assert ms_torch.is_grad_enabled() | |||
| assert not ms_torch.is_grad_enabled() | |||
| assert ms_torch.is_grad_enabled() == before | |||
| return x | |||
| @SKIP_ENV_GRAPH_MODE(reason="inference_mode not support graph mode") | |||
| def test_inference_mode_context_manager(): | |||
| with ms_torch.inference_mode(): | |||
| assert ms_torch.is_inference_mode_enabled() | |||
| with ms_torch.inference_mode(False): | |||
| assert not ms_torch.is_inference_mode_enabled() | |||
| assert ms_torch.is_inference_mode_enabled() | |||
| assert not ms_torch.is_inference_mode_enabled() | |||
| @SKIP_ENV_GRAPH_MODE(reason="inference_mode not support graph mode") | |||
| def test_inference_mode_decorator(): | |||
| for mode in (True, False): | |||
| @ms_torch.inference_mode(mode) | |||
| def ms_func(x): | |||
| assert ms_torch.is_inference_mode_enabled() == mode | |||
| return x * x | |||
| x = ms_torch.tensor(2., requires_grad=True).to(ms_torch.float32) | |||
| ms_result = ms.ops.grad(ms_func)(x) | |||
| @torch.inference_mode(mode) | |||
| def torch_func(x): | |||
| assert torch.is_inference_mode_enabled() == mode | |||
| return x * x | |||
| x = torch.tensor(2., requires_grad=True).to(torch.float32) | |||
| y = torch_func(x) | |||
| if not mode: | |||
| y.backward() | |||
| pt_result = x.grad | |||
| param_compare(ms_result, pt_result) | |||
| else: | |||
| param_compare(ms_result, ms.ops.zeros_like(ms_result)) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
| test_no_grad() | |||
| test_enbale_grad_func() | |||
| test_set_grad_enable_func() | |||
| test_detach_() | |||
| test_parameter_data_grad() | |||
| test_is_grad_enable() | |||
| test_is_grad_enable_nested() | |||
| test_inference_mode_context_manager() | |||
| test_inference_mode_decorator() | |||
+ 63
- 62
testing/ut/pytorch/data/test_dataloader.py
View File
| @@ -26,7 +26,6 @@ from msadapter.pytorch.utils.data import ( | |||
| _utils | |||
| ) | |||
| import msadapter.pytorch as torch | |||
| import mindspore as ms | |||
| from msadapter.pytorch._utils import ExceptionWrapper | |||
| from msadapter.pytorch.utils.data.dataset import random_split | |||
| @@ -126,19 +125,20 @@ def test_splits_are_mutually_exclusive(): | |||
| all_values.sort() | |||
| assert np.allclose(data, all_values) | |||
| def test_splits_indexing_type(): | |||
| class CustomDataset(): | |||
| def __init__(self, custom_list): | |||
| self.data = custom_list | |||
| class CustomDataset(): | |||
| def __init__(self, custom_list): | |||
| self.data = custom_list | |||
| def __getitem__(self, key): | |||
| if type(key) == type(0): | |||
| return self.data[key] | |||
| else: | |||
| raise TypeError("Type do not match.") | |||
| def __getitem__(self, key): | |||
| if type(key) == type(0): | |||
| return self.data[key] | |||
| else: | |||
| raise TypeError("Type do not match.") | |||
| def __len__(self): | |||
| return len(self.data) | |||
| def __len__(self): | |||
| return len(self.data) | |||
| def test_splits_indexing_type(): | |||
| x = [1, 2, 3, 4, 5] | |||
| dataset = CustomDataset(x) | |||
| @@ -159,30 +159,30 @@ def test_slicing_of_subset_of_dataset(): | |||
| # Testing slicing a subset initialized with a dataset | |||
| dataset = TensorDataset(torch.tensor([1, 2, 3, 4, 5])) | |||
| subset_of_dataset = Subset(dataset, [0, 1, 2, 3, 4]) | |||
| assert np.allclose(subset_of_dataset[:][0].asnumpy(), dataset[:][0].asnumpy()) | |||
| assert np.allclose(subset_of_dataset[1:2][0].asnumpy(), dataset[1:2][0].asnumpy()) | |||
| assert np.allclose(subset_of_dataset[0:-1:2][0].asnumpy(), dataset[0:-1:2][0].asnumpy()) | |||
| assert np.allclose(subset_of_dataset[:][0], dataset[:][0]) | |||
| assert np.allclose(subset_of_dataset[1:2][0], dataset[1:2][0]) | |||
| assert np.allclose(subset_of_dataset[0:-1:2][0], dataset[0:-1:2][0]) | |||
| # Testing slicing of subset from random split | |||
| subset1, subset2 = random_split(dataset, [3, 2]) | |||
| assert np.allclose(subset1[:][0].asnumpy(), dataset[subset1.indices[:]][0].asnumpy()) | |||
| assert np.allclose(subset1[0:2][0].asnumpy(), dataset[subset1.indices[0:2]][0].asnumpy()) | |||
| assert np.allclose(subset1[0:-1:2][0].asnumpy(), dataset[subset1.indices[0:-1:2]][0].asnumpy()) | |||
| assert np.allclose(subset1[:][0], dataset[subset1.indices[:]][0]) | |||
| assert np.allclose(subset1[0:2][0], dataset[subset1.indices[0:2]][0]) | |||
| assert np.allclose(subset1[0:-1:2][0], dataset[subset1.indices[0:-1:2]][0]) | |||
| def test_slicing_of_subset_of_subset(): | |||
| # Testing slicing a subset initialized with a subset | |||
| dataset = TensorDataset(torch.tensor([1, 2, 3, 4, 5])) | |||
| subset_of_dataset = Subset(dataset, [0, 1, 2, 3, 4]) | |||
| subset_of_subset = Subset(subset_of_dataset, [0, 1, 2, 3, 4]) | |||
| assert np.allclose(subset_of_subset[:][0].asnumpy(), dataset[:][0].asnumpy()) | |||
| assert np.allclose(subset_of_subset[0:2][0].asnumpy(), dataset[0:2][0].asnumpy()) | |||
| assert np.allclose(subset_of_subset[0:-1:2][0].asnumpy(), dataset[0:-1:2][0].asnumpy()) | |||
| assert np.allclose(subset_of_subset[:][0], dataset[:][0]) | |||
| assert np.allclose(subset_of_subset[0:2][0], dataset[0:2][0]) | |||
| assert np.allclose(subset_of_subset[0:-1:2][0], dataset[0:-1:2][0]) | |||
| # Testing slicing of subset of subset from random split | |||
| subset1, subset2 = random_split(dataset, [4, 1]) | |||
| subset_of_subset1, subset_of_subset2 = random_split(subset1, [3, 1]) | |||
| idx = [subset1.indices[i] for i in subset_of_subset1.indices] | |||
| assert np.allclose(subset_of_subset1[:][0].asnumpy(), dataset[idx[:]][0].asnumpy()) | |||
| assert np.allclose(subset_of_subset1[0:2][0].asnumpy(), dataset[idx[0:2]][0].asnumpy()) | |||
| assert np.allclose(subset_of_subset1[0:-1:2][0].asnumpy(), dataset[idx[0:-1:2]][0].asnumpy()) | |||
| assert np.allclose(subset_of_subset1[:][0], dataset[idx[:]][0]) | |||
| assert np.allclose(subset_of_subset1[0:2][0], dataset[idx[0:2]][0]) | |||
| assert np.allclose(subset_of_subset1[0:-1:2][0], dataset[idx[0:-1:2]][0]) | |||
| class CountingDataset(Dataset): | |||
| def __init__(self, n): | |||
| @@ -218,23 +218,23 @@ def test_getitem(): | |||
| l = torch.randn(15, 10) | |||
| source = TensorDataset(t, l) | |||
| for i in range(15): | |||
| assert np.allclose(t[i].asnumpy(), source[i][0].asnumpy()) | |||
| assert np.allclose(l[i].asnumpy(), source[i][1].asnumpy()) | |||
| assert np.allclose(t[i].asnumpy(), source[i][0]) | |||
| assert np.allclose(l[i].asnumpy(), source[i][1]) | |||
| def test_getitem_1d(): | |||
| t = torch.randn(15) | |||
| l = torch.randn(15) | |||
| source = TensorDataset(t, l) | |||
| for i in range(15): | |||
| assert np.allclose(t[i].asnumpy(), source[i][0].asnumpy()) | |||
| assert np.allclose(l[i].asnumpy(), source[i][1].asnumpy()) | |||
| assert np.allclose(t[i].asnumpy(), source[i][0]) | |||
| assert np.allclose(l[i].asnumpy(), source[i][1]) | |||
| def test_single_tensor(): | |||
| t = torch.randn(5, 10) | |||
| source = TensorDataset(t) | |||
| assert np.allclose(len(source), 5) | |||
| for i in range(5): | |||
| assert np.allclose(t[i].asnumpy(), source[i][0].asnumpy()) | |||
| assert np.allclose(t[i].asnumpy(), source[i][0]) | |||
| def test_many_tensors(): | |||
| t0 = torch.randn(5, 10, 2, 3, 4, 5) | |||
| @@ -244,10 +244,10 @@ def test_many_tensors(): | |||
| source = TensorDataset(t0, t1, t2, t3) | |||
| assert np.allclose(len(source), 5) | |||
| for i in range(5): | |||
| assert np.allclose(t0[i].asnumpy(), source[i][0].asnumpy()) | |||
| assert np.allclose(t1[i].asnumpy(), source[i][1].asnumpy()) | |||
| assert np.allclose(t2[i].asnumpy(), source[i][2].asnumpy()) | |||
| assert np.allclose(t3[i].asnumpy(), source[i][3].asnumpy()) | |||
| assert np.allclose(t0[i].asnumpy(), source[i][0]) | |||
| assert np.allclose(t1[i].asnumpy(), source[i][1]) | |||
| assert np.allclose(t2[i].asnumpy(), source[i][2]) | |||
| assert np.allclose(t3[i].asnumpy(), source[i][3]) | |||
| def test_concat_two_singletons(): | |||
| result = ConcatDataset([[0], [1]]) | |||
| @@ -277,9 +277,9 @@ def test_add_dataset(): | |||
| d3 = TensorDataset(torch.randn(7, 3, 28, 28), torch.randn(7)) | |||
| result = d1 + d2 + d3 | |||
| assert np.allclose(21, len(result)) | |||
| assert np.allclose(0, (d1[0][0] - result[0][0]).abs().sum().asnumpy()) | |||
| assert np.allclose(0, (d2[0][0] - result[7][0]).abs().sum().asnumpy()) | |||
| assert np.allclose(0, (d3[0][0] - result[14][0]).abs().sum().asnumpy()) | |||
| assert np.allclose(0, (torch.tensor(d1[0][0]) - torch.tensor(result[0][0])).abs().sum().asnumpy()) | |||
| assert np.allclose(0, (torch.tensor(d2[0][0]) - torch.tensor(result[7][0])).abs().sum().asnumpy()) | |||
| assert np.allclose(0, (torch.tensor(d3[0][0]) - torch.tensor(result[14][0])).abs().sum().asnumpy()) | |||
| # takes in dummy var so this can also be used as a `worker_init_fn` | |||
| @@ -1099,18 +1099,18 @@ def test_worker_seed_reproducibility(): | |||
| for i in range(len(first)): | |||
| assert np.allclose(first[i], second[i]) | |||
| # def test_multi_epochs_reproducibility(): | |||
| # num_workers = 3 # TODO test num_workers > 0 | |||
| # batch_size = 10 | |||
| # num_epochs = 3 | |||
| # | |||
| # dataset = TestMultiEpochDataset(batch_size * num_workers) | |||
| # dataloader = _get_data_loader(dataset, batch_size=batch_size, | |||
| # shuffle=False, num_workers=num_workers) | |||
| # | |||
| # for ind in range(num_epochs): | |||
| # for batch_idx, sample in enumerate(dataloader): | |||
| # np.allclose(sample.asnumpy().tolist(), [batch_idx % num_workers] * batch_size) | |||
| def test_multi_epochs_reproducibility(): | |||
| num_workers = 3 # TODO test num_workers > 0 | |||
| batch_size = 10 | |||
| num_epochs = 3 | |||
| dataset = TestMultiEpochDataset(batch_size * num_workers) | |||
| dataloader = _get_data_loader(dataset, batch_size=batch_size, | |||
| shuffle=False, num_workers=num_workers) | |||
| for ind in range(num_epochs): | |||
| for batch_idx, sample in enumerate(dataloader): | |||
| np.allclose(sample.asnumpy().tolist(), [batch_idx % num_workers] * batch_size) | |||
| # def test_get_worker_info(): | |||
| @@ -1127,13 +1127,13 @@ def test_shuffle(): | |||
| _test_shuffle(_get_data_loader(dataset, shuffle=True)) | |||
| def test_shuffle_batch_none(): | |||
| _test_shuffle(DataLoader(dataset, batch_size=None, shuffle=True)) | |||
| _test_shuffle(DataLoader(dataset, batch_size=None)) | |||
| def test_shuffle_batch(): | |||
| _test_shuffle(_get_data_loader(dataset, batch_size=2, shuffle=True)) | |||
| def test_shuffle_reproducibility(): | |||
| np.random.seed(42) #TODO test num_workers > 0 | |||
| np.random.seed(42) | |||
| ms.set_seed(42) | |||
| first = list(DataLoader(dataset, shuffle=True, num_workers=0)) | |||
| np.random.seed(42) | |||
| @@ -1384,27 +1384,28 @@ def test_len_1(): | |||
| check_len(_get_data_loader(dataset, batch_size=2), 50) | |||
| check_len(_get_data_loader(dataset, batch_size=3), 34) | |||
| def test_iterabledataset_len(): | |||
| class IterableDataset(torch.utils.data.IterableDataset): | |||
| def __len__(self): | |||
| return 10 | |||
| class IterableDataset_custom(torch.utils.data.IterableDataset): | |||
| def __len__(self): | |||
| return 10 | |||
| def __iter__(self): | |||
| return iter(range(10)) | |||
| def __iter__(self): | |||
| return iter(range(10)) | |||
| def test_iterabledataset_len(): | |||
| iterable_loader = DataLoader(IterableDataset(), batch_size=1) | |||
| iterable_loader = DataLoader(IterableDataset_custom(), batch_size=1) | |||
| assert np.allclose(len(iterable_loader), 10) | |||
| iterable_loader = DataLoader(IterableDataset(), batch_size=1, drop_last=True) | |||
| iterable_loader = DataLoader(IterableDataset_custom(), batch_size=1, drop_last=True) | |||
| assert np.allclose(len(iterable_loader), 10) | |||
| iterable_loader = DataLoader(IterableDataset(), batch_size=2) | |||
| iterable_loader = DataLoader(IterableDataset_custom(), batch_size=2) | |||
| assert np.allclose(len(iterable_loader), 5) | |||
| iterable_loader = DataLoader(IterableDataset(), batch_size=2, drop_last=True) | |||
| iterable_loader = DataLoader(IterableDataset_custom(), batch_size=2, drop_last=True) | |||
| assert np.allclose(len(iterable_loader), 5) | |||
| iterable_loader = DataLoader(IterableDataset(), batch_size=3) | |||
| iterable_loader = DataLoader(IterableDataset_custom(), batch_size=3) | |||
| assert np.allclose(len(iterable_loader), 4) | |||
| iterable_loader = DataLoader(IterableDataset(), batch_size=3, drop_last=True) | |||
| iterable_loader = DataLoader(IterableDataset_custom(), batch_size=3, drop_last=True) | |||
| assert np.allclose(len(iterable_loader), 3) | |||
+ 119
- 37
testing/ut/pytorch/functional/test_activation.py
View File
| @@ -8,7 +8,8 @@ from mindspore import context | |||
| import msadapter.pytorch as ms_torch | |||
| import msadapter.pytorch.nn.functional as msa_fun | |||
| from ...utils import set_mode_by_env_config, SKIP_ENV_GRAPH_MODE | |||
| from ...utils import SKIP_ENV_ASCEND, set_mode_by_env_config, SKIP_ENV_GRAPH_MODE, param_compare, \ | |||
| is_test_under_ascend_context | |||
| set_mode_by_env_config() | |||
| @@ -17,10 +18,10 @@ set_mode_by_env_config() | |||
| def test_rrelu(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| torch_output = t_fun.rrelu(torch_input, inplace=True) | |||
| ms_input = ms_torch.Tensor(data) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_output = msa_fun.rrelu(ms_input, inplace=True) | |||
| assert np.allclose(ms_output.asnumpy(), torch_output.numpy()) | |||
| @@ -28,53 +29,129 @@ def test_rrelu(): | |||
| def test_rrelu_(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| _ = t_fun.rrelu_(torch_input) | |||
| ms_input = ms_torch.Tensor(data) | |||
| ms_input = ms_torch.tensor(data) | |||
| _ = msa_fun.rrelu_(ms_input) | |||
| assert np.allclose(ms_input.asnumpy(), torch_input.numpy()) | |||
| @SKIP_ENV_ASCEND(reason="selu currently not support float64 on Ascend") | |||
| def test_selu_fp64(): | |||
| data = np.random.rand(2, 2).astype(np.float64) | |||
| torch_input = torch.tensor(data) | |||
| torch_output = t_fun.selu(torch_input) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_output = msa_fun.selu(ms_input) | |||
| param_compare(ms_output, torch_output) | |||
| def test_selu(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| data = np.random.rand(3, 5).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| torch_output = t_fun.selu(torch_input) | |||
| ms_input = ms_torch.Tensor(data) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_output = msa_fun.selu(ms_input) | |||
| assert np.allclose(ms_output.asnumpy(), torch_output.numpy()) | |||
| param_compare(ms_output, torch_output) | |||
| @SKIP_ENV_GRAPH_MODE(reason="nn.selu() inpalce operation only support on pynative mode.") | |||
| @SKIP_ENV_ASCEND(reason="selu currently not support float64 on Ascend") | |||
| def test_selu_inplace_fp64(): | |||
| data = np.random.rand(2, 3).astype(np.float64) | |||
| torch_input = torch.tensor(data) | |||
| _ = t_fun.selu(torch_input, True) | |||
| ms_input = ms_torch.tensor(data) | |||
| _ = msa_fun.selu(ms_input, True) | |||
| param_compare(ms_input, torch_input) | |||
| @SKIP_ENV_GRAPH_MODE(reason="nn.selu() inpalce operation only support on pynative mode.") | |||
| def test_selu_inplace(): | |||
| data = np.random.rand(3, 5).astype(np.float32) | |||
| torch_input = torch.tensor(data) | |||
| _ = t_fun.selu(torch_input, True) | |||
| ms_input = ms_torch.tensor(data) | |||
| _ = msa_fun.selu(ms_input, True) | |||
| param_compare(ms_input, torch_input) | |||
| def test_celu(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| torch_output = t_fun.celu(torch_input) | |||
| ms_input = ms_torch.Tensor(data) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_output = msa_fun.celu(ms_input) | |||
| assert np.allclose(ms_output.asnumpy(), torch_output.numpy()) | |||
| param_compare(ms_output, torch_output) | |||
| def test_celu_alpha(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.tensor(data) | |||
| torch_output = t_fun.celu(torch_input, -2) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_output = msa_fun.celu(ms_input, -2) | |||
| param_compare(ms_output, torch_output) | |||
| @SKIP_ENV_GRAPH_MODE(reason="nn.celu() inpalce operation only support on pynative mode.") | |||
| def test_celu_alpha_inplace(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.tensor(data) | |||
| _ = t_fun.celu(torch_input, -2, True) | |||
| ms_input = ms_torch.tensor(data) | |||
| _ = msa_fun.celu(ms_input, -2, True) | |||
| param_compare(ms_input, torch_input) | |||
| def test_gelu(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| torch_output = t_fun.gelu(torch_input) | |||
| ms_input = ms_torch.Tensor(data) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_output = msa_fun.gelu(ms_input) | |||
| assert np.allclose(ms_output.asnumpy(), torch_output.numpy(), atol=1e-3) | |||
| if is_test_under_ascend_context(): | |||
| param_compare(ms_output, torch_output, atol=1e-4) | |||
| else: | |||
| param_compare(ms_output, torch_output) | |||
| @SKIP_ENV_ASCEND(reason="selu currently not support float64 on Ascend") | |||
| def test_gelu_tanh_fp64(): | |||
| data = np.random.rand(2, 2).astype(np.float64) | |||
| torch_input = torch.tensor(data) | |||
| torch_output = t_fun.gelu(torch_input, approximate='tanh') | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_output = msa_fun.gelu(ms_input, approximate='tanh') | |||
| param_compare(ms_output, torch_output) | |||
| def test_gelu_tanh(): | |||
| data = np.random.rand(3, 5).astype(np.float32) | |||
| torch_input = torch.tensor(data) | |||
| torch_output = t_fun.gelu(torch_input, approximate='tanh') | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_output = msa_fun.gelu(ms_input, approximate='tanh') | |||
| param_compare(ms_output, torch_output) | |||
| def test_mish(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| torch_output = t_fun.mish(torch_input) | |||
| ms_input = ms_torch.Tensor(data) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_output = msa_fun.mish(ms_input) | |||
| if context.get_context('device_target') == 'Ascend': | |||
| assert np.allclose(ms_output.asnumpy(), torch_output.numpy(), atol=1e-3) | |||
| @@ -85,10 +162,10 @@ def test_mish(): | |||
| def test_softshrink(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| torch_output = t_fun.softshrink(torch_input) | |||
| ms_input = ms_torch.Tensor(data) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_output = msa_fun.softshrink(ms_input) | |||
| assert np.allclose(ms_output.asnumpy(), torch_output.numpy()) | |||
| @@ -96,10 +173,10 @@ def test_softshrink(): | |||
| def test_relu(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| torch_output = t_fun.relu(torch_input) | |||
| ms_input = ms_torch.Tensor(data) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_output = msa_fun.relu(ms_input) | |||
| assert np.allclose(ms_output.asnumpy(), torch_output.numpy()) | |||
| @@ -107,20 +184,20 @@ def test_relu(): | |||
| def test_relu_(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| _ = t_fun.relu_(torch_input) | |||
| ms_input = ms_torch.Tensor(data) | |||
| ms_input = ms_torch.tensor(data) | |||
| _ = msa_fun.relu_(ms_input) | |||
| assert np.allclose(ms_input.asnumpy(), torch_input.numpy()) | |||
| def test_hardtanh(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| torch_output = t_fun.hardtanh(torch_input) | |||
| ms_input = ms_torch.Tensor(data) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_output = msa_fun.hardtanh(ms_input) | |||
| assert np.allclose(ms_output.asnumpy(), torch_output.numpy()) | |||
| @@ -128,10 +205,10 @@ def test_hardtanh(): | |||
| def test_hardtanh_(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| _ = t_fun.hardtanh_(torch_input) | |||
| ms_input = ms_torch.Tensor(data) | |||
| ms_input = ms_torch.tensor(data) | |||
| _ = msa_fun.hardtanh_(ms_input) | |||
| assert np.allclose(ms_input.asnumpy(), torch_input.numpy()) | |||
| @@ -139,10 +216,10 @@ def test_hardtanh_(): | |||
| def test_hardswish(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| torch_output = t_fun.hardswish(torch_input) | |||
| ms_input = ms_torch.Tensor(data) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_output = msa_fun.hardswish(ms_input) | |||
| assert np.allclose(ms_output.asnumpy(), torch_output.numpy()) | |||
| @@ -150,10 +227,10 @@ def test_hardswish(): | |||
| def test_relu6(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| torch_output = t_fun.relu6(torch_input) | |||
| ms_input = ms_torch.Tensor(data) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_output = msa_fun.relu6(ms_input) | |||
| assert np.allclose(ms_output.asnumpy(), torch_output.numpy()) | |||
| @@ -161,10 +238,10 @@ def test_relu6(): | |||
| def test_leaky_relu(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| torch_output = t_fun.leaky_relu(torch_input) | |||
| ms_input = ms_torch.Tensor(data) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_output = msa_fun.leaky_relu(ms_input) | |||
| assert np.allclose(ms_output.asnumpy(), torch_output.numpy()) | |||
| @@ -172,10 +249,10 @@ def test_leaky_relu(): | |||
| def test_leaky_relu_(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| _ = t_fun.leaky_relu_(torch_input) | |||
| ms_input = ms_torch.Tensor(data) | |||
| ms_input = ms_torch.tensor(data) | |||
| _ = msa_fun.leaky_relu_(ms_input) | |||
| assert np.allclose(ms_input.asnumpy(), torch_input.numpy()) | |||
| @@ -195,7 +272,7 @@ def test_prelu(): | |||
| def test_elu_(): | |||
| data = np.random.rand(2, 3).astype(np.float32) | |||
| torch_input = torch.Tensor(data) | |||
| torch_input = torch.tensor(data) | |||
| _ = t_fun.elu_(torch_input) | |||
| ms_input = ms_torch.tensor(data) | |||
| @@ -207,6 +284,9 @@ if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
| test_rrelu() | |||
| test_selu() | |||
| test_selu_fp64() | |||
| test_selu_inplace() | |||
| test_selu_inplace_fp64() | |||
| test_celu() | |||
| test_gelu() | |||
| test_mish() | |||
| @@ -217,4 +297,6 @@ if __name__ == '__main__': | |||
| test_elu_() | |||
| test_leaky_relu_() | |||
| test_relu_() | |||
| test_rrelu_() | |||
| test_rrelu_() | |||
| test_gelu_tanh() | |||
| test_gelu_tanh_fp64() | |||
+ 22
- 10
testing/ut/pytorch/functional/test_arange.py
View File
| @@ -7,7 +7,7 @@ import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ...utils import set_mode_by_env_config | |||
| from ...utils import set_mode_by_env_config, param_compare | |||
| set_mode_by_env_config() | |||
| @@ -16,31 +16,41 @@ def test_arange1(): | |||
| torch_result = torch.arange(1, 10) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| param_compare(ms_result, torch_result) | |||
| def test_arange2(): | |||
| ms_result = ms_torch.arange(1.0, 3, 0.5) | |||
| torch_result = torch.arange(1.0, 3, 0.5) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| param_compare(ms_result, torch_result) | |||
| def test_arange3(): | |||
| ms_result = ms_torch.arange(1, 10, 5, dtype=ms_torch.int64) | |||
| torch_result = torch.arange(1, 10, 5, dtype=torch.int64) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| param_compare(ms_result, torch_result) | |||
| def test_arange4(): | |||
| ms_result = ms_torch.arange(2, 2) | |||
| ms_result = ms_torch.arange(2, 2, dtype=ms_torch.float32) | |||
| torch_result = torch.arange(2, 2) | |||
| torch_result = torch.arange(2, 2, dtype=torch.float32) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| param_compare(ms_result, torch_result) | |||
| def test_arange5(): | |||
| ms_result = ms_torch.arange(5, dtype=ms_torch.float64) | |||
| torch_result = torch.arange(5, dtype=torch.float64) | |||
| param_compare(ms_result, torch_result) | |||
| def test_arange6(): | |||
| ms_result = ms_torch.arange(ms_torch.tensor(1), ms_torch.tensor(10), ms_torch.tensor(2)) | |||
| torch_result = torch.arange(torch.tensor(1), torch.tensor(10), torch.tensor(2)) | |||
| param_compare(ms_result, torch_result) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
| @@ -48,3 +58,5 @@ if __name__ == '__main__': | |||
| test_arange2() | |||
| test_arange3() | |||
| test_arange4() | |||
| test_arange5() | |||
| test_arange6() | |||
+ 20
- 20
testing/ut/pytorch/functional/test_cat.py
View File
| @@ -7,45 +7,45 @@ import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ...utils import set_mode_by_env_config | |||
| from ...utils import SKIP_ENV_ASCEND, set_mode_by_env_config, param_compare | |||
| set_mode_by_env_config() | |||
| def test_cat1(): | |||
| ms_tensor = ms_torch.tensor([1, 2, 3]) | |||
| ms_result = ms_torch.cat((ms_tensor, ms_tensor), dim=0) | |||
| torch_tensor = torch.tensor([1, 2, 3]) | |||
| torch_result = torch.cat((torch_tensor, torch_tensor), dim=0) | |||
| ms_tensor = ms_torch.tensor([1, 2, 3]).to(ms_torch.uint8) | |||
| ms_result = ms_torch.cat((ms_tensor, ms_tensor, ms_tensor, ms_tensor.char()), dim=0) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| torch_tensor = torch.tensor([1, 2, 3]).to(torch.uint8) | |||
| torch_result = torch.cat((torch_tensor, torch_tensor, torch_tensor, torch_tensor.char()), dim=0) | |||
| param_compare(ms_result, torch_result) | |||
| def test_cat2(): | |||
| ms_tensor = ms_torch.tensor([[1, 2, 3], [1, 2, 3]]) | |||
| ms_result = ms_torch.cat((ms_tensor, ms_tensor), dim=1) | |||
| ms_result = ms_torch.cat((ms_tensor.short(), ms_tensor.half(), ms_tensor.short()), dim=1) | |||
| torch_tensor = torch.tensor([[1, 2, 3], [1, 2, 3]]) | |||
| torch_result = torch.cat((torch_tensor, torch_tensor), dim=1) | |||
| torch_result = torch.cat((torch_tensor.short(), torch_tensor.half(), torch_tensor.short()), dim=1) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| param_compare(ms_result, torch_result) | |||
| def test_cat3(): | |||
| ms_tensor = ms_torch.tensor([[1, 2, 3], [1, 2, 3]]) | |||
| ms_result = ms_torch.cat([ms_tensor, ms_tensor], dim=0) | |||
| ms_result = ms_torch.cat([ms_tensor.int(), ms_tensor.long()], dim=0) | |||
| torch_tensor = torch.tensor([[1, 2, 3], [1, 2, 3]]) | |||
| torch_result = torch.cat([torch_tensor, torch_tensor], dim=0) | |||
| torch_result = torch.cat([torch_tensor.int(), torch_tensor.long()], dim=0) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| param_compare(ms_result, torch_result) | |||
| @SKIP_ENV_ASCEND(reason="currently concat not support float64 on Ascend") | |||
| def test_concat1(): | |||
| ms_tensor = ms_torch.tensor([1, 2, 3]) | |||
| ms_result = ms_torch.concat((ms_tensor, ms_tensor), dim=0) | |||
| ms_result = ms_torch.concat((ms_tensor.double(), ms_tensor.half()), dim=0) | |||
| torch_tensor = torch.tensor([1, 2, 3]) | |||
| torch_result = torch.concat((torch_tensor, torch_tensor), dim=0) | |||
| torch_result = torch.concat((torch_tensor.double(), torch_tensor.half()), dim=0) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| param_compare(ms_result, torch_result) | |||
| def test_concat2(): | |||
| ms_tensor = ms_torch.tensor([[1, 2, 3], [1, 2, 3]]) | |||
| @@ -54,16 +54,16 @@ def test_concat2(): | |||
| torch_tensor = torch.tensor([[1, 2, 3], [1, 2, 3]]) | |||
| torch_result = torch.concat((torch_tensor, torch_tensor), dim=1) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| param_compare(ms_result, torch_result) | |||
| def test_concat3(): | |||
| ms_tensor = ms_torch.tensor([[1, 2, 3], [1, 2, 3]]) | |||
| ms_result = ms_torch.concat([ms_tensor, ms_tensor], dim=0) | |||
| ms_result = ms_torch.concat([ms_tensor.bool(), ms_tensor.byte()], dim=-1) | |||
| torch_tensor = torch.tensor([[1, 2, 3], [1, 2, 3]]) | |||
| torch_result = torch.concat([torch_tensor, torch_tensor], dim=0) | |||
| torch_result = torch.concat([torch_tensor.bool(), torch_tensor.byte()], dim=-1) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| param_compare(ms_result, torch_result) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
+ 1
- 0
testing/ut/pytorch/functional/test_cumsum.py
View File
| @@ -40,6 +40,7 @@ def test_cumsum3(): | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| @SKIP_ENV_ASCEND(reason='cumsum not support int64 input on Ascend') | |||
| def test_cumsum_uint8_overflow(): | |||
| data = np.array([66, 66, 66, 66, 66]).astype(np.uint8) | |||
+ 3
- 2
testing/ut/pytorch/functional/test_diag.py
View File
| @@ -7,7 +7,7 @@ import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ...utils import set_mode_by_env_config | |||
| from ...utils import set_mode_by_env_config, SKIP_ENV_ASCEND | |||
| set_mode_by_env_config() | |||
| def test_diag1(): | |||
| @@ -34,6 +34,8 @@ def test_diag2(): | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| # TODO: undo skipping after bug fixed | |||
| @SKIP_ENV_ASCEND(reason="ms.numpy.diag has bug on Ascend") | |||
| def test_diag3(): | |||
| np_1 = np.array([1, 2, 3]) | |||
| @@ -72,7 +74,6 @@ def test_diagonal2(): | |||
| # TODO: mindspore return float32 != torch return float64 | |||
| # assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| def test_diagonal3(): | |||
| np_1 = np.random.randn(3, 3) | |||
+ 13
- 14
testing/ut/pytorch/functional/test_diff.py
View File
| @@ -7,7 +7,7 @@ import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ...utils import set_mode_by_env_config | |||
| from ...utils import SKIP_ENV_ASCEND, SKIP_ENV_CPU, SKIP_ENV_GPU, param_compare, set_mode_by_env_config | |||
| set_mode_by_env_config() | |||
| def test_diff1(): | |||
| @@ -43,32 +43,31 @@ def test_diff3(): | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| @SKIP_ENV_ASCEND(reason="diff currently not support float64 on Ascend") | |||
| def test_diff4(): | |||
| np_1 = np.random.randn(7, 8) | |||
| np_2 = np.random.randn(7, 8) | |||
| ms_tensor_1 = ms_torch.tensor(np_1) | |||
| ms_tensor_2 = ms_torch.tensor(np_2) | |||
| ms_result = ms_torch.diff(ms_tensor_1, dim=-1, append=ms_tensor_2) | |||
| ms_result1 = ms_torch.diff(ms_tensor_1) | |||
| torch_tensor_1 = torch.tensor(np_1) | |||
| torch_tensor_2 = torch.tensor(np_2) | |||
| torch_result = torch.diff(torch_tensor_1, dim=-1, append=torch_tensor_2) | |||
| torch_result1 = torch.diff(torch_tensor_1) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy(), atol=1e-6) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| param_compare(ms_result1, torch_result1) | |||
| def test_diff5(): | |||
| np_1 = np.random.randn(7, 8) | |||
| np_2 = np.random.randn(7, 8) | |||
| np_1 = np.random.randn(3, 4, 5).astype(np.float32) | |||
| np_2 = np.random.randn(3, 4, 5).astype(np.float32) | |||
| ms_tensor_1 = ms_torch.tensor(np_1) | |||
| ms_tensor_2 = ms_torch.tensor(np_2) | |||
| ms_result = ms_torch.diff(ms_tensor_1, n=3, dim=-1, append=ms_tensor_2) | |||
| ms_result1 = ms_torch.diff(ms_tensor_1, dim=-1, append=ms_tensor_2) | |||
| ms_result2 = ms_torch.diff(ms_tensor_1, n=3, dim=-1, append=ms_tensor_2) | |||
| torch_tensor_1 = torch.tensor(np_1) | |||
| torch_tensor_2 = torch.tensor(np_2) | |||
| torch_result = torch.diff(torch_tensor_1, n=3, dim=-1, append=torch_tensor_2) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy(), atol=1e-6) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| torch_result1 = torch.diff(torch_tensor_1, dim=-1, append=torch_tensor_2) | |||
| torch_result2 = torch.diff(torch_tensor_1, n=3, dim=-1, append=torch_tensor_2) | |||
| param_compare(ms_result1, torch_result1) | |||
| param_compare(ms_result2, torch_result2) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
+ 3
- 1
testing/ut/pytorch/functional/test_empty.py
View File
| @@ -7,16 +7,18 @@ import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ...utils import set_mode_by_env_config | |||
| from ...utils import set_mode_by_env_config, type_shape_compare | |||
| set_mode_by_env_config() | |||
| def test_empty1(): | |||
| ms_result = ms_torch.empty(2, 3, dtype=ms_torch.float32) | |||
| torch_result = torch.empty(2, 3, dtype=torch.float32) | |||
| type_shape_compare(ms_result, torch_result) | |||
| def test_empty2(): | |||
| ms_result = ms_torch.empty((2, 3), dtype=ms_torch.float32) | |||
| torch_result = torch.empty((2, 3), dtype=torch.float32) | |||
| type_shape_compare(ms_result, torch_result) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
+ 5
- 5
testing/ut/pytorch/functional/test_eye.py
View File
| @@ -7,18 +7,18 @@ import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ...utils import set_mode_by_env_config | |||
| from ...utils import set_mode_by_env_config, param_compare | |||
| set_mode_by_env_config() | |||
| def test_eye1(): | |||
| ms_result = ms_torch.eye(n=2, m=3, dtype=ms_torch.float32) | |||
| torch_result = torch.eye(n=2, m=3, dtype=torch.float32) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| param_compare(ms_result, torch_result) | |||
| def test_eye2(): | |||
| ms_result = ms_torch.eye(n=2, dtype=ms_torch.float32) | |||
| torch_result = torch.eye(n=2, dtype=torch.float32) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| ms_result = ms_torch.eye(n=2, dtype=ms_torch.int64) | |||
| torch_result = torch.eye(n=2, dtype=torch.int64) | |||
| param_compare(ms_result, torch_result) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
+ 13
- 33
testing/ut/pytorch/functional/test_flip.py
View File
| @@ -1,13 +1,11 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import mindspore as ms | |||
| import msadapter.pytorch as ms_torch | |||
| import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ...utils import set_mode_by_env_config | |||
| from ...utils import set_mode_by_env_config, param_compare | |||
| set_mode_by_env_config() | |||
| def test_flip1(): | |||
| @@ -17,18 +15,16 @@ def test_flip1(): | |||
| torch_tensor_1 = torch.tensor(np_1) | |||
| torch_result = torch.flip(torch_tensor_1, (1, )) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| param_compare(ms_result, torch_result) | |||
| def test_flip2(): | |||
| np_1 = np.random.randn(4, 5, 6, 7) | |||
| ms_tensor_1 = ms_torch.tensor(np_1) | |||
| ms_result = ms_torch.flip(ms_tensor_1, (0, 3)) | |||
| ms_result = ms_torch.flip(ms_tensor_1, [0, 3]) | |||
| torch_tensor_1 = torch.tensor(np_1) | |||
| torch_result = torch.flip(torch_tensor_1, (0, 3)) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| torch_result = torch.flip(torch_tensor_1, [0, 3]) | |||
| param_compare(ms_result, torch_result) | |||
| def test_flip3(): | |||
| np_1 = np.random.randn(3, 4, 5) | |||
| @@ -37,8 +33,7 @@ def test_flip3(): | |||
| torch_tensor_1 = torch.tensor(np_1) | |||
| torch_result = torch.flip(torch_tensor_1, (0, 1)) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| param_compare(ms_result, torch_result) | |||
| def test_flip4(): | |||
| @@ -48,8 +43,7 @@ def test_flip4(): | |||
| torch_tensor_1 = torch.tensor(np_1) | |||
| torch_result = torch.flip(torch_tensor_1, [0, 1]) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| param_compare(ms_result, torch_result) | |||
| def test_fliplr1(): | |||
| np_1 = np.random.randn(4, 4) | |||
| @@ -58,39 +52,26 @@ def test_fliplr1(): | |||
| torch_tensor_1 = torch.tensor(np_1) | |||
| torch_result = torch.fliplr(torch_tensor_1) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| param_compare(ms_result, torch_result) | |||
| def test_fliplr2(): | |||
| np_1 = np.random.randn(3, 4, 5) | |||
| ms_tensor_1 = ms_torch.tensor(np_1) | |||
| ms_result = ms_torch.fliplr(ms_tensor_1) | |||
| torch_tensor_1 = torch.tensor(np_1) | |||
| torch_result = torch.fliplr(torch_tensor_1) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| def test_fliplr3(): | |||
| np_1 = np.random.randn(4, 5, 6, 7) | |||
| ms_tensor_1 = ms_torch.tensor(np_1) | |||
| ms_result = ms_torch.fliplr(ms_tensor_1) | |||
| torch_tensor_1 = torch.tensor(np_1) | |||
| torch_result = torch.fliplr(torch_tensor_1) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| param_compare(ms_result, torch_result) | |||
| def test_fliplr4(): | |||
| np_1 = np.reshape(np.arange(8), (2, 2, 2)) | |||
| def test_fliplr3(): | |||
| #TODO: numpy higher than 1.20 should use float64 instead of float | |||
| np_1 = np.reshape(np.arange(8), (2, 2, 2)).astype(np.float64) | |||
| ms_tensor_1 = ms_torch.tensor(np_1) | |||
| ms_result = ms_torch.fliplr(ms_tensor_1) | |||
| torch_tensor_1 = torch.tensor(np_1) | |||
| torch_result = torch.fliplr(torch_tensor_1) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| param_compare(ms_result, torch_result) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
| @@ -101,5 +82,4 @@ if __name__ == '__main__': | |||
| test_fliplr1() | |||
| test_fliplr2() | |||
| test_fliplr3() | |||
| test_fliplr4() | |||
+ 532
- 243
testing/ut/pytorch/functional/test_function.py
View File
| @@ -255,7 +255,24 @@ def test_take(): | |||
| def test_abs(): | |||
| x = np.random.randn(2, 3, 4) * 20 | |||
| x = (np.random.randn(2, 3, 4) * 20).astype(np.float32) | |||
| torch_x = torch.tensor(x) | |||
| ms_x = ms_torch.tensor(x) | |||
| torch_out = torch.abs(torch_x) | |||
| ms_out = ms_torch.abs(ms_x) | |||
| param_compare(torch_out, ms_out) | |||
| def test_abs_int(): | |||
| x = (np.random.randn(2, 3, 4) * 20).astype(np.int32) | |||
| torch_x = torch.tensor(x) | |||
| ms_x = ms_torch.tensor(x) | |||
| torch_out = torch.abs(torch_x) | |||
| ms_out = ms_torch.abs(ms_x) | |||
| param_compare(torch_out, ms_out) | |||
| @SKIP_ENV_ASCEND(reason='abs not support float64 and int16 input on Ascend') | |||
| def test_abs_fp64(): | |||
| x = np.random.randn(2, 3, 4) | |||
| x1 = x.astype(np.float64) | |||
| x2 = x.astype(np.int16) | |||
| torch_x1 = torch.tensor(x1) | |||
| @@ -343,21 +360,23 @@ def test_fft(): | |||
| param_compare(t_r1, ms_r1) | |||
| param_compare(t_r2, ms_r2) | |||
| def test_fmod(): | |||
| np_array = (np.random.randn(2, 3) * 20).astype(np.float32) | |||
| t_r = torch.fmod(torch.tensor([-3., -2, -1, 1, 2, 3]), 2) | |||
| t_r1 = torch.fmod(torch.tensor([1, 2, 3, 4, 5]), -1.5) | |||
| t_r2 = torch.fmod(torch.tensor(np_array), 0) | |||
| ms_r = ms_torch.fmod(ms_torch.tensor([-3., -2, -1, 1, 2, 3]), 2) | |||
| ms_r1 = ms_torch.fmod(ms_torch.tensor([1, 2, 3, 4, 5]), -1.5) | |||
| ms_r2 = ms_torch.fmod(ms_torch.tensor(np_array), 0) | |||
| param_compare(t_r, ms_r) | |||
| param_compare(t_r1, ms_r1) | |||
| param_compare(t_r2, ms_r2, equal_nan=True) | |||
| @SKIP_ENV_ASCEND(reason="ascend not support inf result, result will not be correct") | |||
| def test_fmod_inf_nan(): | |||
| np_array = (np.random.randn(2, 3) * 20).astype(np.float32) | |||
| t_r2 = torch.fmod(torch.tensor(np_array), 0) | |||
| ms_r2 = ms_torch.fmod(ms_torch.tensor(np_array), 0) | |||
| param_compare(t_r2, ms_r2, equal_nan=True) | |||
| def test_frac(): | |||
| t_r = torch.frac(torch.tensor([1, 2.5, -3.2])) | |||
| @@ -575,8 +594,14 @@ def test_norm_p_minus_2(): | |||
| def test_bartlett_window(): | |||
| t_r = torch.bartlett_window(5) | |||
| ms_r = ms_torch.bartlett_window(5) | |||
| t_r1 = torch.bartlett_window(5, False) | |||
| ms_r1 = ms_torch.bartlett_window(5, False) | |||
| t_r2 = torch.bartlett_window(5, dtype=torch.float64) | |||
| ms_r2 = ms_torch.bartlett_window(5, dtype=ms_torch.float64) | |||
| assert np.allclose(t_r.numpy(), ms_r.numpy()) | |||
| param_compare(t_r, ms_r) | |||
| param_compare(t_r1, ms_r1) | |||
| param_compare(t_r2, ms_r2) | |||
| def test_hamming_window(): | |||
| @@ -641,7 +666,6 @@ def test_einsum(): | |||
| torch.einsum('bn,anm,bm->ba', l, A, r) | |||
| @SKIP_ENV_GPU(reason="ms.ops.histc not support GPU now.") | |||
| def test_histc(): | |||
| data1 = np.array([1, 2, 1, 0, -1, -2, 2, 2, 3, 3, 4, 5, 6]).astype(np.float32) | |||
| t_r1 = torch.histc(torch.tensor(data1), bins=4, min=3, max=3) | |||
| @@ -651,9 +675,9 @@ def test_histc(): | |||
| t_r3 = torch.histc(torch.tensor([1., 1, 1]), bins=4, min=3, max=3) | |||
| ms_r3 = ms_torch.histc(ms_torch.tensor([1., 1, 1]), bins=4, min=3, max=3) | |||
| assert np.allclose(t_r1.numpy(), ms_r1.numpy()) | |||
| assert np.allclose(t_r2.numpy(), ms_r2.numpy()) | |||
| assert np.allclose(t_r3.numpy(), ms_r3.numpy()) | |||
| param_compare(t_r1, ms_r1) | |||
| param_compare(t_r2, ms_r2) | |||
| param_compare(t_r3, ms_r3) | |||
| def test_histogram(): | |||
| @@ -681,18 +705,26 @@ def test_histogram(): | |||
| def test_triu(): | |||
| a = torch.randn(3, 3) | |||
| t_r = torch.triu(a) | |||
| t_r1 = torch.triu(a, diagonal=1) | |||
| t_r2 = torch.triu(a, diagonal=-1) | |||
| ms_r = ms_torch.triu(ms_torch.tensor(a.numpy())) | |||
| ms_r1 = ms_torch.triu(ms_torch.tensor(a.numpy()), diagonal=1) | |||
| ms_r2 = ms_torch.triu(ms_torch.tensor(a.numpy()), diagonal=-1) | |||
| assert np.allclose(t_r.numpy(), ms_r.numpy()) | |||
| assert np.allclose(t_r1.numpy(), ms_r1.numpy()) | |||
| assert np.allclose(t_r2.numpy(), ms_r2.numpy()) | |||
| a = np.random.randn(3, 3).astype(np.int32) | |||
| a1 = np.random.randn(3, 3).astype(np.float32) | |||
| t1 = torch.tensor(a) | |||
| t2 = torch.tensor(a1) | |||
| ms1 = ms_torch.tensor(a) | |||
| ms2 = ms_torch.tensor(a1) | |||
| t_r = torch.triu(t1) | |||
| t_r1 = torch.triu(t1, diagonal=1) | |||
| t_r2 = torch.triu(t1, diagonal=-1) | |||
| t_r3 = torch.triu(t2) | |||
| ms_r = ms_torch.triu(ms1) | |||
| ms_r1 = ms_torch.triu(ms1, diagonal=1) | |||
| ms_r2 = ms_torch.triu(ms1, diagonal=-1) | |||
| ms_r3 = ms_torch.triu(ms2) | |||
| param_compare(ms_r, t_r) | |||
| param_compare(ms_r1, t_r1) | |||
| param_compare(ms_r2, t_r2) | |||
| param_compare(ms_r3, t_r3) | |||
| def test_index_select(): | |||
| @@ -705,12 +737,25 @@ def test_index_select(): | |||
| indices = ms_torch.tensor([0, 2]) | |||
| ms_out = ms_torch.index_select(x_ms, 1, indices) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| param_compare(ms_out, torch_out) | |||
| @SKIP_ENV_ASCEND(reason="bmm currently not support float64 on Ascend") | |||
| def test_bmm_fp64(): | |||
| input = np.random.randn(1, 3, 4) | |||
| mat2 = np.random.randn(1, 4, 5) | |||
| torch_input = torch.tensor(input) | |||
| torch_mat2 = torch.tensor(mat2) | |||
| torch_out = torch.bmm(torch_input, torch_mat2) | |||
| ms_input = ms_torch.tensor(input) | |||
| ms_mat2 = ms_torch.tensor(mat2) | |||
| ms_out = ms_torch.bmm(ms_input, ms_mat2) | |||
| param_compare(torch_out, ms_out) | |||
| def test_bmm(): | |||
| input = np.random.randn(2, 3, 4) | |||
| mat2 = np.random.randn(2, 4, 5) | |||
| input = np.random.randn(3, 5, 6).astype(np.float32) | |||
| mat2 = np.random.randn(3, 6, 8).astype(np.float32) | |||
| torch_input = torch.tensor(input) | |||
| torch_mat2 = torch.tensor(mat2) | |||
| @@ -719,12 +764,13 @@ def test_bmm(): | |||
| ms_input = ms_torch.tensor(input) | |||
| ms_mat2 = ms_torch.tensor(mat2) | |||
| ms_out = ms_torch.bmm(ms_input, ms_mat2) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| param_compare(torch_out, ms_out, atol=1e-4) | |||
| def test_baddbmm(): | |||
| x = np.random.randn(10, 3, 5) | |||
| b1 = np.random.randn(10, 3, 4) | |||
| b2 = np.random.randn(10, 4, 5) | |||
| @SKIP_ENV_ASCEND(reason="baddbmm currently not support float64 on Ascend") | |||
| def test_baddbmm_fp64(): | |||
| x = np.random.randn(1, 3, 5) | |||
| b1 = np.random.randn(1, 3, 4) | |||
| b2 = np.random.randn(1, 4, 5) | |||
| torch_input = torch.tensor(x) | |||
| torch_batch1 = torch.tensor(b1) | |||
| @@ -735,7 +781,23 @@ def test_baddbmm(): | |||
| ms_torch_batch1 = ms_torch.tensor(b1) | |||
| ms_torch_batch2 = ms_torch.tensor(b2) | |||
| ms_torch_out = ms_torch.baddbmm(ms_torch_input, ms_torch_batch1, ms_torch_batch2, beta=2, alpha=1.5) | |||
| assert np.allclose(torch_out.numpy(), ms_torch_out.numpy()) | |||
| param_compare(torch_out, ms_torch_out, atol=1e-4) | |||
| def test_baddbmm(): | |||
| x = np.random.randn(10, 3, 5).astype(np.float32) | |||
| b1 = np.random.randn(10, 3, 4).astype(np.float32) | |||
| b2 = np.random.randn(10, 4, 5).astype(np.float32) | |||
| torch_input = torch.tensor(x) | |||
| torch_batch1 = torch.tensor(b1) | |||
| torch_batch2 = torch.tensor(b2) | |||
| torch_out = torch.baddbmm(torch_input, torch_batch1, torch_batch2, beta=2., alpha=1.5) | |||
| ms_torch_input = ms_torch.tensor(x) | |||
| ms_torch_batch1 = ms_torch.tensor(b1) | |||
| ms_torch_batch2 = ms_torch.tensor(b2) | |||
| ms_torch_out = ms_torch.baddbmm(ms_torch_input, ms_torch_batch1, ms_torch_batch2, beta=2., alpha=1.5) | |||
| param_compare(torch_out, ms_torch_out, atol=1e-4) | |||
| def test_argmin(): | |||
| x = np.random.randn(2, 3, 2) | |||
| @@ -836,7 +898,10 @@ def test_topk(): | |||
| torch_v, torch_i = torch.topk(torch_x, 3) | |||
| ms_x = ms_torch.tensor(x) | |||
| ms_v, ms_i = ms_torch.topk(ms_x, 3) | |||
| assert np.allclose(torch_v.numpy(), ms_v.numpy()) | |||
| if is_test_under_ascend_context(): | |||
| assert np.allclose(torch_v.numpy(), ms_v.numpy(), atol=1e-3) | |||
| else: | |||
| assert np.allclose(torch_v.numpy(), ms_v.numpy()) | |||
| assert np.allclose(torch_i.numpy(), ms_i.numpy()) | |||
| def test_topk_with_dim(): | |||
| @@ -853,10 +918,11 @@ def test_topk_with_dim(): | |||
| assert np.allclose(torch_i.numpy(), ms_i.numpy()) | |||
| def test_addbmm(): | |||
| @SKIP_ENV_ASCEND(reason="addbmm currently not support float64 on Ascend") | |||
| def test_addbmm_fp64(): | |||
| M_ = np.random.randn(3, 5) | |||
| batch1_ = np.random.randn(10, 3, 4) | |||
| batch2_ = np.random.randn(10, 4, 5) | |||
| batch1_ = np.random.randn(1, 3, 4) | |||
| batch2_ = np.random.randn(1, 4, 5) | |||
| M = torch.tensor(M_) | |||
| batch1 = torch.tensor(batch1_) | |||
| @@ -867,8 +933,23 @@ def test_addbmm(): | |||
| batch1 = ms_torch.tensor(batch1_) | |||
| batch2 = ms_torch.tensor(batch2_) | |||
| ms_output = ms_torch.addbmm(M, batch1, batch2, alpha=2, beta=3) | |||
| param_compare(torch_output, torch_output) | |||
| assert np.allclose(ms_output.numpy(), torch_output.numpy()) | |||
| def test_addbmm(): | |||
| M_ = np.random.randn(3, 5).astype(np.float32) | |||
| batch1_ = np.random.randn(4, 3, 4).astype(np.float32) | |||
| batch2_ = np.random.randn(4, 4, 5).astype(np.float32) | |||
| M = torch.tensor(M_) | |||
| batch1 = torch.tensor(batch1_) | |||
| batch2 = torch.tensor(batch2_) | |||
| torch_output = torch.addbmm(M, batch1, batch2, alpha=2.5, beta=3.5) | |||
| M = ms_torch.tensor(M_) | |||
| batch1 = ms_torch.tensor(batch1_) | |||
| batch2 = ms_torch.tensor(batch2_) | |||
| ms_output = ms_torch.addbmm(M, batch1, batch2, alpha=2.5, beta=3.5) | |||
| param_compare(torch_output, ms_output, atol=1e-4) | |||
| def test_addr(): | |||
| vec1 = torch.arange(1., 4.) | |||
| @@ -902,6 +983,7 @@ def test_allclose_equal_nan_false(): | |||
| c2 = torch.allclose(torch.tensor([1.0, float('nan')]), torch.tensor([1.0, float('nan')])) | |||
| assert c1 == c2 | |||
| @SKIP_ENV_ASCEND(reason='isclose not support equal_nan=False on Ascend') | |||
| def test_isclose_equal_nan_false(): | |||
| a1 = ms_torch.isclose(ms_torch.tensor((1., 2, 3)), ms_torch.tensor((1 + 1e-10, 3, 4))) | |||
| b1 = ms_torch.isclose(ms_torch.tensor((float('inf'), 4)), ms_torch.tensor((float('inf'), 6)), rtol=.5) | |||
| @@ -912,21 +994,22 @@ def test_isclose_equal_nan_false(): | |||
| assert np.allclose(a1.numpy(), a2.numpy()) | |||
| assert np.allclose(b1.numpy(), b2.numpy()) | |||
| @SKIP_ENV_ASCEND(reason='isclose not support equal_nan=False on Ascend') | |||
| def test_isclose(): | |||
| a1 = ms_torch.isclose(ms_torch.tensor((1., 2, 3)), ms_torch.tensor((1 + 1e-10, 3, 4)), equal_nan=True) | |||
| b1 = ms_torch.isclose(ms_torch.tensor((float('inf'), 4)), ms_torch.tensor((float('inf'), 6)), rtol=.5, equal_nan=True) | |||
| a2 = torch.isclose(torch.tensor((1., 2, 3)), torch.tensor((1 + 1e-10, 3, 4)), equal_nan=True) | |||
| b2 = torch.isclose(torch.tensor((float('inf'), 4)), torch.tensor((float('inf'), 6)), rtol=.5, equal_nan=True) | |||
| assert np.allclose(a1.numpy(), a2.numpy()) | |||
| @SKIP_ENV_ASCEND(reason="isclose not support inf on Ascend") | |||
| def test_isclose_inf(): | |||
| b1 = ms_torch.isclose(ms_torch.tensor((float('inf'), 4)), ms_torch.tensor((float('inf'), 6)), rtol=.5, equal_nan=True) | |||
| b2 = torch.isclose(torch.tensor((float('inf'), 4)), torch.tensor((float('inf'), 6)), rtol=.5, equal_nan=True) | |||
| assert np.allclose(b1.numpy(), b2.numpy()) | |||
| def test_addmm(): | |||
| _M = np.random.randn(2, 3) | |||
| _mat1 = np.random.randn(2, 3) | |||
| _mat2 = np.random.randn(3, 3) | |||
| @SKIP_ENV_ASCEND(reason="baddbmm currently not support float64 on Ascend") | |||
| def test_addmm_fp64(): | |||
| _M = np.random.randn(1, 2) | |||
| _mat1 = np.random.randn(1, 2) | |||
| _mat2 = np.random.randn(2, 2) | |||
| M = ms_torch.tensor(_M) | |||
| mat1 = ms_torch.tensor(_mat1) | |||
| @@ -938,11 +1021,43 @@ def test_addmm(): | |||
| mat2 = torch.tensor(_mat2) | |||
| a2 = torch.addmm(M, mat1, mat2, alpha=2, beta=3) | |||
| assert np.allclose(a1.numpy(), a2.numpy()) | |||
| param_compare(a1, a2) | |||
| def test_cholesky(): | |||
| def test_addmm(): | |||
| _M = np.random.randn(2, 3).astype(np.float32) | |||
| _mat1 = np.random.randn(2, 3).astype(np.float32) | |||
| _mat2 = np.random.randn(3, 3).astype(np.float32) | |||
| M = ms_torch.tensor(_M) | |||
| mat1 = ms_torch.tensor(_mat1) | |||
| mat2 = ms_torch.tensor(_mat2) | |||
| a1 = ms_torch.addmm(M, mat1, mat2, alpha=2.5, beta=3.5) | |||
| M = torch.tensor(_M) | |||
| mat1 = torch.tensor(_mat1) | |||
| mat2 = torch.tensor(_mat2) | |||
| a2 = torch.addmm(M, mat1, mat2, alpha=2.5, beta=3.5) | |||
| param_compare(a1, a2, atol=1e-4) | |||
| @SKIP_ENV_ASCEND(reason="cholesky currently not support float64 on Ascend") | |||
| def test_cholesky_fp64(): | |||
| _data1 = np.random.randn(3, 3) | |||
| _data2 = np.random.randn(3, 2, 2) | |||
| a = torch.tensor(_data1) | |||
| a = a @ a.mT + 1e-3 | |||
| torch_out1 = torch.cholesky(a) | |||
| a = ms_torch.tensor(_data1) | |||
| a = a @ a.mT + 1e-3 | |||
| ms_out1 = ms_torch.cholesky(a) | |||
| param_compare(ms_out1, torch_out1, atol=1e-4) | |||
| def test_cholesky(): | |||
| _data1 = np.random.randn(4, 4).astype(np.float32) | |||
| _data2 = np.random.randn(5, 2, 2).astype(np.float32) | |||
| a = torch.tensor(_data1) | |||
| a = a @ a.mT + 1e-3 | |||
| @@ -960,8 +1075,8 @@ def test_cholesky(): | |||
| a = a @ a.mT + 1e-03 | |||
| ms_out2 = ms_torch.cholesky(a) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| param_compare(ms_out1, torch_out1, atol=1e-4) | |||
| param_compare(ms_out2, torch_out2) | |||
| def test_dist(): | |||
| _data1 = np.random.randn(4) | |||
| @@ -1020,20 +1135,69 @@ def test_any(): | |||
| assert np.allclose(d1.numpy(), d2.numpy()) | |||
| @SKIP_ENV_GPU(reason="Unsupport on GPU.") | |||
| def test_cholesky_inverse(): | |||
| _data = np.random.randn(3, 3) | |||
| @SKIP_ENV_ASCEND(reason="baddbmm currently not support float64 on Ascend") | |||
| def test_cholesky_inverse_fp64(): | |||
| _data = np.random.randn(2, 2) | |||
| a = torch.tensor(_data) | |||
| a = torch.mm(a, a.t()) + 1e-05 * torch.eye(3) | |||
| a = torch.mm(a, a.t()) + 1e-05 * torch.eye(2) | |||
| u = torch.cholesky(a) | |||
| torch_out = torch.cholesky_inverse(u) | |||
| a = ms_torch.tensor(_data) | |||
| a = ms_torch.mm(a, a.t()) + 1e-05 * ms_torch.eye(3) | |||
| a = ms_torch.mm(a, a.t()) + 1e-05 * ms_torch.eye(2) | |||
| u = ms_torch.cholesky(a) | |||
| ms_out = ms_torch.cholesky_inverse(u) | |||
| assert np.allclose(torch_out.numpy(), ms_out.numpy(), rtol=1e-2, atol=1e-5) | |||
| assert np.allclose(torch_out.numpy(), ms_out.numpy()) | |||
| @SKIP_ENV_GPU(reason="cholesky_inverse currently not support on GPU.") | |||
| def test_cholesky_inverse(): | |||
| _data = np.random.randn(4, 4).astype(np.float32) | |||
| a = torch.tensor(_data) | |||
| a = torch.mm(a, a.t()) + 1e-05 * torch.eye(4) | |||
| u = torch.cholesky(a) | |||
| torch_out = torch.cholesky_inverse(u) | |||
| a = ms_torch.tensor(_data) | |||
| a = ms_torch.mm(a, a.t()) + 1e-05 * ms_torch.eye(4) | |||
| u = ms_torch.cholesky(a) | |||
| ms_out = ms_torch.cholesky_inverse(u) | |||
| param_compare(torch_out, ms_out, rtol=1e-2, atol=1e-5) | |||
| def test_cholesky_solve(): | |||
| data1 = np.random.randn(3, 2).astype(np.float32) | |||
| data2 = np.random.randn(3, 3).astype(np.float32) | |||
| a_t = torch.tensor(data1) | |||
| b_t = torch.tensor(data2) | |||
| a_t = torch.mm(a_t, a_t.t()) + 1e-05 * torch.eye(3) | |||
| u_t = torch.cholesky(a_t) | |||
| torch_out1 = torch.cholesky_solve(u_t, b_t) | |||
| torch_out2 = torch.cholesky_solve(u_t, b_t, True) | |||
| a_ms = ms_torch.tensor(data1) | |||
| b_ms = ms_torch.tensor(data2) | |||
| a_ms = ms_torch.mm(a_ms, a_ms.t()) + 1e-05 * ms_torch.eye(3) | |||
| u_ms = ms_torch.cholesky(a_ms) | |||
| ms_out1 = ms_torch.cholesky_solve(u_ms, b_ms) | |||
| ms_out2 = ms_torch.cholesky_solve(u_ms, b_ms, True) | |||
| param_compare(torch_out1, ms_out1, rtol=1e-2, atol=1e-5) | |||
| param_compare(torch_out2, ms_out2, rtol=1e-2, atol=1e-5) | |||
| @SKIP_ENV_ASCEND(reason="cholesky_solve currently not support float64 on Ascend") | |||
| def test_cholesky_solve_fp64(): | |||
| data1 = np.random.randn(2, 3) | |||
| data2 = np.random.randn(2, 2) | |||
| a_t = torch.tensor(data1) | |||
| b_t = torch.tensor(data2) | |||
| torch_out1 = torch.cholesky_solve(a_t, b_t) | |||
| a_ms = ms_torch.tensor(data1) | |||
| b_ms = ms_torch.tensor(data2) | |||
| ms_out1 = ms_torch.cholesky_solve(a_ms, b_ms) | |||
| param_compare(torch_out1, ms_out1) | |||
| def test_iscomplex(): | |||
| a = ms_torch.tensor([1+1j, 2, 3]) | |||
| @@ -1187,7 +1351,7 @@ def test_vdot_int(): | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| @SKIP_ENV_ASCEND(reason='ms.ops.vdot not support complex input on Ascend') | |||
| def test_vdot_complex(): | |||
| data1_1 = np.array([2, 3+1j, 4]) | |||
| data1_2 = np.array([1, 2+1j, 3]) | |||
| @@ -1259,7 +1423,7 @@ def test_amin_float64(): | |||
| def test_nanmean(): | |||
| x = np.array([[float('nan'), 1, 2], [1, 2, 3]]) | |||
| x = np.array([[float('nan'), 1, 2], [1, 2, 3]]).astype(np.float32) | |||
| x_pt = torch.tensor(x) | |||
| out1_pt = torch.nanmean(x_pt) | |||
| x_ms = ms_torch.tensor(x) | |||
| @@ -1276,7 +1440,7 @@ def test_nanmean(): | |||
| def test_nansum(): | |||
| a = np.array([1., 2., float('nan'), 4.]) | |||
| a = np.array([1., 2., float('nan'), 4.]).astype(np.float32) | |||
| a_pt = torch.tensor(a) | |||
| out1_pt = torch.nansum(a_pt) | |||
| a_ms = ms_torch.tensor(a) | |||
| @@ -1287,7 +1451,7 @@ def test_nansum(): | |||
| out2_ms = ms_torch.nansum(ms_torch.tensor([1., float("nan")])) | |||
| assert np.allclose(out2_pt.numpy(), out2_ms.numpy()) | |||
| b = np.array([[1, 2], [3., float("nan")]]) | |||
| b = np.array([[1, 2], [3., float("nan")]]).astype(np.float32) | |||
| b_pt = torch.tensor(b) | |||
| out3_pt = torch.nansum(b_pt) | |||
| b_ms = ms_torch.tensor(b) | |||
| @@ -1354,28 +1518,36 @@ def test_vstack(): | |||
| torch_tensor2 = torch.tensor(b) | |||
| torch_tensor3 = torch.tensor(a2) | |||
| torch_tensor4 = torch.tensor(b2) | |||
| torch_out1 = torch.vstack((torch_tensor1, torch_tensor2)) | |||
| torch_out2 = torch.vstack((torch_tensor3, torch_tensor4)) | |||
| torch_out3 = torch.vstack([torch_tensor3, torch_tensor4]) | |||
| torch_out4 = torch.vstack([torch_tensor3, torch_tensor4]) | |||
| torch_out1 = torch.vstack((torch_tensor1.byte(), torch_tensor2.int())) | |||
| torch_out2 = torch.vstack((torch_tensor3.float(), torch_tensor4.float())) | |||
| torch_out4 = torch.vstack([torch_tensor3.short(), torch_tensor4.int()]) | |||
| ms_tensor1 = ms_torch.tensor(a) | |||
| ms_tensor2 = ms_torch.tensor(b) | |||
| ms_tensor3 = ms_torch.tensor(a2) | |||
| ms_tensor4 = ms_torch.tensor(b2) | |||
| ms_out1 = ms_torch.vstack((ms_tensor1, ms_tensor2)) | |||
| ms_out2 = ms_torch.vstack((ms_tensor3, ms_tensor4)) | |||
| ms_out3 = ms_torch.vstack([ms_tensor3, ms_tensor4]) | |||
| ms_out4 = ms_torch.vstack([ms_tensor3, ms_tensor4]) | |||
| ms_out1 = ms_torch.vstack((ms_tensor1.byte(), ms_tensor2.int())) | |||
| ms_out2 = ms_torch.vstack((ms_tensor3.float(), ms_tensor4.float())) | |||
| ms_out4 = ms_torch.vstack([ms_tensor3.short(), ms_tensor4.int()]) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| assert np.allclose(torch_out3.numpy(), ms_out3.numpy()) | |||
| assert torch_out3.numpy().dtype == ms_out3.numpy().dtype | |||
| assert np.allclose(torch_out4.numpy(), ms_out4.numpy()) | |||
| assert torch_out4.numpy().dtype == ms_out4.numpy().dtype | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2) | |||
| param_compare(torch_out4, ms_out4) | |||
| @SKIP_ENV_ASCEND(reason="vstack currently not support float64 on Ascend") | |||
| def test_vstack_fp64(): | |||
| a = np.random.randn(3, 1) | |||
| b = np.random.randn(3, 1) | |||
| torch_tensor1 = torch.tensor(a) | |||
| torch_tensor2 = torch.tensor(b) | |||
| torch_out1 = torch.vstack((torch_tensor1.long(), torch_tensor2.double())) | |||
| ms_tensor1 = ms_torch.tensor(a) | |||
| ms_tensor2 = ms_torch.tensor(b) | |||
| ms_out1 = ms_torch.vstack((ms_tensor1.long(), ms_tensor2.double())) | |||
| param_compare(torch_out1, ms_out1) | |||
| def test_flipud(): | |||
| x = np.arange(4).reshape(2, 2).astype(np.int16) | |||
| @@ -1621,27 +1793,26 @@ def test_block_diag(): | |||
| def test_logspace(): | |||
| # TODO: for end=10, the result will be 1e10, which exceeds the upper limit of int16 and int32, | |||
| # and result in inconsistent behavior between pytorch and mindspore. | |||
| # Thus, change end=10 to end=8 for better maintainability | |||
| torch_out1 = torch.logspace(start=-10, end=8, steps=5, dtype=torch.int16) | |||
| torch_out2 = torch.logspace(start=0.1, end=1.0, steps=5, dtype=torch.float32) | |||
| torch_out3 = torch.logspace(start=0.1, end=1.0, steps=1, dtype=torch.int64) | |||
| torch_out4 = torch.logspace(start=2, end=2, steps=1, base=2) | |||
| ms_out1 = ms_torch.logspace(start=-10, end=8, steps=5, dtype=ms_torch.int16) | |||
| ms_out2 = ms_torch.logspace(start=0.1, end=1.0, steps=5, dtype= ms_torch.float32) | |||
| ms_out3 = ms_torch.logspace(start=0.1, end=1.0, steps=1, dtype=ms_torch.int64) | |||
| ms_out4 = ms_torch.logspace(start=2, end=2, steps=1, base=2) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| assert np.allclose(torch_out3.numpy(), ms_out3.numpy()) | |||
| assert torch_out3.numpy().dtype == ms_out3.numpy().dtype | |||
| assert np.allclose(torch_out4.numpy(), ms_out4.numpy()) | |||
| assert torch_out4.numpy().dtype == ms_out4.numpy().dtype | |||
| param_compare(ms_out2, torch_out2) | |||
| param_compare(ms_out3, torch_out3) | |||
| param_compare(ms_out4, torch_out4) | |||
| @SKIP_ENV_GPU(reason='ms.ops.logspace has bug on GPU') | |||
| def test_logspace_skip_gpu(): | |||
| # TODO: for end=10, the result will be 1e10, which exceeds the upper limit of int16 and int32, | |||
| # and result in inconsistent behavior between pytorch and mindspore. | |||
| # Thus, change end=10 to end=8 for better maintainability | |||
| torch_out1 = torch.logspace(start=-10, end=8, steps=5, dtype=torch.int16) | |||
| ms_out1 = ms_torch.logspace(start=-10, end=8, steps=5, dtype=ms_torch.int16) | |||
| param_compare(ms_out1, torch_out1) | |||
| def test_column_stack(): | |||
| x1 = np.array([1, 2, 3]) | |||
| @@ -1653,20 +1824,35 @@ def test_column_stack(): | |||
| torch_y1 = torch.tensor(y1) | |||
| torch_x2 = torch.tensor(x2) | |||
| torch_y2 = torch.tensor(y2) | |||
| torch_out1 = torch.column_stack([torch_x1, torch_y1]) | |||
| torch_out2 = torch.column_stack((torch_x2, torch_y2, torch_y2)) | |||
| torch_out1 = torch.column_stack([torch_x1.short(), torch_y1.bool()]) | |||
| torch_out2 = torch.column_stack([torch_x1.float(), torch_y1.int()]) | |||
| torch_out3 = torch.column_stack([torch_x2.byte(), torch_y2.bool()]) | |||
| ms_x1 = ms_torch.tensor(x1) | |||
| ms_y1 = ms_torch.tensor(y1) | |||
| ms_x2 = ms_torch.tensor(x2) | |||
| ms_y2 = ms_torch.tensor(y2) | |||
| ms_out1 = ms_torch.column_stack([ms_x1, ms_y1]) | |||
| ms_out2 = ms_torch.column_stack((ms_x2, ms_y2, ms_y2)) | |||
| ms_out1 = ms_torch.column_stack([ms_x1.short(), ms_y1.bool()]) | |||
| ms_out2 = ms_torch.column_stack([ms_x1.float(), ms_y1.int()]) | |||
| ms_out3 = ms_torch.column_stack([ms_x2.byte(), ms_y2.bool()]) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| param_compare(ms_out1, torch_out1) | |||
| param_compare(ms_out2, torch_out2) | |||
| param_compare(ms_out3, torch_out3) | |||
| @SKIP_ENV_ASCEND(reason="column_stack currently not support float64 on Ascend") | |||
| def test_column_stack_fp64(): | |||
| x1 = np.arange(5) | |||
| y1 = np.arange(10).reshape(5, 2) | |||
| torch_x1 = torch.tensor(x1) | |||
| torch_y1 = torch.tensor(y1) | |||
| ms_x1 = ms_torch.tensor(x1) | |||
| ms_y1 = ms_torch.tensor(y1) | |||
| torch_out1 = torch.column_stack((torch_x1.float(), torch_y1.float(), torch_y1.double())) | |||
| ms_out1 = ms_torch.column_stack((ms_x1.float(), ms_y1.float(), ms_y1.double())) | |||
| param_compare(ms_out1, torch_out1) | |||
| def test_hstack(): | |||
| x1 = np.array([1, 2, 3]) | |||
| @@ -1678,20 +1864,35 @@ def test_hstack(): | |||
| torch_y1 = torch.tensor(y1) | |||
| torch_x2 = torch.tensor(x2) | |||
| torch_y2 = torch.tensor(y2) | |||
| torch_out1 = torch.hstack([torch_x1, torch_y1]) | |||
| torch_out2 = torch.hstack((torch_x2, torch_y2)) | |||
| torch_out1 = torch.hstack((torch_x1.float(), torch_y1.short())) | |||
| torch_out2 = torch.hstack((torch_x2.byte(), torch_y2.int())) | |||
| ms_x1 = ms_torch.tensor(x1) | |||
| ms_y1 = ms_torch.tensor(y1) | |||
| ms_x2 = ms_torch.tensor(x2) | |||
| ms_y2 = ms_torch.tensor(y2) | |||
| ms_out1 = ms_torch.hstack([ms_x1, ms_y1]) | |||
| ms_out2 = ms_torch.hstack((ms_x2, ms_y2)) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| ms_out1 = ms_torch.hstack((ms_x1.float(), ms_y1.short())) | |||
| ms_out2 = ms_torch.hstack((ms_x2.byte(), ms_y2.int())) | |||
| param_compare(ms_out1, torch_out1) | |||
| param_compare(ms_out2, torch_out2) | |||
| @SKIP_ENV_ASCEND(reason="hstack currently not support float64 on Ascend") | |||
| def test_hstack_fp64(): | |||
| x1 = np.random.randn(1, 3) | |||
| y1 = np.random.randn(1, 3) | |||
| torch_x1 = torch.tensor(x1) | |||
| torch_y1 = torch.tensor(y1) | |||
| ms_x1 = ms_torch.tensor(x1) | |||
| ms_y1 = ms_torch.tensor(y1) | |||
| torch_out1 = torch.hstack([torch_x1.float(), torch_y1.double()]) | |||
| ms_out1 = ms_torch.hstack([ms_x1.float(), ms_y1.double()]) | |||
| param_compare(ms_out1, torch_out1) | |||
| def test_movedim(): | |||
| t = np.random.randn(3,2,1) | |||
| @@ -1703,10 +1904,8 @@ def test_movedim(): | |||
| ms_out1 = ms_torch.movedim(ms_t, 1, 0) | |||
| ms_out2 = ms_torch.movedim(ms_t, (1, 2), (0, 1)) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| param_compare(ms_out1, torch_out1) | |||
| param_compare(ms_out2, torch_out2) | |||
| def test_moveaxis(): | |||
| t = np.random.randn(2, 5, 4).astype(np.int16) | |||
| @@ -1718,10 +1917,8 @@ def test_moveaxis(): | |||
| ms_out1 = ms_torch.moveaxis(ms_t, -1, 0) | |||
| ms_out2 = ms_torch.moveaxis(ms_t, (-1, -2), (0, -1)) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| param_compare(ms_out1, torch_out1) | |||
| param_compare(ms_out2, torch_out2) | |||
| def test_swapdims(): | |||
| x1 = np.array([[[0,1],[2,3]],[[4,5],[6,7]]]) | |||
| @@ -1734,10 +1931,8 @@ def test_swapdims(): | |||
| ms_out1 = ms_torch.swapdims(ms_tensor1, 0, 1) | |||
| ms_out2 = ms_torch.swapdims(ms_tensor1, 0, 2) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| param_compare(ms_out1, torch_out1) | |||
| param_compare(ms_out2, torch_out2) | |||
| def test_swapaxes(): | |||
| x1 = np.array([[[0,1],[2,3]],[[4,5],[6,7]]]).astype(np.float32) | |||
| @@ -1750,10 +1945,8 @@ def test_swapaxes(): | |||
| ms_out1 = ms_torch.swapaxes(ms_tensor1, 0, 1) | |||
| ms_out2 = ms_torch.swapaxes(ms_tensor1, 0, 2) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| param_compare(ms_out1, torch_out1) | |||
| param_compare(ms_out2, torch_out2) | |||
| @SKIP_ENV_ASCEND(reason='ms tensor of shape 0 not supported on Ascend') | |||
| def test_swapaxes2(): | |||
| @@ -1765,12 +1958,8 @@ def test_swapaxes2(): | |||
| ms_out1 = ms_torch.swapaxes(ms_tensor1, 0, 1) | |||
| ms_out2 = ms_torch.swapaxes(ms_tensor1, 0, 2) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert torch_out1.numpy().shape == ms_out1.numpy().shape | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| assert torch_out2.numpy().shape == ms_out2.numpy().shape | |||
| param_compare(ms_out1, torch_out1) | |||
| param_compare(ms_out2, torch_out2) | |||
| def test_row_stack(): | |||
| a = np.random.randn(2, 3) * 20 | |||
| @@ -1778,18 +1967,16 @@ def test_row_stack(): | |||
| torch_tensor1 = torch.tensor(a) | |||
| torch_tensor2 = torch.tensor(b) | |||
| torch_out1 = torch.row_stack((torch_tensor1.int(), torch_tensor2.int())) | |||
| torch_out1 = torch.row_stack((torch_tensor1.int(), torch_tensor2.float())) | |||
| torch_out2 = torch.row_stack([torch_tensor1.float(), torch_tensor2.float()]) | |||
| ms_tensor1 = ms_torch.tensor(a) | |||
| ms_tensor2 = ms_torch.tensor(b) | |||
| ms_out1 = ms_torch.row_stack((ms_tensor1.int(), ms_tensor2.int())) | |||
| ms_out1 = ms_torch.row_stack((ms_tensor1.int(), ms_tensor2.float())) | |||
| ms_out2 = ms_torch.row_stack([ms_tensor1.float(), ms_tensor2.float()]) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| param_compare(ms_out1, torch_out1) | |||
| param_compare(ms_out2, torch_out2) | |||
| #TODO:Unsupported op [MatrixExp] on CPU | |||
| ''' | |||
| @@ -1886,12 +2073,10 @@ def test_triu_indices(): | |||
| ms_out2 = ms_torch.triu_indices(4, 3, -1, dtype=ms_torch.float32) | |||
| ms_out3 = ms_torch.triu_indices(4, 3, 1, dtype=ms_torch.uint8) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| assert np.allclose(torch_out3.numpy(), ms_out3.numpy()) | |||
| assert torch_out3.numpy().dtype == ms_out3.numpy().dtype | |||
| param_compare(ms_out1, torch_out1) | |||
| param_compare(ms_out2, torch_out2) | |||
| param_compare(ms_out3, torch_out3) | |||
| def test_argwhere(): | |||
| data = np.array([[1, 0, 1], [2, 3, 4]]) | |||
| @@ -2059,61 +2244,93 @@ def test_lcm(): | |||
| assert torch_out4.numpy().dtype == ms_out4.numpy().dtype | |||
| def test_renorm(): | |||
| x = np.ones((3, 3)) | |||
| x = np.ones((3, 3)).astype(np.float32) | |||
| x[1].fill(2) | |||
| x[2].fill(3) | |||
| torch_x = torch.tensor(x) | |||
| torch_out1 = torch.renorm(torch_x, 1, 0, 5) | |||
| torch_out2 = torch.renorm(torch_x, 2, 1, 2) | |||
| torch_out3 = torch.renorm(torch_x, 2., 1, 2.) | |||
| ms_x = ms_torch.tensor(x) | |||
| ms_out1 = ms_torch.renorm(ms_x, 1, 0, 5) | |||
| ms_out2 = ms_torch.renorm(ms_x, 2, 1, 2) | |||
| ms_out3 = ms_torch.renorm(ms_x, 2., 1, 2.) | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2) | |||
| param_compare(torch_out3, ms_out3) | |||
| @SKIP_ENV_ASCEND(reason='vdot do not support float64 input on Ascend') | |||
| def test_renorm_fp64(): | |||
| x = np.ones((2, 2)) | |||
| x[0].fill(2) | |||
| x[1].fill(3) | |||
| torch_x = torch.tensor(x) | |||
| torch_out1 = torch.renorm(torch_x, 1, 0, 5) | |||
| torch_out2 = torch.renorm(torch_x.double(), 2, 1, 2) | |||
| torch_out3 = torch.renorm(torch_x.double(), 2., 1, 2.) | |||
| ms_x = ms_torch.tensor(x) | |||
| ms_out1 = ms_torch.renorm(ms_x, 1, 0, 5) | |||
| ms_out2 = ms_torch.renorm(ms_x.double(), 2, 1, 2) | |||
| ms_out3 = ms_torch.renorm(ms_x.double(), 2., 1, 2.) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| assert np.allclose(torch_out3.numpy(), ms_out3.numpy()) | |||
| assert torch_out3.numpy().dtype == ms_out3.numpy().dtype | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2) | |||
| def test_tensordot(): | |||
| a1 = np.arange(60.).reshape(3, 4, 5) | |||
| b1 = np.arange(24.).reshape(4, 3, 2) | |||
| a2 = np.random.randn(3, 4, 5).astype(np.float64) | |||
| b2 = np.random.randn(4, 5, 6).astype(np.float64) | |||
| a3 = np.random.randn(3, 5, 4, 6) | |||
| b3 = np.random.randn(6, 4, 5, 3) | |||
| a1 = np.arange(60.).reshape(3, 4, 5).astype(np.float32) | |||
| b1 = np.arange(24.).reshape(4, 3, 2).astype(np.float32) | |||
| a2 = np.random.randn(3, 4, 5).astype(np.float32) | |||
| b2 = np.random.randn(4, 5, 6).astype(np.float32) | |||
| torch_a1 = torch.tensor(a1) | |||
| torch_b1 = torch.tensor(b1) | |||
| torch_a2 = torch.tensor(a2) | |||
| torch_b2 = torch.tensor(b2) | |||
| torch_a3 = torch.tensor(a3) | |||
| torch_b3 = torch.tensor(b3) | |||
| ms_a1 = ms_torch.tensor(a1) | |||
| ms_b1 = ms_torch.tensor(b1) | |||
| ms_a2 = ms_torch.tensor(a2) | |||
| ms_b2 = ms_torch.tensor(b2) | |||
| ms_a3 = ms_torch.tensor(a3) | |||
| ms_b3 = ms_torch.tensor(b3) | |||
| torch_out1 = torch.tensordot(torch_a1, torch_b1, dims=([1, 0], [0, 1])) | |||
| torch_out2 = torch.tensordot(torch_a2, torch_b2, dims=2) | |||
| torch_out3 = torch.tensordot(torch_a3, torch_b3, dims=([2, 1, 3], [1, 2, 0])) | |||
| ms_out1 = ms_torch.tensordot(ms_a1, ms_b1, dims=([1, 0], [0, 1])) | |||
| ms_out2 = ms_torch.tensordot(ms_a2, ms_b2, dims=2) | |||
| ms_out3 = ms_torch.tensordot(ms_a3, ms_b3, dims=([2, 1, 3], [1, 2, 0])) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| assert np.allclose(torch_out3.numpy(), ms_out3.numpy()) | |||
| assert torch_out3.numpy().dtype == ms_out3.numpy().dtype | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2, atol=1e-4) | |||
| @SKIP_ENV_GPU(reason="tensordot currently not support int on Ascend") | |||
| def test_tensordot_int(): | |||
| a1 = np.random.randn(3, 4, 5).astype(np.int32) | |||
| b1 = np.random.randn(4, 3, 2).astype(np.int32) | |||
| torch_a1 = torch.tensor(a1) | |||
| torch_b1 = torch.tensor(b1) | |||
| ms_a1 = ms_torch.tensor(a1) | |||
| ms_b1 = ms_torch.tensor(b1) | |||
| torch_out1 = torch.tensordot(torch_a1, torch_b1, dims=([1, 0], [0, 1])) | |||
| ms_out1 = ms_torch.tensordot(ms_a1, ms_b1, dims=([1, 0], [0, 1])) | |||
| param_compare(torch_out1, ms_out1) | |||
| @SKIP_ENV_ASCEND(reason="tensordot currently not support float64 on Ascend") | |||
| def test_tensordot_fp64(): | |||
| a1 = np.random.randn(3, 4, 5) | |||
| b1 = np.random.randn(4, 3, 2) | |||
| torch_a1 = torch.tensor(a1) | |||
| torch_b1 = torch.tensor(b1) | |||
| ms_a1 = ms_torch.tensor(a1) | |||
| ms_b1 = ms_torch.tensor(b1) | |||
| torch_out1 = torch.tensordot(torch_a1, torch_b1, dims=([1, 0],[0, 1])) | |||
| ms_out1 = ms_torch.tensordot(ms_a1, ms_b1, dims=([1, 0],[0, 1])) | |||
| param_compare(torch_out1, ms_out1) | |||
| def test_randn_like(): | |||
| x = np.ones((2, 3, 4)) | |||
| @@ -2261,6 +2478,10 @@ def test_index_add(): | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| # TODO: index_add to support input of more than 2-D & dim >= 1 | |||
| # test fails on Ascend | |||
| @SKIP_ENV_ASCEND(reason="index_add doesn't support input of more than 2-D & dim >= 1 on Ascend") | |||
| def test_index_add_dim2(): | |||
| x2 = np.ones((1, 1, 2), dtype=np.int64) | |||
| t2 = np.array([[[2, 5, 4]]], dtype=np.int64) | |||
| index2 = np.array([0, 1, 0]) | |||
| @@ -2307,6 +2528,7 @@ def test_index_copy(): | |||
| # assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| # assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| @SKIP_ENV_ASCEND(reason="scatter_add requires updates_shape=indices_shape + input_x_shape[1:] on ascend") | |||
| def test_scatter_add(): | |||
| src_np1 = np.ones((2, 5)) | |||
| index_np1 = np.array([[0, 1, 2, 0, 0], [0, 1, 2, 0, 0]]) | |||
| @@ -2323,8 +2545,7 @@ def test_scatter_add(): | |||
| ms_input1 = ms_torch.tensor(input_np1) | |||
| ms_out1 = ms_torch.scatter_add(ms_input1, 0, ms_index1, ms_src1) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| param_compare(ms_out1, torch_out1) | |||
| def test_std_mean(): | |||
| a1 = np.array([[-0.8166, -1.3802, -0.3560]]) | |||
| @@ -2417,31 +2638,27 @@ def test_select_scatter(): | |||
| def test_dstack(): | |||
| a1 = np.array([1, 2, 3]) | |||
| # a1 = np.array([1, 2, 3]).astype(np.float32) | |||
| b1 = np.array([4, 5, 6]) | |||
| # b1 = np.array([4, 5, 6]).astype(np.int16) | |||
| torch_a1 = torch.tensor(a1) | |||
| torch_b1 = torch.tensor(b1) | |||
| torch_out1 = torch.dstack([torch_a1, torch_b1]) | |||
| torch_out1 = torch.dstack([torch_a1.byte(), torch_b1.char()]) | |||
| ms_a1 = ms_torch.tensor(a1) | |||
| ms_b1 = ms_torch.tensor(b1) | |||
| ms_out1 = ms_torch.dstack([ms_a1, ms_b1]) | |||
| ms_out1 = ms_torch.dstack([ms_a1.byte(), ms_b1.char()]) | |||
| a2 = np.array([[1],[2],[3]]) | |||
| b2 = np.array([[4],[5],[6]]) | |||
| a2 = np.array([[1],[2],[3]]).astype(np.float64) | |||
| b2 = np.array([[4],[5],[6]]).astype(np.float64) | |||
| torch_a2 = torch.tensor(a2) | |||
| torch_b2 = torch.tensor(b2) | |||
| torch_out2 = torch.dstack((torch_a2, torch_b2)) | |||
| torch_out2 = torch.dstack((torch_a2.float(), torch_b2.long())) | |||
| ms_a2 = ms_torch.tensor(a2) | |||
| ms_b2 = ms_torch.tensor(b2) | |||
| ms_out2 = ms_torch.dstack((ms_a2, ms_b2)) | |||
| ms_out2 = ms_torch.dstack((ms_a2.float(), ms_b2.long())) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| param_compare(ms_out1, torch_out1) | |||
| param_compare(ms_out2, torch_out2) | |||
| def test_randint_like(): | |||
| a = np.random.rand(3, 2, 1) | |||
| @@ -2512,21 +2729,31 @@ def test_combinations(): | |||
| a = [1, 2, 3] | |||
| torch_a = torch.tensor(a) | |||
| torch_out1 = torch.combinations(torch_a) | |||
| torch_out2 = torch.combinations(torch_a.short(), r=3) | |||
| torch_out3 = torch.combinations(torch_a.double(), with_replacement=True) | |||
| ms_a = ms_torch.tensor(a) | |||
| ms_out1 = ms_torch.combinations(ms_a) | |||
| ms_out2 = ms_torch.combinations(ms_a.short(), r=3) | |||
| ms_out3 = ms_torch.combinations(ms_a.double(), with_replacement=True) | |||
| torch_out2 = torch.combinations(torch_a.byte(), r=3) | |||
| torch_out3 = torch.combinations(torch_a.float(), with_replacement=True) | |||
| ms_out2 = ms_torch.combinations(ms_a.byte(), r=3) | |||
| ms_out3 = ms_torch.combinations(ms_a.float(), with_replacement=True) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| assert np.allclose(torch_out3.numpy(), ms_out3.numpy()) | |||
| assert torch_out3.numpy().dtype == ms_out3.numpy().dtype | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2) | |||
| param_compare(torch_out3, ms_out3) | |||
| @SKIP_ENV_ASCEND(reason="combinations currently not support float64 and int16 on Ascend") | |||
| def test_combinations_fp64(): | |||
| a = np.random.randn(3) | |||
| torch_a = torch.tensor(a) | |||
| ms_a = ms_torch.tensor(a) | |||
| torch_out1 = torch.combinations(torch_a.double(), with_replacement=True) | |||
| torch_out2 = torch.combinations(torch_a.short(), r=3) | |||
| ms_out1 = ms_torch.combinations(ms_a.double(), with_replacement=True) | |||
| ms_out2 = ms_torch.combinations(ms_a.short(), r=3) | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2) | |||
| def test_fmax(): | |||
| a = torch.tensor([1., float('nan'), 3, float('nan')]) | |||
| @@ -2743,10 +2970,8 @@ def test_scatter_reduce_sum(): | |||
| ms_out1 = ms_torch.scatter_reduce(ms_input, 0, ms_index, ms_src, reduce="sum") | |||
| ms_out2 = ms_torch.scatter_reduce(ms_input, 0, ms_index, ms_src, reduce="sum", include_self=False) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| param_compare(ms_out1, torch_out1) | |||
| param_compare(ms_out2, torch_out2) | |||
| def test_scatter_reduce_amax(): | |||
| torch_src = torch.tensor([1., 2., 3., 4., 5., 6.]) | |||
| @@ -2761,10 +2986,8 @@ def test_scatter_reduce_amax(): | |||
| ms_out3 = ms_torch.scatter_reduce(ms_input2, 0, ms_index, ms_src, reduce="amax") | |||
| ms_out4 = ms_torch.scatter_reduce(ms_input2, 0, ms_index, ms_src, reduce="amax", include_self=False) | |||
| assert np.allclose(torch_out3.numpy(), ms_out3.numpy()) | |||
| assert torch_out3.numpy().dtype == ms_out3.numpy().dtype | |||
| assert np.allclose(torch_out4.numpy(), ms_out4.numpy()) | |||
| assert torch_out4.numpy().dtype == ms_out4.numpy().dtype | |||
| param_compare(ms_out3, torch_out3) | |||
| param_compare(ms_out4, torch_out4) | |||
| def test_scatter_reduce_amin(): | |||
| torch_src = torch.tensor([1., 2., 3., 4., 5., 6.]) | |||
| @@ -2779,10 +3002,8 @@ def test_scatter_reduce_amin(): | |||
| ms_out7 = ms_torch.scatter_reduce(ms_input, 0, ms_index, ms_src, reduce="amin") | |||
| ms_out8 = ms_torch.scatter_reduce(ms_input, 0, ms_index, ms_src, reduce="amin", include_self=False) | |||
| assert np.allclose(torch_out7.numpy(), ms_out7.numpy()) | |||
| assert torch_out7.numpy().dtype == ms_out7.numpy().dtype | |||
| assert np.allclose(torch_out8.numpy(), ms_out8.numpy()) | |||
| assert torch_out8.numpy().dtype == ms_out8.numpy().dtype | |||
| param_compare(ms_out7, torch_out7) | |||
| param_compare(ms_out8, torch_out8) | |||
| def test_scatter_reduce_prod(): | |||
| torch_src = torch.tensor([1., 2., 3., 4., 5., 6.]) | |||
| @@ -2797,10 +3018,8 @@ def test_scatter_reduce_prod(): | |||
| ms_out5 = ms_torch.scatter_reduce(ms_input, 0, ms_index, ms_src, reduce="prod") | |||
| ms_out6 = ms_torch.scatter_reduce(ms_input, 0, ms_index, ms_src, reduce="prod", include_self=False) | |||
| assert np.allclose(torch_out5.numpy(), ms_out5.numpy()) | |||
| assert torch_out5.numpy().dtype == ms_out5.numpy().dtype | |||
| assert np.allclose(torch_out6.numpy(), ms_out6.numpy()) | |||
| assert torch_out6.numpy().dtype == ms_out6.numpy().dtype | |||
| param_compare(ms_out5, torch_out5) | |||
| param_compare(ms_out6, torch_out6) | |||
| def test_asarray(): | |||
| array = ms.numpy.array([1, 2, 3]) | |||
| @@ -2838,6 +3057,25 @@ def test_result_type(): | |||
| ms_out2 = ms_torch.result_type(ms_tensor1, 1.0) | |||
| assert str(ms_out2).upper() == str(torch_out2)[6:].upper() | |||
| def test_promote_types(): | |||
| for type1 in [bool, np.bool_, np.uint8, np.int8, np.int16, np.int32, int, \ | |||
| np.int64, np.float16, np.float32, np.float64, float, np.complex64, np.complex128]: | |||
| for type2 in [np.bool_, np.uint8, np.int8, np.int16, np.int32, int, \ | |||
| np.int64, np.float32, np.float64, float, np.complex64, np.complex128]: | |||
| t_type1 = torch.tensor(np.array([1]).astype(type1)).dtype | |||
| t_type2 = torch.tensor(np.array([1]).astype(type2)).dtype | |||
| ms_type1 = ms_torch.tensor(np.array([1]).astype(type1)).dtype | |||
| ms_type2 = ms_torch.tensor(np.array([1]).astype(type2)).dtype | |||
| torch_out1 = torch.promote_types(t_type1, t_type2) | |||
| ms_out1 = ms_torch.promote_types(ms_type1, ms_type2) | |||
| assert str(ms_out1).upper() == str(torch_out1)[6:].upper() | |||
| @ms.jit | |||
| def my_test(ms_type1, ms_type2): | |||
| ms_out = ms_torch.promote_types(ms_type1, ms_type2) | |||
| return ms_out | |||
| ms_out1 = my_test(ms_type1, ms_type2) | |||
| assert str(ms_out1).upper() == str(torch_out1)[6:].upper() | |||
| def test_complex(): | |||
| for type1 in (np.float32, np.float64): | |||
| real_array1 = np.random.randn(3, 3).astype(type1) | |||
| @@ -2868,24 +3106,22 @@ def test_index_reduce_amin_float64(): | |||
| torch.arange(-4, -1, dtype=torch.float64), 'amin') | |||
| ms_out = ms_torch.index_reduce(ms_torch.full((5,), 2, dtype=ms_torch.float64), 0, ms_torch.tensor([1, 2, 3]), | |||
| ms_torch.arange(-4, -1, dtype=ms_torch.float64), 'amin') | |||
| assert np.allclose(torch_out.numpy(), ms_out.numpy()) | |||
| assert torch_out.numpy().dtype == ms_out.numpy().dtype | |||
| param_compare(ms_out, torch_out) | |||
| def test_index_reduce_amin(): | |||
| torch_out2 = torch.index_reduce(torch.full((5,), 3, dtype=torch.float32), 0, torch.tensor([0, 1, 3]), | |||
| torch.arange(2, 5, dtype=torch.float32), 'amin', include_self=False) | |||
| ms_out2 = ms_torch.index_reduce(ms_torch.full((5,), 3, dtype=ms_torch.float32), 0, ms_torch.tensor([0, 1, 3]), | |||
| ms_torch.arange(2, 5, dtype=ms_torch.float32), 'amin', include_self=False) | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| param_compare(ms_out2, torch_out2) | |||
| def test_index_reduce_amax(): | |||
| torch_out = torch.index_reduce(torch.full((2, 3, 4, 5), 10, dtype=torch.float16), 3, | |||
| torch.tensor([1, 0, 3]), torch.arange(1, 73).half().reshape(2,3,4,3), 'amax') | |||
| ms_out = ms_torch.index_reduce(ms_torch.full((2, 3, 4, 5), 10, dtype=ms_torch.float16), 3, | |||
| ms_torch.tensor([1, 0, 3]), ms_torch.arange(1, 73).half().reshape(2,3,4,3), 'amax') | |||
| assert np.allclose(torch_out.numpy(), ms_out.numpy()) | |||
| assert torch_out.numpy().dtype == ms_out.numpy().dtype | |||
| param_compare(ms_out, torch_out) | |||
| def test_index_reduce_prod(): | |||
| torch_out = torch.index_reduce(torch.full((2, 3, 4, 5), 10, dtype=torch.float16), 3, | |||
| @@ -2894,9 +3130,7 @@ def test_index_reduce_prod(): | |||
| ms_out = ms_torch.index_reduce(ms_torch.full((2, 3, 4, 5), 10, dtype=ms_torch.float16), 3, | |||
| ms_torch.tensor([1, 0, 3]), ms_torch.arange(1, 73).half().reshape(2,3,4,3), 'prod', | |||
| include_self=False) | |||
| assert np.allclose(torch_out.numpy(), ms_out.numpy()) | |||
| assert torch_out.numpy().dtype == ms_out.numpy().dtype | |||
| param_compare(ms_out, torch_out) | |||
| def test_can_cast(): | |||
| for type1 in [np.bool_, np.uint8, np.int8, np.int16, np.int32, \ | |||
| @@ -2958,50 +3192,90 @@ def test_diagonal_scatter(): | |||
| param_compare(ms_out1, torch_out1) | |||
| param_compare(ms_out2, torch_out2) | |||
| @SKIP_ENV_GPU(reason="nanmedian is not supported on GPU") | |||
| @SKIP_ENV_ASCEND(reason="nanmedian is not supported on Ascend") | |||
| def test_nanmedian1(): | |||
| torch_a = torch.tensor([[2, 3, 1], [float('nan'), 1, float('nan')]]) | |||
| torch_out = torch.nanmedian(torch_a, 1, keepdim=True) | |||
| ms_a = ms_torch.tensor([[2, 3, 1], [float('nan'), 1, float('nan')]]) | |||
| ms_out = ms_torch.nanmedian(ms_a, 1, keepdim=True) | |||
| param_compare(torch_out[0], ms_out[0], equal_nan=True) | |||
| param_compare(torch_out[1], ms_out[1]) | |||
| @SKIP_ENV_GPU(reason="nanmedian is not supported on GPU") | |||
| @SKIP_ENV_ASCEND(reason="nanmedian is not supported on Ascend") | |||
| def test_nanmedian2(): | |||
| x = np.random.randint(0, 5, (2, 3, 4)).astype(np.float32) | |||
| mask = np.random.randint(0, 2, (2, 3, 4)).astype(np.bool8) | |||
| torch_x = torch.tensor(x) | |||
| torch_mask = torch.tensor(mask) | |||
| torch_in = torch_x.masked_fill(torch_mask, float('nan')) | |||
| ms_x = ms_torch.tensor(x) | |||
| ms_mask = ms_torch.tensor(mask) | |||
| ms_in = ms_x.masked_fill(ms_mask, float('nan')) | |||
| torch_out2 = torch.nanmedian(torch_in, 2, keepdim=True) | |||
| ms_out2 = ms_torch.nanmedian(ms_in, 2, keepdim=True) | |||
| param_compare(torch_out2[0], ms_out2[0], equal_nan=True) | |||
| param_compare(torch_out2[1], ms_out2[1]) | |||
| torch_out3 = torch.nanmedian(torch_in) | |||
| ms_out3 = ms_torch.nanmedian(ms_in) | |||
| assert np.allclose(torch_out3.numpy(), ms_out3.numpy(), equal_nan=True) | |||
| assert torch_out3.numpy().dtype == ms_out3.numpy().dtype | |||
| def test_all1(): | |||
| data = np.array([[0, 1], [2, 3]]) | |||
| torch_input = torch.tensor(data) | |||
| torch_out = torch.all(torch_input) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.all(ms_input) | |||
| param_compare(torch_out, ms_out) | |||
| def test_all2(): | |||
| data = np.array([[0., 1.], [2., 3.]]) | |||
| torch_input = torch.tensor(data) | |||
| torch_out = torch.all(torch_input, dim=0) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.all(ms_input, dim=0) | |||
| param_compare(torch_out, ms_out) | |||
| def test_randn(): | |||
| size = () | |||
| torch_out = torch.randn(size) | |||
| ms_out = ms_torch.randn(size) | |||
| type_shape_compare(torch_out, ms_out) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
| test_range1() | |||
| test_range2() | |||
| test_astensor() | |||
| test_zeros_like() | |||
| test_ones_like() | |||
| test_empty_like() | |||
| test_full() | |||
| test_full_like() | |||
| test_where() | |||
| test_where2() | |||
| test_seed() | |||
| test_rand() | |||
| test_linspace() | |||
| test_take() | |||
| test_abs() | |||
| test_abs1() | |||
| test_atan2() | |||
| test_clamp() | |||
| test_cos() | |||
| test_fft() | |||
| test_fmod() | |||
| test_frac() | |||
| test_log() | |||
| test_sin() | |||
| test_norm_p_inf() | |||
| test_norm_p_minus_inf() | |||
| test_norm_p_minus_1() | |||
| @@ -3011,28 +3285,20 @@ if __name__ == '__main__': | |||
| test_norm_p_1() | |||
| test_norm_p_2() | |||
| test_norm_p_2_jit() | |||
| test_bartlett_window() | |||
| test_hamming_window() | |||
| test_hann_windoww() | |||
| test_cumsum() | |||
| test_einsum() | |||
| test_histc() | |||
| test_triu() | |||
| test_index_select() | |||
| test_bmm() | |||
| test_baddbmm() | |||
| test_argmin() | |||
| test_argmax() | |||
| test_broadcast_to() | |||
| test_ravel() | |||
| test_numel() | |||
| test_logsumexp() | |||
| test_addmv() | |||
| @@ -3103,6 +3369,7 @@ if __name__ == '__main__': | |||
| test_kron() | |||
| test_gcd() | |||
| test_index_add() | |||
| test_index_add_dim2() | |||
| test_index_copy() | |||
| test_scatter_add() | |||
| test_std_mean() | |||
| @@ -3142,3 +3409,25 @@ if __name__ == '__main__': | |||
| test_deterministic_apis() | |||
| test_diagonal_scatter() | |||
| test_empty_like_fp64() | |||
| test_all1() | |||
| test_all2() | |||
| test_nanmedian1() | |||
| test_nanmedian2() | |||
| test_cholesky_solve() | |||
| test_cholesky_solve_fp64() | |||
| test_renorm_fp64() | |||
| test_bmm_fp64() | |||
| test_baddbmm_fp64() | |||
| test_addbmm_fp64() | |||
| test_addmm_fp64() | |||
| test_cholesky_fp64() | |||
| test_cholesky_inverse_fp64() | |||
| test_vstack_fp64() | |||
| test_column_stack_fp64() | |||
| test_hstack_fp64() | |||
| test_combinations_fp64() | |||
| test_abs_fp64() | |||
| test_abs_int() | |||
| test_promote_types() | |||
| test_tensordot_int() | |||
| test_randn() | |||
+ 330
- 69
testing/ut/pytorch/functional/test_linalg.py
View File
| @@ -7,8 +7,9 @@ import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from msadapter.utils import is_under_gpu_context | |||
| from ...utils import SKIP_ENV_ASCEND, SKIP_ENV_CPU, SKIP_ENV_GPU, SKIP_ENV_GRAPH_MODE, is_test_under_ascend_context, is_test_under_pynative_context, param_compare, \ | |||
| type_shape_compare, SKIP_ENV_ASCEND_GRAPH_MODE, is_test_under_gpu_context, grad_test | |||
| from ...utils import SKIP_ENV_ASCEND, SKIP_ENV_CPU, SKIP_ENV_GPU, SKIP_ENV_GRAPH_MODE, is_test_under_ascend_context, \ | |||
| is_test_under_pynative_context, param_compare, type_shape_compare, SKIP_ENV_ASCEND_GRAPH_MODE, \ | |||
| is_test_under_gpu_context, grad_test | |||
| from ...utils import set_mode_by_env_config | |||
| set_mode_by_env_config() | |||
| @@ -27,8 +28,9 @@ def test_eigh(): | |||
| assert np.allclose(torch_l.numpy(), ms_l.numpy()) | |||
| assert np.allclose(torch_q.numpy(), ms_q.numpy()) | |||
| @SKIP_ENV_GRAPH_MODE(reason='solve not support on graph mode') | |||
| def test_solve(): | |||
| a = np.random.randn(3,3) | |||
| a = np.random.randn(3, 3) | |||
| b = np.random.randn(3,) | |||
| torch_a = torch.tensor(a) | |||
| @@ -40,14 +42,17 @@ def test_solve(): | |||
| torch_x = torch.linalg.solve(torch_a, torch_b) | |||
| ms_x = ms_torch.linalg.solve(ms_a, ms_b) | |||
| #TODO: mindspore has problem supporting numpy trans to ms.Tensor | |||
| ''' | |||
| @ms.jit | |||
| def func(a, b): | |||
| x = ms_torch.linalg.solve(a, b) | |||
| return x | |||
| ms_x1 = func(ms_a, ms_b) | |||
| ''' | |||
| param_compare(torch_x, ms_x) | |||
| param_compare(torch_x, ms_x1) | |||
| #param_compare(torch_x, ms_x1) | |||
| def test_slogdet(): | |||
| data1 = np.random.randn(3, 3) | |||
| @@ -90,29 +95,77 @@ def test_det(): | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| def test_cholesky(): | |||
| # A1 = np.random.randn(2, 2).astype(np.complex128) | |||
| A1 = np.random.randn(2, 2).astype(np.int64) | |||
| A1 = A1 @ A1.T.conj() + np.eye(2) | |||
| A2 = np.random.randn(3, 2, 2).astype(np.float64) | |||
| A1 = np.random.randn(3, 2, 2).astype(np.float32) | |||
| torch_A1 = torch.tensor(A1) | |||
| torch_A1 = torch_A1 @ torch_A1.mT.conj() + torch.eye(2) | |||
| torch_out1 = torch.linalg.cholesky(torch_A1) | |||
| ms_A1 = ms_torch.tensor(A1) | |||
| ms_A1 = ms_A1 @ ms_A1.mT.conj() + ms_torch.eye(2) | |||
| ms_out1 = ms_torch.linalg.cholesky(ms_A1) | |||
| param_compare(torch_out1, ms_out1) | |||
| @SKIP_ENV_ASCEND(reason="cholesky currently not support float64 on Ascend") | |||
| def test_cholesky_fp64(): | |||
| A1 = np.random.randn(2, 2).astype(np.float64) | |||
| A1 = A1 @ A1.T.conj() + np.eye(2).astype(np.float64) | |||
| torch_A1 = torch.tensor(A1) | |||
| torch_A1 = torch_A1 @ torch_A1.T.conj() + torch.eye(2) | |||
| torch_out1 = torch.linalg.cholesky(torch_A1) | |||
| torch_A2 = torch.tensor(A2) | |||
| torch_A2 = torch_A2 @ torch_A2.mT.conj() + torch.eye(2) | |||
| torch_out2 = torch.linalg.cholesky(torch_A2) | |||
| ms_A1 = ms_torch.tensor(A1) | |||
| ms_A1 = ms_A1 @ ms_A1.T.conj() + ms_torch.eye(2) | |||
| ms_out1 = ms_torch.linalg.cholesky(ms_A1) | |||
| ms_A2 = ms_torch.tensor(A2) | |||
| ms_A2 = ms_A2 @ ms_A2.mT.conj() + ms_torch.eye(2) | |||
| ms_out2 = ms_torch.linalg.cholesky(ms_A2) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| param_compare(torch_out1, ms_out1) | |||
| def test_cholesky_ex(): | |||
| A1 = np.random.randn(3, 2, 2).astype(np.float32) | |||
| torch_A1 = torch.tensor(A1) | |||
| torch_A1 = torch_A1 @ torch_A1.mT.conj() + torch.eye(2) | |||
| torch_out1 = torch.linalg.cholesky_ex(torch_A1) | |||
| torch_out2 = torch.linalg.cholesky_ex(torch_A1, upper=True) | |||
| ms_A1 = ms_torch.tensor(A1) | |||
| ms_A1 = ms_A1 @ ms_A1.mT.conj() + ms_torch.eye(2) | |||
| ms_out1 = ms_torch.linalg.cholesky_ex(ms_A1) | |||
| ms_out2 = ms_torch.linalg.cholesky_ex(ms_A1, upper=True) | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2) | |||
| @SKIP_ENV_GPU(reason="cholesky_ex currently not support int32 input on GPU") | |||
| def test_cholesky_ex_int(): | |||
| A1 = np.random.randn(2, 2).astype(np.int32) | |||
| torch_A1 = torch.tensor(A1) | |||
| torch_A1 = torch_A1 @ torch_A1.mT.conj() + torch.eye(2) | |||
| torch_out1, torch_info = torch.linalg.cholesky_ex(torch_A1) | |||
| ms_A1 = ms_torch.tensor(A1) | |||
| ms_A1 = ms_A1 @ ms_A1.mT.conj() + ms_torch.eye(2) | |||
| ms_out1, ms_info = ms_torch.linalg.cholesky_ex(ms_A1) | |||
| param_compare(torch_out1, ms_out1) | |||
| assert torch_info == ms_info | |||
| @SKIP_ENV_ASCEND(reason="cholesky_ex currently not support float64 on Ascend") | |||
| def test_cholesky_ex_fp64(): | |||
| A1 = np.random.randn(2, 2) | |||
| torch_A1 = torch.tensor(A1) | |||
| torch_A1 = torch_A1 @ torch_A1.mT.conj() + torch.eye(2) | |||
| torch_out1, torch_info1 = torch.linalg.cholesky_ex(torch_A1) | |||
| ms_A1 = ms_torch.tensor(A1) | |||
| ms_A1 = ms_A1 @ ms_A1.mT.conj() + ms_torch.eye(2) | |||
| ms_out1, ms_info1 = ms_torch.linalg.cholesky_ex(ms_A1) | |||
| param_compare(torch_out1, ms_out1) | |||
| assert torch_info1 == ms_info1 | |||
| def test_inv(): | |||
| A = np.random.randn(4, 4) | |||
| @@ -120,24 +173,41 @@ def test_inv(): | |||
| ms_A = ms_torch.tensor(A) | |||
| torch_out = torch.linalg.inv(torch_A) | |||
| ms_out = ms_torch.linalg.inv(ms_A) | |||
| assert np.allclose(torch_out.numpy(), ms_out.numpy()) | |||
| assert torch_out.numpy().dtype == ms_out.numpy().dtype | |||
| param_compare(torch_out, ms_out) | |||
| A = np.random.randn(2, 3, 4, 4) | |||
| torch_A = torch.tensor(A) | |||
| ms_A = ms_torch.tensor(A) | |||
| torch_out = torch.linalg.inv(torch_A) | |||
| ms_out = ms_torch.linalg.inv(ms_A) | |||
| assert np.allclose(torch_out.numpy(), ms_out.numpy()) | |||
| assert torch_out.numpy().dtype == ms_out.numpy().dtype | |||
| param_compare(torch_out, ms_out) | |||
| @SKIP_ENV_ASCEND(reason="inv currently not support complex128 on Ascend") | |||
| def test_inv_complex(): | |||
| A = np.random.randn(4, 4).astype(np.complex128) | |||
| torch_A = torch.tensor(A) | |||
| ms_A = ms_torch.tensor(A) | |||
| torch_out = torch.linalg.inv(torch_A) | |||
| ms_out = ms_torch.linalg.inv(ms_A) | |||
| assert np.allclose(torch_out.numpy(), ms_out.numpy()) | |||
| assert torch_out.numpy().dtype == ms_out.numpy().dtype | |||
| param_compare(torch_out, ms_out) | |||
| def test_inv_ex(): | |||
| A = np.random.randn(2, 3, 4, 4) | |||
| torch_A = torch.tensor(A) | |||
| ms_A = ms_torch.tensor(A) | |||
| torch_out = torch.linalg.inv_ex(torch_A) | |||
| ms_out = ms_torch.linalg.inv_ex(ms_A) | |||
| param_compare(torch_out, ms_out) | |||
| @SKIP_ENV_ASCEND(reason="inv_ex currently not support complex128 on Ascend") | |||
| def test_inv_ex_complex(): | |||
| A = np.random.randn(4, 4).astype(np.complex128) | |||
| torch_A = torch.tensor(A) | |||
| ms_A = ms_torch.tensor(A) | |||
| torch_out, torch_info = torch.linalg.inv_ex(torch_A) | |||
| ms_out, ms_info = ms_torch.linalg.inv_ex(ms_A) | |||
| param_compare(torch_out, ms_out) | |||
| assert torch_info == ms_info | |||
| @SKIP_ENV_ASCEND(reason='matmul not support input dtype as float64 on Ascend') | |||
| def test_matmul_float64(): | |||
| @@ -149,8 +219,7 @@ def test_matmul_float64(): | |||
| ms_tensor1 = ms_torch.tensor(a) | |||
| ms_tensor2 = ms_torch.tensor(b) | |||
| ms_out1 = ms_torch.linalg.matmul(ms_tensor1, ms_tensor2) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| param_compare(torch_out1, ms_out1) | |||
| @SKIP_ENV_GPU(reason='matmul not support input dtype as complex128 on GPU') | |||
| @SKIP_ENV_ASCEND(reason='matmul not support input dtype as complex128 on Ascend') | |||
| @@ -163,10 +232,8 @@ def test_matmul_complex128(): | |||
| ms_tensor1 = ms_torch.tensor(a) | |||
| ms_tensor2 = ms_torch.tensor(b) | |||
| ms_out2 = ms_torch.linalg.matmul(ms_tensor1, ms_tensor2) | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| param_compare(torch_out2, ms_out2) | |||
| @SKIP_ENV_GPU(reason='matmul not support input dtype as int32') | |||
| def test_matmul_int32(): | |||
| a = np.random.randn(10, 3, 4).astype(np.int32) | |||
| b = np.random.randn(4, 5).astype(np.int32) | |||
| @@ -177,8 +244,7 @@ def test_matmul_int32(): | |||
| ms_tensor2 = ms_torch.tensor(b) | |||
| ms_out3 = ms_torch.linalg.matmul(ms_tensor1, ms_tensor2) | |||
| assert np.allclose(torch_out3.numpy(), ms_out3.numpy()) | |||
| assert torch_out3.numpy().dtype == ms_out3.numpy().dtype | |||
| param_compare(torch_out3, ms_out3) | |||
| def test_diagonal(): | |||
| a = np.random.randn(3, 3).astype(np.float64) | |||
| @@ -207,11 +273,11 @@ def test_diagonal(): | |||
| assert torch_out3.numpy().dtype == ms_out3.numpy().dtype | |||
| @SKIP_ENV_GPU(reason='multi_dot not support input dtype as int64') | |||
| @SKIP_ENV_ASCEND(reason="CANN_VERSION_ERR: ms.ops.Matmul not support int64 input on Ascend.") | |||
| def test_multi_dot_int64(): | |||
| torch_out1 = torch.linalg.multi_dot([torch.tensor([1, 2]), torch.tensor([2, 3])]) | |||
| ms_out1 = ms_torch.linalg.multi_dot([ms.Tensor([1, 2]), ms.Tensor([2, 3])]) | |||
| assert np.allclose(torch_out1.numpy(), ms_out1.numpy()) | |||
| assert torch_out1.numpy().dtype == ms_out1.numpy().dtype | |||
| param_compare(torch_out1, ms_out1) | |||
| A = np.arange(2 * 3).reshape(2, 3) | |||
| B = np.arange(3 * 2).reshape(3, 2) | |||
| @@ -227,23 +293,23 @@ def test_multi_dot_int64(): | |||
| ms_C = torch.tensor(C) | |||
| ms_out4 = torch.linalg.multi_dot((ms_A, ms_B, ms_C)) | |||
| assert np.allclose(torch_out4.numpy(), ms_out4.numpy()) | |||
| assert torch_out4.numpy().dtype == ms_out4.numpy().dtype | |||
| param_compare(torch_out4, ms_out4) | |||
| def test_multi_dot(): | |||
| torch_out2 = torch.linalg.multi_dot([torch.tensor([[1, 2]], dtype=torch.float32), | |||
| torch.tensor([2, 3], dtype=torch.float32)]) | |||
| torch_out3 = torch.linalg.multi_dot([torch.tensor([[1, 2]], dtype=torch.float64), | |||
| torch.tensor([[2], [3]], dtype=torch.float64)]) | |||
| ms_out2 = ms_torch.linalg.multi_dot([ms.Tensor([[1, 2]], dtype=ms.float32), | |||
| ms.Tensor([2, 3], dtype=ms.float32)]) | |||
| ms_out3 = ms_torch.linalg.multi_dot([ms.Tensor([[1, 2]], dtype=ms.float64), | |||
| ms.Tensor([[2], [3]], dtype=ms.float64)]) | |||
| param_compare(torch_out2, ms_out2) | |||
| assert np.allclose(torch_out2.numpy(), ms_out2.numpy()) | |||
| assert torch_out2.numpy().dtype == ms_out2.numpy().dtype | |||
| assert np.allclose(torch_out3.numpy(), ms_out3.numpy()) | |||
| assert torch_out3.numpy().dtype == ms_out3.numpy().dtype | |||
| @SKIP_ENV_ASCEND(reason="multi_dot currently not support float64 on Ascend") | |||
| def test_multi_dot_fp64(): | |||
| torch_out3 = torch.linalg.multi_dot([torch.tensor([[1, 2]], dtype=torch.float64), | |||
| torch.tensor([[2], [3]], dtype=torch.float64)]) | |||
| ms_out3 = ms_torch.linalg.multi_dot([ms.Tensor([[1, 2]], dtype=ms.float64), | |||
| ms.Tensor([[2], [3]], dtype=ms.float64)]) | |||
| param_compare(torch_out3, ms_out3) | |||
| def test_householder_product(): | |||
| h = np.random.randn(3, 3, 3, 2, 2).astype(np.complex128) | |||
| @@ -400,37 +466,26 @@ def test_vander(): | |||
| @SKIP_ENV_GPU("test_eigvals only test on CPU and Ascend, which encapsulates the ms.ops.eig") | |||
| def test_eigvals(): | |||
| for type1 in (np.float32, np.float64, np.complex64, np.complex128): | |||
| np_array = np.array([[1, 2, 3],[4, 5, 6], [7, 8, 9]]).astype(type1) | |||
| torch_tensor = torch.tensor(np_array) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| torch_out = torch.linalg.eigvals(torch_tensor) | |||
| ms_out = ms_torch.linalg.eigvals(ms_tensor) | |||
| #TODO: the order of the results varies according to different hardwares | |||
| #the current result is generated on GPU | |||
| np_ret = [0, -1.1168444e+00+0.j, 1.6116846e+01+0.j] | |||
| assert np.allclose(ms_out.numpy(), np_ret, atol=1e-6) | |||
| assert ms_out.numpy().dtype == torch_out.numpy().dtype | |||
| assert ms_out.numpy().shape == torch_out.numpy().shape | |||
| np_array = np.random.randn(3, 3).astype(np.float32) | |||
| torch_tensor = torch.tensor(np_array) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| torch_out = torch.linalg.eigvals(torch_tensor) | |||
| ms_out = ms_torch.linalg.eigvals(ms_tensor) | |||
| assert np.allclose(np.sort(np.abs(torch_out.numpy())), np.sort(np.abs(ms_out.numpy())), atol=1e-5) | |||
| type_shape_compare(torch_out, ms_out) | |||
| @SKIP_ENV_ASCEND("test_eigvals_grad only test on GPU because it encapsulates the numpy.linalg.eig") | |||
| @SKIP_ENV_CPU("test_eigvals_gpu only test on GPU because it encapsulates the numpy.linalg.eig") | |||
| @SKIP_ENV_GRAPH_MODE("eigvals have prolem on GPU when using graph mode") | |||
| def test_eigvals_grad(): | |||
| for type1 in (np.float32, np.float64, np.complex64, np.complex128): | |||
| np_array = np.array([[1, 2, 3],[4, 5, 6], [7, 8, 9]]).astype(type1) | |||
| torch_tensor = torch.tensor(np_array) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| torch_out = torch.linalg.eigvals(torch_tensor) | |||
| ms_out = ms_torch.linalg.eigvals(ms_tensor) | |||
| #TODO: the order of the result varies between different hardwares | |||
| #the current result is generated on GPU | |||
| np_ret = [1.6116846e+01+0.j, -1.1168444e+00+0.j, 0] | |||
| assert np.allclose(ms_out.numpy(), np_ret, atol=1e-6) | |||
| assert ms_out.numpy().dtype == torch_out.numpy().dtype | |||
| assert ms_out.numpy().shape == torch_out.numpy().shape | |||
| #grad_test('eigvals', ms_torch.linalg.eigvals, ms_tensor) | |||
| np_array = np.random.randn(2, 2).astype(np.float32) | |||
| torch_tensor = torch.tensor(np_array) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| torch_out = torch.linalg.eigvals(torch_tensor) | |||
| ms_out = ms_torch.linalg.eigvals(ms_tensor) | |||
| assert np.allclose(np.sort(np.abs(torch_out.numpy())), np.sort(np.abs(ms_out.numpy())), atol=1e-5) | |||
| type_shape_compare(torch_out, ms_out) | |||
| #grad_test('eigvals', ms_torch.linalg.eigvals, ms_tensor) | |||
| @SKIP_ENV_ASCEND_GRAPH_MODE("Ascend encapsulate numpy func, which has PyInterpret problem on Graph mode") | |||
| def test_svd(): | |||
| @@ -521,6 +576,7 @@ def test_pinv(): | |||
| param_compare(ms_out2, torch_out2, atol=1e-5) | |||
| param_compare(ms_out3, torch_out3, atol=1e-5) | |||
| @SKIP_ENV_GRAPH_MODE(reason='eigvalsh not support on graph mode') | |||
| def test_eigvalsh(): | |||
| a = np.random.randn(3, 3).astype(np.float32) | |||
| b = np.array([[ 1.+0.j, -0.-2.j], [ 0.+2.j, 5.+0.j]]) | |||
| @@ -546,6 +602,8 @@ def test_eigvalsh(): | |||
| param_compare(torch_output2, ms_output2) | |||
| param_compare(torch_output3, ms_output3) | |||
| param_compare(torch_output4, ms_output4) | |||
| #TODO: mindspore has problem supporting numpy trans to ms.Tensor | |||
| ''' | |||
| grad_test('eigvalsh', ms_torch.linalg.eigvalsh, ms_tensor1) | |||
| @ms.jit | |||
| def fun(tensor1): | |||
| @@ -553,6 +611,7 @@ def test_eigvalsh(): | |||
| return ms_output1 | |||
| ms_output5 = fun(ms_tensor1) | |||
| param_compare(torch_output1, ms_output5) | |||
| ''' | |||
| def test_norm(): | |||
| x = np.random.randn(2, 2) | |||
| @@ -637,6 +696,188 @@ def test_vecdot(): | |||
| assert ms_out.dtype == ms.float64 | |||
| assert np.allclose(ms_out.numpy(), np.array([-1.62841749, -0.85996609, -0.44250129])) | |||
| def test_matrix_norm(): | |||
| x = np.random.randn(2, 3, 4).astype(np.float32) | |||
| torch_tensor1 = torch.tensor(x) | |||
| ms_tensor1 = ms_torch.tensor(x) | |||
| t_r1 = torch.linalg.matrix_norm(torch_tensor1) | |||
| t_r2 = torch.linalg.matrix_norm(torch_tensor1, dim=(0, -1)) | |||
| t_r3 = torch.linalg.matrix_norm(torch_tensor1, dim=(0, -1), keepdim=True) | |||
| ms_r1 = ms_torch.linalg.matrix_norm(ms_tensor1) | |||
| ms_r2 = ms_torch.linalg.matrix_norm(ms_tensor1, dim=(0, -1)) | |||
| ms_r3 = ms_torch.linalg.matrix_norm(ms_tensor1, dim=(0, -1), keepdim=True) | |||
| param_compare(t_r1, ms_r1) | |||
| param_compare(t_r2, ms_r2) | |||
| param_compare(t_r3, ms_r3) | |||
| def test_matrix_norm_ord1(): | |||
| y = np.random.randn(2, 3).astype(np.float32) | |||
| torch_tensor = torch.tensor(y) | |||
| ms_tensor = ms_torch.tensor(y) | |||
| t_r1 = torch.linalg.matrix_norm(torch_tensor, 1) | |||
| t_r2 = torch.linalg.matrix_norm(torch_tensor, -1) | |||
| t_r3 = torch.linalg.matrix_norm(torch_tensor, float('inf')) | |||
| t_r4 = torch.linalg.matrix_norm(torch_tensor, float('-inf')) | |||
| ms_r1 = ms_torch.linalg.matrix_norm(ms_tensor, 1) | |||
| ms_r2 = ms_torch.linalg.matrix_norm(ms_tensor, -1) | |||
| ms_r3 = ms_torch.linalg.matrix_norm(ms_tensor, float('inf')) | |||
| ms_r4 = ms_torch.linalg.matrix_norm(ms_tensor, float('-inf')) | |||
| param_compare(t_r1, ms_r1) | |||
| param_compare(t_r2, ms_r2) | |||
| param_compare(t_r3, ms_r3) | |||
| param_compare(t_r4, ms_r4) | |||
| @SKIP_ENV_ASCEND(reason="Ascend not support nuclear norm, and -2/2 norm") | |||
| def test_matrix_norm_ord2(): | |||
| y = np.random.randn(2, 3).astype(np.float32) | |||
| torch_tensor = torch.tensor(y) | |||
| ms_tensor = ms_torch.tensor(y) | |||
| t_r1 = torch.linalg.matrix_norm(torch_tensor, 2) | |||
| t_r2 = torch.linalg.matrix_norm(torch_tensor, -2) | |||
| t_r3 = torch.linalg.matrix_norm(torch_tensor, 'nuc') | |||
| ms_r1 = ms_torch.linalg.matrix_norm(ms_tensor, 2) | |||
| ms_r2 = ms_torch.linalg.matrix_norm(ms_tensor, -2) | |||
| ms_r3 = ms_torch.linalg.matrix_norm(ms_tensor, 'nuc') | |||
| param_compare(t_r1, ms_r1) | |||
| param_compare(t_r2, ms_r2) | |||
| param_compare(t_r3, ms_r3) | |||
| @SKIP_ENV_ASCEND(reason="matrix_norm currently not support float64 on Ascend") | |||
| def test_matrix_norm_fp64(): | |||
| x = np.random.randn(2, 3, 4) | |||
| torch_tensor1 = torch.tensor(x) | |||
| ms_tensor1 = ms_torch.tensor(x) | |||
| t_r1 = torch.linalg.matrix_norm(torch_tensor1) | |||
| ms_r1 = ms_torch.linalg.matrix_norm(ms_tensor1) | |||
| param_compare(t_r1, ms_r1) | |||
| def test_matrix_rank(): | |||
| A_t = torch.eye(10) | |||
| A_ms = ms_torch.eye(10) | |||
| torch_out1 = torch.linalg.matrix_rank(A_t) | |||
| torch_out2 = torch.linalg.matrix_rank(A_t, hermitian=True) | |||
| torch_out3 = torch.linalg.matrix_rank(A_t, atol=1.0, rtol=0.0) | |||
| ms_out1 = ms_torch.linalg.matrix_rank(A_ms) | |||
| ms_out2 = ms_torch.linalg.matrix_rank(A_ms, hermitian=True) | |||
| ms_out3 = ms_torch.linalg.matrix_rank(A_ms, atol=1.0, rtol=0.0) | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2) | |||
| param_compare(torch_out3, ms_out3) | |||
| ''' | |||
| @ms.jit | |||
| def my_test(A): | |||
| ms_out = ms_torch.linalg.matrix_rank(A) | |||
| return ms_out | |||
| ms_out4 = my_test(A_ms) | |||
| param_compare(torch_out1, ms_out4) | |||
| ''' | |||
| def test_matrix_rank_4d(): | |||
| A = np.random.randn(2, 4, 3, 3).astype(np.float32) | |||
| A_t = torch.tensor(A) | |||
| A_ms = ms_torch.tensor(A) | |||
| torch_out1 = torch.linalg.matrix_rank(A_t) | |||
| ms_out1 = ms_torch.linalg.matrix_rank(A_ms) | |||
| param_compare(torch_out1, ms_out1) | |||
| @SKIP_ENV_GPU(reason="cross currently not support on GPU") | |||
| def test_cross(): | |||
| np_1 = np.random.randn(2, 3, 3).astype(np.float32) | |||
| np_2 = np.random.randn(2, 3, 3).astype(np.float32) | |||
| ms_tensor_1 = ms_torch.tensor(np_1) | |||
| ms_tensor_2 = ms_torch.tensor(np_2) | |||
| ms_result = ms_torch.cross(ms_tensor_1, ms_tensor_2) | |||
| torch_tensor_1 = torch.tensor(np_1) | |||
| torch_tensor_2 = torch.tensor(np_2) | |||
| torch_result = torch.cross(torch_tensor_1, torch_tensor_2) | |||
| param_compare(ms_result, torch_result) | |||
| @SKIP_ENV_ASCEND(reason="solve_triangular currently not support on Ascend") | |||
| def test_solve_triangular(): | |||
| np_array1 = np.random.randn(3, 3).astype(np.float32) | |||
| np_array2 = np.random.randn(3, 4).astype(np.float32) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| torch_tensor2 = torch.tensor(np_array2) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| ms_tensor2 = ms_torch.tensor(np_array2) | |||
| A_t = torch_tensor1.triu() | |||
| A_t1 = torch_tensor1.tril() | |||
| X_t = torch.linalg.solve_triangular(A_t, torch_tensor2, upper=True) | |||
| X_t1 = torch.linalg.solve_triangular(A_t1, torch_tensor2, upper=False, unitriangular=True) | |||
| A_ms1 = ms_tensor1.tril() | |||
| A_ms = ms_tensor1.triu() | |||
| X_ms = ms_torch.linalg.solve_triangular(A_ms, ms_tensor2, upper=True) | |||
| X_ms1 = ms_torch.linalg.solve_triangular(A_ms1, ms_tensor2, upper=False, unitriangular=True) | |||
| param_compare(X_t, X_ms) | |||
| param_compare(X_t1, X_ms1) | |||
| @SKIP_ENV_ASCEND(reason="solve_triangular currently not support on Ascend") | |||
| def test_solve_triangular_3d(): | |||
| np_array1 = np.random.randn(2, 3, 3).astype(np.float32) | |||
| np_array2 = np.random.randn(2, 3, 4).astype(np.float32) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| torch_tensor2 = torch.tensor(np_array2) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| ms_tensor2 = ms_torch.tensor(np_array2) | |||
| A_t = torch_tensor1.triu() | |||
| X_t = torch.linalg.solve_triangular(A_t, torch_tensor2, upper=True, unitriangular=True) | |||
| A_ms = ms_tensor1.triu() | |||
| X_ms = ms_torch.linalg.solve_triangular(A_ms, ms_tensor2, upper=True, unitriangular=True) | |||
| param_compare(X_t, X_ms) | |||
| @SKIP_ENV_ASCEND(reason="cond currently not support complex input on Ascend") | |||
| def test_cond_complex128(): | |||
| x = np.random.randn(3, 3).astype(np.complex128) | |||
| torch_tensor1 = torch.tensor(x) | |||
| ms_tensor1 = ms_torch.tensor(x) | |||
| t_r1 = torch.linalg.cond(torch_tensor1) | |||
| t_r2 = torch.linalg.cond(torch_tensor1, -2) | |||
| ms_r1 = ms_torch.linalg.cond(ms_tensor1) | |||
| ms_r2 = ms_torch.linalg.cond(ms_tensor1, -2) | |||
| param_compare(t_r1, ms_r1) | |||
| param_compare(t_r2, ms_r2) | |||
| @SKIP_ENV_ASCEND(reason="cond currently not support complex input on Ascend") | |||
| def test_cond_complex64(): | |||
| y = np.random.randn(3, 3).astype(np.complex64) | |||
| torch_tensor1 = torch.tensor(y) | |||
| ms_tensor1 = ms_torch.tensor(y) | |||
| t_r1 = torch.linalg.cond(torch_tensor1, 'fro') | |||
| t_r2 = torch.linalg.cond(torch_tensor1, 'nuc') | |||
| ms_r1 = ms_torch.linalg.cond(ms_tensor1, 'fro') | |||
| ms_r2 = ms_torch.linalg.cond(ms_tensor1, 'nuc') | |||
| param_compare(t_r1, ms_r1) | |||
| param_compare(t_r2, ms_r2) | |||
| @SKIP_ENV_ASCEND(reason="ms.ops.cond not support on Ascend") | |||
| def test_cond_float(): | |||
| y = np.random.randn(4, 4).astype(np.float32) | |||
| torch_tensor1 = torch.tensor(y) | |||
| ms_tensor1 = ms_torch.tensor(y) | |||
| t_r1 = torch.linalg.cond(torch_tensor1) | |||
| t_r2 = torch.linalg.cond(torch_tensor1, 1) | |||
| t_r3 = torch.linalg.cond(torch_tensor1, float('inf')) | |||
| ms_r1 = ms_torch.linalg.cond(ms_tensor1) | |||
| ms_r2 = ms_torch.linalg.cond(ms_tensor1, 1) | |||
| ms_r3 = ms_torch.linalg.cond(ms_tensor1, float('inf')) | |||
| param_compare(t_r1, ms_r1) | |||
| param_compare(t_r2, ms_r2) | |||
| param_compare(t_r3, ms_r3) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
| test_eigh() | |||
| @@ -644,6 +885,7 @@ if __name__ == '__main__': | |||
| test_slogdet() | |||
| test_det() | |||
| test_cholesky() | |||
| test_cholesky_int() | |||
| test_inv() | |||
| test_matmul_float64() | |||
| test_matmul_complex128() | |||
| @@ -669,3 +911,22 @@ if __name__ == '__main__': | |||
| test_norm_advanced() | |||
| test_vector_norm() | |||
| # test_vecdot() | |||
| test_cholesky_fp64() | |||
| test_multi_dot_fp64() | |||
| test_inv_complex() | |||
| test_cholesky_ex() | |||
| test_cholesky_ex_fp64() | |||
| test_inv_ex() | |||
| test_inv_ex_complex() | |||
| test_matrix_norm() | |||
| test_matrix_norm_ord1() | |||
| test_matrix_norm_ord2() | |||
| test_matrix_norm_fp64() | |||
| test_matrix_rank() | |||
| test_matrix_rank_4d() | |||
| test_cross() | |||
| test_solve_triangular() | |||
| test_solve_triangular_3d() | |||
| test_cond_complex128() | |||
| test_cond_complex64() | |||
| test_cond_float() | |||
+ 3
- 3
testing/ut/pytorch/functional/test_mask.py
View File
| @@ -7,7 +7,7 @@ import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ...utils import set_mode_by_env_config | |||
| from ...utils import set_mode_by_env_config, param_compare | |||
| set_mode_by_env_config() | |||
| def test_masked_select(): | |||
| @@ -19,8 +19,8 @@ def test_masked_select(): | |||
| ms_tensor = ms_torch.tensor(x) | |||
| ms_mask = ms_tensor.ge(0.5) | |||
| ms_out = ms_torch.masked_select(ms_tensor, ms_mask) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| param_compare(ms_out, torch_out) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
+ 433
- 142
testing/ut/pytorch/functional/test_math.py
View File
| @@ -10,7 +10,7 @@ from ...utils import SKIP_ENV_ASCEND, is_test_under_ascend_context, is_test_unde | |||
| is_test_under_pynative_context, param_compare, grad_test, type_shape_compare | |||
| from msadapter.utils import is_under_cpu_context | |||
| from ...utils import set_mode_by_env_config, SKIP_ENV_GRAPH_MODE, SKIP_ENV_GPU | |||
| from ...utils import set_mode_by_env_config, SKIP_ENV_GRAPH_MODE, SKIP_ENV_GPU, SKIP_ENV_CPU | |||
| set_mode_by_env_config() | |||
| def test_round1(): | |||
| @@ -87,7 +87,7 @@ def test_ceil1(): | |||
| def test_sign1(): | |||
| np_array = np.array([[1.1, 0], [-0, -0.5]]).astype(np.float32) | |||
| np_array = np.array([[1.1, 0, 0.0], [-0, -0.5, -0.0]]).astype(np.float32) | |||
| torch_tensor = torch.tensor(np_array) | |||
| torch_out = torch.sign(torch_tensor) | |||
| @@ -95,8 +95,8 @@ def test_sign1(): | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| ms_out = ms_torch.sign(ms_tensor) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| param_compare(torch_out, ms_out) | |||
| def test_sign2(): | |||
| @@ -108,8 +108,8 @@ def test_sign2(): | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| ms_out = ms_torch.sign(ms_tensor) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| param_compare(torch_out, ms_out) | |||
| def test_pow1(): | |||
| @@ -127,6 +127,7 @@ def test_pow1(): | |||
| param_compare(torch_out, ms_out) | |||
| @SKIP_ENV_ASCEND(reason="pow currently not support inf and nan input on Ascend") | |||
| def test_pow2(): | |||
| np_array = np.array([0, 1, 5, -2, -9, -0, 5]).astype(np.int64) | |||
| np_array1 = np.array([0, np.nan, 5, -2, np.nan, -0, 5]).astype(np.int32) | |||
| @@ -152,8 +153,10 @@ def test_pow2(): | |||
| #ms_out4 = ms_torch.pow(ms_tensor, 2333) | |||
| param_compare(torch_out, ms_out) | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2) | |||
| #TODO: currently GPU has problem calculating negative inputs | |||
| if not is_test_under_gpu_context(): | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2) | |||
| param_compare(torch_out3, ms_out3) | |||
| #param_compare(torch_out4, ms_out4) | |||
| @@ -221,7 +224,7 @@ def test_exp3(): | |||
| param_compare(torch_out, ms_out) | |||
| @SKIP_ENV_ASCEND(reason="CANN_VERSION_ERR: ms.ops.Mul with int64 input result not correct on Ascend.") | |||
| def test_mul1(): | |||
| a = np.array([1, 2]) | |||
| b = np.array([[3], [4]]) | |||
| @@ -229,18 +232,29 @@ def test_mul1(): | |||
| torch_tensor_a = torch.tensor(a) | |||
| torch_tensor_b = torch.tensor(b) | |||
| torch_out = torch.mul(torch_tensor_a, torch_tensor_b) | |||
| torch_out1 = torch.multiply(torch_tensor_a, torch_tensor_b) | |||
| ms_tensor_a = ms_torch.tensor(a) | |||
| ms_tensor_b = ms_torch.tensor(b) | |||
| ms_out = ms_torch.mul(ms_tensor_a, ms_tensor_b) | |||
| ms_out1 = ms_torch.multiply(ms_tensor_a, ms_tensor_b) | |||
| param_compare(torch_out, ms_out) | |||
| param_compare(torch_out1, ms_out1) | |||
| @SKIP_ENV_ASCEND(reason="CANN_VERSION_ERR: ms.ops.Mul with int64 input result not correct on Ascend.") | |||
| def test_multiply(): | |||
| a = np.array([1, 2]) | |||
| b = np.array([[3], [4]]) | |||
| torch_tensor_a = torch.tensor(a) | |||
| torch_tensor_b = torch.tensor(b) | |||
| torch_out1 = torch.multiply(torch_tensor_a, torch_tensor_b) | |||
| ms_tensor_a = ms_torch.tensor(a) | |||
| ms_tensor_b = ms_torch.tensor(b) | |||
| ms_out1 = ms_torch.multiply(ms_tensor_a, ms_tensor_b) | |||
| param_compare(torch_out1, ms_out1) | |||
| @SKIP_ENV_ASCEND(reason="mul: ms.ops.mul has bug on Ascend") | |||
| def test_mul2(): | |||
| b = np.array([[3], [4]]) | |||
| @@ -491,7 +505,7 @@ def test_atan_fp64(): | |||
| torch_out = torch.atan(torch_tensor) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| ms_out = ms_torch.atan(ms_tensor) | |||
| param_compare(torch_out, ms_out) | |||
| def test_arctan(): | |||
| @@ -531,7 +545,7 @@ def test_arctan_int(): | |||
| param_compare(torch_out, ms_out) | |||
| def test_atanh(): | |||
| #atanh already support float64 on Ascend | |||
| #atanh already support float64 on Ascend | |||
| np_array = np.random.rand(2, 3, 2).astype(np.float64) | |||
| torch_tensor = torch.tensor(np_array) | |||
| torch_out = torch.atanh(torch_tensor) | |||
| @@ -543,7 +557,7 @@ def test_atanh(): | |||
| def test_arctanh(): | |||
| #atanh already support float64 on Ascend | |||
| #atanh already support float64 on Ascend | |||
| np_array = np.random.rand(1, 4, 5, 6).astype(np.float64) | |||
| np_array[0, 0, 0, 0] = 0 | |||
| torch_tensor = torch.tensor(np_array) | |||
| @@ -963,6 +977,7 @@ def test_float_power_complex(): | |||
| assert ms_out2.asnumpy().dtype == torch_out2.numpy().dtype | |||
| ''' | |||
| @SKIP_ENV_ASCEND(reason="ascend not support inf result") | |||
| def test_floor_divide(): | |||
| np_array = (np.random.randn(3, 4, 5) * 20).astype(np.int32) | |||
| np_other = (np.random.rand(4, 5) * 20).astype(np.float32) | |||
| @@ -995,15 +1010,35 @@ def test_floor_divide(): | |||
| param_compare(torch_out5, ms_out5) | |||
| assert str(torch_e) == str(ms_e) | |||
| @SKIP_ENV_CPU(reason="testcase for ascend only, because ascend not support inf, cpu test will be cover by test_floor_divide") | |||
| @SKIP_ENV_GPU(reason="testcase for ascend only, because ascend not support inf, gpu test will be cover by test_floor_divide") | |||
| def test_floor_divide_ascend(): | |||
| np_array = (np.random.randn(3, 4, 5) * 20).astype(np.int32) | |||
| np_other = (np.random.rand(4, 5) * 20).astype(np.float32) | |||
| np_other = np.where(np_other == 0, 1, np_other) | |||
| torch_tensor = torch.tensor(np_array) | |||
| torch_other = torch.tensor(np_other) | |||
| torch_out1 = torch.floor_divide(torch_tensor, torch_other) | |||
| torch_out2 = torch.floor_divide(torch_tensor, 2) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| ms_other = ms_torch.tensor(np_other) | |||
| ms_out1 = ms_torch.floor_divide(ms_tensor, ms_other) | |||
| ms_out2 = ms_torch.floor_divide(ms_tensor, 2) | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2) | |||
| def test_frexp(): | |||
| for type1 in (np.float16, np.float32): | |||
| np_array = np.random.randn(1, 4, 4).astype(type1) | |||
| np_array = (np.random.randn(1, 4, 4)).astype(type1) | |||
| torch_tensor = torch.tensor(np_array) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| torch_out1, torch_out2 = torch.frexp(torch_tensor) | |||
| ms_out1, ms_out2 = ms_torch.frexp(ms_tensor) | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2) | |||
| if is_test_under_pynative_context(): | |||
| torch_out3 = torch.zeros(torch_out1.shape, dtype=torch_out1.dtype) | |||
| torch_out4 = torch.zeros(torch_out2.shape, dtype=torch_out2.dtype) | |||
| @@ -1013,12 +1048,11 @@ def test_frexp(): | |||
| ms_torch.frexp(ms_tensor, out=(ms_out3, ms_out4)) | |||
| param_compare(torch_out3, ms_out3) | |||
| param_compare(torch_out4, ms_out4) | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2) | |||
| @SKIP_ENV_ASCEND(reason="frexp not support float64 on Ascend") | |||
| def test_frexp_fp64(): | |||
| np_array = np.random.randn(1, 4, 4).astype(np.float64) | |||
| np_array = np.random.randn(2, 2).astype(np.float64) | |||
| torch_tensor = torch.tensor(np_array) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| @@ -1037,21 +1071,27 @@ def test_frexp_fp64(): | |||
| param_compare(torch_out2, ms_out2) | |||
| def test_gradient(): | |||
| np_array = np.array([4., 1., 1., 16.]) | |||
| np_coordinates = np.array([-2., -1., 1., 4.]) | |||
| np_array = np.array([4., 1., 1., 16.]).astype(np.float32) | |||
| torch_tensor = torch.tensor(np_array) | |||
| torch_coordinates = torch.tensor(np_coordinates) | |||
| torch_out1 = torch.gradient(torch_tensor, spacing=torch.tensor(1)) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| ms_coordinates = ms_torch.tensor(np_coordinates) | |||
| ms_out1 = ms_torch.gradient(ms_tensor, spacing=ms_torch.tensor(1)) | |||
| assert ms_out1[0].asnumpy().dtype == torch_out1[0].numpy().dtype | |||
| for i in range(len(ms_out1)): | |||
| assert np.allclose(ms_out1[i].asnumpy(), torch_out1[i].numpy()) | |||
| param_compare(torch_out1, ms_out1) | |||
| @SKIP_ENV_ASCEND(reason="gradient currently not support float64 on Ascend") | |||
| def test_gradient_fp64(): | |||
| np_array = np.random.randn(4) | |||
| torch_tensor = torch.tensor(np_array) | |||
| torch_out1 = torch.gradient(torch_tensor, spacing=torch.tensor(1)) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| ms_out1 = ms_torch.gradient(ms_tensor, spacing=ms_torch.tensor(1)) | |||
| param_compare(torch_out1, ms_out1) | |||
| def test_imag(): | |||
| np_array = np.array([[1+5j, 2-1j, 3.0, -4j, -0j]]) | |||
| @@ -1079,12 +1119,10 @@ def test_ldexp(): | |||
| param_compare(torch_out, ms_out) | |||
| def test_lerp(): | |||
| np_array = np.random.rand(1, 4, 5, 5)*5-2 | |||
| np_other = np.random.rand(4, 5, 5)*5-2 | |||
| np_weight = np.random.rand(1, 4, 5, 5)*5-2 | |||
| np_array = (np.random.rand(1, 4, 5, 5) * 5 - 2).astype(np.float32) | |||
| np_other = (np.random.rand(4, 5, 5) * 5 - 2).astype(np.float32) | |||
| np_weight = (np.random.rand(1, 4, 5, 5) * 5 - 2).astype(np.float32) | |||
| torch_tensor = torch.tensor(np_array) | |||
| torch_other = torch.tensor(np_other) | |||
| @@ -1101,10 +1139,27 @@ def test_lerp(): | |||
| param_compare(torch_out1, ms_out1, atol=1e-6) | |||
| param_compare(torch_out2, ms_out2, atol=1e-6) | |||
| @SKIP_ENV_ASCEND(reason="lerp currently not support float64 on Ascend") | |||
| def test_lerp_fp64(): | |||
| np_array = np.random.rand(2, 2) | |||
| np_other = np.random.rand(2) | |||
| np_weight = np.random.rand(2, 2) | |||
| torch_tensor = torch.tensor(np_array) | |||
| torch_other = torch.tensor(np_other) | |||
| torch_weight = torch.tensor(np_weight) | |||
| torch_out1 = torch.lerp(torch_tensor, torch_other, torch_weight) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| ms_other = ms_torch.tensor(np_other) | |||
| ms_weight = ms_torch.tensor(np_weight) | |||
| ms_out1 = ms_torch.lerp(ms_tensor, ms_other, ms_weight) | |||
| param_compare(torch_out1, ms_out1, atol=1e-6) | |||
| def test_logaddexp(): | |||
| np_array = np.random.rand(1, 4, 5, 6)*5-2 | |||
| np_other = np.random.rand(1, 4, 5, 6)*5-2 | |||
| np_array = (np.random.rand(1, 4, 5, 6) * 5 - 2).astype(np.float32) | |||
| np_other = (np.random.rand(1, 4, 5, 6) * 5 - 2).astype(np.float32) | |||
| torch_tensor = torch.tensor(np_array) | |||
| torch_other = torch.tensor(np_other) | |||
| @@ -1116,10 +1171,26 @@ def test_logaddexp(): | |||
| ms_out = ms_torch.logaddexp(ms_tensor, ms_other) | |||
| ms_out2 = ms_torch.logaddexp2(ms_tensor, ms_other) | |||
| param_compare(torch_out, ms_out) | |||
| param_compare(torch_out2, ms_out2) | |||
| param_compare(torch_out, ms_out, atol=1e-5) | |||
| param_compare(torch_out2, ms_out2, atol=1e-5) | |||
| @SKIP_ENV_ASCEND(reason="logaddexp currently not support float64 on Ascend") | |||
| def test_logaddexp_fp64(): | |||
| np_array = np.random.rand(2, 3) | |||
| np_other = np.random.rand(2, 3) | |||
| torch_tensor = torch.tensor(np_array) | |||
| torch_other = torch.tensor(np_other) | |||
| torch_out = torch.logaddexp(torch_tensor, torch_other) | |||
| torch_out2 = torch.logaddexp2(torch_tensor, torch_other) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| ms_other = ms_torch.tensor(np_other) | |||
| ms_out = ms_torch.logaddexp(ms_tensor, ms_other) | |||
| ms_out2 = ms_torch.logaddexp2(ms_tensor, ms_other) | |||
| param_compare(torch_out, ms_out) | |||
| param_compare(torch_out2, ms_out2) | |||
| def test_logical_and(): | |||
| np_array = np.random.randn(120).reshape(2, 2, 6, 5) * 16 - 8 | |||
| @@ -1209,7 +1280,7 @@ def test_lu_unpack(): | |||
| param_compare(torch_l1, ms_l1) | |||
| param_compare(torch_u1, ms_u1) | |||
| @SKIP_ENV_GRAPH_MODE(reason="nn.cell currently has memcpy problem in graph mode") | |||
| def test_lstsq(): | |||
| for type1 in (np.float32, np.float64): | |||
| x1 = np.random.randn(5,5).astype(type1) | |||
| @@ -1235,7 +1306,7 @@ def test_lstsq(): | |||
| #TODO: cpu use ops.lstsq, which doe not support bprop | |||
| if not is_under_cpu_context(): | |||
| grad_test('lstsq', ms_torch.lstsq, ms_a1, ms_x1) | |||
| def test_tanh(): | |||
| np_array = np.random.rand(1, 1, 1, 1, 3, 4, 5).astype(np.float64) | |||
| @@ -1302,12 +1373,8 @@ def test_i0(): | |||
| ms_out = ms_torch.i0(ms_tensor) | |||
| ms_out2 = ms_torch.i0(ms_tensor2) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| assert ms_out.asnumpy().shape == torch_out.numpy().shape | |||
| assert np.allclose(ms_out2.asnumpy(), torch_out2.numpy()) | |||
| assert ms_out2.asnumpy().dtype == torch_out2.numpy().dtype | |||
| assert ms_out2.asnumpy().shape == torch_out2.numpy().shape | |||
| param_compare(torch_out, ms_out) | |||
| param_compare(torch_out2, ms_out2) | |||
| def test_igamma(): | |||
| @@ -1370,7 +1437,7 @@ def test_mvlgamma(): | |||
| def test_nan_to_num(): | |||
| np_array = np.array([np.nan, np.inf, -np.inf, 3]) | |||
| typetest = [np.half, np.float32, np.float64, np.int32] | |||
| typetest = [np.half, np.float32, np.int32] | |||
| for i in typetest: | |||
| np_array_ = np_array.astype(i) | |||
| torch_tensor = torch.tensor(np_array_) | |||
| @@ -1380,9 +1447,13 @@ def test_nan_to_num(): | |||
| ms_out = ms_torch.nan_to_num(ms_tensor) | |||
| param_compare(torch_out, ms_out) | |||
| def test_nan_to_num1(): | |||
| if is_test_under_ascend_context(): | |||
| np_array = np.array([np.nan, np.inf, -np.inf, 3]).astype(np.float32) | |||
| else: | |||
| np_array = np.array([np.nan, np.inf, -np.inf, 3]) | |||
| torch_tensor = torch.tensor(np_array) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| torch_out = torch.nan_to_num(torch_tensor, 1.1, 2, -1) | |||
| ms_out = ms_torch.nan_to_num(ms_tensor, 1.1, 2, -1) | |||
| @@ -1531,7 +1602,7 @@ def test_reciprocal(): | |||
| # while torch returns nan+nanj | |||
| #np_array2 = np.array([[0j, -0j, 0, -0, -0-0j, 0+0j]]) | |||
| #np_array2 = np.array([[np.inf, -0.0, 1.0, np.nan]]) | |||
| np_array2 = np.array([[np.inf, 0.0, 1.0, np.nan]]) | |||
| np_array2 = np.array([[np.inf, 0.0, 1.0, np.nan]]).astype(np.float32) | |||
| np_array3 = np.array([[1, 1, 2]]).astype(np.int16) | |||
| np_array4 = np.array([[1, -1, 0]]).astype(np.bool_) | |||
| @@ -1585,7 +1656,7 @@ def test_remainder(): | |||
| assert np.allclose(ms_out3.asnumpy(), torch_out3.numpy()) | |||
| assert ms_out3.asnumpy().dtype == torch_out3.numpy().dtype | |||
| @SKIP_ENV_ASCEND(reason="ascend not support nan result") | |||
| def test_rsqrt(): | |||
| np_array1 = np.array([[-3, -2, -1, 0, 2, 3]]).astype(np.float32) | |||
| np_array2 = np.array([[1, 2, 3, 4, 5]]).astype(np.int64) | |||
| @@ -1603,7 +1674,18 @@ def test_rsqrt(): | |||
| param_compare(ms_out1, torch_out1, equal_nan=True) | |||
| param_compare(ms_out2, torch_out2) | |||
| def test_roll(): | |||
| @SKIP_ENV_CPU(reason="testcase for ascend only, because ascend not support nan, cpu test will be covered by test_rsqrt.") | |||
| @SKIP_ENV_GPU(reason="testcase for ascend only, because ascend not support nan, gpu test will be covered by test_rsqrt.") | |||
| def test_rsqrt_ascend(): | |||
| np_array1 = np.array([[1, 2, 3, 4, 5]]).astype(np.int64) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| torch_out1 = torch.rsqrt(torch_tensor1) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| ms_out1 = ms_torch.rsqrt(ms_tensor1) | |||
| param_compare(ms_out1, torch_out1) | |||
| def test_roll(): | |||
| x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=np.float32) | |||
| torch_tensor = torch.tensor(x).view(3, 3) | |||
| ms_tensor =ms_torch.tensor(x).view(3, 3) | |||
| @@ -1618,46 +1700,38 @@ def test_roll(): | |||
| ms_out3 = ms_torch.roll(ms_tensor, -1, 0) | |||
| ms_out4 = ms_torch.roll(ms_tensor, shifts=(2, 1), dims=(0, 1)) | |||
| assert np.allclose(ms_out1.numpy(), torch_out1.numpy()) | |||
| assert np.allclose(ms_out2.numpy(), torch_out2.numpy()) | |||
| assert np.allclose(ms_out3.numpy(), torch_out3.numpy()) | |||
| assert np.allclose(ms_out4.numpy(), torch_out4.numpy()) | |||
| assert ms_out1.numpy().dtype == torch_out1.numpy().dtype | |||
| assert ms_out2.numpy().dtype == torch_out2.numpy().dtype | |||
| assert ms_out3.numpy().dtype == torch_out3.numpy().dtype | |||
| assert ms_out4.numpy().dtype == torch_out4.numpy().dtype | |||
| assert ms_out1.numpy().shape == torch_out1.numpy().shape | |||
| assert ms_out2.numpy().shape == torch_out2.numpy().shape | |||
| assert ms_out3.numpy().shape == torch_out3.numpy().shape | |||
| assert ms_out4.numpy().shape == torch_out4.numpy().shape | |||
| param_compare(ms_out1, torch_out1) | |||
| param_compare(ms_out2, torch_out2) | |||
| param_compare(ms_out3, torch_out3) | |||
| param_compare(ms_out4, torch_out4) | |||
| def test_rot90(): | |||
| np_array = np.array([[0, 1],[2, 3]], dtype=np.float32) | |||
| np_array = np.array([[0, 1],[2, 3]], dtype=np.int32) | |||
| np_array1 = np.random.randn(2, 3, 3).astype(np.float32) | |||
| dims1 = [0, 1] | |||
| dims2 = [1, 0] | |||
| torch_tensor = torch.tensor(np_array) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| torch_out1 = torch.rot90(torch_tensor, 1, dims1) | |||
| torch_out2 = torch.rot90(torch_tensor, 2, dims1) | |||
| torch_out3 = torch.rot90(torch_tensor, -1, dims1) | |||
| torch_out4 = torch.rot90(torch_tensor, 1, dims2) | |||
| torch_out5 = torch.rot90(torch_tensor1, 1, dims2) | |||
| ms_out1 = ms_torch.rot90(ms_tensor, 1, dims1) | |||
| ms_out2 = ms_torch.rot90(ms_tensor, 2, dims1) | |||
| ms_out3 = ms_torch.rot90(ms_tensor, -1, dims1) | |||
| ms_out4 = ms_torch.rot90(ms_tensor, 1, dims2) | |||
| ms_out5 = ms_torch.rot90(ms_tensor1, 1, dims2) | |||
| param_compare(ms_out1, torch_out1) | |||
| param_compare(ms_out2, torch_out2) | |||
| param_compare(ms_out3, torch_out3) | |||
| param_compare(ms_out4, torch_out4) | |||
| param_compare(ms_out5, torch_out5) | |||
| torch_out1 = torch.rot90(torch_tensor, 1,dims1) | |||
| torch_out2 = torch.rot90(torch_tensor, 2,dims1) | |||
| torch_out3 = torch.rot90(torch_tensor, -1,dims1) | |||
| torch_out4 = torch.rot90(torch_tensor, 1,dims2) | |||
| ms_out1 = ms_torch.rot90(ms_tensor, 1,dims1) | |||
| ms_out2 = ms_torch.rot90(ms_tensor, 2,dims1) | |||
| ms_out3 = ms_torch.rot90(ms_tensor, -1,dims1) | |||
| ms_out4 = ms_torch.rot90(ms_tensor, 1,dims2) | |||
| assert np.allclose(ms_out1.numpy(), torch_out1.numpy()) | |||
| assert np.allclose(ms_out2.numpy(), torch_out2.numpy()) | |||
| assert np.allclose(ms_out3.numpy(), torch_out3.numpy()) | |||
| assert np.allclose(ms_out4.numpy(), torch_out4.numpy()) | |||
| assert ms_out1.numpy().dtype == torch_out1.numpy().dtype | |||
| assert ms_out1.numpy().shape == torch_out1.numpy().shape | |||
| assert ms_out2.numpy().dtype == torch_out2.numpy().dtype | |||
| assert ms_out2.numpy().shape == torch_out2.numpy().shape | |||
| assert ms_out3.numpy().dtype == torch_out3.numpy().dtype | |||
| assert ms_out3.numpy().shape == torch_out3.numpy().shape | |||
| assert ms_out4.numpy().dtype == torch_out4.numpy().dtype | |||
| assert ms_out4.numpy().shape == torch_out4.numpy().shape | |||
| def test_searchsorted(): | |||
| for type1 in (np.float16, np.float32, np.float64, np.int16, np.int32, np.int64): | |||
| @@ -1694,21 +1768,23 @@ def test_sgn(): | |||
| torch_tensor3 = torch.tensor(np_array3) | |||
| torch_out1 = torch.sgn(torch_tensor1) | |||
| torch_out2 = torch.sgn(torch_tensor2) | |||
| torch_out3 = torch.sgn(torch_tensor3) | |||
| if not is_test_under_ascend_context(): | |||
| torch_out3 = torch.sgn(torch_tensor3) | |||
| ms_tensor3 = ms_torch.tensor(np_array3) | |||
| ms_out3 = ms_torch.sgn(ms_tensor3) | |||
| assert np.allclose(ms_out3.asnumpy(), torch_out3.numpy()) | |||
| assert ms_out3.asnumpy().dtype == torch_out3.numpy().dtype | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| ms_tensor2 = ms_torch.tensor(np_array2) | |||
| ms_tensor3 = ms_torch.tensor(np_array3) | |||
| ms_out1 = ms_torch.sgn(ms_tensor1) | |||
| ms_out2 = ms_torch.sgn(ms_tensor2) | |||
| ms_out3 = ms_torch.sgn(ms_tensor3) | |||
| assert np.allclose(ms_out1.asnumpy(), torch_out1.numpy(), equal_nan=True) | |||
| assert ms_out1.asnumpy().dtype == torch_out1.numpy().dtype | |||
| assert np.allclose(ms_out2.asnumpy(), torch_out2.numpy()) | |||
| assert ms_out2.asnumpy().dtype == torch_out2.numpy().dtype | |||
| assert np.allclose(ms_out3.asnumpy(), torch_out3.numpy()) | |||
| assert ms_out3.asnumpy().dtype == torch_out3.numpy().dtype | |||
| def test_qr(): | |||
| np_array = np.random.randn(2,3).astype(np.float32) | |||
| @@ -1763,7 +1839,7 @@ def test_sinc(): | |||
| ms_tensor2 = ms_torch.tensor(np_array2) | |||
| ms_out1 = ms_torch.sinc(ms_tensor1) | |||
| ms_out2 = ms_torch.sinc(ms_tensor2) | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2) | |||
| @@ -1879,6 +1955,9 @@ def test_tan(): | |||
| def test_true_divide(): | |||
| np_array1 = np.random.randn(10).astype(np.float64) * 5 | |||
| np_array2 = np.random.randn(10).astype(np.float32) * 5 | |||
| if is_test_under_ascend_context(): | |||
| # to prevent 0 divisor, because ascend not support inf and nan. | |||
| np_array2 = np.where(np.abs(np_array2 < 1), 1, np_array2) | |||
| for x_dtype in (np.int16, np.int32, np.uint8, np.half, np.double, np.single): | |||
| np_array1_ = np_array1.astype(x_dtype) | |||
| torch_tensor1 = torch.tensor(np_array1_) | |||
| @@ -1910,32 +1989,46 @@ def test_true_divide(): | |||
| def test_trunc(): | |||
| np_array1 = np.random.randn(10).astype(np.float64) * 5 | |||
| np_array2 = np.random.randn(10).astype(np.float32) * 5 | |||
| #np_array3 = np.array([0.0, -0.0, np.inf, -np.inf, np.nan]) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| torch_tensor2 = torch.tensor(np_array2) | |||
| torch_out1 = torch.trunc(torch_tensor1) | |||
| #torch_tensor3 = torch.tensor(np_array3) | |||
| torch_out2 = torch.trunc(torch_tensor2) | |||
| #torch_out3 = torch.trunc(torch_tensor3) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| ms_tensor2 = ms_torch.tensor(np_array2) | |||
| ms_out1 = ms_torch.trunc(ms_tensor1) | |||
| #ms_tensor3 = ms_torch.tensor(np_array3) | |||
| ms_out2 = ms_torch.trunc(ms_tensor2) | |||
| #ms_out3 = ms_torch.trunc(ms_tensor3) | |||
| assert np.allclose(ms_out1.asnumpy(), torch_out1.numpy()) | |||
| assert ms_out1.asnumpy().dtype == torch_out1.numpy().dtype | |||
| assert np.allclose(ms_out2.asnumpy(), torch_out2.numpy()) | |||
| assert ms_out2.asnumpy().dtype == torch_out2.numpy().dtype | |||
| param_compare(torch_out2, ms_out2) | |||
| @SKIP_ENV_ASCEND(reason="trunc currently not support float64 on Ascend") | |||
| def test_trunc_fp64(): | |||
| np_array1 = np.random.randn(10).astype(np.float64) * 5 | |||
| #np_array3 = np.array([0.0, -0.0, np.inf, -np.inf, np.nan]) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| torch_out1 = torch.trunc(torch_tensor1) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| ms_out1 = ms_torch.trunc(ms_tensor1) | |||
| param_compare(torch_out1, ms_out1) | |||
| def test_xlogy(): | |||
| np_array1 = np.random.randn(10).astype(np.float64) * 5 | |||
| np_array2 = np.random.randn(10).astype(np.float32) * 5 | |||
| np_array1[0:2] = 0 | |||
| np_array2[1:3] = np.nan | |||
| np_array2[5] = np.inf | |||
| np_array2[0] = 2 | |||
| if is_test_under_ascend_context(): | |||
| # prevent negative and 0 input | |||
| np_array2 = np.random.random(10).astype(np.float32) * 5 | |||
| else: | |||
| np_array2 = np.random.randn(10).astype(np.float32) * 5 | |||
| if not is_test_under_ascend_context(): | |||
| # prevent nan and inf input on ascend, because ascend not support | |||
| np_array1[0:2] = 0 | |||
| np_array2[1:3] = np.nan | |||
| np_array2[5] = np.inf | |||
| np_array2[0] = 2 | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| torch_tensor2 = torch.tensor(np_array2) | |||
| @@ -2064,40 +2157,53 @@ def test_logdet(): | |||
| ms_out2 = ms_torch.logdet(ms_tensor2) | |||
| #TODO: logdet not accurate in Graph mode | |||
| assert np.allclose(ms_out1.asnumpy(), torch_out1.numpy(), atol=1e-5, equal_nan=True) | |||
| assert ms_out1.asnumpy().dtype == torch_out1.numpy().dtype | |||
| assert np.allclose(ms_out2.asnumpy(), torch_out2.numpy(), atol=1e-5, equal_nan=True) | |||
| assert ms_out2.asnumpy().dtype == torch_out2.numpy().dtype | |||
| if is_test_under_ascend_context(): | |||
| # can not prevent nan from input, can only see if nan in output | |||
| if not np.isnan(torch_out1.numpy()).any(): | |||
| assert np.allclose(ms_out1.asnumpy(), torch_out1.numpy(), atol=1e-5, equal_nan=True) | |||
| assert ms_out1.asnumpy().dtype == torch_out1.numpy().dtype | |||
| if not np.isnan(torch_out2.numpy()).any(): | |||
| assert np.allclose(ms_out2.asnumpy(), torch_out2.numpy(), atol=1e-5, equal_nan=True) | |||
| assert ms_out2.asnumpy().dtype == torch_out2.numpy().dtype | |||
| else: | |||
| assert np.allclose(ms_out1.asnumpy(), torch_out1.numpy(), atol=1e-5, equal_nan=True) | |||
| assert ms_out1.asnumpy().dtype == torch_out1.numpy().dtype | |||
| assert np.allclose(ms_out2.asnumpy(), torch_out2.numpy(), atol=1e-5, equal_nan=True) | |||
| assert ms_out2.asnumpy().dtype == torch_out2.numpy().dtype | |||
| def test_inner(): | |||
| np_array1 = np.random.rand(2, 4).astype(np.float32) * 5 | |||
| np_other1 = np.random.rand(1, 3, 4).astype(np.float32) * 5 | |||
| np_array2 = np.array([1, 2, 3]).astype(np.int16) | |||
| np_other2 = np.array([0, 2, 1]).astype(np.int16) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| torch_other1 = torch.tensor(np_other1) | |||
| torch_tensor2 = torch.tensor(np_array2) | |||
| torch_other2 = torch.tensor(np_other2) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| ms_other1 = ms_torch.tensor(np_other1) | |||
| ms_tensor2 = ms_torch.tensor(np_array2) | |||
| ms_other2 = ms_torch.tensor(np_other2) | |||
| torch_out1 = torch.inner(torch_tensor1, torch_other1) | |||
| ms_out1 = ms_torch.inner(ms_tensor1, ms_other1) | |||
| torch_out2 = torch.inner(torch_tensor2, torch_other2) | |||
| ms_out2 = ms_torch.inner(ms_tensor2, ms_other2) | |||
| torch_out3 = torch.inner(torch.tensor(2), torch_tensor1) | |||
| ms_out3 = ms_torch.inner(ms_torch.tensor(2), ms_tensor1) | |||
| assert np.allclose(ms_out1.asnumpy(), torch_out1.numpy(), equal_nan=True) | |||
| assert ms_out1.asnumpy().dtype == torch_out1.numpy().dtype | |||
| @SKIP_ENV_ASCEND(reason="torch.inner doesn't support inputs of int type on Ascend") | |||
| def test_inner_int(): | |||
| np_array2 = np.array([1, 2, 3]).astype(np.int16) | |||
| np_other2 = np.array([0, 2, 1]).astype(np.int16) | |||
| torch_tensor2 = torch.tensor(np_array2) | |||
| torch_other2 = torch.tensor(np_other2) | |||
| ms_tensor2 = ms_torch.tensor(np_array2) | |||
| ms_other2 = ms_torch.tensor(np_other2) | |||
| torch_out2 = torch.inner(torch_tensor2, torch_other2) | |||
| ms_out2 = ms_torch.inner(ms_tensor2, ms_other2) | |||
| assert np.allclose(ms_out2.asnumpy(), torch_out2.numpy(), equal_nan=True) | |||
| assert ms_out2.asnumpy().dtype == torch_out2.numpy().dtype | |||
| # TODO: use the testcase below after ms.ops.inner is corrected | |||
| #assert np.allclose(ms_out3.asnumpy(), torch_out3.numpy(), equal_nan=True) | |||
| #assert ms_out3.asnumpy().dtype == torch_out3.numpy().dtype | |||
| def test_inner_scalar(): | |||
| torch_out3 = torch.inner(torch.tensor(2), torch.tensor([3.2, 4.1])) | |||
| ms_out3 = ms_torch.inner(ms_torch.tensor(2), ms_torch.tensor([3.2, 4.1])) | |||
| assert np.allclose(ms_out3.asnumpy(), torch_out3.numpy(), equal_nan=True) | |||
| assert ms_out3.asnumpy().dtype == torch_out3.numpy().dtype | |||
| def test_repeat_interleave(): | |||
| np_array1 = np.array([[1, 2], [3, 4]]).astype(np.int32) | |||
| @@ -2185,6 +2291,8 @@ def test_poisson(): | |||
| ms_out4 = ms_torch.poisson(ms_tensor1) | |||
| param_compare(ms_out1, ms_out3) | |||
| param_compare(ms_out2, ms_out4) | |||
| #TODO: mindspore has problem supporting numpy trans to ms.Tensor | |||
| ''' | |||
| ms.set_seed(10) | |||
| @ms.jit | |||
| def func(a): | |||
| @@ -2192,27 +2300,45 @@ def test_poisson(): | |||
| return x | |||
| ms_out5 = func(ms_tensor1) | |||
| param_compare(ms_out1, ms_out5) | |||
| ''' | |||
| @SKIP_ENV_GPU(reason="Eig currently not support on GPU") | |||
| @SKIP_ENV_ASCEND(reason="testcase not support on Ascend") | |||
| def test_eig_fp64(): | |||
| np_array1 = np.random.randn(2, 2).astype(np.float64) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| torch_u1, torch_v1 = torch.linalg.eig(torch_tensor1) | |||
| ms_u1, ms_v1 = ms_torch.eig(ms_tensor1) | |||
| assert np.allclose(np.sort(np.abs(torch_u1.numpy())), np.sort(np.abs(ms_u1.numpy()))) | |||
| type_shape_compare(torch_u1, ms_u1) | |||
| assert np.allclose(np.sort(np.abs(torch_v1.numpy())), np.sort(np.abs(ms_v1.numpy()))) | |||
| type_shape_compare(torch_v1, ms_v1) | |||
| @SKIP_ENV_GPU(reason="Eig currently not support on GPU") | |||
| def test_eig_complex(): | |||
| np_array1 = np.random.randn(2, 2).astype(np.complex64) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| torch_u1, torch_v1 = torch.linalg.eig(torch_tensor1) | |||
| ms_u1, ms_v1 = ms_torch.eig(ms_tensor1) | |||
| assert np.allclose(np.sort(np.abs(torch_u1.numpy())), np.sort(np.abs(ms_u1.numpy()))) | |||
| type_shape_compare(torch_u1, ms_u1) | |||
| assert np.allclose(np.sort(np.abs(torch_v1.numpy())), np.sort(np.abs(ms_v1.numpy()))) | |||
| type_shape_compare(torch_v1, ms_v1) | |||
| @SKIP_ENV_GPU(reason="Eig currently not support on GPU") | |||
| def test_eig(): | |||
| for type1 in (np.float64, np.float32, np.complex64): | |||
| np_array1 = np.array([[1, 2], [3, 4]]).astype(type1) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| torch_u, torch_v = torch.linalg.eig(torch_tensor1) | |||
| ms_u, ms_v = ms_torch.eig(ms_tensor1) | |||
| #ms.ops.dist currently only support float32 and float64 type | |||
| #To calculate Euclidean distance of complex componets, use np.linalg.norm instead | |||
| torch_y = torch.dist(torch_v @ torch.diag(torch_u) @ torch.linalg.inv(torch_v), torch_tensor1) | |||
| ms_out1 = ms_v @ ms.ops.diag(ms_u) @ ms.ops.inverse(ms_v) | |||
| ms_y = np.linalg.norm(ms_out1.numpy() - ms_tensor1.numpy()) | |||
| assert np.allclose(ms_y, torch_y.numpy(), atol=1e-7) | |||
| assert ms_u.numpy().dtype == torch_u.numpy().dtype | |||
| assert ms_u.numpy().shape == torch_u.numpy().shape | |||
| assert ms_v.numpy().dtype == torch_v.numpy().dtype | |||
| assert ms_v.numpy().shape == torch_v.numpy().shape | |||
| np_array1 = np.array([[1, 2], [3, 4]]).astype(np.float32) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| torch_u1, torch_v1 = torch.linalg.eig(torch_tensor1) | |||
| ms_u1, ms_v1 = ms_torch.eig(ms_tensor1) | |||
| param_compare(torch_u1, ms_u1) | |||
| param_compare(torch_v1, ms_v1) | |||
| def test_vander(): | |||
| np_array = [1, 2, 3, 4, 5] | |||
| @@ -2246,7 +2372,7 @@ def test_histogramdd(): | |||
| #TODO: Currently not support float64 dtype | |||
| np_array1 = np.array([[0., 1.], [1., 0.], [2., 0.], [2., 0.]]).astype(np.float32) | |||
| np_array2 = np.array([[0., 0.], [1., 1.], [2., 2.]]).astype(np.float32) | |||
| np_array3 = np.arange(15).reshape(5, 3).astype(np.float32) | |||
| np_array3 = np.arange(15).reshape(5, 3).astype(np.float64) | |||
| weight = np.array([1., 2., 4., 8.]).astype(np.float32) | |||
| range1 = [0., 1., 0., 1.] | |||
| @@ -2265,6 +2391,13 @@ def test_histogramdd(): | |||
| ms_hist2, ms_edge2 = ms_torch.histogramdd(ms_tensor2, bins=(2, 2), range=range1, density=True) | |||
| torch_hist3, torch_edge3 = torch.histogramdd(torch_tensor3, (2, 3, 4)) | |||
| ms_hist3, ms_edge3 = ms_torch.histogramdd(ms_tensor3, (2, 3, 4)) | |||
| if is_test_under_pynative_context(): | |||
| torch_hist4 = torch.histogramdd(torch_tensor3, (2, 3, 4)).hist | |||
| torch_edge4 = torch.histogramdd(torch_tensor3, (2, 3, 4)).bin_edges | |||
| ms_hist4 = ms_torch.histogramdd(ms_tensor3, (2, 3, 4)).hist | |||
| ms_edge4 = ms_torch.histogramdd(ms_tensor3, (2, 3, 4)).bin_edges | |||
| param_compare(torch_hist4, ms_hist4) | |||
| param_compare(torch_edge4, ms_edge4) | |||
| torch_res = [torch_hist1, torch_hist2, torch_hist3, torch_edge1, torch_edge2, torch_edge3] | |||
| ms_res = [ms_hist1, ms_hist2, ms_hist3, ms_edge1, ms_edge2, ms_edge3] | |||
| @@ -2294,7 +2427,7 @@ def test_pinverse(): | |||
| param_compare(ms_out3, torch_out3, atol=1e-5) | |||
| def test_symeig(): | |||
| np_array = np.random.randn(5, 5) | |||
| np_array = np.random.randn(5, 5).astype(np.float32) | |||
| torch_tensor1 = torch.tensor(np_array) | |||
| torch_tensor = torch_tensor1 + torch_tensor1.t() | |||
| ms_tensor1 = ms_torch.tensor(np_array) | |||
| @@ -2311,8 +2444,20 @@ def test_symeig(): | |||
| param_compare(torch_val1, ms_val1) | |||
| param_compare(torch_val2, ms_val2) | |||
| param_compare(torch_val3, ms_val3) | |||
| param_compare(torch_vec2.abs(), ms_vec2.abs()) | |||
| param_compare(torch_vec2.abs(), ms_vec2.abs(), atol=1e-5) | |||
| @SKIP_ENV_ASCEND(reason="symeig currently not support float64 on Ascend") | |||
| def test_symeig_fp64(): | |||
| np_array = np.random.randn(2, 2) | |||
| torch_tensor1 = torch.tensor(np_array) | |||
| torch_tensor = torch_tensor1 + torch_tensor1.t() | |||
| ms_tensor1 = ms_torch.tensor(np_array) | |||
| ms_tensor = ms_tensor1 + ms_tensor1.t() | |||
| torch_val1, _ = torch.symeig(torch_tensor) | |||
| ms_val1, _ = ms_torch.symeig(ms_tensor) | |||
| param_compare(torch_val1, ms_val1) | |||
| @SKIP_ENV_GRAPH_MODE(reason="graph mode cannot support collections.namedtuple.") | |||
| @SKIP_ENV_ASCEND(reason="Currently not support Eigh on Ascend") | |||
| @@ -2460,7 +2605,7 @@ def test_view_as_complex(): | |||
| param_compare(torch_out2, ms_out2) | |||
| def test_chain_matmul(): | |||
| for type1 in (np.float32, np.int32, np.int64): | |||
| for type1 in (np.float32, np.int32): | |||
| np_array1 = np.random.randn(2, 3).astype(type1) | |||
| np_array2 = np.random.randn(3, 4).astype(type1) | |||
| np_array3 = np.random.randn(4, 5).astype(type1) | |||
| @@ -2479,6 +2624,27 @@ def test_chain_matmul(): | |||
| ms_out = ms_torch.chain_matmul(ms_tensor1, ms_tensor2, ms_tensor3, ms_tensor4) | |||
| param_compare(torch_out, ms_out) | |||
| @SKIP_ENV_ASCEND(reason="CANN_VERSION_ERR: ms.ops.Matmul not support int64 input on Ascend.") | |||
| def test_chain_matmul_int64(): | |||
| type1 = np.int64 | |||
| np_array1 = np.random.randn(2, 3).astype(type1) | |||
| np_array2 = np.random.randn(3, 4).astype(type1) | |||
| np_array3 = np.random.randn(4, 5).astype(type1) | |||
| np_array4 = np.random.randn(5, 6).astype(type1) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| torch_tensor2 = torch.tensor(np_array2) | |||
| torch_tensor3 = torch.tensor(np_array3) | |||
| torch_tensor4 = torch.tensor(np_array4) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| ms_tensor2 = ms_torch.tensor(np_array2) | |||
| ms_tensor3 = ms_torch.tensor(np_array3) | |||
| ms_tensor4 = ms_torch.tensor(np_array4) | |||
| torch_out = torch.chain_matmul(torch_tensor1, torch_tensor2, torch_tensor3, torch_tensor4) | |||
| ms_out = ms_torch.chain_matmul(ms_tensor1, ms_tensor2, ms_tensor3, ms_tensor4) | |||
| param_compare(torch_out, ms_out) | |||
| @SKIP_ENV_ASCEND(reason="Currently not support float64 on Ascend") | |||
| def test_chain_matmul_fp64(): | |||
| np_array1 = np.random.randn(4, 5).astype(np.float64) | |||
| @@ -2578,7 +2744,10 @@ def test_cumulative_trapezoid1(): | |||
| param_compare(torch_out3, ms_out3) | |||
| def test_log1p(): | |||
| x = np.random.randn(3, 5) | |||
| if is_test_under_ascend_context(): | |||
| x = (np.random.rand(3, 5) - 1).astype(np.float32) | |||
| else: | |||
| x = np.random.randn(3, 5) | |||
| torch_tensor = torch.tensor(x) | |||
| torch_out = torch.log1p(torch_tensor) | |||
| @@ -2588,9 +2757,9 @@ def test_log1p(): | |||
| param_compare(torch_out, ms_out, equal_nan=True) | |||
| @SKIP_ENV_ASCEND(reason="not support inf on Ascend, func test will be cover in test_log10 in test_tensor.py") | |||
| def test_log10(): | |||
| x = np.random.rand(3, 5).astype(np.int32) | |||
| torch_tensor1 = torch.tensor(x) | |||
| torch_out1 = torch.log10(torch_tensor1) | |||
| @@ -2599,6 +2768,7 @@ def test_log10(): | |||
| param_compare(torch_out1, ms_out1) | |||
| @SKIP_ENV_ASCEND(reason="not support inf on Ascend, func test will be cover in test_log2 in test_tensor.py") | |||
| def test_log2(): | |||
| x = np.random.rand(3, 5).astype(np.int32) | |||
| @@ -2610,6 +2780,110 @@ def test_log2(): | |||
| param_compare(torch_out1, ms_out1) | |||
| def test_narrow_copy(): | |||
| x = np.random.randn(4, 5).astype(np.float32) | |||
| x1_pt = torch.tensor(x) | |||
| x1_ms = ms_torch.tensor(x) | |||
| x1_ms_temp = x1_ms | |||
| out1_pt = x1_pt.narrow_copy(0, 1, 2) | |||
| out1_ms = x1_ms.narrow_copy(0, 1, 2) | |||
| out2_pt = x1_pt.narrow_copy(-1, 2, 3) | |||
| out2_ms = x1_ms.narrow_copy(-1, 2, 3) | |||
| param_compare(out1_pt, out1_ms) | |||
| param_compare(out2_pt, out2_ms) | |||
| assert np.allclose(x1_ms_temp.numpy(), x1_ms.numpy()) | |||
| def test_narrow_copy1(): | |||
| x = np.random.randn(4, 5).astype(np.float32) | |||
| x1_ms = ms_torch.tensor(x) | |||
| x1_ms_temp = x1_ms.clone() | |||
| out1_ms = x1_ms.narrow_copy(0, 1, 2) | |||
| out1_ms[0][0] = 1000 | |||
| param_compare(x1_ms_temp, x1_ms) | |||
| def test_matrix_rank(): | |||
| A = np.triu(np.random.randn(4, 4).astype(np.float32)) | |||
| A1 = A + A.T | |||
| A_t = torch.tensor(A1) | |||
| A_ms = ms_torch.tensor(A1) | |||
| torch_out1 = torch.matrix_rank(A_t, symmetric=True, tol=1.0) | |||
| ms_out1 = ms_torch.matrix_rank(A_ms, symmetric=True, tol=1.0) | |||
| param_compare(torch_out1, ms_out1) | |||
| @SKIP_ENV_ASCEND(reason="matrix_rank currently not support float64 on Ascend") | |||
| def test_matrix_rank_fp64(): | |||
| A = np.triu(np.random.randn(2, 2)) | |||
| A1 = A + A.T | |||
| A_t = torch.tensor(A1) | |||
| A_ms = ms_torch.tensor(A1) | |||
| torch_out1 = torch.matrix_rank(A_t) | |||
| ms_out1 = ms_torch.matrix_rank(A_ms) | |||
| param_compare(torch_out1, ms_out1) | |||
| @SKIP_ENV_ASCEND(reason="ormqr currently not support on Ascend") | |||
| @SKIP_ENV_CPU(reason="ormqr currently not support on CPU") | |||
| def test_ormqr(): | |||
| a = np.random.randn(3, 3) | |||
| b = np.random.randn(3) | |||
| c = np.random.randn(3, 3) | |||
| A_t = torch.tensor(a) | |||
| B_t = torch.tensor(b) | |||
| C_t = torch.tensor(c) | |||
| A_ms = ms_torch.tensor(a) | |||
| B_ms = ms_torch.tensor(b) | |||
| C_ms = ms_torch.tensor(c) | |||
| torch_out1 = torch.ormqr(A_t, B_t, C_t) | |||
| torch_out2 = torch.ormqr(A_t, B_t, C_t, left=False, transpose=True) | |||
| ms_out1 = ms_torch.ormqr(A_ms, B_ms, C_ms) | |||
| ms_out2 = ms_torch.ormqr(A_ms, B_ms, C_ms, left=False, transpose=True) | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2) | |||
| @SKIP_ENV_ASCEND(reason="triangular_solve currently not support on Ascend") | |||
| def test_triangular_solve(): | |||
| np_array1 = np.random.randn(2, 3, 3).astype(np.float32) | |||
| np_array2 = np.random.randn(2, 3, 4).astype(np.float32) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| torch_tensor2 = torch.tensor(np_array2) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| ms_tensor2 = ms_torch.tensor(np_array2) | |||
| A_t = torch_tensor1.triu() | |||
| A_t1 = torch_tensor1.tril() | |||
| X_t = torch.triangular_solve(torch_tensor2, A_t, transpose=True, upper=True) | |||
| X_t1 = torch.triangular_solve(torch_tensor2, A_t1, upper=False, unitriangular=True) | |||
| A_ms1 = ms_tensor1.tril() | |||
| A_ms = ms_tensor1.triu() | |||
| X_ms = ms_torch.triangular_solve(ms_tensor2, A_ms, transpose=True, upper=True) | |||
| X_ms1 = ms_torch.triangular_solve(ms_tensor2, A_ms1, upper=False, unitriangular=True) | |||
| param_compare(X_t, X_ms) | |||
| param_compare(X_t1, X_ms1) | |||
| @SKIP_ENV_GRAPH_MODE(reason='triangular_solve not support namedtuple on graph mode') | |||
| @SKIP_ENV_ASCEND(reason="triangular_solve currently not support on Ascend") | |||
| def test_triangular_solve_namedtuple(): | |||
| np_array1 = np.random.randn(2, 3, 3).astype(np.float32) | |||
| np_array2 = np.random.randn(2, 3, 4).astype(np.float32) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| torch_tensor2 = torch.tensor(np_array2) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| ms_tensor2 = ms_torch.tensor(np_array2) | |||
| A_t = torch_tensor1.triu() | |||
| X_t = torch.triangular_solve(torch_tensor2, A_t, transpose=True, upper=True) | |||
| t_sol = X_t.solution | |||
| t_coef = X_t.cloned_coefficient | |||
| A_ms = ms_tensor1.triu() | |||
| X_ms = ms_torch.triangular_solve(ms_tensor2, A_ms, transpose=True, upper=True) | |||
| ms_sol = X_ms.solution | |||
| ms_coef = X_ms.cloned_coefficient | |||
| param_compare(t_sol, ms_sol) | |||
| param_compare(t_coef, ms_coef) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
| @@ -2628,6 +2902,7 @@ if __name__ == '__main__': | |||
| test_exp2() | |||
| test_exp3() | |||
| test_mul1() | |||
| test_multiply() | |||
| test_mul2() | |||
| test_absolute() | |||
| test_acos() | |||
| @@ -2684,6 +2959,7 @@ if __name__ == '__main__': | |||
| test_igamma() | |||
| test_mvlgamma() | |||
| test_nan_to_num() | |||
| test_nan_to_num1() | |||
| test_neg() | |||
| test_nextafter() | |||
| test_positive() | |||
| @@ -2713,9 +2989,13 @@ if __name__ == '__main__': | |||
| test_addmm() | |||
| test_logdet() | |||
| test_inner() | |||
| test_inner_int() | |||
| test_inner_scalar() | |||
| test_repeat_interleave() | |||
| test_matrix_power() | |||
| test_poisson() | |||
| test_eig_complex() | |||
| test_eig_fp64() | |||
| test_eig() | |||
| test_vander() | |||
| test_histogramdd() | |||
| @@ -2747,4 +3027,15 @@ if __name__ == '__main__': | |||
| test_igammac() | |||
| test_log1p() | |||
| test_log10() | |||
| test_log2() | |||
| test_log2() | |||
| test_narrow_copy() | |||
| test_narrow_copy1() | |||
| test_gradient_fp64() | |||
| test_lerp_fp64() | |||
| test_logaddexp_fp64() | |||
| test_symeig_fp64() | |||
| test_trunc_fp64() | |||
| test_matrix_rank() | |||
| test_ormqr() | |||
| test_triangular_solve() | |||
| test_triangular_solve_namedtuple() | |||
testing/ut/pytorch/functional/test_blas_and_lapack.py → testing/ut/pytorch/functional/test_matmul.py
View File
| @@ -1,16 +1,14 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import mindspore as ms | |||
| import msadapter.pytorch as ms_torch | |||
| import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ...utils import set_mode_by_env_config, SKIP_ENV_GPU | |||
| from ...utils import set_mode_by_env_config, param_compare, SKIP_ENV_ASCEND | |||
| set_mode_by_env_config() | |||
| @SKIP_ENV_GPU(reason="not support int-dtype input on GPU, only support float dtype input") | |||
| @SKIP_ENV_ASCEND(reason="CANN_VERSION_ERR: ms.ops.Matmul not support int64 input on Ascend.") | |||
| def test_matmul1(): | |||
| np_1 = np.array([1, 2, 3, 4]).astype(np.int64) | |||
| np_2 = np.array([5, 6, 7, 8]).astype(np.int64) | |||
| @@ -23,8 +21,7 @@ def test_matmul1(): | |||
| torch_tensor_2 = torch.tensor(np_2) | |||
| torch_out = torch.matmul(torch_tensor_1, torch_tensor_2) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| param_compare(torch_out, ms_out) | |||
| def test_matmul2(): | |||
| @@ -38,10 +35,10 @@ def test_matmul2(): | |||
| torch_tensor_1 = torch.tensor(np_1) | |||
| torch_tensor_2 = torch.tensor(np_2) | |||
| torch_out = torch.matmul(torch_tensor_1, torch_tensor_2) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| @SKIP_ENV_GPU(reason="not support int-dtype input on GPU, only support float dtype input") | |||
| param_compare(torch_out, ms_out) | |||
| def test_matmul3(): | |||
| np_1 = np.arange(0, 36).reshape(3, 1, 6, 2).astype(np.int32) | |||
| np_2 = np.arange(0, 40).reshape(5, 2, 4).astype(np.int32) | |||
| @@ -54,11 +51,9 @@ def test_matmul3(): | |||
| torch_tensor_2 = torch.tensor(np_2) | |||
| torch_out = torch.matmul(torch_tensor_1, torch_tensor_2) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| param_compare(torch_out, ms_out) | |||
| @SKIP_ENV_GPU(reason="not support int-dtype input on GPU, only support float dtype input") | |||
| def test_matmul4(): | |||
| np_1 = np.arange(0, 12).reshape(3, 1, 2, 2).astype(np.int32) | |||
| np_2 = np.arange(0, 20).reshape(5, 2, 2).astype(np.int32) | |||
| @@ -71,8 +66,7 @@ def test_matmul4(): | |||
| torch_tensor_2 = torch.tensor(np_2) | |||
| torch_out = torch.matmul(torch_tensor_1, torch_tensor_2) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| param_compare(torch_out, ms_out) | |||
| if __name__ == '__main__': | |||
+ 21
- 7
testing/ut/pytorch/functional/test_mm.py
View File
| @@ -5,14 +5,14 @@ import mindspore as ms | |||
| import msadapter.pytorch as ms_torch | |||
| import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ...utils import set_mode_by_env_config | |||
| from ...utils import SKIP_ENV_ASCEND, param_compare, set_mode_by_env_config, SKIP_ENV_GPU | |||
| set_mode_by_env_config() | |||
| @SKIP_ENV_ASCEND(reason="CANN_VERSION_ERR: ms.ops.Matmul not support int64 input on Ascend.") | |||
| def test_mm1(): | |||
| np_1 = np.array([[1, 2],[3, 4]]) | |||
| np_2 = np.array([[1, 2],[3, 4]]) | |||
| np_2 = np.array([[-1, 2],[3, 4]]) | |||
| ms_tensor_1 = ms_torch.tensor(np_1) | |||
| ms_tensor_2 = ms_torch.tensor(np_2) | |||
| ms_result = ms_torch.mm(ms_tensor_1, ms_tensor_2) | |||
| @@ -25,8 +25,8 @@ def test_mm1(): | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| def test_mm2(): | |||
| np_1 = np.array([[1., 2],[3, 4]]) | |||
| np_2 = np.array([[1, 2.],[3, 4]]) | |||
| np_1 = np.array([[1., 2],[3, 4]]).astype(np.float32) | |||
| np_2 = np.array([[1, 2.],[3, 4]]).astype(np.float32) | |||
| ms_tensor_1 = ms_torch.tensor(np_1) | |||
| ms_tensor_2 = ms_torch.tensor(np_2) | |||
| ms_result = ms_torch.mm(ms_tensor_1, ms_tensor_2) | |||
| @@ -35,10 +35,24 @@ def test_mm2(): | |||
| torch_tensor_2 = torch.tensor(np_2) | |||
| torch_result = torch.mm(torch_tensor_1, torch_tensor_2) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| param_compare(ms_result, torch_result) | |||
| @SKIP_ENV_ASCEND(reason="mm currently not support float64 on Ascend") | |||
| def test_mm2_fp64(): | |||
| np_1 = np.random.randn(2, 2) | |||
| np_2 = np.random.randn(2, 2) | |||
| ms_tensor_1 = ms_torch.tensor(np_1) | |||
| ms_tensor_2 = ms_torch.tensor(np_2) | |||
| ms_result = ms_torch.mm(ms_tensor_1, ms_tensor_2) | |||
| torch_tensor_1 = torch.tensor(np_1) | |||
| torch_tensor_2 = torch.tensor(np_2) | |||
| torch_result = torch.mm(torch_tensor_1, torch_tensor_2) | |||
| param_compare(ms_result, torch_result) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
| test_mm1() | |||
| test_mm2() | |||
| test_mm2_fp64() | |||
+ 42
- 11
testing/ut/pytorch/functional/test_reduction.py
View File
| @@ -7,7 +7,8 @@ import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from msadapter.pytorch.nn import Module | |||
| from ...utils import SKIP_ENV_GRAPH_MODE, set_mode_by_env_config, param_compare | |||
| from ...utils import SKIP_ENV_GRAPH_MODE, set_mode_by_env_config, param_compare, SKIP_ENV_ASCEND, \ | |||
| SKIP_ENV_GPU | |||
| set_mode_by_env_config() | |||
| def test_max(): | |||
| @@ -48,9 +49,9 @@ def test_max(): | |||
| ms_out1 = ms_max1(ms_tensor) | |||
| ms_out2 = ms_max2(ms_tensor) | |||
| assert ms_out1[0].numpy().all() == pt_out1[0].numpy().all() | |||
| assert ms_out2[1].numpy().all() == pt_out2[1].numpy().all() | |||
| param_compare(ms_out1, pt_out1) | |||
| param_compare(ms_out2, pt_out2) | |||
| def test_max1(): | |||
| np_array = np.array([[1, 2],[3, 4]]).astype(np.float32) | |||
| @@ -61,8 +62,7 @@ def test_max1(): | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| ms_out = ms_torch.max(ms_tensor) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| param_compare(torch_out, ms_out) | |||
| @SKIP_ENV_GRAPH_MODE(reason="graph cannot support collections.namedtuple.") | |||
| @@ -75,9 +75,8 @@ def test_max2(): | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| ms_out = ms_torch.max(ms_tensor, dim=1, keepdim=True) | |||
| assert np.allclose(ms_out.values.asnumpy(), torch_out.values.numpy()) | |||
| assert np.allclose(ms_out.indices.asnumpy(), torch_out.indices.numpy()) | |||
| assert ms_out.values.asnumpy().dtype == torch_out.values.numpy().dtype | |||
| param_compare(torch_out, ms_out) | |||
| @SKIP_ENV_GRAPH_MODE(reason="graph cannot support collections.namedtuple.") | |||
| @@ -90,9 +89,22 @@ def test_max3(): | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| ms_out = ms_torch.max(ms_tensor, dim=0) | |||
| assert np.allclose(ms_out.values.asnumpy(), torch_out.values.numpy()) | |||
| assert np.allclose(ms_out.indices.asnumpy(), torch_out.indices.numpy()) | |||
| assert ms_out.values.asnumpy().dtype == torch_out.values.numpy().dtype | |||
| param_compare(torch_out, ms_out) | |||
| def test_max4(): | |||
| np_array1 = (np.random.randn(2, 3) * 5).astype(np.int32) | |||
| np_array2 = (np.random.randn(2, 3) * 5).astype(np.int32) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| torch_tensor2 = torch.tensor(np_array2) | |||
| torch_out = torch.max(input=torch_tensor1, other=torch_tensor2) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| ms_tensor2 = ms_torch.tensor(np_array2) | |||
| ms_out = ms_torch.max(input=ms_tensor1, other=ms_tensor2) | |||
| param_compare(torch_out, ms_out) | |||
| def test_mean_sum1(): | |||
| @@ -290,6 +302,20 @@ def test_min4(): | |||
| assert np.allclose(ms_out2.asnumpy(), torch_indices.numpy()) | |||
| assert ms_out1.asnumpy().dtype == torch_out.numpy().dtype | |||
| def test_min5(): | |||
| np_array1 = (np.random.randn(2, 3) * 5).astype(np.int32) | |||
| np_array2 = (np.random.randn(2, 3) * 5).astype(np.int32) | |||
| torch_tensor1 = torch.tensor(np_array1) | |||
| torch_tensor2 = torch.tensor(np_array2) | |||
| torch_out = torch.min(input=torch_tensor1, other=torch_tensor2) | |||
| ms_tensor1 = ms_torch.tensor(np_array1) | |||
| ms_tensor2 = ms_torch.tensor(np_array2) | |||
| ms_out = ms_torch.min(input=ms_tensor1, other=ms_tensor2) | |||
| param_compare(torch_out, ms_out) | |||
| def test_prod(): | |||
| np_array = np.random.randn(2, 3, 4) * 2 | |||
| @@ -322,6 +348,9 @@ def test_sum(): | |||
| assert np.allclose(ms_output.asnumpy(), torch_output.numpy()) | |||
| assert ms_output.asnumpy().dtype == torch_output.numpy().dtype | |||
| @SKIP_ENV_GPU(reason="ms.Tensor(float64_max).astype(ms.int16), gpu result is not the same as CPU, will have wrong result") | |||
| @SKIP_ENV_ASCEND(reason='ms.Tensor(float64_max).astype(ms.int16), ascend result is not the same as CPU, will have wrong result') | |||
| def test_sum_float64_max_to_int16(): | |||
| float64_max = np.finfo(np.float64).max | |||
| torch_output = torch.sum(torch.tensor([float64_max, float64_max]), dtype=torch.int16) | |||
| ms_output = ms_torch.sum(ms_torch.tensor([float64_max, float64_max]), dtype=ms_torch.int16) | |||
| @@ -334,6 +363,7 @@ if __name__ == '__main__': | |||
| test_max1() | |||
| test_max2() | |||
| test_max3() | |||
| test_max4() | |||
| test_mean_sum1() | |||
| test_mean_sum2() | |||
| test_mean_sum3() | |||
| @@ -347,5 +377,6 @@ if __name__ == '__main__': | |||
| test_min2() | |||
| test_min3() | |||
| test_min4() | |||
| test_min5() | |||
| test_prod() | |||
| test_sum() | |||
+ 18
- 12
testing/ut/pytorch/functional/test_softmax.py
View File
| @@ -7,29 +7,35 @@ import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ...utils import set_mode_by_env_config | |||
| from ...utils import SKIP_ENV_ASCEND, SKIP_ENV_CPU, SKIP_ENV_GPU, param_compare, set_mode_by_env_config, is_test_under_ascend_context | |||
| set_mode_by_env_config() | |||
| @SKIP_ENV_ASCEND(reason="currently softmax not support float64 on Ascend") | |||
| def test_softmax_fp64(): | |||
| np_array = np.random.randn(2, 3) | |||
| torch_tensor = torch.tensor(np_array) | |||
| torch_out1 = torch.softmax(torch_tensor, -1, torch.float32) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| ms_out1 = ms_torch.softmax(ms_tensor, -1, ms_torch.float32) | |||
| param_compare(torch_out1, ms_out1) | |||
| def test_softmax(): | |||
| np_array = np.random.randn(4, 3, 3, 20) | |||
| np_array = np.random.randn(4, 3, 3, 20).astype(np.float32) | |||
| torch_tensor = torch.tensor(np_array) | |||
| torch_out1 = torch.softmax(torch_tensor, -1, torch.float32) | |||
| torch_out2 = torch.softmax(torch_tensor, 3, float) | |||
| torch_out3 = torch.softmax(torch_tensor, 2) | |||
| torch_out2 = torch.softmax(torch_tensor, 2) | |||
| ms_tensor = ms_torch.tensor(np_array) | |||
| ms_out1 = ms_torch.softmax(ms_tensor, -1, ms_torch.float32) | |||
| ms_out2 = ms_torch.softmax(ms_tensor, 3, float) | |||
| ms_out3 = ms_torch.softmax(ms_tensor, 2) | |||
| ms_out2 = ms_torch.softmax(ms_tensor, 2) | |||
| assert np.allclose(ms_out1.asnumpy(), torch_out1.numpy()) | |||
| assert ms_out1.asnumpy().dtype == torch_out1.numpy().dtype | |||
| assert np.allclose(ms_out2.asnumpy(), torch_out2.numpy()) | |||
| assert ms_out2.asnumpy().dtype == torch_out2.numpy().dtype | |||
| assert np.allclose(ms_out3.asnumpy(), torch_out3.numpy()) | |||
| assert ms_out3.asnumpy().dtype == torch_out3.numpy().dtype | |||
| param_compare(torch_out1, ms_out1) | |||
| param_compare(torch_out2, ms_out2) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
| test_softmax() | |||
| test_softmax_fp64() | |||
+ 15
- 5
testing/ut/pytorch/functional/test_stack.py
View File
| @@ -7,7 +7,7 @@ import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ...utils import set_mode_by_env_config | |||
| from ...utils import set_mode_by_env_config, param_compare | |||
| set_mode_by_env_config() | |||
| def test_stack1(): | |||
| @@ -22,8 +22,7 @@ def test_stack1(): | |||
| torch_tensor_2 = torch.tensor(np_2) | |||
| torch_result = torch.stack((torch_tensor_1, torch_tensor_2), dim=1) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| param_compare(ms_result, torch_result) | |||
| def test_stack2(): | |||
| np_1 = np.array([[1, 2], [3, 4]]) | |||
| @@ -37,10 +36,21 @@ def test_stack2(): | |||
| torch_tensor_2 = torch.tensor(np_2) | |||
| torch_result = torch.stack((torch_tensor_1, torch_tensor_2)) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| param_compare(ms_result, torch_result) | |||
| def test_stack3(): | |||
| np_1 = np.array([[0, 1], [1, 1]]) | |||
| ms_tensor_1 = ms_torch.tensor(np_1) | |||
| ms_result = ms_torch.stack((ms_tensor_1.byte(), ms_tensor_1.char())) | |||
| torch_tensor_1 = torch.tensor(np_1) | |||
| torch_result = torch.stack((torch_tensor_1.byte(), torch_tensor_1.char())) | |||
| param_compare(ms_result, torch_result) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
| test_stack1() | |||
| test_stack2() | |||
| test_stack3() | |||
+ 14
- 8
testing/ut/pytorch/functional/test_zeros.py
View File
| @@ -7,26 +7,32 @@ import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ...utils import set_mode_by_env_config | |||
| from ...utils import set_mode_by_env_config, param_compare | |||
| set_mode_by_env_config() | |||
| def test_zeros1(): | |||
| ms_result = ms_torch.zeros(1, 2, 3) | |||
| torch_result = torch.zeros(1, 2, 3) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| param_compare(ms_result, torch_result) | |||
| def test_zeros2(): | |||
| ms_result = ms_torch.zeros((1, 2, 3)) | |||
| torch_result = torch.zeros((1, 2, 3)) | |||
| param_compare(ms_result, torch_result) | |||
| def test_zeros3(): | |||
| ms_result = ms_torch.zeros([5], dtype=ms_torch.float64) | |||
| torch_result = torch.zeros([5], dtype=torch.float64) | |||
| param_compare(ms_result, torch_result) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy()) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| def test_zeros4(): | |||
| ms_result = ms_torch.zeros(size=(2, 3), dtype=ms_torch.float64) | |||
| torch_result = torch.zeros(size=(2, 3), dtype=torch.float64) | |||
| param_compare(ms_result, torch_result) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
| test_zeros1() | |||
| test_zeros2() | |||
| test_zeros3() | |||
| test_zeros4() | |||
+ 1
- 1
testing/ut/pytorch/nn/functional/test_avg_pooling.py
View File
| @@ -268,7 +268,7 @@ def test_avg_pool2d_4(): | |||
| ms_output = ms_fun(ms_tensor) | |||
| if is_under_ascend_context(): | |||
| param_compare(ms_output, torch_output, atol=1e-3) | |||
| param_compare(ms_output, torch_output, atol=3e-3) | |||
| else: | |||
| param_compare(ms_output, torch_output, atol=1e-7) | |||
+ 5
- 5
testing/ut/pytorch/nn/functional/test_conv_transpose3d.py
View File
| @@ -14,7 +14,7 @@ set_mode_by_env_config() | |||
| _atol = 1e-5 | |||
| if is_test_under_ascend_context(): | |||
| _atol = 3e-2 | |||
| _atol = 8e-2 | |||
| def test_conv_transpose3d1(): | |||
| np_input = np.random.randn(2, 16, 50, 10, 20).astype(np.float32) | |||
| @@ -31,7 +31,7 @@ def test_conv_transpose3d1(): | |||
| if is_test_under_gpu_context(): | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy(), rtol=1e-3, atol=1e-4) | |||
| else: | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy(), rtol=1e-3, atol=_atol) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy(), rtol=1e-2, atol=_atol) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| assert ms_result.asnumpy().shape == torch_result.numpy().shape | |||
| @@ -50,7 +50,7 @@ def test_conv_transpose3d2(): | |||
| torch_result = torch.nn.functional.conv_transpose3d( | |||
| torch_tensor, torch_weight, stride=2, padding=1, groups=1, dilation=1) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy(), rtol=1e-3, atol=_atol) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy(), rtol=1e-2, atol=_atol) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| assert ms_result.asnumpy().shape == torch_result.numpy().shape | |||
| @@ -69,7 +69,7 @@ def test_conv_transpose3d3(): | |||
| torch_result = torch.nn.functional.conv_transpose3d( | |||
| torch_tensor, torch_weight, stride=2, padding=0, output_padding=0, groups=1, dilation=1) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy(), rtol=1e-3, atol=_atol) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy(), rtol=1e-2, atol=_atol) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| assert ms_result.asnumpy().shape == torch_result.numpy().shape | |||
| @@ -88,7 +88,7 @@ def test_conv_transpose3d4(): | |||
| torch_result = torch.nn.functional.conv_transpose3d( | |||
| torch_tensor, torch_weight, stride=2, padding=(1, 1, 2), groups=1, dilation=1) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy(), rtol=1e-3, atol=_atol) | |||
| assert np.allclose(ms_result.asnumpy(), torch_result.numpy(), rtol=1e-2, atol=_atol) | |||
| assert ms_result.asnumpy().dtype == torch_result.numpy().dtype | |||
| assert ms_result.asnumpy().shape == torch_result.numpy().shape | |||
+ 16
- 16
testing/ut/pytorch/nn/functional/test_dropout.py
View File
| @@ -198,10 +198,10 @@ def test_alphadropout1(): | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.nn.functional.alpha_dropout(ms_input, 0.2, True) | |||
| mean = ms_input.mean() | |||
| std = ms_input.std() | |||
| assert abs(ms_out.data.mean() - mean) < 0.1 | |||
| assert abs(ms_out.data.std() - std) < 0.1 | |||
| mean = ms_input.mean().numpy() | |||
| std = ms_input.std().numpy() | |||
| assert np.abs(ms_out.data.mean().numpy() - mean) < 0.1 | |||
| assert np.abs(ms_out.data.std().numpy() - std) < 0.1 | |||
| torch_input = torch.tensor(data) | |||
| torch_out = torch.nn.functional.alpha_dropout(torch_input, 0.2, True) | |||
| @@ -216,10 +216,10 @@ def test_alphadropout2(): | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.nn.functional.alpha_dropout(ms_input, 0.6, True) | |||
| mean = ms_input.mean() | |||
| std = ms_input.std() | |||
| assert abs(ms_out.data.mean() - mean) < 0.1 | |||
| assert abs(ms_out.data.std() - std) < 0.1 | |||
| mean = ms_input.mean().numpy() | |||
| std = ms_input.std().numpy() | |||
| assert np.abs(ms_out.data.mean().numpy() - mean) < 0.1 | |||
| assert np.abs(ms_out.data.std().numpy() - std) < 0.1 | |||
| torch_input = torch.tensor(data) | |||
| torch_out = torch.nn.functional.alpha_dropout(torch_input, 0.6, True) | |||
| @@ -263,10 +263,10 @@ def test_featurealphadropout1(): | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.nn.functional.feature_alpha_dropout(ms_input, 0.5, True) | |||
| mean = ms_input.mean() | |||
| std = ms_input.std() | |||
| assert abs(ms_out.data.mean() - mean) < 0.1 | |||
| assert abs(ms_out.data.std() - std) < 0.1 | |||
| mean = ms_input.mean().numpy() | |||
| std = ms_input.std().numpy() | |||
| assert np.abs(ms_out.data.mean().numpy() - mean) < 0.1 | |||
| assert np.abs(ms_out.data.std().numpy() - std) < 0.1 | |||
| torch_input = torch.tensor(data) | |||
| torch_out = torch.nn.functional.feature_alpha_dropout(torch_input, 0.5, True) | |||
| @@ -285,10 +285,10 @@ def test_featurealphadropout2(): | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.nn.functional.feature_alpha_dropout(ms_input, 0.35, True) | |||
| mean = ms_input.mean() | |||
| std = ms_input.std() | |||
| assert abs(ms_out.data.mean() - mean) < 0.1 | |||
| assert abs(ms_out.data.std() - std) < 0.1 | |||
| mean = ms_input.mean().numpy() | |||
| std = ms_input.std().numpy() | |||
| assert np.abs(ms_out.data.mean().numpy() - mean) < 0.1 | |||
| assert np.abs(ms_out.data.std().numpy() - std) < 0.1 | |||
| torch_input = torch.tensor(data) | |||
| torch_out = torch.nn.functional.feature_alpha_dropout(torch_input, 0.35, True) | |||
+ 3
- 2
testing/ut/pytorch/nn/functional/test_functional.py
View File
| @@ -14,10 +14,11 @@ set_mode_by_env_config() | |||
| def test_interpolate1(): | |||
| tensor = np.arange(1, 5).reshape((1, 1, 2, 2)).astype(np.float32) | |||
| torch_tensor = torch.tensor(tensor) | |||
| torch_output = torch.nn.functional.interpolate(torch_tensor, size=3, mode="bilinear", align_corners=True) | |||
| torch_output = torch.nn.functional.interpolate(torch_tensor, size=[3, torch.tensor(3)], | |||
| mode="bilinear", align_corners=True) | |||
| ms_tensor = ms_torch.tensor(tensor) | |||
| ms_output = interpolate(ms_tensor, size=3, mode="bilinear", align_corners=True) | |||
| ms_output = interpolate(ms_tensor, size=[3, ms_torch.tensor(3)], mode="bilinear", align_corners=True) | |||
| assert np.allclose(ms_output.asnumpy(), torch_output.numpy()) | |||
+ 61
- 2
testing/ut/pytorch/nn/functional/test_grid_sample.py
View File
| @@ -8,7 +8,7 @@ from torch.nn.functional import grid_sample | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ....utils import set_mode_by_env_config | |||
| from ....utils import SKIP_ENV_ASCEND, SKIP_ENV_CPU, SKIP_ENV_GPU, set_mode_by_env_config, param_compare | |||
| set_mode_by_env_config() | |||
| @@ -22,9 +22,68 @@ def test_grid_sample(): | |||
| torch_input = torch.tensor(data) | |||
| torch_out = grid_sample(torch_input, grid=torch.tensor(grid_data)) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| param_compare(ms_out, torch_out) | |||
| def test_grid_sample_all_args(): | |||
| data = np.array(np.ones(shape=(2, 2, 2, 2))).astype(np.float32) | |||
| grid_data = np.arange(0.2, 1, 0.1).reshape((2, 2, 1, 2)).astype(np.float32) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.nn.functional.grid_sample(ms_input, grid=ms_torch.tensor(grid_data), \ | |||
| mode="nearest", padding_mode="reflection", align_corners=True) | |||
| torch_input = torch.tensor(data) | |||
| torch_out = grid_sample(torch_input, grid=torch.tensor(grid_data), \ | |||
| mode="nearest", padding_mode="reflection", align_corners=True) | |||
| param_compare(ms_out, torch_out) | |||
| @SKIP_ENV_ASCEND(reason="grid_sample currently not support float64 on Ascend") | |||
| def test_grid_sample_all_args_fp64(): | |||
| data = np.array(np.ones(shape=(1, 1, 2, 2))).astype(np.float64) | |||
| grid_data = np.arange(0.2, 1, 0.1).reshape((1, 2, 2, 2)).astype(np.float64) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.nn.functional.grid_sample(ms_input, grid=ms_torch.tensor(grid_data), \ | |||
| mode="nearest", padding_mode="reflection", align_corners=True) | |||
| torch_input = torch.tensor(data) | |||
| torch_out = grid_sample(torch_input, grid=torch.tensor(grid_data), \ | |||
| mode="nearest", padding_mode="reflection", align_corners=True) | |||
| param_compare(ms_out, torch_out) | |||
| def test_grid_sample_all_args2(): | |||
| data = np.array(np.ones(shape=(2, 2, 2, 2))).astype(np.float32) | |||
| grid_data = np.arange(0.2, 1, 0.1).reshape((2, 2, 1, 2)).astype(np.float32) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.nn.functional.grid_sample(ms_input, ms_torch.tensor(grid_data), \ | |||
| "nearest", "reflection", True) | |||
| torch_input = torch.tensor(data) | |||
| torch_out = grid_sample(torch_input, torch.tensor(grid_data), \ | |||
| "nearest", "reflection", True) | |||
| param_compare(ms_out, torch_out) | |||
| @SKIP_ENV_ASCEND(reason="grid_sample currently not support float64 on Ascend") | |||
| def test_grid_sample_all_args2_fp64(): | |||
| data = np.array(np.ones(shape=(2, 2, 2, 2))).astype(np.float64) | |||
| grid_data = np.arange(0.2, 1, 0.1).reshape((2, 2, 1, 2)).astype(np.float64) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.nn.functional.grid_sample(ms_input, ms_torch.tensor(grid_data), \ | |||
| "nearest", "reflection", True) | |||
| torch_input = torch.tensor(data) | |||
| torch_out = grid_sample(torch_input, torch.tensor(grid_data), \ | |||
| "nearest", "reflection", True) | |||
| param_compare(ms_out, torch_out) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
| test_grid_sample() | |||
| test_grid_sample_all_args() | |||
| test_grid_sample_all_args2() | |||
| test_grid_sample_all_args_fp64() | |||
| test_grid_sample_all_args2_fp64() | |||
+ 13
- 21
testing/ut/pytorch/nn/functional/test_linear.py
View File
| @@ -1,13 +1,10 @@ | |||
| #!/usr/bin/env python | |||
| # -*- coding: utf-8 -*- | |||
| import mindspore as ms | |||
| import msadapter.pytorch as ms_torch | |||
| import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ....utils import set_mode_by_env_config | |||
| from ....utils import set_mode_by_env_config, param_compare | |||
| set_mode_by_env_config() | |||
| @@ -23,8 +20,7 @@ def test_linear1(): | |||
| torch_weight = torch.tensor(weight) | |||
| torch_out = torch.nn.functional.linear(torch_data, torch_weight) | |||
| assert ms_out.shape == torch_out.shape | |||
| assert ms_out.numpy().dtype == torch_out.numpy().dtype | |||
| param_compare(ms_out, torch_out) | |||
| def test_linear2(): | |||
| data = np.ones((1, 2, 5)).astype(np.float32) | |||
| @@ -41,8 +37,7 @@ def test_linear2(): | |||
| torch_bias = torch.tensor(bias) | |||
| torch_out = torch.nn.functional.linear(torch_data, torch_weight, bias=torch_bias) | |||
| assert ms_out.shape == torch_out.shape | |||
| assert ms_out.numpy().dtype == torch_out.numpy().dtype | |||
| param_compare(ms_out, torch_out) | |||
| def test_linear3(): | |||
| @@ -57,8 +52,7 @@ def test_linear3(): | |||
| torch_weight = torch.tensor(weight) | |||
| torch_out = torch.nn.functional.linear(torch_data, torch_weight) | |||
| assert ms_out.shape == torch_out.shape | |||
| assert ms_out.numpy().dtype == torch_out.numpy().dtype | |||
| param_compare(ms_out, torch_out) | |||
| def test_bilinear(): | |||
| @@ -67,21 +61,19 @@ def test_bilinear(): | |||
| weight = np.random.randn(4, 3, 5) | |||
| bias = np.random.randn(4) | |||
| torch_input1 = torch.tensor(data1) | |||
| torch_input2 = torch.tensor(data2) | |||
| torch_weight = torch.tensor(weight) | |||
| torch_bias = torch.tensor(bias) | |||
| torch_input1 = torch.Tensor(data1) | |||
| torch_input2 = torch.Tensor(data2) | |||
| torch_weight = torch.Tensor(weight) | |||
| torch_bias = torch.Tensor(bias) | |||
| torch_out = torch.nn.functional.bilinear(torch_input1, torch_input2, torch_weight, torch_bias) | |||
| ms_input1 = ms_torch.tensor(data1) | |||
| ms_input2 = ms_torch.tensor(data2) | |||
| ms_weight = ms_torch.tensor(weight) | |||
| ms_bias = ms_torch.tensor(bias) | |||
| ms_input1 = ms_torch.Tensor(data1) | |||
| ms_input2 = ms_torch.Tensor(data2) | |||
| ms_weight = ms_torch.Tensor(weight) | |||
| ms_bias = ms_torch.Tensor(bias) | |||
| ms_out = ms_torch.nn.functional.bilinear(ms_input1, ms_input2, ms_weight, ms_bias) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.shape == torch_out.shape | |||
| assert ms_out.numpy().dtype == torch_out.numpy().dtype | |||
| param_compare(ms_out, torch_out) | |||
| if __name__ == '__main__': | |||
+ 7
- 13
testing/ut/pytorch/nn/functional/test_normalize.py
View File
| @@ -7,7 +7,7 @@ import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ....utils import set_mode_by_env_config | |||
| from ....utils import set_mode_by_env_config, param_compare | |||
| set_mode_by_env_config() | |||
| @@ -22,8 +22,7 @@ def test_normalize1(): | |||
| torch_input = torch.tensor(data) | |||
| torch_out = torch.nn.functional.normalize(torch_input) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| param_compare(ms_out, torch_out) | |||
| def test_normalize2(): | |||
| @@ -37,9 +36,7 @@ def test_normalize2(): | |||
| torch_input = torch.tensor(data) | |||
| torch_out = torch.nn.functional.normalize(torch_input, 2.2, 0, 10) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| param_compare(ms_out, torch_out) | |||
| def test_local_response_norm1(): | |||
| data = np.random.random((4, 4, 4)).astype(np.float32)*10 | |||
| @@ -51,10 +48,9 @@ def test_local_response_norm1(): | |||
| torch_out = torch.nn.functional.local_response_norm(torch_input, 3, 0.01) | |||
| if ms.get_context('device_target') == 'Ascend': | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy(), rtol=1e-3, atol=1e-5) | |||
| param_compare(ms_out, torch_out, rtol=1e-3, atol=1e-5) | |||
| else: | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| param_compare(ms_out, torch_out) | |||
| def test_local_response_norm2(): | |||
| @@ -67,11 +63,9 @@ def test_local_response_norm2(): | |||
| torch_out = torch.nn.functional.local_response_norm(torch_input, 3, 0.01) | |||
| if ms.get_context('device_target') == 'Ascend': | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy(), rtol=1e-3, atol=1e-5) | |||
| param_compare(ms_out, torch_out, rtol=1e-3, atol=1e-5) | |||
| else: | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| param_compare(ms_out, torch_out) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
+ 9
- 11
testing/ut/pytorch/nn/functional/test_one_hot.py
View File
| @@ -7,34 +7,32 @@ import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ....utils import set_mode_by_env_config | |||
| from ....utils import set_mode_by_env_config, param_compare | |||
| set_mode_by_env_config() | |||
| def test_one_hot1(): | |||
| data = np.array([0, 2, 3, 4, 7]).astype(np.int64) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.nn.functional.one_hot(ms_input) | |||
| torch_input = torch.tensor(data) | |||
| torch_out = torch.nn.functional.one_hot(torch_input) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.nn.functional.one_hot(ms_input) | |||
| param_compare(ms_out, torch_out) | |||
| def test_one_hot2(): | |||
| data = np.array([[[0, 2, 3], [1, 1, 2]]]).astype(np.int64) | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.nn.functional.one_hot(input=ms_input, num_classes=5) | |||
| torch_input = torch.tensor(data) | |||
| torch_out = torch.nn.functional.one_hot(input=torch_input, num_classes=5) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.nn.functional.one_hot(input=ms_input, num_classes=5) | |||
| param_compare(ms_out, torch_out) | |||
| if __name__ == '__main__': | |||
+ 240
- 2
testing/ut/pytorch/nn/functional/test_pad.py
View File
| @@ -10,7 +10,8 @@ from mindspore import context | |||
| import msadapter.pytorch as ms_torch | |||
| from msadapter.pytorch.nn.functional import pad | |||
| from ....utils import set_mode_by_env_config | |||
| from ....utils import set_mode_by_env_config, param_compare, SKIP_ENV_CPU, SKIP_ENV_GPU, SKIP_ENV_ASCEND,\ | |||
| SKIP_ENV_GRAPH_MODE | |||
| set_mode_by_env_config() | |||
| @@ -38,8 +39,245 @@ def test_pad_mode(): | |||
| ms_out_1 = pad(ms_t4d, p1d, "reflect") | |||
| assert np.allclose(py_out_1.numpy(), ms_out_1.asnumpy()) | |||
| def test_pad_constant_value_2d_padding_4d_input(): | |||
| padding = (2, 2, 3, 3) | |||
| data = np.random.randn(2, 3, 4, 5).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'constant', None) | |||
| torch_result= F.pad(torch.tensor(data), padding, 'constant', None) | |||
| param_compare(ms_result, torch_result) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'constant', -float('inf')) | |||
| torch_result= F.pad(torch.tensor(data), padding, 'constant', -float('inf')) | |||
| param_compare(ms_result, torch_result) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'constant', 3) | |||
| torch_result= F.pad(torch.tensor(data), padding, 'constant', 3) | |||
| param_compare(ms_result, torch_result) | |||
| def test_pad_constant_value_2d_padding_5d_input(): | |||
| padding = (2, 2, 3, 3) | |||
| data = np.random.randn(2, 3, 4, 5, 6).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'constant', None) | |||
| torch_result= F.pad(torch.tensor(data), padding, 'constant', None) | |||
| param_compare(ms_result, torch_result) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'constant', -float('inf')) | |||
| torch_result= F.pad(torch.tensor(data), padding, 'constant', -float('inf')) | |||
| param_compare(ms_result, torch_result) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'constant', 3) | |||
| torch_result= F.pad(torch.tensor(data), padding, 'constant', 3) | |||
| param_compare(ms_result, torch_result) | |||
| def test_pad_constant_value_3d_padding_4d_input(): | |||
| padding = (2, 2, 3, 3, 4, 4) | |||
| data = np.random.randn(2, 3, 4, 5).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'constant', None) | |||
| torch_result= F.pad(torch.tensor(data), padding, 'constant', None) | |||
| param_compare(ms_result, torch_result) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'constant', -float('inf')) | |||
| torch_result= F.pad(torch.tensor(data), padding, 'constant', -float('inf')) | |||
| param_compare(ms_result, torch_result) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'constant', 3) | |||
| torch_result= F.pad(torch.tensor(data), padding, 'constant', 3) | |||
| param_compare(ms_result, torch_result) | |||
| def test_pad_constant_value_3d_padding_5d_input(): | |||
| padding = (2, 2, 3, 3, 4, 4) | |||
| data = np.random.randn(2, 3, 4, 5, 6).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'constant', None) | |||
| torch_result= F.pad(torch.tensor(data), padding, 'constant', None) | |||
| param_compare(ms_result, torch_result) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'constant', -float('inf')) | |||
| torch_result= F.pad(torch.tensor(data), padding, 'constant', -float('inf')) | |||
| param_compare(ms_result, torch_result) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'constant', 3) | |||
| torch_result= F.pad(torch.tensor(data), padding, 'constant', 3) | |||
| param_compare(ms_result, torch_result) | |||
| def test_pad_reflect_1d_padding_2d_3d_input(): | |||
| padding = (2, 2) | |||
| data = np.random.randn(2, 3, 4).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'reflect') | |||
| torch_result= F.pad(torch.tensor(data), padding, 'reflect') | |||
| param_compare(ms_result, torch_result) | |||
| data = np.random.randn(3, 4).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'reflect') | |||
| torch_result= F.pad(torch.tensor(data), padding, 'reflect') | |||
| param_compare(ms_result, torch_result) | |||
| def test_pad_reflect_2d_padding_3d_4d_input(): | |||
| padding = (2, 2, 3, 3) | |||
| data = np.random.randn(2, 3, 4, 5).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'reflect') | |||
| torch_result= F.pad(torch.tensor(data), padding, 'reflect') | |||
| param_compare(ms_result, torch_result) | |||
| data = np.random.randn(3, 4, 5).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'reflect') | |||
| torch_result= F.pad(torch.tensor(data), padding, 'reflect') | |||
| param_compare(ms_result, torch_result) | |||
| @SKIP_ENV_CPU(reason='reflect mode not support 3d padding') | |||
| @SKIP_ENV_GPU(reason='reflect mode not support 3d padding') | |||
| @SKIP_ENV_ASCEND(reason='reflect mode not support 3d padding') | |||
| def test_pad_reflect_3d_padding_4d_5d_input(): | |||
| padding = (3, 3, 2, 2, 1, 1) | |||
| data = np.random.randn(2, 3, 4, 5).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'reflect') | |||
| torch_result= F.pad(torch.tensor(data), padding, 'reflect') | |||
| param_compare(ms_result, torch_result) | |||
| data = np.random.randn(2, 3, 4, 5, 6).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'reflect') | |||
| torch_result= F.pad(torch.tensor(data), padding, 'reflect') | |||
| param_compare(ms_result, torch_result) | |||
| def test_pad_replicate_1d_padding_2d_3d_input(): | |||
| padding = (2, 2) | |||
| data = np.random.randn(2, 3, 4).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'replicate') | |||
| torch_result= F.pad(torch.tensor(data), padding, 'replicate') | |||
| param_compare(ms_result, torch_result) | |||
| data = np.random.randn(3, 4).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'replicate') | |||
| torch_result= F.pad(torch.tensor(data), padding, 'replicate') | |||
| param_compare(ms_result, torch_result) | |||
| def test_pad_replicate_2d_padding_3d_4d_input(): | |||
| padding = (2, 2, 3, 3) | |||
| data = np.random.randn(2, 3, 4, 5).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'replicate') | |||
| torch_result= F.pad(torch.tensor(data), padding, 'replicate') | |||
| param_compare(ms_result, torch_result) | |||
| data = np.random.randn(3, 4, 5).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'replicate') | |||
| torch_result= F.pad(torch.tensor(data), padding, 'replicate') | |||
| param_compare(ms_result, torch_result) | |||
| def test_pad_replicate_3d_padding_4d_5d_input(): | |||
| padding = (3, 3, 2, 2, 1, 1) | |||
| data = np.random.randn(2, 3, 4, 5).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'replicate') | |||
| torch_result= F.pad(torch.tensor(data), padding, 'replicate') | |||
| param_compare(ms_result, torch_result) | |||
| data = np.random.randn(2, 3, 4, 5, 6).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'replicate') | |||
| torch_result= F.pad(torch.tensor(data), padding, 'replicate') | |||
| param_compare(ms_result, torch_result) | |||
| def test_pad_circular_1d_padding_3d_input(): | |||
| padding = (2, 2) | |||
| data = np.random.randn(2, 3, 4).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'circular') | |||
| torch_result= F.pad(torch.tensor(data), padding, 'circular') | |||
| param_compare(ms_result, torch_result) | |||
| def test_pad_circular_2d_padding_4d_input(): | |||
| padding = (2, 2, 3, 3) | |||
| data = np.random.randn(2, 3, 4, 5).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'circular') | |||
| torch_result= F.pad(torch.tensor(data), padding, 'circular') | |||
| param_compare(ms_result, torch_result) | |||
| def test_pad_circular_3d_padding_5d_input(): | |||
| padding = (3, 3, 2, 2, 1, 1) | |||
| data = np.random.randn(2, 3, 4, 5, 6).astype(np.float32) | |||
| ms_result = pad(ms_torch.tensor(data), padding, 'circular') | |||
| torch_result= F.pad(torch.tensor(data), padding, 'circular') | |||
| param_compare(ms_result, torch_result) | |||
| @SKIP_ENV_GRAPH_MODE(reason='def pad(input, pad,...): `pad` name is the same as function name, not support GraphMode') | |||
| def test_pad_graph(): | |||
| class PadNet(ms_torch.nn.Module): | |||
| def __init__(self): | |||
| super().__init__() | |||
| def forward(self, x, padding): | |||
| output = pad(x, padding, 'circular') | |||
| return output | |||
| data = np.random.randn(2, 3, 4, 5, 6).astype(np.float32) | |||
| net = PadNet() | |||
| padding = (3, 3, 2, 2, 1, 1) | |||
| x = ms_torch.tensor(data) | |||
| ms_result = net(x, padding) | |||
| torch_result= F.pad(torch.tensor(data), padding, 'circular') | |||
| param_compare(ms_result, torch_result) | |||
| @SKIP_ENV_GRAPH_MODE(reason='def pad(input, pad,...): `pad` name is the same as function name, not support GraphMode') | |||
| def test_pad_grad(): | |||
| class PadNet(ms_torch.nn.Module): | |||
| def __init__(self): | |||
| super().__init__() | |||
| def forward(self, x, padding): | |||
| output = pad(x, padding, 'circular') | |||
| output = ms_torch.sum(output) | |||
| return output | |||
| data = np.random.randn(2, 3, 4, 5, 6).astype(np.float32) | |||
| net = PadNet() | |||
| padding = (3, 3, 2, 2, 1, 1) | |||
| x = ms_torch.tensor(data) | |||
| ms_out, ms_gradient = ms.ops.value_and_grad(net)(x, padding) | |||
| torch_x = torch.tensor(data).requires_grad_(True) | |||
| torch_out = torch.sum(F.pad(torch_x, padding, 'circular')) | |||
| torch_out.backward() | |||
| torch_gradient = torch_x.grad | |||
| param_compare(ms_out, torch_out.detach()) | |||
| param_compare(ms_gradient, torch_gradient) | |||
| if __name__ == '__main__': | |||
| set_mode_by_env_config() | |||
| test_pad_shape() | |||
| test_pad_mode() | |||
| test_pad_mode() | |||
| test_pad_constant_value_2d_padding_4d_input() | |||
| test_pad_constant_value_2d_padding_5d_input() | |||
| test_pad_constant_value_3d_padding_4d_input() | |||
| test_pad_constant_value_3d_padding_5d_input() | |||
| test_pad_reflect_1d_padding_2d_3d_input() | |||
| test_pad_reflect_2d_padding_3d_4d_input() | |||
| test_pad_reflect_3d_padding_4d_5d_input() | |||
| test_pad_replicate_1d_padding_2d_3d_input() | |||
| test_pad_replicate_2d_padding_3d_4d_input() | |||
| test_pad_replicate_3d_padding_4d_5d_input() | |||
| test_pad_circular_1d_padding_3d_input() | |||
| test_pad_circular_2d_padding_4d_input() | |||
| test_pad_circular_3d_padding_5d_input() | |||
| test_pad_graph() | |||
| test_pad_grad() | |||
+ 4
- 6
testing/ut/pytorch/nn/functional/test_pdist.py
View File
| @@ -7,7 +7,7 @@ import torch | |||
| import numpy as np | |||
| from mindspore import context | |||
| from ....utils import set_mode_by_env_config | |||
| from ....utils import set_mode_by_env_config, param_compare | |||
| set_mode_by_env_config() | |||
| @@ -20,12 +20,11 @@ def test_pdist1(): | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.nn.functional.pdist(ms_input, 3.1) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| param_compare(ms_out, torch_out) | |||
| def test_pdist2(): | |||
| data = np.arange(0, 12).reshape(4, 3).astype(np.float32) | |||
| data = np.arange(0, 12).reshape(4, 3).astype(np.float64) | |||
| torch_input = torch.tensor(data) | |||
| torch_out = torch.nn.functional.pdist(torch_input, 0) | |||
| @@ -33,8 +32,7 @@ def test_pdist2(): | |||
| ms_input = ms_torch.tensor(data) | |||
| ms_out = ms_torch.nn.functional.pdist(ms_input, 0) | |||
| assert np.allclose(ms_out.asnumpy(), torch_out.numpy()) | |||
| assert ms_out.asnumpy().dtype == torch_out.numpy().dtype | |||
| param_compare(ms_out, torch_out) | |||
| if __name__ == '__main__': | |||